实时渲染第四版
渲染管线流程¶
- 应用阶段:
- 基本运行在 CPU,少部分计算如计算着色器运行在 GPU
- 进行碰撞检测、动画、物理模拟等任务
- 几何处理阶段
- 负责逐三角形和逐顶点的操作
- 顶点着色、投影、裁剪、屏幕映射
- 可选:曲面细分、几何着色器、流式输出
- 光栅化阶段
- 对前一阶段中被保留下来的图元进行光栅化,找到位于图元内部的像素,发送到后面的像素处理阶段
- 三角形设置、三角形遍历
- 像素处理阶段
- 逐像素处理和操作:像素着色和合并
- 关键是计算出每个可见图元所覆盖像素的颜色值,对纹理进行渲染;通识用 z-buffer 解决可见性问题,最终实现将图像显示在屏幕上
图形处理单元¶
GPU 的工作模式-SIMD¶
- 用一套指令同时驱动多条并行“车道”(组成一个线程组 wrap)对不同数据做同样运算,并在等待时快速切换线程组以保持硬件满负荷。
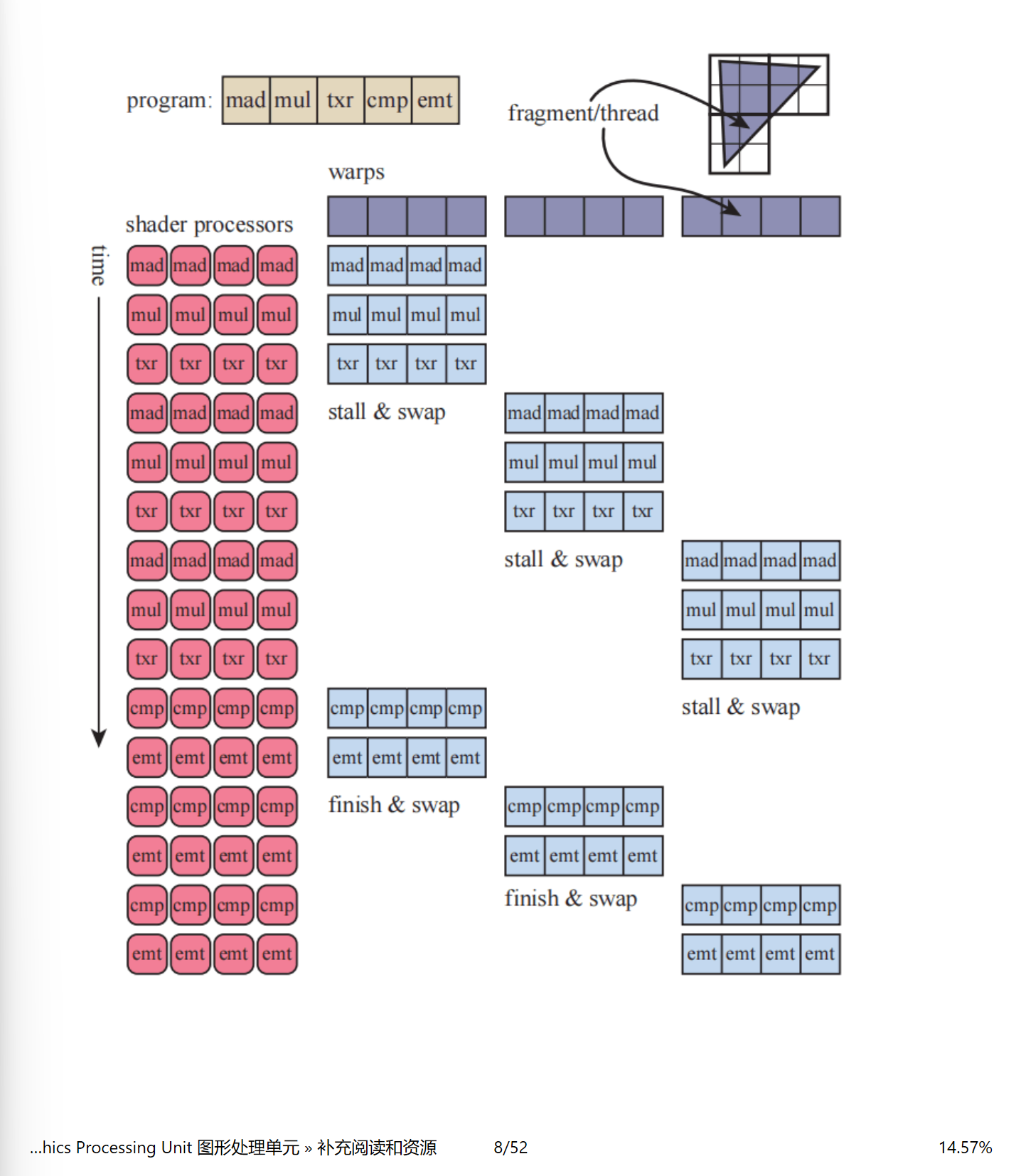
- 一线程组并行处理多组数据,当被阻断时切换另一个线程组继续执行,保证硬件性能被充分利用 影响性能的因素:
- 线程发散:遇到 if/loop 等动态分支时,不同线程走了不同路径。由于 SIMD 需要“同指令同步执行”,硬件只能先执行一条分支、用掩码屏蔽未走该分支的线程,再执行另一条分支;结果是有效并行度被分摊,部分线程空转,整体吞吐下降。
- 让同一 warp 内的数据尽量同质,减少条件分歧(空间分块、按材质/状态批处理)。
- 用分支可替代的算术/插值/step/saturate 等无分歧写法。
- 把重分支逻辑放到较粗粒度阶段(CPU、Compute 预分类)。
- 循环次数固定或上限一致,避免每线程循环次数差异过大。
- 寄存器的数目影响 GPU 上能同时存在的线程数量和 wrap 数量
GPU 管线¶

绿色为可编程图形管线
- 顶点着色器-曲面细分-几何着色器-裁剪-屏幕映射-三角形设置与遍历(光栅化)-片元着色器-混合输出