1. 每章的核心概念,尤其作业中的问答题;
2. 大数据平台(Hadoop,HBase,Hive,Spark等)的架构和原理;
3. MapReduce和Spark的编程模型和编程方法,可以结合讲义、作业和实验中的程序复习;不考MPI编程和HBase编程。其中程序填空要求填代码(可以用不同的语言,但要表达清楚),MapReduce程序设计可以写伪代码或代码,Spark编程要求能读懂程序,掌握常用API和算子。建议同学们复习时阅读讲义中的代码,并回顾下作业和实验中的编程题。
大数据概述¶
1 大数据背景简介¶
-
大数据背景
- 信息化浪潮:信息处理-信息传输-信息爆炸
-
重点
¶
-
什么是数据:对现实世界特定方面的一种记录。这些记录可以是数字、文字、图像、声音等多种形式。数据可以以多种形式存在:结构化、半结构化、非结构化数据。
-
重点
¶
-
什么是大数据:超大的、难以用现有常规的数据库管理技术和工具处理的数据集。
-
重点
¶
-
大数据类型
- 按照结构特征划分:
- 结构化、半结构化、非结构化
-
重点
¶
- 按照获取和处理方式划分:
- 在线 (实时)
- 离线
- 关联特征划分:
- 无关联,简单关联数据(键值数据)
- 复杂关联数据(图数据)
- 按照结构特征划分:
-
大数据涉及的关键技术
- 软件是大数据的引擎
- 海量数据存储技术:分布式文件系统
- 实时数据处理技术:流计算引擎
- 数据高速传输技术:服务器/存储间高速通信
- 搜索技术:文本检索、智能搜索、实时搜索
- 数据分析技术:自然语言处理、文本情感分析、机器学习、聚类关联、数据模型
重点¶
2 并行计算基础¶
-
提高计算机硬件性能的主要手段
- 提高处理器字长
- 提高集成度
- 流水线等微体系结构技术(指令级并发)
- 提高处理器频率
- 单核处理器性能提升接近极限
-
Scale up:纵向扩展,指的是通过增强单个节点的硬件性能来提高系统的处理能力。 - 优点:维护简单,无需更改架构 - 缺点:成本高,物理上限,故障
