U1二进制编码
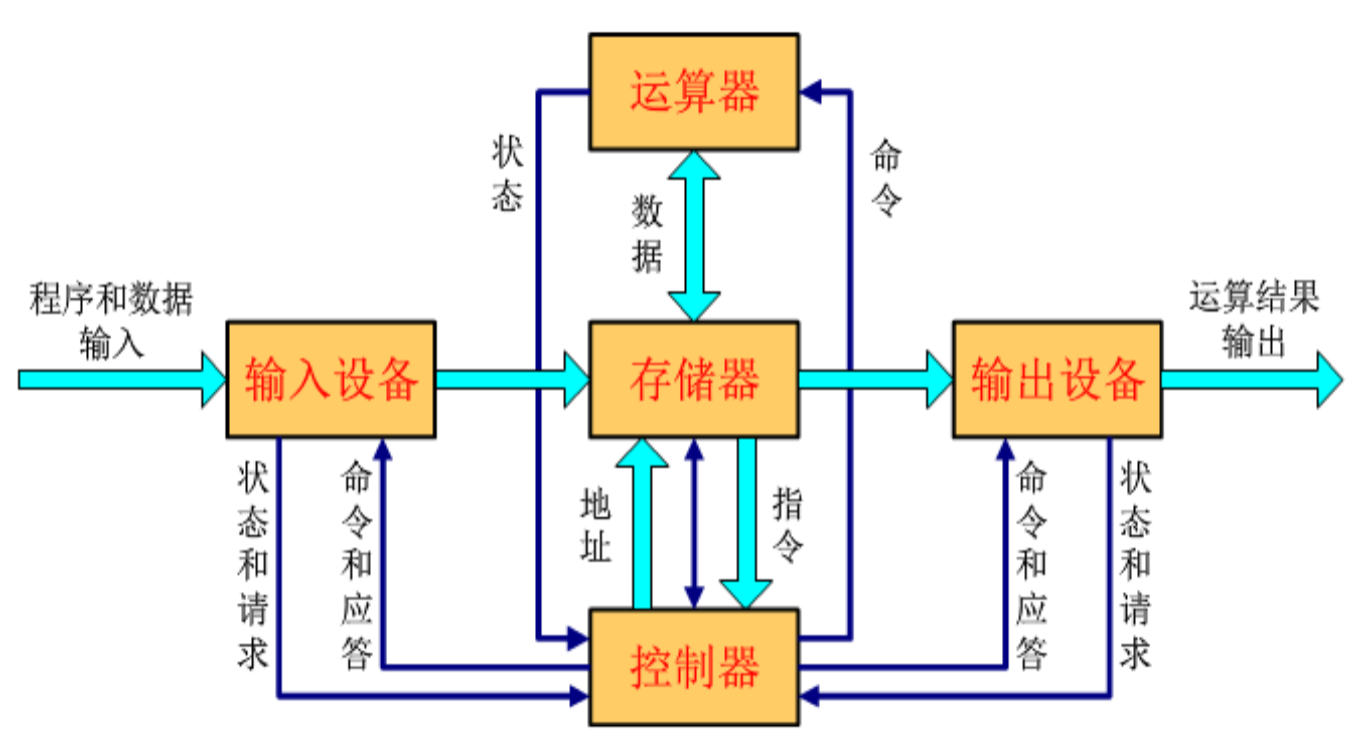
冯诺依曼体系结构¶
-
组成部件:
- 存储器存放数据、指令,都是二进制,但能区分;
- 控制器自动取出指令来执行;
- 运算器进行算术逻辑等运算;
- 通过输入设备、输出设备和主机进行通信。
-
工作方式:存储程序
- 从高存储取出指令逐条执行

