可扩展
- CS/BS 的服务器存在性能瓶颈(单体服务器不行)
扩展方式¶
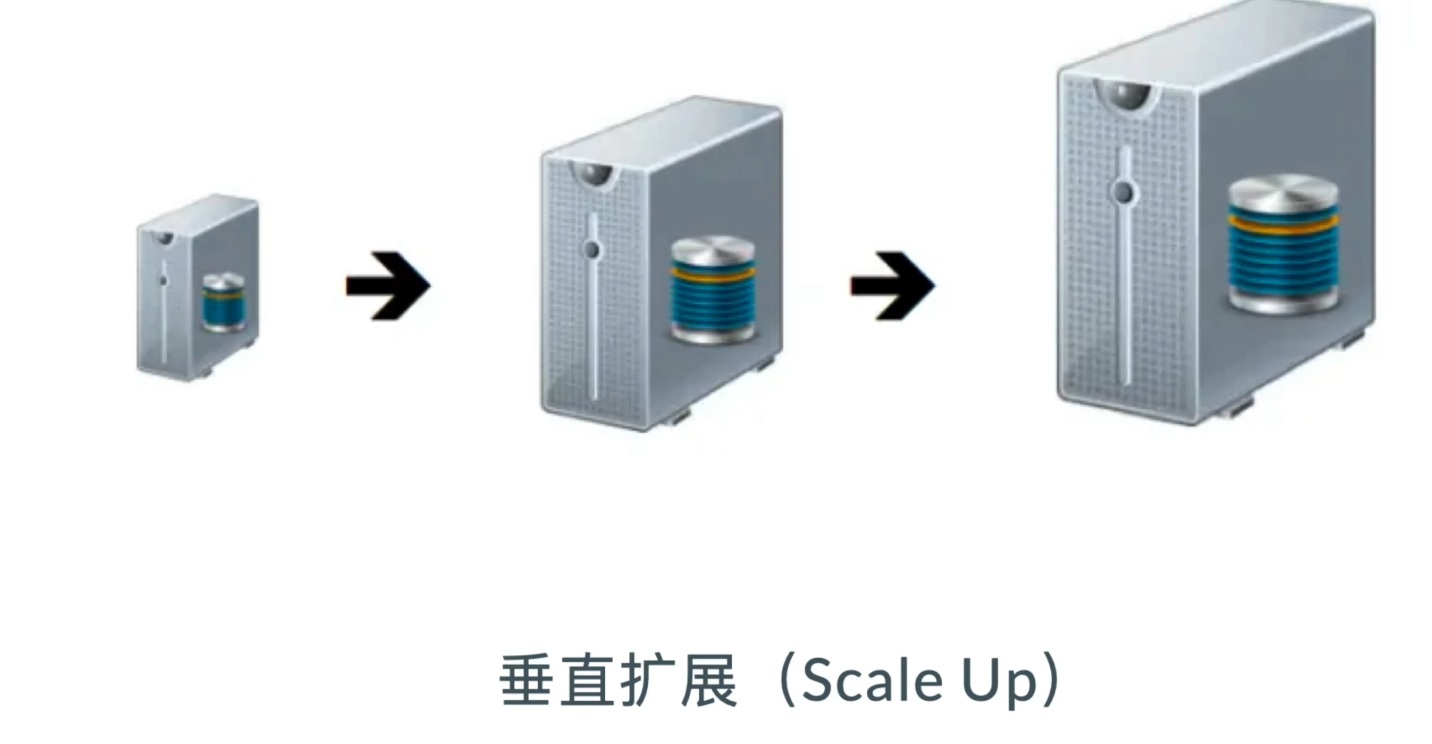
垂直扩展 Scale-up¶
- 升级单台机的配置
- 性价比低,有上限
通过虚拟机/容器模拟¶
- 通过虚拟机限制资源,实现模拟垂直扩展
- 使用 Jib 对程序进行打包
- 或者手动用 jar 创建 docker 镜像
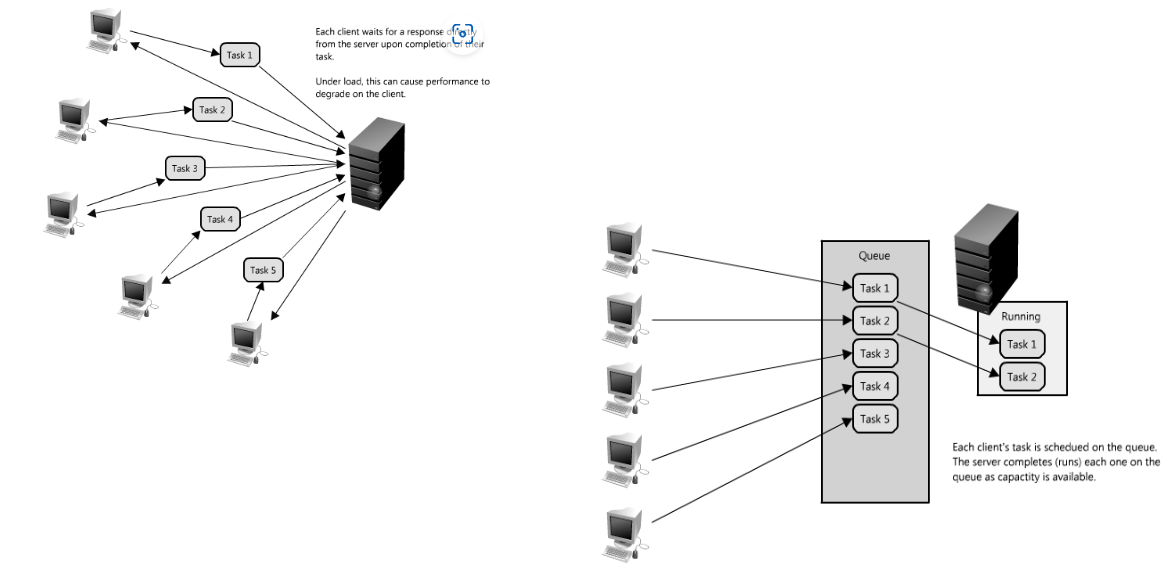
水平扩展¶