-
Scale out:横向扩展,指的是通过增加更多的节点到现有系统中,分散处理负载。每个节点可能性能普通,但通过并行工作来提升整体性能。
- 优点:灵活,中低端硬件,容错性
- 缺点:分布式架构,管理较为复杂
-
重点
¶
-
- 并行计算的主要技术特点问题
-
重点
¶
-
-
-
MPI 并行程序设计的特点:提供可靠的、面向消息(基于消息传递)的通信;在高性能科学计算领域广泛使用,适合于处理计算密集型的科学计算;独立于语言的编程规范,可移植性好。并行计算粒度大*,特别适合于大规模可扩展并行算法
- 用户必须通过显式地发送和接收消息来实现处理机间的数据交换。
- 每个并行进程均有自己独立的地址空间,相互之间访问不能直接进行,必须通过显式的消息传递来实现。(所有节点运行同一个程序,但处理不同的数据)
-
MPI 通信机制
- 点对点通信:同步、异步
- 节点集合通信:广播、同步、规约(对一组数据进程执行特定操作如求和并传送给一个进程)等
- 用户自定义的复合数据类型传输
-
不足:
- 无良好的数据和任务划分支持
- 缺少分布文件系统支持分布数据存储管理
- 通信开销大,当计算问题复杂、节点数量很大时,难以处理,性能大幅下降
- 无节点失效恢复机制,一旦有节点失效,可能导致计算过程无效
- 缺少良好的构架支撑,程序员需要考虑以上所有细节问题,程序设计较为复杂
Hadoop 与 MapReduce¶
3 MapReduce 简介¶
-
大数据处理:分而治之
- 前后数据项之间具有强依赖关系的计算只能串行(如斐波那契)
- 当大数据可以划分为具有同样计算过程的数据块,并且之间不存在数据依赖关系时使用并行计算
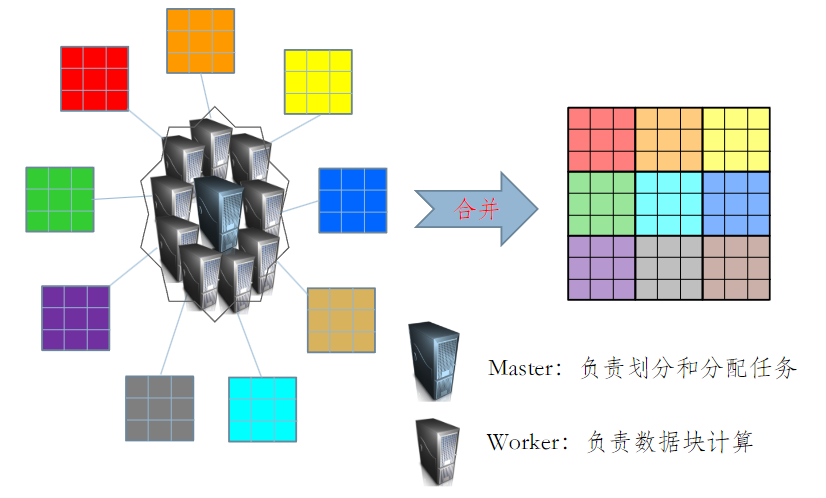
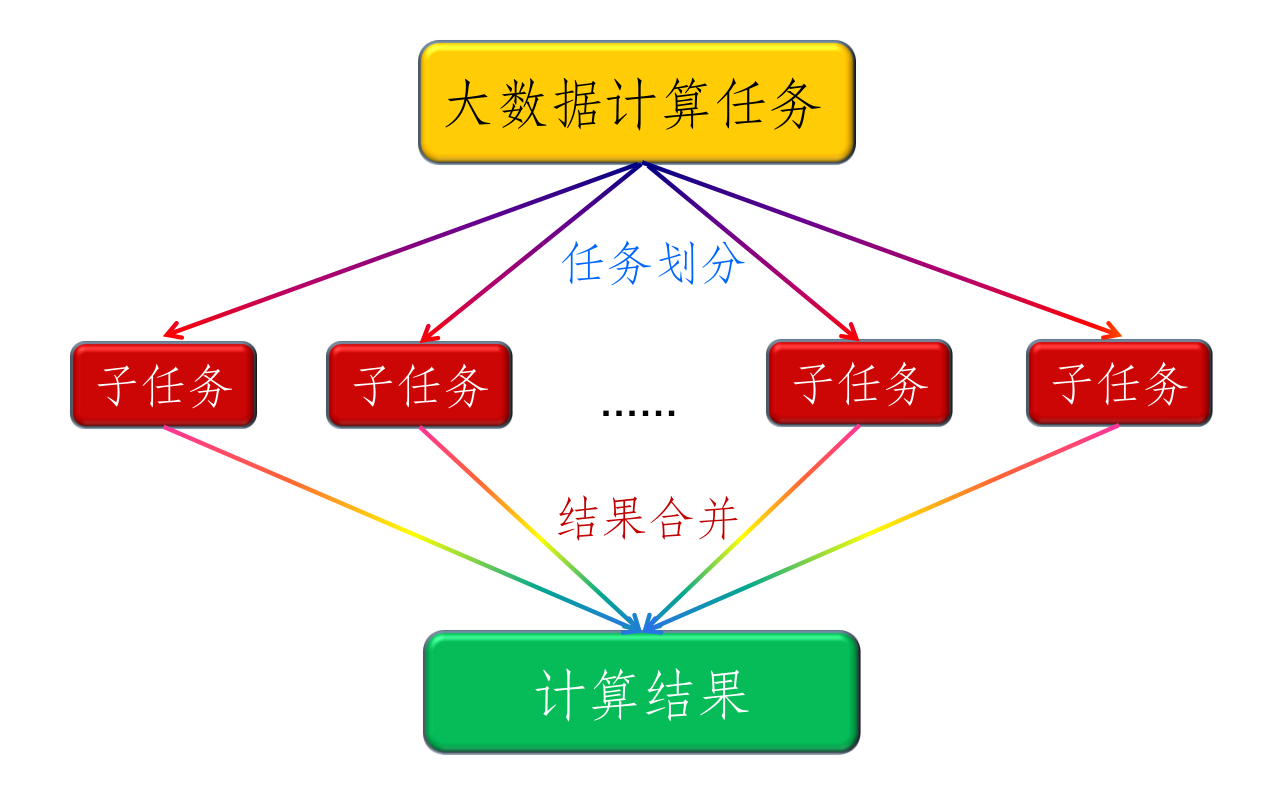
-
4 Google MapReduce 的基本架构¶
Google MapReduce¶
-
重点
¶
-
