P4
- 使用idea+scala完成实验
- 所有输出在项目spark文件夹下的output文件夹
T1任务一¶
代码¶
- 从 csv 读取数据到 RDD
val conf = new SparkConf().setAppName("Spark Pi").setMaster("local") val sc = new SparkContext(conf) val fileRDD = sc.textFile("C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\application_data.csv") val header = fileRDD.first() val dataRDD = fileRDD.filter(row => row != header) val data = dataRDD.map{line => val parts = line.split(",") val difference = parts(7).toDouble - parts(6).toDouble (parts, difference)} -
去掉首行,并且加入额外的差值列(用于子任务2的排序)
-
子任务1
val loanAmounts = data.map(x => x._1(7).toDouble) def getRange(amount: Double): (Double, Double) = { val lower = (amount / 10000).toInt * 10000 val upper = lower + 10000 (lower, upper) } val rangeCounts = loanAmounts.map(amount => (getRange(amount), 1)).reduceByKey(_ + _) val sortedConts = rangeCounts.sortBy(_._1._1) val outputPath = "C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\spark\\output\\task1_1" sortedConts.saveAsTextFile(outputPath) - 提取出贷款金额,并且建立映射到范围区域,最后使用reduceByKey聚合得到结果
-
将结果根据左侧起点进行排序,之后存储到文件
-
子任务2
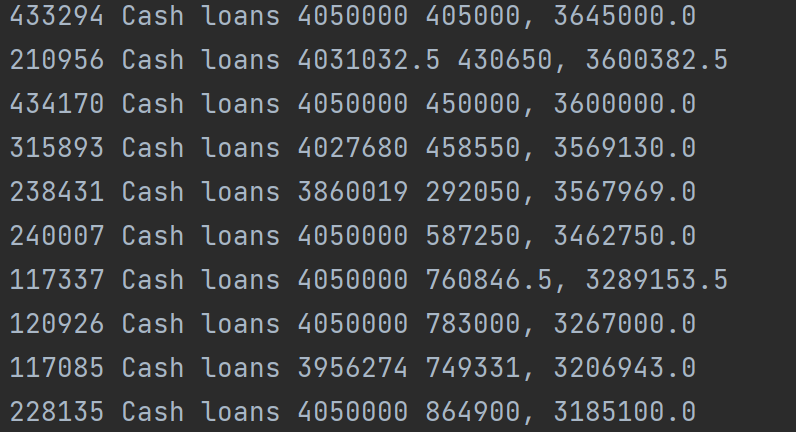
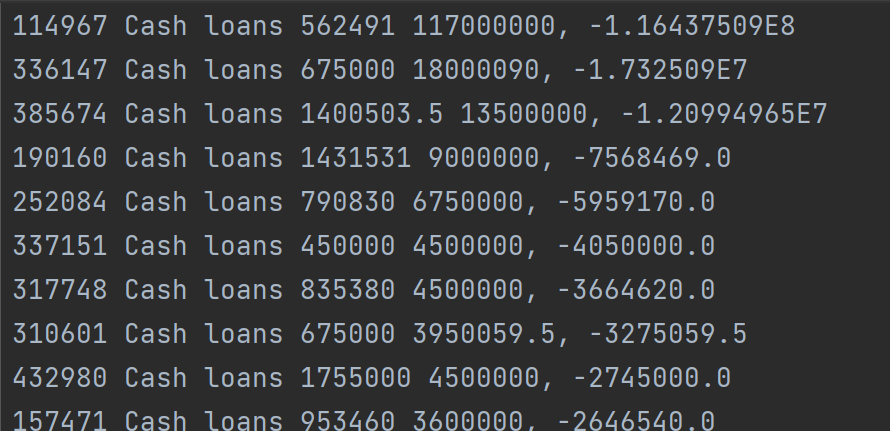
val res= data.sortBy(_._2,ascending = true) val max5 = res.sortBy(x => x._2, ascending = false).take(10) val min5 = res.take(10) val max5RDD = sc.parallelize(max5) val min5RDD = sc.parallelize(min5) val res2 = max5RDD.union(min5RDD) val res3 = res2.map(t => t._1(0)+" "+t._1(1)+" "+t._1(7)+" "+t._1(6)+", "+t._2) val outputPath2 = "C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\spark\\output\\task1_2" res3.saveAsTextFile(outputPath2) - 根据创建RDD时添加的额外列进行排序,提取出最大最小的项,将数组转化为RDD后进行合并
- 将结果存储到文件
运行截图¶
-
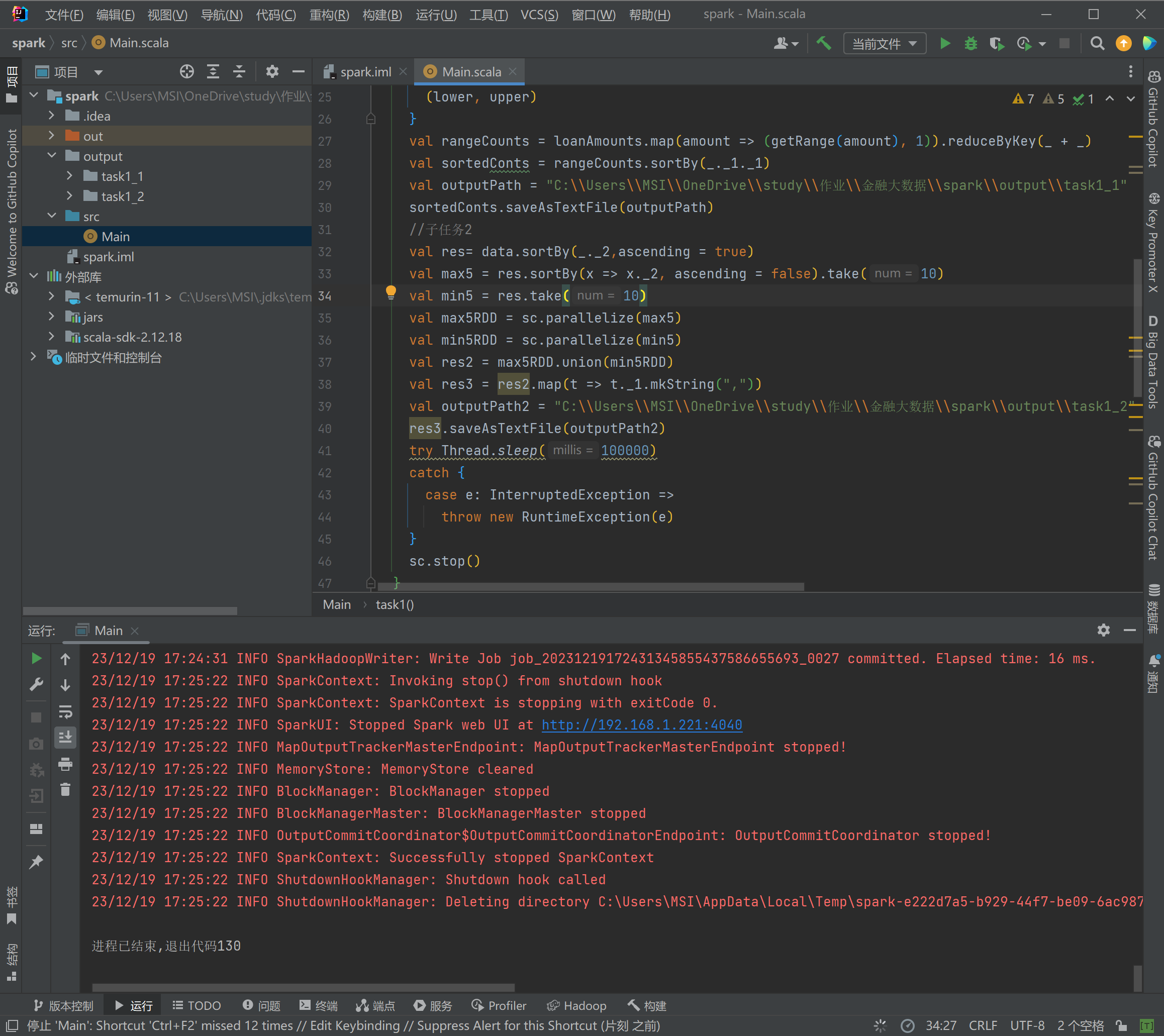
-
webui查看job运行结果
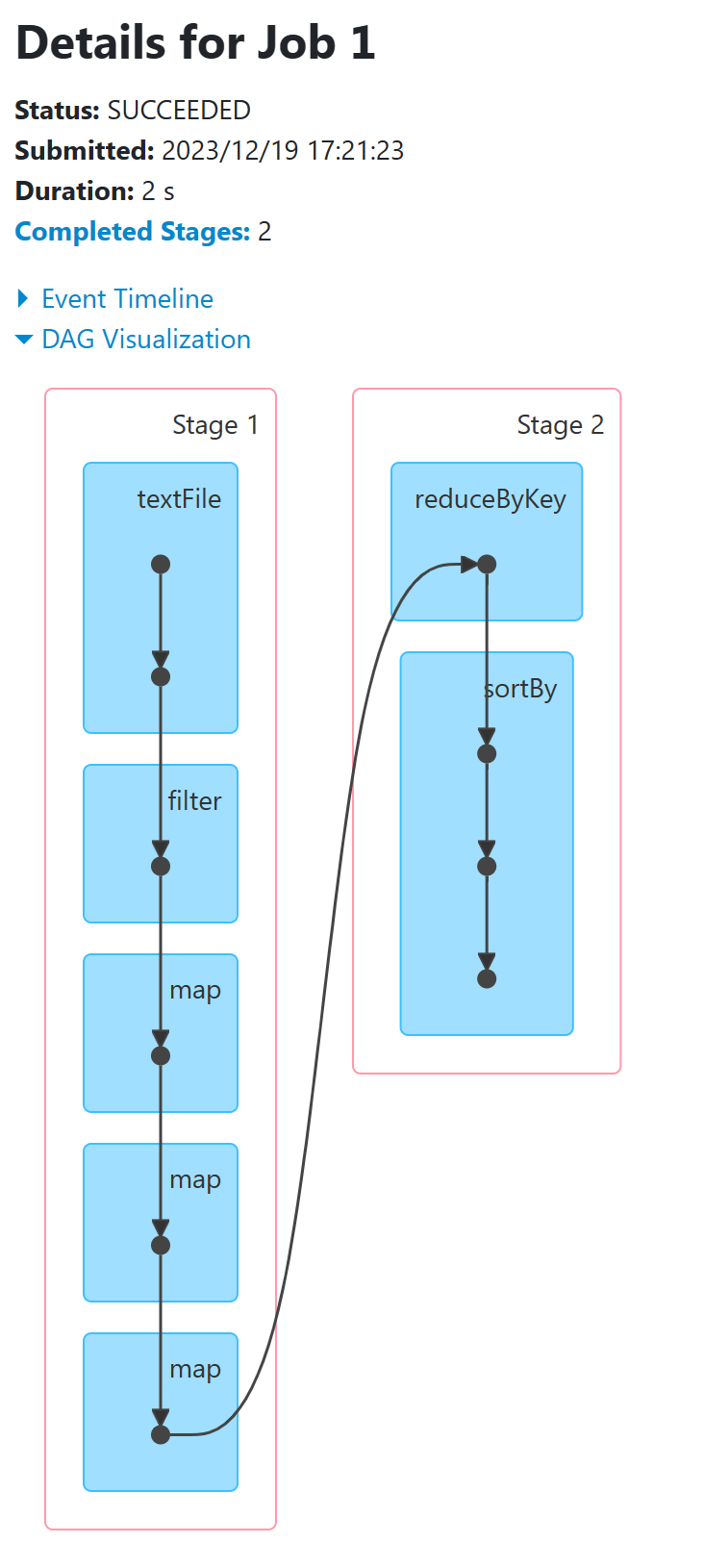
