P6
实验内容¶
实验一 :控制器设计实验¶
整体方案设计¶
- 根据指令与控制信号的对应关系绘制电路图
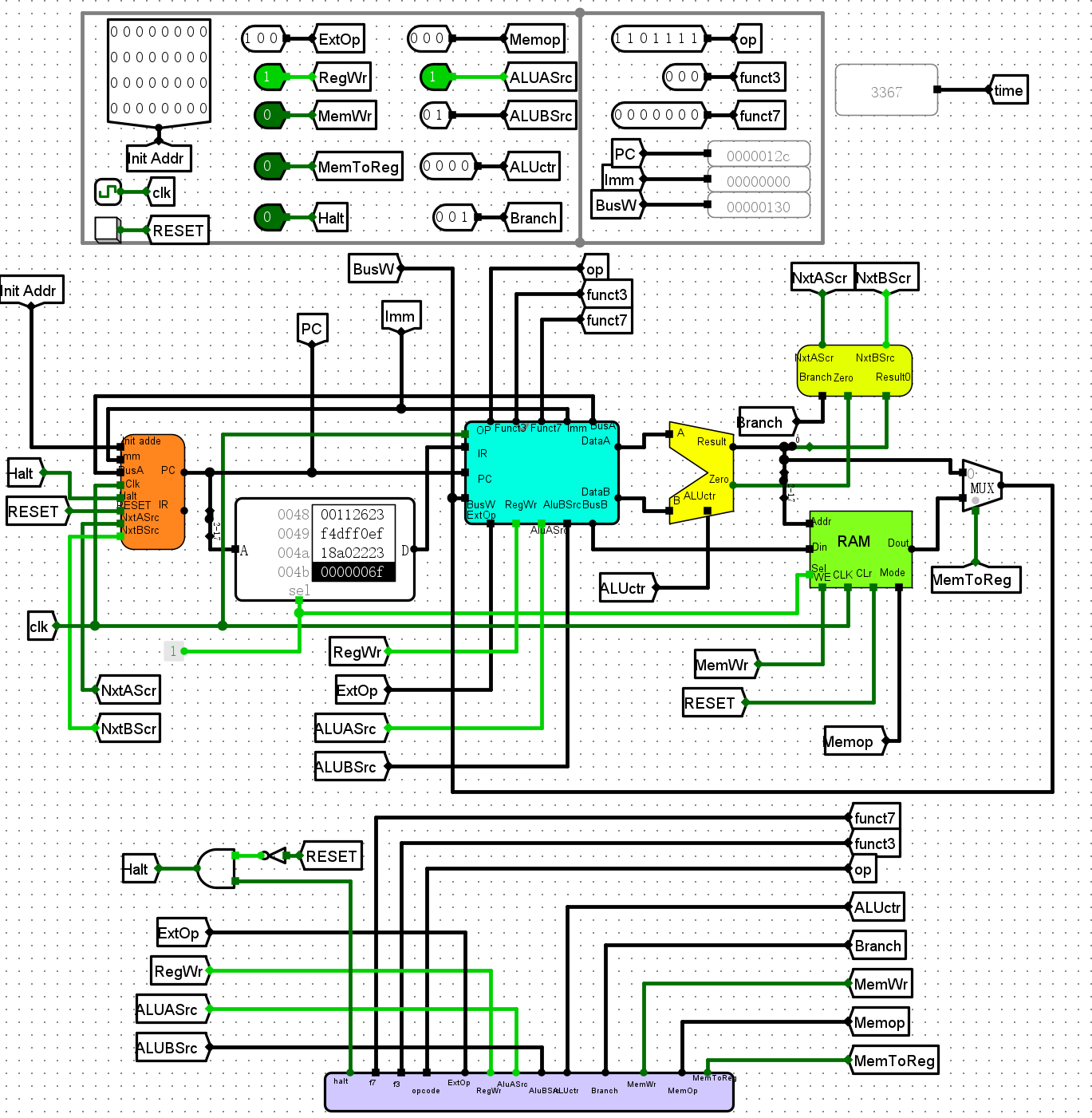
电路图¶
- 对opcode进行分类转化为一位标志
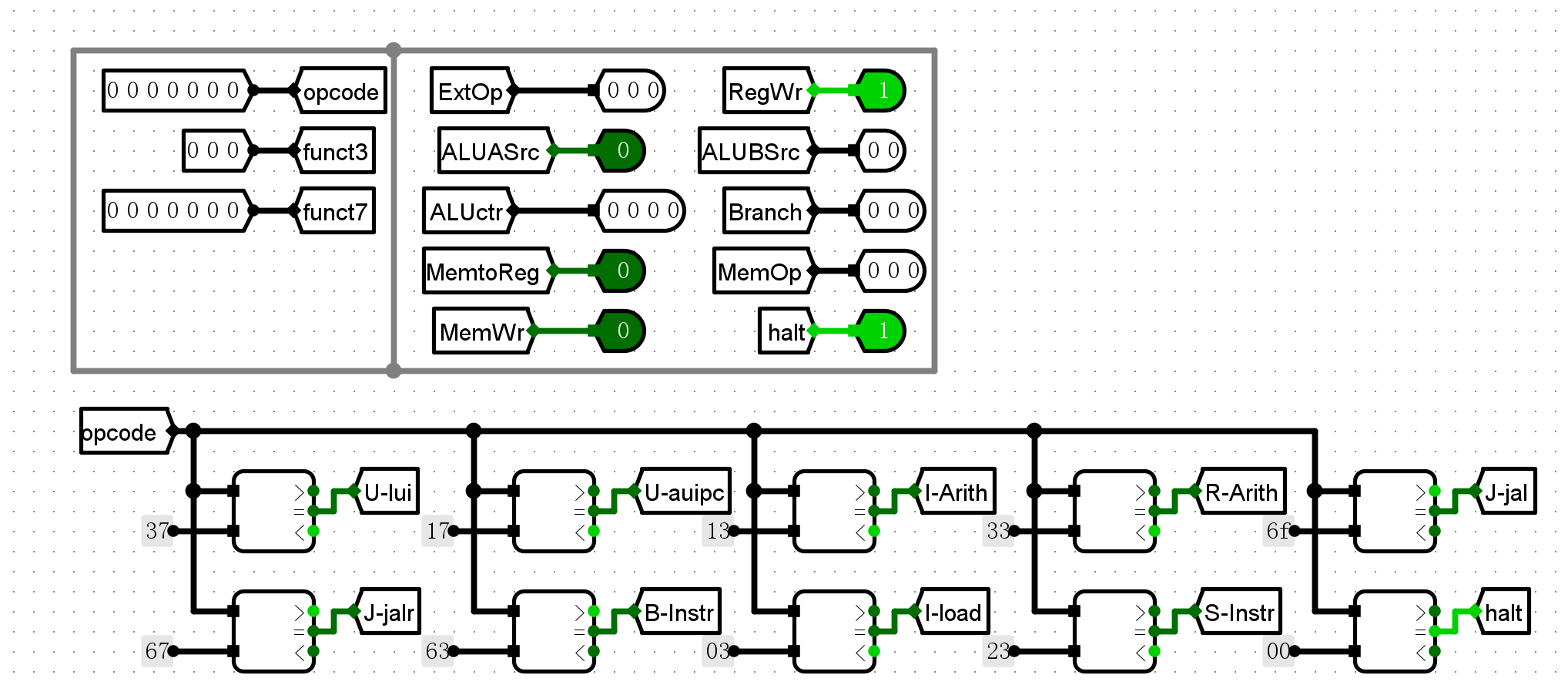
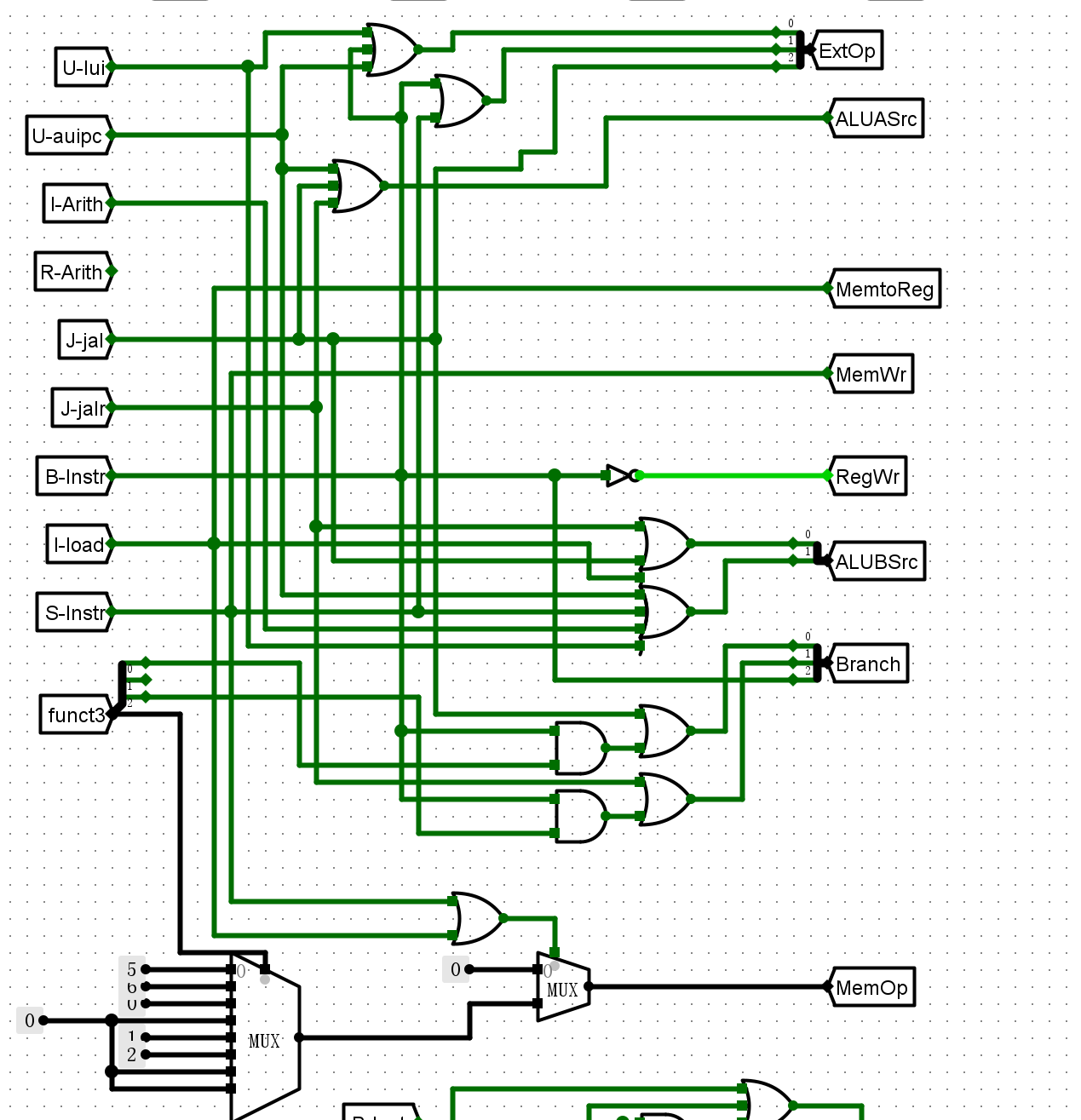
- ALUctr的设计
-
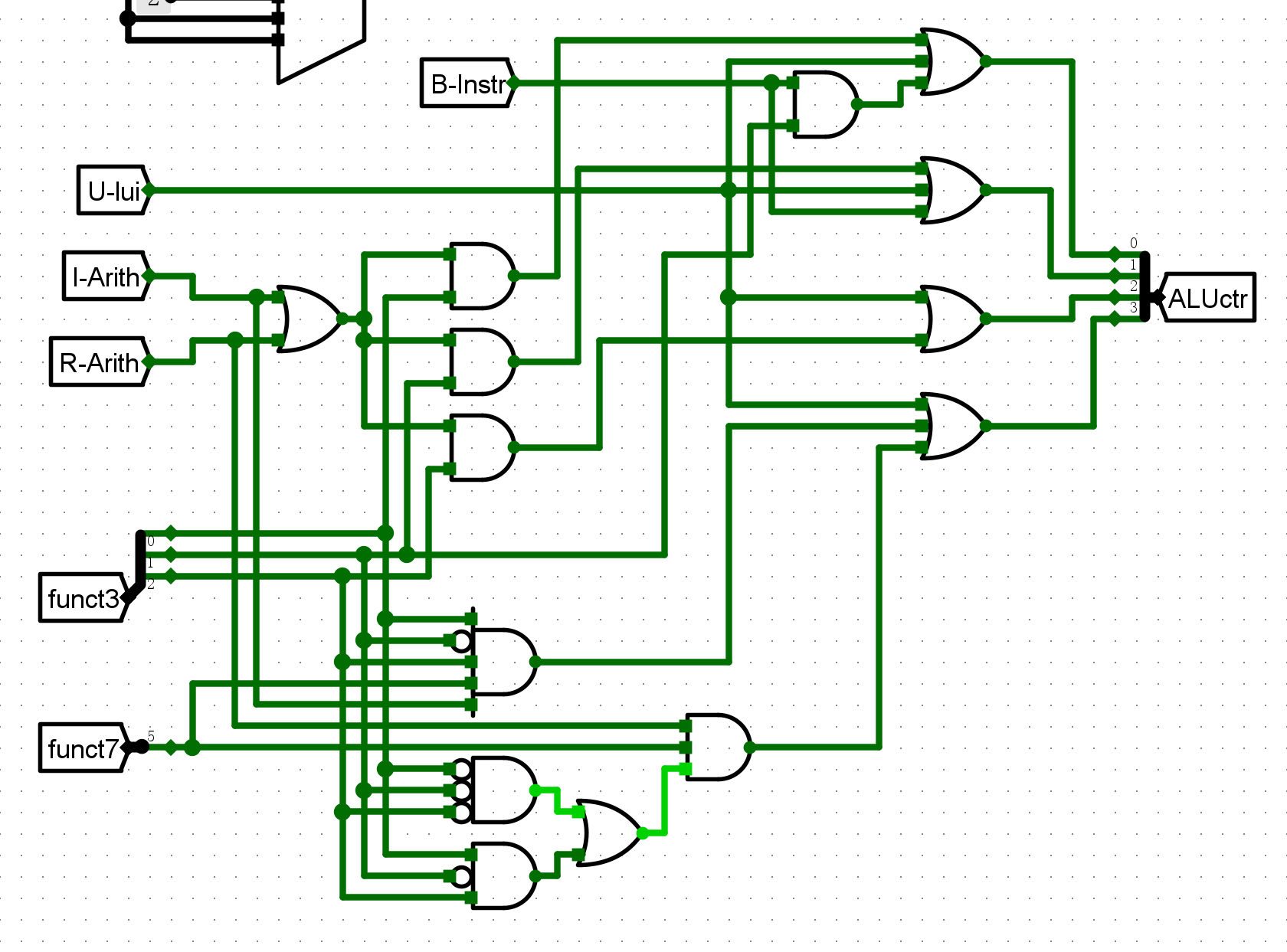
-

仿真测试¶
- 部分解码示例
- lui
-
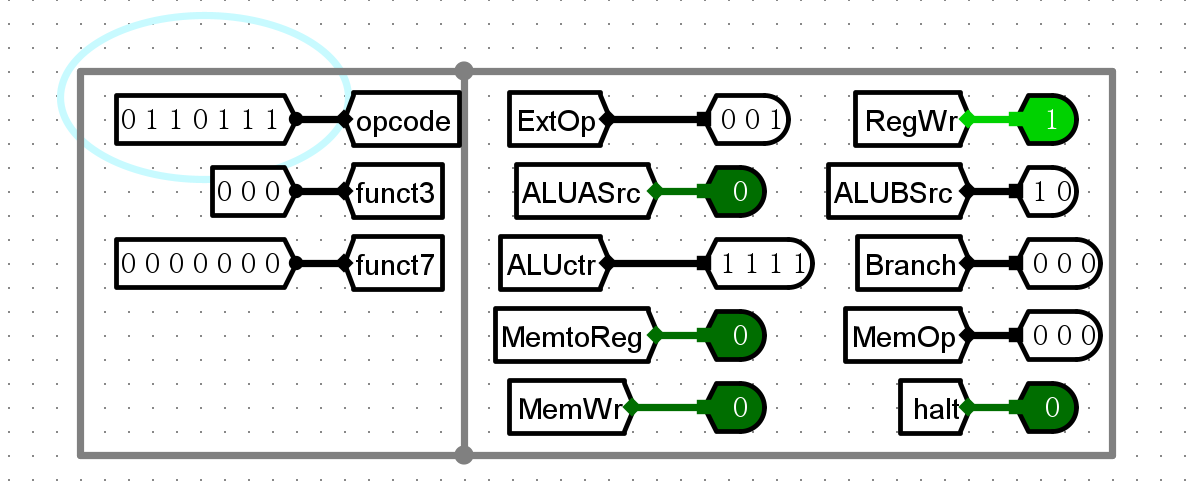
-
slli
-
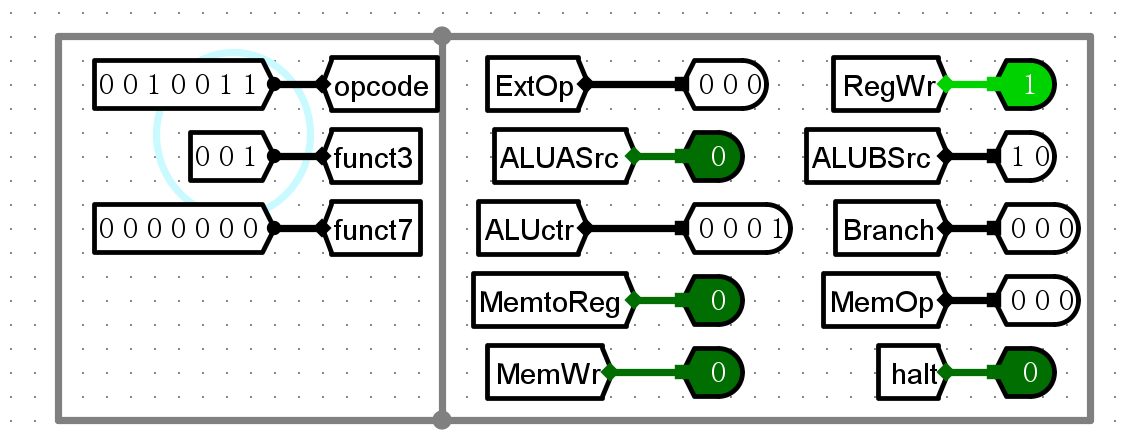
-
beq
-
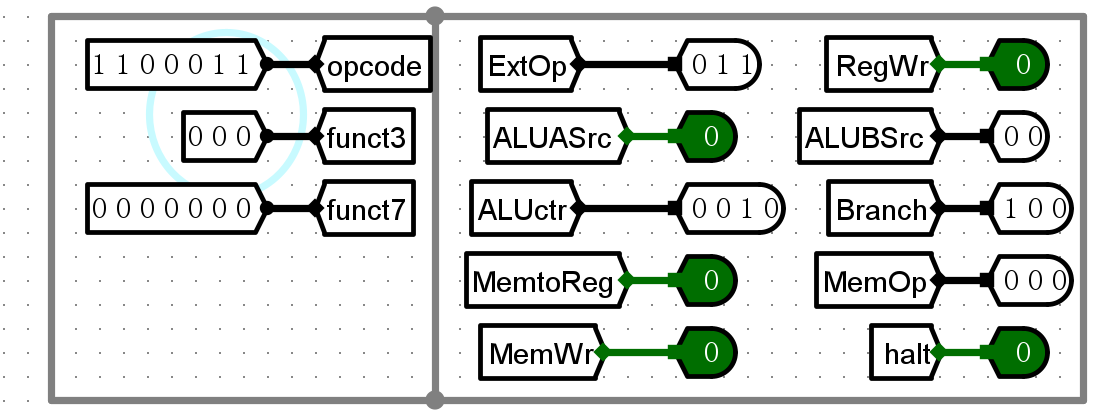
-
sw
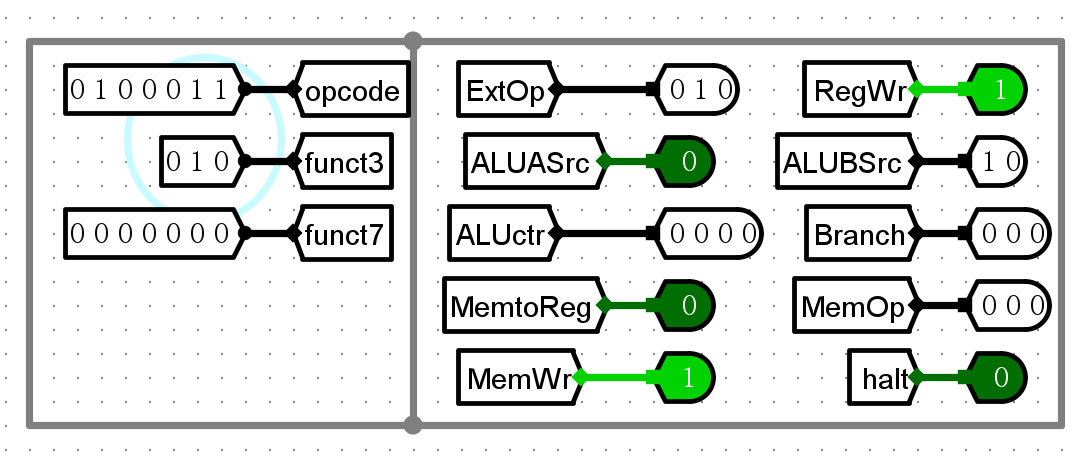
错误现象及分析¶
- 在完成实验的过程中,没有遇到任何错误。
实验二 :单周期 CPU 设计实验¶
整体方案设计¶
- 将控制器加入实验5的数据通路,代替手动输入控制信号
