补充¶
- make之前要先进入pa_nju文件夹
- 先make clean再进行测试
- 提交:
make submit_paxx
pa1¶
内存模拟¶

- 使用一个数组来模拟内存(多层读取,在PA3-2涉及)
uint8_t hw_mem[MEM_SIZE_B];
uint32_t hw_mem_read(paddr_t paddr, size_t len) {
uint32_t ret = 0;
memcpy(&ret, hw_mem + paddr, len);
return ret;
}
uint32_t paddr_read(paddr_t paddr, size_t len) {
uint32_t ret = 0;
ret = hw_mem_read(paddr, len);
return ret;
}
uint32_t laddr_read(laddr_t laddr, size_t len) {
return paddr_read(laddr, len);
}
uint32_t vaddr_read(vaddr_t vaddr, uint8_t sreg, size_t len) {
assert(len == 1 || len == 2 || len == 4);
return laddr_read(vaddr, len);
}
寄存器模拟¶
-
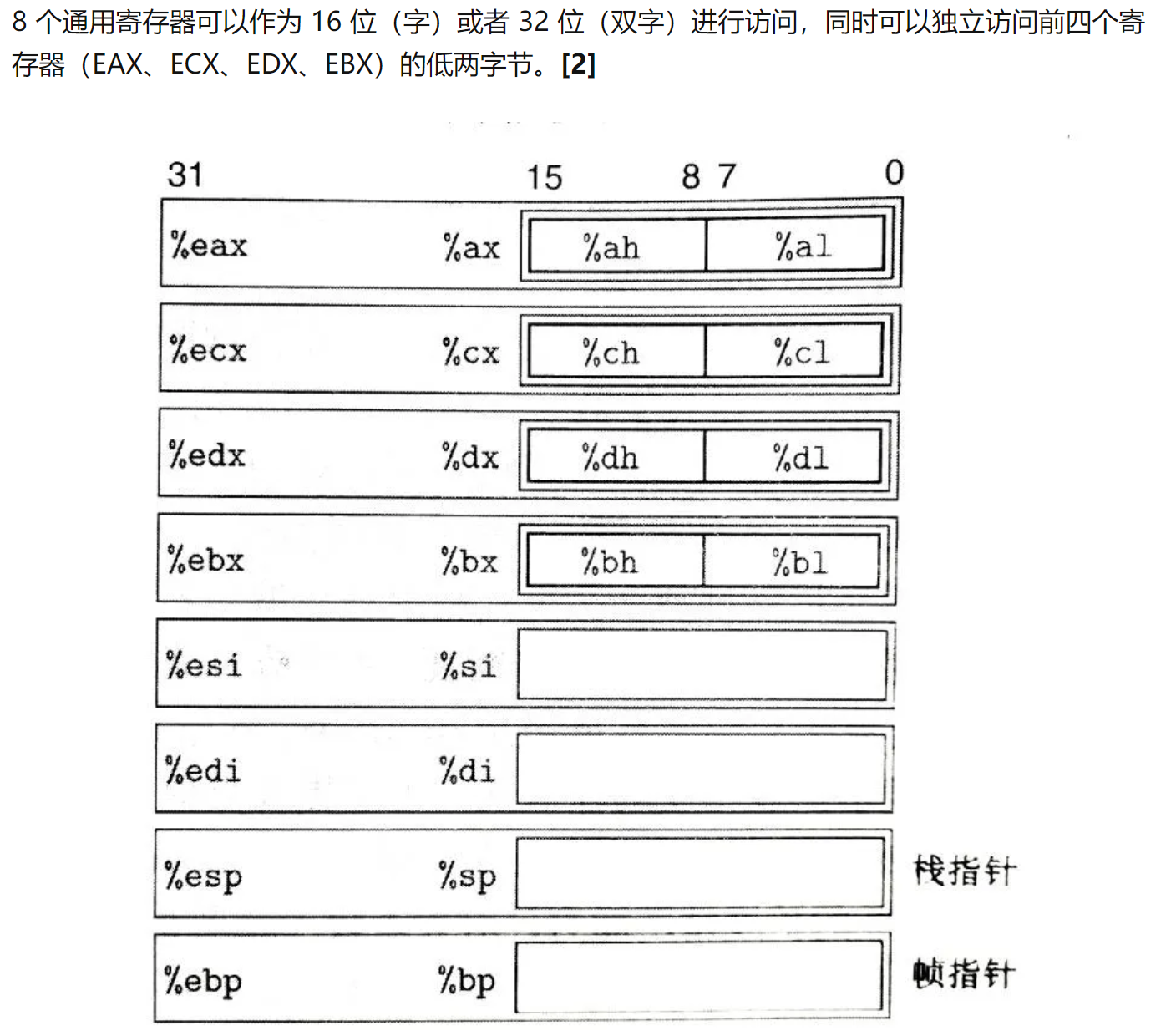
-
数据结构
-
c typedef struct { union { union { union {//前4行寄存器,润许不同方式访问位于不同位置的元素 uint32_t _32; uint16_t _16; uint8_t _8[2]; }; uint32_t val;//寄存器32位的总值 } gpr[8]; struct { uint32_t eax, ecx, edx, ebx, esp, ebp, esi, edi;}; //每个变量对应32位空间,正好对应上面的区域划分,使用union类型实现了对不同位置数据的读写 }; … } CPU_STATE;
整数运算和表示¶
- 返回结果,并设置标志位
- 结果不足32位时高位补0
uint32_t alu_add(uint32_t src, uint32_t dest, size_t data_size) {//表示参与运算的两个数,以及操作数的长度(8,16,32)
printf("\e[0;31mPlease implement me at alu.c\e[0m\n"); assert(0);
return 0;
}
- 有关ADD指令的描述 261(找到i386⼿册Sec. 17.2.2.11),看Flags Affected: OF, SF, ZF, AF, CF, and PF as described in Appendix C(AF不模拟)
- 例
uint32_t alu_add(uint32_t src, uint32_t dest, size_t data_size) {
uint32_t res = 0;
res = dest + src;
// 获取计算结果
set_CF_add(res, src, data_size); // 设置标志位 set_PF(res); // set_AF();
// 我们不模拟AF
set_ZF(res, data_size);
set_SF(res, data_size);
set_OF_add(res, src, dest, data_size);
return res & (0xFFFFFFFF >> (32 - data_size)); // ⾼位清零并返回
}
标志位的判断¶
-
对cpu中eflags寄存器的访问 i386⼿册 sec 2.3.4.1
-
OF,SF,ZF,CF,PF
-

-
CF(进位标志) =1 算术操作最高位产生了进位或借位 =0 最高位无进位或借位 ;
c void set_CF_add(uint32_t result, uint32_t src, size_t data_size) { result = sign_ext(result & (0xFFFFFFFF >> (32 - data_size)), data_size); src = sign_ext(src & (0xFFFFFFFF >> (32 - data_size)), data_size);//先规格化数据,高位置0 cpu.eflags.CF = result < src; //直接cpu.eflags对成员函数进行赋值 }
-
PF(奇偶标志) =1 数据最低8位中1的个数为偶数; =0 数据最低8位中1的个数为奇数;
-
ZF(零标志) =1 操作结果为0 =0 结果不为0;
c void set_ZF(uint32_t result, size_t data_size) { result = result & (0xFFFFFFFF >> (32 - data_size)); cpu.eflags.ZF = (result == 0); }
-
SF(符号标志) =1 结果最高位为1 =0 结果最高位为0;
c void set_SF(uint32_t result, size_t data_size) { result = sign_ext(result & (0xFFFFFFFF >> (32 - data_size)), data_size); cSFpu.eflags.SF = sign(result);//alu.h定义,返回标志位 }
-
OF(溢出标志) =1 此次运算发生了溢出 =0 无溢出。
-
++->-,--->+发生变号
-
c if(sign(src) == sign(dest)) { if(sign(src) != sign(result)) cpu.eflags.OF = 1; else cpu.eflags.OF = 0; } else { cpu.eflags.OF= 0; }
-
浮点数的运算和表示¶
-
浮点数表示结构
-
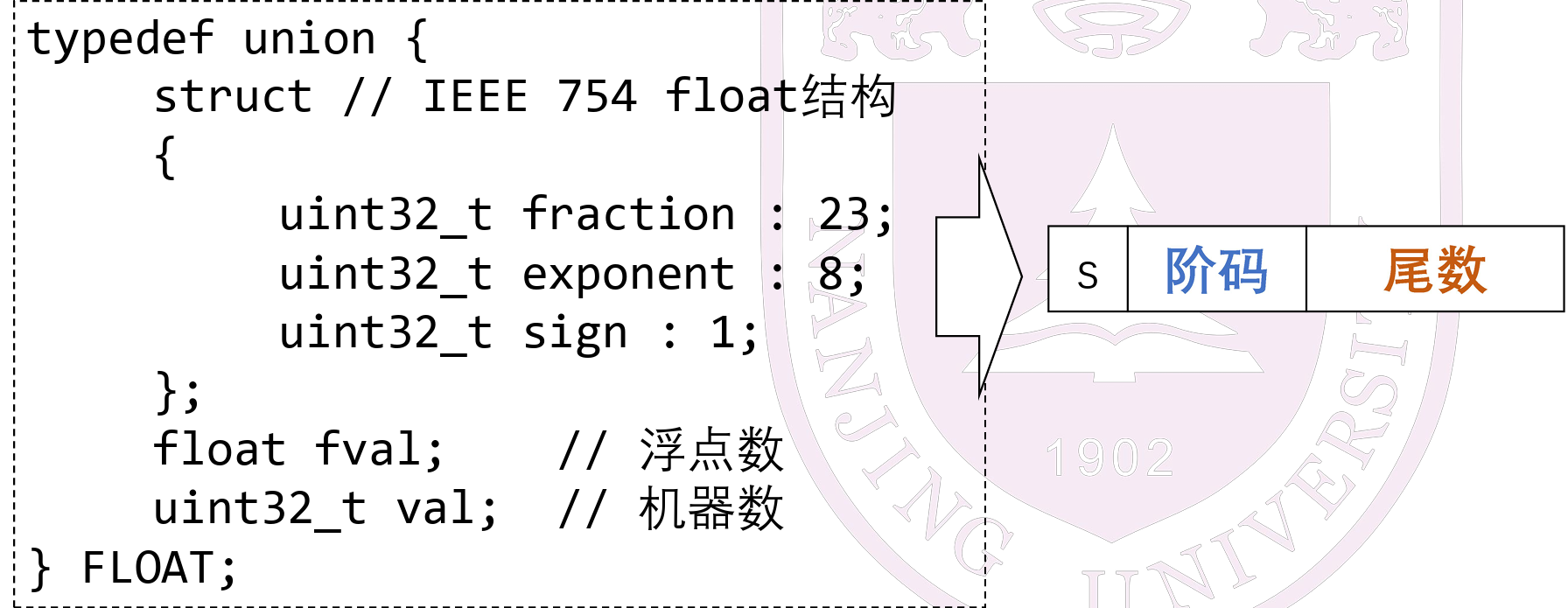
加减法¶
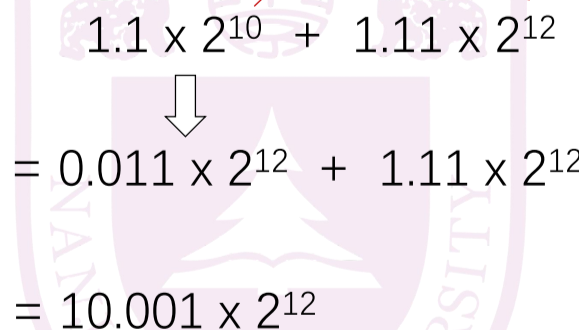
-

-
过程:
- 提取符号、阶码、尾数
- 整数运算得到中间结果
- 对阶:小阶向大阶看齐 小阶增加至大阶,同时尾数 右移,保证对应真值不变
- 对接过程中需要移位,而移位会造成精度损失,因此使用保护位提高精度(先向左移3位,会破坏阶数,不过已经提取保存了)

- 尾数相加(相减)
- 舍入并规格化后返回(加减法中一定有exp>0)

