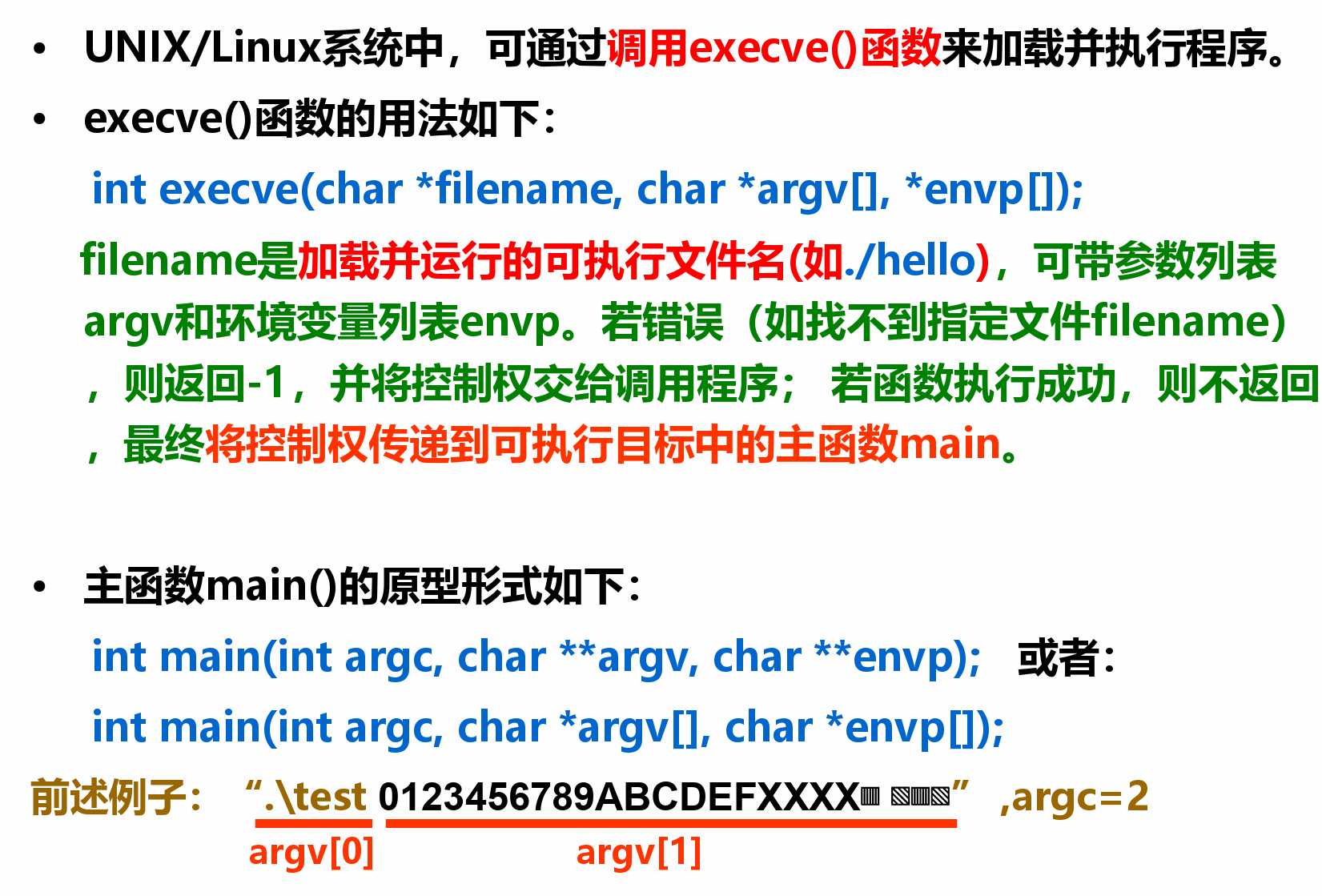
程序的转换与机器级表示¶
程序转换概述¶
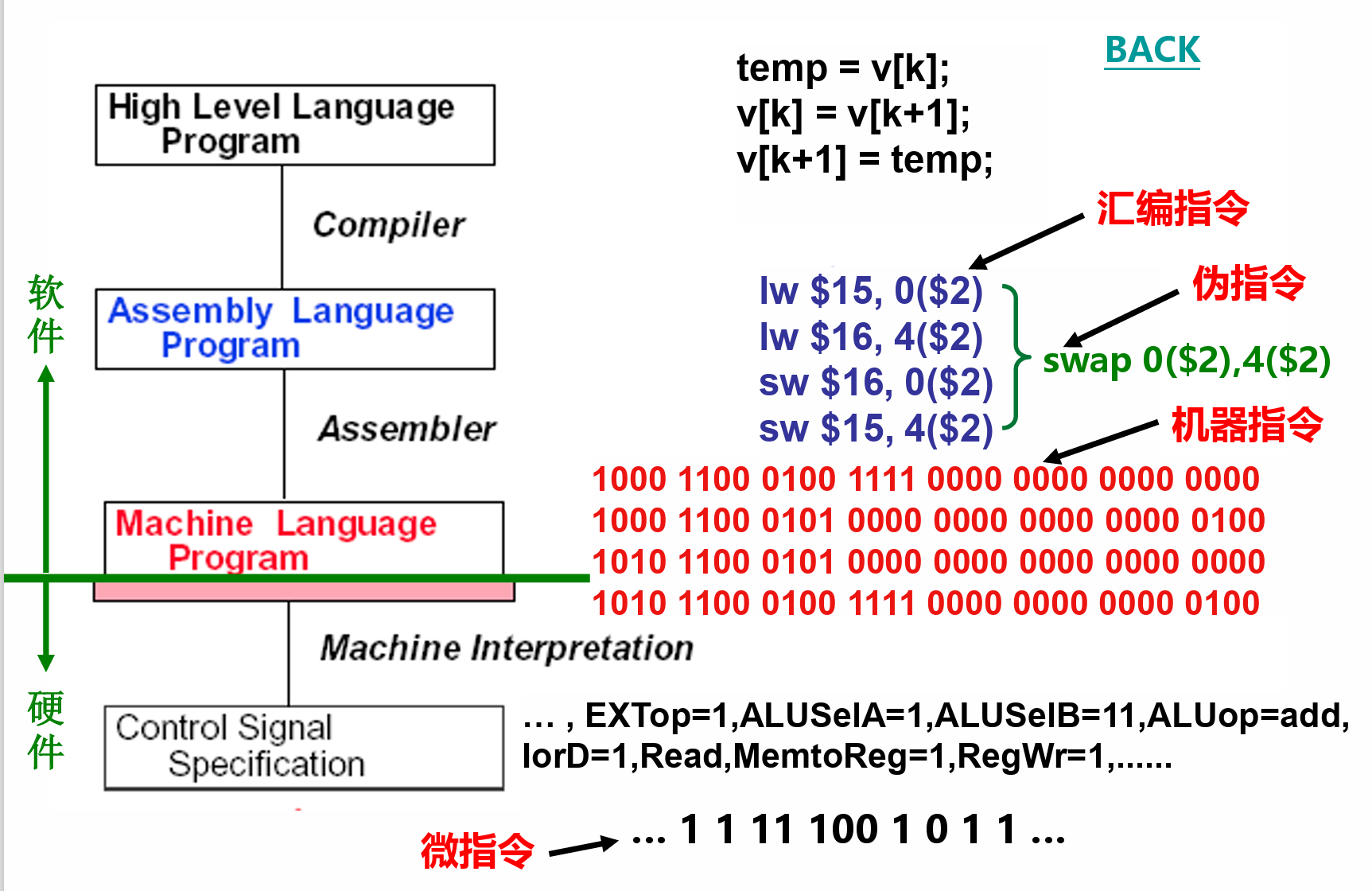
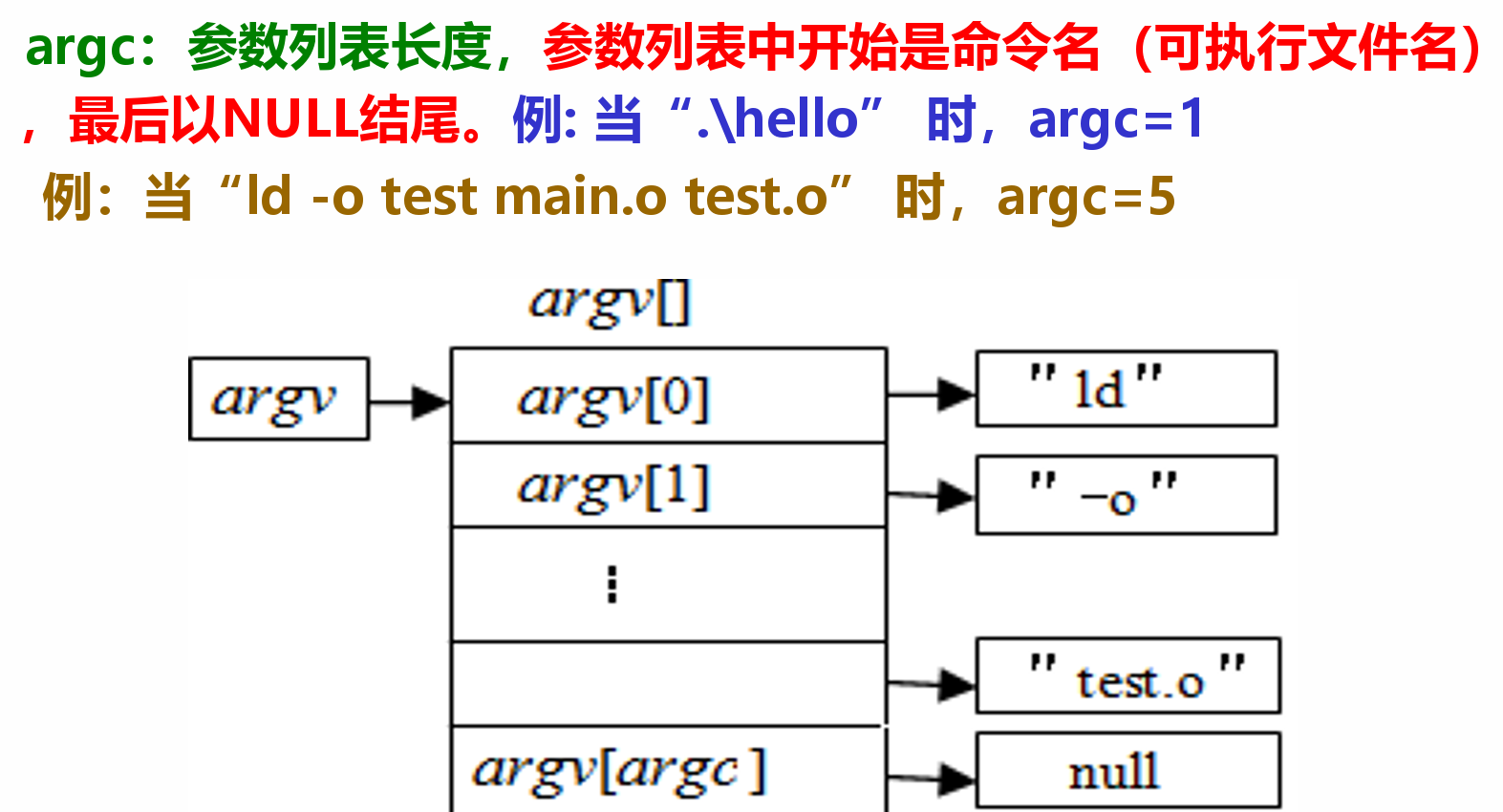
指令¶
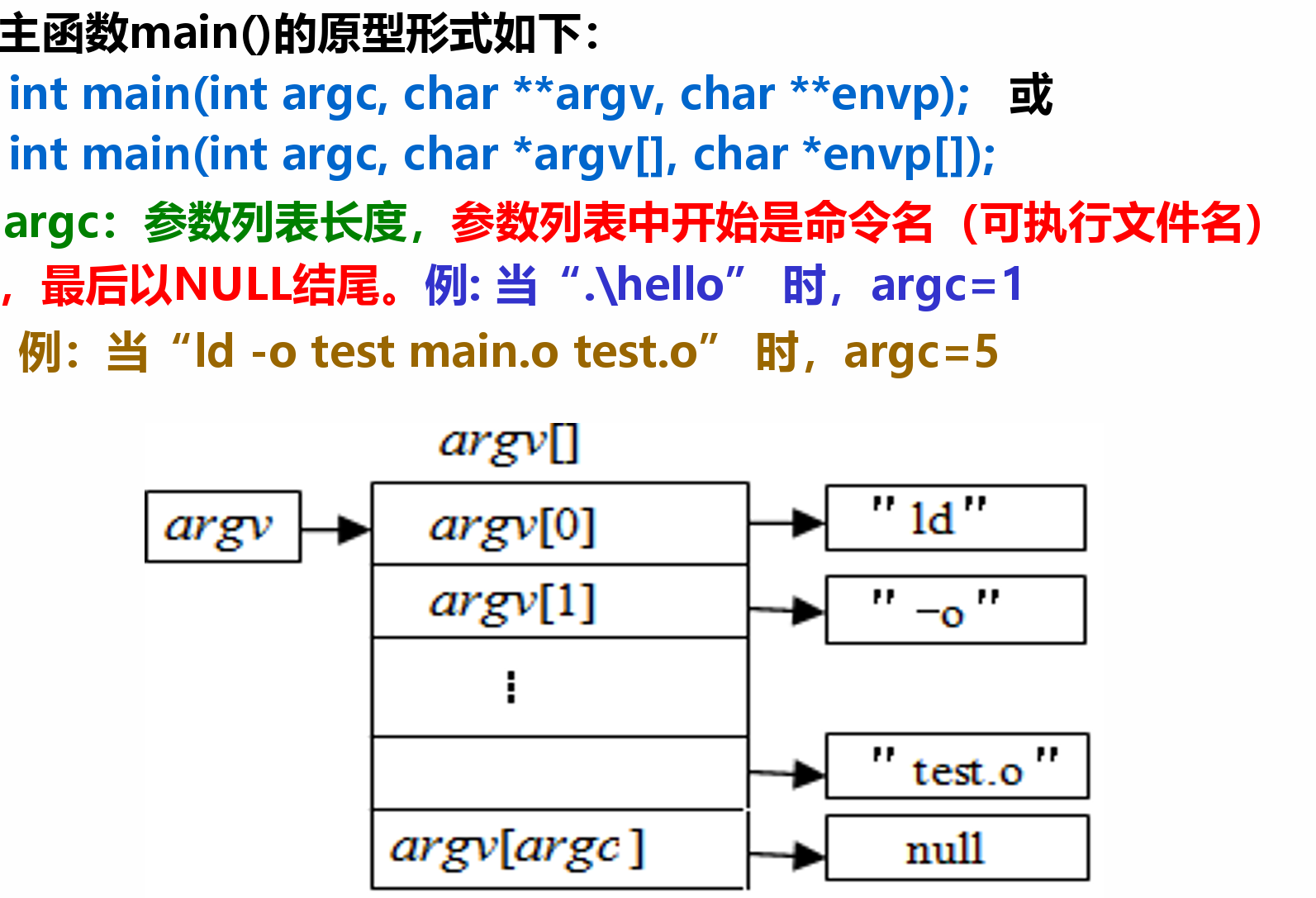
- 分类:微指令、机器指令和伪(宏)指令
- 微指令是微程序级命令,属于硬件范畴
- 机器指令介于二者之间,处于硬件和软件的交界面
- 伪指令是由若干机器指令组成的指令序列,属于软件范畴
机器级指令¶

- 标识要将 cl 处的都元素移动到 R[]..处
- 使用AT&T格式:
- 寄存器操作数形式为“% +寄存器名 ”
- 存储器操作数形式为:偏移量(基址寄存器,变址寄存器,比例因子)

-

-
机器指令和汇编指令一一对应,都是机器级指令
- 将机器语言转化为汇编的程序为反汇编程序
- 汇编指令是机器指令的符号表示
机器指令格式¶

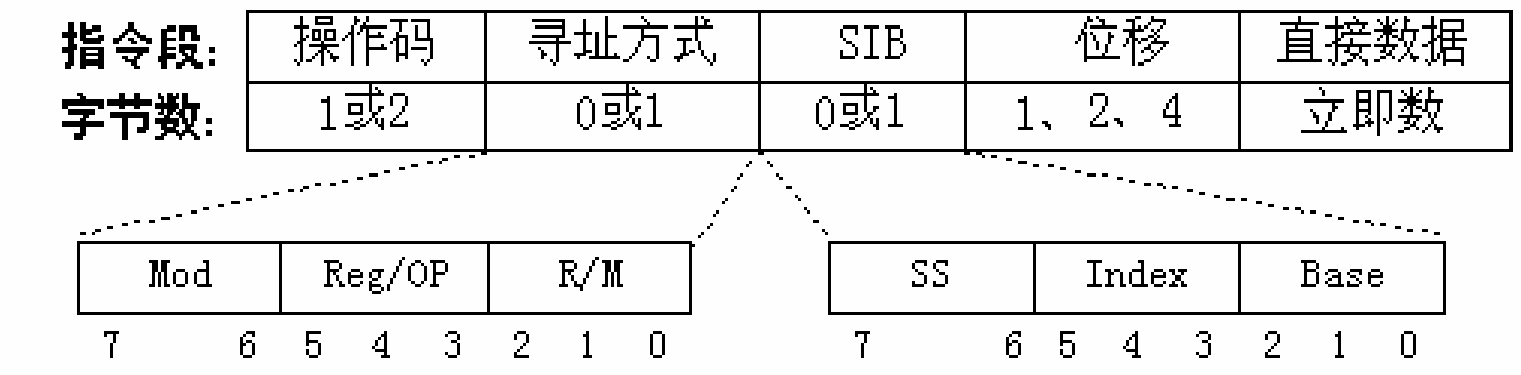
- 前缀类型:用于修改指令的功能或操作数的大小、段寄存器或地址模式等。
- 操作码:用于确定指令的操作类型,如移动、算术、逻辑、控制转移等。
- 寻址方式:用于确定操作数所在的寄存器编号或有效地址计算方式。
- 位移量:用于表示相对或绝对地址,或者作为立即数使用。
- 立即数:用于表示常量值,作为源操作数使用。