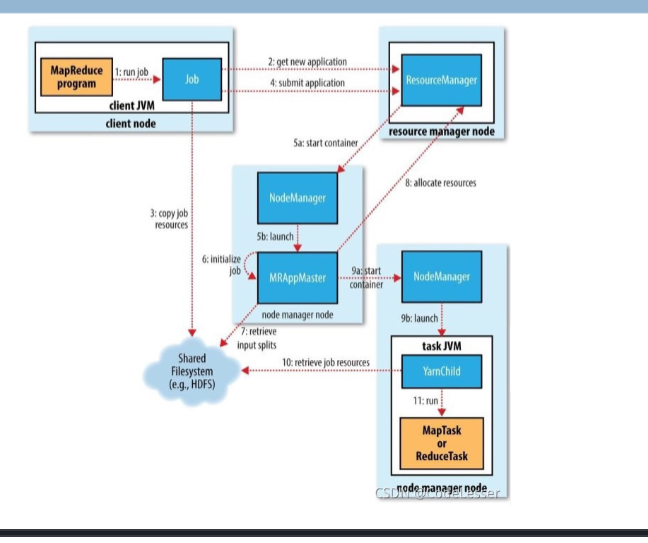
工作过程
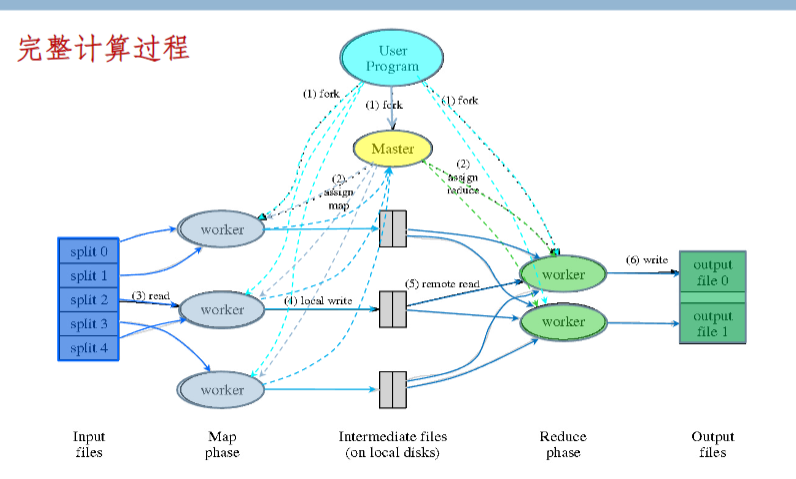
- 首先对输入数据切片(slip)
- 用户作业将程序提交给主节点,主节点寻找可用的 map、reduce 节点节点并传送程序给节点
- map 节点启动任务,将中间结果存储在本地并告知主节点
- 所有 map 节点完成之后启动 Reduce ,从 map 节点告诉主节点的位置取数据
- reduce 节点将计算结果汇总到结果文件
-
-
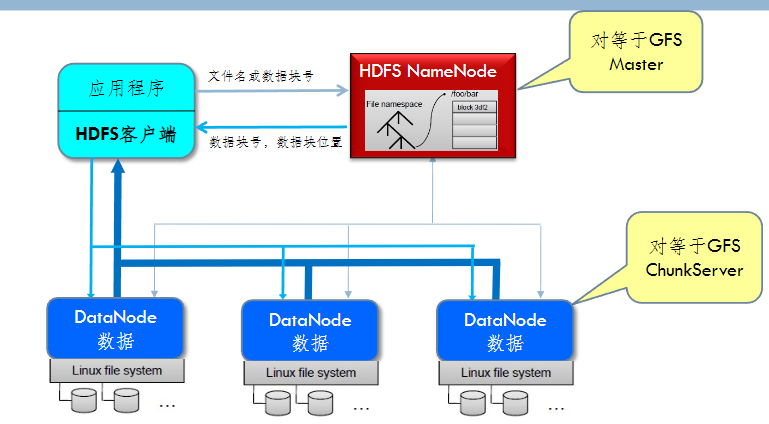
GFS¶
- Google GFS 是一个基于分布式集群的大型分布式文件系统,为 MapReduce 计算框架提供数据存储和数据可靠性支撑;数据存储在物理上分布的每个节点上,但通过 GFS 将整个数据形成一个逻辑上整体的文件。
-
重点
¶
BigTable 基本工作原理¶
- 在 GFS 之上的一个结构化数据存储和访问管理系统
-
主要解决一些大型媒体数据(Web 文档、图片等)的结构化存储问题。其结构化粒度没有那么高,也没有事务处理等能力,因此,它并不是真正意义上的数据库。
-
设计目标:高度可扩展、高吞吐、海量服务、高容错、多类型数据
-
重点
¶
5 Hadoop MapReduce 基本架构¶
- Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,
- 特性:高可靠性;高效性;高可扩展性;高容错性;成本低;运行在 Linux 平台上;支持多种编程语言。
HDFS¶
- 基本构架
-
HDFS 客户端:
- HDFS 客户端是一个库,暴露了 HDFS 文件系统接口
- 严格来说,客户端并不算是 HDFS 的一部分。
- 客户端可以支持打开、读取、写入等常见的操作,提供 shell 命令以及 Java 接口
-
读写过程
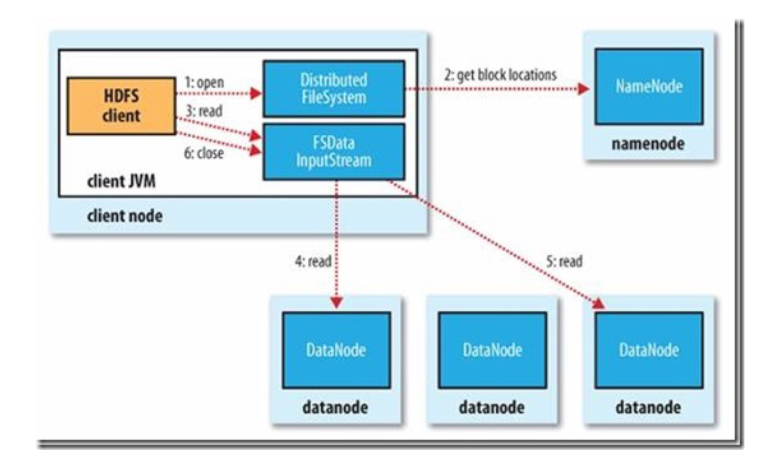