- sig_grs>>26=1,说明刚好剩下的是23+3位
- 阶码上溢变无穷

- 额外移动一次是因为exp=0是是-126而不是-127,所以要纠正

- 舍入规则:
- 如果
G = 0,向下舍入(什么都不做) - 如果
G = 1,RS == 10或RS == 01或1,向上舍入(向尾数添加一个) - if
GSR = 111,round to even - 舍入若产生尾数加1,有可能出现破坏规格化的情况 •,此时需要进行额外的一次右规并判断阶码上溢的情况
- 如果
乘除法¶
- 乘法:尾数相乘,阶码相加
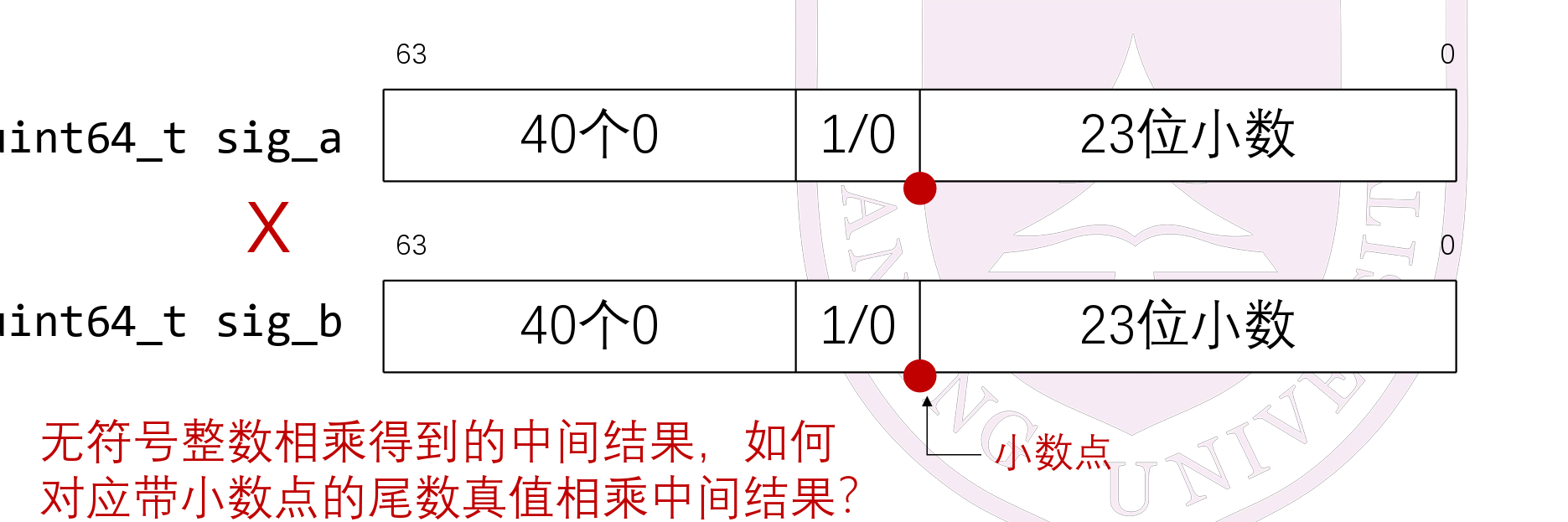
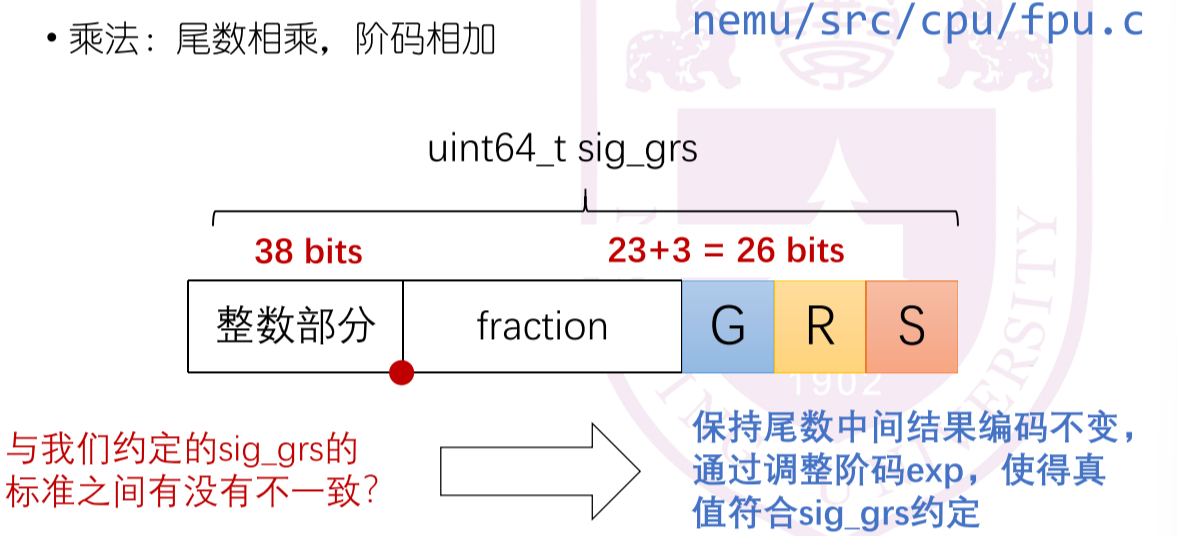
- 与约定的26位小数相比,得到的是46位小数,要对exp-20进行修正
- 除法:尾数相除,阶码相减

-
同样由于不一定是26位小数,要通过对exp修正
-

pa2¶
预备知识¶
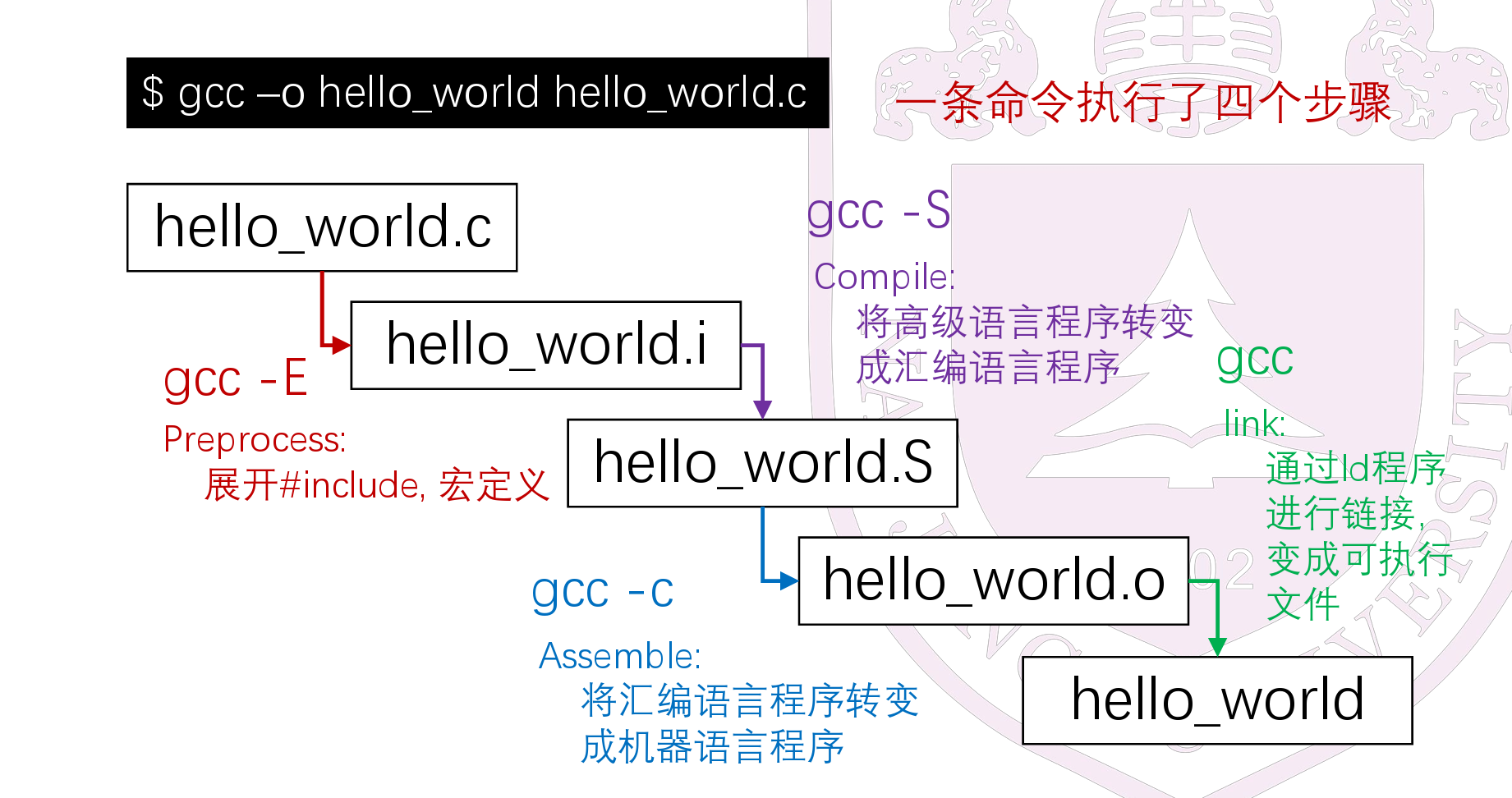
从高级语言到机器指令¶
linux操作¶
-
shell $ gcc –E –o hello_world.i hello_world.c $ cat hello_world.i | less -
shell $ gcc –S –o hello_world.S hello_world.i $ cat hello_world.S | less -
shell $ gcc –c –o hello_world.o hello_world.S $ hexdump hello_world.o | less -
shell $ gcc –c –o hello_world.o hello_world.S $ objdump -d hello_world.o | less -
反汇编,nemu中使用
objdump4nemu-i386 -