- 在用户视角,只有单一的服务器(用户无感),由负载均衡服务器来负责调度
- 网络层(l3)负载均衡
- 服务器位于子网中,子网边缘有负载均衡器
- 主要涉及 IP 地址,负载均衡器会修改数据包 IP 地址,使其指向选定的后端服务器
- L3负载均衡通常是由较低层的网络设备(如路由器)处理
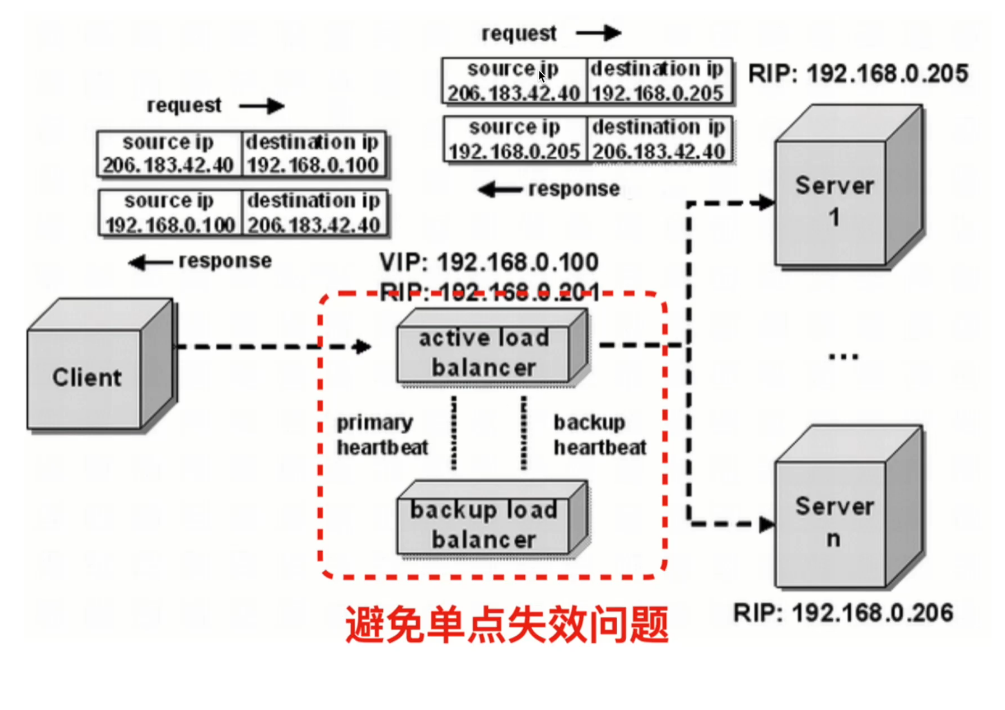
- 传输层(l4)负载均衡
- 基于 socket 负载均衡,还涉及到传输层的端口号。能够查看传输层协议如 TCP 或 UDP 的头部信息,根据源和目标的端口号来决定数据包的去向。
