运行时刻环境
- 静态分配:编译器在编译时刻就可以做出存储分配决定,不需要考虑运行时刻的情形(全局变量、常量)
-
动态分配:
- 栈存储:过程的调用/返回同步进行分配和回收,值的生命期与过程生命期相同
- 堆存储:数据对象比创建它的过程调用更长寿;手工创建,可以使用垃圾回收机制管理
-
存储组织方式
- 静态区:内存分配在程序加载时完成,内存释放在程序结束时进行。用于存储静态分配的全局变量和静态变量,生命周期贯穿程序整个运行期。灵活性差
- 堆区:用于动态内存分配,内存块在运行时手动分配和释放。容易产生碎片,分配释放效率低。
- 栈区:内存分配和释放由编译器自动进行,函数调用和返回时自动管理。管理简单速度较快,但是空间有限容易溢出。
栈式分配¶
-
过程调用在时间上总是嵌套关系,因此适合使用栈来分配内存空间
-
活动树
- 表示运行期间的所有过程活动,每个节点对应一个活动,根节点对应 main
- 子节点表示活动内的过程调用,从左到右为先后顺序

函数调用与活动记录¶
- 活动记录
- 过程调用和返回由控制栈进行管理,每个活跃的活动对应于栈中的一个活动记录
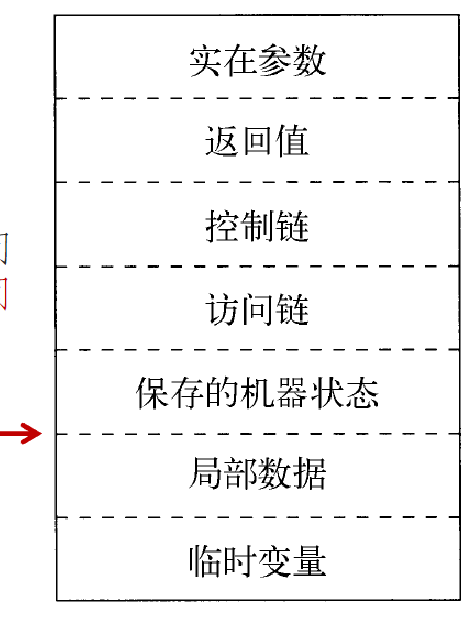
- 控制链:用于跟踪函数调用顺序的结构,主要目的是在多个函数调用时保持函数的调用和返回顺序正确。
- 当一个函数调用另一个函数时,当前函数的环境会被保存在控制链上。当被调用的函数执行完毕后,通过控制链恢复调用者的环境。
- 控制链是一个动态链:根据函数调用关系来生成,栈上的活动记录通过动态链维护调用关系
- 访问链:解决作用域的问题,尤其是在有嵌套函数的情况下
