P10
简述RDD、DataFrame、DataSet的区别¶
- RDD (Resilient Distributed Dataset):
- RDD 是 Spark 的基本抽象,提供了一个不可变、分布式的数据集合,可以并行操作。
- 特点:
- 支持底层的数据处理抽象。
- 提供了详细的控制,允许用户手动优化。
- 支持各种数据类型,但无法针对数据结构进行编程,对结构化数据的访问和操作没有优化(更适合处理非结构化数据)
-
RDD 更适合低层次的数据处理和需要精细控制的场景
-
DataFrame:
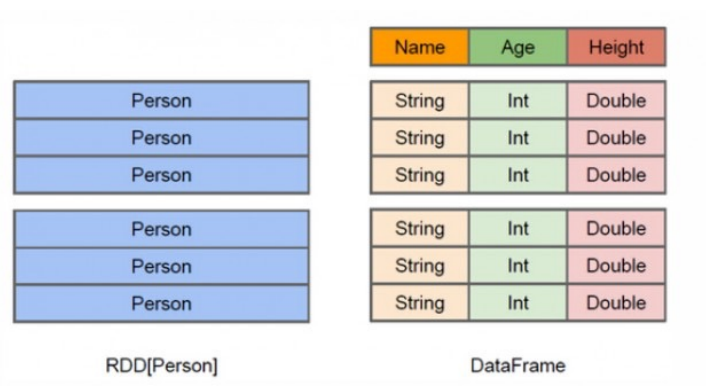
- DataFrame 是一个分布式的数据集合,类似于关系型数据库中的表,具有列和行的概念。
-
特点:
- 高级抽象,构建在RDD之上。
- 支持多种数据源。只能处理结构化数据,无法很好处理非结构数据。
- 能够通过提供的 schema 自动推断数据类型。
- 经过优化,性能较好
- DataFrame 提供了一个高效的接口,适用于结构化数据的查询操作
-
DataSet:

- DataSet API 是 DataFrame API 的一个扩展,提供了类型安全的对象接口。
- 特点:
- 结合了RDD的类型安全和DataFrame的优化能力。
- 提供了编译时类型检查。
- 支持各种数据类型,结构化和非结构化。
- 通过 Encoder 进行序列化,比RDD更高效。
- DataSet 结合了两者的优点,适用于需要类型安全和高效处理能力的场。
简述Spark ML的流水线含义¶
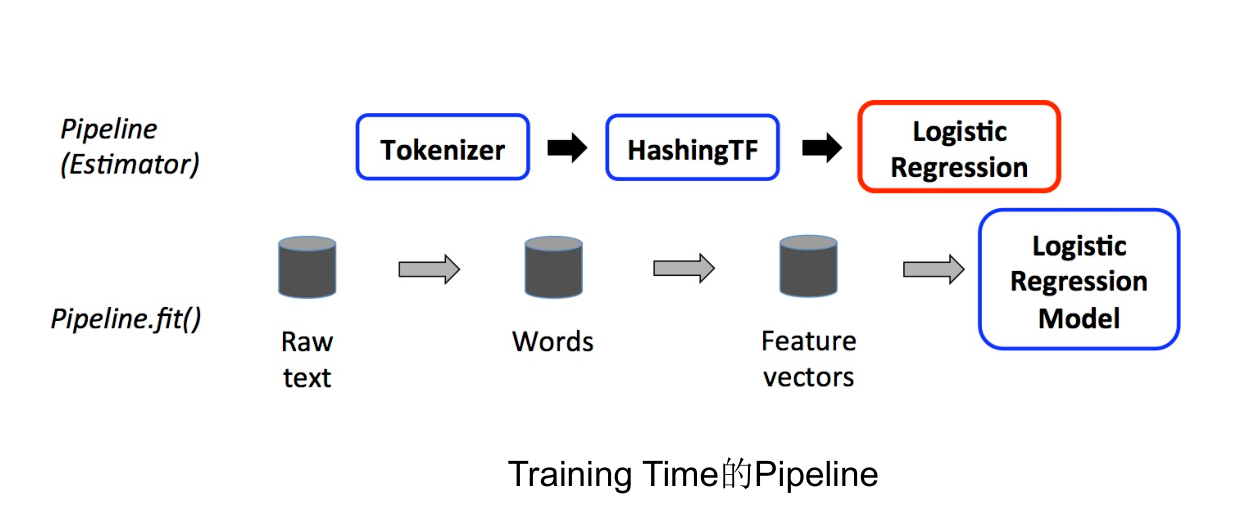
- Spark ML库中的流水线是一个由多个阶段组成的工作流程,用于构建和调优机器学习模型。在 Spark ML中,一个流水线代表了一个完整的数据处理和学习过程,它将数据转换、特征提取、模型训练等步骤串联起来,形成一个可以顺序执行的工作流,主要由Transformer和Estimator两种算法组成。