汇编语言编程¶
-
过程:

-
``` .data//数据 (符号,相当于全局变量名)hello_str: .ascii(类型) “Hello World!\n”(初始值) .text//代码 .globl main main: movl $4, %eax movl $1, %ebx movl $hello_str, %ecx movl $13, %edx int $0x80
```
gdb调试¶
-
安装gdb调试器:sudo apt-get install gdb
-
调试某程序:gdb <程序名>
- gdb是linux内置的调试器(控制nemu的执行)
-
monitor是nemu设计的内置调试器(nemu控制testcase等程序的运行)
-
-
monitor
-
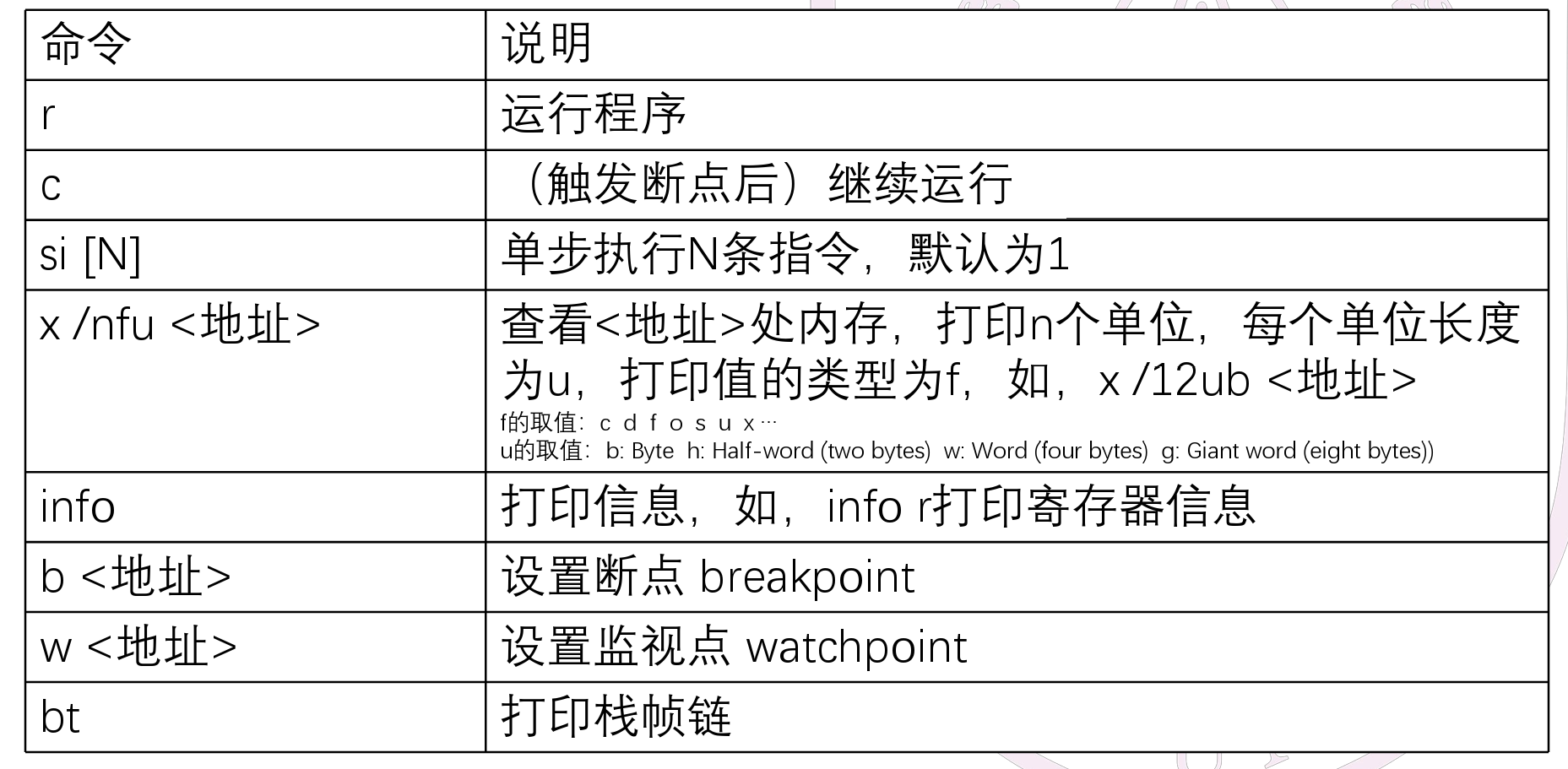
命令 格式 使用举例 说明 帮助 Help help 打印帮助信息 继续运行 C c 继续运行被暂停的程序 退出 Q q 退出当前正在运行的程序 单步执行 si [N] si 10 单步执行N条指令,N缺省为1 打印程序状态 info info r info w 打印寄存器状态 打印监视点信息 * 表达式求值 p EXPR p $eax + 1 求出表达式EXPR的值(EXPR中可以出现数字,0x开头的十六进制数字,$开头的寄存器,*开头的指针解引用,括号对,和算术运算符) * 扫描内存 x N EXPR x 10 0x10000 以表达式EXPR的值为起始地址,以十六进制形式连续输出N个4字节 * 设置监视点 w EXPR w *0x2000 当表达式EXPR的值发生变化时,暂停程序运行 * 设置断点 b EXPR b main 在EXPR处设置断点。除此以外,框架代码还提供了宏BREAK_POINT,可以插入到用户程序中,起到断点的作用 删除监视点或断点 d N d 2 删除第N号监视点或断点
linux命令¶
-
程序执行过程(以testcase中的add为例)
-
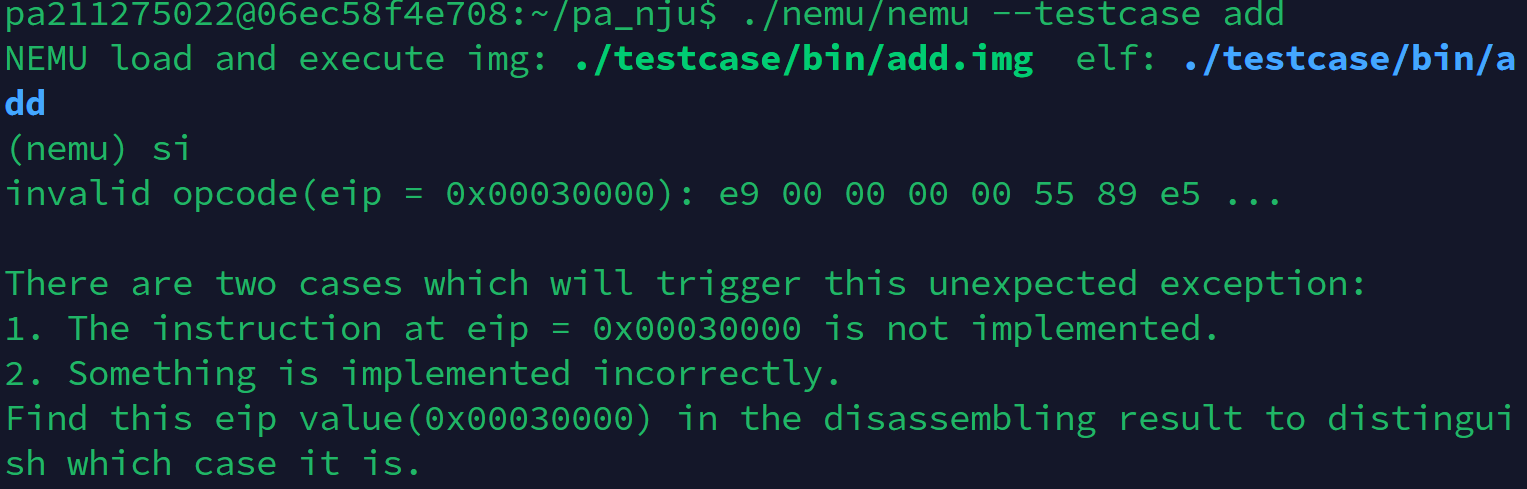
shell make//编译 cd pa_nju//进入文件夹 ./nemu/nemu --autorun --testcase add ./nemu/nemu --testcase add//使用monitor调试 //反汇编 调试过程中报错的程序进行检查,需要先进入testcase文件夹 ./objdump4nemu-i386 -d ./bin/add [|less(进入类似vim的界面,便于进行查看,使用方向键翻页,/进行搜索)] -
-
执行程序后会显示错误的文件以及错误命令的eip,也可以对文件进行反汇编,然后再在文件中查找指定的eip确定发生了错误的指令
-
也可以通过MakeFile中配置好的进行执行(run和debug两个模块)
-
tongguo
make runmake debug执行
2-1¶
- 执行make run(单独指定测试执行)或者make test_pa-2-1运行PA 2-1任务
- 程序将要执行的二进制文件指令拷贝到绿色区域,eip指向0x30000逐渐读取,向右开始执行指令
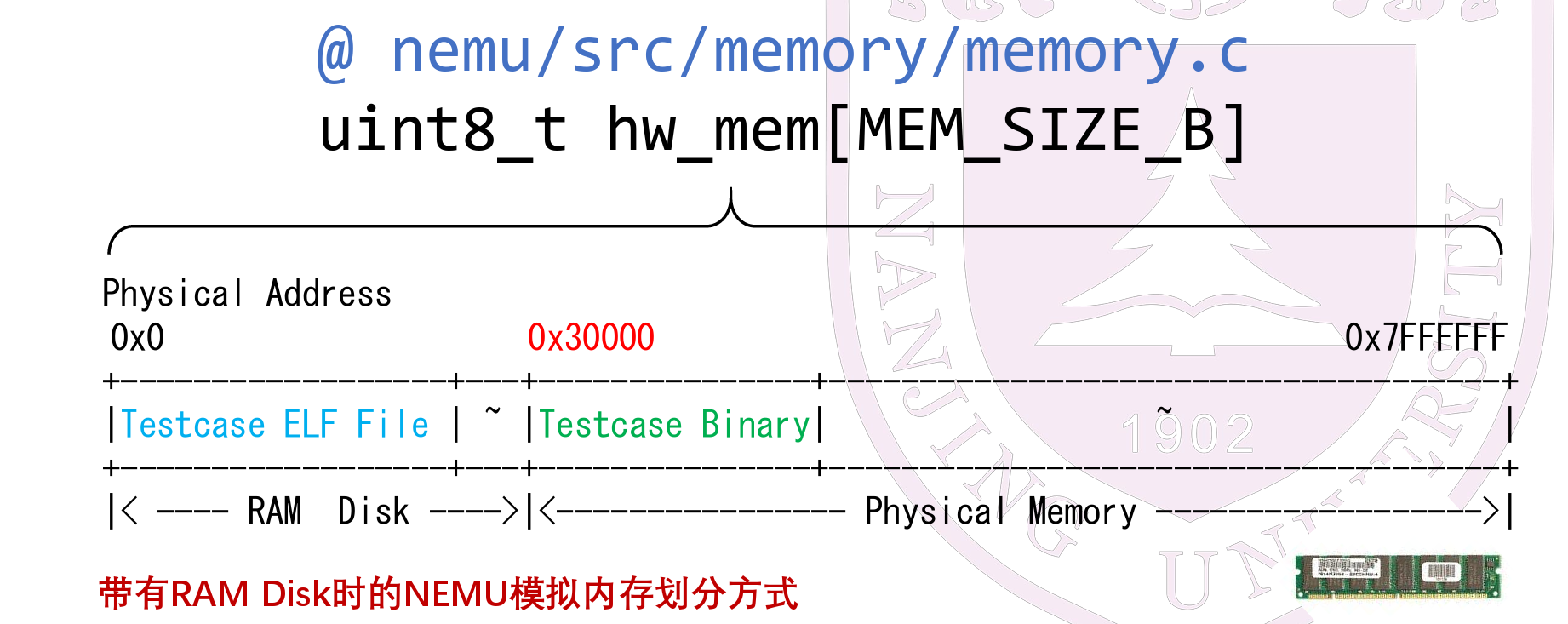
- 栈从0x7FFFFFF开始生长


- 操作码(
opcode),它指出指令对应要执行的功能是什么; - 前缀中只考虑操作数长度(
operand-size):如0x66前缀表示指令是16位(否则位32位) - 0x0F表示双字节指令
- ModR/M辅助说明操作码的操作数(操作数的个数、种类[寄存器、内存地址、常量])
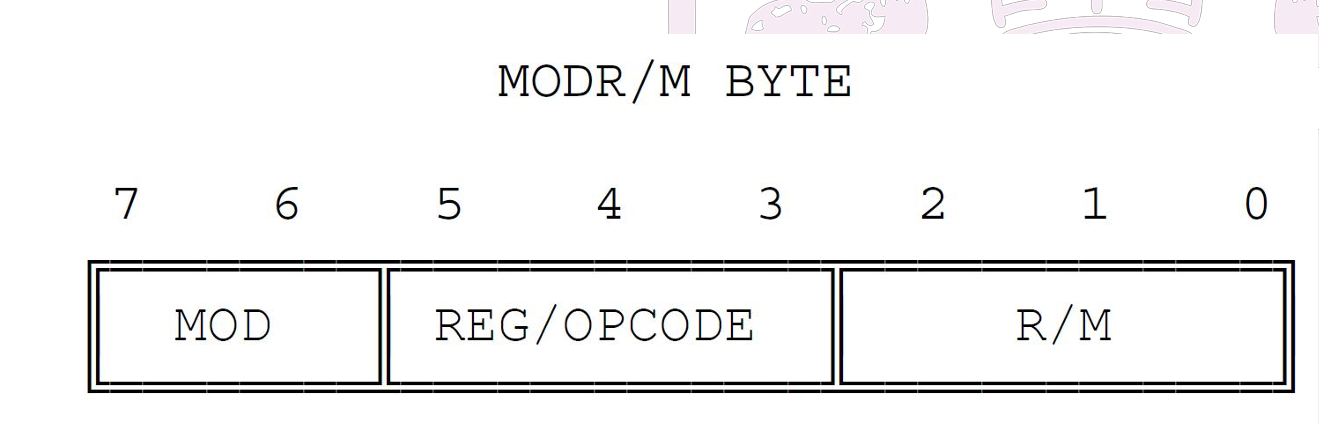
- 当opcode是一条group指令时,mord/m的中间部分是用于进一步确定是group中的那一条具体的指令
- p242 17.2.1
- SIB用来辅助说明ModR/M,辅助寻址
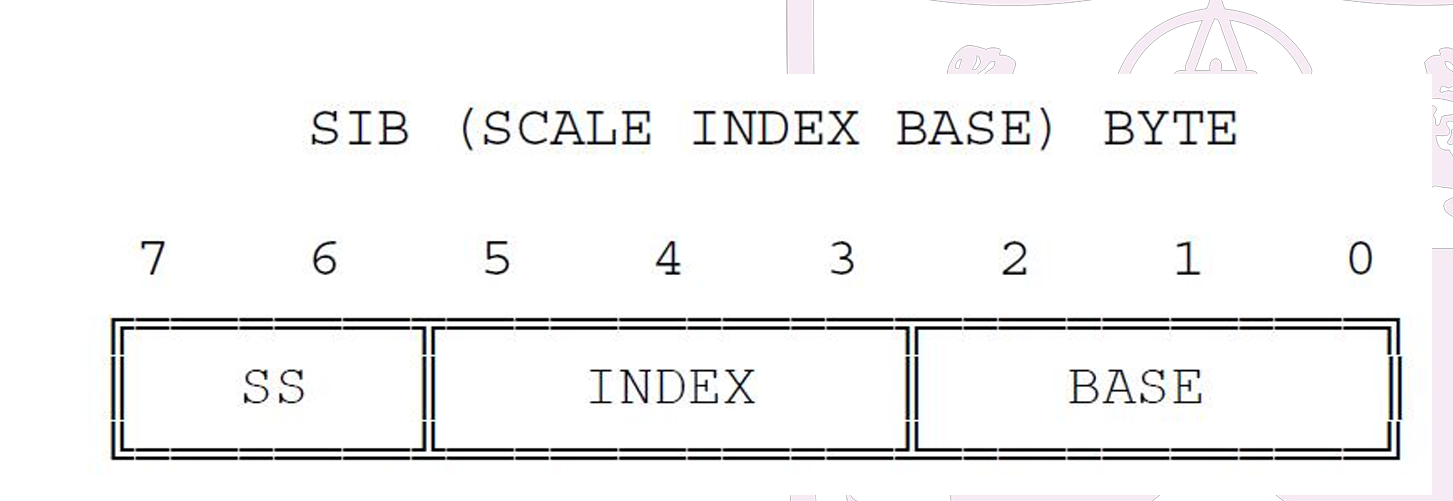
- p242 17.2.1
指令的执行¶
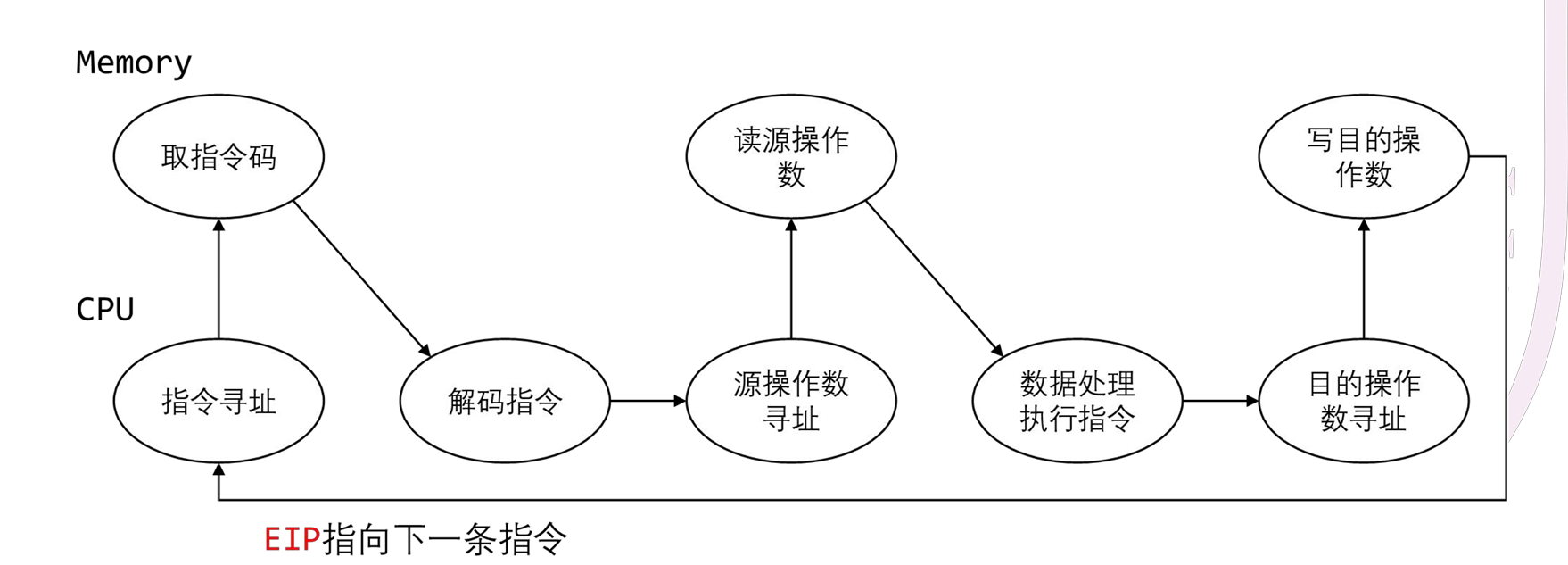
- 指令的执行过程 ¶
¶
- instr_fetch表示读取地址指定字节数目的内容(读取内存)