-
-
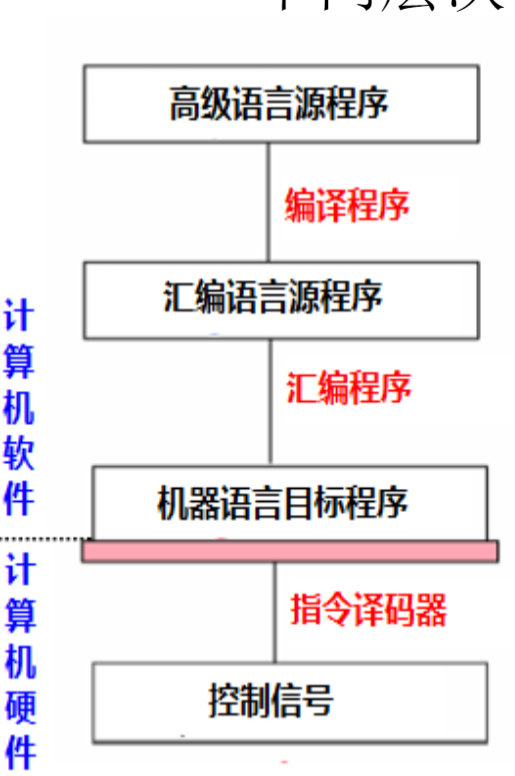
ISA 指令集体系结构
- 规定了如何使用硬件,
- 核心是指令系统,包括指令格式、操作种类以及每种操作对应的操作数的相应规定;指令可以接受的操作数的类型;指令中操作数的寻址方式;
- 操作数所能存放的寄存器的名称、编号、长度和用途;
- 操作数所能存放的存储空间的大小和编址方式;
- 操作数在存储空间存放时按照大端还是小端方式存放;
- 指令执行过程的控制方式,包括程序计数器、条件码定义等。
基本概念¶
- 机器数:用01编码、计算机内部
- 数值数据:有/无符号整数、浮点数、十进制数
- 非数值数据:逻辑数、字符
- 真值:机器数真正的值,由机器码和机器码的解释方式共同决定
数值数据¶
进制¶
- 后缀B表示二进制,后缀H或前缀0x表示十六进制,后缀O表示八进制

- 转化为8/16进制直接用8/16替换掉2就可以(实际上一般先转化为 2 进制再进一步转化为 8/16 进制)
数据的编码¶
-
原码:用来表示浮点数的尾数
-
补码:负数补码为对应正数各位取反末尾加1
-
另一种表示

-
移码(无符号数):
- 将每一个数值都加上一个偏置常数,主要用于浮点数阶码,长度为 n 时一般选择 \(2^{n-1}\) 或 \(2^{n-1}-1\),移码的机器数减去这个偏移值得到阶
- float 127 double 1023
-
补码转移码只需要直接加上偏移值(忽视溢出,译码本身是无符号数)p1
-
BCD:每个十进制位使用4位二进制表示(存在6种冗余状态)
- 有权码:8421码,四个位权值不同,权值的和就是要表示的十进制数
- 无权码:
- 余 3 码:用8421码+0011
- 格雷码:相邻编码只有一位二进位不同
浮点数¶
-

-


- 符号位(1)(1):0表示正,1表示负
-
阶码(8)(11):00000001(-126)~ 11111110(127)
-
尾数(23)(52):尾数的小数前点后面有一个隐藏的1(1.xx),尾数只存储小数点后面的部分