-
Transformer:可以将一个DataFrame转换为另一个DataFrame。
-
Estimator:可以拟合(训练)数据并产生一个Transformer的算法,用于构建训练模型。
-
Pipeline:指定连接多个Transformers和Estimators的ML工作流。
-
Parameter:全部的Transformers和Estimators共享一个指定Parameter的通用API。
-
工作流程:首先使用几个
Transformer对原始数据进行预处理,然后使用一个Estimator来拟合一个模型,最后使用该模型(作为一个Transformer)对新数据进行预测。 -
一个流水线被指定为一系列由Transformer或Estimator组成的阶段。这些阶段按照顺序运行,输入的DataFrame在运行的每个阶段进行转换
-
简述批量计算和流式计算的区别¶
- 数据处理单位:
- 批量计算:以数据块为单位进行处理。在批量计算中,每个任务接收一定大小的数据块进行处理。这意味着系统会等待直到收集到足够的数据后才开始处理。
-
流式计算:以单条数据记录为单位进行处理。流式计算的算子处理完一条数据后会立即将其发送给下游算子,因此数据的处理延迟通常很短。
-
数据源:
- 批量计算:通常处理静态的、有限的数据集,这些数据集被存储在文件系统如 HDFS 或数据库中。
-
流式计算:用于处理连续生成的、潜在无限的数据流。
-
任务类型:
- 批量计算:任务通常是一次性的,也就是说,每个任务在处理完分配给它的数据块后就会结束。批量作业通常有明确的开始和结束。
-
流式计算:任务通常是持久运行的,也称为长任务。这些任务不停地从数据源接收数据,处理后即时产出结果。流式计算的任务可能永远不会结束,除非显式停止。
-
离线=批量?实时=流式?
