P1
211275022田昊东¶
单机伪分布式安装¶
-
在ubuntu18.04完成安装
-
Hadoop在任务计划分发、心跳监测、任务管理、多租户管理等功能上,需要通过SSH进行通讯,故先安装ssh,并配置公私钥
-
安装
sudo apt-get install openssh-server -
配置公私钥:
cd ~/.ssh/ssh-keygen -t rsacat ./id_rsa.pub >> ./authorized_keys
-
由于hadoop使用java编写,需要先配置java环境
-
sudo apt-get install default-jre default-jdk -
编辑环境变量
-
sudo vim ~/.bashrc -
bash export JAVA_HOME=/usr/lib/jvm/default-java export HADOOP_HOME=/usr/local/hadoop export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH -
source ~/.bashrc
-
-
下载并解压hadoop
-
sudo tar -zxf /home/hadoop/Downloads/hadoop-3.3.6.tar.gz -C /usr/local -
将java环境写入配置文件
-
cd ./hadoop/etc/hadoop sudo vim hadoop-env.sh- 添加
export JAVA_HOME=/usr/lib/jvm/default-java -
激活配置
source hadoop-env.sh -
编辑配置文件
-
core-site.xml
-
sudo gedit core-site.xml -
xml <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/usr/local/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> -
设置存放目录以及主机号、端口号
-
-
hdfs-site.xml
-
sudo gedit hdfs-site.xml -
xml <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop/tmp/dfs/data</value> </property> </configuration> -
配置复制块的数目,namenode节点以及datanode节点存储的本地路径
-
-
mapred-site.xml
-
sudo gedit mapred-site.xml -
xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
-
-
yarn-site.xml
-
sudo gedit yarn -site.xml -
xml <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
-
-
格式化hadoop
/usr/local/hadoop/bin/hdfs namenode -format -
启动系统
-
启动系统
start-all.sh - 使用
jps检查运行状态 -
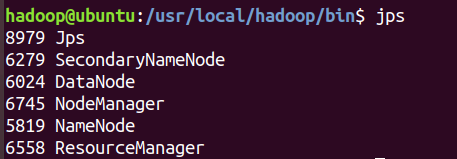
-
运行测试
- 创建文件夹
hdfs dfs -put usr/local/hadoop/etc/hadoop/*.xml inputhdfs dfs -rm -r output