高级程序语言转化为机器语言¶
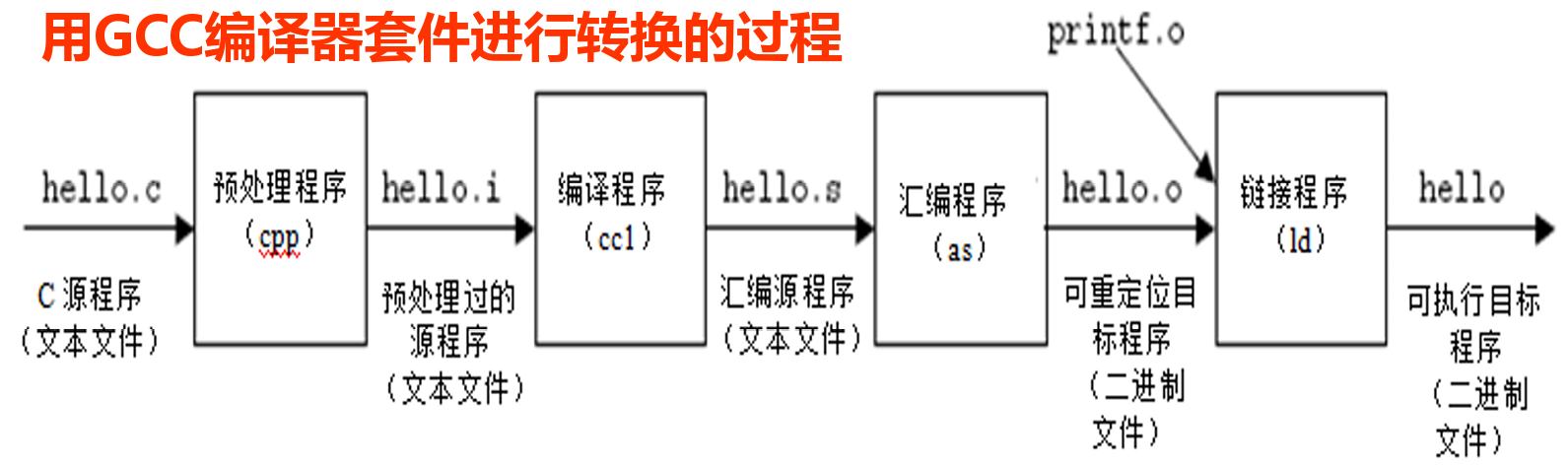
- 预处理:在高级语言源程序中插入所有用#include命令指定的文 件和用#define声明指定的宏。
- 编译:将预处理后的源程序文件编译生成相应的汇编语言程序。
- 汇编:由汇编程序将汇编语言源程序文件转换为可重定位的机器 语言目标代码文件。
- 链接:由链接器将多个可重定位的机器语言目标文件以及库例程 (如printf()库函数)链接起来,生成最终的可执行目标文件。
IA-32 /x86-64指令系统¶
数据类型¶
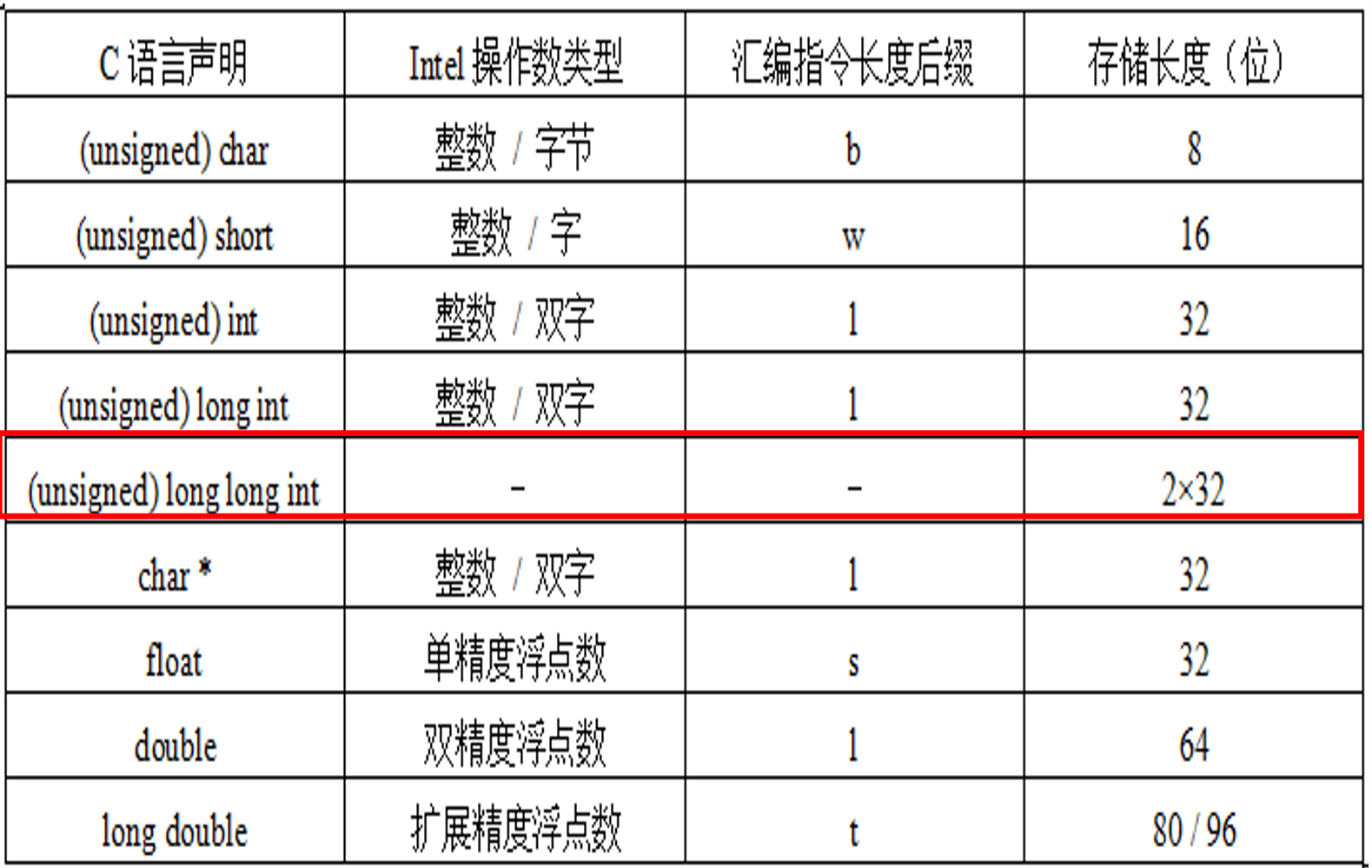
- 为了提高long double浮点数的访存性能 ,将其存储为12个字节 (即 96 位 , 数据访问分32位和64位两次读写). 其中前两个字节不用,仅用后10个字节, 即低80位。
寄存器¶
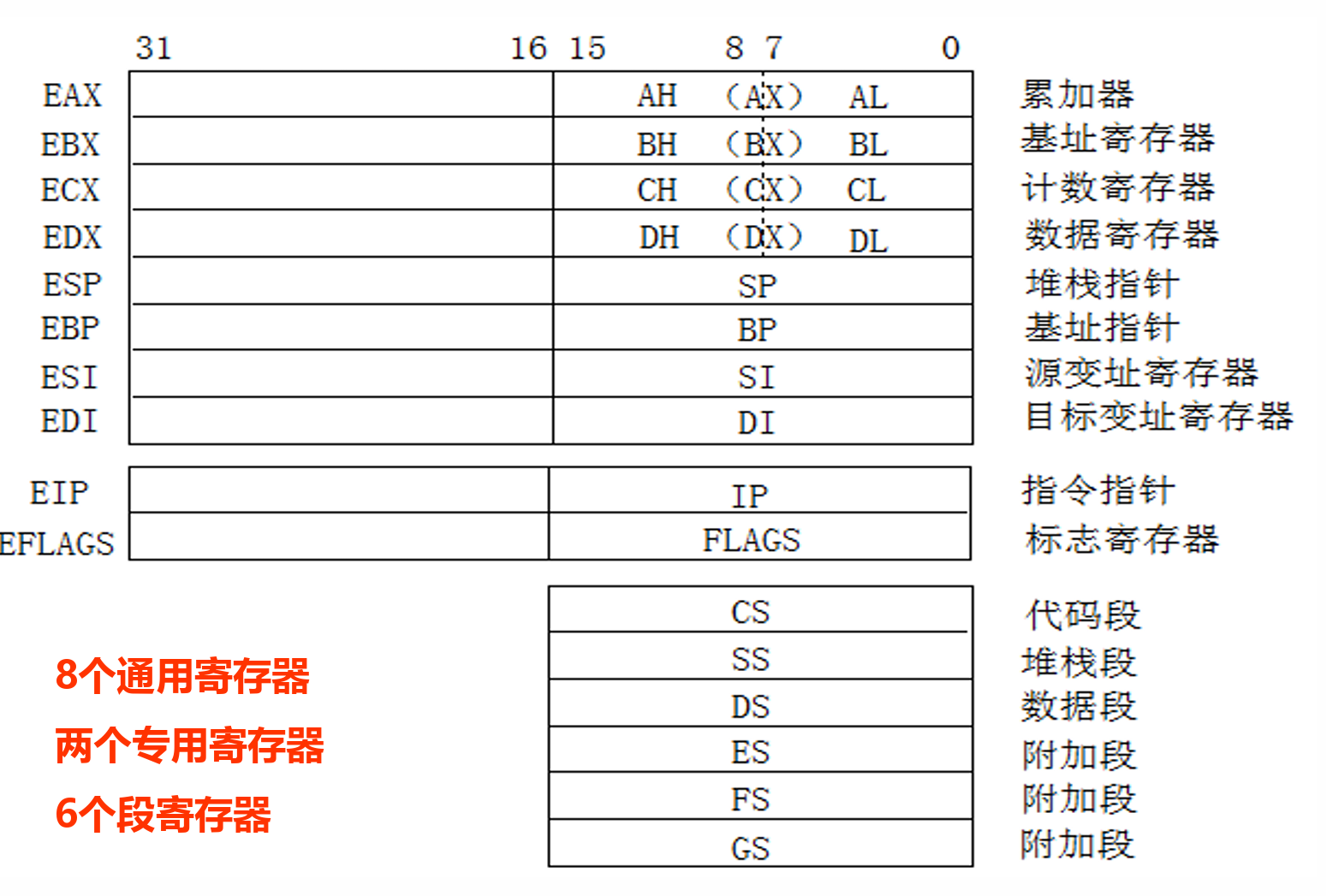
标志寄存器¶

寻址方式¶
-
根据指令给定信息得到操作数或操作数地址
-
操作数所在的位置
- 指令中:立即寻址(立即数)(把操作数直接写在指令中,不需要访问存储器或寄存器。)
- 寄存器中:寄存器寻址(把操作数存放在CPU的寄存器中,也不需要访问存储器)
- 存储单元中(存储器操作数是指把操作数存放在内存或I/O端口中,需要通过地址码来访问)
-
这三种方式的速度和范围有所不同。一般来说,立即寻址最快,但只能用于常数或已知数据;寄存器寻址次之,但受限于寄存器的数量和大小;存储器操作数最慢,但可以访问更大的空间和更灵活的数据结构
-
两种工作模式:实地址模式和保护模式
-
实地址模式(基本用不到,一般只有在系统启动过程中使用)
-
保护模式(需要掌握)
- 加电后进入,采用虚拟存储管理,多任务情况下隔离、保护
- 80286以上高档微处理器最常用的工作模式
- 寻址空间为232B,32位地址分段(段基址+段内偏移量
-
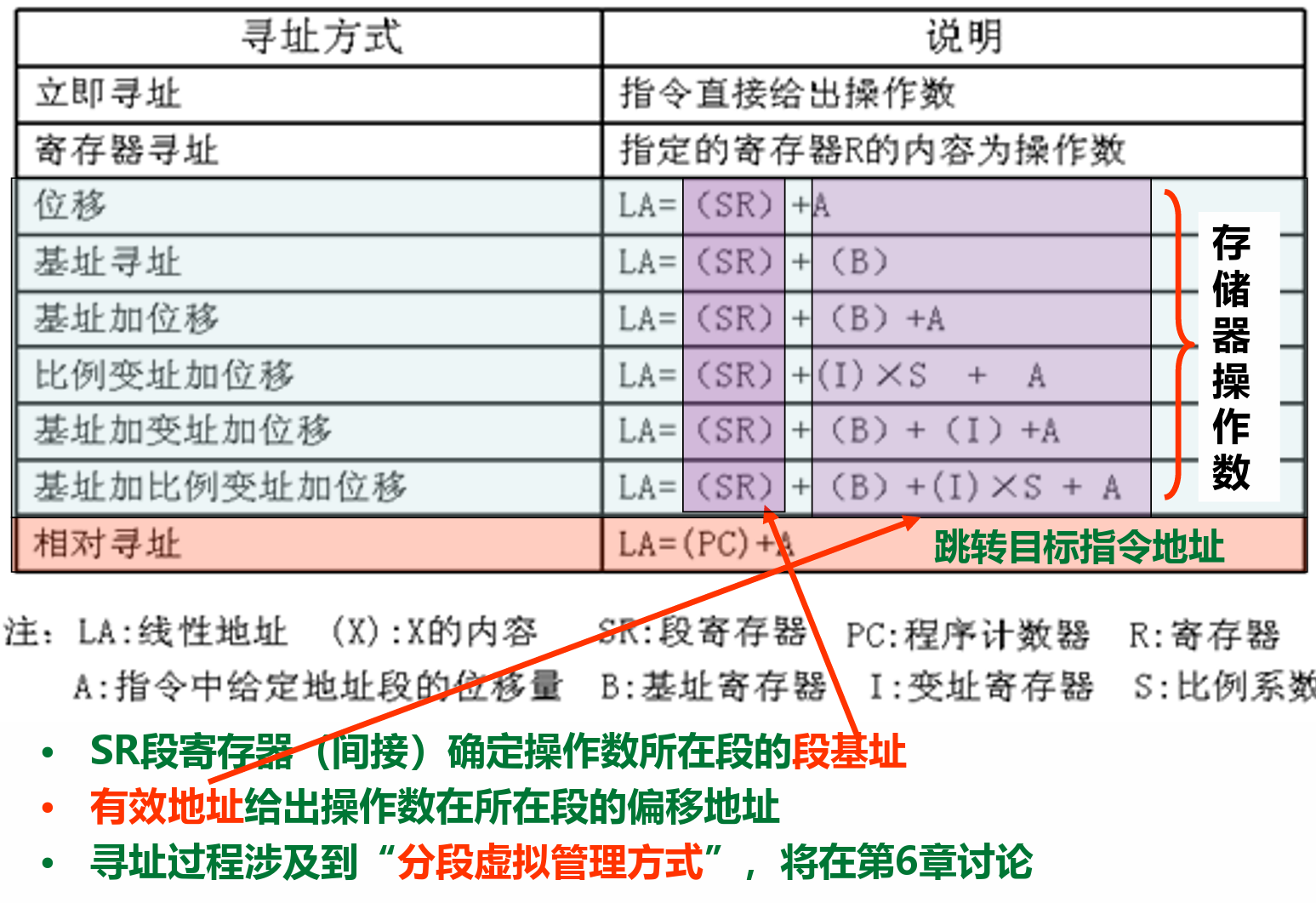
- S的含义为操作数的字节个数,在IA-32中,S的取值可以是1、2、4或8。(若数组元素的类型为 short,则比例系数就是2;若数组元素类型为float,则比例系数就是4)
- 非比例变址相当于比例系数为1 的比例变址情况,无须乘以比例系数。(char)
- IA-32提供的 “基址加位移”“基址加比例变址加位移” 等这些复杂的存储器操作数寻址 方式,主要是为了指令能够方便地访问到数组、结构、联合等复合数据类型元素 。
- 若数组 a 的首地址存放在 EBX 寄存器,下标变量 i 存放在 ESI 寄存器,则实现 “ 将 a[i]送 EAX"
movl x(%ebx, %esi, 4), %eax目标地址为M[ R [ ebx] + 4 * R [ esi ] + x(a[i]的首地址相对于该结构类型数据的首地址的位移) ](即实际地址=基址+变址*比例因子+偏移)
- 若数组 a 的首地址存放在 EBX 寄存器,下标变量 i 存放在 ESI 寄存器,则实现 “ 将 a[i]送 EAX"
-
要区分
%ebx这是指寄存器,(%ebx)这是指寄存器中内容指向的地址 -

