P8
简述Hive和HBase的区别¶
- HBase与Hive通常是配合使用的,HBase针对OLTP(联机事务处理),Hive针对OLAP(联机分析处理)
- HBase 是基于 Hadoop 的 NoSQL 的数据库,而 Hive 严格上来说不是数据库,主要目的是为了让开发人员能够通过 SQL 来计算和处理 HDFS 上的结构化数据。
- Hive是逻辑表,通过元数据描述HDFS上的结构化文本数据,而Hive本身不存储数据,完全依赖HDFS和MapReduce;而HBase则是一个物理表,存储了非结构化数据
- Hive 是基于行模式,而 HBase 基于列模式。
- HBase 的表是疏松的存储的,因此用户可以给行定义各种不同的列;而 Hive 表是稠密型,即定义多少列,每一行有存储固定列数的数据(类似于关系型数据库)。
- Hive不能保证处理的低迟延问题;而HBase是近实时系统。
-
Hive 提供完整的 SQL 实现,通常被用来做一些基于历史数据的挖掘、分析。而 HBase 不适用于有 join,多级索引,表关系复杂的应用场景。
-
数据源抽取到HDFS存储->通过Hive清洗、处理和计算原始数据->可存入HBase->数据应用从HBase查询数据
简述Hive的体系结构和各组成模块的作用¶
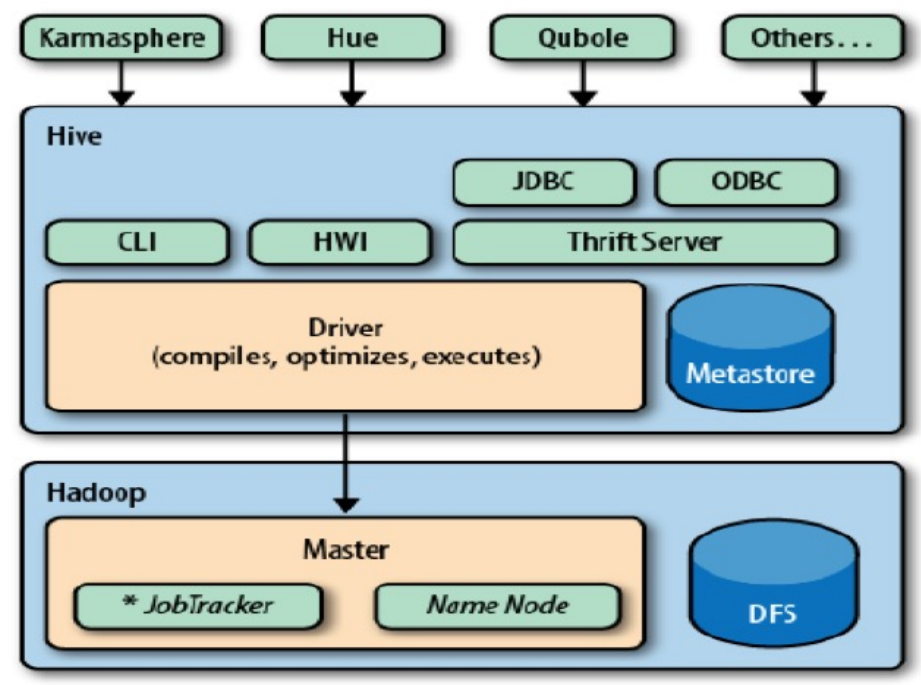
- Hive 是构建在整个 hadoop 之上的,主要由 Driver(Complier、 Optimizer、Executor)、Metastore、客户端(CLI、HWI、ThriftServers(JDBC、ODBC))组成
-
-
用户接口:Hive 提供了几种用户交互接口,这些接口允许用户通过 HiveQL来与 Hive 进行交互。
- CLI组件:命令行接口。
- ThriftServers:提供JDBC和ODBC接入的能力
-
Hive WEB Interface(HWI):提供了一种通过网页的方式访问 hive 的服务。
-
HiveQL 处理引擎 Driver:用户提交的 HiveQL 查询会被解析、优化(Complier、Optimizer 和 Executor),最终转换为一系列的 MapReduce 任务,以便在 Hadoop 集群上执行。
-
