P2
T1-统计违约情况¶
代码¶
- map
java public static class MergeMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { if(key.get()==0) return; Stream<String> stream = Stream.of(value.toString().split(",")); Optional<String> lastElement = stream.reduce((first, second) -> second); if(lastElement.isPresent()) { int res = Integer.parseInt(lastElement.get()); if(res == 1) context.write(new Text("dis keep"), new LongWritable(1)); else context.write(new Text("keep"), new LongWritable(1)); } } } - 按行读取(key为0说明是第一行,直接丢弃)
- 按照,对每一行进行划分得到字符串数组
-
取得最后一个元素,如果是1就表示违约,用key=dis keep表示,值为1
- 如果为0就表示没有违约,用keep表示
-
reduce
java public static class MergeReducer extends Reducer<Text, LongWritable, Text, LongWritable> { @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { LongWritable res = new LongWritable(0); for(LongWritable value : values) { res.set(res.get() + value.get()); } context.write(key, res); } } - 数据分类两个key,对于每种key,只需要读取值中的每一项并求和就可以得到结果
运行结果¶

dis keep 24825
keep 282686
T2-统计贷款交易数¶
代码¶
- map
public static class MergeMapper extends Mapper<LongWritable, Text, Text, LongWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { if(key.get()==0) return; Stream<String> stream = Stream.of(value.toString().split(",")); Optional<String> lastElement = stream.skip(25).findFirst(); if(lastElement.isPresent()) { context.write(new Text(lastElement.get()), new LongWritable(1)); } } } -
以星期几为键,统计数目
-
reduce
public static class MergeReducer extends Reducer<Text, LongWritable, Text, LongWritable> { public static class Pair { private Text key; private LongWritable value; public Pair(Text key, LongWritable value) { this.key = key; this.value = value; } public Text getKey() { return key; } public LongWritable getValue() { return value; } } private List<Pair> sortedData = new ArrayList<>(); @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { LongWritable res = new LongWritable(0); for(LongWritable value : values) { res.set(res.get() + value.get()); } sortedData.add(new Pair(new Text(key), res)); } @Override protected void cleanup(Context