-

常用指令¶
传送¶
- 通用数据传送指令
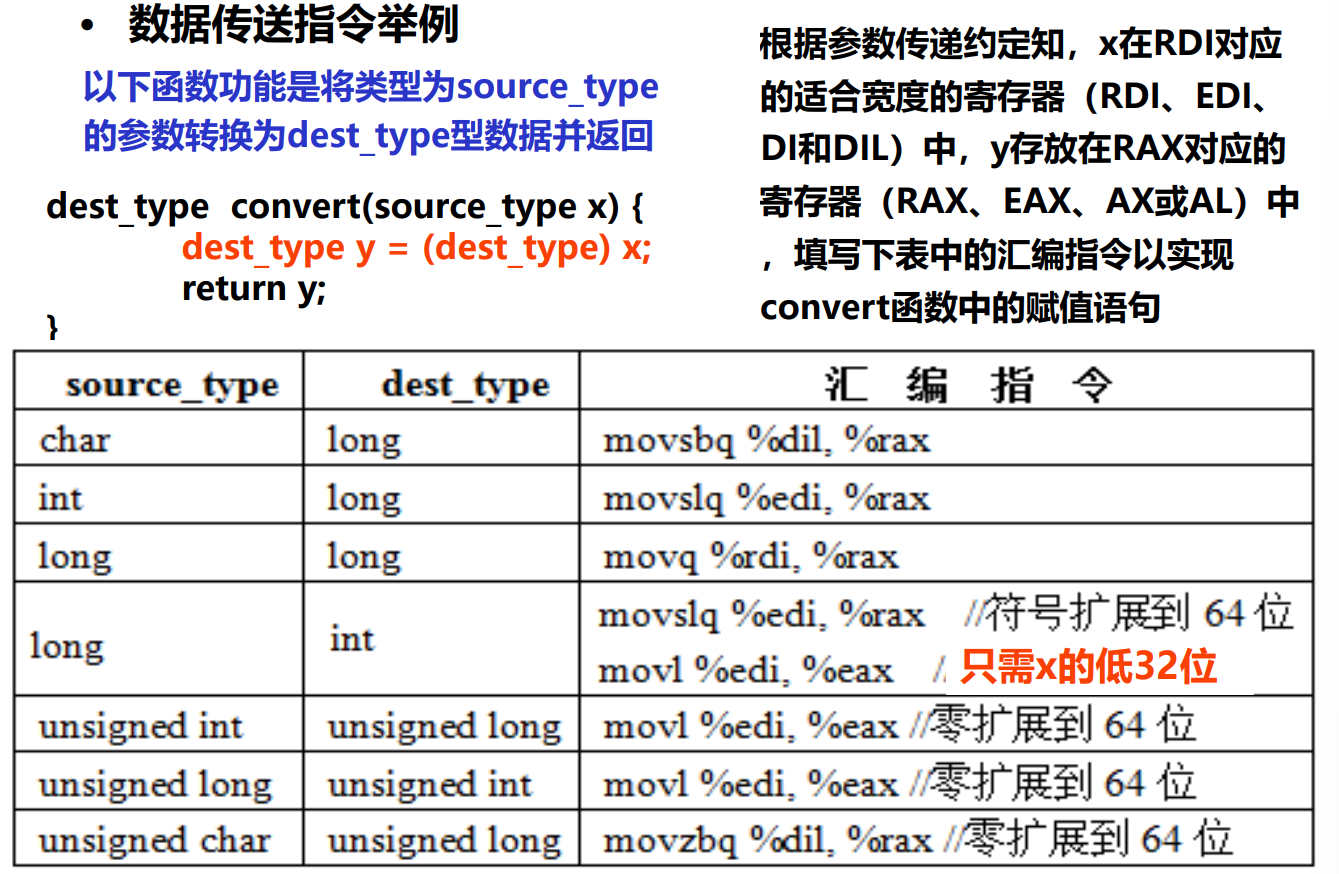
- MOV:一般传送(无符号数和有符号数之间转化也是),包括movb、movw和movl等
- MOVS:符号扩展传送,如movsbw、movswl等
- MOVZ:零扩展(无符号数)传送,如movzwl、movzbl等
- tip:bw,wl表示扩展前后的数据大小
- XCHG:数据交换
- PUSH/POP:入栈/出栈,pushl,pushw,popl,popw等
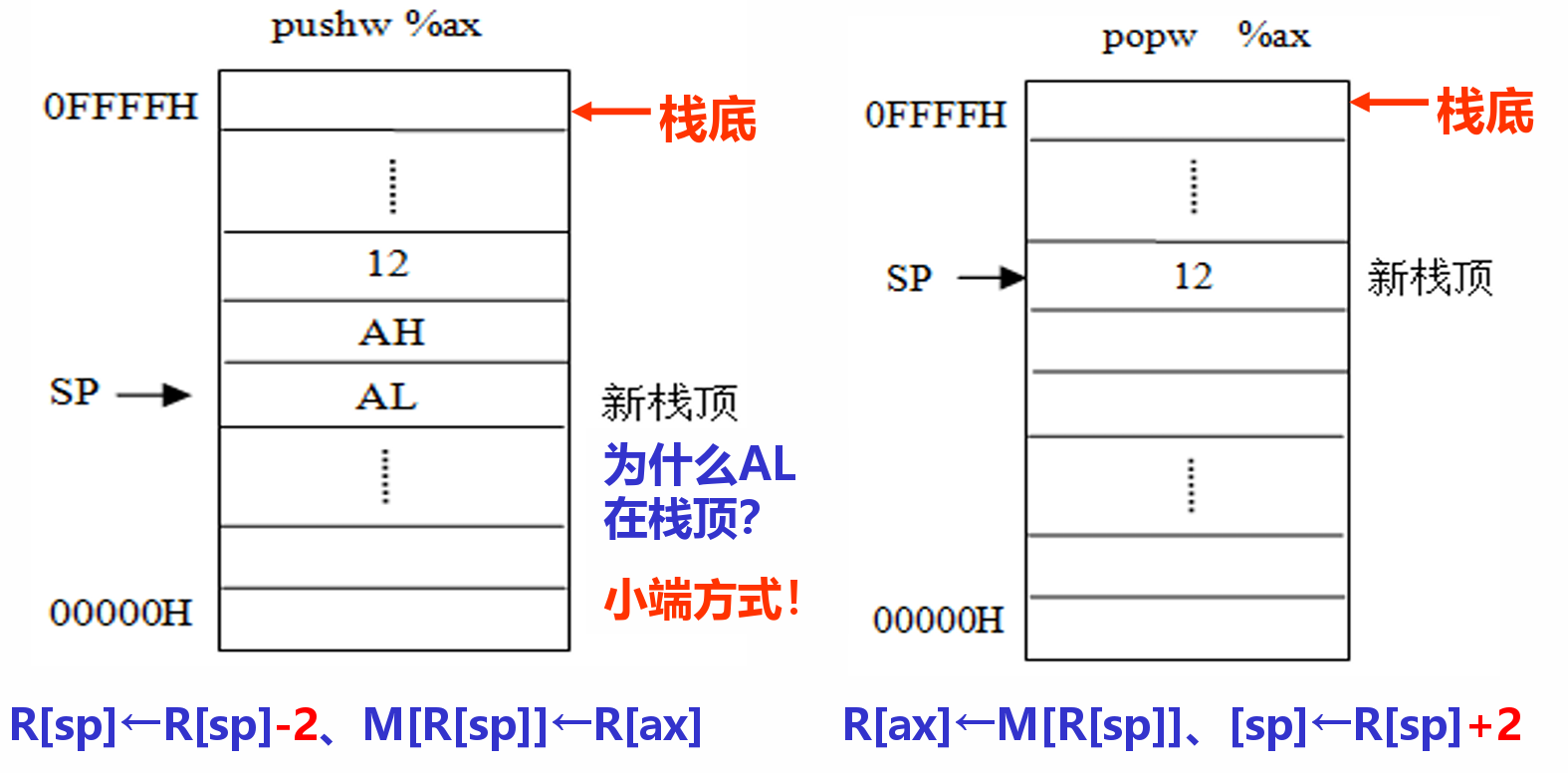
- 入栈时栈顶向低地址移动两个字节,然后写入数据(注意小端要 lsb 匹配低地址)
- 地址传送指令
- LEA:加载有效地址,如leal (%edx,%eax),%eax”的功能为 R[eax]←R[edx]+R[eax](mov为:R[eax]←M(R[edx]+R[eax]),差一个M),执行前,若R[edx]=i, R[eax]=j,则指令执行后,R[eax]=i+j(可以用于加法)
- 输入输出指令
- IN和OUT:I/O端口与寄存器之间的交换
- 标志传送指令
-
PUSHF、POPF:将EFLAG压栈,或将栈顶内容送EFLAG
-


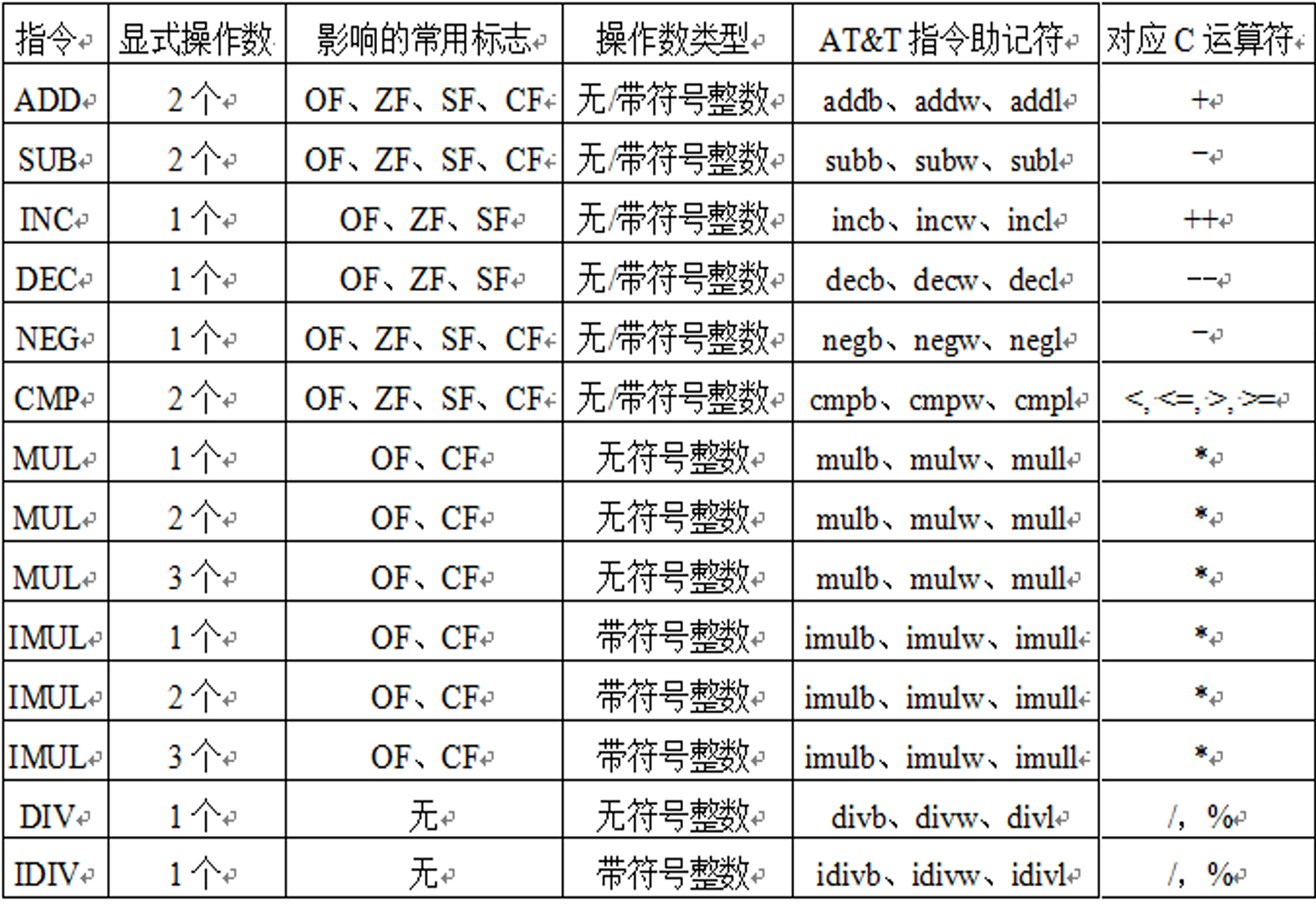
定点算数指令uu¶
- 加/ 减运算(影响标志、不区分无/带符号)
- ADD:加,包括 addb、addw、addl 等等 - SUB:减,包括subb、subw、subl等
- 增1 / 减1运算(影响除CF以外的标志、不区分无/带符号)
- INC:加,包括incb、incw、incl等
- DEC:减,包括decb、decw、decl等
- 取负运算(影响标志、若对0取负,则结果为0则CF=0, 否则CF=1)
- NEG:取负,包括negb、negw、negl等
- 比较运算(做减法得到标志、不区分无/带符号)
- CMP:比较,包括cmpb、cmpw、cmpl等
- 乘/ 除运算(区分无/带符号)
- MUL / IMUL:无符号乘/ 带符号乘(影响标志OF和CF)
- mul:如果乘积的高一半(AH或DX)为0,则OF=CF=0;否则OF=CF=1
- imul高一半全部为符号位扩展则为0,否则为1
- DIV/ IDIV:带无符号除 / 带符号
-

-
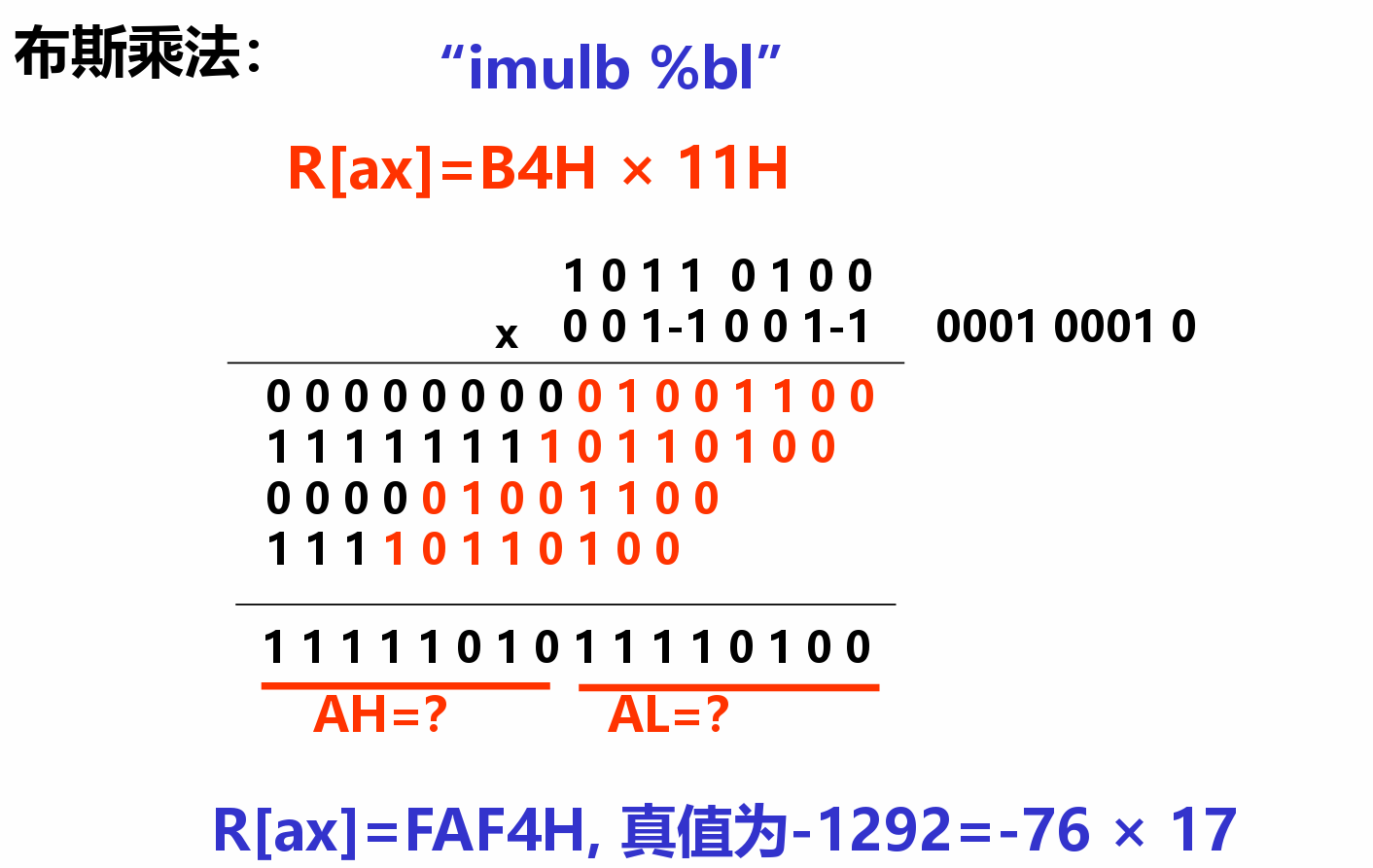
例¶
- (末尾加H也可以表示16进制)
-

-


位运算指令¶
- 逻辑运算(仅NOT不影响标志,其他指令OF=CF=0,而ZF和SF 根据结果设置:若全0,则ZF=1;若最高位为1,则SF=1 )
- NOT:非,包括notb、notw、notl等
- AND:与,包括andb、andw、andl等
- OR:或,包括orb、orw、orl等
- XOR:异或,包括xorb、xorw、xorl等
- TEST:做“与”操作测试,仅影响标志
- 移位运算(左/右移时,最高/最低位送CF)
- SHL/SHR:逻辑左/右移,包括shlb、shrw、shrl等
- SAL/SAR:算术左/右移,左移判溢出,右移高位补符 (移位前、后符号位发生变化,则OF=1 )
- ROL/ROR: 循环左/右移,包括rolb、rorw、roll等
以上均将移出位移入CF- RCL/RCR: 带循环左/右移,将CF作为操作数一部分循环移位