- 通过在每个函数的环境记录中保存一个指向外围作用域的链接,从而构建起一个作用域链,使得内部函数可以访问到外部函数的变量。
- 访问链是一个静态链:编译时确定,由函数声明的层次关系来决定(具体见下面变量访问)
- 机器状态:寄存器等信息
- 局部数据:这指的是在函数内部声明的变量,只在该函数的作用域内部有效。这些数据在函数调用时创建,在函数结束时销毁。
- 临时变量:在函数执行过程中用于存储临时结果的变量。这些变量通常不是由用户直接定义的,而是由编译器在编译过程中生成的。
-
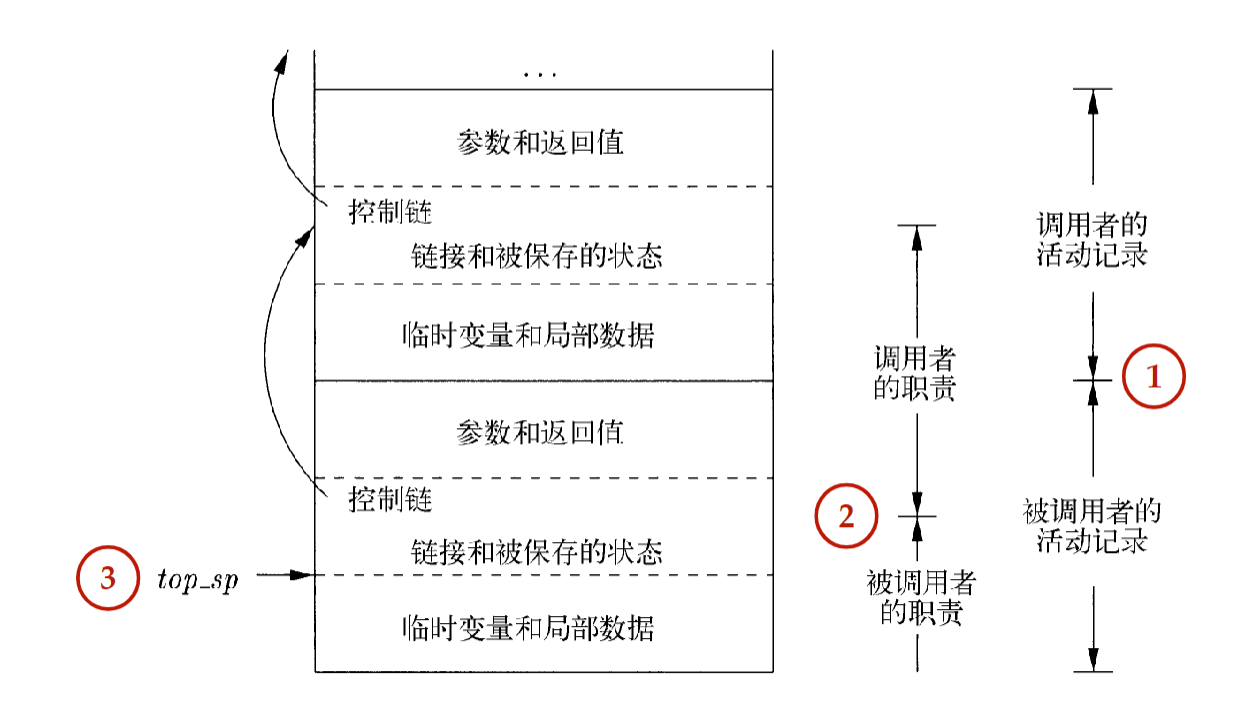
布局原则:
- 调用者和被调用者之间传递的值放在被调用者活动记录的开始位置
- 固定长度的项放在中间位置
- 早期不知道大小的项在活动记录尾部
- 栈顶指针 (top_sp) 通常指向固定长度字段的末端(局部数据之前的位置)
- 这就是栈内存中的实际布局,从上到下依次为:实参-返回值-控制链(指向调用者的指针)-访问链-机器状态-局部数据-临时变量 docs/学校课程/课程/编译原理/作业/p9#^9e9e3e|7.2.4
-
调用代码序列:活动记录分配空间,填写记录中的信息
- 调用代码序列会分割到调用者和被调用者中(把代码尽可能放在被调用者中, 多次调用时可以让代码更短,避免重复)
- 调用者计算实在参数的值
- 将返回地址和原 top_sp 存放到被调用者的活动记录中;调用者增加 top_sp 的值 (越过了调用者的局部数据和临时变量、以及被调用者的参数和机器状态字段)
- 被调用者保存寄存器值和其它状态字段
- 被调用者初始化局部数据,开始运行