- 使用opcode_entry函数数组来执行对应指定id的指令
- 任务就是完成指令解析函数的设置,并将对应的函数填入到数组的指定位置
- 对于groupp类型,会自动跳转到group数组,将函数填入对应的group数组即可


- v表示长度会受到0x66前缀的影响
- 如
mov_i2rm_v 
辅助工具¶
可能需要的操作¶
-
拓展
-
32位:
sign_ext(uint32_t x, size_t data_size) -
64:
sign_ext_64(uint32_t x, size_t data_size) -
符号位设置
-
cpu.eflags.进行读取和设置 -
寄存器访问;
-
cpu.eax
OPERAND数据结构¶
-

-
封装操作数类型,包含操作数地址(范围与类型相关)、类型、内容、长度
-
opr->type 类型 与opr->addr构成的地址表示方式 OPR_MEMopr->addr中保存的是一个内存地址(位于数据段或栈段)OPR_IMMopr->addr中保存的是一个立即数的内存地址(位于代码段)OPR_REGopr->addr中保存的是一个通用寄存器的编号,随着opr->data_size的不同,其对应关系略有不同。参照nemu/include/cpu/reg.h中定义的enum数据结构。OPR_SREGopr->addr中保存的是一个段寄存器的编号,参照nemu/include/cpu/reg.h中定义的enum数据结构。(PA 3-2用到)OPR_CREGopr->addr中保存的是一个控制寄存器的编号CRx,x=0,1,2,3。(PA 3-2开始用到) -
针对
OPERAND,有两个主要的方法来封装操作数的读写操作,分别为:
void operand_read(OPERAND *opr);
void operand_write(OPERAND *opr);
这两个函数的作用分别是将地址为opr->addr的操作数的值从读到opr->val中,以及将opr->val写到地址opr->addr里。操作数的读写过程会根据操作数的类型(opr->type)来决定对应的寻址方式,并根据操作数的长度(opr->data_size)来决定最后读写的位数。
ModR/M字节的解析¶
int modrm_rm(uint32_t eip, OPERAND * rm);
int modrm_r_rm(uint32_t eip, OPERAND * r, OPERAND * rm);
//一下两个是需要通过modrm字节来确定操作码的情况
int modrm_opcode_rm(uint32_t eip, uint8_t * opcode, OPERAND * rm);
int modrm_opcode(uint32_t eip, uint8_t * opcode);
这四个函数分别对应指令希望通过解析ModR/M字节所获得的数据的四中不同类型组合,已涵盖实验中所涉及的所有指令。当指令的opcode确定时,就已经能够通过查阅手册确定:1) 是否需要解析ModR/M字节;2) 通过解析ModR/M字节应当获得什么操作数类型的信息。因此,在指令对应的函数实现中,根据需要调用上述四个函数中的一个即可。以上四个函数的返回值类型都为整型,其含义是为了完整解析ModR/M字节所包含的信息所一共扫描的字节个数,包含ModR/M字节本身,也包含后续可能出现的SIB字节和displacement字节。每个函数的第一个参数都为eip,其含义是ModR/M字节在内存中的地址,若当前eip指向opcode,则ModR/M字节的地址为eip + 1。
值得注意的是,这四个函数只负责对操作数的地址和类型进行填写,不会帮助我们完成操作数值的读写,因此在调用过后,不要忘记调用operand_read()或operand_write()函数。(知道了地址和类型就可以用read操作直接获取数值)
(会自动同时完成对sib字节的解析(如果有必要的话))
例¶
// 宏展开后这一行即为 int mov_i2rm_v(uint32_t eip, uint8_t opcode) {
make_instr_func(mov_i2rm_v) {
OP rm, imm;
rm.data_size = data_size; // 操作数长度,根据是否出现0x66前缀,可以是16或32,调用全局变量data_size获取
int len = 1; // opcode 长度1字节
len += modrm_rm(eip + 1, &rm); // 读ModR/M字节,rm的type和addr会被填写
imm.type = OPR_IMM; // 填入立即数类型
imm.addr = eip + len; // 找到立即数的地址
imm.sreg = SREG_CS; // 设置段寄存器,PA 3-2再涉及
imm.data_size = data_size; // 右侧的data_size为一个uint8_t类型全局变量
operand_read(&imm); // 执行 mov 操作
rm.val = imm.val;
operand_write(&rm);
return len + data_size / 8; // opcode长度 + ModR/M字节扫描长度 + 立即数长度
宏优化¶
- 基本流程:
- 指定源操作数和目的操作数的长度。该长度可以从指令名称中的操作数长度后缀来确定,
b就是8位;v就是data_size,表示由0x66前缀确定的位数;类似地还可以定义w和l后缀,分别代表16位和32位。 -
解码操作数地址。源操作数和目的操作数的类型也可以从指令名称中间的操作数类型部分来确定,如,
rm2r就是rm类型的源操作数mov到r类型的目的操作数。所有指令中的操作数类型有限,每种操作数解码地址的方法也都固定,比如遇到rm2r或r2rm类型,那必然使用modrm_r_rm()函数去解码地址; -
执行指令的数据操作。比如
mov指令就是做数据转移,add指令就是做加法等; -
返回指令长度。即指令
opcode本身1字节,再加上操作数地址解码过程中扫描过的字节数。 add、or、adc、sbb等许多指令都包含操作重复只有操作数类型和长度变化的情形。- 我们可以把源操作数和目的操作数对应的
OPERAND从局部变量变为全局变量。这样可以节省栈空间,同时规范源操作数和目的操作数的变量名称,方便我们进一步抽象。在框架代码的nemu/src/cpu/decode/operand.c源文件中,我们定义了两个OPERAND类型的全局变量,opr_src和opr_dest,用于表示源操作数和目的操作数,为所有的指令实现函数共享。
对操作的封装¶
-
注释为''mov操作''的那三行代码,会在所有的函数中变成一模一样的代码
-
使用函数进行打包
-
c static void instr_execute_2op() { //`static`关键字是为了将`instr_execute_2op()`函数的作用域限制在该`.c`文件中(必须用该函数cai'n) operand_read(&opr_src); opr_dest.val = opr_src.val; operand_write(&opr_dest); }
对操作数获取的优化¶
-
我们对第1点中要做的工作也封装成一系列
decode_data_size函数,如,decode_data_size_b、decode_data_size_v等等,在这些函数中对全局操作数变量opr_src和opr_dest赋予相应的以比特计的操作数长度。在框架代码中,我们用宏代替函数,定义了一系列的decode_data_size宏,使用宏的好处是减少函数调用次数,提高程序性能。 -
综上所述,我们实现一条(双目)指令所需要的所有信息包括:指令名称(
inst_name)、源操作数类型(src_type)、目的操作数类型(dest_type)、操作数长度后缀(suffix)。 -
我们约定实现(双目)指令操作的函数统一命名为
static void instr_execute_2op()。(nemu/include/cpu/instr_helper.h) -
c #define make_instr_impl_2op(inst_name, src_type, dest_type, suffix) make_instr_func(concat7(inst_name, _, src_type, 2, dest_type, _, suffix)) { int len = 1; concat(decode_data_size_, suffix) //还定义了宏用来对数据大小赋值 concat3(decode_operand, _, concat3(src_type, 2, dest_type)) //还定义了宏用来调用modrm对数据类型、地址进行读取(或直接对立即数进行设置)但是还有手动进行write以及read操作! instr_execute_2op(); return len; }- 就是一个字符串拼接过程
-
根据框架代码的构筑经验,适用和不适用宏的指令分别是:
-
适用宏的指令:
adc,add,and,bt,cbw,cmov,cmp,dec,inc,jcc, 大多数的mov,not,or,pop,push,sar,sbb,setcc,shl,shr,sub,test,xor -
不适用的指令:
call,cltd,cmps,div,idiv,mul,imul,cld,clc,sahf,hlt,int,jmp,lea,leave,rep,ret,stos,x87
使用print_asm()函数输出指令信息¶
在nemu/include/cpu/instr_helper.h中定义了四个用于输出指令信息的print_asm()函数,函数名最后的数字指出需要打印几个操作数。如使用框架代码中预定义的宏来实现指令,那么已经由框架代码负责调用合适的print_asm()函数。若不使用框架代码中的宏,那么在指令实现函数中,调用合适的print_asm()函数即可。注意遇到跳转指令,print_asm()函数要在改变eip之前调用。print_asm()函数中的len参数用于指出指令的长度,若不知道该怎么设置,可以暂时设置为一个较大的值。
有的时候我们希望能将执行过程中的输出同时打印到一个log文件中以方便慢慢查看。这个时候可以采用以下命令:
make run |& tee log.txt
具体的含义请自行搜索。
void print_asm_0(char *instr, char *suffix, uint8_t len);
void print_asm_1(char *instr, char *suffix, uint8_t len, OPERAND *opr_1);
void print_asm_2(char *instr, char *suffix, uint8_t len, OPERAND *opr_1, OPERAND *opr_2);
void print_asm_3(char *instr, char *suffix, uint8_t len, OPERAND *opr_1, OPERAND *opr_2, OPERAND *opr_3);
例子¶
//.c中实现
static void instr_execute_2op() { // 所有mov指令共享的执行方法
operand_read(&opr_src);
opr_dest.val = opr_src.val;
operand_write(&opr_dest);
}
make_instr_impl_2op(mov, i, rm, b)
make_instr_impl_2op(mov, i, rm, v)
make_instr_impl_2op(mov, r, rm, v)
make_instr_impl_2op(mov, rm, r, v)
//.h声明格式(别忘分号)
make_instr_func(函数名称);
案例分析¶
-
通常来说如果两个操作数不等长,可能需要单独来写
-
```c make_instr_func(mov_zrm162r_v) { int len = 1; OPERAND r, rm; r.data_size = data_size; rm.data_size = 16; len += modrm_r_rm(eip + 1, &r, &rm);
operand_read(&rm); r.val = rm.val; operand_write(&r); print_asm_2("mov", "", len, &rm, &r); return len;} ```
-
对元素size的解析
-
c #define decode_data_size_b opr_src.data_size = opr_dest.data_size = 8; #define decode_data_size_w opr_src.data_size = opr_dest.data_size = 16; #define decode_data_size_l opr_src.data_size = opr_dest.data_size = 32; #define decode_data_size_v opr_src.data_size = opr_dest.data_size = data_size; #define decode_data_size_bv \ opr_src.data_size = 8; \ opr_dest.data_size = data_size; #define decode_data_size_short_ opr_src.data_size = opr_dest.data_size = 8; #define decode_data_size_near opr_src.data_size = opr_dest.data_size = 32; -
对元素解析
-
```c //对单个元素的解析 ///一般rm需要用modrm解析 #define decode_operand_rm \ len += modrm_rm(eip + 1, &opr_src); //r的话一般是固定的,可以直接设置 #define decode_operand_r \ opr_src.type = OPR_REG; \ opr_src.addr = opcode & 0x7;
// AL = AX = EAX #define decode_operand_a \ opr_src.type = OPR_REG; \ opr_src.addr = REG_AL;
#define decode_operand_i \ opr_src.type = OPR_IMM; \ opr_src.sreg = SREG_CS; \ opr_src.addr = eip + 1; \ len += opr_src.data_size / 8; //对两个元素的解析 #define decode_operand_r2rm \ len += modrm_r_rm(eip + 1, &opr_src, &opr_dest);
#define decode_operand_rm2r \ len += modrm_r_rm(eip + 1, &opr_dest, &opr_src); //立即数放在指令最后面,先正常modrm设置len后再读取立即数 #define decode_operand_i2rm \ len += modrm_rm(eip + 1, &opr_dest); \ opr_src.type = OPR_IMM; \ opr_src.sreg = SREG_CS; \ opr_src.addr = eip + len; \ len += opr_src.data_size / 8;
#define decode_operand_i2r \ len += opr_src.data_size / 8; \ opr_src.type = OPR_IMM; \ opr_src.sreg = SREG_CS; \ opr_src.addr = eip + 1; \ opr_dest.type = OPR_REG; \ opr_dest.addr = opcode & 0x7;
// REG_AL == REG_AX == REG_EAX == 0 #define decode_operand_i2a \ opr_src.type = OPR_IMM; \ opr_src.sreg = SREG_CS; \ opr_src.addr = eip + 1; \ opr_dest.type = OPR_REG; \ opr_dest.addr = REG_AL; \ len += opr_src.data_size / 8;
// REG_CL == REG_CX == REG_ECX == 1 #define decode_operand_c2rm \ len += modrm_rm(eip + 1, &opr_dest); \ opr_src.type = OPR_REG; \ opr_src.addr = REG_CL;
#define decode_operand_o2a \ opr_src.type = OPR_MEM; \ opr_src.sreg = SREG_DS; \ if (verbose) \ clear_operand_mem_addr(&opr_src); \ opr_src.addr = instr_fetch(eip + 1, 4); \ if (verbose) \ opr_src.mem_addr.disp = opr_src.addr; \ opr_dest.type = OPR_REG; \ opr_dest.addr = REG_AL; \ len += 4;
#define decode_operand_a2o \ opr_dest.type = OPR_MEM; \ opr_dest.sreg = SREG_DS; \ if (verbose) \ clear_operand_mem_addr(&opr_dest); \ opr_dest.addr = instr_fetch(eip + 1, 4); \ if (verbose) \ opr_dest.mem_addr.disp = opr_dest.addr; \ opr_src.type = OPR_REG; \ opr_src.addr = REG_AL; \ len += 4; ```
2-2(程序的装载-程序头表)¶
基本概念¶
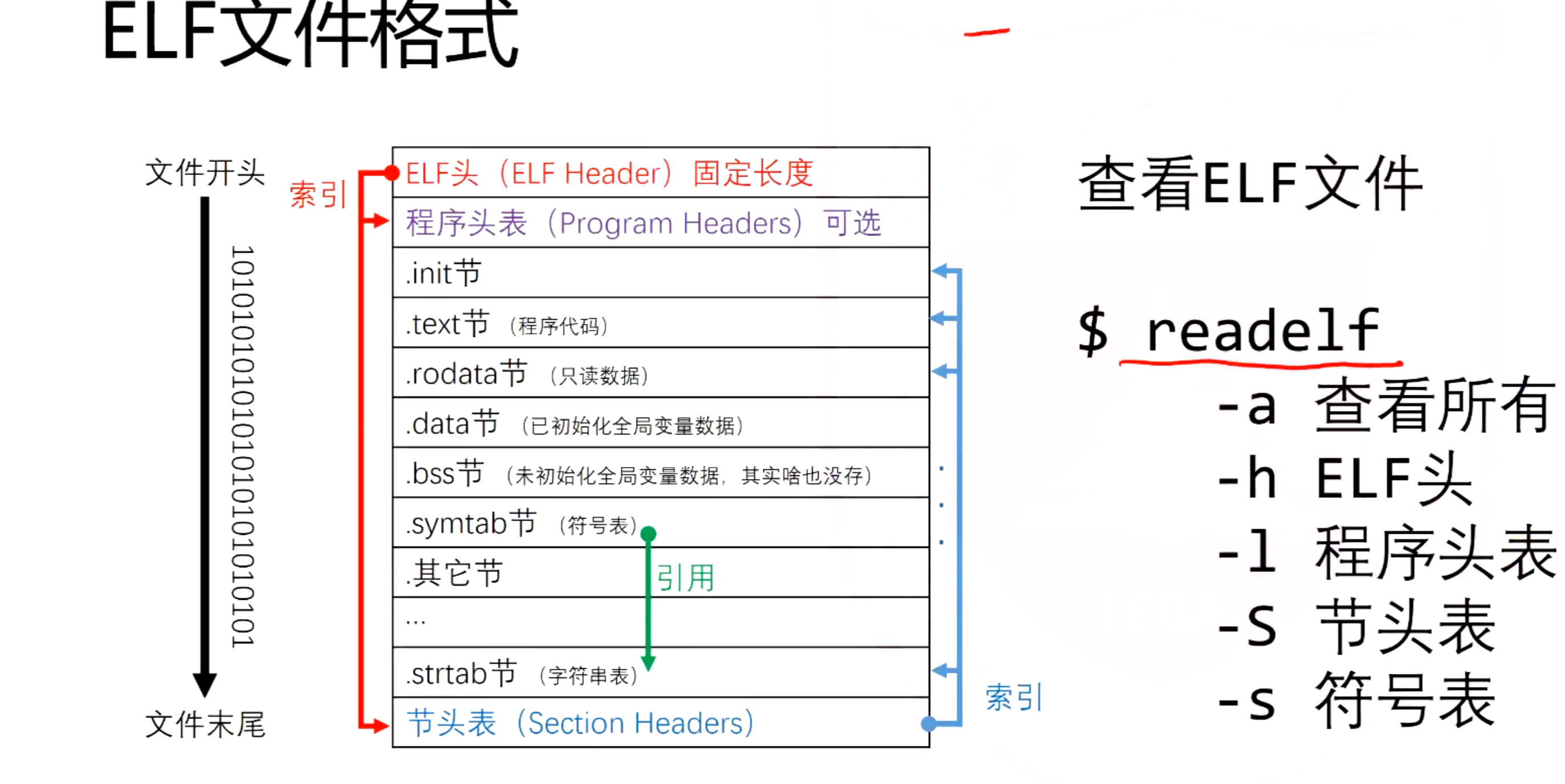
- elf是类unix系统上的可执行可连接文件的标准格式
- .o文件以及链接之后的可执行文件都是elf文件