元数据存储Metastore:Hive使用一个关系数据库来存储元数据,这些元数据包括表结构、列数据类型、表分区信息等。
简述Hive的数据模型¶
-
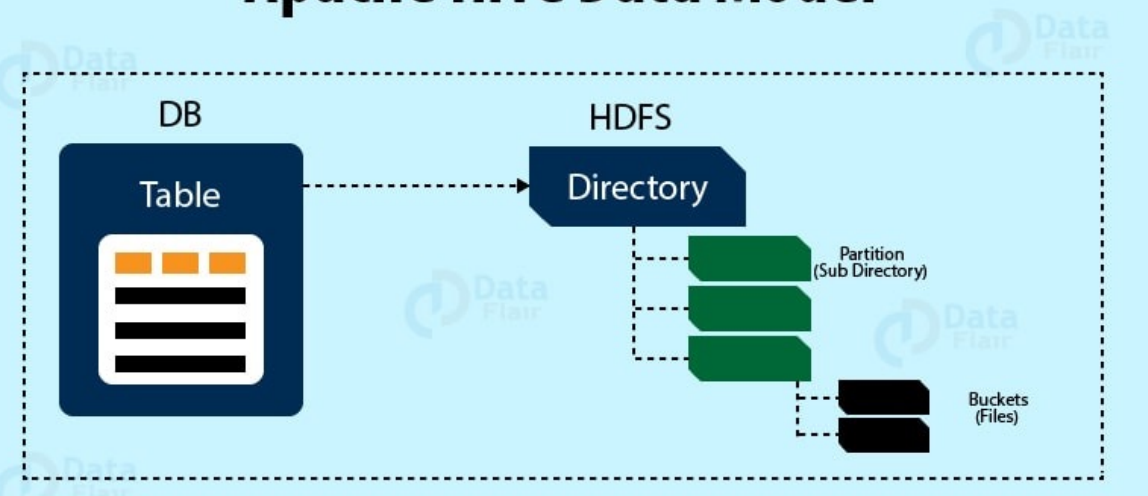
Hive 的数据模型是一个表->分区->桶->记录的多级结构
-
表:
-
在 Hive 中,表是最顶层的数据组织单位,类似于传统关系型数据库中的表。表中存储了相关的数据,并且有固定的列和数据类型。
-
分区:
- 根据分区键进行分区,提高了查询数据的效率
- 在查询某一个分区的数据的时候,只需要查询相对应目录下的数据,而不会执行全表扫描,也就是说, Hive在查询的时候会进行分区剪裁。
-
此外每个表可以有一个或多个分区键。
-
桶:
- 在分区内部,数据可以进一步划分为桶。在一定范围内的数据按照 Hash 的方式进行划分
-
Hive 是针对表的某一列进行分桶。Hive 采用对表的列值进行哈希计算,然后除以桶的个数求余的方式决定该条记录存放在哪个桶中。分桶的好处是可以获得更高的查询处理效率,使取样更高效。
-
记录:
-
在桶内部,数据以行的形式存储,每行数据由多个列组成。
-
元数据存储metastore:起到了整体组织的作用
- 元数据使用SQL的形式存储在传统的关系数据库中,可以使用任意一种关系数据库
-
在数据库中,保存最重要的信息是有关数据库中的数据表格描述,包括每一个表的格式定义,列的类型等
-
metastore 运行模式
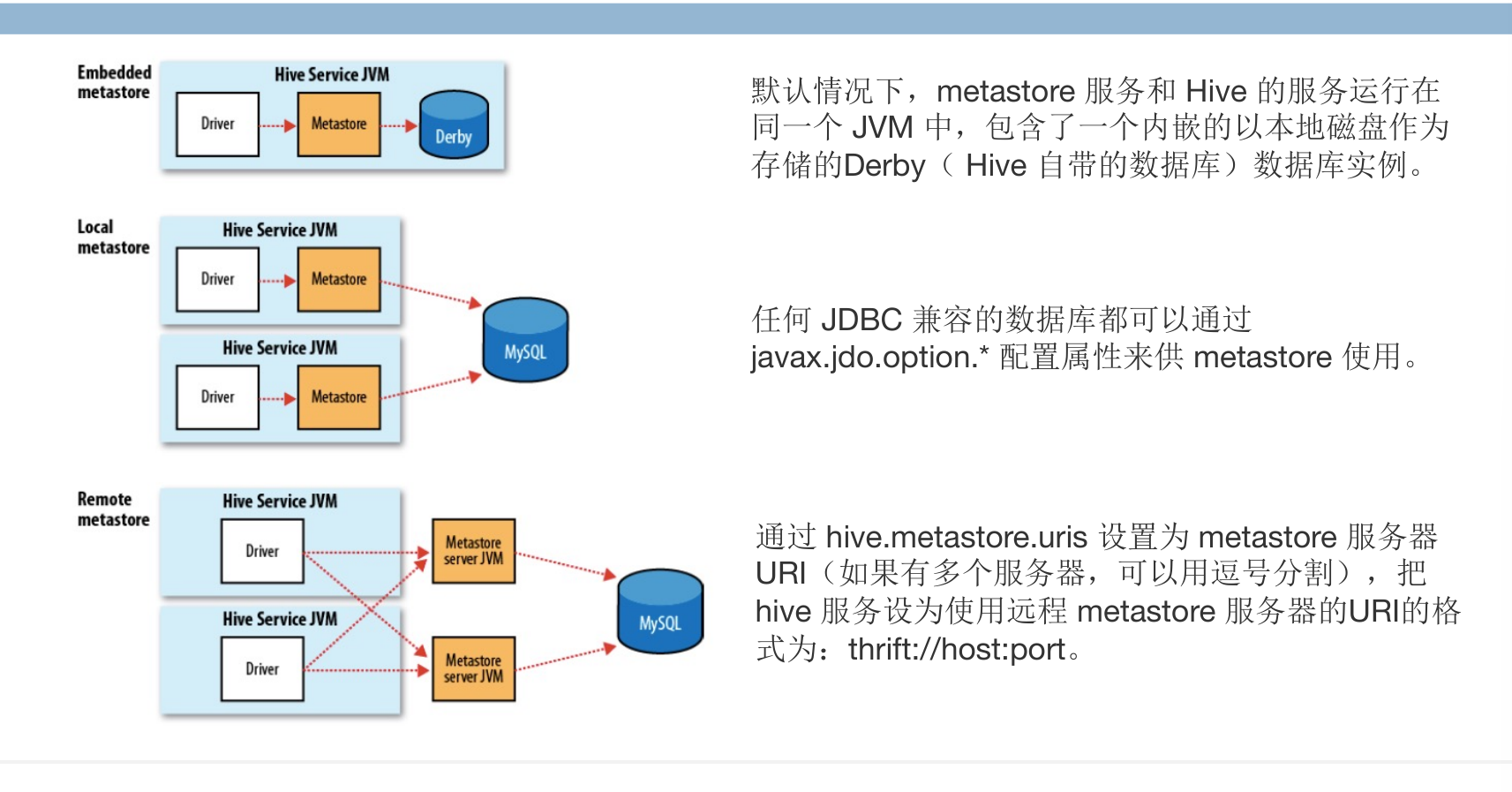
- 内嵌 Metastore:Hive 的默认设置。在这种模式下,Hive 会使用一个内嵌的 Derby 数据库实例来存储元数据,每次只能被一个 Hive 会话打开。
- 本地 Metastore:在本地 Metastore 配置中,元数据服务作为 Hive 服务的一部分运行在同一个 JVM 进程中。但使用一个独立的数据库来存储元数据,这个数据库可以是 MySQL、PostgreSQL 等。允许多个 Hive 客户端同时访问 Metastore。
- 远程 Metastore:在远程 Metastore 配置中,Metastore 服务在独立于 Hive 服务的不同进程中运行。这意味着一个或多个 Metastore 服务器可以服务于多个 Hive 实例。