- 返回代码序列:恢复机器状态,使调用者继续运行
- 被调用者将返回值放到与参数相邻的位置
- 被调用者恢复 top_sp 和其它寄存器,跳转到返回地址
-
-
栈中的变长数据
- 如局部变长数组要分配在栈里,使用间接分配,这样数组的起点(指针)固定(可以编译时确定),方便进行访问
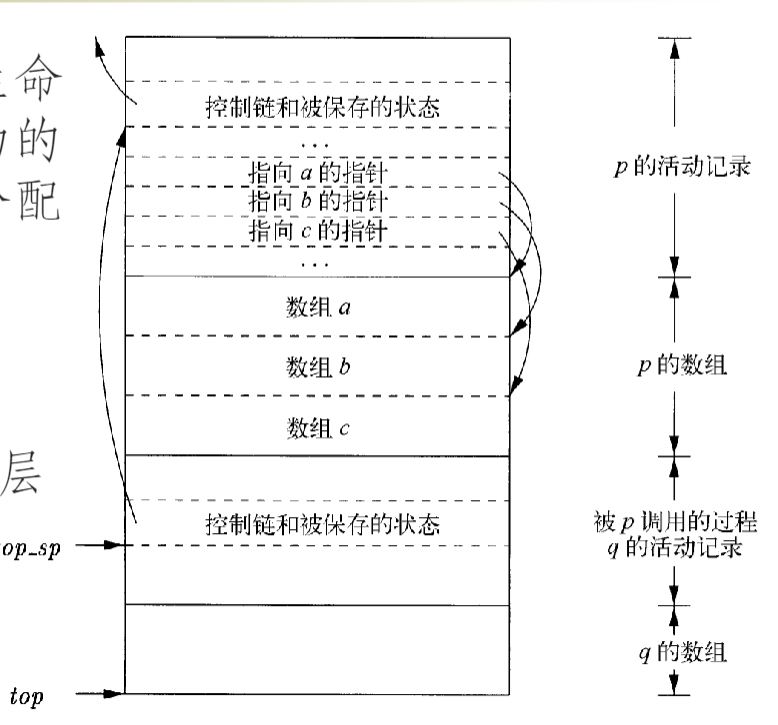
- top 指向实际栈顶;top_sp 用于寻找上层记录的定长字段
变量的访问¶
-
无嵌套过程的局部数据的访问
- 函数自身的局部变量:相对地址已知,存放在当前活动记录内,通过 \(top\_sp\) 指针加上相对地址进行访问
- 全局变量:在静态区,地址在编译时刻可知
-
有嵌套过程
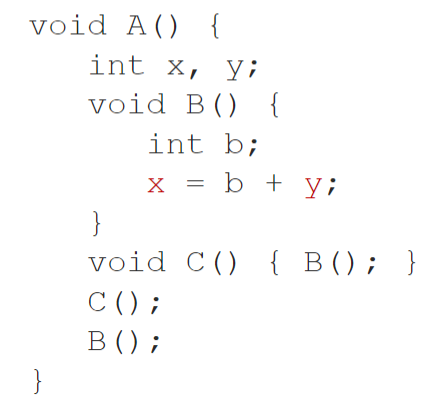
- B 内可以访问 A 的变量,需要通过访问链进行
- 嵌套深度:每嵌套一层加 1;不内嵌于任何其他过程的深度为 1(这里指的是静态声明嵌套而不是递归调用)

- 如果过程 p 在声明时直接嵌套在过程 q 中,那么 p 活动记录中的访问链指向上层最近的 q 的活动记录
- 这就形成了一个链路,嵌套深度沿着链路逐一递减
- 假设深度 \(n_{p}\) 的过程访问深度 \(n_{q}\) 的变量 \(x\),上跳的次数(偏移量)在编译时刻已知 \(n_{p}-n_{q}\) ,这样就可以通过偏移量进行访问(就像无嵌套那样)
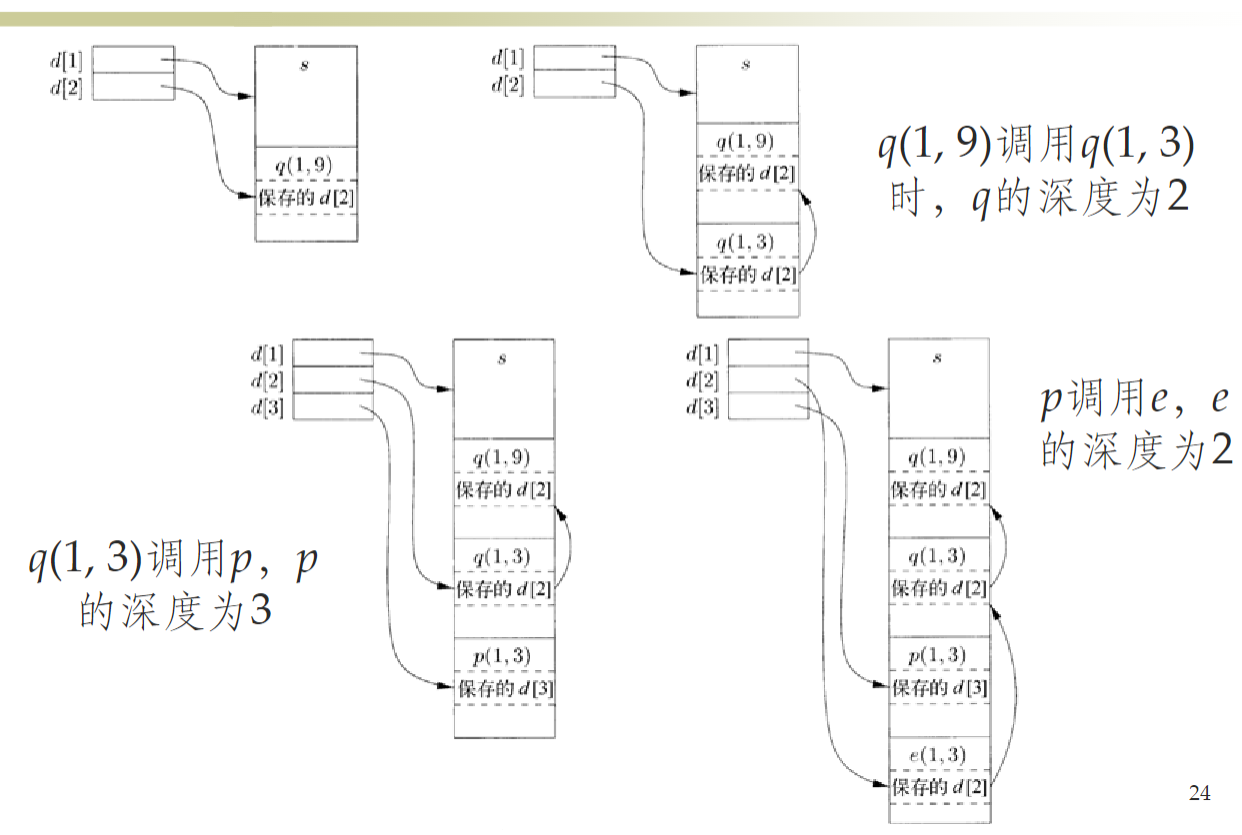
- 访问链的维护:过程 q 调用过程 p 时( \(n_{p}\) 和 \(n_{q}\) )