- 离线和实时应该指的是:数据处理的延迟;批量和流式指的是:数据处理的方式。两者并没有必然的关系。事实上 Spark streaming 就是采用小批量的方式来实现实时计算。
简述Spark Streaming和Spark Structured Streaming的区别¶
- 流模型:
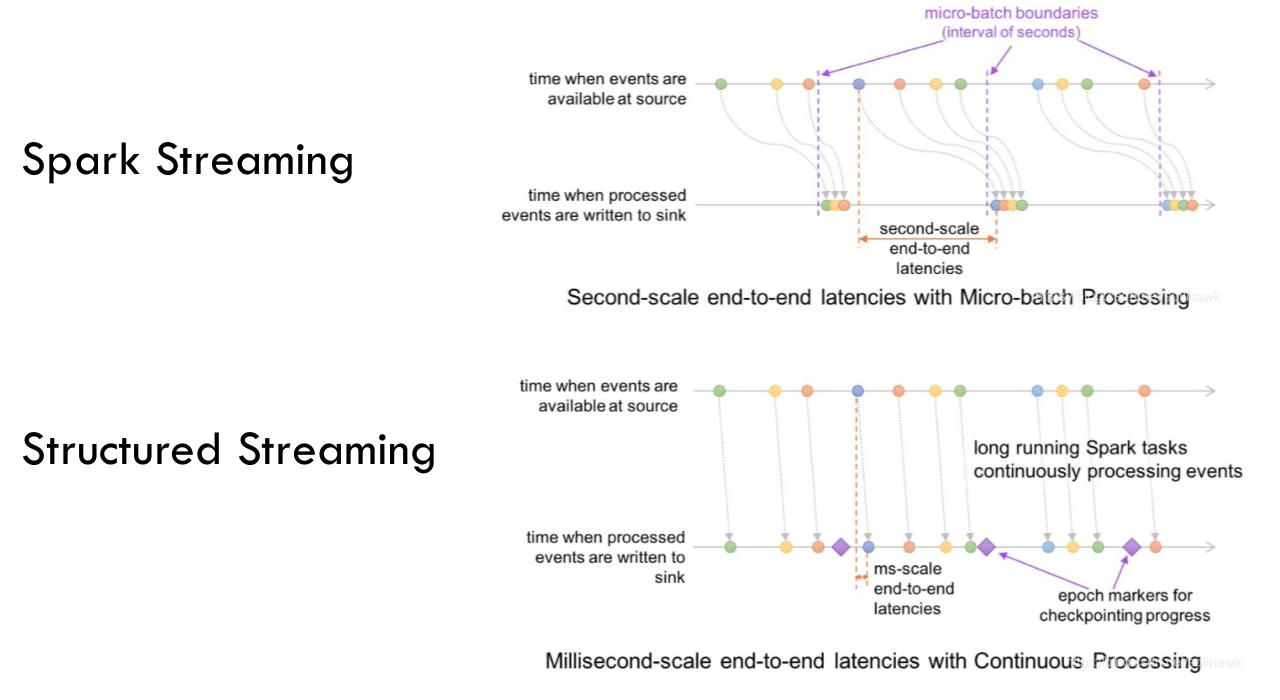
- Spark Streaming 是Spark最初的流处理框架,使用微批处理的方法。提供了基于RDDs的Dstream API,每个时间间隔内的数据为一个RDD,源源不断对RDD进行处理来实现流计算.
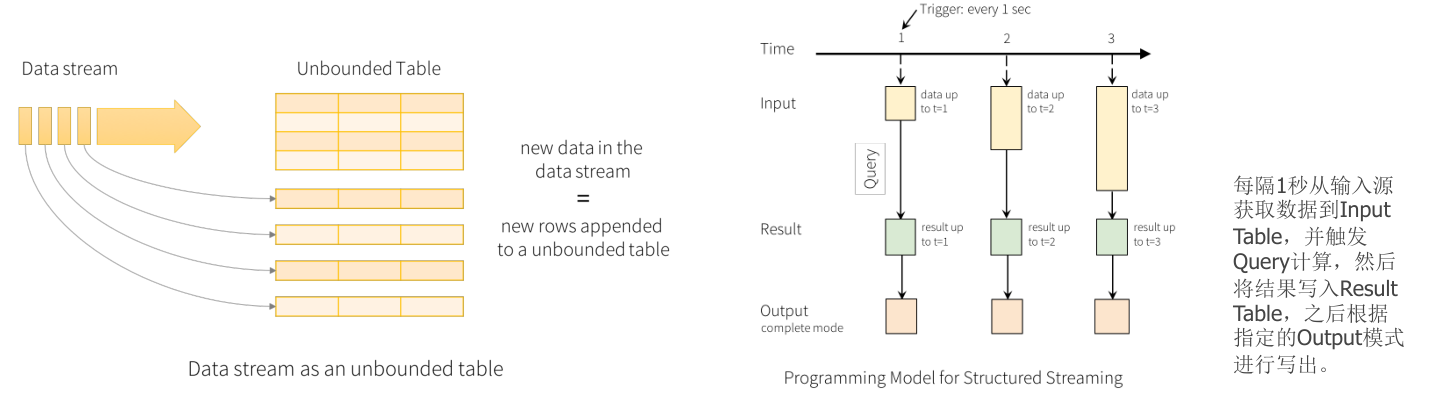
- Structured Streaming 把实时数据流看作是一个无界表,每个数据项的到来就像是向表中追加新行。它构建在 Spark SQL 引擎之上,提供了使用 DataFrame 和 DataSet API 处理数据流的能力。
-
-
编程接口:
- Spark Streaming 提供的是基于 RDD 的 DStream API。
-
Structured Streaming 使用 DataFrame 和 DataSet API,允许使用 Spark SQL 的功能来处理数据。
-
处理时间和事件时间:
- 处理时间:流处理引擎接收到数据的时间
- 事件时间:事件真正发生的时间
- Spark Streaming 主要基于处理时间,即数据到达处理引擎的时间。
- Structured Streaming 支持基于事件时间的数据处理,允许开发者根据数据中包含的时间戳字段来处理数据,这对于处理乱序数据或实现窗口计算非常重要。
-
-
可靠性保障:
- Spark Streaming 和 Structured Streaming 都使用了 checkpoint 机制来提供可靠性保证,通过设置检查点将数据保存到文件系统,并在出现故障时恢复数据。