电路图¶
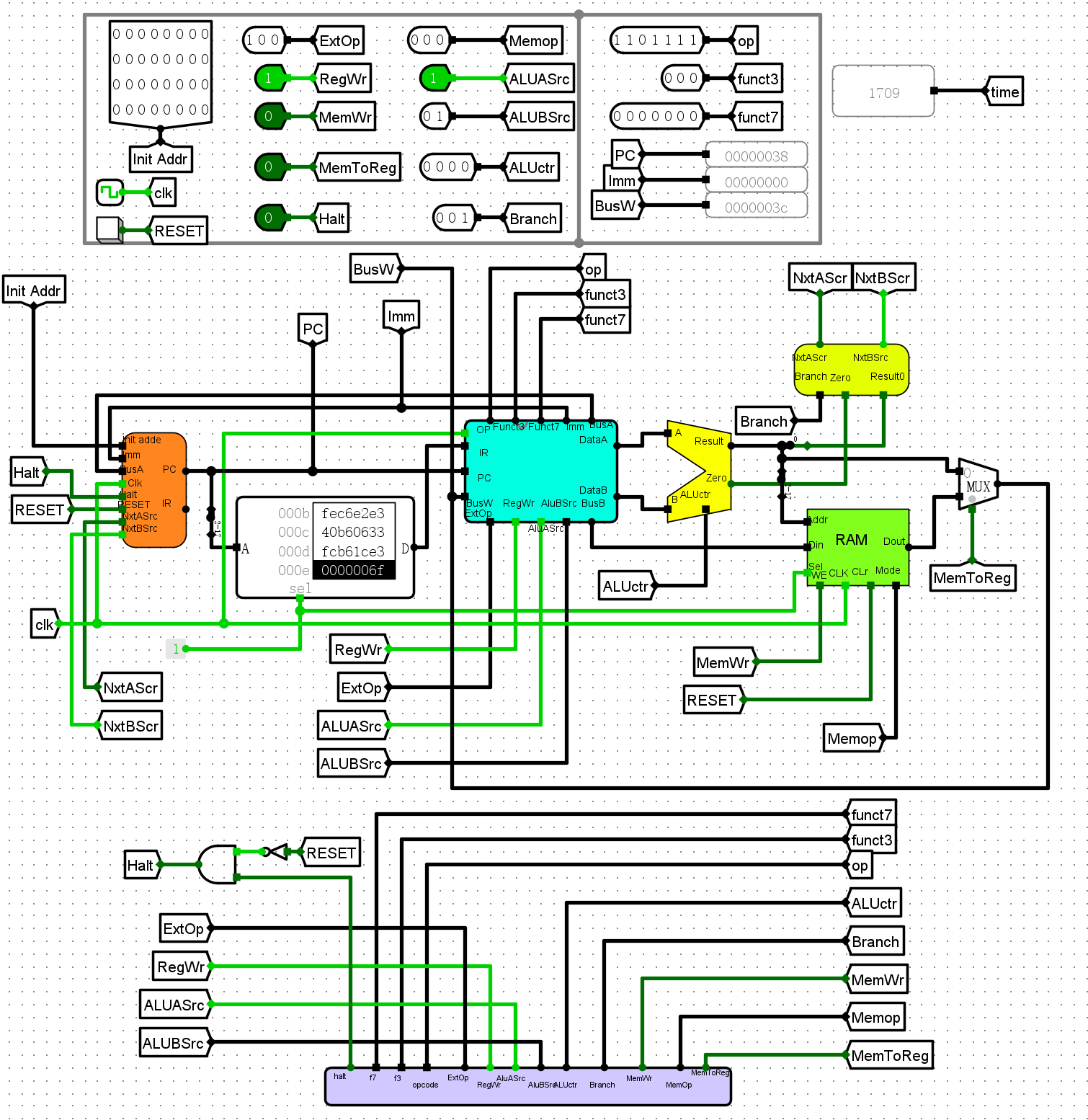
仿真测试¶
-
执行实验五的程序,并逐步比对探测量
-
得到表格与实验5一致
-
序号 汇编指令 PC BusW 立即数 寄存器堆 数据寄存器 1 lui x5,-1 00000000 fffff000 fffff000 x5:fffff000 2 addi x5,x5,100 00000004 fffff064 00000064 x5:fffff064 3 sw x5,0(x0) 00000008 00000000 00000000 0:fffff064 4 srai x6,x5,3 0000000c fffffe0c 00000403 X6:fffffe0c 5 sw x6,4(x0) 00000010 00000004 000000004 1:fffffe0c 6 lh x7,4(x0) 00000014 fffffe0c 00000004 X7:fffffe0c 7 xori x8,x7,-1 00000018 000001f3 ffffffff X8:000001f3 8 sw x8,8(x0) 0000001c 00000008 00000008 