- \(n_{p}>n_{q}\):\(p\) 在 \(q\) 中直接定义, p 的访问链指向当前活动记录 (即 q),如 sort 调用 quicksort (1, 9)
- \(n_{p}=n_{q}\):新活动记录的访问链等于当前记录的访问链, 如 quicksort (1, 9)调用 quicksort (1, 3)
- \(n_{p}<n_{q}\):有过程 r,p 直接在 r 中定义,而 q 嵌套在 r 中;p 的访问链指向栈中 r 的活动记录,如 partition 调用 exchange

- 显示表
- 用访问链访问数据,访问开销与嵌套深度差有关;使用显示表可以提高效率,访问开销为常量
- 为每个嵌套深度保留一个指针,指针 d[i] 指向栈中最近的、嵌套深度为 i 的活动记录(i 在编译时就已知)
- 维护方式:在调用 \(p\) 的过程就是嵌套深度从小到大的一个过程,在这个过程中就能填入 \(d[i]\)(如在 \(p\) 处填入 \(d[n_{p}]\)), 返回时恢复值(这是因为深度并不是单调递增的)(如果一个深度有多个,则用链表串起来)
堆式分配¶
-
用于存放生命周期不确定、或生存到被明确删除为止的数据对象
-
(堆)存储管理器:
- 负责分配、回收堆空间的子系统
- 分配:为内存请求分配一段连续、适当大小的堆空间(必要时向操作系统为堆申请空间)
- 回收:把被回收的空间返回空闲空间缓冲池,以满足其它内存需求
- 评价:
- 空间效率:减少内存碎片,使需要的堆空间最小
- 程序运行效率(低开销)
- 碎片问题
