神经网络架构与技术
网络结构图¶
常见网络架构¶
上/下采样金字塔 Encoder–Decoder¶
- 编码端逐级下采样扩大感受野与抽象语义;解码端逐级上采样恢复空间分辨率
- 典型形状:逐级等比变化
- 编码:长宽减少,通道升高
- 解码:通道减少,长宽增加
- 优点
- 语义与细节的平衡:深层有全局上下文,浅层保留局部边界;金字塔汇聚多尺度信息。
- 计算可控:大部分重计算发生在低分辨率层。
长短程跳跃连接¶
- 短程跳跃连接
- 典型形态:块内的输出直接加到块内的输出
- 通常跨越很浅的层/一个残差块(2–3 个卷积层)
- 解决退化/梯度消失:深层网络训练难,恒等映射更易学;残差把学习目标从“映射”转为“残差”,优化曲面更平滑。
- 信息保真:保留低频/主成分,F(x) 只需补充高频/细节,提升收敛与泛化。
- 长程跳跃连接
- 典型形态:编码器早期的高分辨率特征,与解码器后期对应分辨率的特征融合
- 跨越多层/多个stage,连接网络的“远端”部分
- 多尺度与定位:编码器越深,语义更强但空间分辨率下降;把浅层的高分辨率边界/纹理特征送到解码端,可恢复精确定位。
- 梯度捷径:为早期层提供远端监督信号的“捷径”,缓解深层梯度衰减。
- t 跳跃后可用 add、concat 等策略进行叠加
具体实现¶
U-Net¶
一种编码器——解码器式的卷积神经网络架构 - U 型架构:左侧编码器逐步下采样取高层语义,右侧解码器逐步上采样回复空间分辨率,并通过跳跃连接把编码器对应层的特征拼接到解码器 - 一种编码器-解码器金字塔+长程跳连架构 - 是金字塔模型的一种具体实现架构
常见技术¶
上下采样¶
最简单的方法就是:卷积/池化(下采样)+最近邻/双线性(上采样)
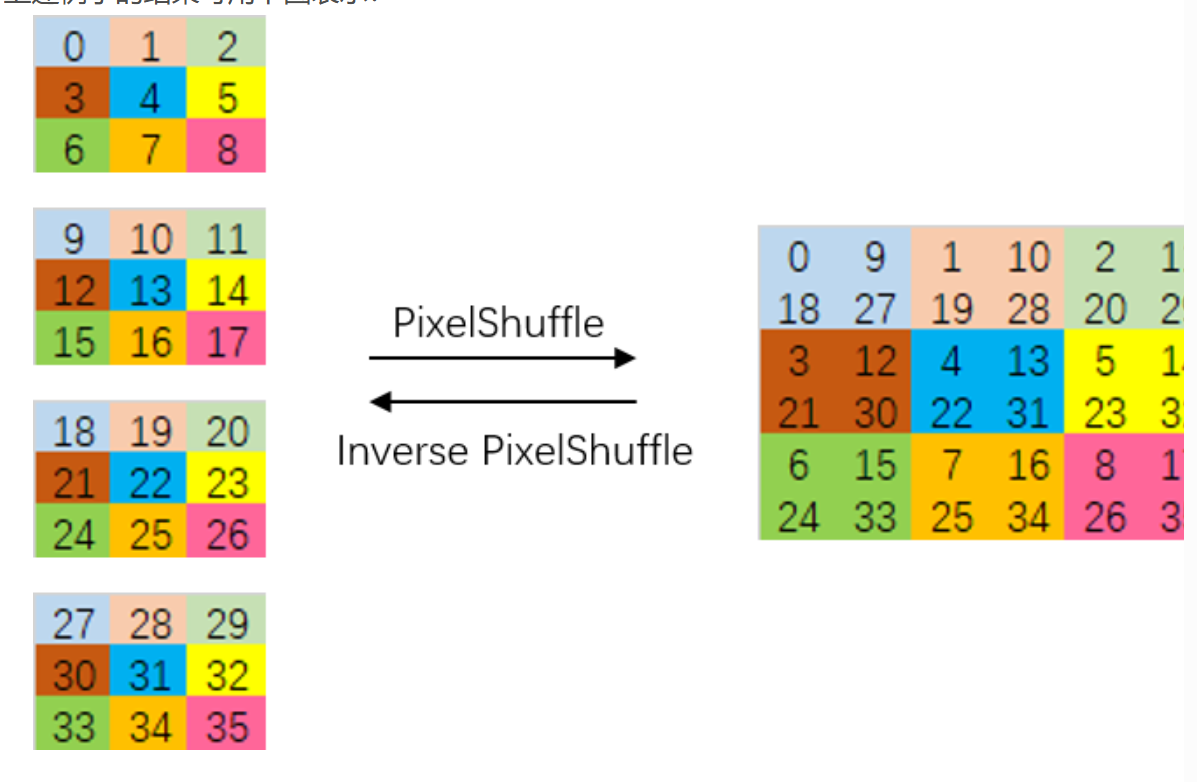
像素重排 PixelShuffle¶
- Space-to-Depth / Depth-to-Space(像素重排,S 2 D/D 2 S)
- S 2 D:把相邻 r×r 的空间邻域重排到通道维,相当于“降分辨率、升通道”的可逆重排操作。
- D 2 S:反操作,又称 PixelShuffle,把通道里的亚像素信息还原到更高分辨率的空间网格。
- 形状变化
- 输入: (B, C, H, W)
- S 2 D (r): (B, C·r², H/r, W/r)
- D 2 S (r): (B, C/(r²), H·r, W·r)
r=2的示意图- pytorch 提供了内置实现
nn.PixelUnshuffle(r), nn.PixelShuffle(r) - 优势
- 计算效率:把大分辨率问题转为低分辨率高通道,后续卷积算力更省。(\(n^2\to n\))
- 细节表达:将亚像素信息编码到通道,利于网络学习超分与抗走样。
- 可逆无损:与插值不同,重排不丢信息,端到端可微。
融合¶
通道拼接 Concat¶
- 把两个特征在通道维拼到一起,信息保留更加完整,后续通过卷积融合
- (B, C1, H, W) || (B, C2, H, W) → (B, C1+C2, H, W)
- 优点:保留完整信息,利于细节;
- 缺点:通道数变大、算力和显存上升。
逐元素相加 Add¶
- 要求融合的两张向量形状一致,直接叠加特征
- (B, C, H, W) + (B, C, H, W) → (B, C, H, W)
- 优点:轻量稳定,便于残差学习;
- 缺点:可能压掉差异性,信息融合更“保守”。