P5
设计思路¶
- Mapper
java
public static class MergeMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
context.write(value, new Text(""));
}
}
-
输入键<偏移量,一行文本>;输出键<文本(类型+股票编号),文本>
-
直接将类型+股票编号作为中间值的键传出
-
Reducer
public static class MergeReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
context.write(key, new Text(""));
}
}
-
直接将中间值输出,这是因为归并之后键已经被自动整合,实现了去重
-
main
java
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Merge Files");
job.setJarByClass(MergeFiles.class);
job.setMapperClass(MergeMapper.class);
job.setReducerClass(MergeReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0])); // 输入路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); // 输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
- 有两个命令行参数,分别指定输入和输出路径,并配置job
运行结果¶

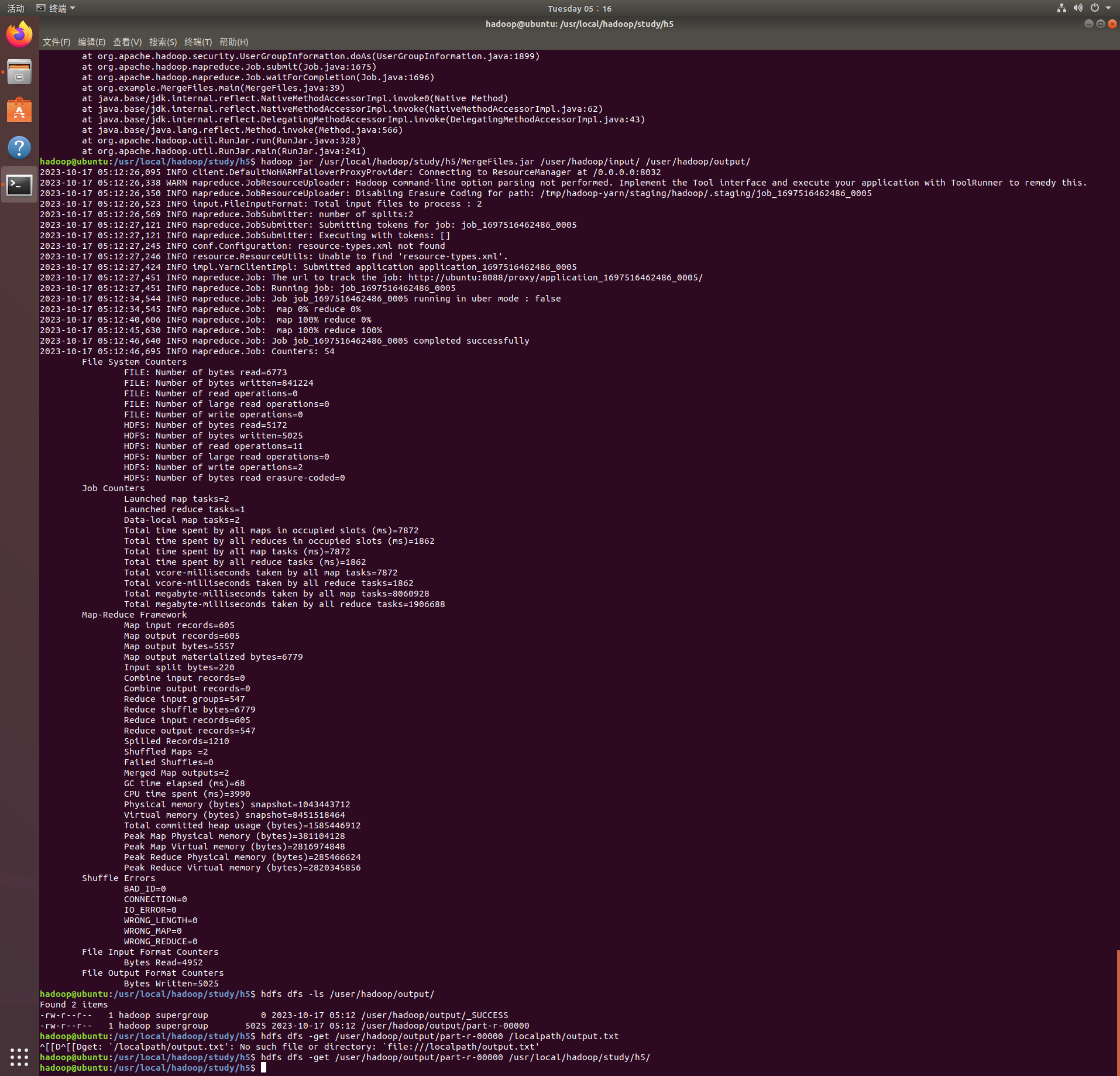
进一步分析¶
性能¶
- mapper实际上什么工作也没有作,存在冗余的问题。并且产生了许多Text空对象,而且一个键可能对应多个空Text对象,这意味着在Hadoop的Shuffle阶段,这些空对象都会被传输和排序,虽然它们对结果没有任何贡献。这不仅浪费了网络带宽,而且也浪费了存储和计算资源。
扩展性¶
- 只允许输入一个输入路径和一个输出路径,参数固定不够灵活。
安全性¶
- 没有对输入参数的数目等进行检查,这可能导致程序的崩溃(在测试时就由于疏忽输错参数出现了该问题),应当增加参数验证和错误处理机制。