P7
简述HBase的数据模型¶
- HBase的数据模型是一个稀疏、多维度、排序的映射表,这张表的索引是行键、列族、列限定符和时间戳。
- 所有数据都以字符串进行存储,用户需要自行进行数据类型的转换
- 每一行都有一个可排序的行键和任意多的列
- 表由一个或多个列族组成,一个列族可以包含很多个列。列族支持动态扩展,不需要预定义数量及类型,同一列族的数据存储在一起。
- 由行键、列族、列限定符可以确定一个单元格,单元格内有数据的不同版本(HBase执行更新操作时不删除,只生成新的),再使用时间戳进行索引
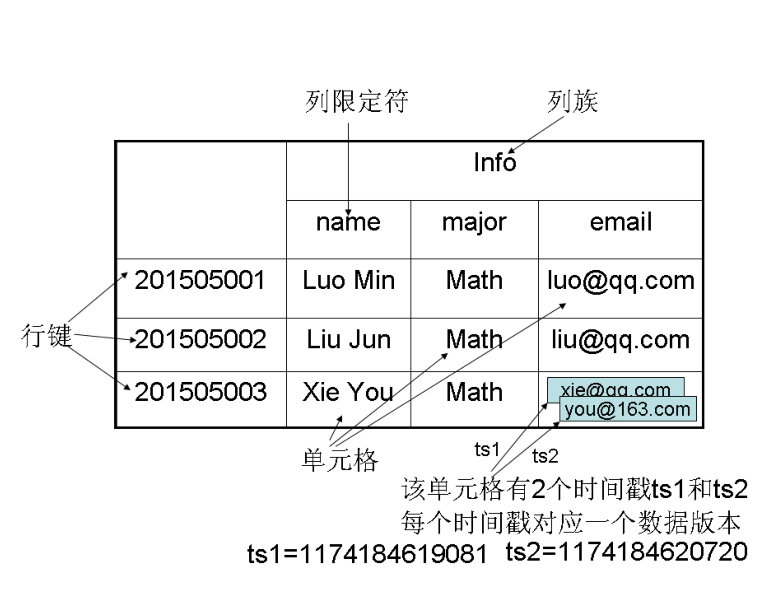
- 即通过四元组获取数据
[行键, 列族, 列限定符, 时间戳] - 行主键:检索记录的主键
- 可以访问单行或进行范围访问
- 存储时根据行键进行排序
- 列族:
- 列族需要在表使用前进行定义,修改比较麻烦
- 访问控制以及在 HDFS 中存储的基本单位
- 时间戳:每个 cell 都保存着同一份数据的多个版本
简述HBase的概念视图和物理视图的不同¶
- 概念视图表述:HBase一定程度上又可以看成一个多维度的Map模型去理解它的数据模型。可以看作一个逐级映射的字典
- 在概念视图上HBase的结构与传统的关系数据库类似,以行为单位
-
概念试视图是一种逻辑上的结构
-
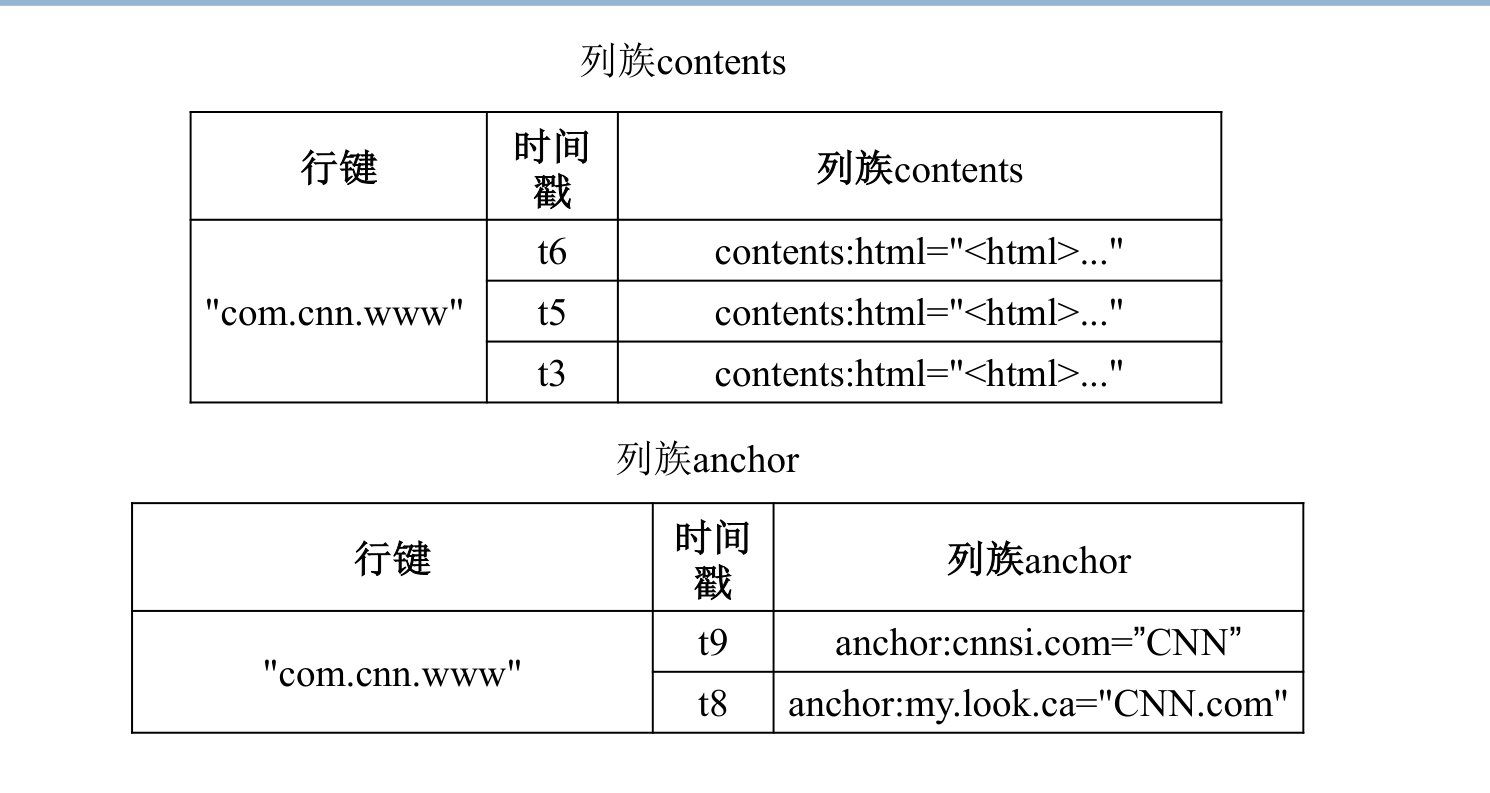