2:000001f3 9 slt x9,x8,x7 00000020 00000000 00000007 X9:00000000 10 sw x9,x12(x0) 00000024 00000000c 0000000c 3:00000000 11 bne x9,x0,label2 00000028 00000000 ffffffd8 12 jarl x10,x0,48 0000002c 00000030 00000030 X10:00000030 13 sw x10,16(x0) 00000030 00000010 00000010 4:00000030 14 auipc x11,100 00000034 00064034 00064000 X11:00064034
错误现象及分析¶
- 在完成实验的过程中,没有遇到任何错误。
实验三 :用累加和程序验证 CPU 设计¶
实验过程¶
- 将汇编程序制作为asm文件并导入到RARS
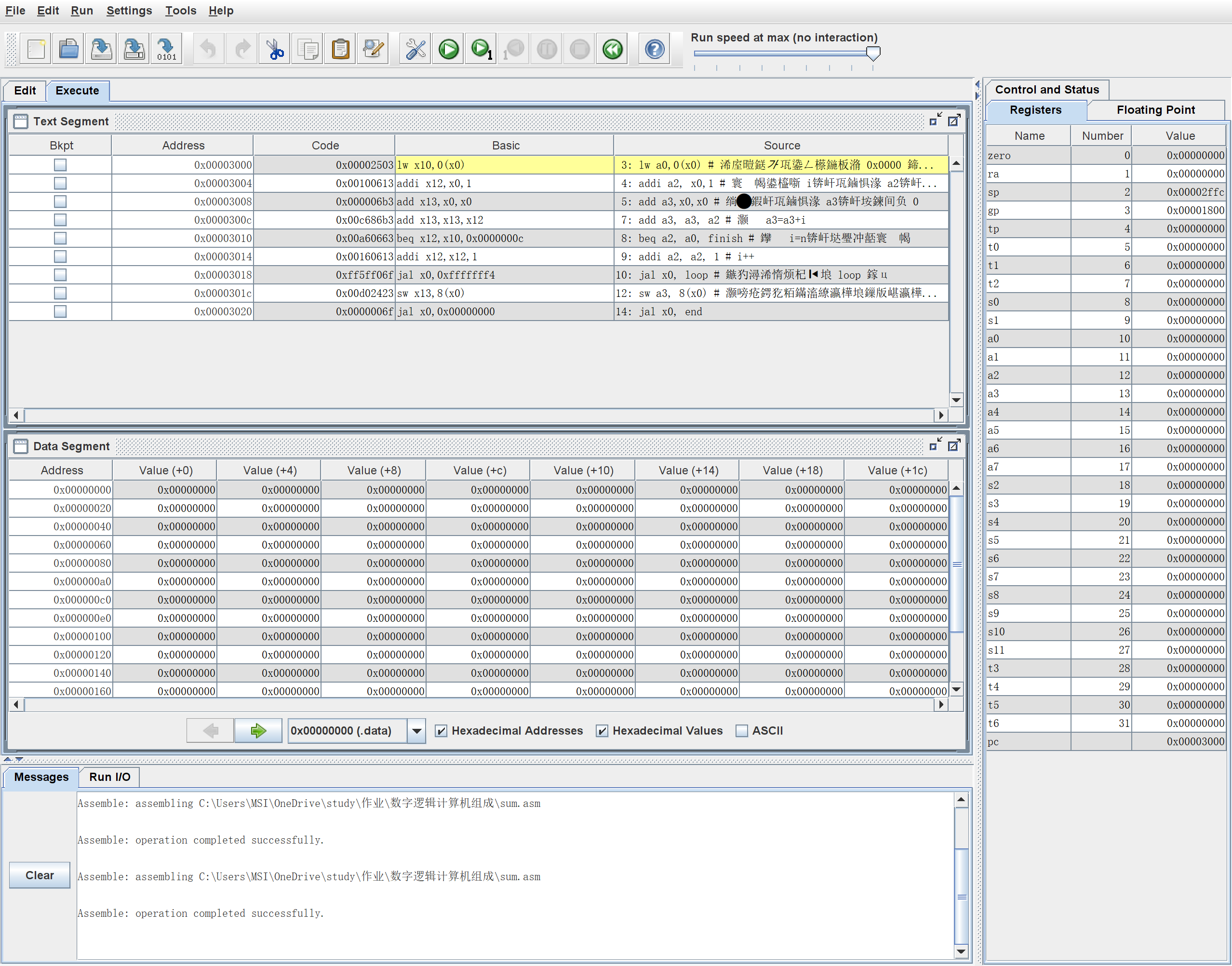
- 在RARS中模拟执行程序
-
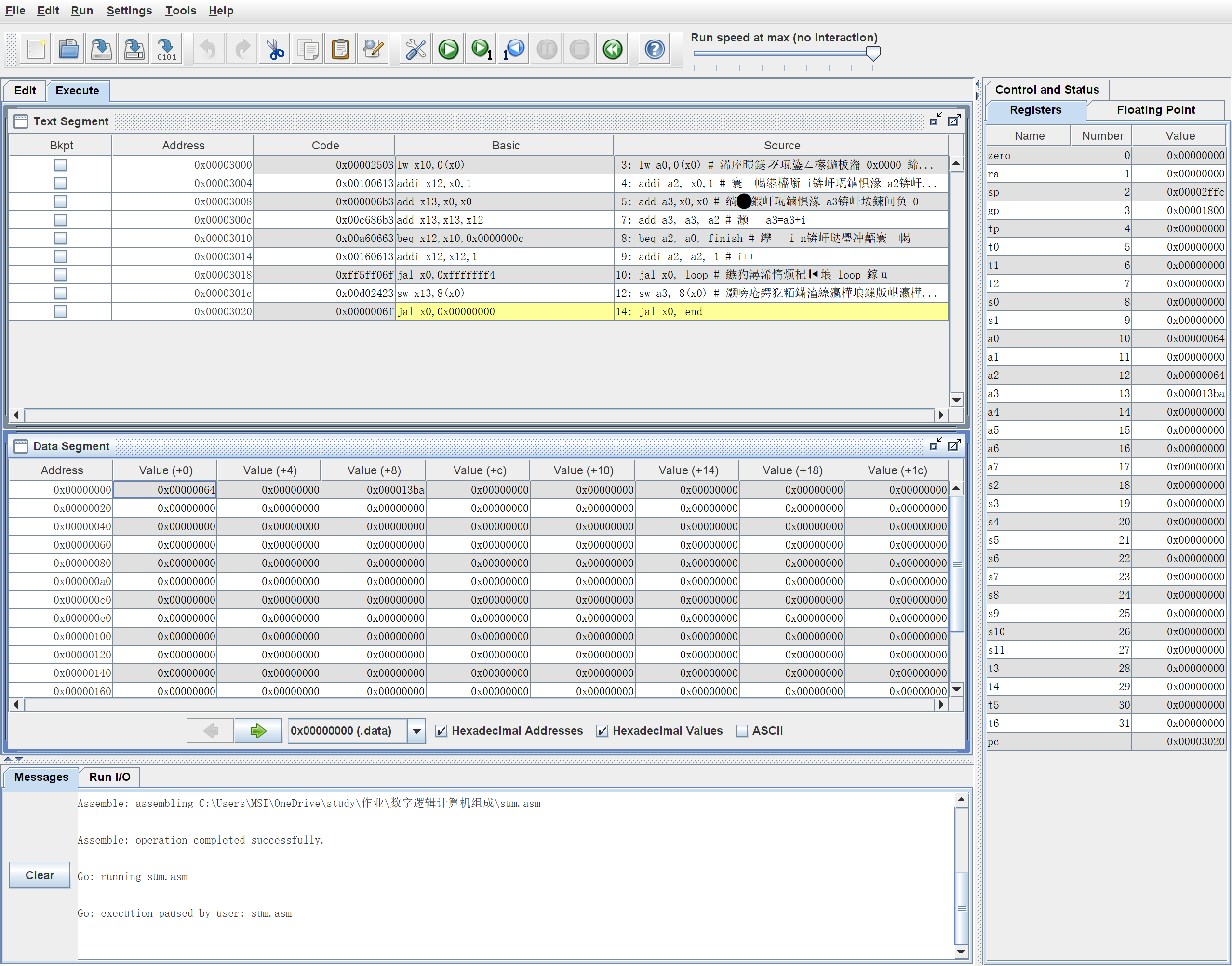
-
将RARS编译得到的机器码导入到rom,并将参数64写入到ram,之后执行程序