例¶


控制转移指令¶
- 无条件转移指令
- JMP DST:无条件转移到目标指令DST处执行
- 条件转移
- Jcc DST:cc为条件码,根据标志(条件码)判断是否满足条件, 若满足,则转移到目标指令DST处执行,否则按顺序执行
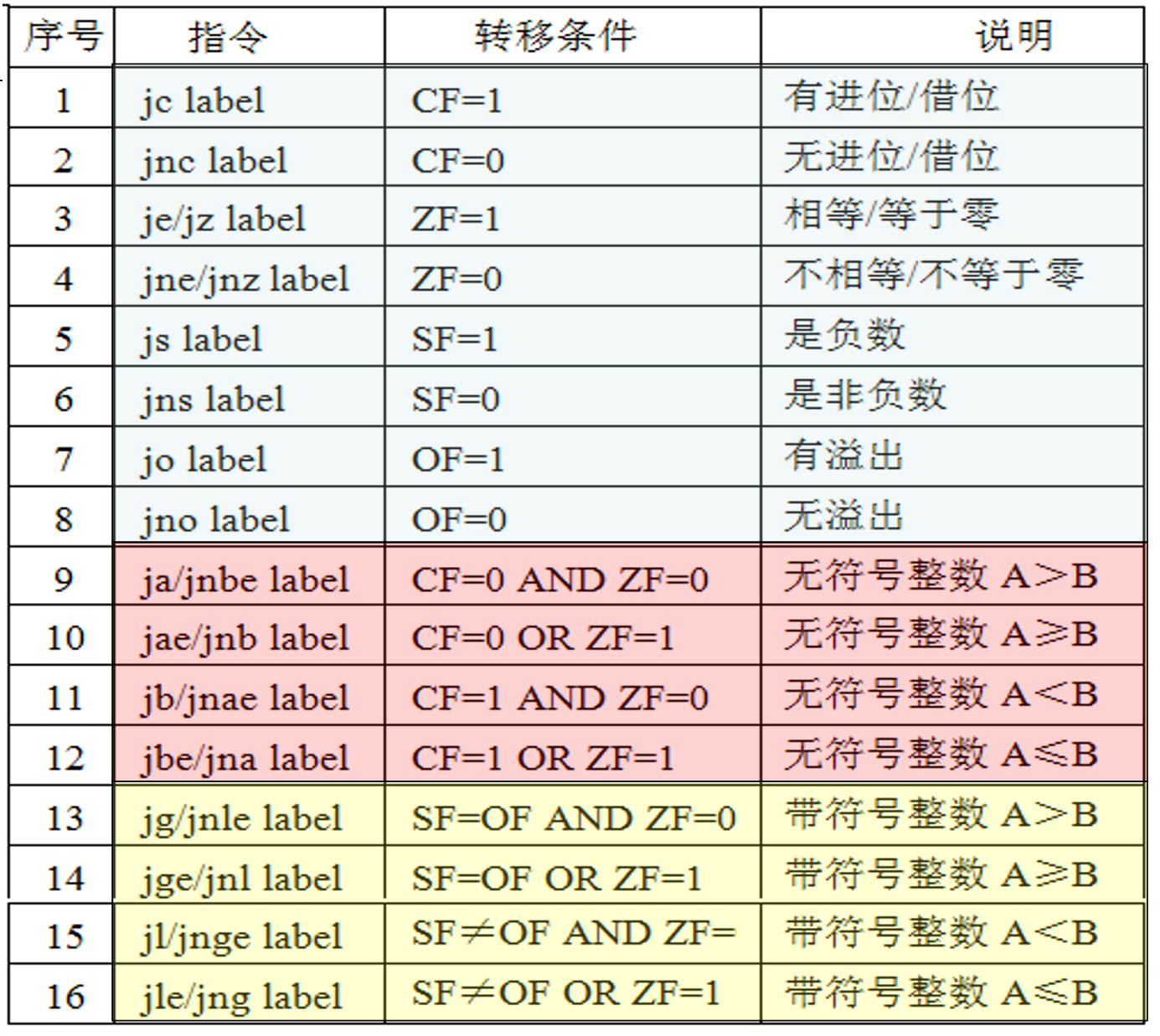
- 条件设置
- SETcc DST:将条件码cc保存到DST(通常是一个8位寄存器,就是操作码后指定的操作数),该操作只能将寄存器的值置为0或1
- 即实现将标志寄存器的状态转化为0/1存储在寄存器中
- 其设置的条件值与条件转移指令的转移条件值完全一样, 指令助记符也类似, 只要将J换成SET即可。
- 调用和返回指令
- CALL DST:返回地址RA入栈,转DST处执行
- 将返回地址(call指令下面一条地址)入栈
- 跳转到指定地址处执行
- tip:题目问执行call后的情况,指的进行跳转之前的情况
- leave: 将esp移至ebp,然后从栈中pop到ebp(回复ebp和esp)
- RET:从栈中取出返回地址RA到eip中,转到RA处执行
- 主程序继续执行通常放在子程序的末尾, 使子程序执行后返回
- *条件传送指
- 该类指令的功能是,如果符合条件就进行传送操作,否则什么都不做,只要将J换成CMOV即可
- 例如,对应表3.6中序号1的指令“cmovc%eax, %edx",其含义为:若 CF= 1,则R[edx]<------R[ eax];否则什么都不做。
- tip:对于相对寻址跳转如部分jmp、jcc、call,目标地址由三部分组成:
eip中当前地址+指令长度+偏移量
浮点数处理指令¶
浮点数寄存器¶
- 浮点协处理器x87架构
- 8个80位寄存器ST(0) ~ ST(7)(采用栈结构),栈顶为ST(0)
- 由MMX发展而来的SSE架构
- MMX指令使用8个64位寄存器MM0~MM7,借用8个80位寄存器 ST(0)~ST(7)中64位尾数所占的位,可同时处理8个字节,或4个字, 或2个双字,或一个64位的数据
- SSE指令集将80位浮点寄存器扩充到128位多媒体扩展通用寄存器 XMM0~XMM7,可同时处理16个字节,或8个字,或4个双字(32 位整数或单精度浮点数),或两个四字的数据,
-
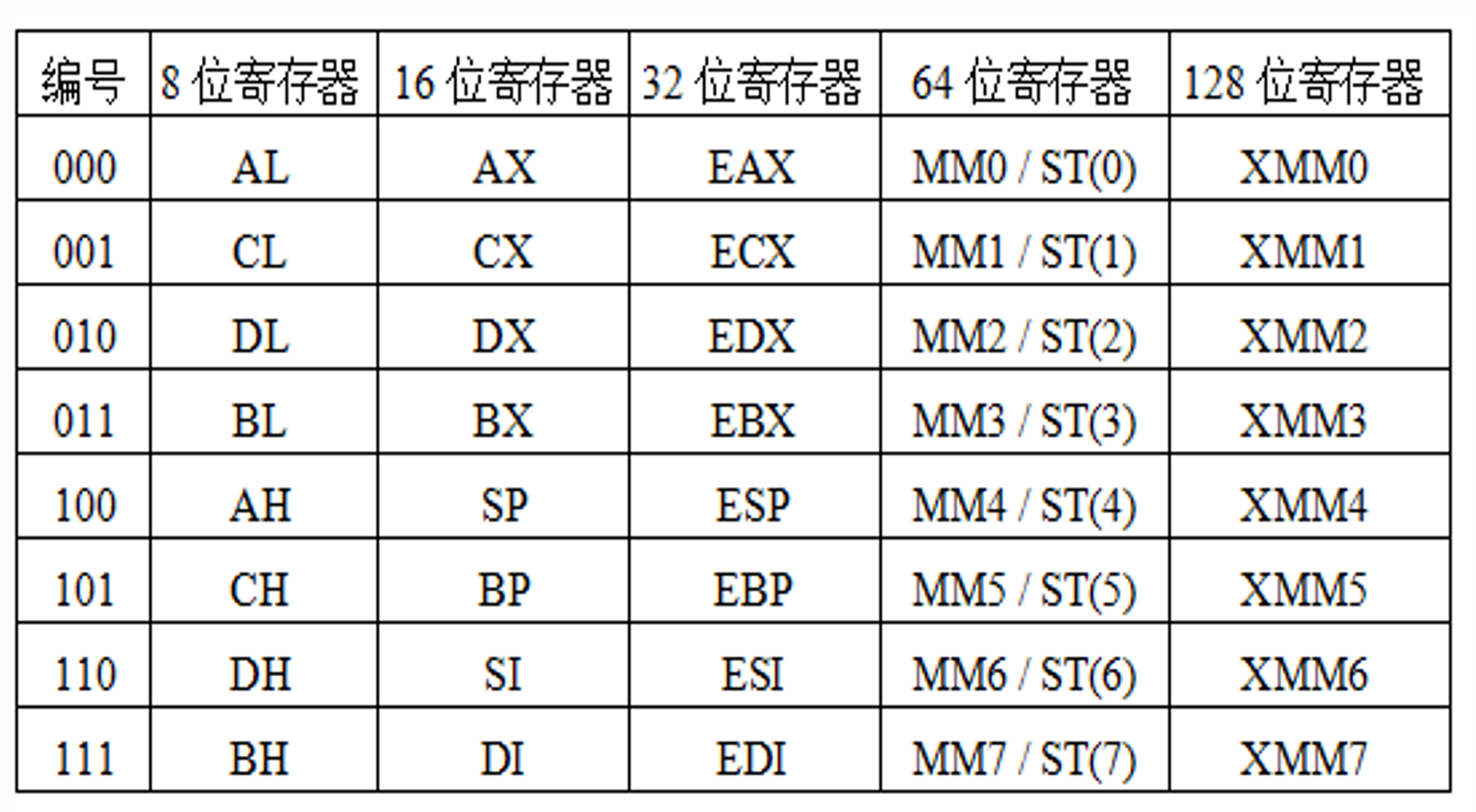
-
所有浮点数运算使用80位扩展运行: 1位符号位s、15位阶码e(偏置常数为16 383)、1位显式首 位有效位j 和 63位尾数f 。它与IEEE 754单精度和双精度浮点格式的一个重要的区别是 ,它没有隐藏位,有效位数共64位。
指令分类¶
- 数据传送:

- I表示从int转化为浮点数传入或浮点型转化为int传出,P表示操作后pop,R表示调换操作顺序

- 运算


例¶




C语言程程序的机器级表示¶
过程(函数)调用的机器级表示¶
调用过程¶
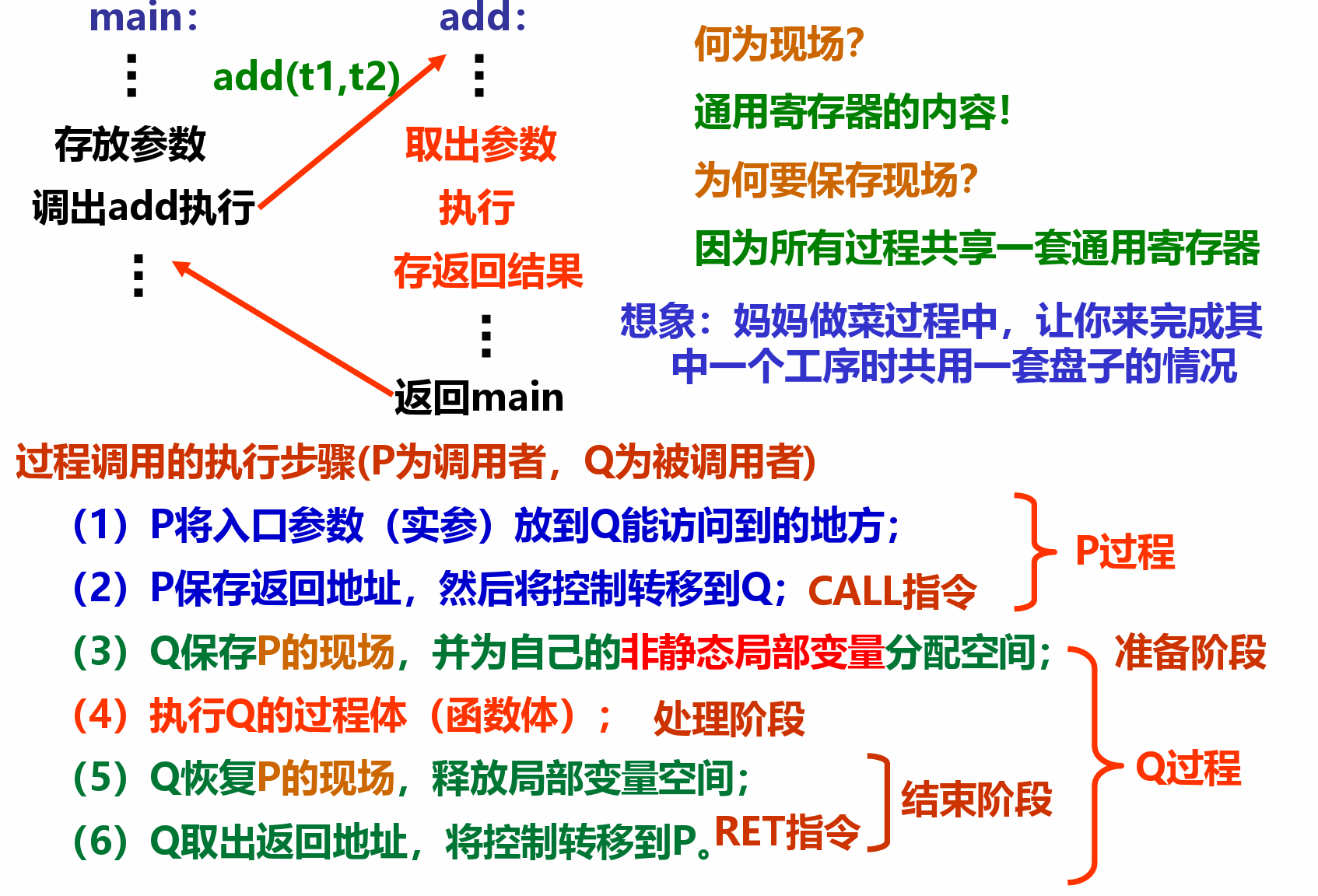
- 例
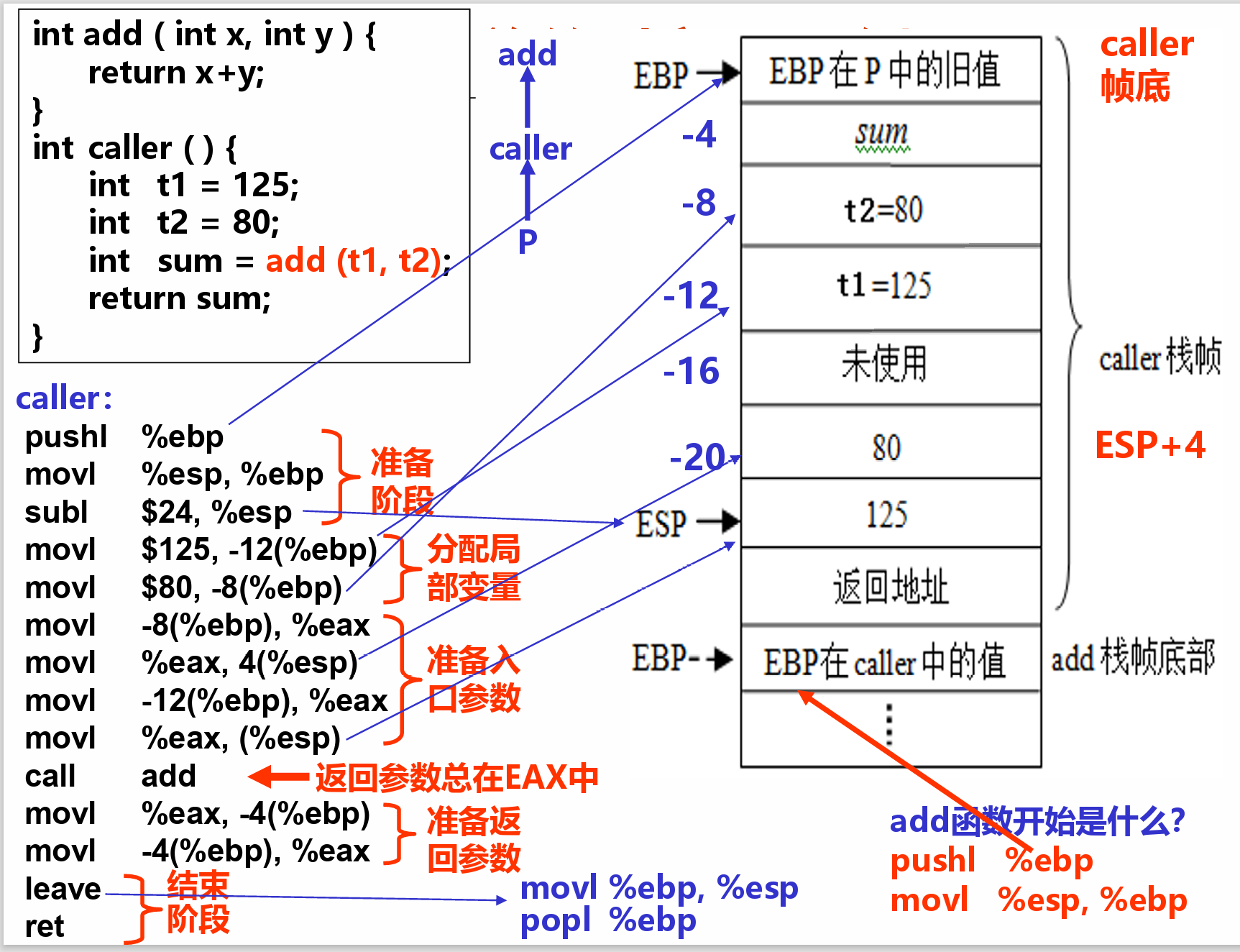
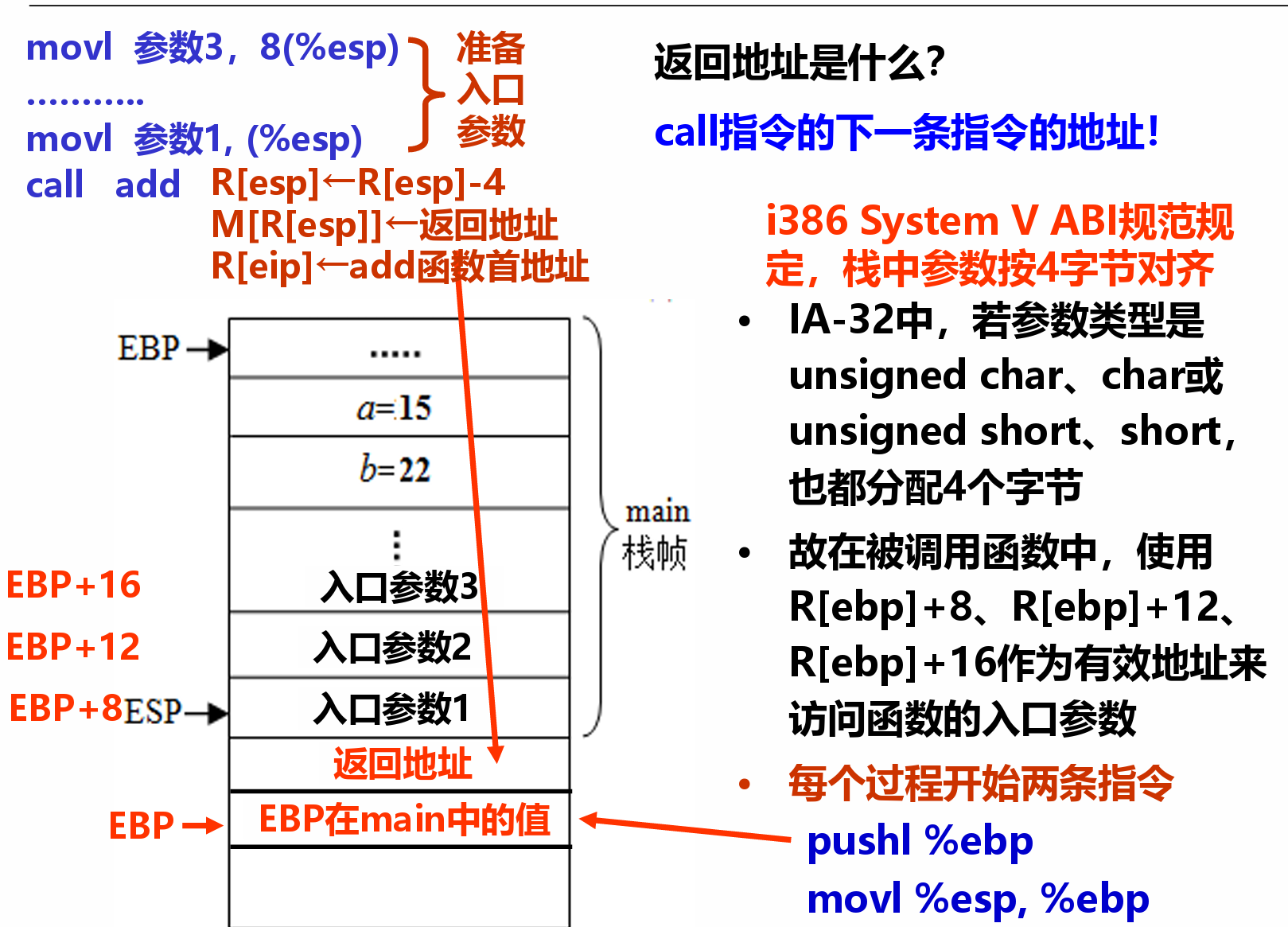
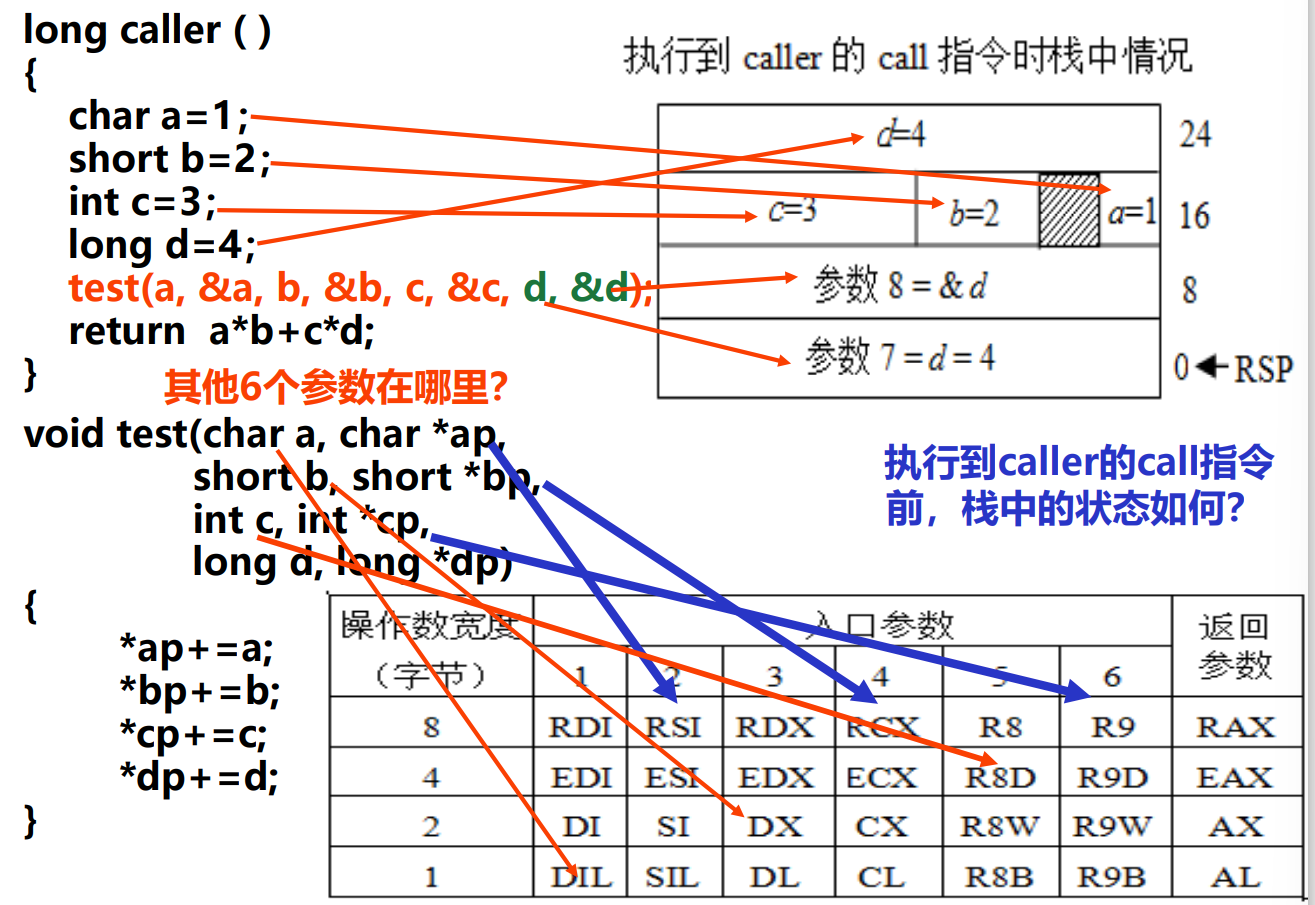
- 注意形参压栈是按照从右到左的形式进行
- 准备阶段
- 形成帧底:push指令和mov指令
- 把ebp旧值push,再重置esp ebp(将ebp指向esp所指向的栈顶)
- 生成栈帧(每个过程自己的栈区):sub指令或and指令(把esp移动到新的栈顶)由于栈帧的大小必须是16字节的倍数,因此会存在未使用的部分
- 保存现场(如果有被调用者保存寄存器):push指令
- 过程(函数)体
- 分配局部变量空间,并赋值
- 具体处理逻辑,如果遇到函数调用时
- 准备参数:将实参送栈帧入口参数处
- CALL指令:保存返回地址并转被调用函数
- 在EAX中准备返回参数
- 结束阶段
- 退栈:leave指令或pop指令
- 取返回地址返回:ret指令
- 结束时重置esp ebp
- 并将存储在栈中的ebp值取回到寄存器
- pop掉ebo以及被调用者保存寄存器,将数据装回寄存器进行恢复
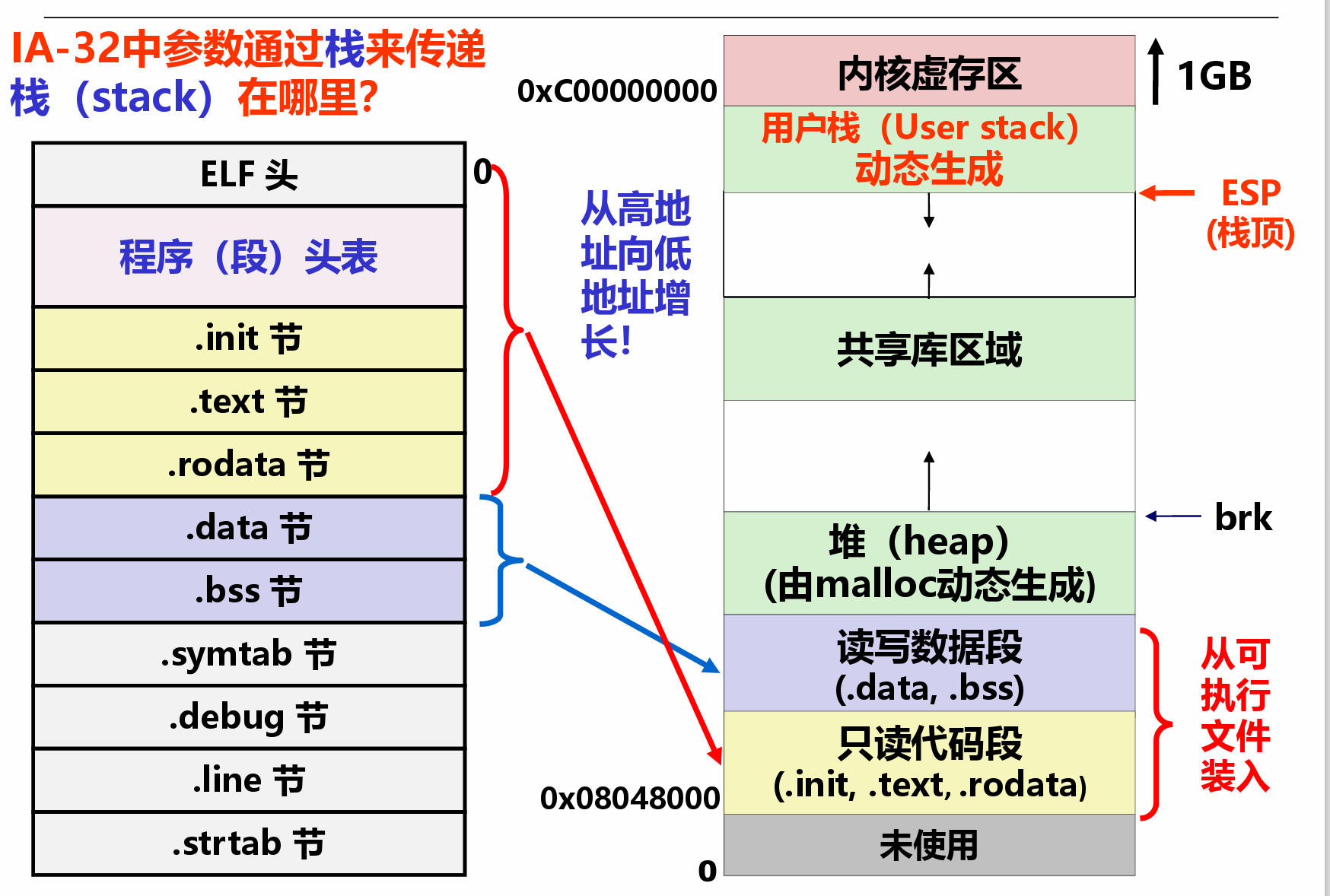
数据存储(栈结构)¶
-
在过程调用中,需要为入口参数、返回地址、调用过程执行时用到的寄存器、被调用过程中的非静态局部变址、过程返回时的结果等数据找到存放空间。由于寄存器的空间有限、并且无法存储一些复杂数据结构,需要一个专门的区域来保存这些数据,这个区域就是栈
-
栈结构:
- 调用者保存寄存器:EAX、EDX、ECX
- 当过程P调用过程Q时,Q可以直接使用这三个寄存器,不用 将它们的值保存到栈中。如果P在从Q返回后还要用这三个寄存器的话,P应在转到Q之前先保存,并在从Q返回后先恢复它们的值再使用。
- 被调用者保存寄存器:EBX、ESI、EDI
- Q必须先将它们的值保存到栈中再使用它们,并在返回P之前 恢复它们的值。
- 如果使用了被调用者保存寄存器,则要将其值先压栈暂存(在EBP下面)(方便之后进行还原)
- EBP和ESP分别是帧指针寄存器和栈指针寄存器,分别用来指 向当前栈帧的底部和顶部。
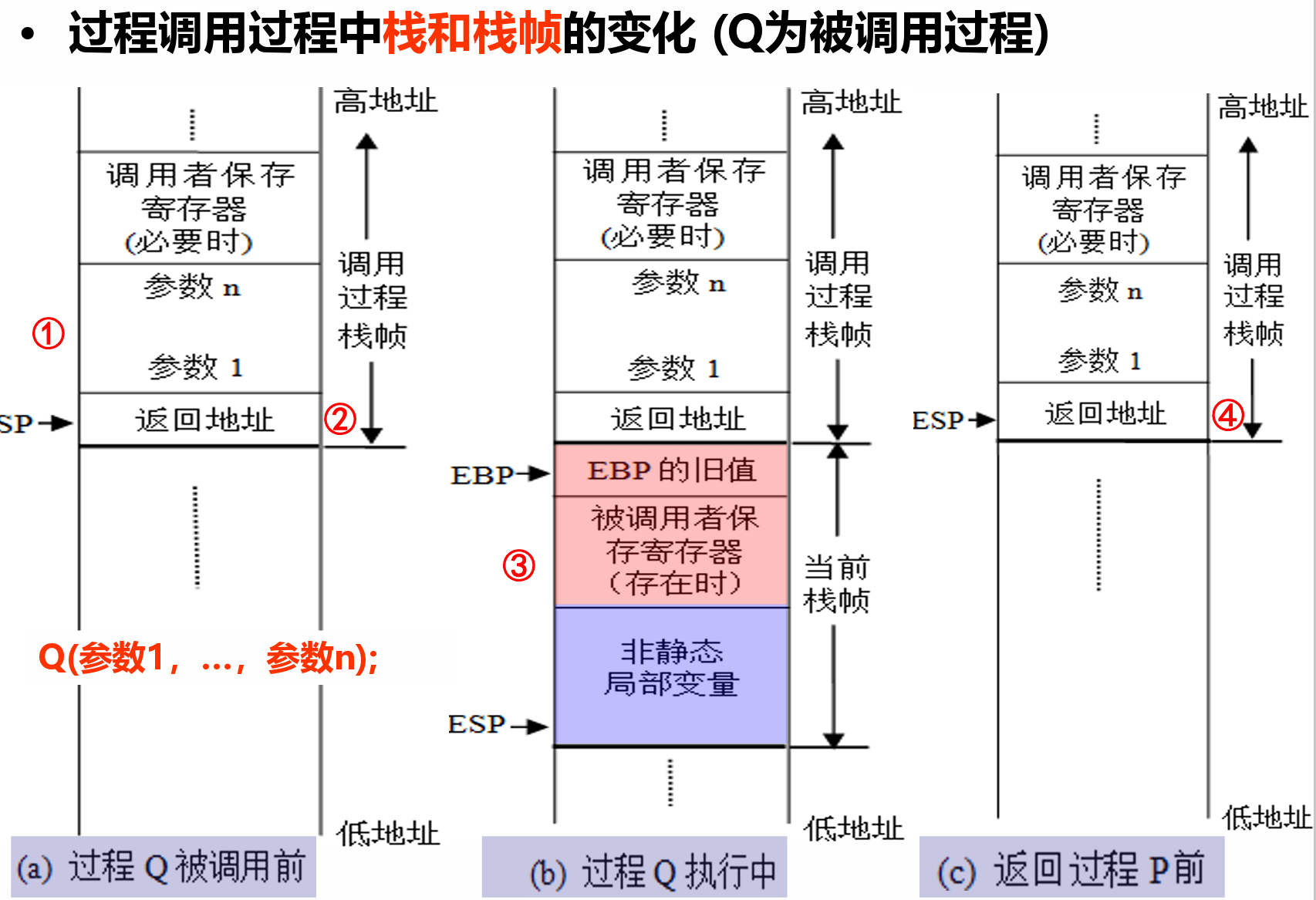
ebp+8(跨过ebp旧值和返回地址)总是表示第一个变量(入口参数)的地址
*非静态局部变量的内存分配¶
-
对于非静态局部变量的分配顺序,C 标准规范中没有规定必须是按顺序从大地址到小地址分配,或是从小地址到大地址分配,因而它属于未定义行为,不同的编译器有不同的处理方式。
-
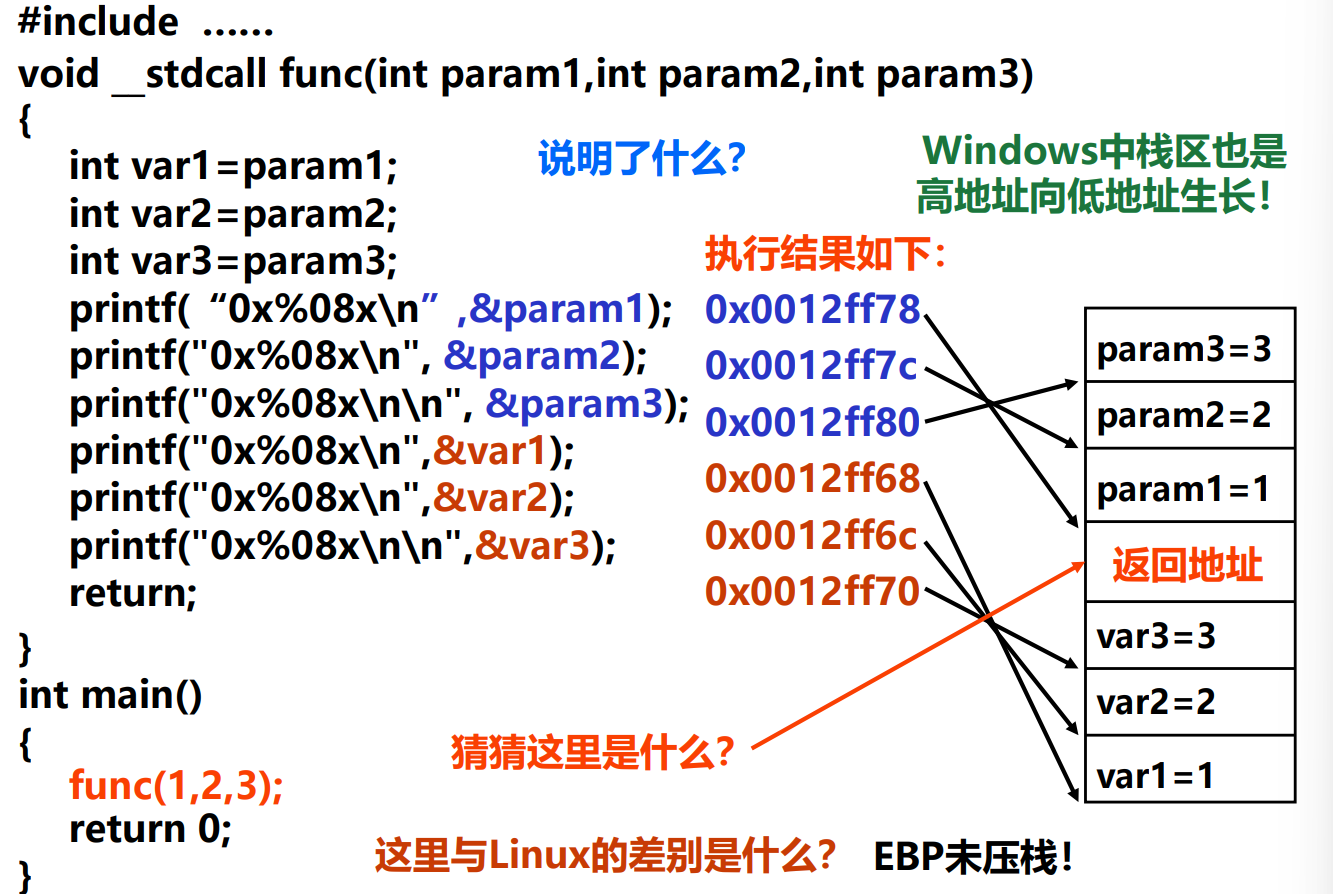
- 返回地址之前的部分输入调用函数的栈帧,后面才是被调用函数的栈帧