- 随着程序分配/回收内存,堆区逐渐被割裂成为若干空闲存储块 (窗口) 和已用存储块的交错
- 通常是把一个窗口的一部分分配出去,其余部分成为更小的块
- 因此回收时应该把连续的窗口接合成为更大的窗口
- 分配方法
- Best-Fit:总是将请求的内存分配在满足请求的最小的窗口中(可以将大的窗口保留下来,应对更大的请求)
- First-Fit:总是将对象放置在第一个能够容纳请求的窗口中,速度较快但是性能较差,此外有较好的数据局部性
-
使用容器的管理方法
- 预设不同容器,每个容器中有很多相同大小的块(可以为不同容器分配不同大小的块)
- 较小的块使用的较多,通常设置较多的容器
- GUN 中使用的存储管理器 Lea:

-
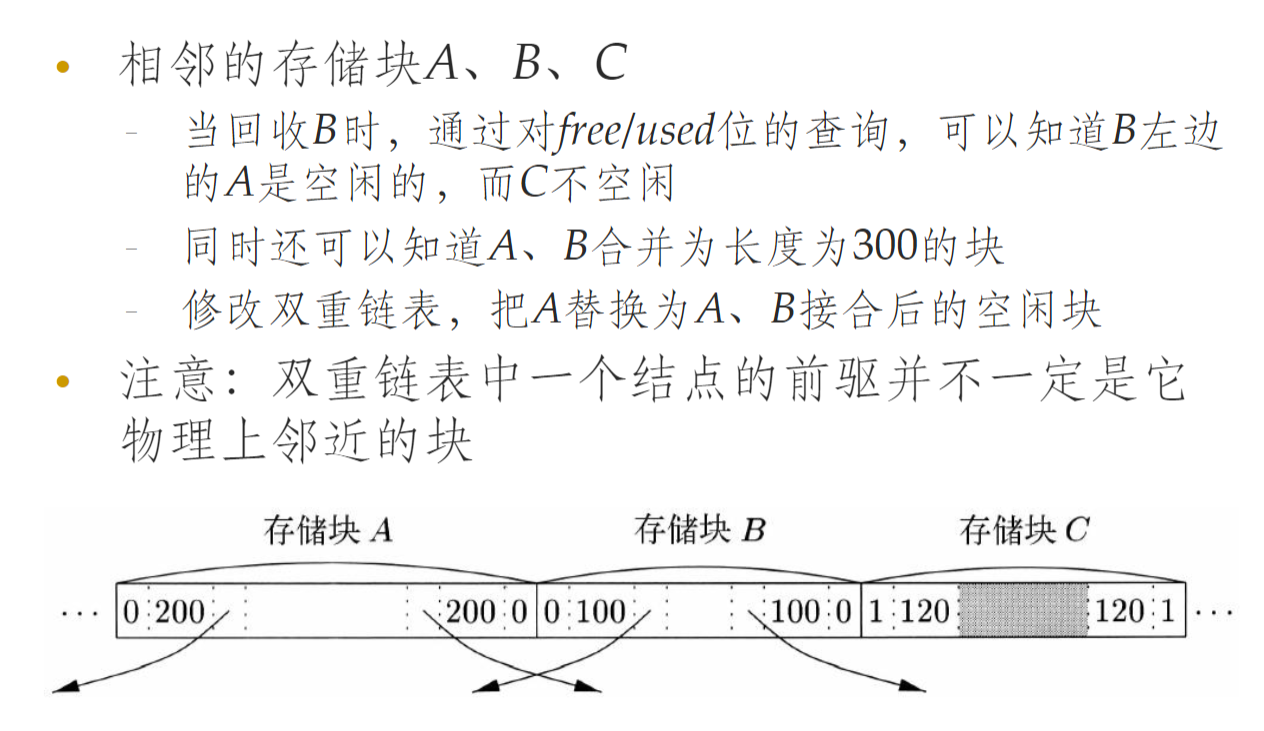
合并碎片内存
- 设置边界标记,表示块两侧是否空闲(即是否可以进行合并)
- 使用双重链表表示空闲块,方便进行合并操作
垃圾回收机制¶
- 垃圾:不需要再被引用(使用)的数据
- 垃圾回收:自动回收不可达数据的机制
-
设计目标:
- 语言必须类型安全:保证回收器能够知道数据元素是否为一个指向某内存块的指针
- 不显著增加应用程序的总运行时间
- 当垃圾回收机制启动时,可能引起应用程序的停顿,这个停顿应该比较短
- 最大限度地利用可用内存,避免内存碎片
- 改善空间局部性和时间局部性
-
可达性:一个存储块可以被程序访问到
- 根集:不需要指针解引用就可以直接访问的数据(如局部变量等),根集的成员都是可达的
- 对于任意一个对象,如果指向它的一个指针被保存在可达对象的某字段或数组元素中,那么这个对象也是可达的