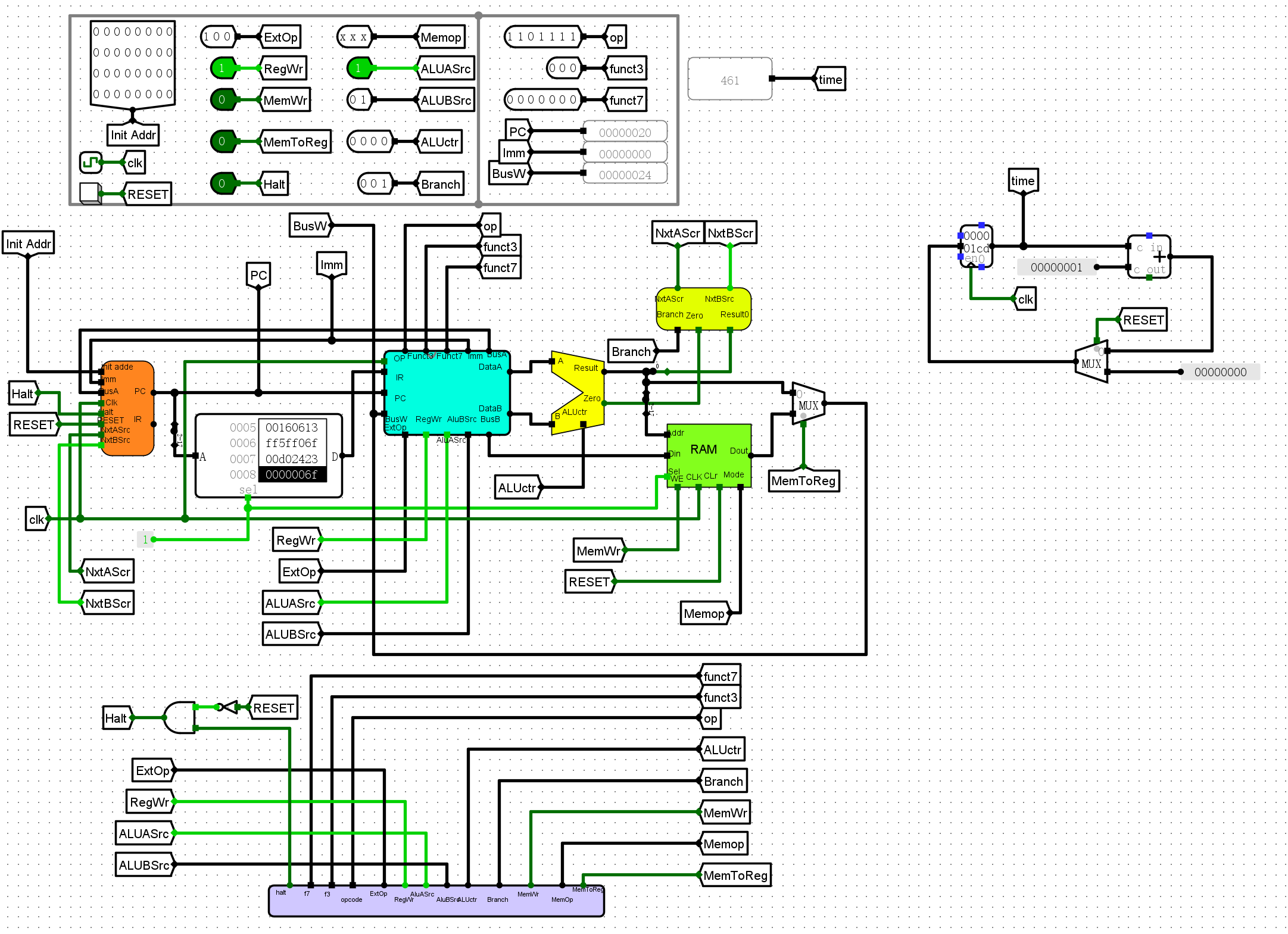
- 程序执行结果,即
00000013ba 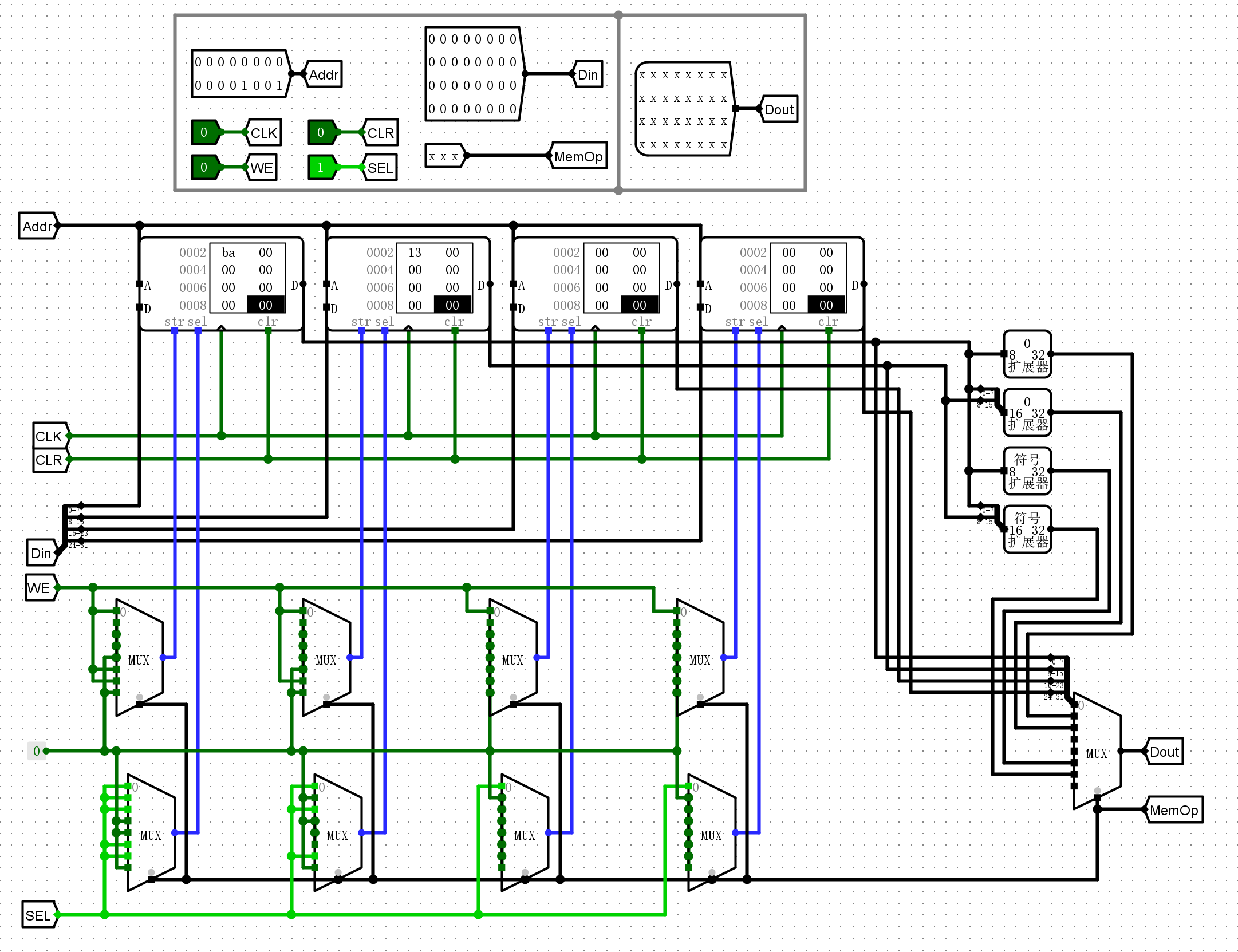
错误现象及分析¶
- 在完成实验的过程中,没有遇到任何错误。
实验四:用冒泡排序程序进行 CPU 设计验证¶
实验过程¶
-
同样使用RARS得到冒泡排序汇编程序对应的机器码,输入到ROM及RAM中,并进行计算
-
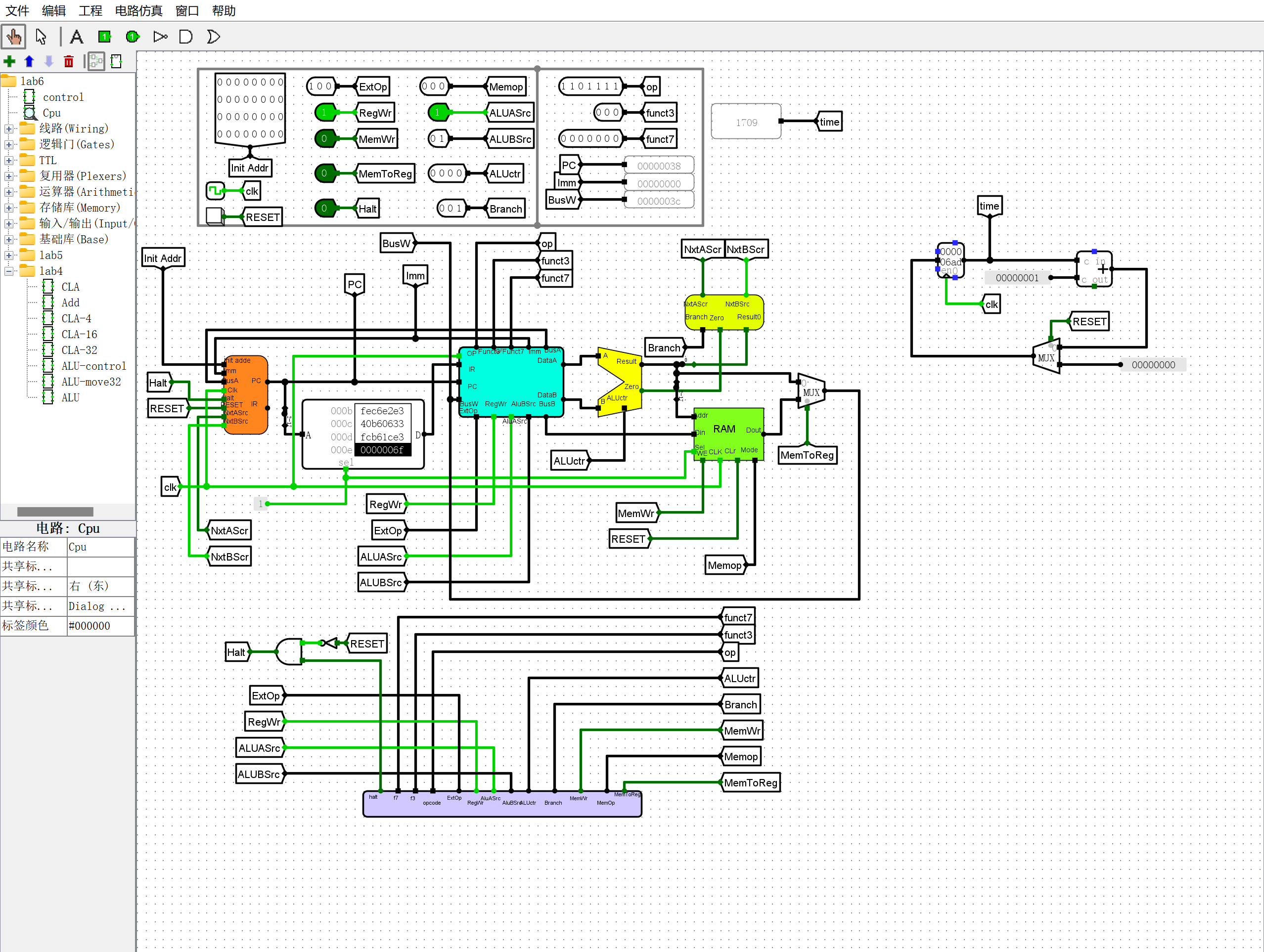
-
RAM中的排序结果
-
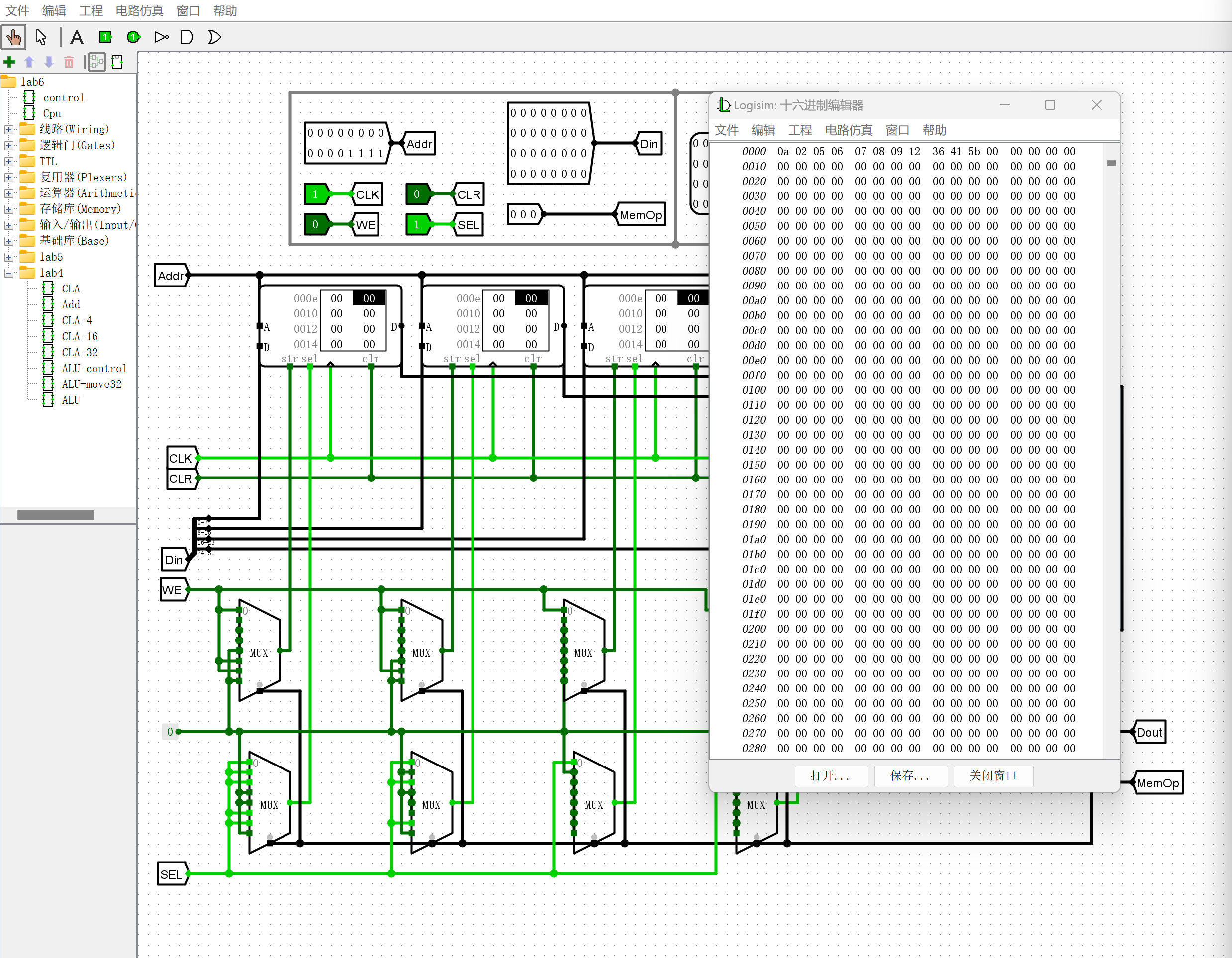
错误现象及分析¶
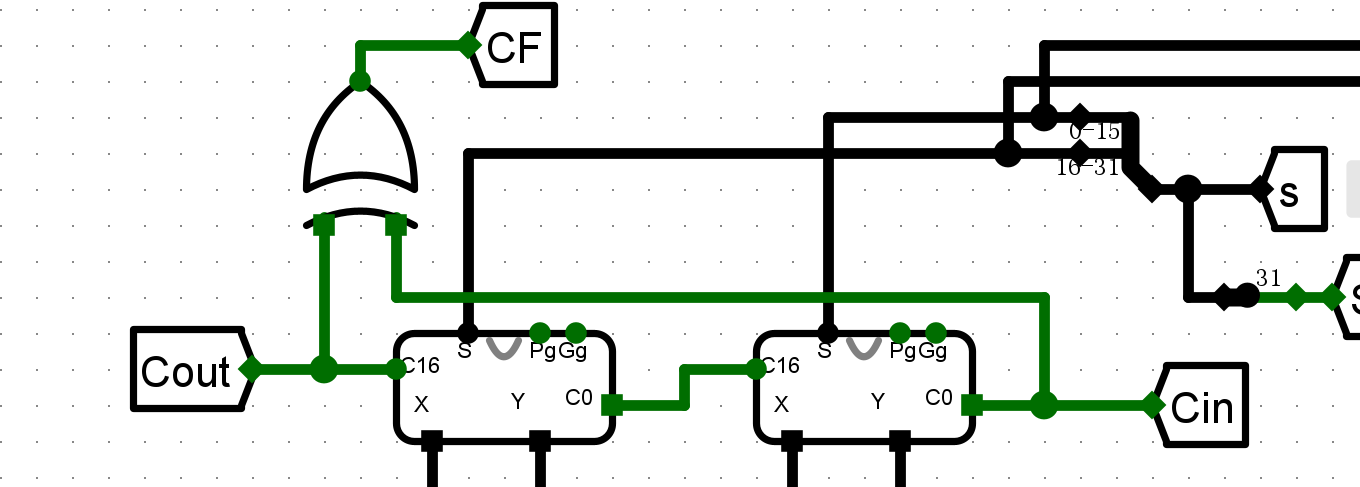
- 出现排序不会终止的问题,经过单步调试发现bgeu执行异常,进一步发现CF标志位错误
- 检查电路发现直接将CF连接到了COUT,修改为COUT和CIN的异或,解决问题,完成实验
实验五 :C 程序汇编测试¶
实验过程¶
- 将数据导入指令寄存器以及ram,然后开始运行程序
- 检查排序的反汇编代码
