P9
简述Spark的技术特点¶
- 速度:Spark通过在内存中计算来优化迭代工作负载的执行速度,这比传统的基于磁盘的Hadoop MapReduce要快。
- 易于使用:Spark支持多种语言,如Scala、Java、Python和R,并提供了丰富的APIs,Spark不仅仅支持Map和Reduce操作,它还支持SQL查询、流数据处理、机器学习和图处理等高级数据分析技术。
- 灵活性:Spark能够处理批处理和实时流数据,提供了统一的数据处理平台。
- 可伸缩性:Spark利用了Hadoop的分布式文件系统(HDFS)的可伸缩性,它能够在数千个节点上扩展。
- 弹性计算:Spark的弹性分布式数据集(RDDs)是一个容错的、并行的数据结构,可以让用户显式地持久化数据到内存中,并在计算过程中复用,这在迭代算法和快速查询中非常有用。
- 内存计算:Spark 的核心是内存计算,它能够极大地提升处理速度。Spark 提出了一种基于内存的弹性分布式数据集(RDD),通过对 RDD 的一系列操作完成计算任务,可以大大提高性能。
- 适用场景:适合需要反复操作特定数据集的应用场合(如迭代),特别是数据量大且计算密集的任务。
- 不适用场景:不适合需要异步和细粒度更新状态的应用,如实时的 web 服务存储或增量更新的应用,例如实时的 web 爬虫和索引。
- 实时统计分析:对于数据量不是非常大但要求实时分析和统计的需求,Spark 也提供了相应的解决方案。
简述Spark的基本构架组成¶
-
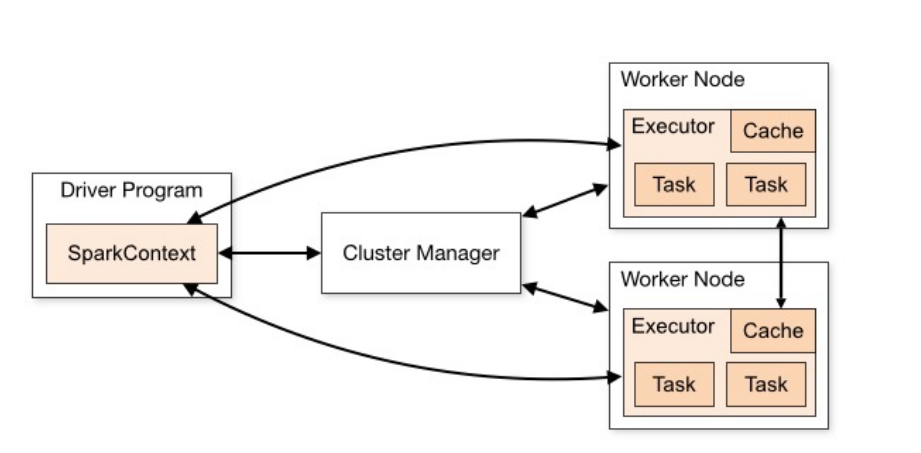
-
Master Node(主节点):在集群部署时,Master Node 充当控制器的角色,负责管理整个集群的正常运行,以及 Worker Nodes 的管理。
- Worker Node(工作节点):作为计算节点,Worker Node 接收 Master Node 的命令执行计算任务,并进行状态汇报。
- Executor(执行器):Executor 是在 Worker Node 上为每个 Application 启动的进程(一个 worker 上只有一个),它负责运行 Task,将数据保存在内存或磁盘中,并将结果返回给 Driver Program。
- Excutor 对象持有一个线程池线程池,每个线程可以执行一个 task,多个 task 之间可以共享内存资源。
- Cluster Manager(集群管理器):负责资源分配的服务,可以是 YARN、Kubernetes 或 Spark 自己的集群管理器。
- Driver Program(驱动程序):运行 Application main ()函数并创建 SparkContext 的进程,负责提交 Job,转化为 Task,并协调各 Executor 间的 Task 调度。Driver Program 可以运行在集群内或集群外。
