实验笔记(编译工具的使用)
实验一:词法分析与语法分析¶
词法分析程序 Flex¶
- 在
.l文件中变下 Flex 程序,通过Flex lexical.l来编译得到 C 语言程序,这个程序有一个yylex()函数 - Flex 也需要一个 main 函数
int main(int argc, char** argv) { if (argc > 1) { if (!(yyin = fopen(argv[1], "r"))) { perror(argv[1]); return 1; } } while (yylex() != 0); return 0; } - 这个 main 可以直接写在
.l文件内,或者在单独的main.c- 其中
yyin是 Flex 内部变量,可能需要extern FILE* yyin
- 其中
- 编译得到可执行文件
gcc main.c lex.yy.c -lfl -o scanner - 使用可执行文件进行词法分析
./scanner test.cmm
编写 Flex 程序¶
- Flex 程序的基本结构
{definitions} %% {rules} %% {user subroutines}
definitions 定义部分¶
- 为后面常用的正则表达式取一个别名
name definitiondigit [0-9] letter [_a-zA-Z] %% ...
rules 规则部分¶
- 绑定正则表达式和响应函数
pattern {action}进行具体操作 - Flex 会按照顺序依次尝试每一个规则,尽可能匹配最长的输入,如果都不匹配就将内容复制到标准输出
- 或者添加
.匹配任何输入,并进行自定义处理digit [0-9] %% {digit}+ {printf("Integer value %d\n"),atoi(yytext)} %%
- 或者添加
- 将数字字符串转化为整数并进行打印
user subroutines 用户自定义代码¶
- 这部分代码会被复制到生成的
lex.yy.c用于执行用户自定义所需的函数 - 如果用户想要对这部分所用到的变量、函数或者头文件进行声明,可以在前面的第一部分之前使用
%{}%来提那家,这部分内容会被复制到lex.yy.c的最前面%{ /* 此处省略#include 部分 */ int chars = 0; int words = 0; int lines = 0; %} letter [a-zA-Z] %% {letter} { words++; chars+= yyleng; } \n { chars++; lines++; } . { chars++; } %% int main(int argc, char** argv) { if (argc > 1) { if (!(yyin = fopen(argv[1], "r"))) { perror(argv[1]); return 1; } } yylex();//读取文件并进行分析 printf("%8d%8d%8d\n", lines, words, chars); return 0; } - 注意引用上面定义的正则一定要添加花括号
{INT} { printf("INT:%s\n",yytext); } - 支持多文件(多参数)的 main 版本
int main(int argc, char** argv) { int i, totchars = 0, totwords = 0, totlines = 0; if (argc < 2) { /* just read stdin */ yylex(); printf("%8d%8d%8d\n", lines, words, chars); return 0; } for (i = 1; i < argc; i++) { FILE *f = fopen(argv[i], "r"); if (!f) { perror(argv[i]); return 1; } yyrestart(f); yylex(); fclose(f); printf("%8d%8d%8d %s\n", lines, words, chars, argv[i]); totchars += chars; chars = 0; totwords += words; words = 0; totlines += lines; lines = 0; } if (argc > 1) printf("%8d%8d%8d total\n", totlines, totwords, totchars); return 0; }