-
当存在未初始化的全局变量(.bss)时filesiz不等于memsiz(filesize不对.bss分配空间,而memsiz会对.bss分配空间,多出来的就是这部分)
-
程序的装载是由操作系统完成的
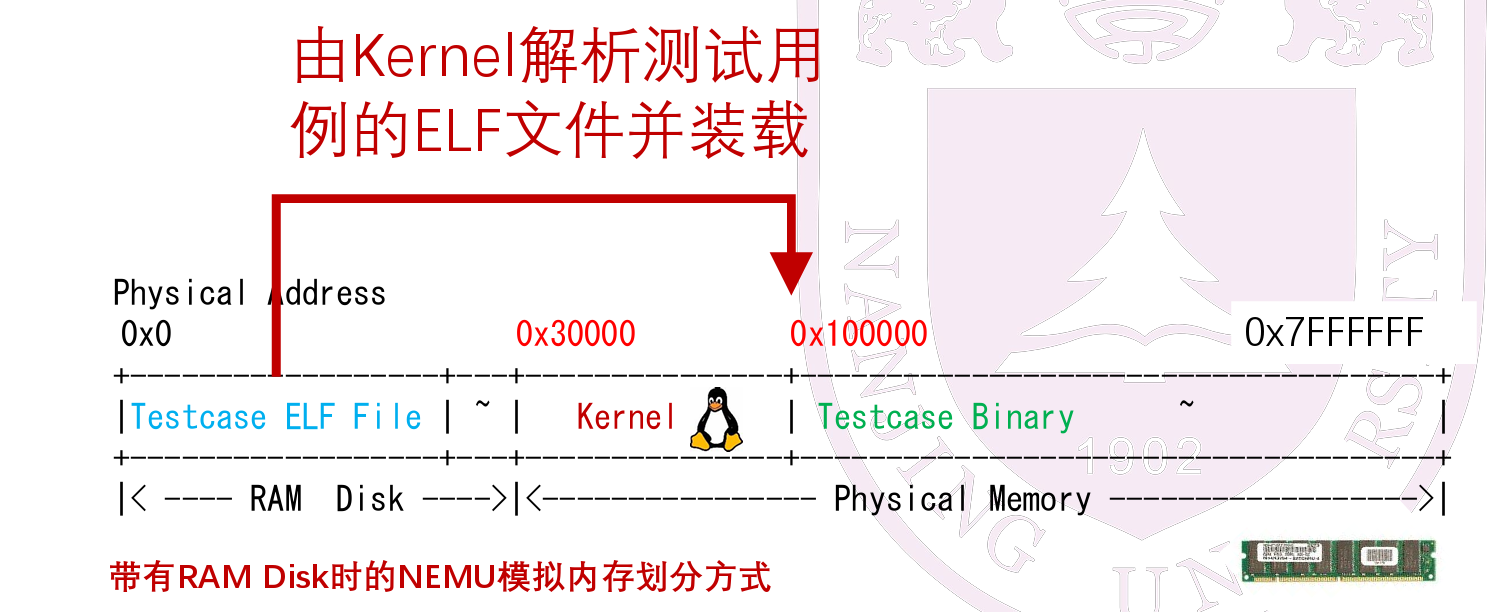
- 先装入操作系统,之后由操作系统进行对程序的装载,从0x100000开始执行
实验内容¶
- 解析程序头表:
- 只装载load类型
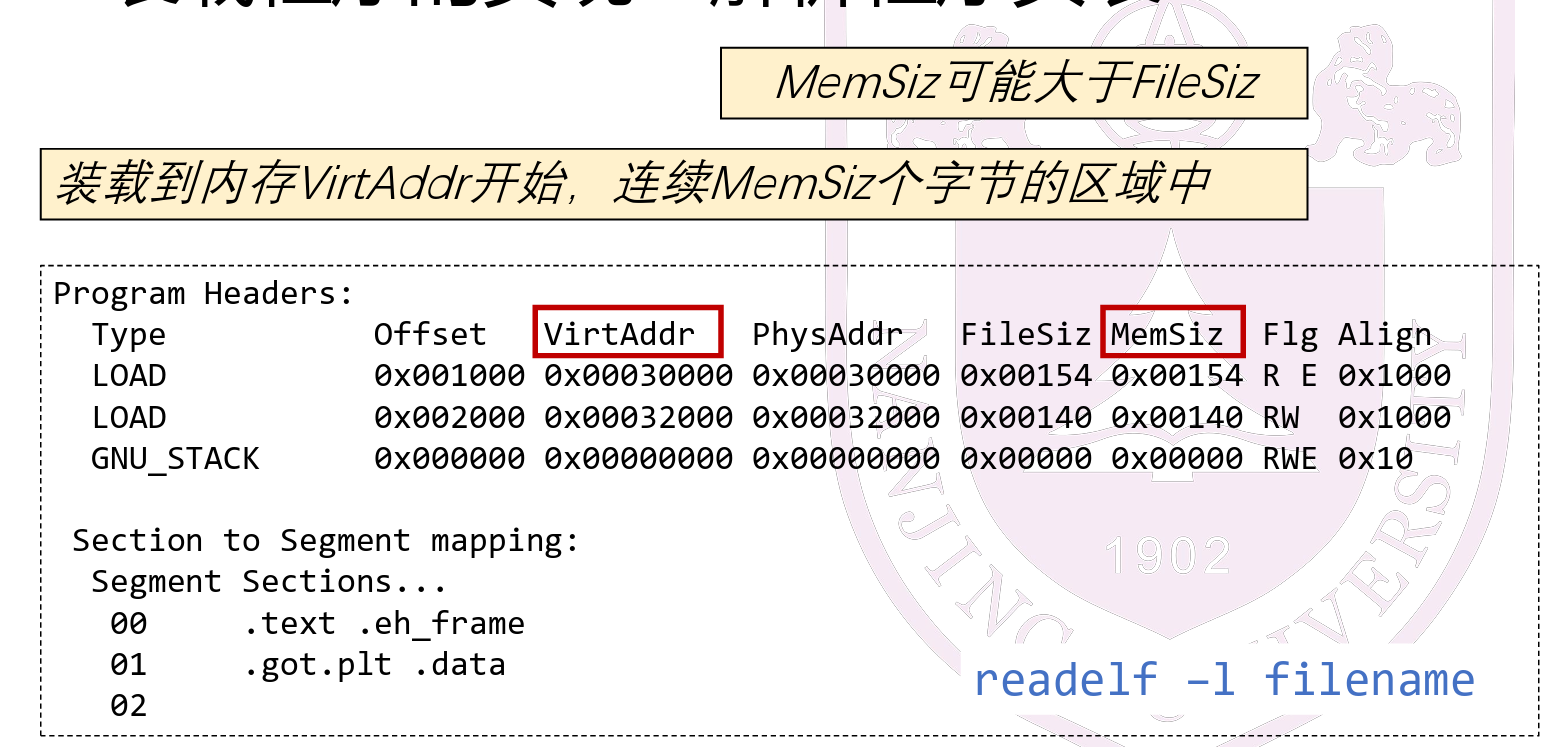