- 准备测试输入
hdfs dfs -put usr/local/hadoop/etc/hadoop/*.xml input - 测试
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'dfs[a-z.]+' - 输出结果
hdfs dfs -cat output/*
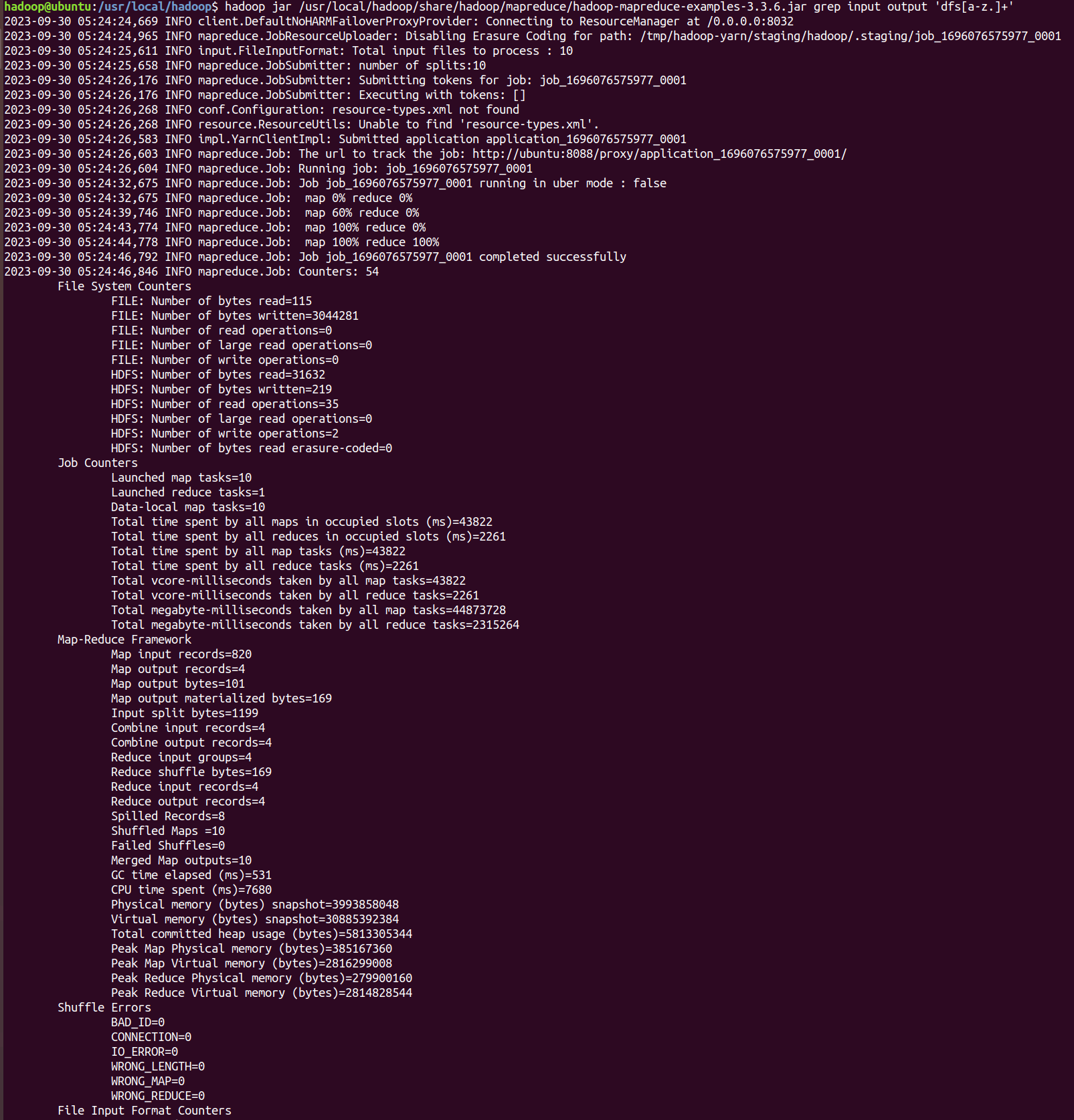
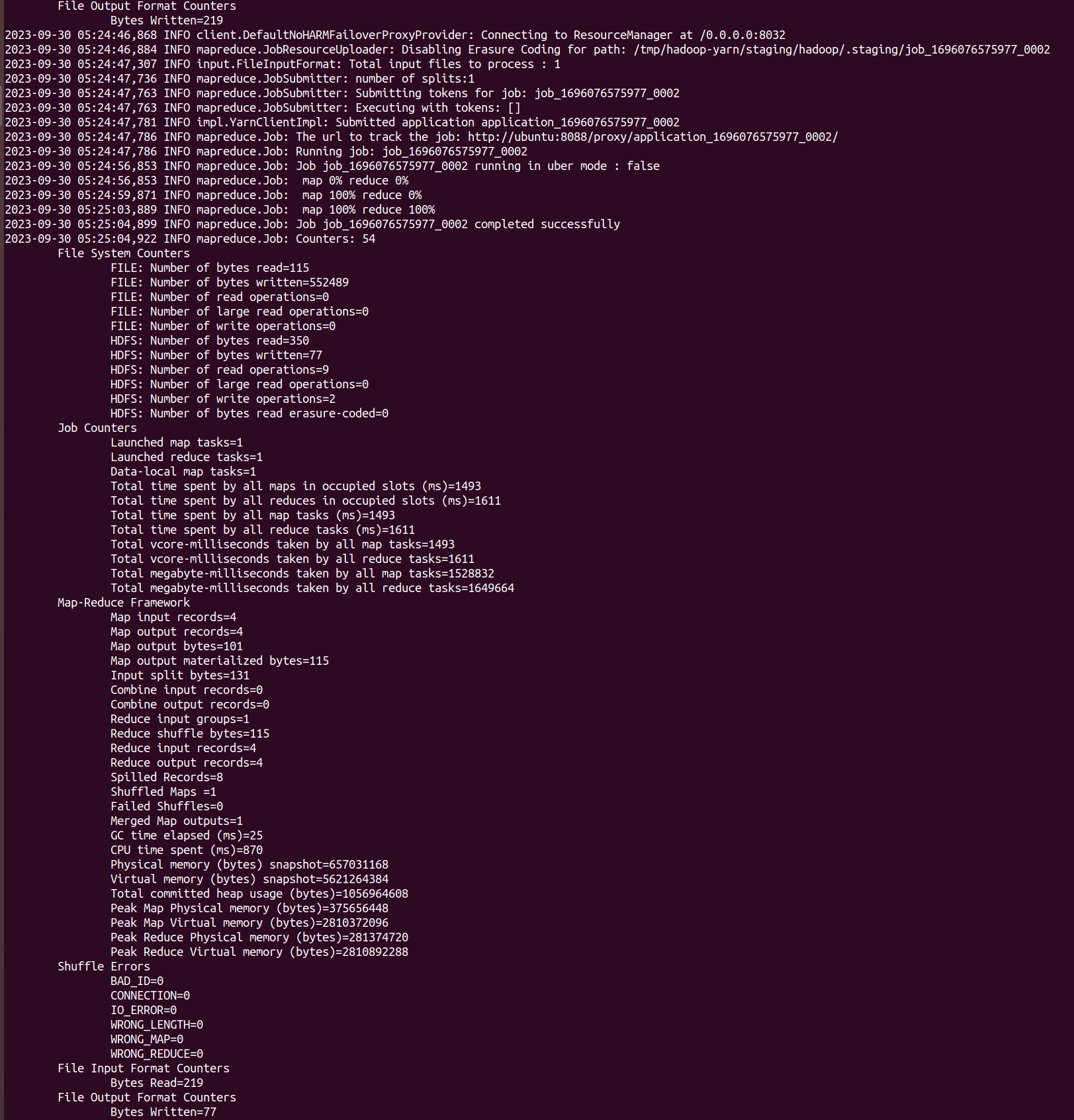

问题及解决¶
-
无法运行测试
-
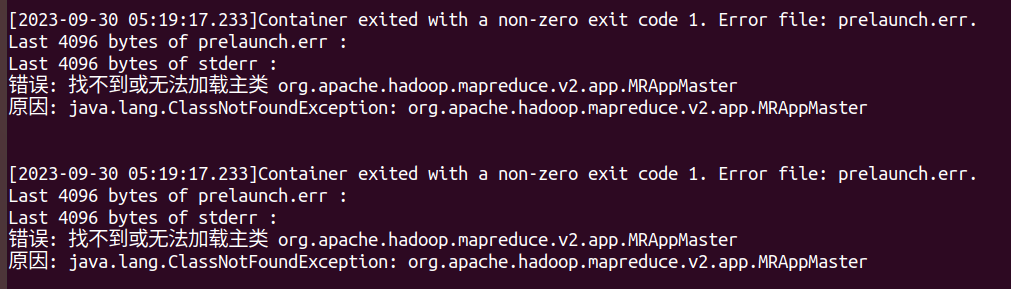
-
hadoop classpath命令获取 Hadoop 的类路径 -
在yarn-site.xml添加
-
告诉 YARN ResourceManager 启动应用程序时要包括的类路径。
-
xml <property> <name>yarn.application.classpath</name> <value>...</value> </property>
-
docker集群安装¶
- docker安装
curl https://get.docker.com/ | bash -s docker --mirror Aliyun - 检查运行状态
sudo systemctl status docker - 启动
sudo systemctl start docker - 将用户添加到docker可执行组
sudo usermod -aG docker hadoop - 拉取docker镜像:
docker pull kiwenlau/hadoop:1.0 