物理视图表述:物理存储格式上按逻辑模型中的行进行分割,并按照列族存储(相同列族的项存储在同一个文件)。值为空的列不予存储(处理稀疏表)。因此可以方便的对列族进行处理,并且可以灵活的只对需要的列进行读取,而不需要按行为单位整个处理。
- 每个列族存储在一个独立文件 IFile 中,在存储文件的内部根据行进行排序,方便根据行键进行快速检索
- 列式存储适合读取操作多,每次读取列少的情况。
-
-
区别
- 概念视图关注于数据的逻辑组织和表结构,而物理视图关注于数据的实际存储、分布式处理和底层架构。
- 概念视图简化了用户与HBase的交互,而物理视图解释了HBase如何实现高性能和水平扩展。

简述HBase系统基本架构以及每个部分的作用¶
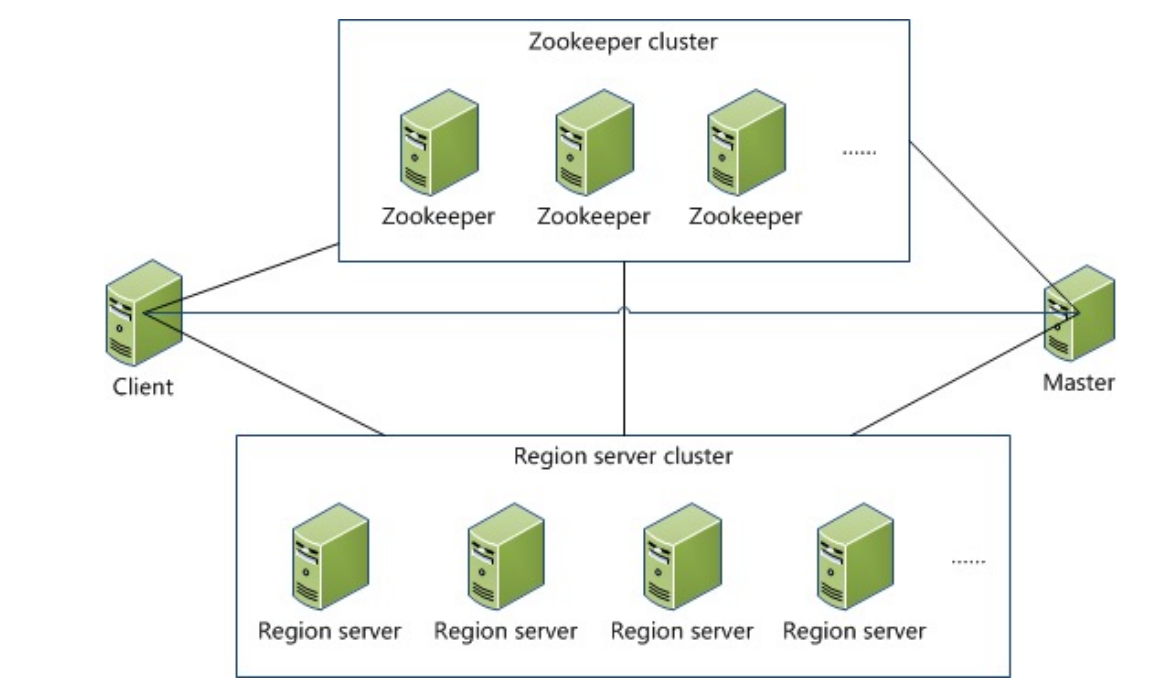
- 系统架构
-
-
Master主要负责表和 Region 的管理工作:
- 表和区域管理:负责表的创建、删除以及区域分裂和合并。管理用户对表的增加、删除、修改、查询等操作
-
负载均衡:对区域进行负载均衡,将区域分配到不同的 RegionServer。对发生故障失效的 Region 服务器上的 Region 进行迁移
-
RegionServer负责维护分配给自己的 Region(合并、分类等),并响应用户的读写请求
-
ZooKeeper 帮助选举出一个 Master 作为集群的总管,并保证在任何时刻总有唯一一个 Master 在运行,这就避免了 Master 的“单点失效”问题
-
