P8
3、¶
- 由于一个指令占据两个字节,而指令顺序执行时有PC=PC+2,这说明存储器中的地址1对应一个字节,即计算机存储器的编制单位为一个字节(8位)。
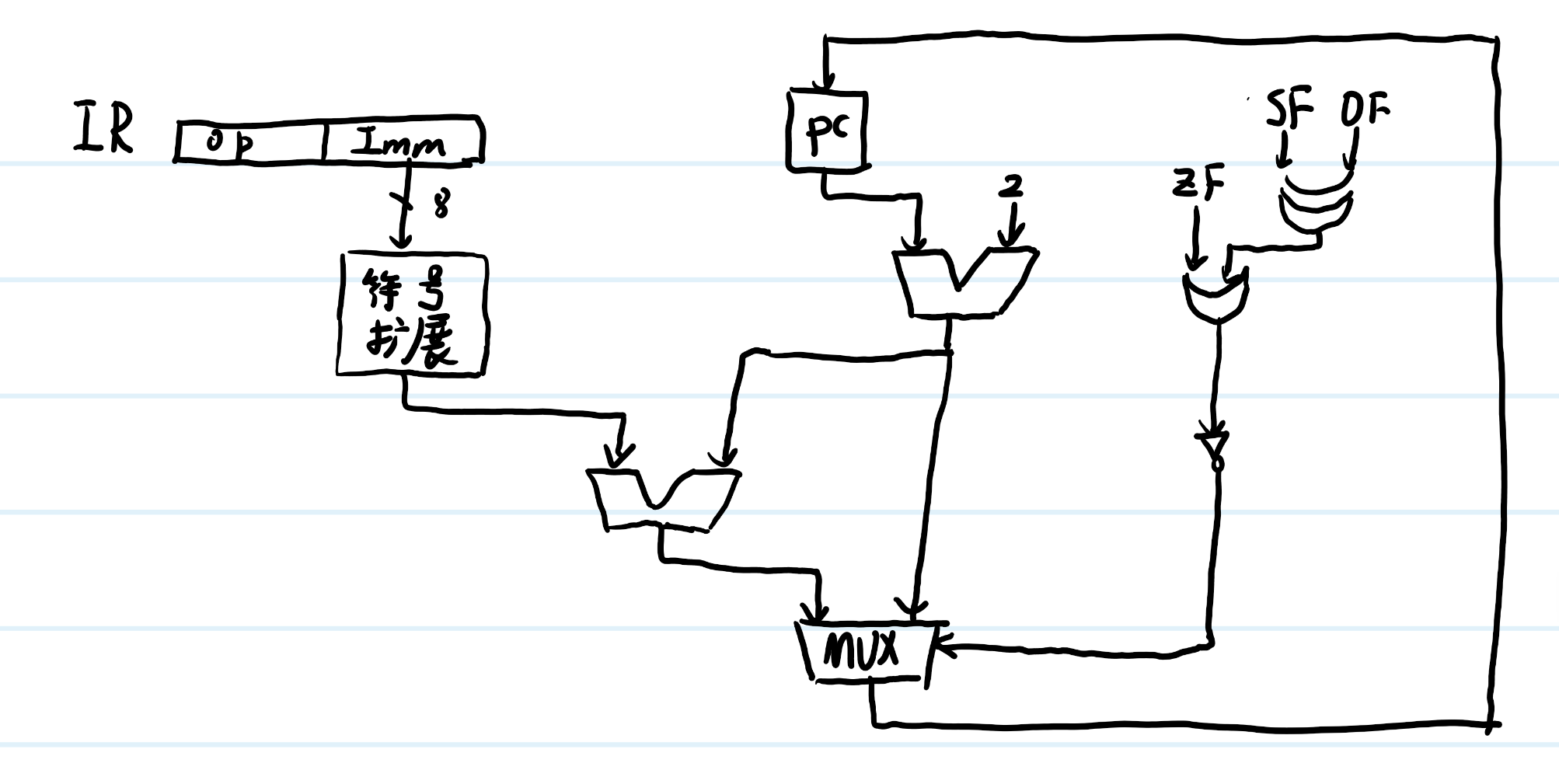
4、¶
- RegWr:所有需要写入到寄存器的指令不能正确执行,即RIUJ
- ALUASrc:不能取PC作为加数,jal、auipc不能正确执行
- Branch:体哦阿健转移指令不能正确执行,如beq
- Jump:转移指令不能正确执行jal
- MemWr:无法写入数据到存储器,S型指令无法执行
- MemtoReg:无法从存储器读取数据到寄存器,lw指令无法执行
5、¶
- RegWr:不需要写入数据到寄存器的指令不能正确执行,即BS
- ALUASrc:加数固定为PC,除了jal,auipc之外其它使用ALU的指令如RI型都无法正确执行
- Branch:B指令以外都可能出错,根据运算器标志位进行跳转
- Jump:除了jal之另外都出错,进行非必要的跳转
- MemWr:总是写入到存储器,除了S指令都可能错误的将数据写入到存储器
- MemtoReg:总是从存储器读取数据,除了rw指令都可能出错
6、¶
xor rs rs rt
xor rt rs rt
xor rs rs rt
-
\[ 设swap所占比例为x \\ 3x+(1-x)=1+0.1\\ x=0.05;\\ 即至少占5\% \]
-
在单周期数据通路中由于一个时钟周期只能写入到一个寄存器,因此无法实现swap指令
-
对于多周期数据通路可以实现,比如可以先将一个值存储到存储器,然后将另一个值写入到该寄存器,再从存储器读取
sw rs imm(r0)
addi rs rt 0
lw rt imm(r0)
11、¶
- 不能,时钟周期是根据最耗时的操作决定的,而最耗时的操作为存储单元的读取,即使 ALU 操作加快也不会影响流水线的执行速度
- \(150*1.2=180<200\) 不会对流水线的性能产生影响