Flex 书写正则表达式¶
- 符号“.”匹配除换行符“\n”之外的任何一个字符。
- 正则表达式
[[Project_1.pdf#page=43&selection=117,0,118,5|Flex高级特征]]¶
语法分析 Bison¶
- 读入词法单元流,判断输入程序是否符合程序设计语言的语法规范,并在匹配规范的情况下构建输入程序的静态结构
- Bison 使用自底向上的 LALR (1)分析技术
- 编译写好的 Bison 源程序
bison syntax.y生成syntax.yy.c,程序内有一个yyparse()方法用于对输入文件进行语法分析- 没有分析错误则返回 0,否则非 0
- Bison 程序的运行还依赖于词法单元,需要再提供 flex 的
yylex函数- 在 Bision 源代码添加 `#include "lex.yy.c"
- 在编译时使用
bison -d syntax.y会自动拆分 c 和 h - 最后在 Flex 中添加
#include "syntax.tab.h"
- 由于 Bison 会在需要时自动调用 yylex (),我们在 main 函数中也就不需要调用它了。不过,Bison 是不会自己调用 yyparse ()和 yyrestart ()的,因此仍需要在 main 函数中显式地调用这两个函数
int main(int argc, char** argv) { if (argc > 1) { if (!(yyin = fopen(argv[1], "r"))) { perror(argv[1]); return 1; } } yyrestart(yyin); yyparse(); return 0; } - 联合编译
gcc main.c syntax.tab.c -lfl -ly -o parser- 执行测试
./parser test.cmm
- 执行测试
编写 Bison 程序¶
- 同样分为三部分:
- 定义部分:词法单元的定义
- 规则部分:具体语法和相应的语义动作
- 用户函数部分
- 对于文法:

%{ #include <stdio.h> %} /* declared tokens */ %token INT %token ADD SUB MUL DIV %% Calc : /* empty */ | Exp { printf("= %d\n", $1); } ; Exp : Factor | Exp ADD Factor { $$ = $1 + $3; } | Exp SUB Factor { $$ = $1 - $3; } ; Factor : Term | Factor MUL Term { $$ = $1 * $3; } | Factor DIV Term { $$ = $1 / $3; } ; Term : INT ; %% #include "lex.yy.c" int main() { yyparse(); } //每发现一个语法错误时被调用 yyerror(char* msg) { fprintf(stderr, "error: %s\n", msg); } - %token 开头定义终结符号(词法单元)
- 不在这里的为非终结符号(至少在任意产生式的左边出现一次)
- 如果需要采用 Flex 生成的 yylex()的话,那么在这里定义的词法单元都可以作为 Flex 源代码里的返回值
- 第一个生产式左边的非终结符号默认为初始符号(或者在开头定义使用
%start X手动指定 X 为初始符号):表示箭头。不同生产式用;分开。- 左边的非终结符的属性值用
$$获取,右侧按照顺序为$i - 动作使用花括号包住(默认为
$$=S1)
- 在 Flex 传递属性
{digit}* { yylval = atoi(yytext);//属性 return INT;//类型 }