-

-

-
特殊表示
- 尾数、解码全0表示0(符号位任意,即有2个0)
- 阶码全1,尾数全0,由符号位决定正无穷和负无穷
- 阶码全1,尾数不为0,表示NaN
-
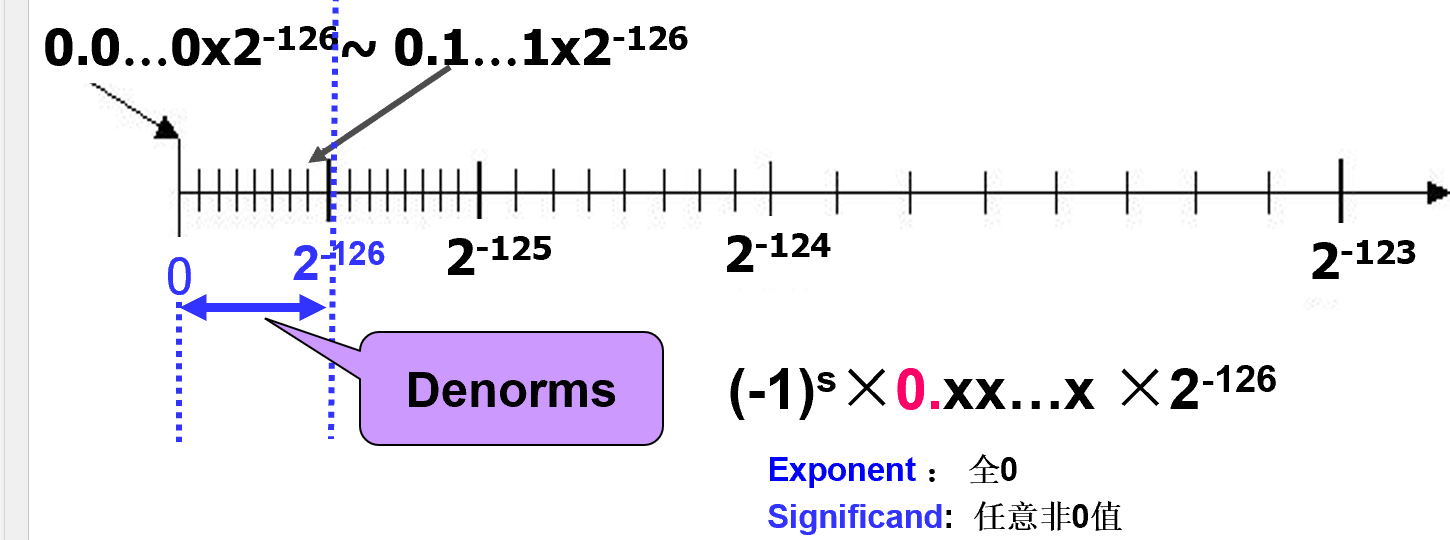
阶码为0,尾数不为0表示非规格化数
- 此部分用于填补下溢
- 为了表示数据的连续性,解码表示的真值仍然为-126(即偏移值为-126)
-
浮点数最大值\(+1.11...1*2^{127}\)
-
精度问题
- 计算存在误差:
- 类型转化可能造成精度损失:

- float->int / int->double 都可能造成精度的损失(浮点数精度由尾数的位数决定)
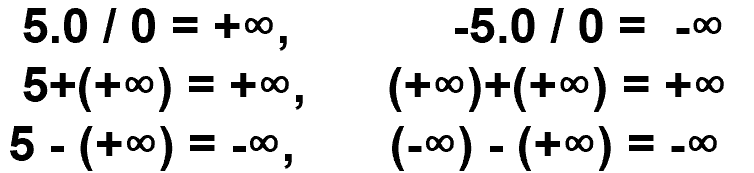

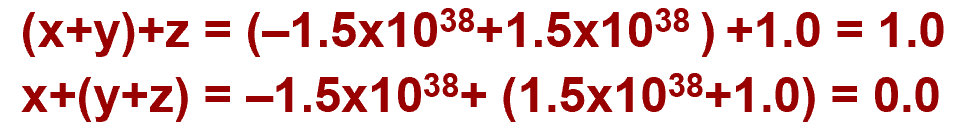
非数值数据¶
- 逻辑数据用一位二进制表示
- 西文字符:只对有限个字母、数学符号以及标点等字符编码,不超过256个(7~8位二进制)
- 7位ASCII码
- 汉字字符
- 输入码: 对汉字用相应按键进行编码表示,用于输入
- 内码: 用于在系统中进行存储、查找、传送等处理
- 字模点阵码或轮廓描述:描述汉字字模的点阵或轮廓,用于输出
- 字库: 所有汉字形状的描述信息集合
- 汉字数目很多,需要至少两个字节尽行存储