- 在 Spark Streaming 中,如果修改了流程序的代码,从 checkpoint 恢复时可能会出现兼容性问题,因为 Spark 可能无法识别修改后的程序。
-
在 Structured Streaming 中,对于指定的代码更改,通常可以从 checkpoint 中恢复数据而不受影响。
-
输出 Sink:
- Spark Streaming 提供了
foreachRDD方法,允许开发者自行编程来将每个批次的数据写出。 -
Structured Streaming 提供了内置的 sink(如 Console Sink、File Sink、Kafka Sink 等),并通过
DataStreamWriter提供了一个简单的配置接口。对于自定义 sink,它提供了ForeachWriter接口。 -
总结:
- Structured Streaming 提供了更简洁的 API、更完善的流功能,并且更适合于流处理的场景。
- Spark Streaming 可能更适合于处理时间不是非常敏感的场景,它已经成为了一个遗留项目,不再更新。
简述GraphX的弹性分布式属性图的设计思想¶
- 具有图视图和表视图两种不同的表示,可以适应不同的操作。并且共用存储不会占用额外的空间
- 表视图: 图的顶点和边可以被表示为两个表(顶点表和边表),使得可以使用Spark SQL的强大功能来进行结构化查询和数据操作。
- 图视图: 传统的图操作,如子图提取、连通组件、最短路径等,可以直接在图视图上执行。
-
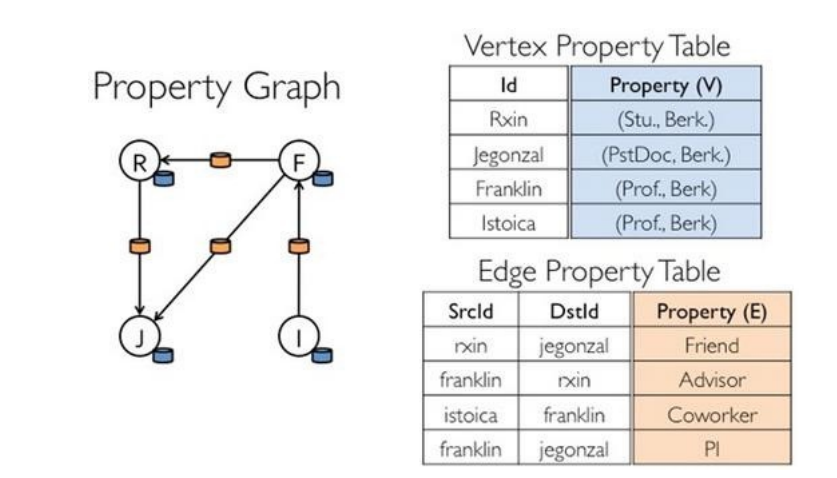
-
对 Graph 视图的所有操作,最终都会转换成其关联的 Table 视图的 RDD 操作来完成。这样对一个图的计算,最终在逻辑上,等价于一系列 RDD 的转换过程。因此 Graph 具备 RDD 的关键特性:具有弹性、分布性、不变性等优良性质
- 是一种属性图,点和边都带有用户自定义的属性,图不仅能表达实体之间的关系,还能存储关于这些实体和关系的丰富信息。