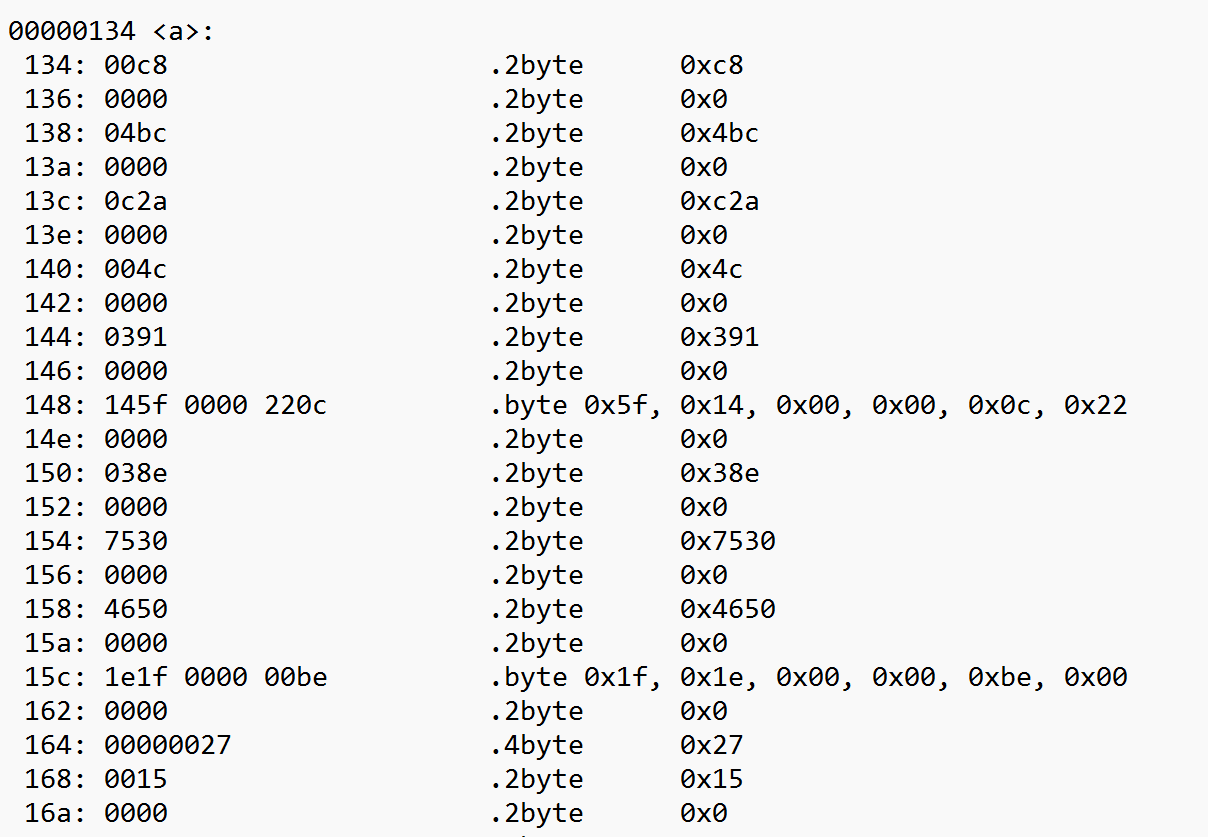
-
可以发现全局变量a的存储地址为00000134,并且这段反汇编中以字节编址,而电路中4个字节编址,因此将地址除以4得到004d
-
完成运行之后,在寄存器检查结果
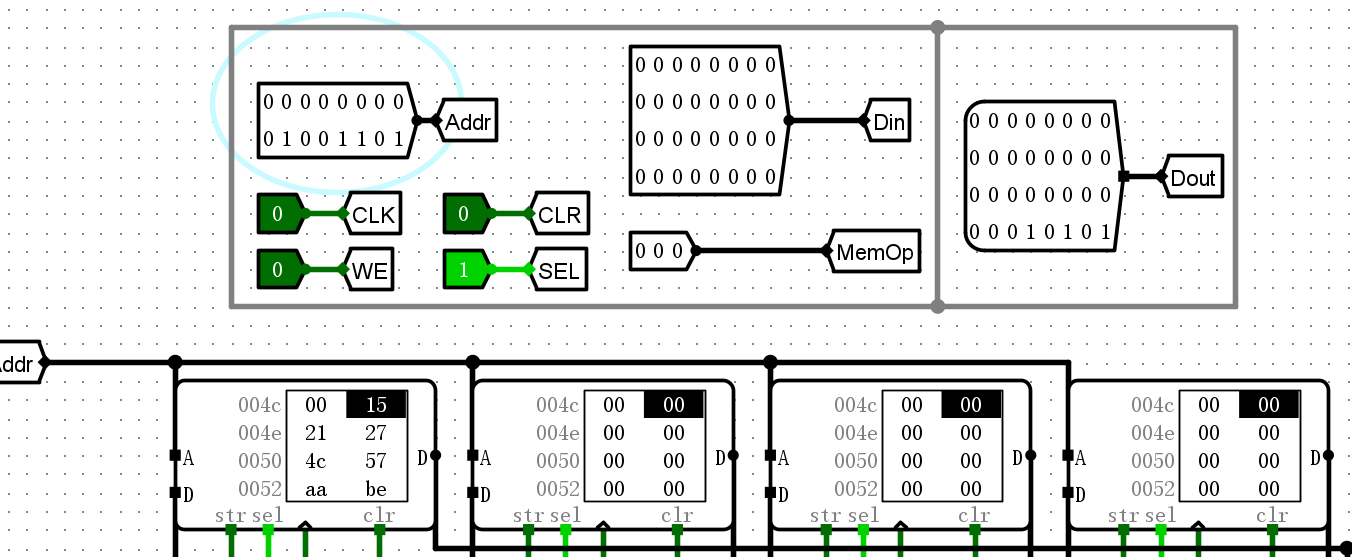
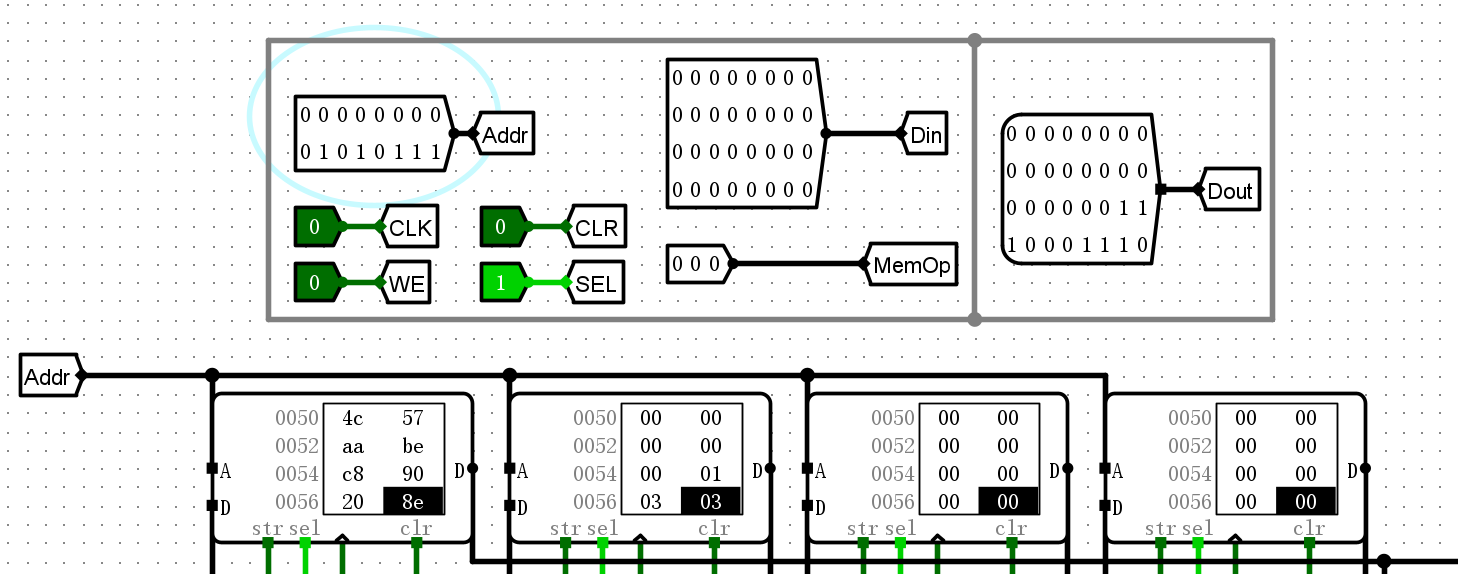
- 得到结果:21, 33, 39, 76, 87, 170, 190, 200, 400, 800, 910, 913, 1212, 2455, 3114, 5215, 7711, 8716, 18000, 30000
错误现象及分析¶
- 在完成实验的过程中,没有遇到任何错误。
思考题¶
在累加和计算程序中,添加溢出判读语句,并把最大的不溢出累计和以及累加序数保存到数据存储器中输出。¶
- ```asm main: lw a0, 0(x0) # 从数据存储器地址 0x0000 单元中读取参数 n 到寄存器 a0 addi a2, x0, 1 # 循环变量 i,存放在 a2,初值为 1 add a3, x0, x0 # 累计和存放在 a3,初值为 0 add a4, x0, x0 # 用于存放最后一个不溢出的累计和 add a5, x0, x0 # 用于存放最后一个不溢出的序数