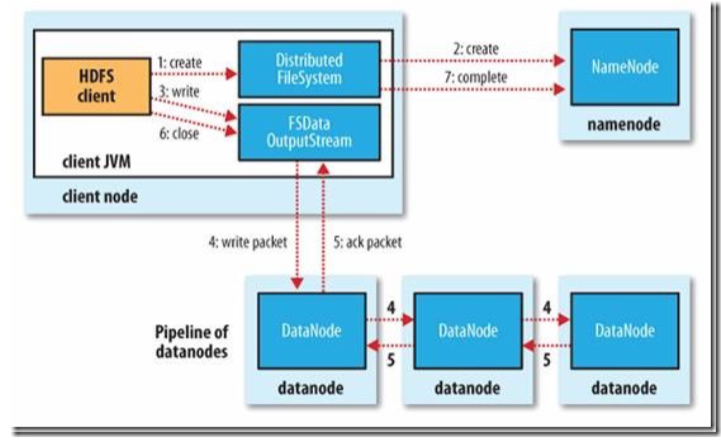
- ack package:确认收到
Hadoop MapReduce¶
-
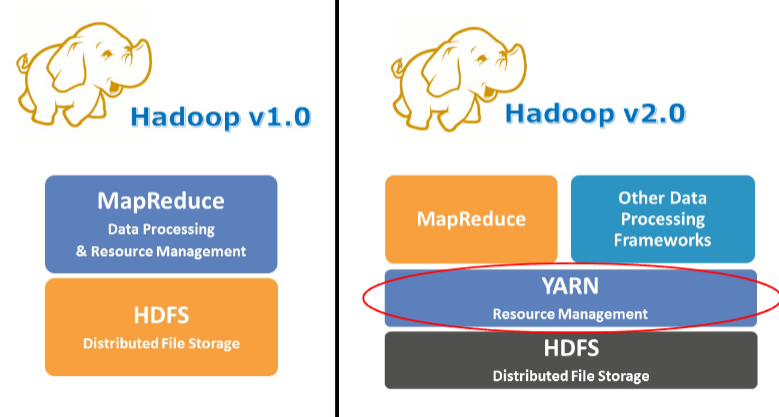
基本构架 (1.0)
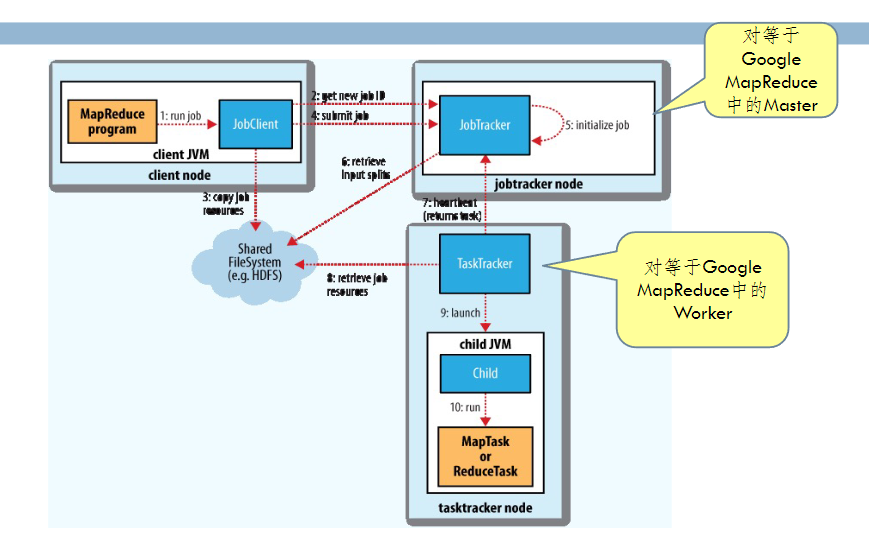
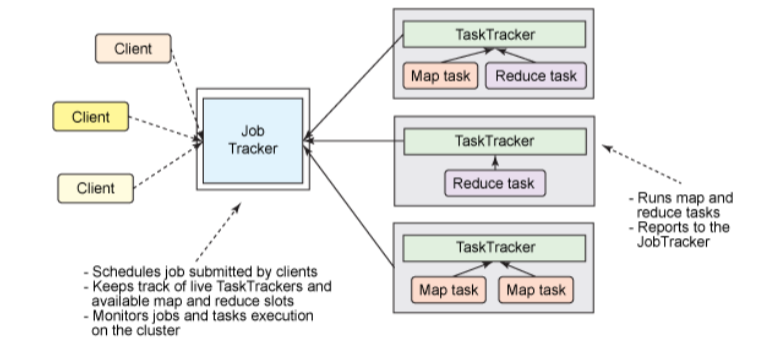
- 所有任务由 JobTracker 调度分配,存在单点故障问题
- TaskTracker 资源分配不够合理(只根据任务个数进行分配),不能按需分配
-
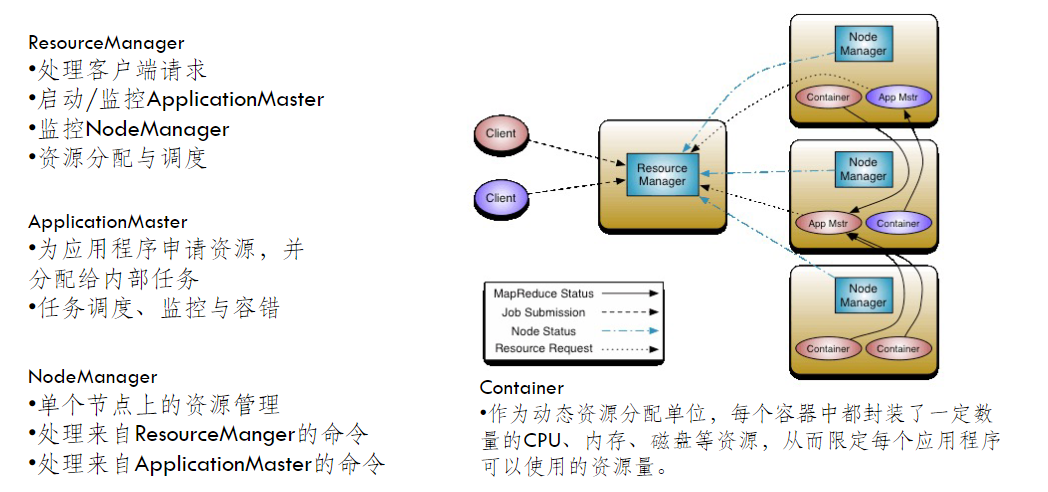
YARN (v2.0)
 **
**
-
重点
¶
-
6/7/8/9 MapReduce 编程¶
MapReduce 编程编程¶
-
-
用户自定义数据类型
- 实现 Writable 接口(或 WritableComparable)
- 含 write、readFields
-
复合键值对的使用:使用复合键值对进行分布式排序(避免进行本地排序)
-
-
-
-
重点¶
*10/11/12 MapReduce 数据挖掘基础算法(不考实现)¶
13 NoSQL 数据库¶
- RDBMS:关系型数据库管理系统
- 模式固定,面型行的数据库,具有 ACID 性质和复杂的 SQL 查询
- 效率低、复杂、扩展性差
-
SQL:结构化查询语言,用于管理关系数据库管理系统(RDBMS)
-
关系型数据库
- 优势:以完善的关系代数理论作为基础,有严格的标准,支持事务ACID四性,借助索引机制可以实现高效的查询
-
劣势:可扩展性较差,无法较好支持海量数据存储,数据模型过于死板、无法较好支持 Web 2.0 应用,事务机制影响了系统的整体性能等
-
NoSQL 数据库
- 优势:可以支持超大规模数据存储,灵活的数据模型可以很好地支持 Web 2.0 应用,具有强大的横向扩展能力等