Client:包含访问HBase的接口,同时在缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程
简述HBase数据查询定位方法及三层结构中各层次的名称和作用¶
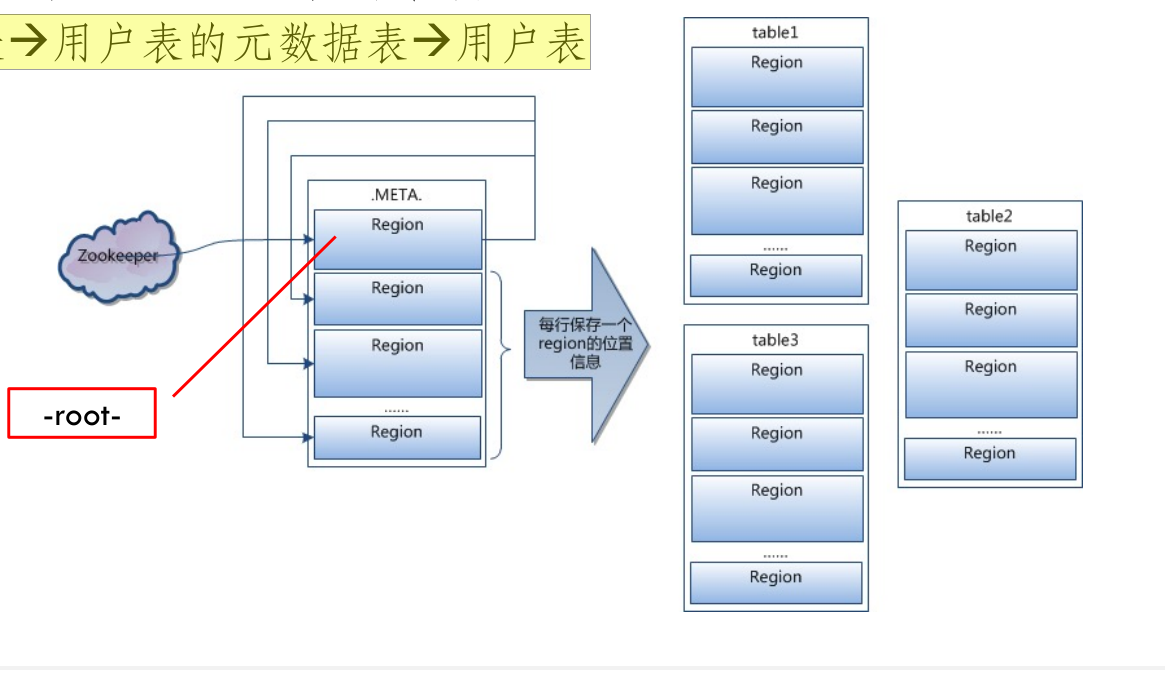
- 三层结构:
- HBase 使用三层类似 B+树的结构来保存 Region 位置
- Zookeeper文件:记录了-ROOT-表的位置信息
- -ROOT-表:记录了.META.表的Region位置信息。通过-ROOT-表,就可以访问.META.表中的数据
- .META.表:记录了用户数据表的Region位置信息,.META.表可以有多个Region,保存了HBase中所有用户数据表的Region位置信息
-
-
数据查询定位方法:
- 访问Zookeeper:首先访问Zookeeper获取-ROOT-表的位置信息。
- 查询-ROOT-表:查询-ROOT-表找到.META.表的Region位置信息。
- 访问.META.表:查询.META.表得到目标用户数据表的Region位置信息。
- 定位Region:根据.META.表提供的信息,HBase可以定位到包含所需数据的具体Region,并将查询请求发送到负责该Region的RegionServer。
- RegionServer处理:RegionServer接收查询请求后,检索相应的Region,并返回查询结果。