loop: add a4, a3, x0 # 保存当前的累加和 add a5, a2, x0 # 保存当前的序数 add a3, a3, a2 # 将 a3=a3+i blt a3, a4, finish # 如果 a3 < a4,则发生了溢出,跳转到 finish beq a2, a0, finish # 若 i=n,则跳出循环 addi a2, a2, 1 # i++ jal x0, loop # 无条件跳转到 loop 执行
finish: sw a4, 4(x0) # 将最后一个不溢出的累加和保存 sw a5, 8(x0) # 将最后一个不溢出的序数保存
end: jal x0, end # 无条件跳转到 end ```
-
a4寄存器用于存储最后一个不溢出的累加和。 -
a5寄存器用于存储最后一个不溢出的序数
如果分支跳转指令不在 ALU 内部使用减法运算来实现,而是在 ALU 外使用独立比较器来实现,说说单周期 CPU 的电路原理图中需要做哪些修改?¶
- 增加独立的比较器:需要在CPU的电路中添加一个比较器组件,它专门用于比较两个寄存器的值。
- 控制逻辑修改:原先通过调整ALUCtr控制加法器的操作模式,现在应该改为控制是否使用比较器,以及比较的模式,因此还需要对控制单元需要进行修改,以便在遇到分支指令时,不再通过ALU进行比较,而是通过这个独立比较器。
- 数据路径调整:原来ALU的输入现在需要连接到新的比较器,数据除了需要连接到原先的ALU,还需要额外连接到新添加的比较器。
- 比较结果的使用:比较器的输出将直接用于决定是否进行分支。还需要通过比较器的结果生成NxAScr以及NxtBScr控制信号,还必须有0扩展器以便将比较之后的结果写入回到寄存器。
实现单周期 CPU 后,如何实现键盘输入、TTY 输出部件等输入输出设备的数据访问,构建完整的计算机系统。¶
- 设计或集成I/O接口:
- 为每个设备定义接口,并将其集成到计算机系统中。这些接口允许CPU与外部设备通信。
- 接口又缓冲区以及控制寄存器组成
- 当CPU读取一个映射到I/O设备的内存地址时,实际上是从设备的缓冲区或状态寄存器读取数据。
- 当CPU写入一个映射到I/O设备的内存地址时,实际上是向设备发送数据或控制信号。
- 实现内存映射I/O:
- 特定的内存地址被映射到I/O设备的控制寄存器或数据缓冲区。
- CPU可以通过读写这些特定的内存地址来与I/O设备交互。