context) throws IOException, InterruptedException { Collections.sort(sortedData, new Comparator<Pair>() { @Override public int compare(Pair pair1, Pair pair2) { return pair2.getValue().compareTo(pair1.getValue()); } }); // 输出排序后的结果 for (Pair pair : sortedData) { context.write(pair.getKey(), pair.getValue()); } } } - 自定义一个pair类,用于对每天的统计结果暂存
- 再reduce种先将结果存储到ArrayList进行暂存
- 在cleanup自定义比较器并对暂存的结果进行排序,再写入到结果
运行结果¶
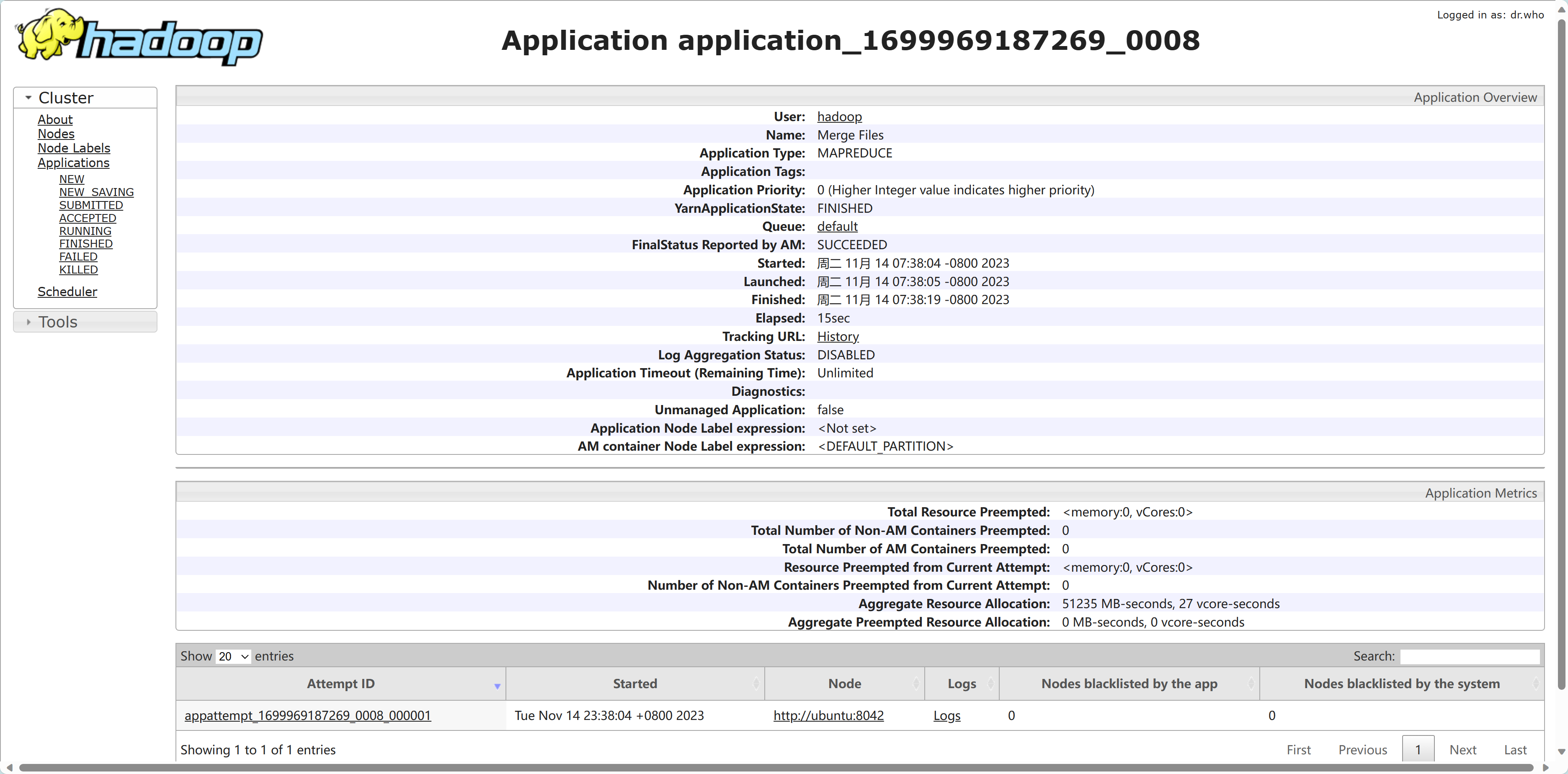
TUESDAY 53901
WEDNESDAY 51934
MONDAY 50714
THURSDAY 50591
FRIDAY 50338
SATURDAY 33852
SUNDAY 16181
T3-贷款违约检测模型¶
代码¶
- 使用knn最邻近分类算法
- 将整个过程如下划分:
- init:求出每一列的最大最小值,为后续的归一化做准备
- maxmin:根据init求出的值,对非字符数据进行01归一化操作
- div:8:2划分数据集得到训练集和测试集
- knn:根据训练集对测试集进行预测得到结果
- score:对预测结果进行分析并计算accuracy值
Init¶
- map
-
统计非字符列的所有取值
//掠过第一行 if (key.get() == 0) return; List<String> line = new ArrayList<>(Arrays.asList(value.toString().split(","))); for (int i = 1; i < line.size() - 1; i++) {// 第一列是id,最后一列是结果,不处理 try { double value1 = Double.parseDouble(line.get(i)); context.write(new Text(i + ""), new DoubleWritable(value1));// 汇总每一列的所有取值 } catch (NumberFormatException e) { ;// 字符数据,不处理 } } -
reduce
- 从可能的取值中找出最大最小值
protected void reduce(Text key, Iterable<DoubleWritable> values, Context context) throws IOException, InterruptedException { double max = Double.MIN_VALUE; double min = Double.MAX_VALUE; for (DoubleWritable value : values) { max = Math.max(max, value.get()); min = Math.min(min, value.get()); } context.write(key, new Text(min + "," + max)); }
maxmin¶
- main
- 需要传入上一次的统计结果
job_maxmin.addCacheFile(new Path(output_init+"/part-r-00000").toUri()); - setup(map)
-
读取文件,建立列号和最大最小值之间的映射
//HashMap<Integer, Pair> minmax = new HashMap<>(); URI[] cacheFiles = context.getCacheFiles(); if (cacheFiles != null && cacheFiles.length > 0) { try { FileSystem fs = FileSystem.get(context.getConfiguration()); Path path = new Path(cacheFiles[0].toString()); BufferedReader reader = new BufferedReader(new InputStreamReader(fs.open(path))); String line;//逐行读取 while ((line = reader.readLine()) != null) { String[] split = line.trim().split("\\s+"); String[] split2 = split[1].split(","); minmax.put(Integer.parseInt(split[0]), new Pair(Double.parseDouble(split2[0]), Double.parseDouble(split2[1]))); } reader.close(); } catch (IOException e) { System.err.println("MinMax::Exception reading DistributedCache: " + e); } } -
map
- 根据建立的映射对所有非字符列进行归一化
List<String> line = new ArrayList<>(Arrays.asList(value.toString().split(","))); String res = ""; for (int i = 1; i < line.size() - 1; i++) { try { double value1 = Double.parseDouble(line.get(i)); Pair pair = minmax.get(i); double min = pair.min; double max = pair.max; double result = (value1 - min) / (max - min); res += "," + result; } catch (NumberFormatException e) { ;// 字符数据,不处理 } } context.write(new Text(line.get(0) + res + "," + line.get(line.size() - 1)), new Text()); - reduce
- 直接存储map的结果即可
context.write(key, new Text());
div¶
- map
- 随机数流
static Iterator<Integer> iterator = new Random(47).ints(0, 100).boxed().iterator(); -
每次取一个随机数,根据值决定key是train还是test,实现近似8:2划分
Integer random = iterator.next(); if (random >= 80) {// 训练集 context.write(new Text("test"), value); } else { context.write(new Text("train"), value); } -
reduce
- 使用multipleOutputs实现将训练集和测试集分别写入到两个文件分别存储
static MultipleOutputs<Text, Text> multipleOutputs; @Override protected void setup(Context context) throws IOException, InterruptedException { multipleOutputs = new MultipleOutputs<>(context); } @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { for (Text value : values) { multipleOutputs.write(value, new Text(), key.toString()); } } @Override protected void cleanup(Context context) throws IOException, InterruptedException { multipleOutputs.close(); }
knn¶
- main
- 传入训练集
job_knn.addCacheFile(new Path(output_div+"/train-r-00000").toUri()); - 训练集需要每个节点一份,用于在分类时进行比对
-
测试集作为 map 的输入
-
setup(map)
-
读取并缓存训练集