- 创建hadoop-docker网络
sudo docker network create --driver=bridge hadoop 
- 准备好hadoop四个配置文件以及构建脚本Dockeerfile
-
配置节点启动配置文件docker-compose.yml
-
yaml version: '3' services: master1: image: hadoop stdin_open: true tty: true command: bash hostname: hadoop330 ports: - "9000:9000" - "9870:9870" - "8088:8088" master2: image: hadoop stdin_open: true tty: true command: bash worker1: image: hadoop stdin_open: true tty: true command: bash worker2: image: hadoop stdin_open: true tty: true command: bash worker3: image: hadoop stdin_open: true tty: true command: bash -
启动集群
docker-compose up -d -
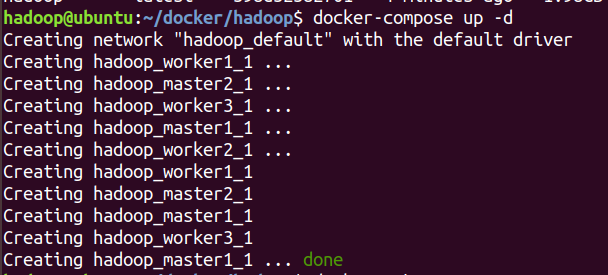
-
查看镜像运行状态
-
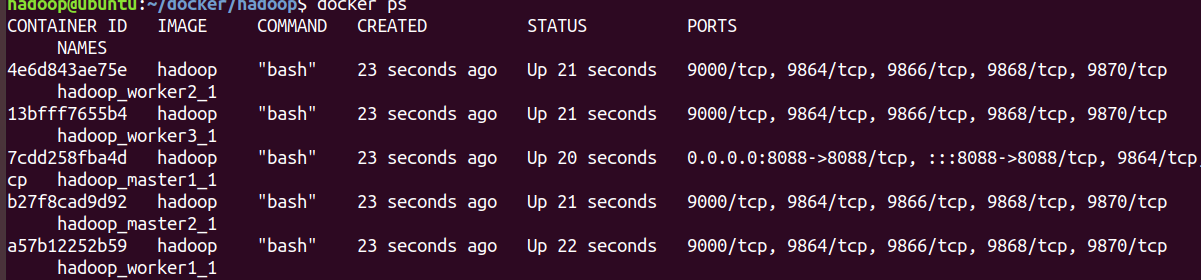
-
进入主节点
docker exec -it job-big-data_master1_1 bash - 格式化HDFS
./bin/hdfs namenode -format - 启动集群