- 多出来的这一部分要清零
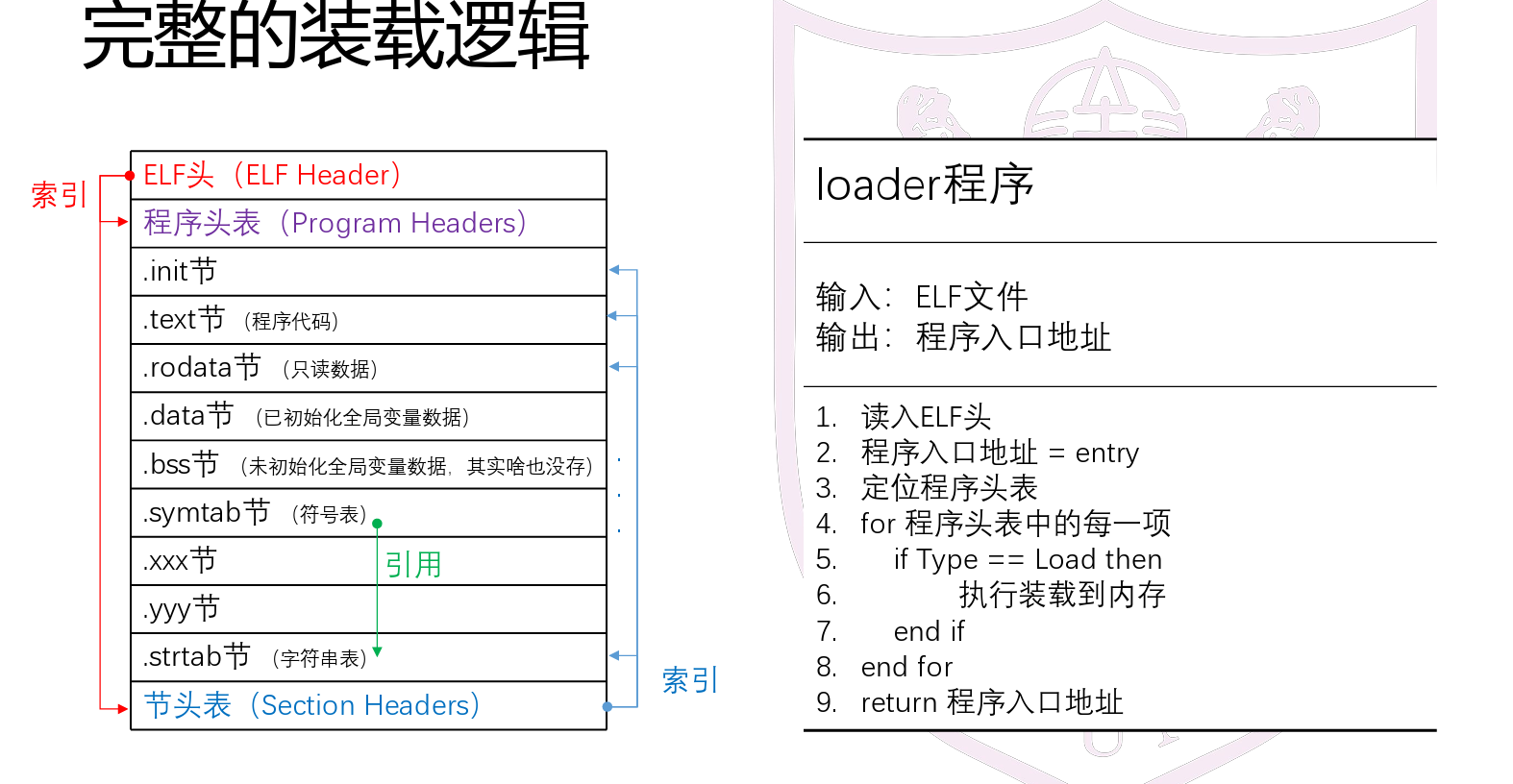


- memset的作用是在一段内存块中填充某个给定的值。 void memset(void s , int ch ,size_t n) 将s中当前位置后面n个字节用ch替换并返回s。
- 功能是从源内存地址的起始位置开始拷贝若干个字节到目标内存地址中。 void memcpy(destination,source,num) 从source的位置开始向后复制num个字节的数据到destination的内存位置
pa3¶
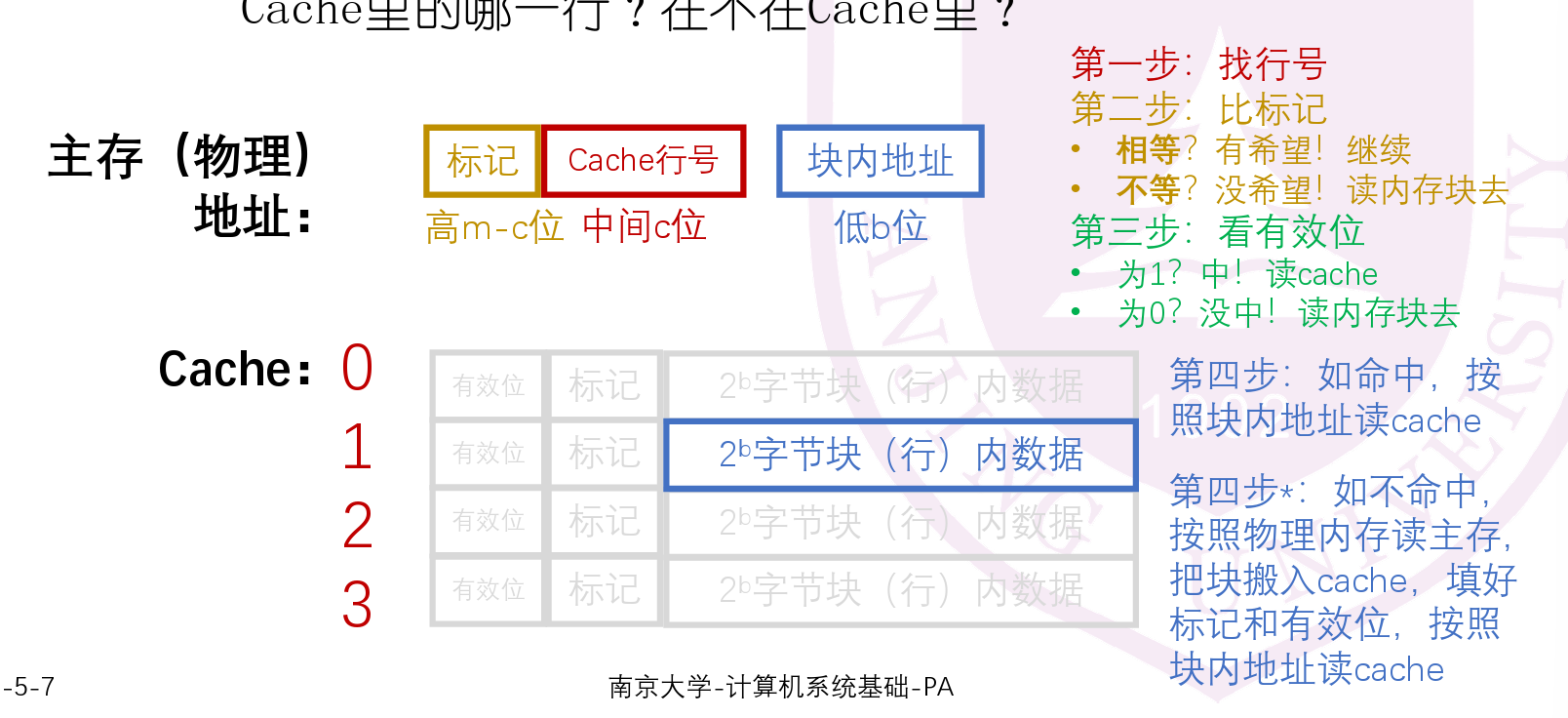