-
-
子任务一部分输出
-
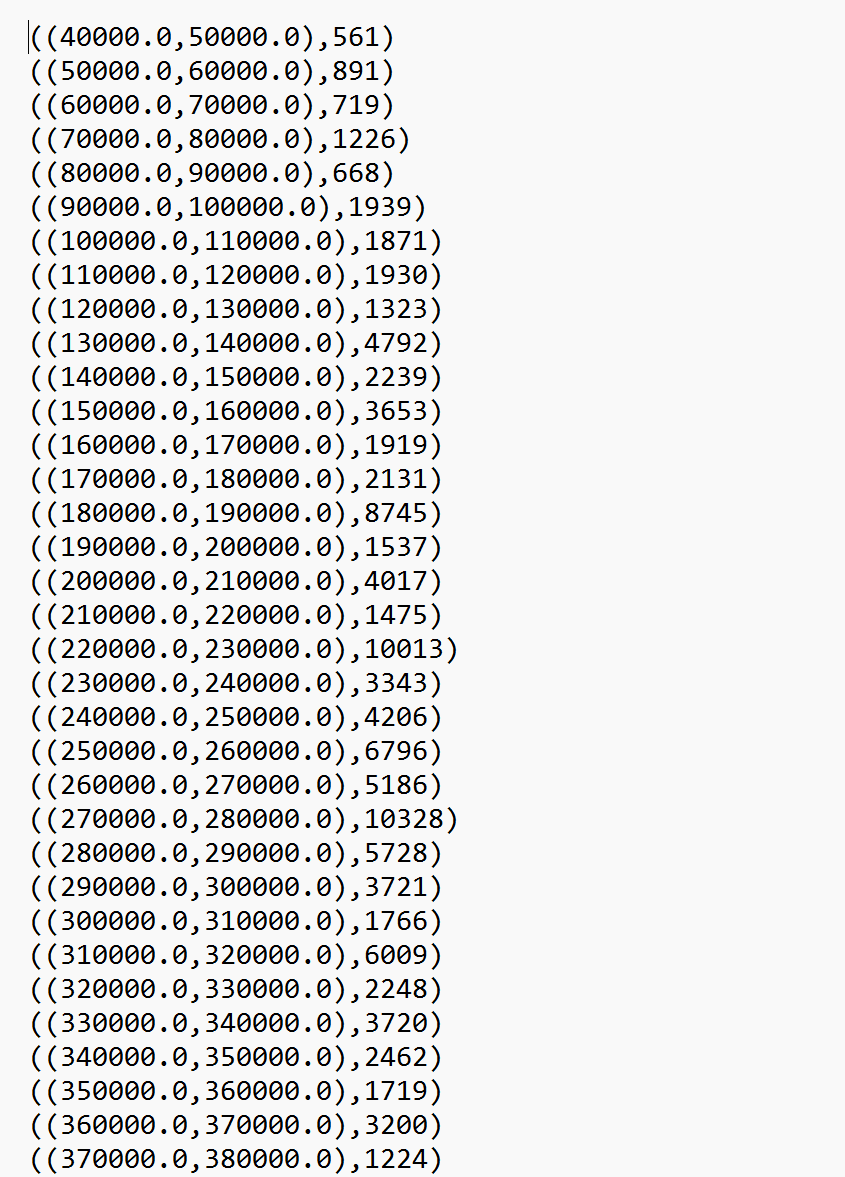
-
子任务二输出
- 最高的10项
- 最低的10项
T2任务二¶
代码¶
-
读取文件到dataframe
val spark = SparkSession.builder.appName("Spark").master("local").getOrCreate() val df = spark.read.option("header", "true").option("inferSchema", "true").csv("C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\application_data.csv") -
子任务1
val dfM = df.filter(df("CODE_GENDER")==="M") val sum = dfM.count() val dfG = dfM.groupBy("CNT_CHILDREN").count() val res = dfG.select(dfG("CNT_CHILDREN"), (dfG("count")/sum).as("count")) val path = "C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\spark\\output\\task2_1" res.write.csv(path) - 先筛选出全部性别为男性的数据,然后统计信息条数
- 根据孩子数目分组,并聚合计数
-
选择孩子数目,以及占全体比率生成新表并写入文件
-
子任务2
val dfI = df.select(df("SK_ID_CURR"),(df("AMT_INCOME_TOTAL")/(-df("DAYS_BIRTH"))).as("avg_income")) val dfB = dfI.filter(dfI("avg_income")>1) val