- Application(应用程序):用户编写的基于 Spark 的程序,通过调用 Spark API 来实现数据处理的应用程序,由一个 Driver 程序和多个 Executor 程序组成,以用户定义的 main 方法作为入口。
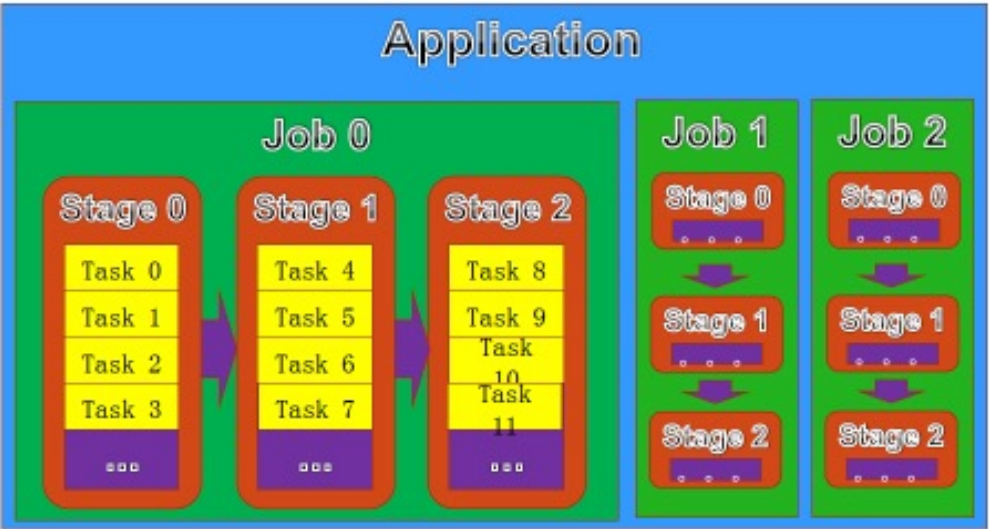
- Job;Stage;Task;
- SparkContext:Spark 的所有功能的主要入口点,是用户逻辑与 Spark 集群交互的主要接口。
- 对一个 Spark 程序进行了必要的初始化过程:创建 SparkConf (参数信息和配置文件)类的实例;创建 SparkEnv (环境对象)类的实例;创建调度类的实例;
简述 Spark 的调度过程¶
-
两种调度器:DAGScheduler 和 TaskScheduler
-
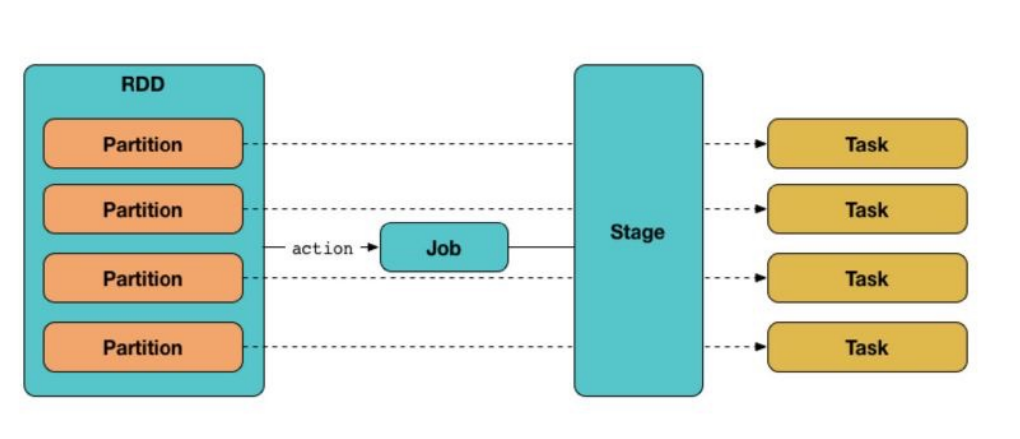
逻辑计划:DAGSchedule 将用户的程序代码根据 RDD 间的依赖关系,划分为多个 Stage,对于划分后的每个 Stage 都抽象为一个由多个 Task 组成的任务集,转换为逻辑执行计划,即有向无环图(DAG)。在 DAG 中,节点表示 RDD,边表示 RDD 之间的转换。基于 DAG,将程序划分为多个 Stage,对于划分后的每个 Stage 都抽象为一个由多个 Task 组成的任务集
-
-
任务调度:TaskScheduler接收DAGScheduler创建的阶段,负责对每个具体的 Task 进行调度,并将这些阶段中的任务分发给集群管理器。
- 对于TaskScheduler,Spark 中的任务调度分为两种:FIFO(先进先出)调度和 FAIR(公平调度)调度。
简述Spark的程序执行过程¶
- 程序提交:用户编写的Spark程序提交到相应的Spark运行框架中
- 创建SparkContext:Spark程序启动时,首先会创建一个SparkContext对象为本次程序的运行环境,这个对象是程序与Spark集群交互的主要接口。
- 集群资源连接:SparkContext会与集群管理器进行通信,以获取执行程序所需的资源。
- 获取Executor节点:一旦资源分配完成,SparkContext会在集群中可用的节点上启动Executor进程。这些进程是执行具体计算任务的实体。
- 代码分发:SparkContext将用户程序中的任务代码和函数序列化后发送到各个Executor。
- 任务执行:最后,SparkContext根据数据的分区和任务的依赖关系,将任务分发到不同的Executor执行。