FileSystem fs = FileSystem.get(context.getConfiguration()); Path path = new Path(cacheFiles[0].toString()); BufferedReader reader = new BufferedReader(new InputStreamReader(fs.open(path))); String line; while ((line = reader.readLine()) != null) { String[] split = line.split(","); Double[] temp = new Double[split.length - 1]; for (int i = 1; i < split.length; i++) { temp[i - 1] = Double.parseDouble(split[i]); } if(data.size()<MaxSize) data.add(temp); } reader.close(); -
优先队列
private PriorityQueue<Double[]> findNearestNeighbors(Double[] testFeatures) { PriorityQueue<Double[]> neighbors = new PriorityQueue<>(k, Comparator.comparingDouble(a -> distance(a, testFeatures))); for (Double[] trainData : data) { neighbors.offer(trainData); if (neighbors.size() > k) { neighbors.poll(); } } return neighbors; } -
维护与目标最为接近的k个条目
-
map
//解析数据 Double[] features = new Double[fields.length - 2]; for (int i = 1; i < fields.length - 1; i++) { features[i - 1] = Double.parseDouble(fields[i]); } // 计算距离并选取最近的k个邻居 PriorityQueue<Double[]> neighbors = findNearestNeighbors(features); // 进行多数投票 int count0 = 0, count1 = 0; for (int i = 0; i < k; i++) { Double[] neighbor = neighbors.poll(); if (neighbor[neighbor.length - 1] - 0.0 < 1e-6) { count0++;//t投票 } else { count1++; } } // 输出结果 context.write(new Text(id), new Text(count1 > count0 ? "1" : "0")); - reduce
- 直接存储map的结果
context.write(key,values.iterator().next());
score¶
- main
- 传入含结果的测试集作为答案用于与预测结果进行比对
-
job_score.addCacheFile(new Path(output_div+"/test-r-00000").toUri()); -
setup(map)
- 同理读取训练集数据,建立id-结果的映射
-
HashMap<Integer,Integer> res = new HashMap<>(); -
map
-
读取预测结果并于训练集的结果进行比对
String[] line = value.toString().split("\\s+"); int id = Integer.parseInt(line[0]); int result = Integer.parseInt(line[line.length-1]); int right = res.get(id); if(result==right) context.write(new Text("res"),new Text("1")); else context.write(new Text("res"),new Text("0")); -
reduce
- 根据对正确和错误数目的统计计算出准确率
for(Text value:values){ if(value.toString().equals("1")) sum1++; else sum2++; } context.write(new Text("Accuracy"),new Text(sum1/(sum1+sum2)+""));
运行结果¶
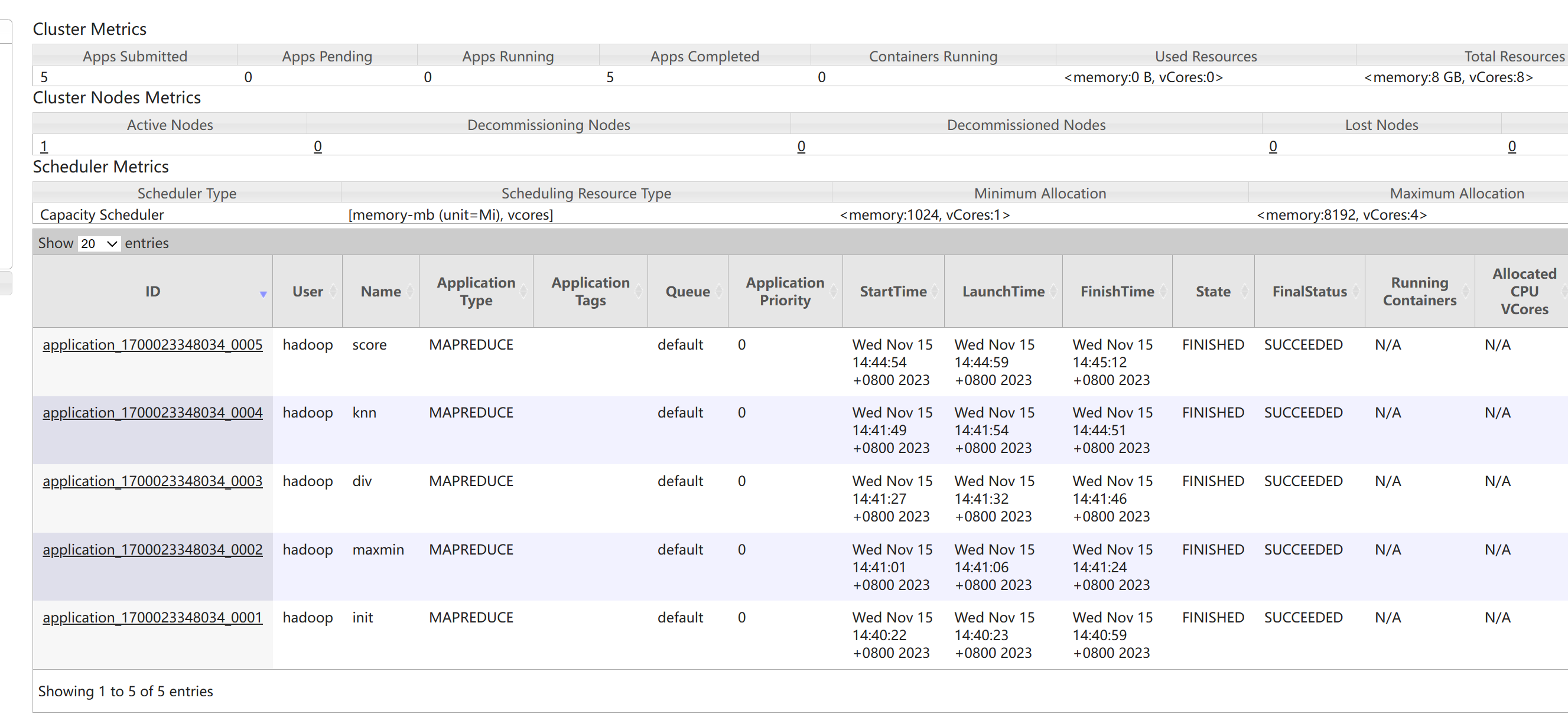
- 可见5个任务运行成功
- 最终统计结果
Accuracy 0.9176155283034192 - 每个步骤的详细输出再output文件夹下