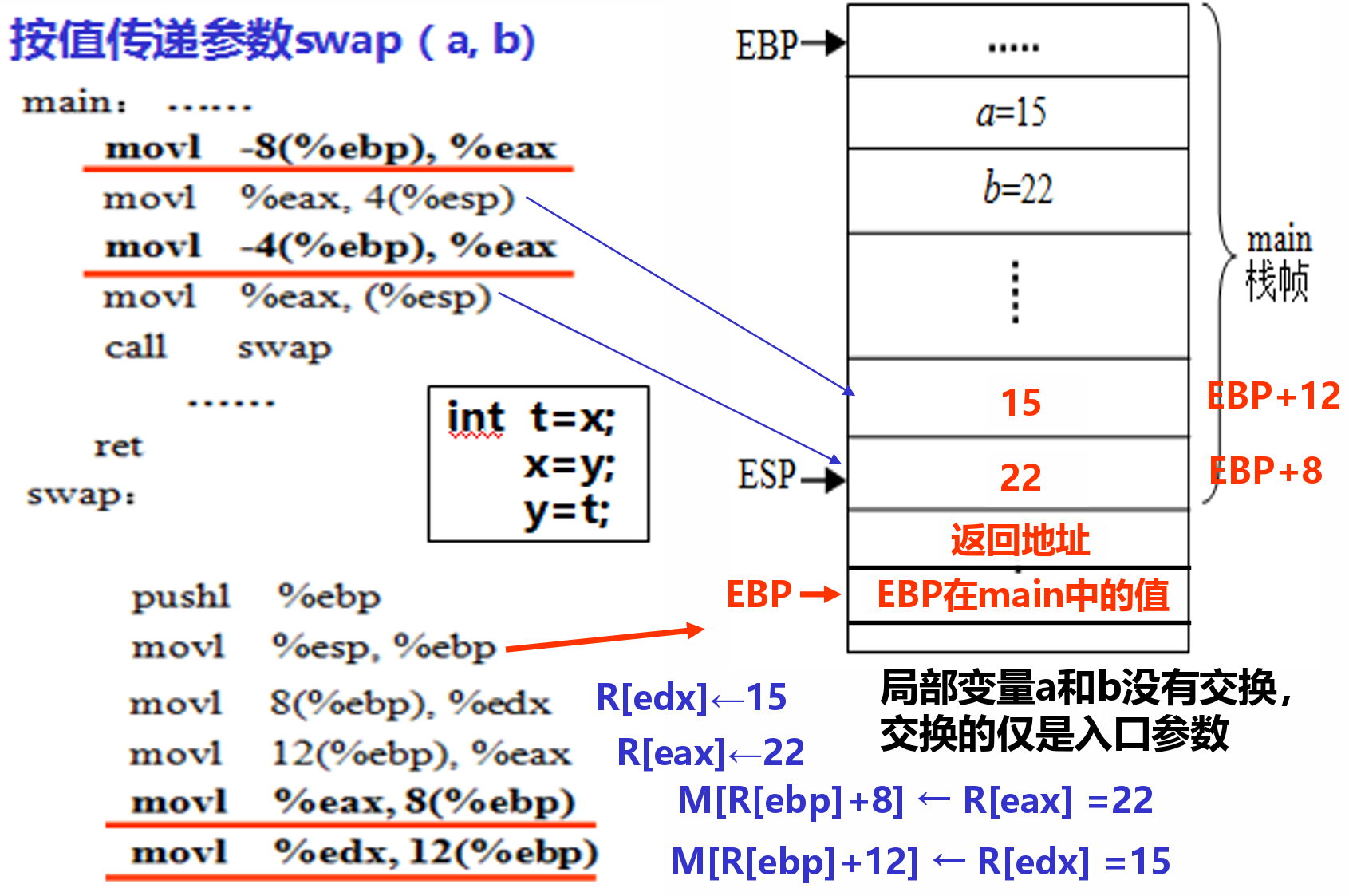
值传递与地址传递¶
-

-
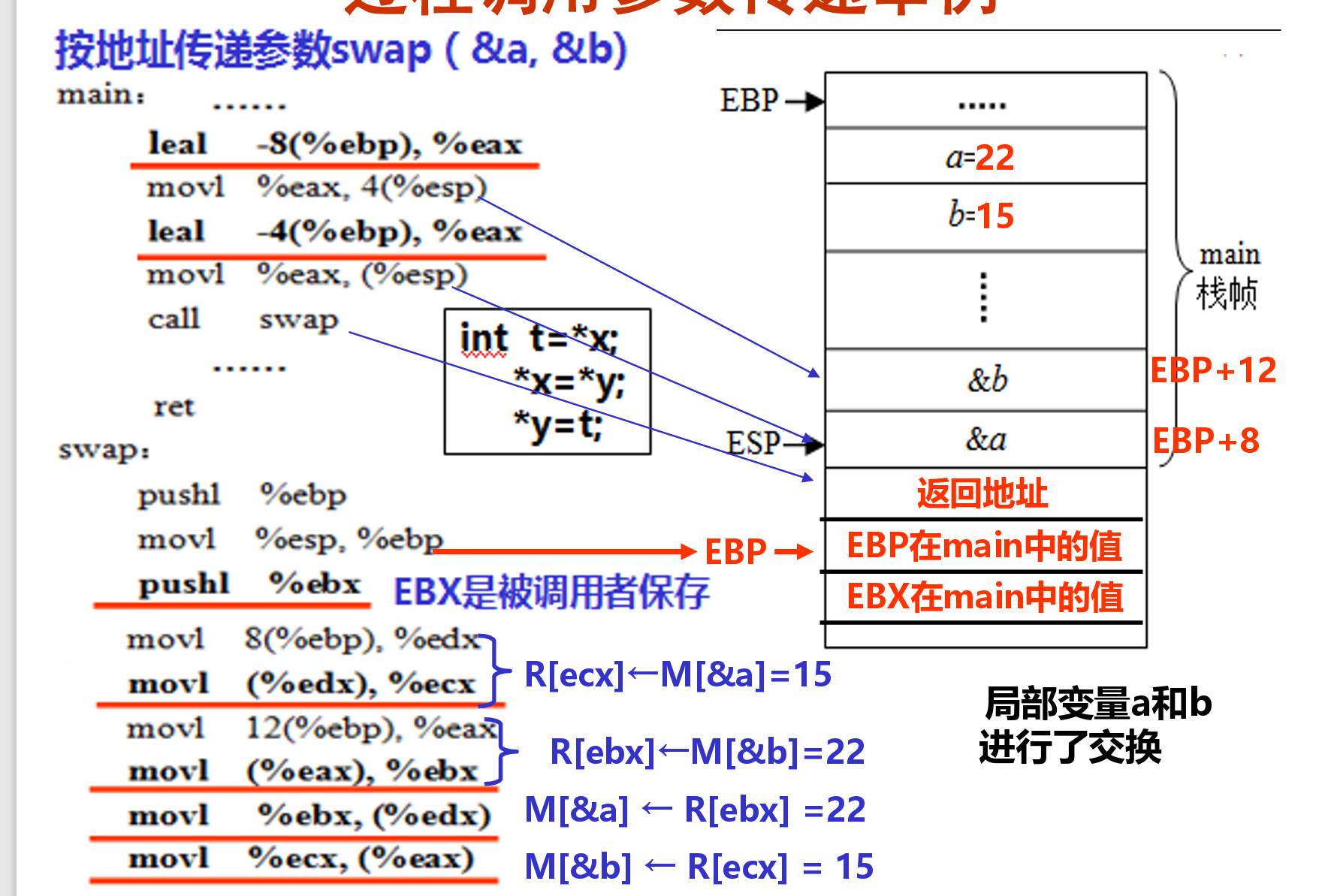
- 使用leal实现把地址传递
-
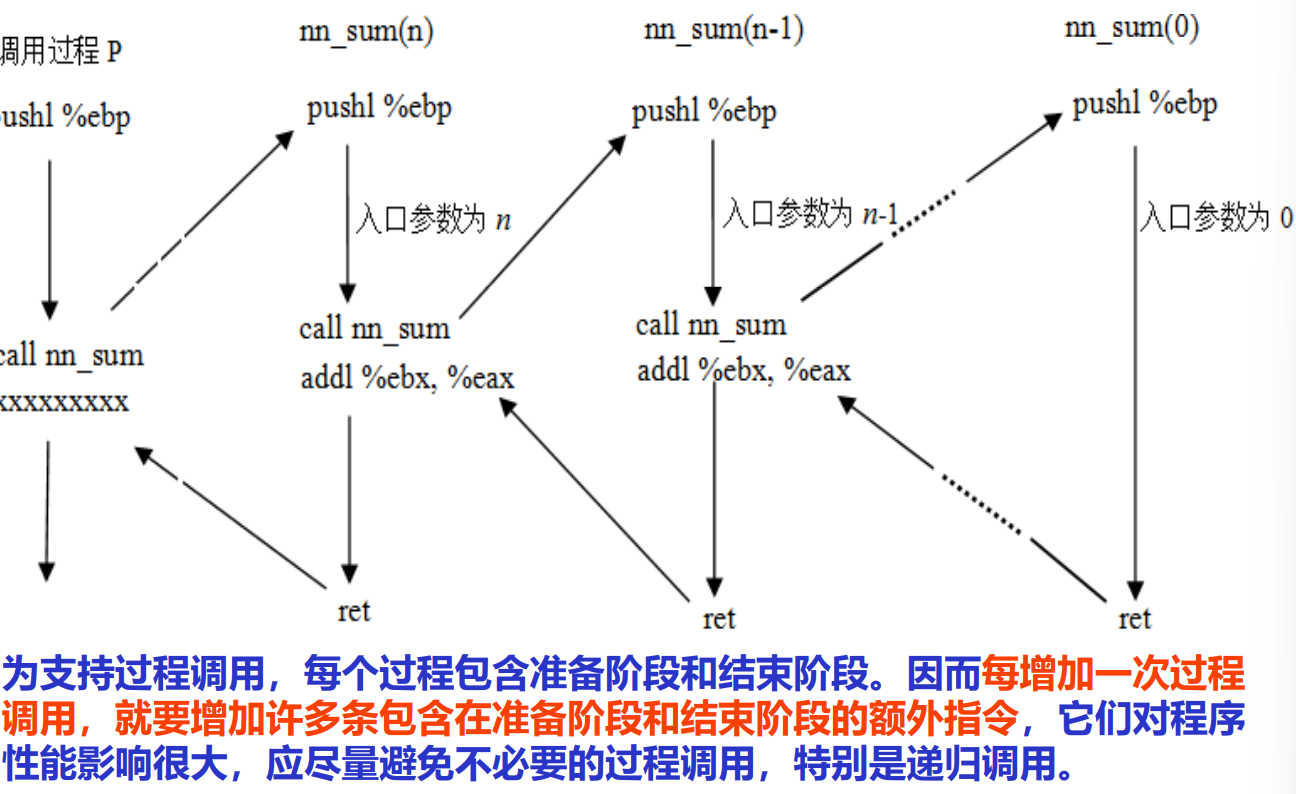
递归函数¶
- 自然数求和

循环与条件语句¶

- 以用一个跳转表来实现a的取值与跳转标号之间的对应关系



- 例
- ****

补充例子¶
- 数组越界的影响

- 在栈中a数组越界,改变了d的值
复杂数据类型的分配和访问¶
数组的分配和访问¶
- 数组可以定义为静态存储型(static)、外部存储(extern)、自动存储型(auto),或者定 义为全局静态区数组,其中,只有auto型数组被分配在栈中,其他存储型数组都分配在静态数 据区。
内存分配与存储¶
- 假定数组 A 的首地址存放在 EDX 中,i 存放在 ECX 中,现要将 A[i] 取到 AX 中
movw (%edx, %ecx, 2), %ax - 称ECX为变址(索引)寄存器,在循环体中(数组遍历)增量
- 全局变量数组

- (buf等于edx的值,都是表示数组的首地址)
- 存放在静态区(每个元素都是小段方式存储)
- 局部变量数组

- 存放在栈上(栈的每个格内是大端方式)
- 注意lea是取地址赋给edx
数组与指针(访问)¶

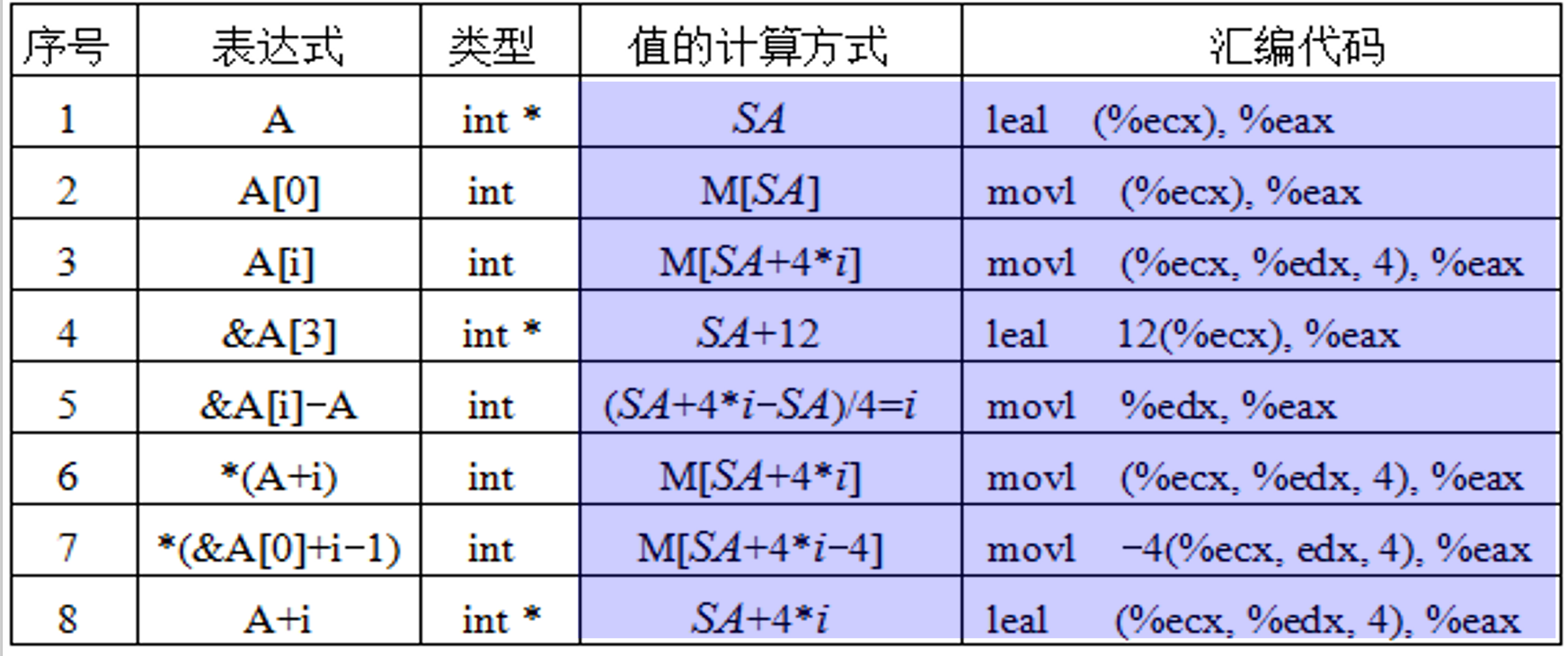
- 注意区分mov和lea(区别在于是将地址转移,还是将值转移)
多维数组与指针数组¶