编写HiveQL语句完成实验3中三张表的创建、加载数据,查询BigData成绩为90及以上的学生姓名,并按成绩从大到小排序。¶
- 表的创建:
-
学生表
CREATE TABLE student (S_No STRING, S_Name STRING, S_Sex STRING, S_Age INT); -
课程表
CREATE TABLE course (C_No STRING, C_Name STRING, C_Credit FLOAT); -
选课表
CREATE TABLE cs (SC_Sno STRING, SC_Cno STRING, SC_Score INT); -
数据加载:
-
假设在本机中存在对应的单个txt文件存储了数据
LOAD DATA LOCAL INPATH './examples/files/student.txt' OVERWRITE INTO TABLE student; LOAD DATA LOCAL INPATH './examples/files/course.txt' OVERWRITE INTO TABLE course; LOAD DATA LOCAL INPATH './examples/files/cs.txt' OVERWRITE INTO TABLE cs; -
查询:
SELECT s.S_Name, cs.SC_Score FROM student s JOIN cs ON s.S_No = cs.SC_Sno JOIN course c ON cs.SC_Cno = c.C_No WHERE c.C_Name = 'BigData' AND cs.SC_Score >= 90 ORDER BY cs.SC_Score DESC; - 查询需要用到全部的三个表,因此要先对表进行拼接,将课程表于选课表根据课程id进行拼接,将学生表与选课表根据学生id进行拼接
SELECT s.S_Name, cs.SC_Score选定要作为结果的列WHERE c.C_Name = 'BigData' AND cs.SC_Score >= 90筛选数据,要求课程名称为BigData并且分数在90以上ORDER BY cs.SC_Score DESC;最后根据分数从大到小排序