- 劣势:缺乏数学理论基础,复杂查询性能不高,大都不能实现事务强一致性,很难实现数据完整性
重点¶
NoSQL¶
- Not Only SQL:不仅仅是 SQL,泛指非关系型数据库
-
放松了对传统数据库ACID 事务处理特征和数据高度结构化的要求,以简化设计、提高数据存储管理的灵活性、提高处理性能、支持良好的水平扩展。
-
-
-
NoSQL 的三大基石
- CAP
- BASE
- 最终一致性
重点¶
重点¶
14 HBase 基础原理与程序设计¶
-
为什么需要 HBase
- Hadoop 无法满足大数据实时访问(HDFS 面向面向批量访问而不是随机访问)
- 传统关系型数据库扩展性差,结构化浪费空间
- 解决大规模数据实时处理问题
-
与 MapReduce 协同工作,为 MapReduce 提供数据输入输出,以完成数据的并行化处理
HBase 数据模型¶
重点¶
重点¶
HBase 的基本架构¶
重点¶
数据存储结构¶
-
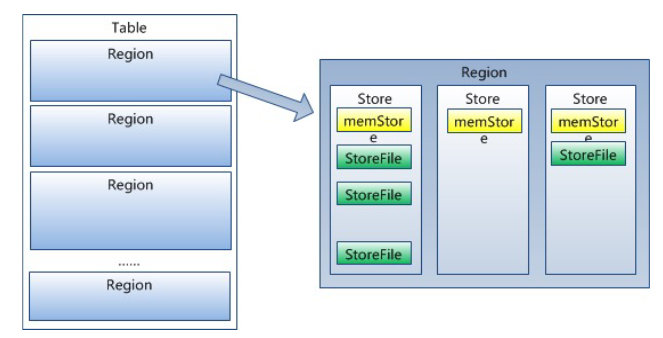
- 一个大表分隔为许多 Region 进行存储
-
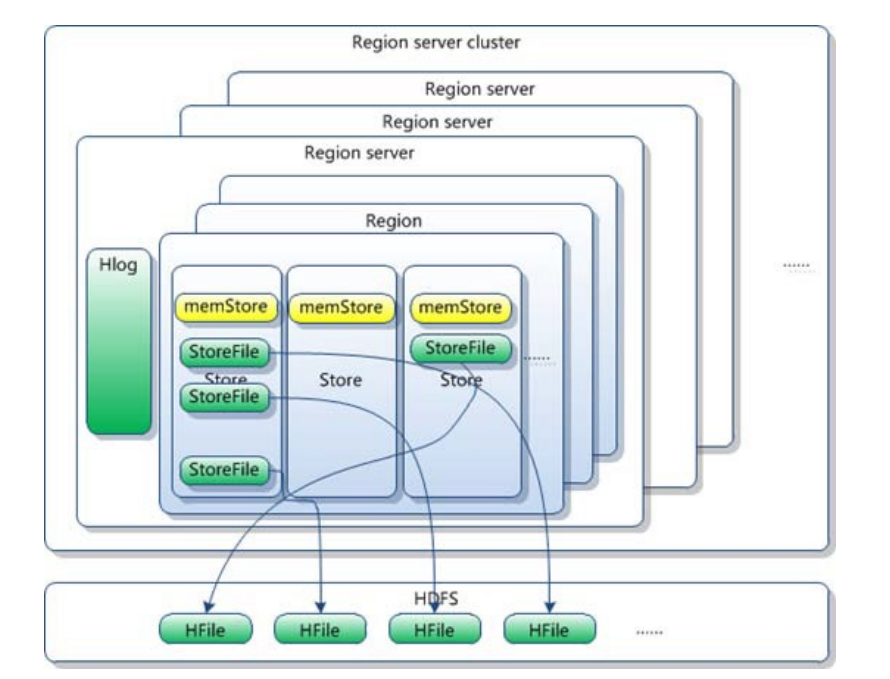
- Region Server cluster->Region server->Region->store->memStore+StoreFile
- Region:表的一个子集,包含了一系列连续的行,数据物理存储和分布的基本单元。
- 由一个 RegionServer 负责管理数据的读写,当大小增大到一定阈值会被分裂,新的 Region最初并不复制或移动数据。它们仍然读取原始 Region 的存储文件(由于不需要立即复制数据,这使得拆分操作可以非常快速地完成,几乎是瞬间的)。(异步)随后在后台进行合并过程,逐渐把原始文件中属于新 Region 的数据异步地写入新的独立文件。