./sbin/start-all.sh -
检查各节点运行状态
jps -
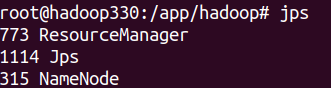
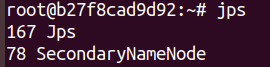
-
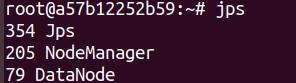
-
运行测试
-
bash $ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/root $ bin/hdfs dfs -mkdir input $ bin/hdfs dfs -put /etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar grep input output 'dfs[a-z.]+' -
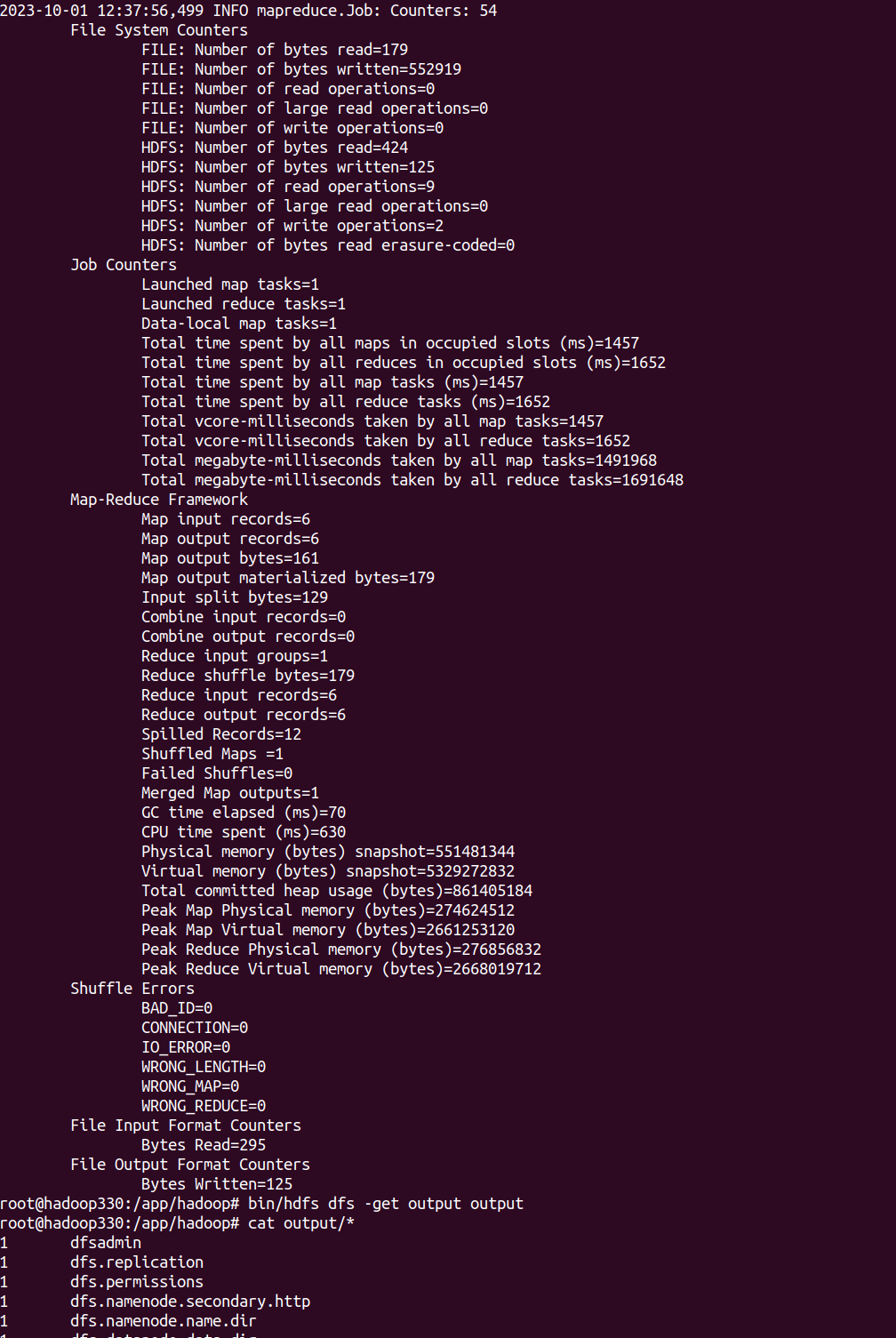
问题及解决¶
-
运行Dockeerfile时无法下载依赖
-
bash > [2/9] RUN yum install -y openssh-server sudo: #0 0.865 CentOS Linux 8 - AppStream 71 B/s | 38 B 00:00 #0 0.867 Error: Failed to download metadata for repo 'appstream': Cannot prepare internal mirrorlist: No URLs in mirrorlist -
换源,载docker构建脚本中添加
RUN sed -i 's/archive.ubuntu.com/mirrors.aliyun.com/g' /etc/apt/sources.list