-
改变可达性的操作
- 创建新对象
- 参数传递,返回值
- 引用赋值(被赋值变量原先引用的对象丢失,变为不可达)
- 过程返回:局部变量释放,根集减小
-
基于引用计数的垃圾回收:每个对象有一个用于存放引用计数的字段
- 对象分配:引用计数设为 1
- 参数传递:引用计数加 1
- 引用赋值:u = v,u 指向的对象引用减 1,v 指向的对象引用加1
- 过程返回:局部变量指向对象的引用计数减 1
-
如果一个对象的引用计数为 0,就要进行垃圾回收(修改计数后总是考虑是否释放)。在删除对象之前,此对象中各个指针所指对象的引用计数减 1
- 开销较大,但不会引起停顿,也能及时回收垃圾
- 存在循环引用问题
-
基于跟踪的垃圾回收:不在垃圾产生时回收,而是周期性地运行
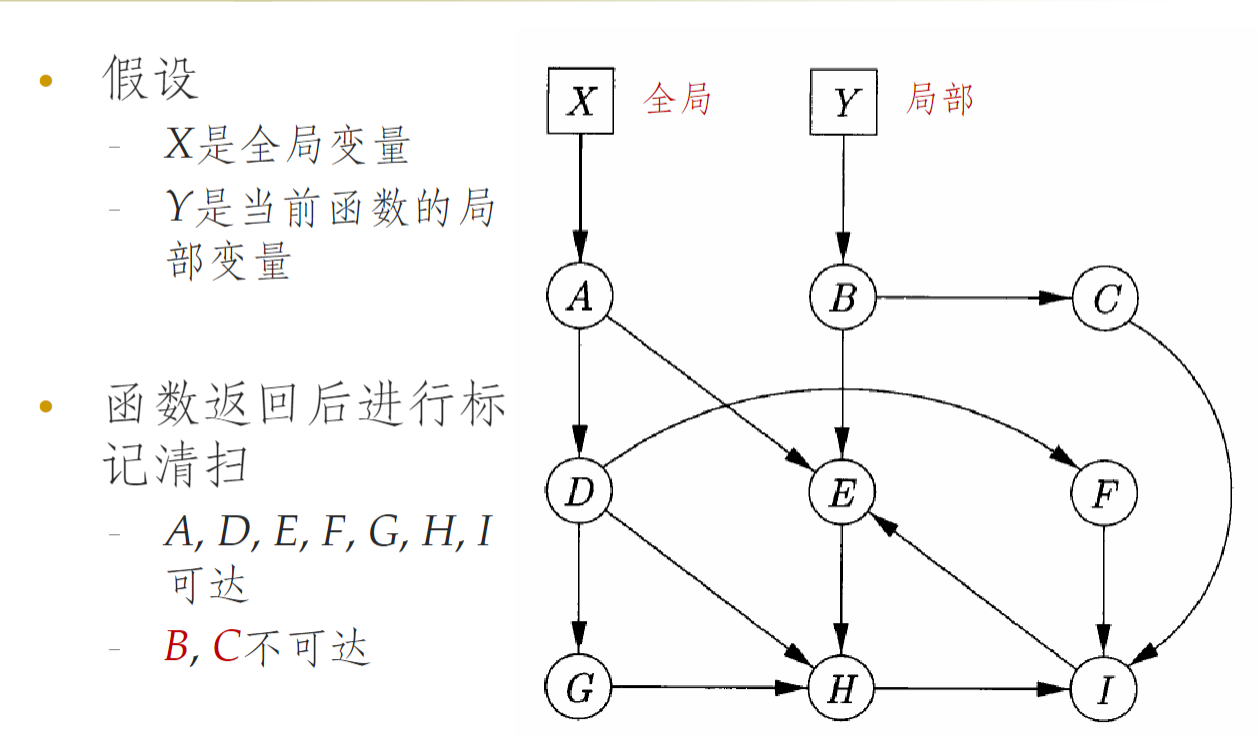
- 标记-清扫式垃圾回收
- 先标记,从根集除法,跟踪并标记出所有可达对象;然后进行清扫,释放所有不可达对象
- 是一种直接全面停顿的算法
- 标记并压缩垃圾回收
- 把可达对象移动到堆区的一端,另一端则是空闲空间,即空闲空间合并成单一块(合并碎片空间)
- 标记-计算新位置-移动
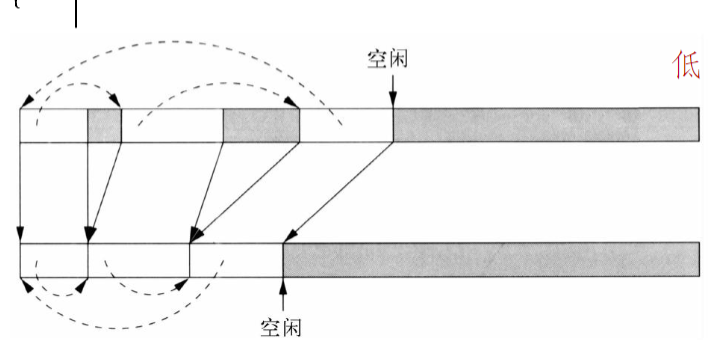
- 拷贝垃圾回收
- 堆空间被分为两个半空间,应用程序在某个半空间内分配存储,当充满这个半空间时,开始垃圾回收
- 回收时,可达对象被拷贝到另一个半空间
- 回收完成后,两个半空间角色对调 docs/学校课程/课程/编译原理/作业/p10#^3ab4c9|7.5.2&7.6.1