属性值的类型¶
- 不同符号对应的属性值可以为不同类型
- Bison 用
YYSTYPE表示属性值的类型,用于全局(批量)的修改属性值的类型#define YYSTYPE float,如果定义为一个联合体就可以实现访问不同类型的属性值 - 用内置机制来对属性值类型进行处理
%{ #include <stdio.h> %} /* declared types */ %union { int type_int; float type_float; double type_double; } /* declared tokens */ %token <type_int> INT %token <type_float> FLOAT %token ADD SUB MUL DIV /* declared non-terminals */ %type <type_double> Exp Factor Term %% Calc : /* empty */ | Exp { printf(“= %lf\n, $1); } ; Exp : Factor | Exp ADD Factor { $$ = $1 + $3; } | Exp SUB Factor { $$ = $1 - $3; } ; Factor : Term | Factor MUL Term { $$ = $1 * $3; } | Factor DIV Term { $$ = $1 / $3; } ; Term : INT { $$ = $1; } | FLOAT { $$ = $1; } ; %% ... - 首先在定义部分的开头使用%union{…}将所有可能的类型都包含进去
- 在%token 部分我们使用一对尖括号<>把需要确定属性值类型的每个词法单元所对应的类型括起来
- 这样就自动带有了相应的类型
词法单元位置¶
- 除了属性值之外,每个语法单元还对应了位置信息
- 通过
@$ @1等获取数据
- 其中的 first_line 和 first_column 分别是该语法单元对应的第一个词素出现的行号和列号,而
- last_line 和 last_column 分别是该语法单元对应的最后一个词素出现的行号和列号。
- 要想使用这些位置信息,还需要在 Flex 源文件的开头部分定义变量 yycolumn,并添加宏定义 YY_USER_ACTION(在执行每个动作之前会执行)
\n { yycolumn = 1; }%locations … %{ /* 此处省略#include 部分 */ int yycolumn = 1; #define YY_USER_ACTION \ yylloc.first_line = yylloc.last_line = yylineno; \ yylloc.first_column = yycolumn; \ yylloc.last_column = yycolumn + yyleng - 1; \ yycolumn += yyleng; %}
二义性与冲突处理¶
- 对于
1+2-3这样的式子可能存在二义性,可以通过显示的指定运算符的优先级和结合性来解决。 - 通过“%left”、“%right”和“%nonassoc” (不可结合)对终结符号的结合性进行规定
- 左结合表示表达式中优先级相同的运算符从左到右进行运算
%right ASSIGN %left ADD SUB %left MUL DIV %left LP RP
- 左结合表示表达式中优先级相同的运算符从左到右进行运算
- 这除了制定了结合性外还设置了优先级(Bison 规定排在后面的运算符的优先级高于前面)
- Bison 默认会对冲入尝试进行处理(移动优先于规约),因此对于嵌套 if-else 的处理是符合要求的(else 总是匹配最近的 if)
- 但是仍然会提示出现了移入规约冲突
- 产生式后面都可以紧跟一个%prec 标记,指明该产生式的优先级等同于一个终结符号
Stmt : IF LP Exp RP Stmt %prec LOWER_THAN_ELSE | IF LP Exp RP Stmt ELSE Stmt