- 即时可用:由于新 Region一开始就可以读取原始 Region 的文件,它们立即变得可用。
- 最终一致性:随着时间的推移,新 Region最终会有自己独立的存储文件,完成分裂。
- store:
- Store 是 Region 中的逻辑分区,对应于一个列族,每个列族存储在自己的 Store 中。
- memstore:
- MemStore 是 Store 的一部分,是一个位于内存中的数据结构,用来缓存即将写入文件系统的数据。
- storefile:
- StoreFile 是 Store 的持久化表示,是存储在HDFS 上的文件,具体格式为 HFile。
数据查询和定位¶
重点¶
HBase Shell¶
难点¶
重点¶
15 Hive 简介¶
-
Hive 包括一个高层语言的执行引擎,类似于SQL的执行引擎,方便对数据进行查询汇总、分析
- 自动将 SQL 转化为 MapReduce 执行
-
优点:可扩展性、延展性、良好的容错性
-
缺点:
- 查询延时很严重,不适用于交互查询系统
- 不是为在线事务处理设计,主要用于 OLAP 而不是而不是 OLTP
- OLTP 是一种面向事务的数据处理方式。它主要用于管理日常事务和操作,如银行交易、零售销售等。(高实时性)
- OLAP 是一种面向分析的数据处理方式。它主要用于复杂的数据分析和查询,包括趋势分析、报告生成等。
-
Hive 本身不存储数据,是逻辑表:通过元数据来描述 Hdfs 上的结构化文本数据。
-
逻辑上,数据是存储在 Hive 表里面的,而表的元数据描述了数据的布局。我们可以对表执行过滤,关联,合并等操作。在 Hadoop 里面,物理数据一般是存储在 HDFS 的,而元数据是存储在关系型数据库的。
-
RDBMS vs. Hive
- HiveQL 提供提供了与 SQL 类似的查询语言
- Hive 使用的是 Hadoop 的 HDFS,关系数据库则是服务器本地的文件系统;
- Hive 使用的计算模型是 MapReduce,而关系数据库则是自己设计的计算模型;