- 应用层 (l7)负载均衡
- 根据应用层数据来决定如何分发流量。这允许它进行更复杂的路由决策,比如基于特定 URL、用户的会话或查看内容类型,具有更高的灵活性。
- 特别适合于需要内容智能决策的应用场景,如基于HTTP/HTTPS的复杂应用程序,可以进行内容缓存、请求转发、会话持久性处理等。
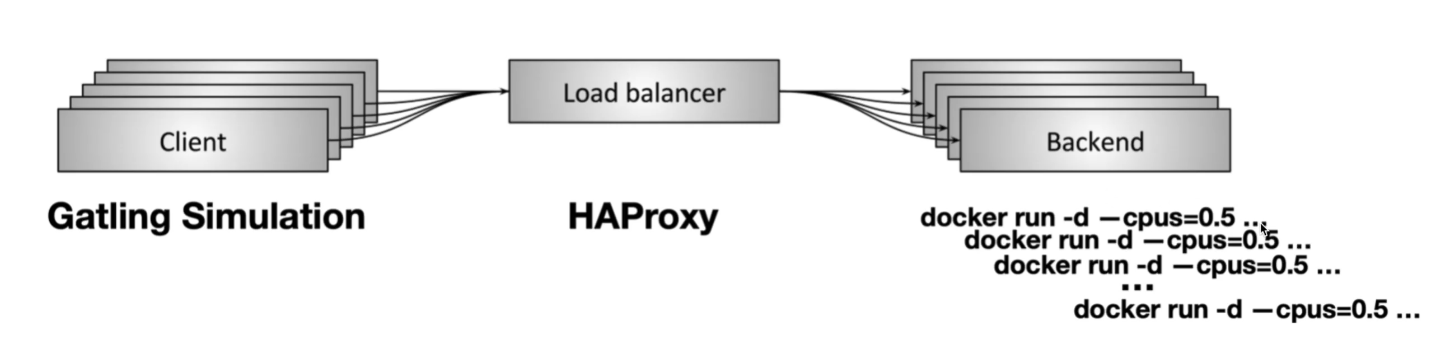
使用 Docker+HAProxy 实现实现水平扩展¶