- num按照小端方式存储元素
- pn中存储的是两个地址(num[0] num[1])
结构体¶

- 通过首地址加上一个偏移量来访问每一个元素
- 两种传递方式:
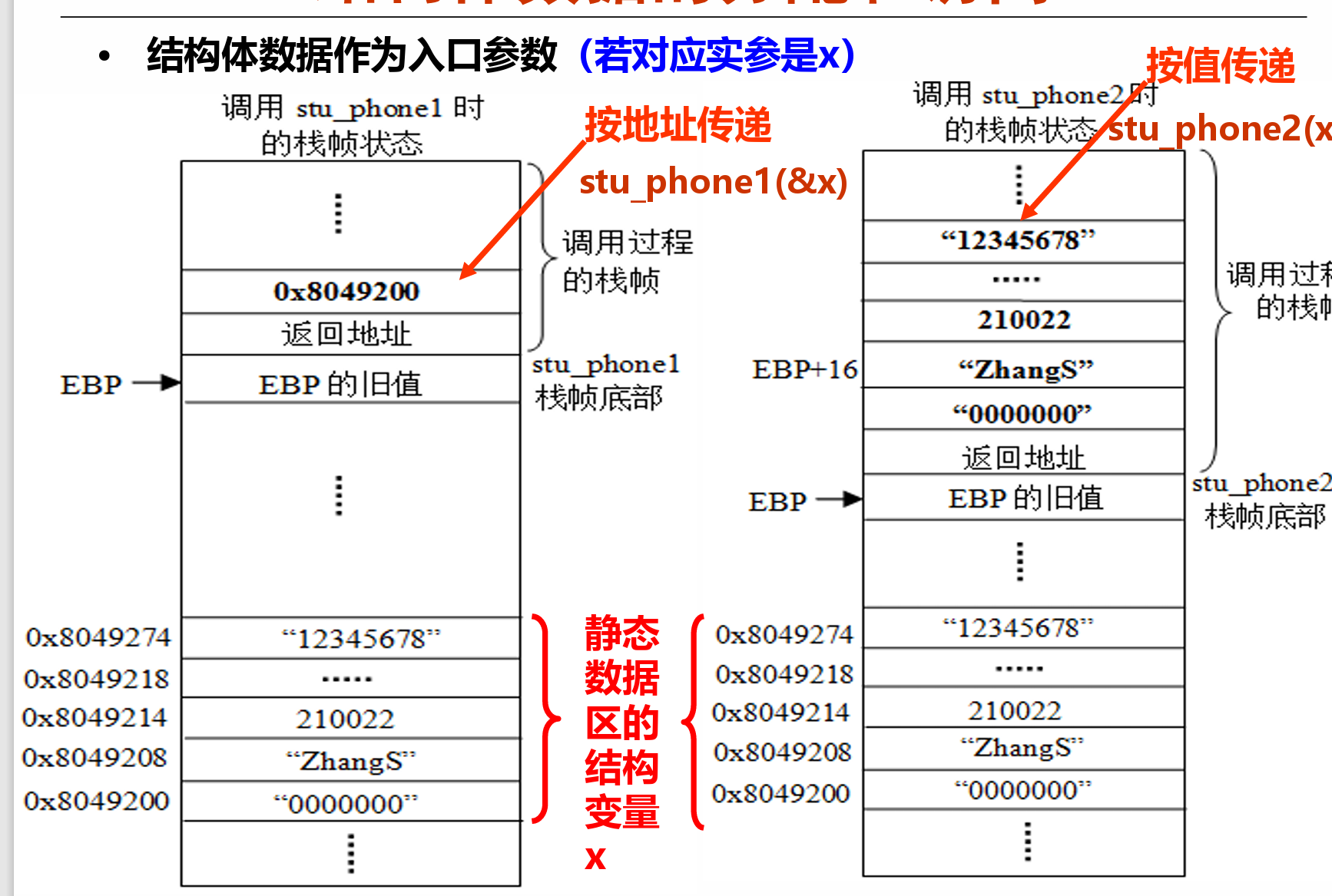
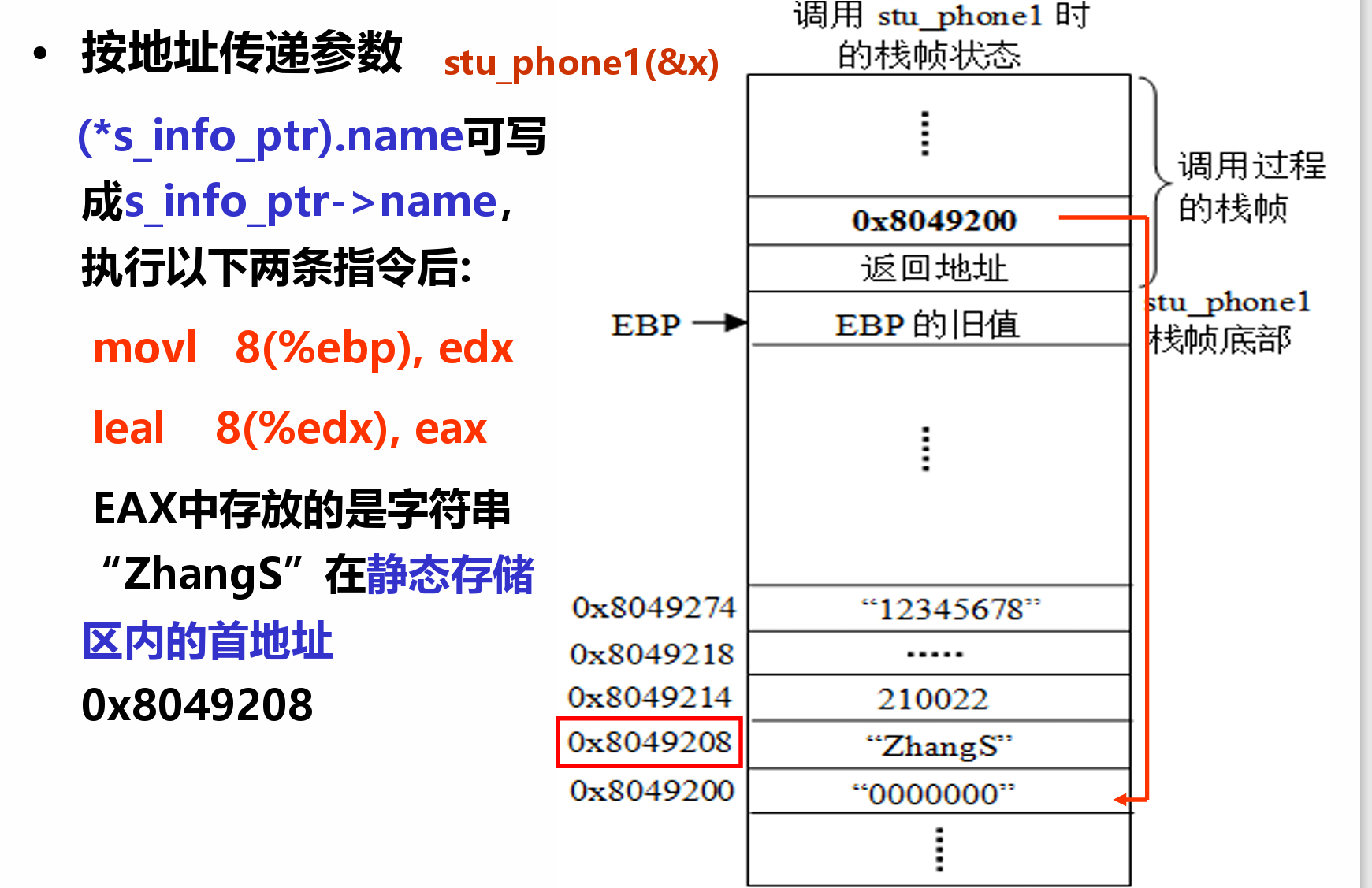
- 先取出结构体的首地址(ebp+8),这个首地址是本质上是个值(不等于edp+8)所以用mov
- 再根据地址偏移找到对应的成员

- 要的地址就是ebp+8所以用lea
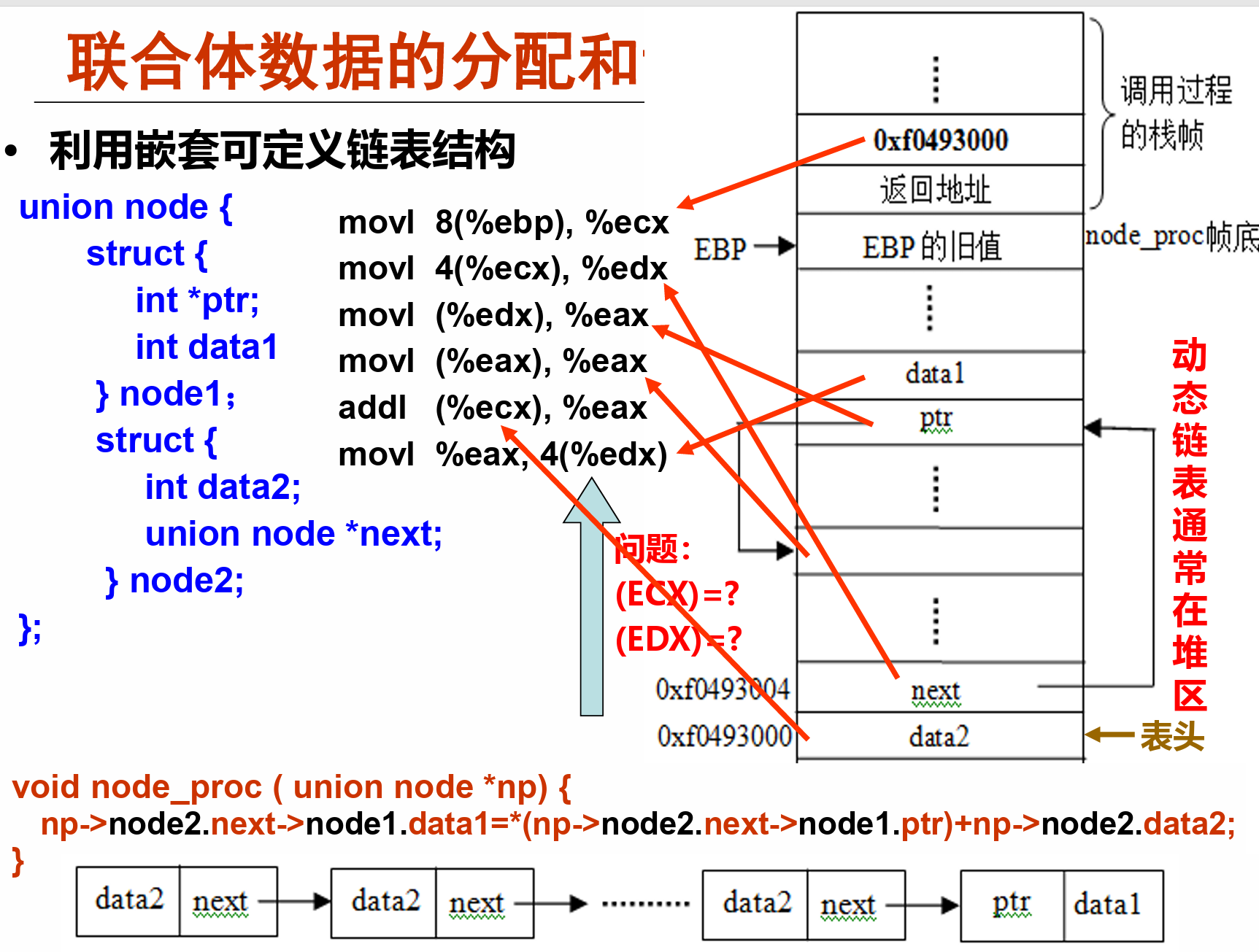
联合类型¶

数据对齐¶
- CPU访问主存 时只能一次读取或写入若干特定位(例如,若每次最多读写64位,则第0-7字节可同时读写,第8 15字节可同时读写,……)
- 因此如果数据的存储不满足这个规律则会导致对统一数据需要多次存取才能完整的到数据,会降低效率,因此需要进行对齐
- 按边界对齐可使读写数据位于8i~8i+7(i=0,1,2,…) 单元内
- 最简单的对齐策略是,按其数据长度对齐。
- windows:int型地址是4的倍 数,short型地址是2的倍数,double和long long型则8的倍数 ,float型是4的倍数,char不对齐(指的是他们存储的起始地址)
- linux:short型为2字节边界对齐,char不对齐,其 他(包括自定义数据类型如struct)的如int、double、long double和指针等类型都是4字节边界 对齐(即为4的倍数)。

结构体对齐¶

- 结构体前面插,中间插,尾插
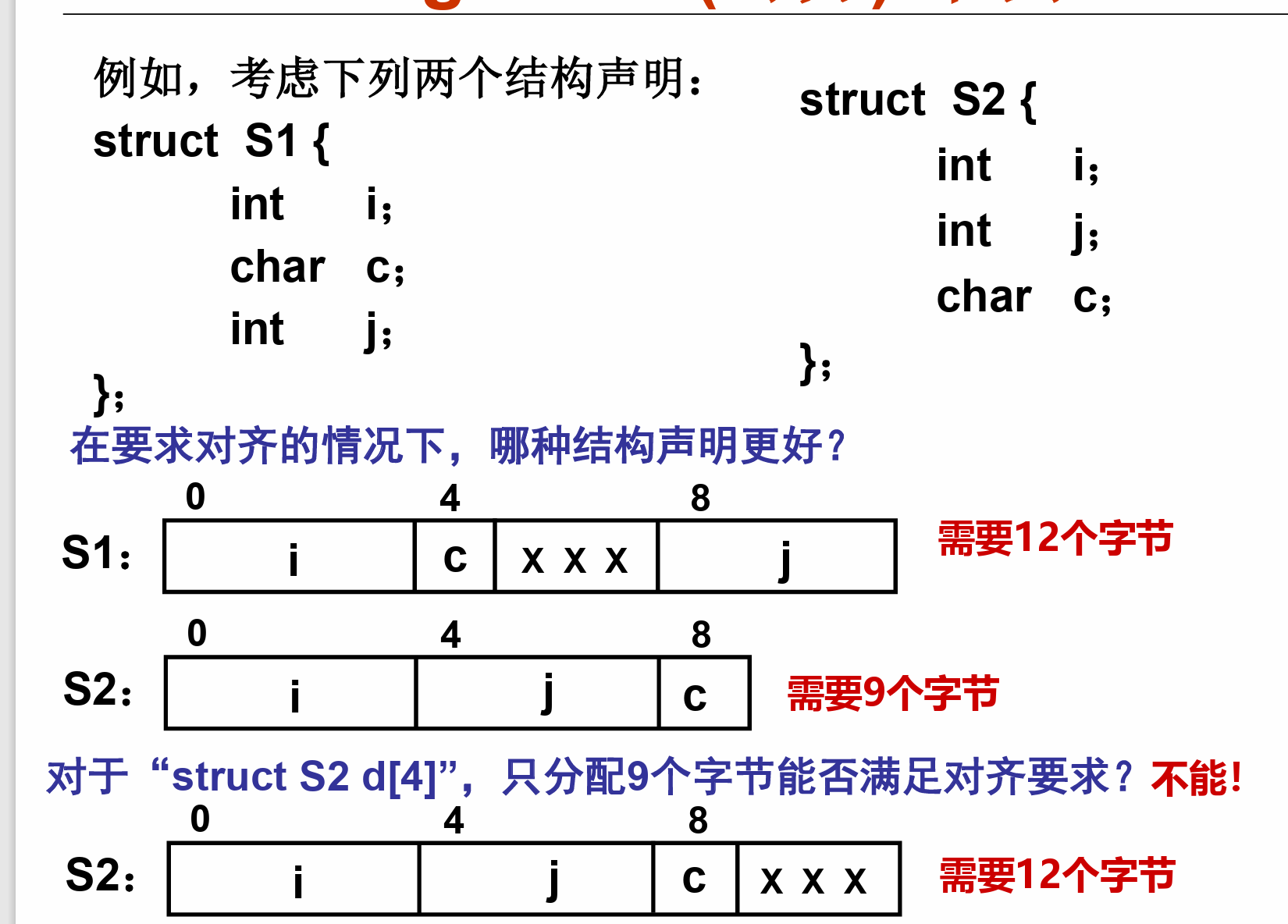
c语言对齐方式的设定¶

\#pragma pack(n)表示的是自然边界比n大时采用n对齐__attribute__((aligned(m)))指的是整个结构体(变量)的内存要按m对齐(起始、结束位置、长度)