- 实现中断处理:
- 中断:I/O设备可以通过中断来通知CPU有新的数据可用或设备已准备好接收数据。
- 轮询:CPU定期检查I/O设备的状态,了解是否有新数据或设备是否准备好。
- 驱动程序:
- 驱动程序是运行在CPU上的软件,负责管理与特定I/O设备的交互。
- 驱动程序控制如何操作设备的硬件接口,包括如何发送命令和解释状态。
如果需要实现 5 级流水线 RV32I CPU,则如何在单周期 CPU 基础上进行修改?¶
- 对CPU阶段进行划分:
- 取指:从程序存储器中获取指令。
- 译码:分析指令并准备必要的操作数。
- 执行:执行算术或逻辑运算,或计算地址。
- 存储器访问:进行数据的加载或存储。
- 写回:将结果写回寄存器。
- 引入流水线寄存器:
- 在每个阶段之间插入流水线寄存器来存储每个阶段的中间结果。
- 修改控制逻辑:需要实现更多的控制信号
- 实现冲突检测和处理:
- 数据冲突:这可以通过数据前递、暂停来解决。
- 控制冲突:引入分支预测、在确定分支目标前暂停流水线。
- 还需要设计一个危险检测单元来识别并处理冲突,确保正确的执行顺序。
- 调整时序和同步:
- 由于引入了流水线,整个CPU的时序需要重新设计,以确保所有阶段都能在各自的时钟周期内正确同步。