- 当语法分析程序读到 IFLP Exp RP 时,如果它面临归约和移入 ELSE 这两种选择,它会根据优先级自动选择移入 ELSE
错误恢复¶
- 当语法分析程序从 yylex ()得到了一个词法单元,如果当前状态并没有针对这个词法单元的动作,那 Bison 就会认为输入文件里出现了语法错误,此时它默认进入如下错误恢复模式:
- 调用 yyerror ("syntax error"),该函数默认会在屏幕上打印出 syntax error 的字样。
- 从栈顶弹出所有还没有处理完的规则,直到语法分析程序回到了一个可以移入特殊符号 error 的状态。
- 移入 error,然后对输入的词法单元进行丢弃,直到找到一个能够跟在 error 之后的符号为止(该步骤也被称为再同步)
- 如果在 error 之后能成功移入三个符号,则继续正常的语法分析;否则,返回前面的步骤二。
- 我们需要在语法里指定 error 符号应该放到哪里
- 一般把 error 放在例如行尾、括号结尾等地方,本质上相当于让行结束符“;”以及括号“{”、“}”、“(”、“)”等作为错误恢复的同步符号:
Stmt → error SEMI CompSt → error RC Exp → error RP
- 一般把 error 放在例如行尾、括号结尾等地方,本质上相当于让行结束符“;”以及括号“{”、“}”、“(”、“)”等作为错误恢复的同步符号:
- 一个简单实现, 在遇到
;)}时消除错误
实验二:语义分析¶
- 目的:进行"上下文相关分析",分析语法正确的程序是否语义正确(如使用的变量是否是作用域内定义过的)
符号表的设计¶
- 记录源程序中各种标识符在编译过程中特性信息。
- 标识符包括:程序名、过程名、函数名、用户定义类型名、变量名、常量名、枚举值名、标号名等。
-
特性信息包括:上述标识符的种类、具体类型、维数、参数个数、数值及目标地址(存储单元地址)等编译过程中的关键信息。
-
符号表也称为环境(Environment),其核心作用是通过标识符映射获得其在编译过程中所需要记录的类型与存储位置等信息。
- 每当遇到语法单元 ExtDef 或者 Def,就说明该节点的子节点们包含了变量或者函数的定义信息,这时候应当将这些信息通过对子节点们的遍历提炼出来并插入到符号表里。
-
每当遇到语法单元 Exp,说明该节点及其子节点们会对变量或者函数进行使用,这个时候应当查符号表以确认这些变量或者函数是否存在以及它们的类型是什么。
-
操作分为填表和查表
- 填表:当分析到程序中的说明或定义语句时, 应将说明或定义的名字,以及与之有关的特性信息填入符号表中
- 可以将程序中出现的所有符号组织成一张表,也可以将不同种类的符号组织成不同的表
- 可以针对每个语句块、每个结构体都新建一张表,也可以将所有语句块中出现的符号全部插入到同一张表中。
- 查表:检查是够重定义、类型是否一致等
- 填表:当分析到程序中的说明或定义语句时, 应将说明或定义的名字,以及与之有关的特性信息填入符号表中
- 使用数据结构
- 链表
- 哈希表
- 平衡搜索树

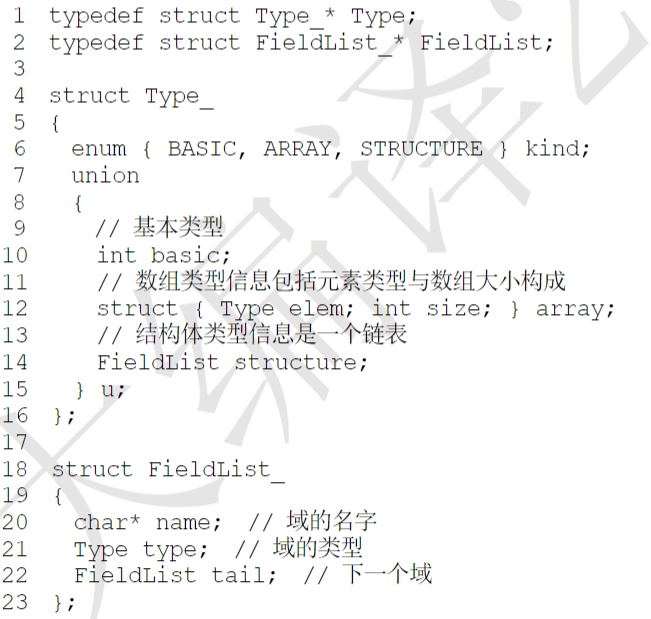
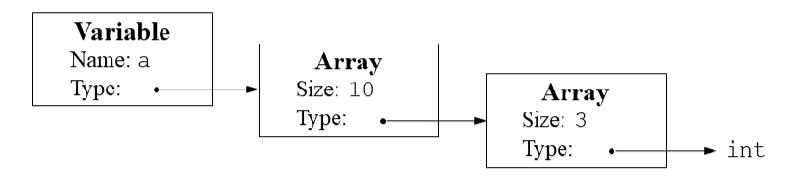
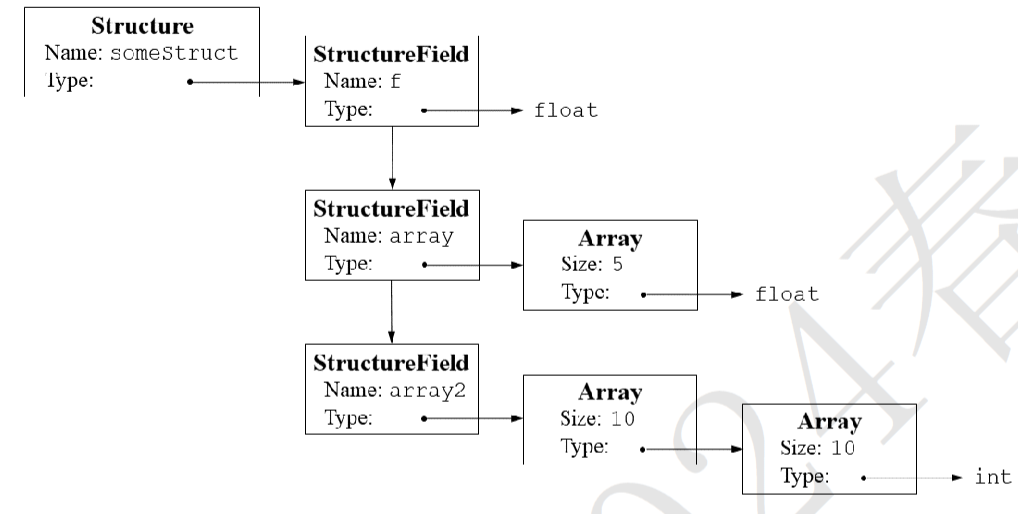
类型表示¶
- 使用链表表示类型
- 三种节点:结构体、数组、标准类型
- 使用链表组合表示
- int a[10][3]
- struct SomeStruct { float f; float array[5]; int array 2[10][10]; }
任务¶
- 需要对语法树进行遍历以进行符号表的相关操作以及类型的构造与检查。
要求¶



提示¶
- 可以只从语法层面来检查左值错误:赋值号左边能出现的只有 ID、Exp LB、Exp RB 以及 Exp DOT ID,而不能是其它形式的语法单元组合。
- 只要数组的基类型和维数相同我们即认为类型是匹配的,例如 int a[10][2]和 int b[5][3]即属于同一类型
- 结构体间的类型等价机制采用名等价,每个匿名的结构体类型我们认为均具有一个独有的隐藏名字,以此进行名等价判定。