__attribute__((packed))优先级更高
越界访问和缓冲区溢出¶
- C语言中的数组元素可使用指针来访问,因而对数组的引用没有边界 约束,也即程序中对数组的访问可能会有意或无意地超越数组存储区 范围而无法发现
- 数组存储区可看成是一个缓冲区,超越数组存储区范围的写入操作称为缓冲区溢出
- 缓冲区溢出攻击是利用缓冲区溢出漏洞所进行的攻击行动。利用缓冲 区溢出攻击,可导致程序运行失败、系统关机、重新启动等后果
例:利用缓冲区溢出转到自设的程序hacker去执行¶
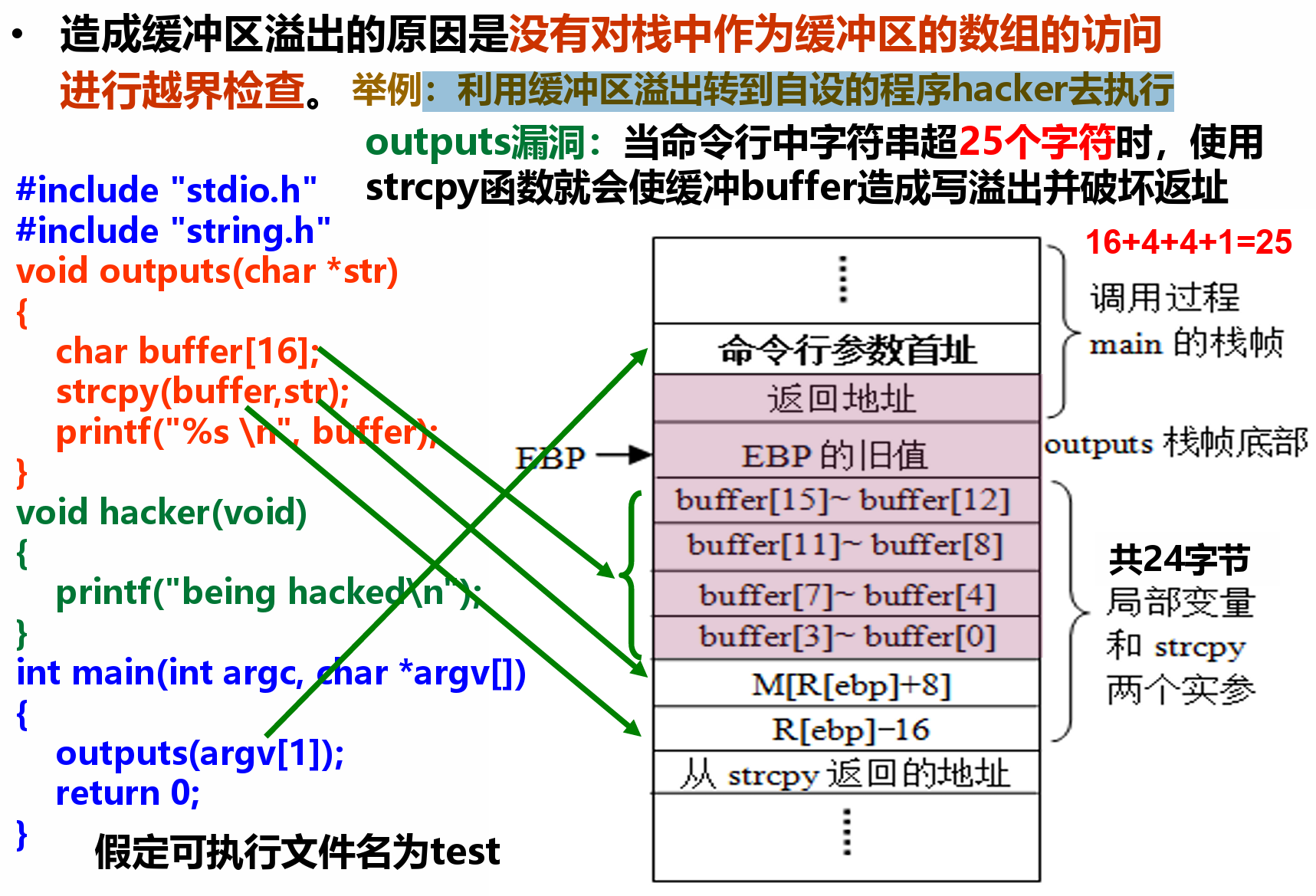
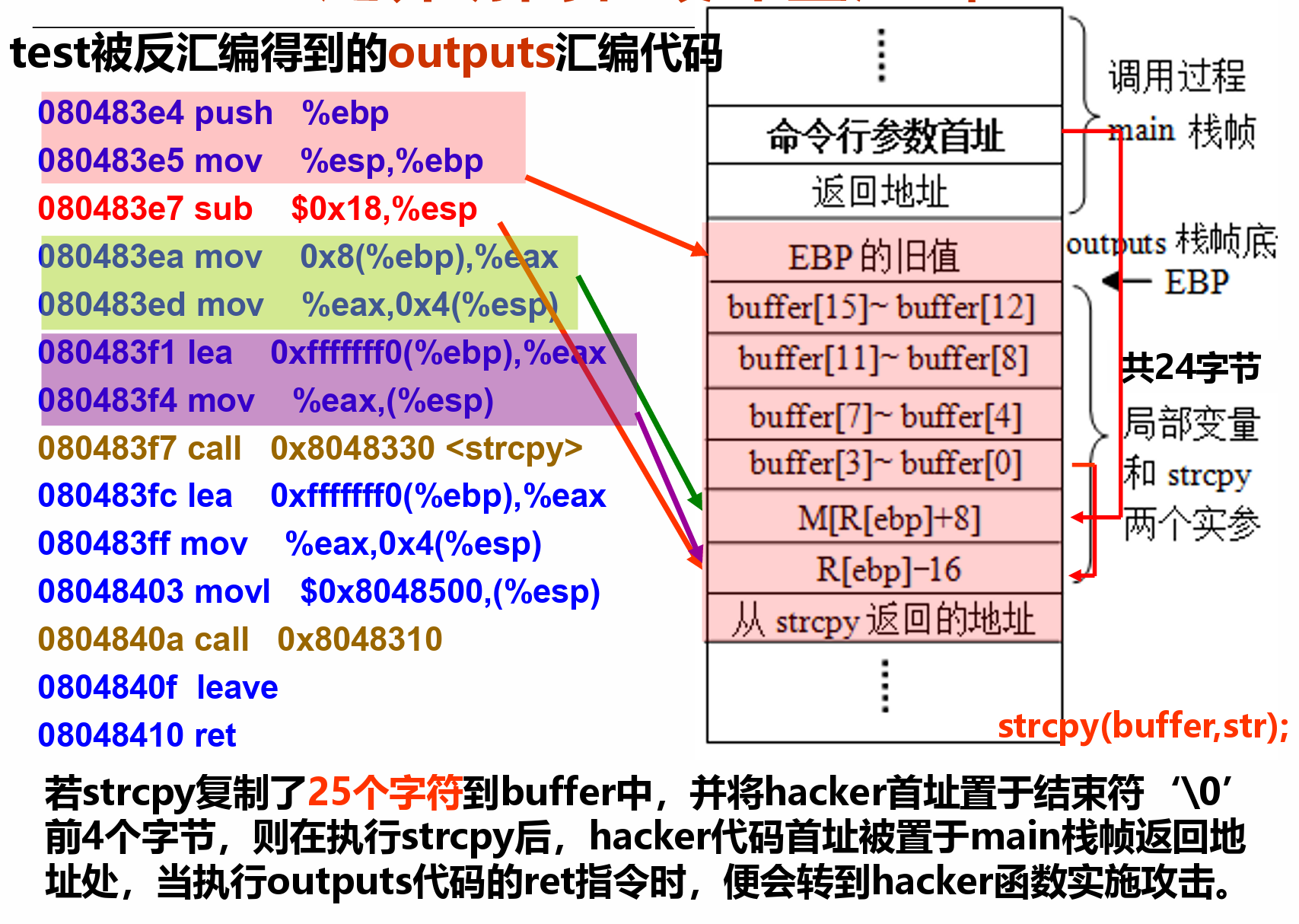
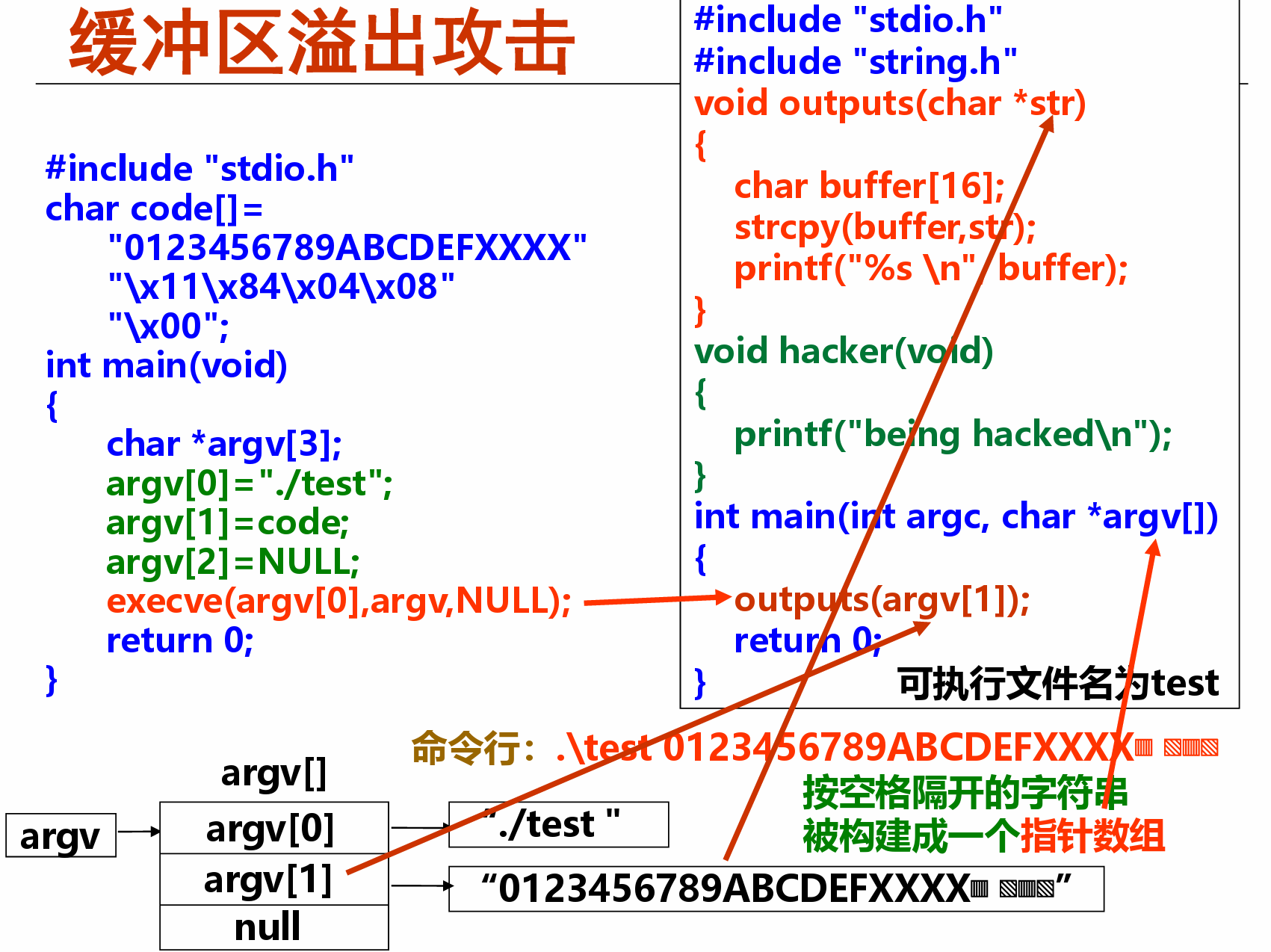
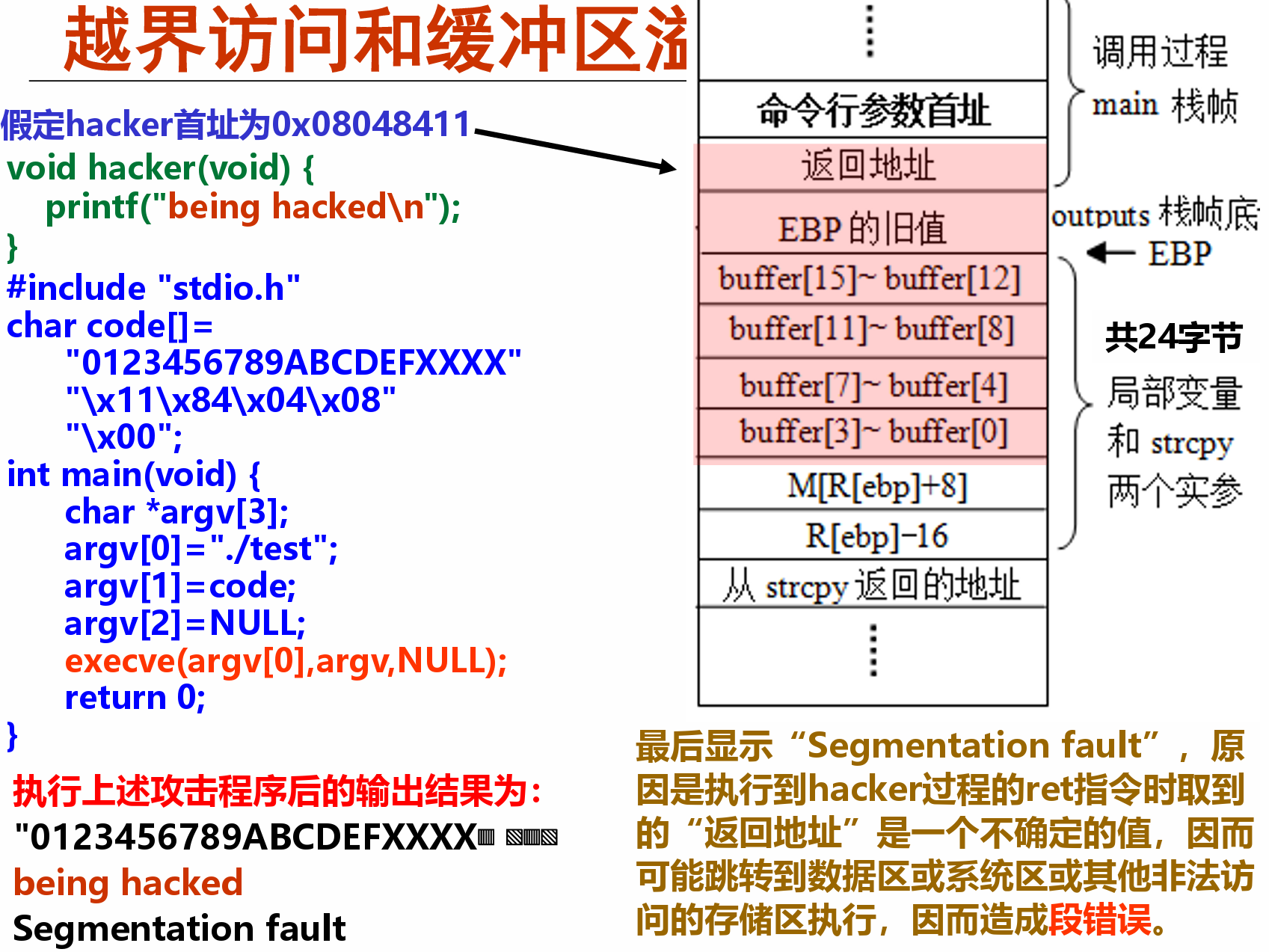
*缓冲区溢出攻击的防范¶
- 从程序员角度去防范
- 用辅助工具帮助程序员查漏,例如,用grep来搜索源代 码中容易产生漏洞的库函数(如strcpy和sprintf等)的 调用;用fault injection查错
- 从编译器和操作系统方面去防范
- 地址空间随机化ASLR 是一种比较有效的防御缓冲区溢出攻击的技术 目前在Linux、FreeBSD和Windows Vista等OS使用
- 只要操作系统相同,则栈位置 就一样,若攻击者知道漏洞程 序使用的栈地址空间,就可设 计一个针对性攻击,在使用该 程序机器上实施攻击–地址空间随机化(栈随机化) 的基本思路是,将加载程序时 生成的代码段、静态数据段、 堆区、动态库和栈区各部分的 首地址进行随机化处理,使每 次启动时,程序各段被加载到 不同地址起始处–对于随机生成的栈起始地址, 攻击者不太容易确定栈的起始 位置
- 栈破坏检测
- 若在程序跳转到攻击代码前能检测出程 序栈已被破坏,就可避免受到严重攻击–新GCC版本在代码中加入了一种栈保护 者(stack protector)机制,用于检测 缓冲区是否越界–主要思想:在函数准备阶段,在其栈帧 中缓冲区底部与保存寄存器之间(如 buffer[15]与保留的EBP之间)加入一 个随机生成的特定值;在函数恢复阶段 ,在恢复寄存器并返回到调用函数前, 先检查该值是否被改变。若改变则程序 异常中止。因为插入在栈帧中的特定值 是随机生成的,所以攻击者很难猜测出
- 可执行代码区域限制
- 通过将程序栈区和堆区设置为不可执行,从而使得攻击者不可能 执行被植入在输入缓冲区的代码,这种技术也被称为非执行的缓 冲区技术。早期Unix系统只有代码段的访问属性是可执行,其他区域的访问 属性是可读或可读可写。但是,近来Unix和Windows系统由于 要实现更好的性能和功能,允许在栈段中动态地加入可执行代码 ,这是缓冲区溢出的根源。为保持程序兼容性,不可能使所有数据段都设置成不可执行。不 过,可以将动态的栈段设置为不可执行,这样,既保证程序的兼 容性,又可以有效防止把代码植入栈(自动变量缓冲区)的溢出 攻击。
*x86-64(补充)¶
- 变化:
- 新增8个64位通用寄存器:R8、R9、R10、R11、R12、R13、R14和 R15。可作为8位(R8B~R15B)、16位(R8W~R15W)或32位寄存 器(R8D~R15D)使用
- 所有GPRs都从32位扩充到64位。8个32位通用寄存器EAX、EBX、ECX 、EDX、EBP、ESP、ESI和 EDI对应扩展寄存器分别为RAX、RBX、 RCX、RDX、RBP、RSP、RSI和RDI;EBP、ESP、ESI和 EDI的低8位 寄存器分别是BPL、SPL、SIL和DIL
- 字长从32位变为64位,故逻辑地址从32位变为64位
- long double型数据虽还采用80位扩展精度格式,但所分配存储空间从 12B扩展为16B,即改为16B对齐,但不管是分配12B还是16B,都只用 到低10B
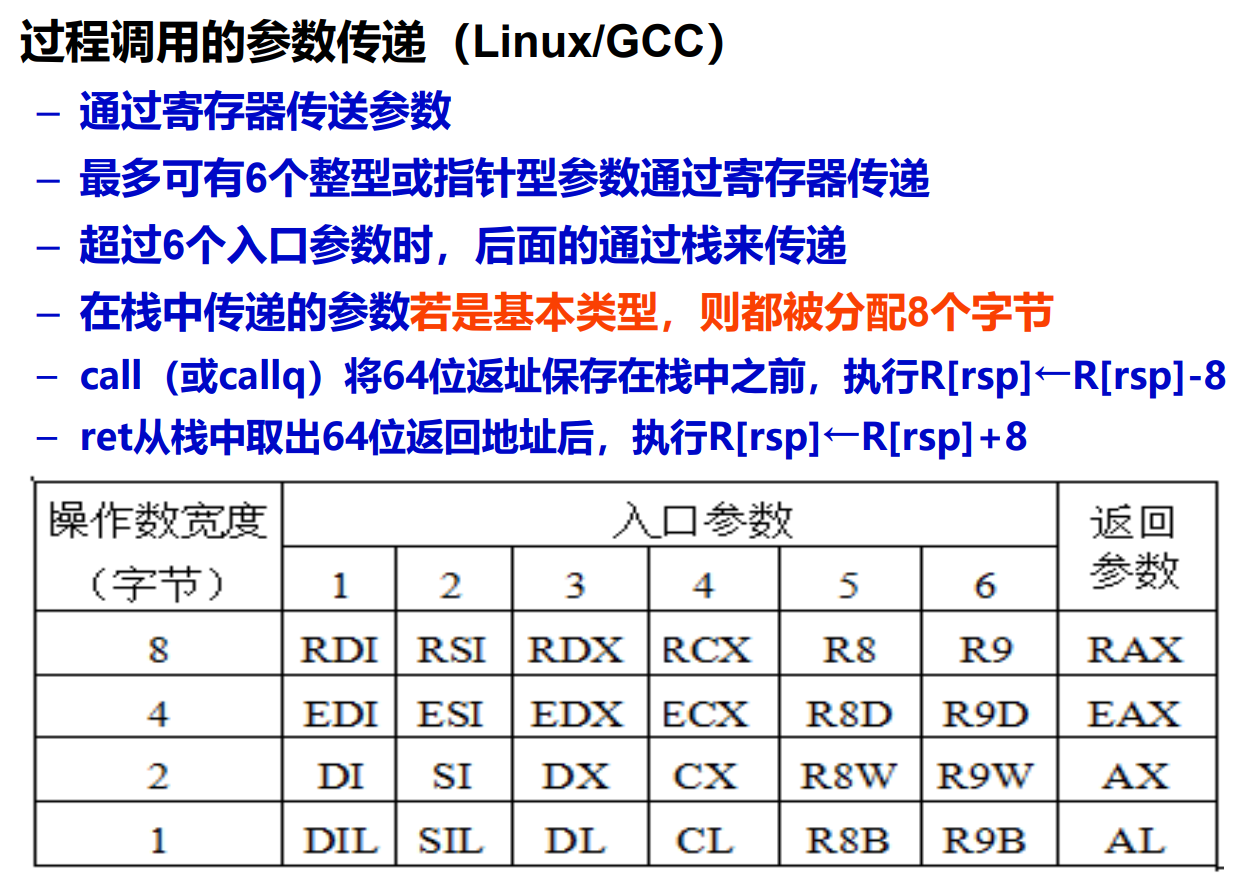
- 过程调用时,通常用通用寄存器而不是栈来传递参数,因此,很多过程不 用访问栈,这使得大多数情况下执行时间比IA-32代码更短
- 128位的MMX寄存器从原来的8个增加到16个,浮点操作采用基于SSE的 面向XMM寄存器的指令集,而不采用基于浮点寄存器栈的指令集
- 参数传递:更多的采用寄存器来传递信息
- 数据对齐:

基本指令¶
传送¶
- 汇编指令中助记符“q”表示操作数长度为 四字(即64位)

- 例