- 使用全写法,非写分配
pa3-2¶
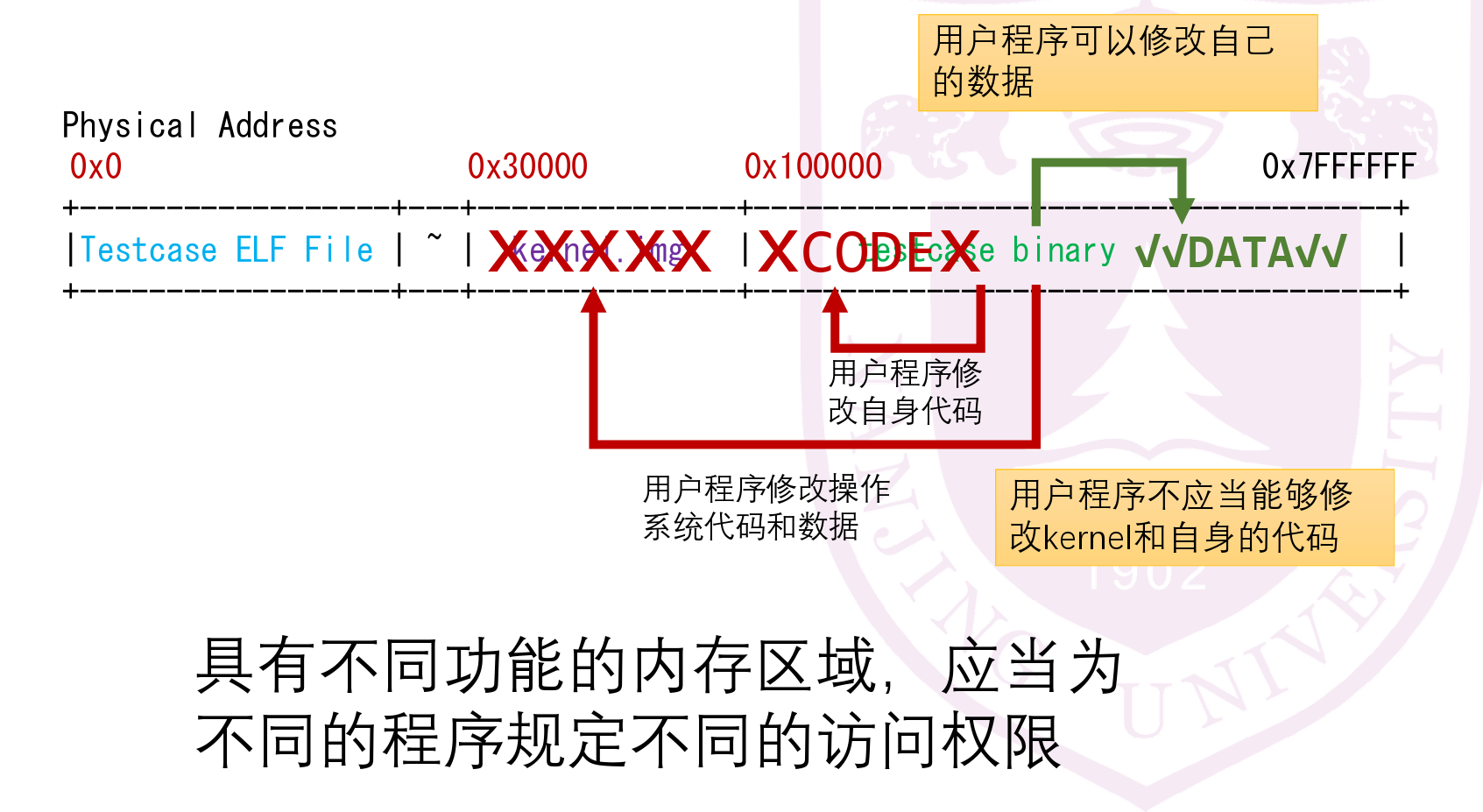

- 可以通过偏移量来检查是否出现了越界情况
-
通过权限等级判断是否有权限访问
-



任务¶
-
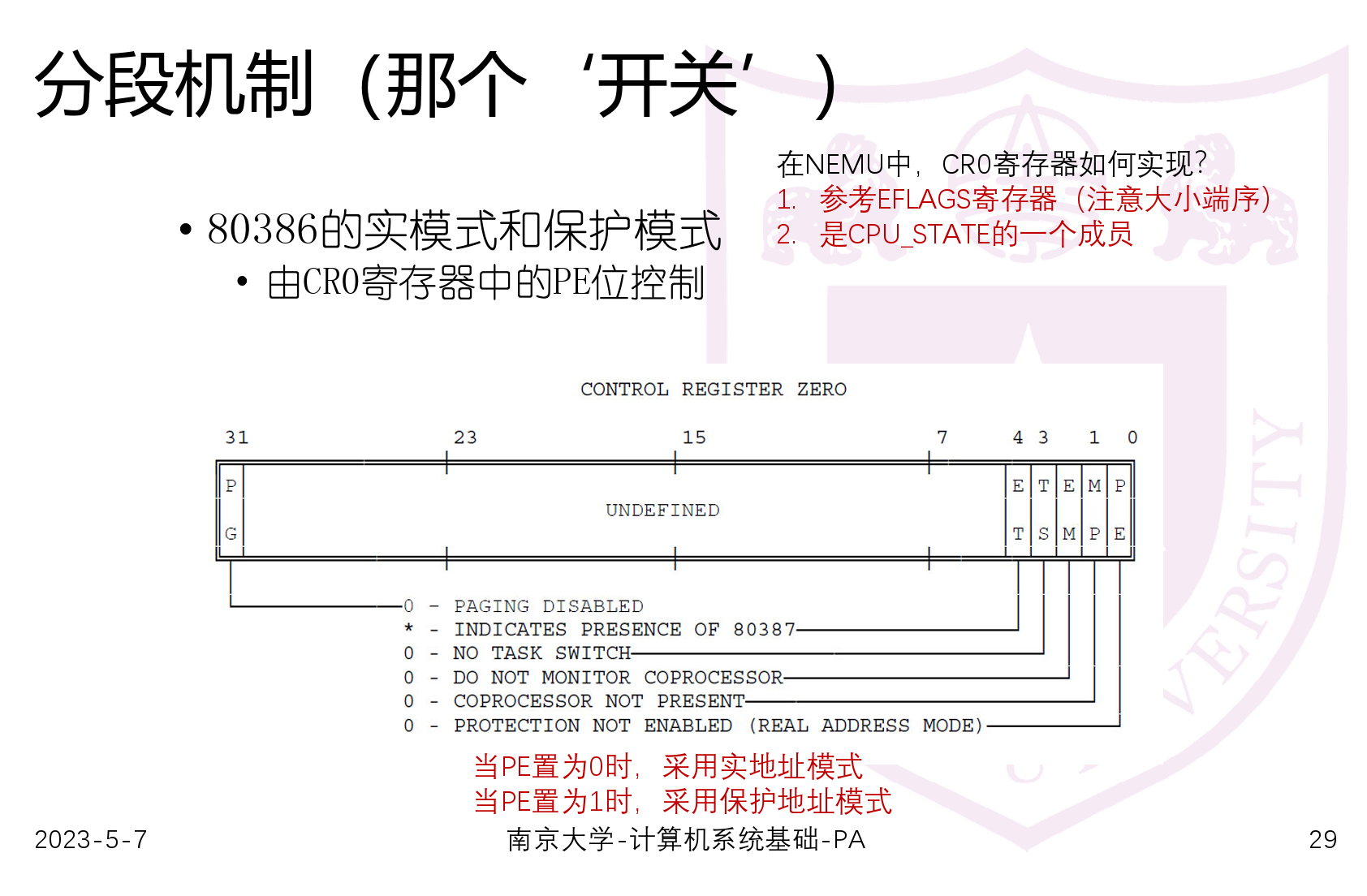
&&参照eflags完成CR0寄存器
-


- &&段选择符待完成

- 段寄存器中除了存储段选择符外还有隐藏信息(关于段选择符缓存)
- pa中ti===1(GDT)
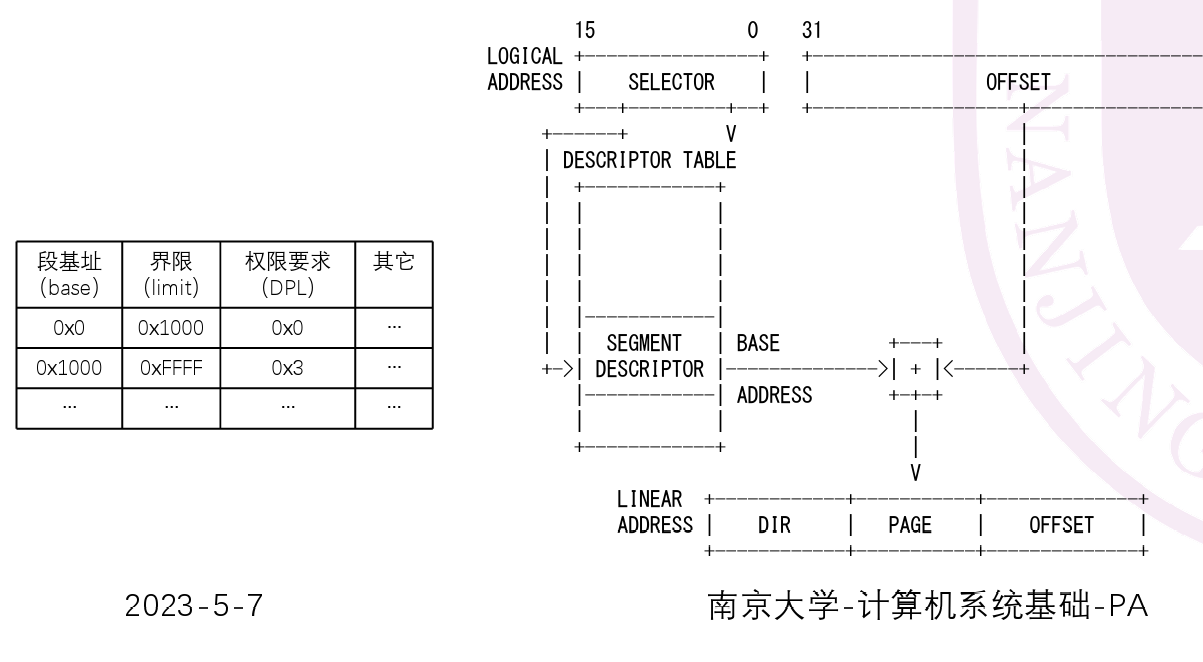
- 根据段选择符中index找到段描述符,得到段基址,与偏移量拼接得到新地址
- 段描述符
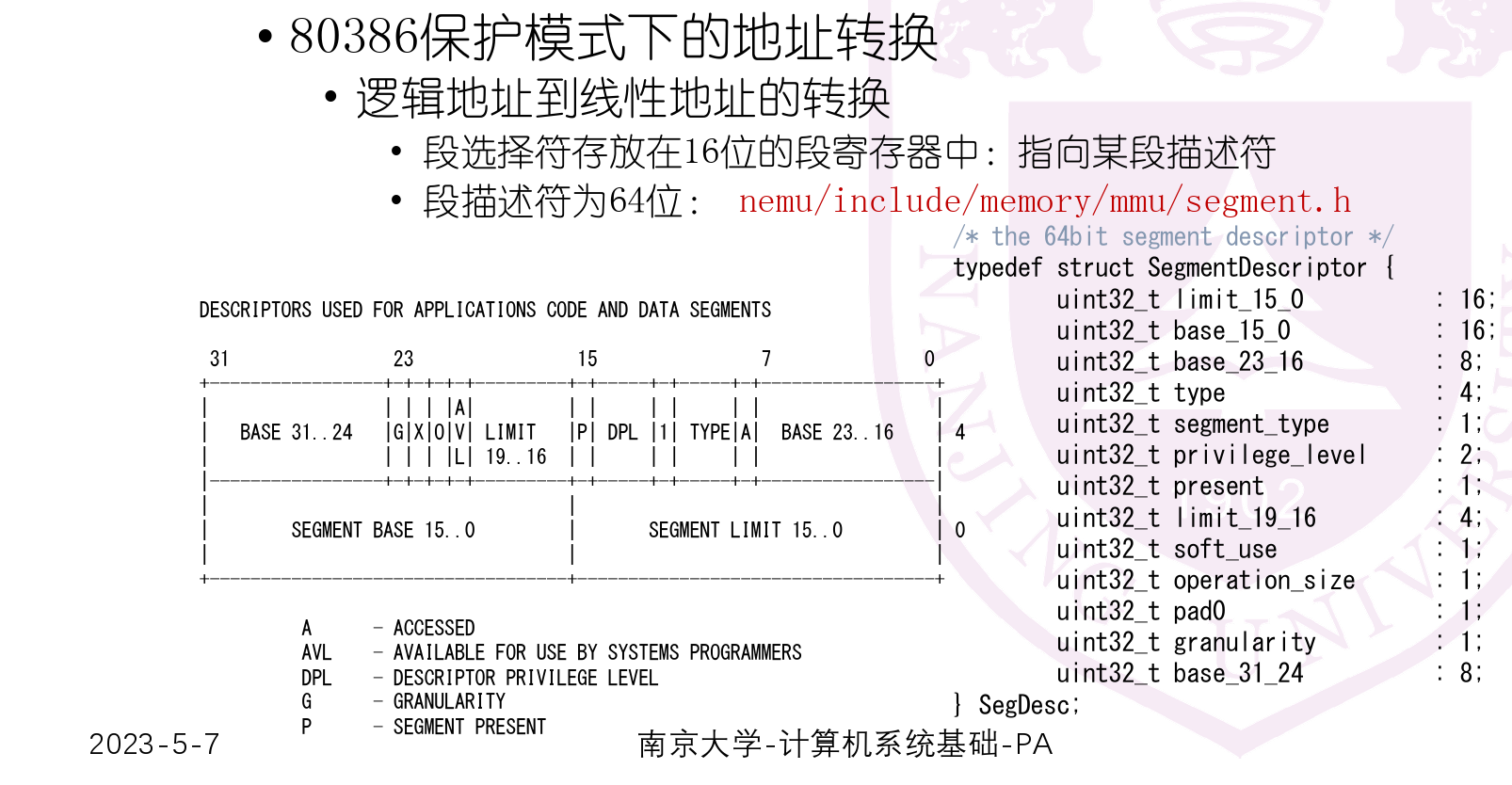
- 段基址被拆分为3段需要拼接得到32位地址
- 段界限(长度减一)被拆分为两部分,共20位(越界检查)
- G=0时以字节位单位,G=1时以页(4kb)为单位(此时20+12达到最大32位地址)
- pa中G===1,不会发生缺段
- 段选择符中RPL为程序劝降,段描述符DPL为段要求的等级(权限检查)
- DPL>=RPL(段选择符的)
- DPL>=CPL(进程的)
- GDT的首地址存储在GDTR中
- GDTR寄存器的数据存储结构如下:
- 16位的界限字段(Limit):用于指定全局描述符表的边界,即表中描述符的数量减一。
- 32位的基址字段(Base Address):指向全局描述符表的起始地址。
实验过程¶
-
完成结构体
-
lgdt指令
-
负责初始化gdt寄存器(保存gdt表的位置)
-
段选择符的缓存与快速地址检索
-
``` uint32_t segment_translate(uint32_t offset, uint8_t sreg) { return cpu.segReg[sreg].base + offset;//隐藏部分包含缓存,不需要去查表了 }
// load the invisible part of a segment register void load_sreg(uint8_t sreg)//实现根据index自动装填隐藏参数 { / TODO: load the invisibile part of the segment register 'sreg' by reading the GDT. * The visible part of 'sreg' should be assigned by mov or ljmp already. / //读取段描述符 SegDesc t; memcpy(&t,hw_mem+cpu.gdtr.base+cpu.segReg[sreg].index*8,8); //隐藏初始化 