- 关系数据库都是为实时查询的业务进行设计的,而 Hive 则是为海量数据做数据挖掘设计的,实时性很差
重点¶
重点¶
重点¶
难点¶
Hive Shell¶
重点¶
16 Spark 简介¶
- MapReduce 计算模式的缺陷:2阶段固定模式,磁盘计算大量 I/O 性能低下
-
Spark基于内存计算思想提高计算性能,提出一种基于内存的弹性分布式数据集(RDD),通过对 RDD 的一系列操作完成计算任务,可以大大提高性能
-
RDDs
- 基于 RDD 之间的依赖关系组成 lineage,通过重计算以及 checkpoint 等机制来保证整个分布式计算的容错性。
-
只读、可分区,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用,弹性是指内存不够时可以与磁盘进行交换。
-
spark 与 hadoop
- spark 中间数据中间数据在内存中,不需要反复 IO,处理效率高
- spark 引入 RDD 抽象以及检查点,容错性更高
- spark 支持支持更多种类的操作,更加通用
重点¶
Spark 架构¶
重点¶
重点¶
重点¶
17/18/19/20 Spark 编程¶
- 以 RDD 为核心,RDD 一旦创建就不能修改,任何转换操作都会生成新的 RDD,并且 RDD 能在任何节点失败的情况下恢复数据
高级编程¶
Spark SQL¶
- 用来操作结构化和半结构化数据
-
很好的兼容性:兼容 Hive,还可以从 RDD、Parquet 文件、JSON 文件中获取数据,可以在 Scala 代码里访问 Hive 元数据,执行 Hive 语句,并且把结果取回作为 RDD 使用,也支持从外部工具中通过 JDBC/ODBC 连接 Spark SQL 进行查询;
-