- \(150*1.4=210>200\) 时钟周期变为210,流水线性能降低
13、¶
- [80,30,60|50,70,10]即时钟周期为170,考虑流水段寄存器,时钟周期为\(170+20=190ps\)
- 指令吞吐率为 \(1/190ps=5263157895\) (指令/秒)
-
单条指令执行时间为\(380ps\),总体平均执行时间为\(190ps\)
-
[80,30|60,50|70,10],时钟周期为\(130ps\)
-
指令吞吐率为 \(1/130ps=7692307692\) (指令/秒)
-
单条指令执行时间为\(390ps\),总体平均执行时间为\(130ps\)
-
[80|30,60|50|70,10],时钟时钟周期为\(110ps\)
-
指令吞吐率为 \(1/110ps=9090909091\) (指令/秒)
-
单条指令执行时间为\(440ps\),总体平均执行时间为\(110ps\)
-
[80|30|60|50|70,10],时钟时钟周期为\(100ps\)
-
指令吞吐率为 \(1/100ps=10000000000\) (指令/秒)
-
单条指令执行时间为\(500ps\),总体平均执行时间为\(100ps\)
14、¶
- 数据相关:
- (1)add与(2)add
- (2)add与(3)lw
- (2)add 与(4)add
- (3)lw与(4)add
- 不使用转发:
-
需要在4条指令之间的三个空隙均插入3个nop,即总共需要9个nop
-
采用转发:不能完全解决数据冒险,因为存在load-use的情况,需要加入一条nop指令
17、¶
assembly lw s2, 100(s6) add s6, s4 ,s7 add s2, s2, s3 lw s3, 200(s7) lw s2, 300(s8) sub s3, s4, s6 beq s2, s8, Loop
18、¶
- 如果在EX阶段确定分支结果,则 \(C=2\)
- lw与bne发生1个时钟周期的阻塞
- j指令执行之后会发生1个时钟周期的阻塞,(假设在ID阶段就取出地址)