浮点数¶
- 第一位为符号位,之后全部为尾数
- 如
0.1001->01001;-0.1001->11001 - 但是对于
1.1001会发生溢出
数据的存储¶
数据的宽度¶
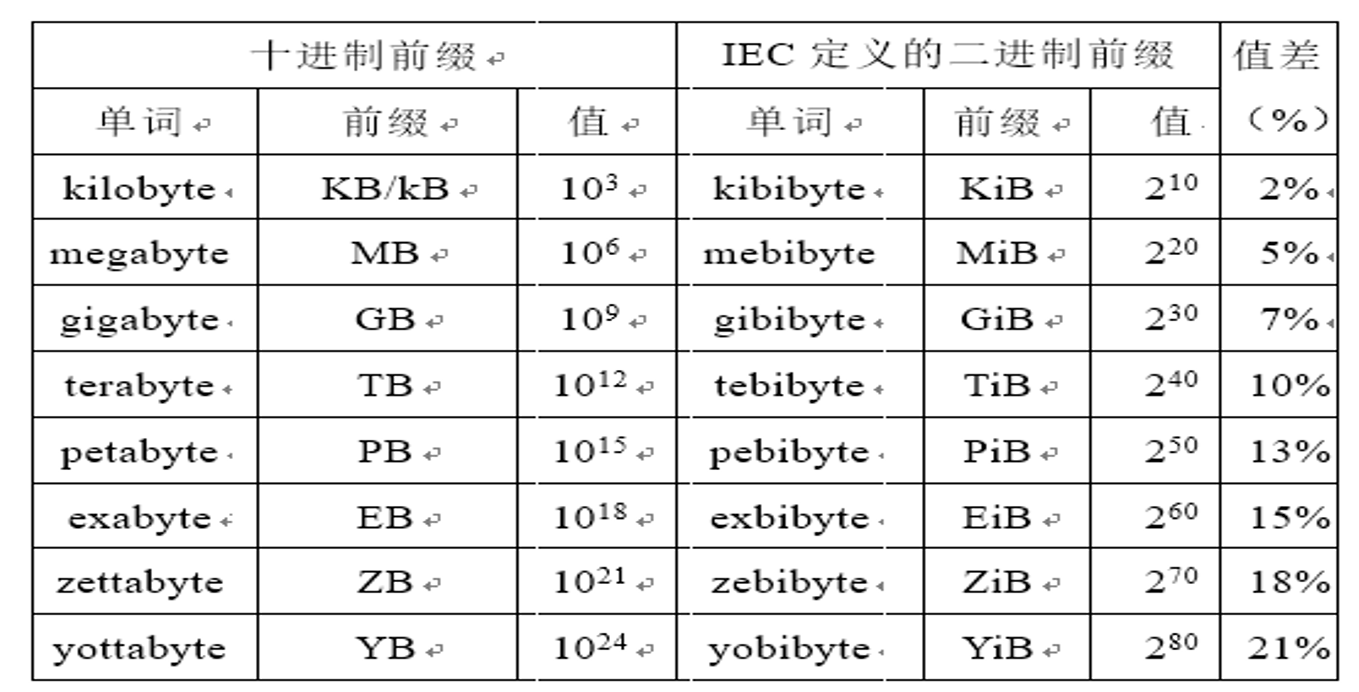
- 1字节byte=8比特bit,一个字=16bit,现代计算机按字节寻址
- 字长指定点运算数据通路宽度(取决于硬件)
- 如:IA-32中的“字”有16位,字长32位

数据的排列¶
-
数据的地址:连续若干单元中最小的地址,即:从小地址开始存放数据
- 若一个short型(16位)数据si存放在单元 0x0100和0x0101中,那么si的地址是什么—— 0x0100
-
LSB表示数据的最低有效位,MSB表示最高有效位
- 大端存储:MSB在左,是数据的地址
- 小端存储:LSB 在左,是数据的地址(I386)
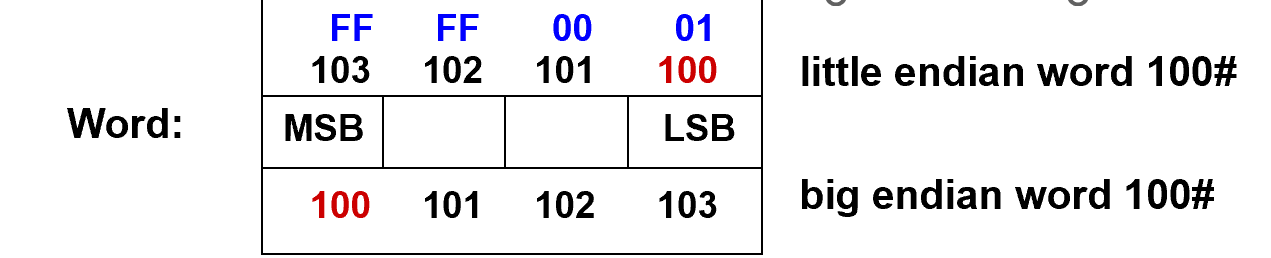
- 拼接时从MSB到LSB