SparkContext是 Spark 的早期编程接口,主要用于 RDD 操作。而SparkSession是 Spark 2.0 之后引入的新接口,是 DataFrame 和 DataSet API 的主要入口点。val conf = new SparkConf().setAppName("Spark Pi").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder.appName("Spark").master("local").getOrCreate()
重点¶
Spark 机器学习¶
-
MLlib 是 Spark 实现一些常见的机器学习算法和实用程序,面向 RDD;
-
Spark ML 是基于 DataFrame 进行机器学习 API 的开发,抽象层次更高。把数据处理的流水线抽象出
-
ML Optimizer 优化器会选择最合适的,已经实现好了的机器学习算法和相关参数
Spark 流式计算¶
- Spark Streaming 将流式计算分解成一系列短小的批处理作业
- 使用 DStream,可以在全部数据到达之前开始进行计算,实现所谓的 "在线算法" 或 "流式处理",将实时计算分解为一系列小的、时间间隔内的批处理任务。这些任务独立而确定,易于管理和调度。
- 在每个时间间隔内,系统会接收输入数据并将其可靠地存储在集群中,形成一个输入数据集。
-
当一个时间间隔结束时,Spark 对应的数据集会并行地进行 Map、Reduce、groupBy 等操作,产生中间数据或新的输出数据集,这些数据被存储在 RDD 中。
-
基本流程:
- 首先创建 StreamingContext
- 通过创建输入 DStream 来创建输入数据源。
- 通过对 DStream 定义 transformation 和 output 算子操作,来定义实时计算逻辑。
- 调用StreamingContext的start()方法,来开始实时处理数据。
重点¶
重点¶
GraphX¶
- GraphX 是 Spark 中用于图和图并行计算的 API。
- GraphX通过扩展Spark RDD引入一个新的图抽象,一个将有效信息放在顶点和边的有向多重图。