cpu.segReg[sreg].base=t.base_15_0+(t.base_23_16<<16)+(t.base_31_24<<24); cpu.segReg[sreg].limit=t.limit_15_0+(t.limit_15_0<<16); cpu.segReg[sreg].type=t.type; cpu.segReg[sreg].privilege_level=t.privilege_level; cpu.segReg[sreg].soft_use=t.soft_use; //断言 assert(t.present==1); assert(t.granularity==1); assert(cpu.segReg[sreg].base==0); assert(cpu.segReg[sreg].limit==0xfffff); } ```
-
jmpl指令
-
传入两个ptr参数,分别指向段index与偏移量(48位地址),可以实现跨段跳跃
pa3-3¶
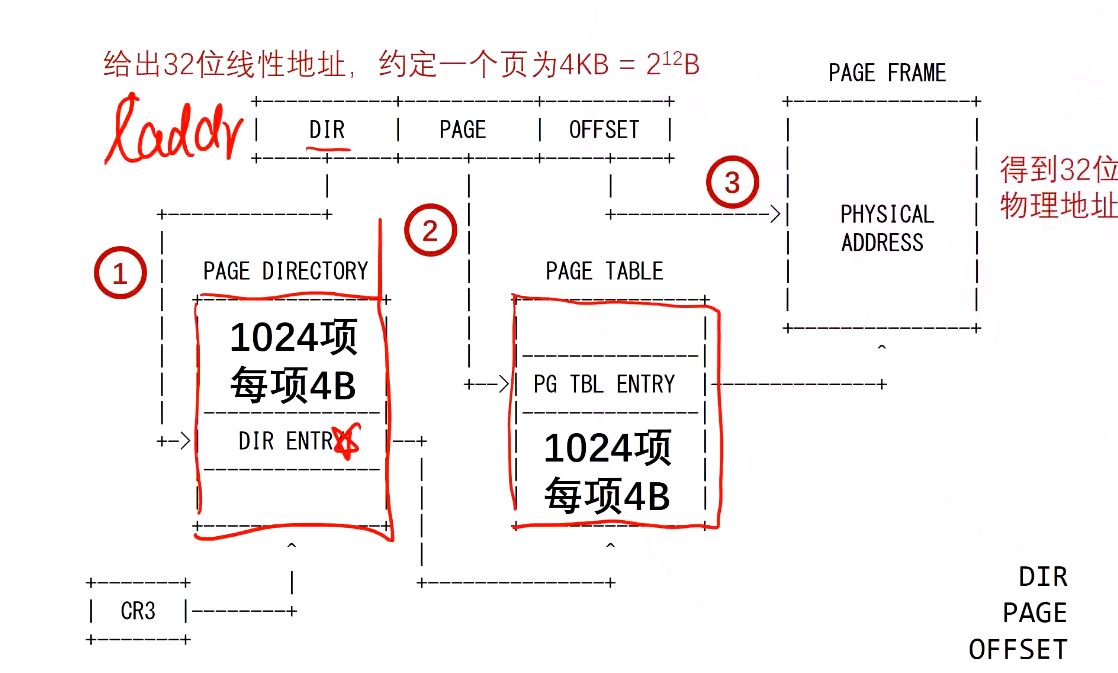
- 分段机制无法解决物理内存大小的局限性以及多进程管理问题——引入分页机制
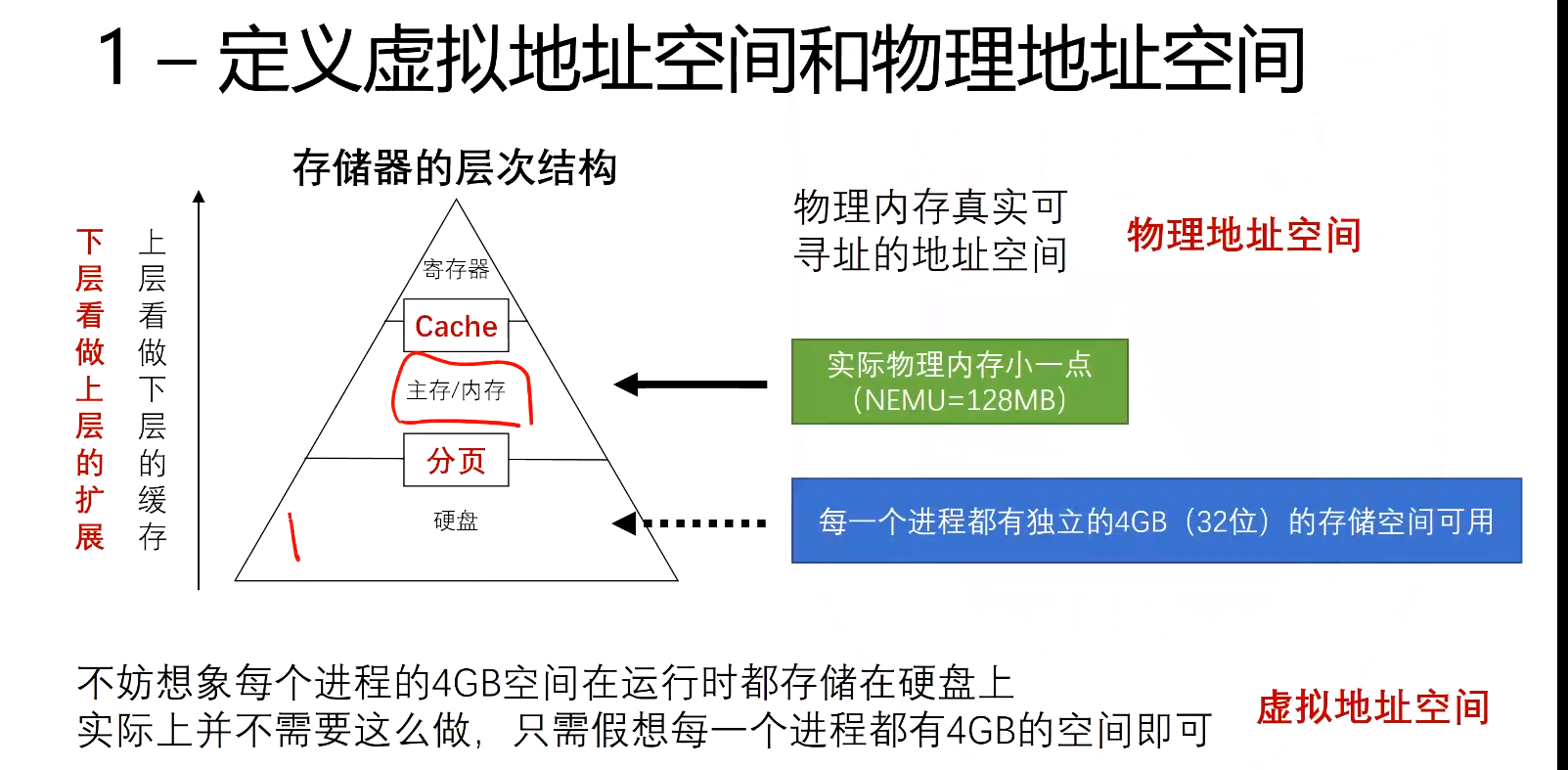
- 使用虚拟地址,为每个进程分配32位最大的4gb独立虚拟地址空间
-
-
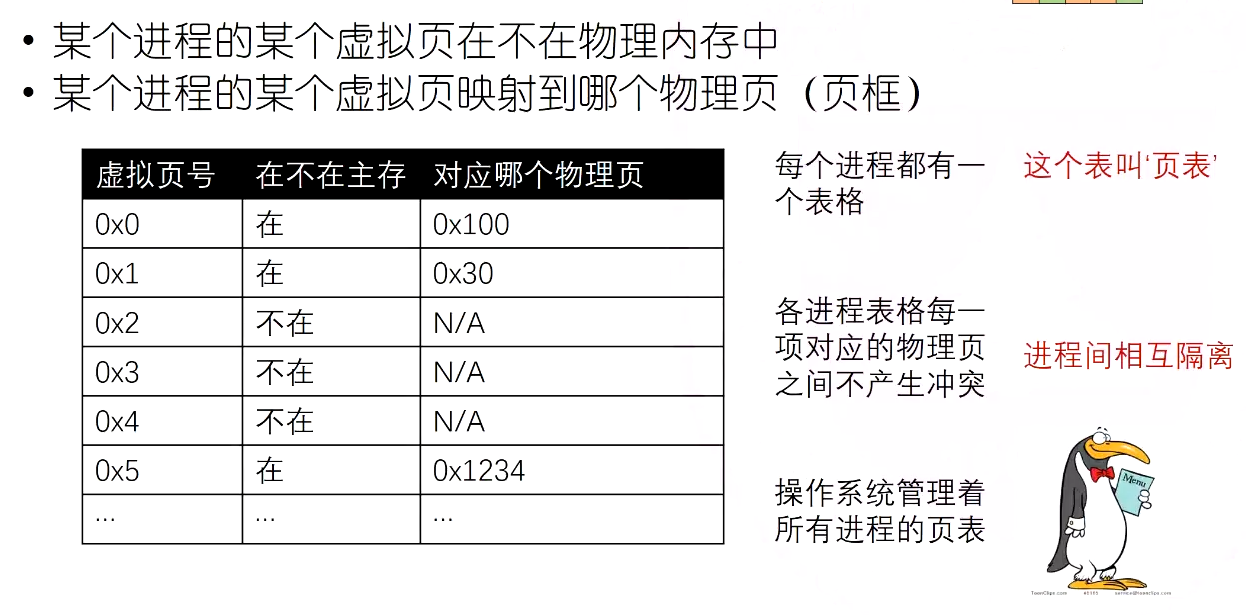
页表¶
-
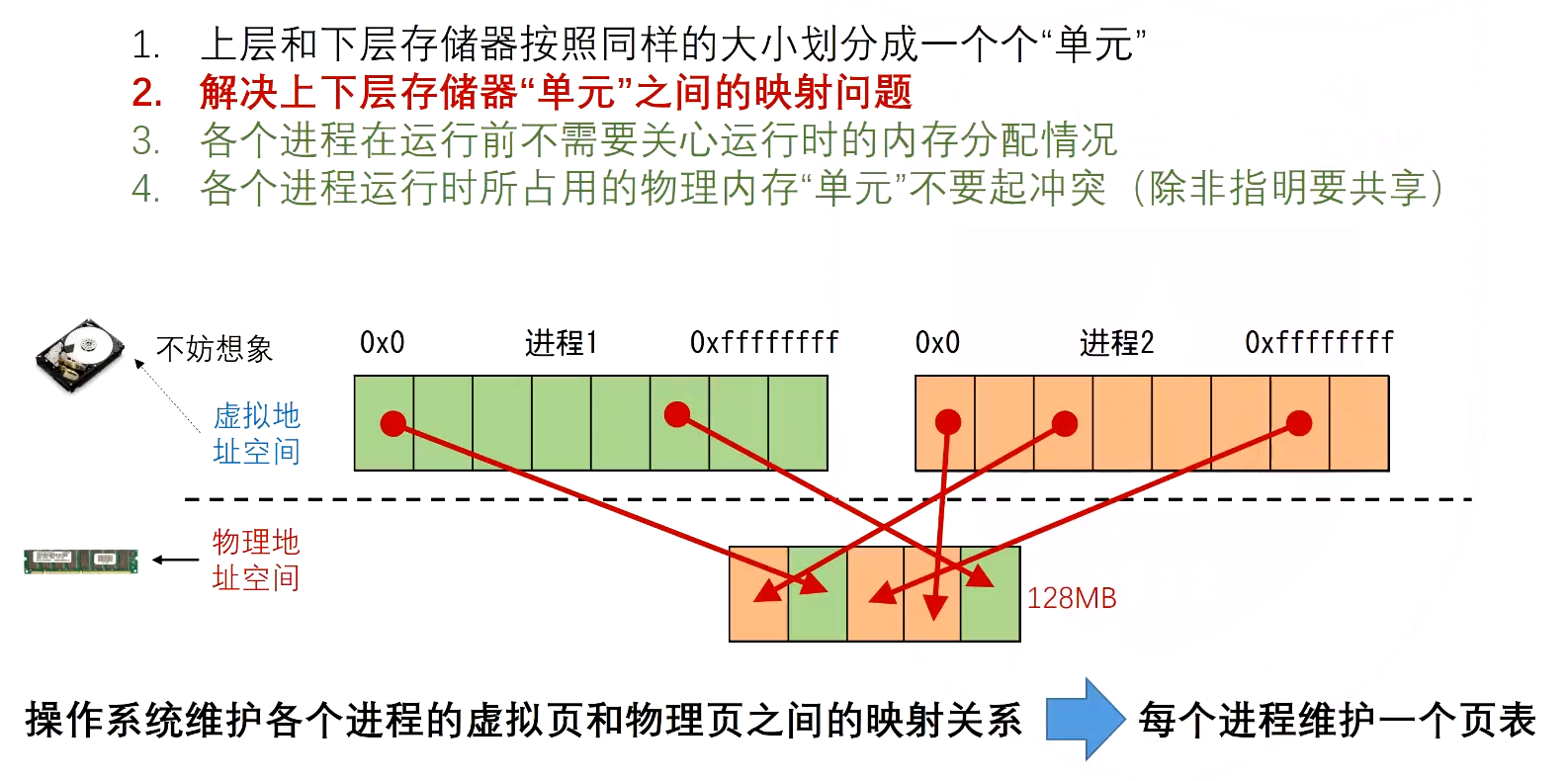
- 全相邻模式在主存中存储,为了避免遍历查找,每个进程维护一个页表便于查找对应关系
-
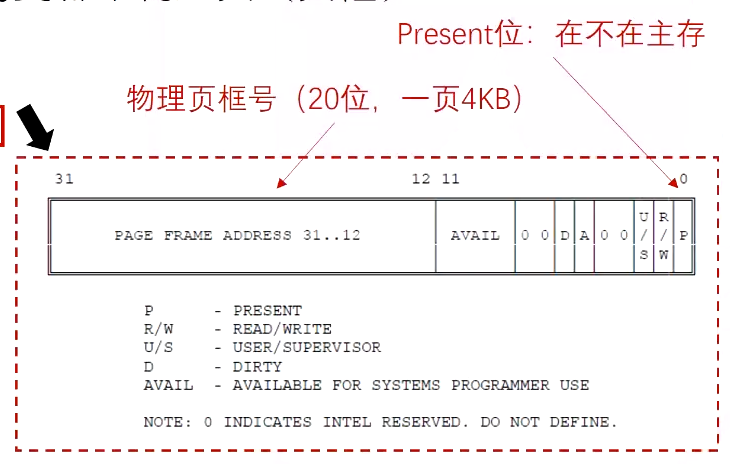
高20位物理页号,p是否已经缓存到了主存(虚拟页号不需要存,以index项序列号来判断)
-
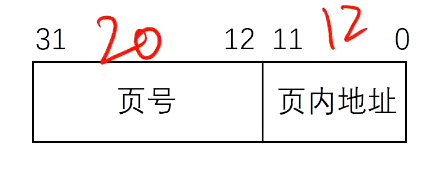
线性地址->物理地址
-
-
将虚拟页号替换为物理页号
-
多级页表
-
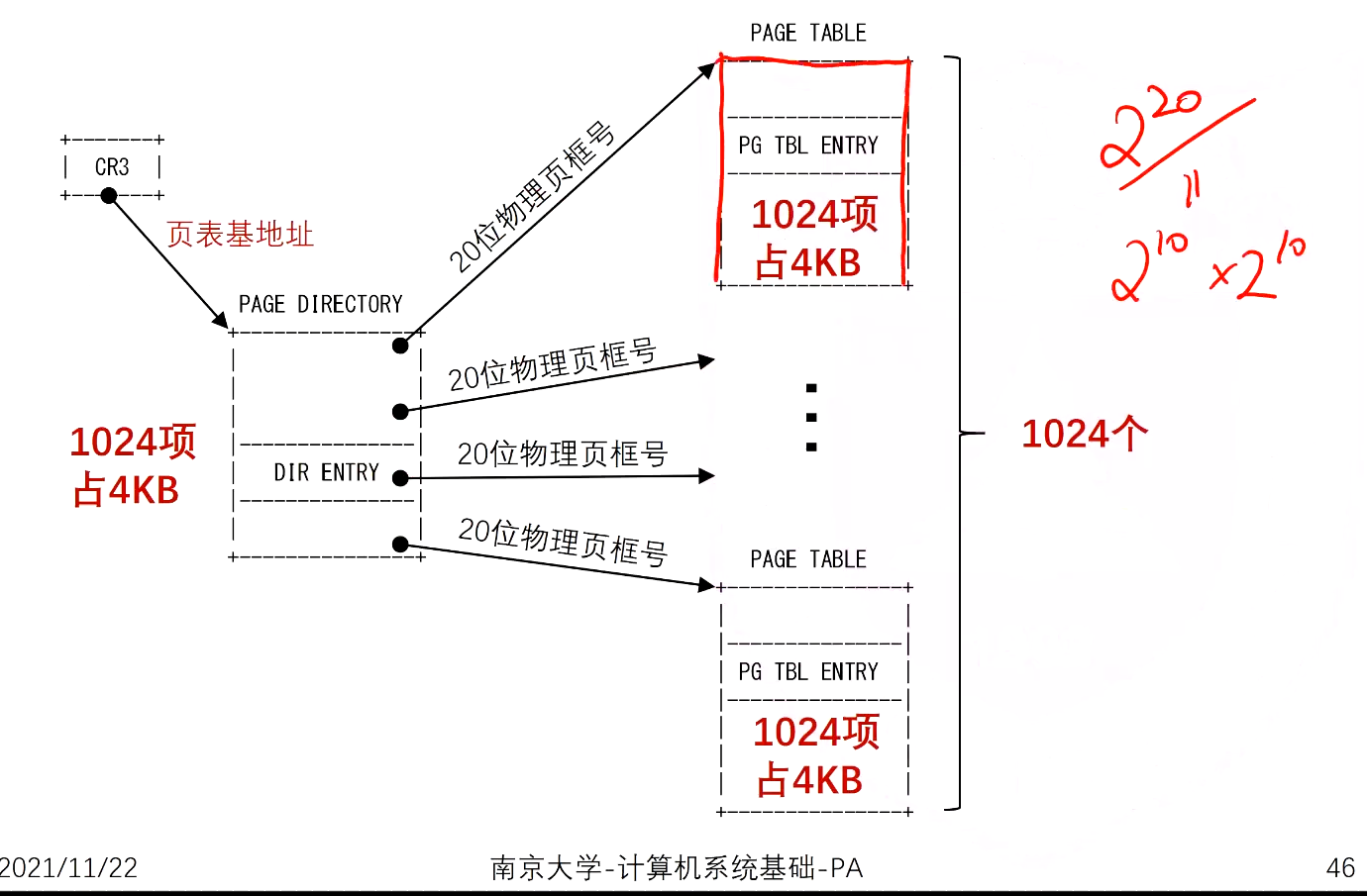
- \(2^{10}\)个\(2^{10}\)项的页表,一级页表、二级页表大小都刚好是一个页
- 将20位页号拆分为高10位和低10位
-
CR3内保存页目录的物理地址:20位物理页框号(4kb对齐)
-
-
实验步骤¶
-

-

c typedef union{ struct{ uint32_t reserved : 12; uint32_t addr : 20; }; uint32_t val; } CR3;
-

-

- 了解kernal如何近些页表的初始化
-

