P3
211275022田昊东¶
1.简述MapReduce的主要功能和设计思想。¶
主要功能¶
- 出错处理:MapReduce能够检测并隔离出错节点,同时调度分配新的节点来接管出错节点的计算任务,从而确保计算的稳定性和可靠性。
- 分布式数据存储与文件管理:MapReduce 将海量数据分布存储在各个节点的本地磁盘上,但同时保持整个数据在逻辑上成为一个完整的数据文件。并且并且具有备份存储和容错机制。
- Combiner和Partitioner:为了减少数据通信开销,MapReduce引入了Combiner和Partitioner。Combiner负责在将数据发送到Reduce处理之前,将具有相同主键的数据在Map节点上合并,从而避免了重复传送相同数据。Partitioner则负责将Map节点输出的中间结果适当划分,以确保相关数据被发送到同一个Reduce节点,提高数据处理效率。
- 任务调度:提交的计算作业会被划分为很多个计算任务,任务调度是MapReduce的核心功能之一。它负责为这些计算任务分配和调度Map和Reduce计算节点,同时监控节点的执行状况。
- 数据/代码互定位:为了减少数据通讯的开销,MapReduce 采用了数据本地性原则,即尽量让一个计算节点处理其本地磁盘上所分布存储的数据。当无法进行本地化数据处理时,MapReduce 会寻找其他可用节点并将数据从网络上传送给该节点进行处理,以实现数据和代码的互定位。
设计思想¶
- 横向扩展取替向扩展:MapReduce采用了横向扩展的策略,选择了价格便宜、易于扩展的大量低端商用服务器,而不是昂贵且难以扩展的高端服务器。
- 认为失效是常态
- 处理向数据迁移:MapReduce倡导将处理向数据靠拢和迁移,而不是传送大量数据到处理节点。通过数据/代码互定位的技术方法,计算节点首先尽量处理本地存储的数据,充分发挥数据本地化的特点。仅当节点无法处理本地数据时,才采用就近原则寻找其他可用计算节点,并将数据传送到该节点。
- 顺序处理数据、避免随机访问数据:由于大规模数据处理涉及到大量的数据记录,不可能将所有数据存放在内存中进行处理,因此需要处理外存中的数据。磁盘的随机访问相对较慢,MapReduce 采用顺序处理数据的策略,避免了随机访问数据。
- 为应用开发者隐藏系统层细节:MapReduce提供了一个抽象机制,将应用程序开发者与系统层细节隔离开来。开发者只需描述需要进行什么计算,而具体的执行细节则由MapReduce系统的执行框架处理。
- 数据扩展和系统规模扩展:MapReduce强调算法应该能够随着数据规模的扩大而保持持续的有效性,性能下降应与数据规模扩大的倍数相当。同时,在集群规模上,要求算法的计算性能应能够随着节点数的增加保持接近线性程度的增长,以确保系统在大规模数据处理时仍然具备高效的计算能力。
2.简述GFS的基本设计原则和数据访问过程。¶
设计原则¶
- 廉价本地磁盘分布存储
- 多数据自动备份解决可靠性:采用廉价的普通磁盘,把磁盘数据出错视为常态,用自动多数据备份存储解决数据存储可靠性问题
- 为上层的 MapReduce 计算框架提供支撑:GFS 作为向上层 MapReduce 执行框架的底层数据存储支撑,负责处理所有的数据自动存储和容错处理。
- 高容错性和可恢复性:GFS的设计原则之一是具备高容错性和可恢复性。由于采用了大量低端服务器,硬件故障和节点失效是常态。GFS通过自动数据备份和数据冗余机制来保证数据的安全性和可靠性。当一个节点发生故障时,系统能够自动切换到备份数据,保证服务的连续性。
访问过程¶
-
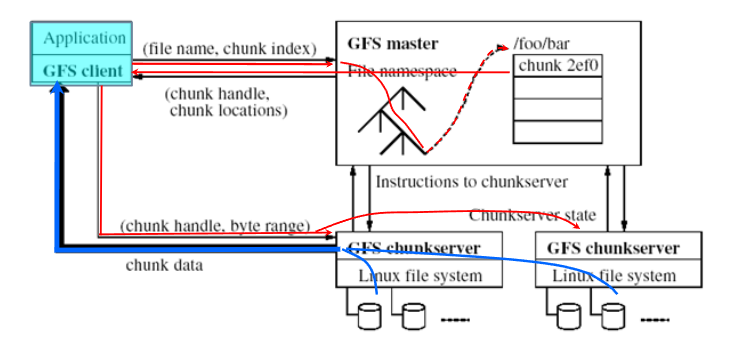
-
告诉GFS Server所要访问的文件名或者数据块索引是什么
- GFS Server根据文件名和数据块索引在其文件目录空间中查找和定位该文件或数据块,找出数据块具体在哪些ChunkServer上;将这些位置信息回送给应用程序
- 应用程序根据GFS Server返回的具体Chunk数据块位置信息,直接访问相应的ChunkServer,直接读取指定位置的数据进行计算处理
3.简述BigTable的数据模型设计。¶
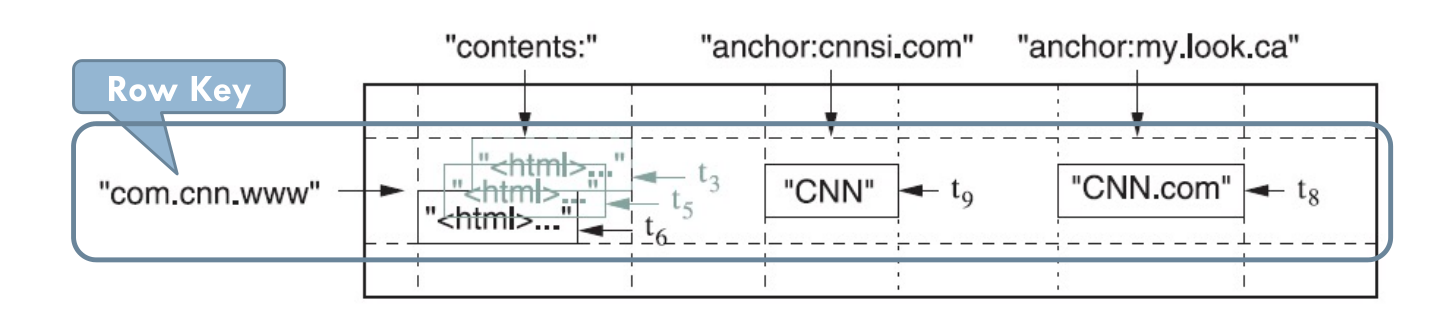
- BigTable主要是一个分布式多维表:通过一个行关键字、一个列关键字、一个时间戳进行索引和查询定位。 (row:string, column:string,time:int64)-> 结果数据字节串(cell)
- 行是大小不超过64KB的任意字符串。表中的数据都是根据行关键字进行排序的。
- 在行的基础上,又分割为不同的列(子表)
- 多个列构成一个列族,族中的数据属于同一类别,一个列族下的数据会被压缩在一起存放,列族是访问控制的单位。
- 查询具体一个列的列键可以由两部分组成 (族名:列名) 。列族用于将数据分类,而列限定符用于唯一标识特定列族中的数据单元格。
- 在确定行、列(族名:列名)、时间戳(会保留一段时间内的历史版本)后就可以通过查询获得目标数据