res2 = dfB.sort(dfB("avg_income").desc) val path2 = "C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\spark\\output\\task2_2" res2.write.csv(path2) - 首先选取ID和每天收入建立新表
- 过滤到收入<=1的项,并按照从大到小排序
- 写入结果
运行截图¶
-
-
webui
- 子任务1结果
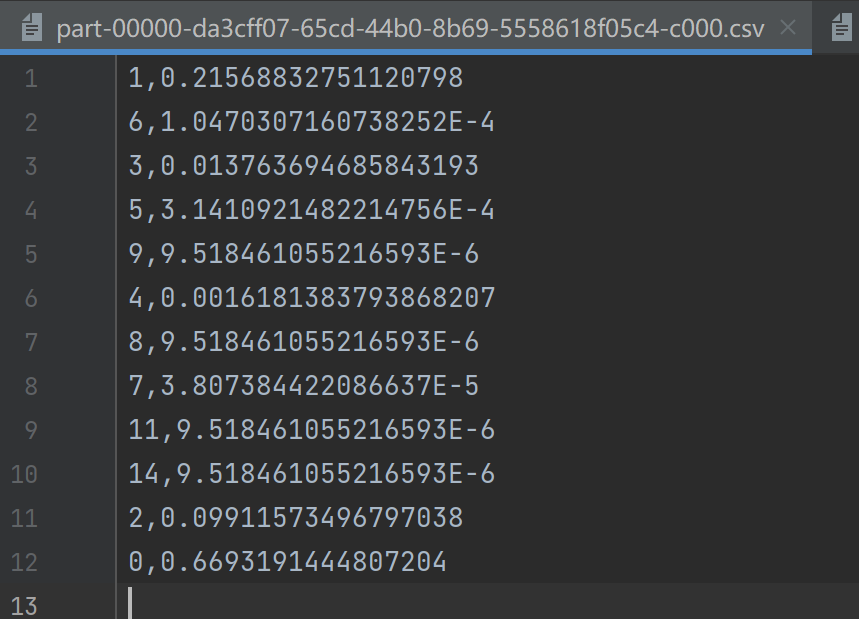
- 子任务2部分结果
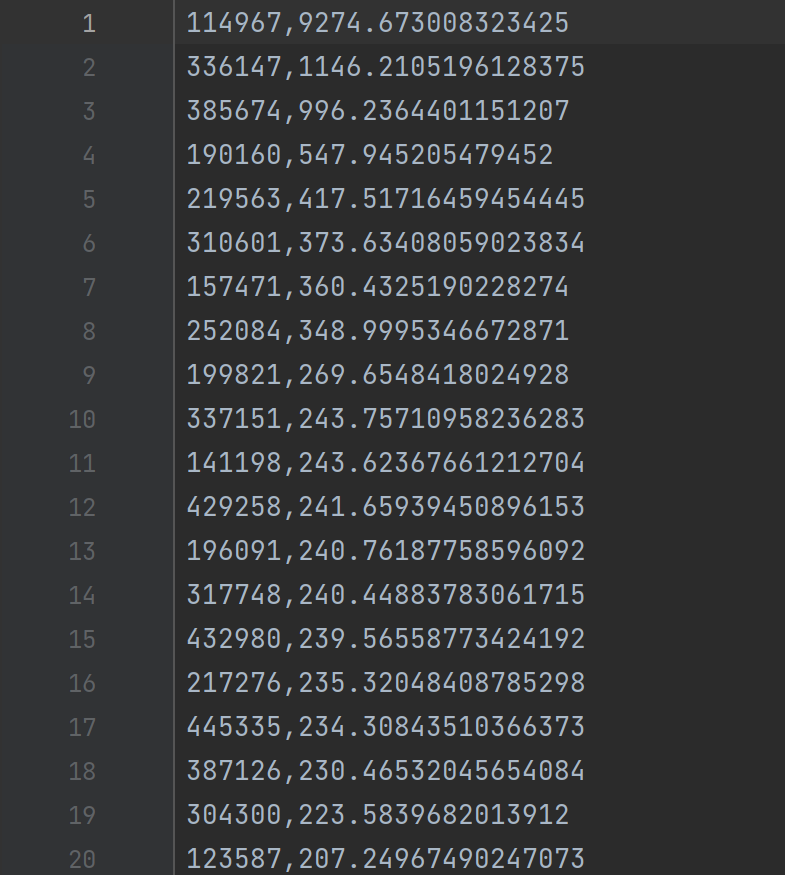
T3任务三¶
代码¶
-
读取文件
val spark = SparkSession.builder.appName("Spark").master("local").getOrCreate() val df = spark.read.option("header", "true").option("inferSchema", "true").csv("C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\application_data.csv") -
准备数据集
val assembler = new VectorAssembler().setInputCols(Array( "CNT_CHILDREN", ... "FLAG_DOCUMENT_21" )).setOutputCol("features").setHandleInvalid("skip") val assemblerDf = assembler.transform(df) - 设置要作为参数的项,将其转化为特征features列,并设置跳过有空行的列
- 划分数据集
val Array(trainingData, testData) = assemblerDf.randomSplit(Array(0.8, 0.2))
val classifier1 = new org.apache.spark.ml.classification.LogisticRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
.setLabelCol("TARGET")
.setFeaturesCol("features")
val model1 = classifier1.fit(trainingData)
val predictions1 = model1.transform(testData)
val evaluator1 = new org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator()
.setLabelCol("TARGET")
.setPredictionCol("prediction")
.setMetricName("accuracy")
val accuracy1 = evaluator1.evaluate(predictions1)
-
决策树模型
val classifier2 = new org.apache.spark.ml.classification.DecisionTreeClassifier() .setLabelCol("TARGET") .setFeaturesCol("features") val model2 = classifier2.fit(trainingData) val predictions2 = model2.transform(testData) val evaluator2 = new org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator() .setLabelCol("TARGET") .setPredictionCol("prediction") .setMetricName("accuracy") val accuracy2 = evaluator2.evaluate(predictions2) -
结果保存
val path1="C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\spark\\output\\task3_logistic" val path2="C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\spark\\output\\task3_decisiontree" val res1 = predictions1.select("SK_ID_CURR", "prediction") val res2 = predictions2.select("SK_ID_CURR", "prediction") res1.write.csv(path1) res2.write.csv(path2) println("LogisticRegression accuracy = " + accuracy1) println("DecisionTreeClassifier accuracy = " + accuracy2) - 选择ID列和Target预测结果列并保存为文件
- 最后输出计算的准确率
运行截图¶
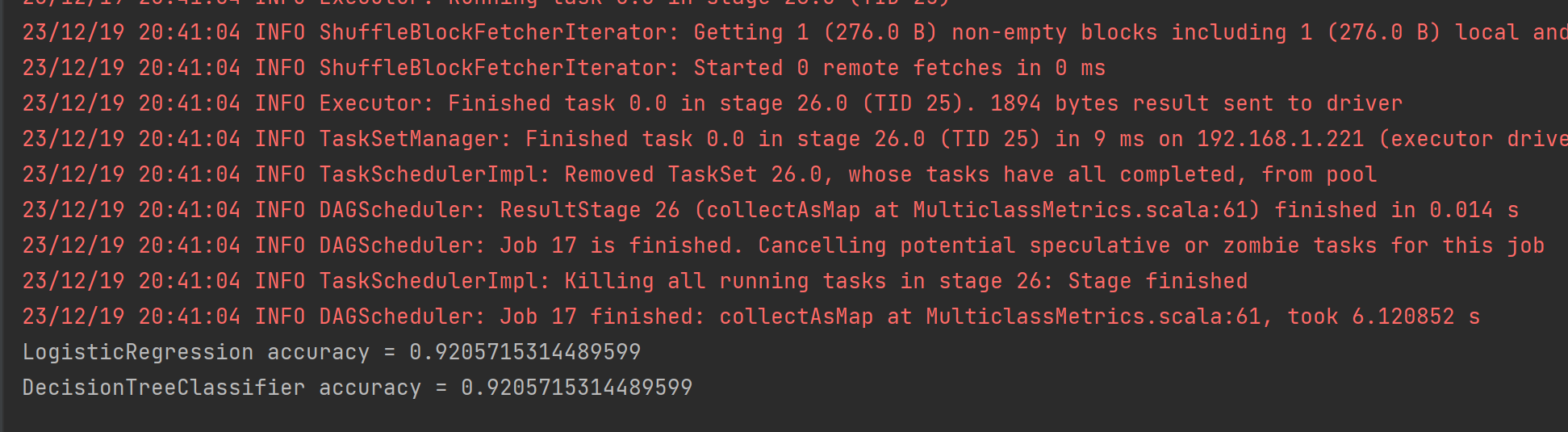
- 由于数据集违约不违约分布的过于不均衡,实际上两个模型的预测结果都是很差的,尝试调整过模型及参数均没有改善
- webui
- LogisticRegression分类结果
- DecisionTreeClassifier分类结果
遇到的问题¶
- 对于RDD中的Array数组元素,不能直接存储到文件(默认将引用存储进去,而不是真实数组的内容),需要先进行转化
val res3 = res2.map(t => t._1.mkString(","))