- HAProxy:提供高可用性、负载均衡,以及基于 TCP 和 HTTP 的应用程序代理,支持L4和L7层的负载均衡
- HAProxy 是一个独立的负载均衡器,它不是作为 Java 代码的一部分配置的,而是单独配置和运行的,作为一个反向代理和负载均衡服务器
defaults mode tcp frontend http_front bind *:8181 default_backend http_back backend http_back balance roundrobin server mypos1 localhost:3001 server mypos2 localhost:3002 server mypos3 localhost:3003 server mypos4 localhost:3004
缓存 Redis¶
-
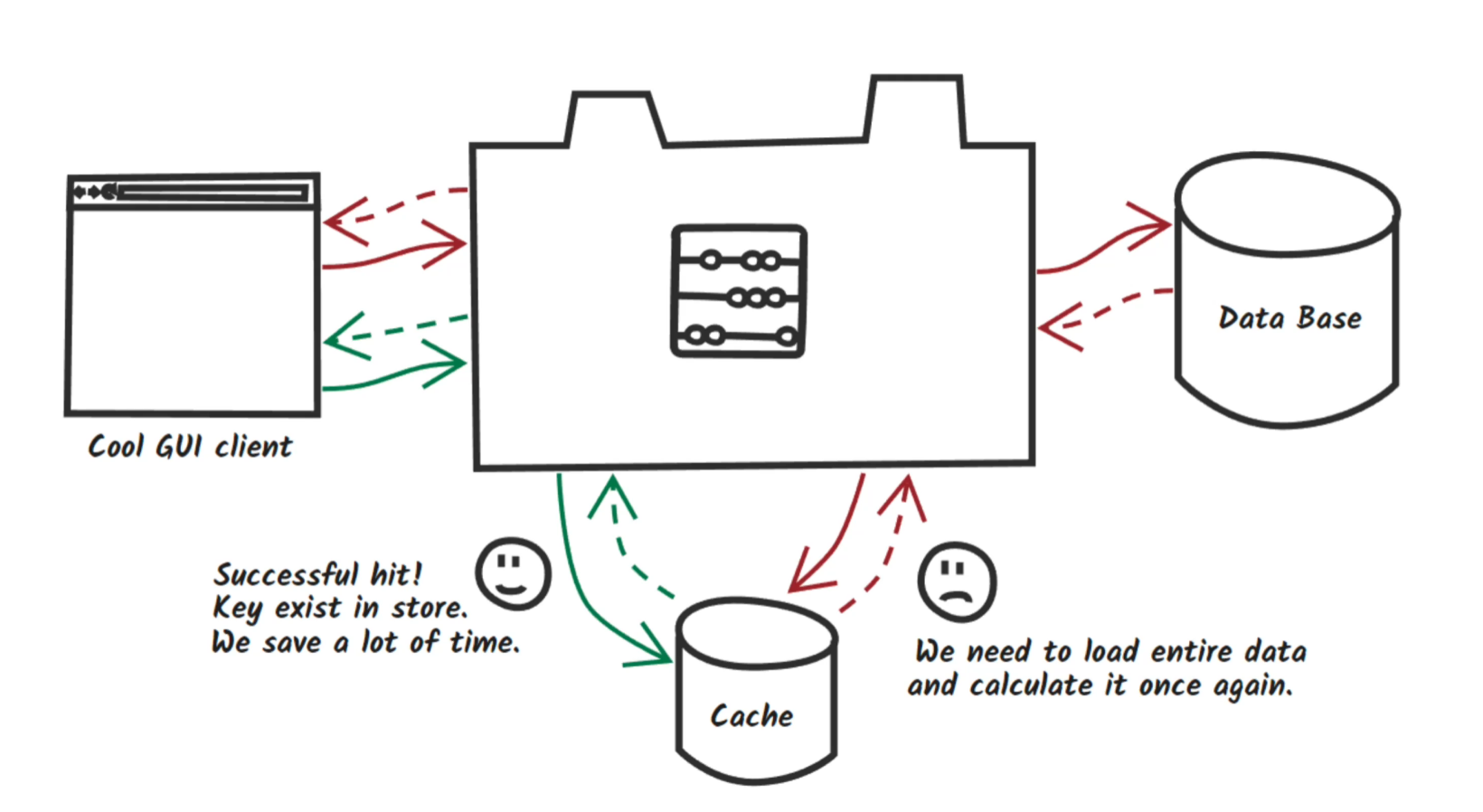
- 为了提高缓存的命中率,这就需要对负载均衡进行改进(导航到已经有缓存的服务器节点)
- 实际采用的方式:所有服务器共享缓存
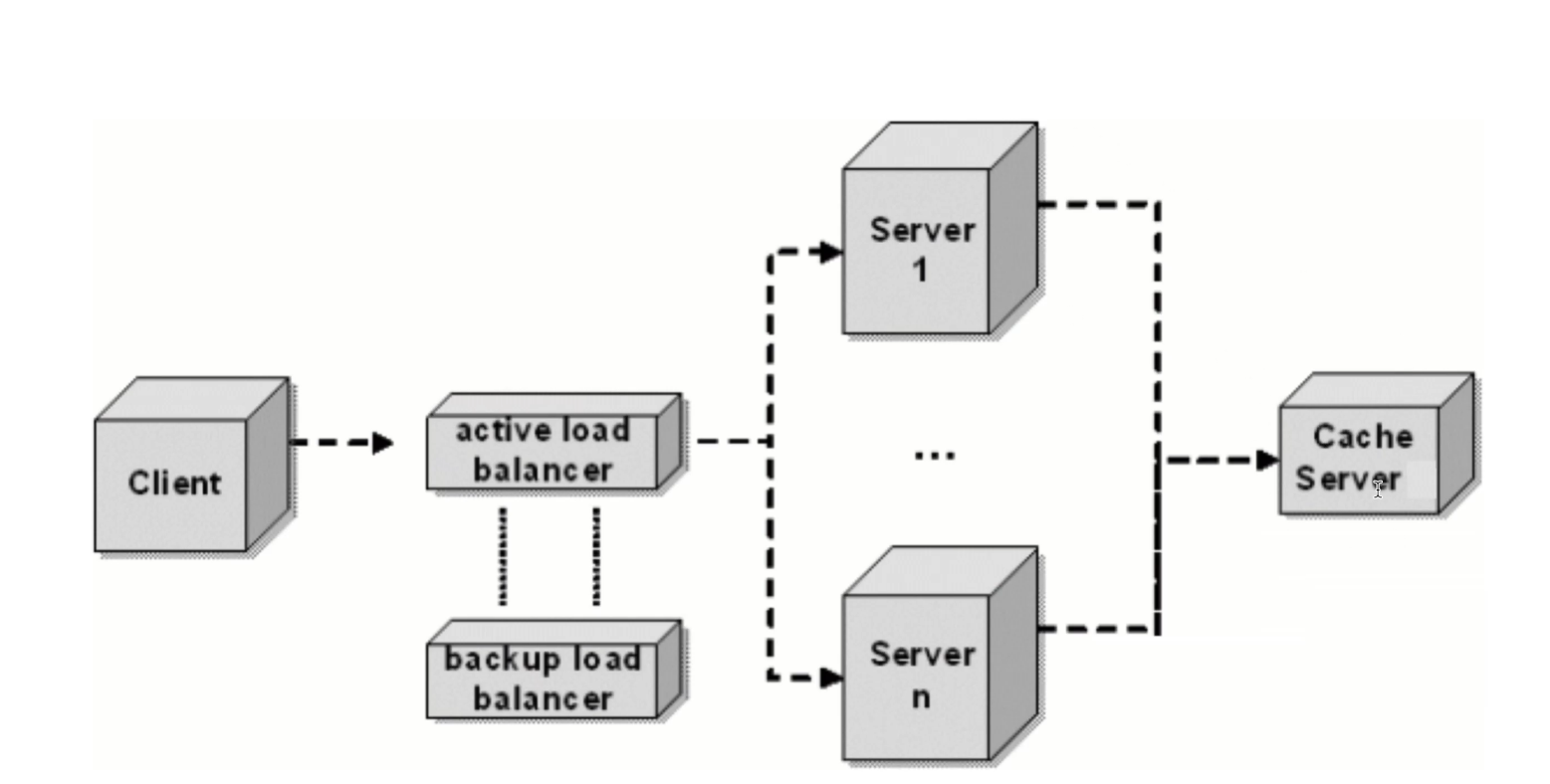
-
缓存也需要集群(不然就成瓶颈了)
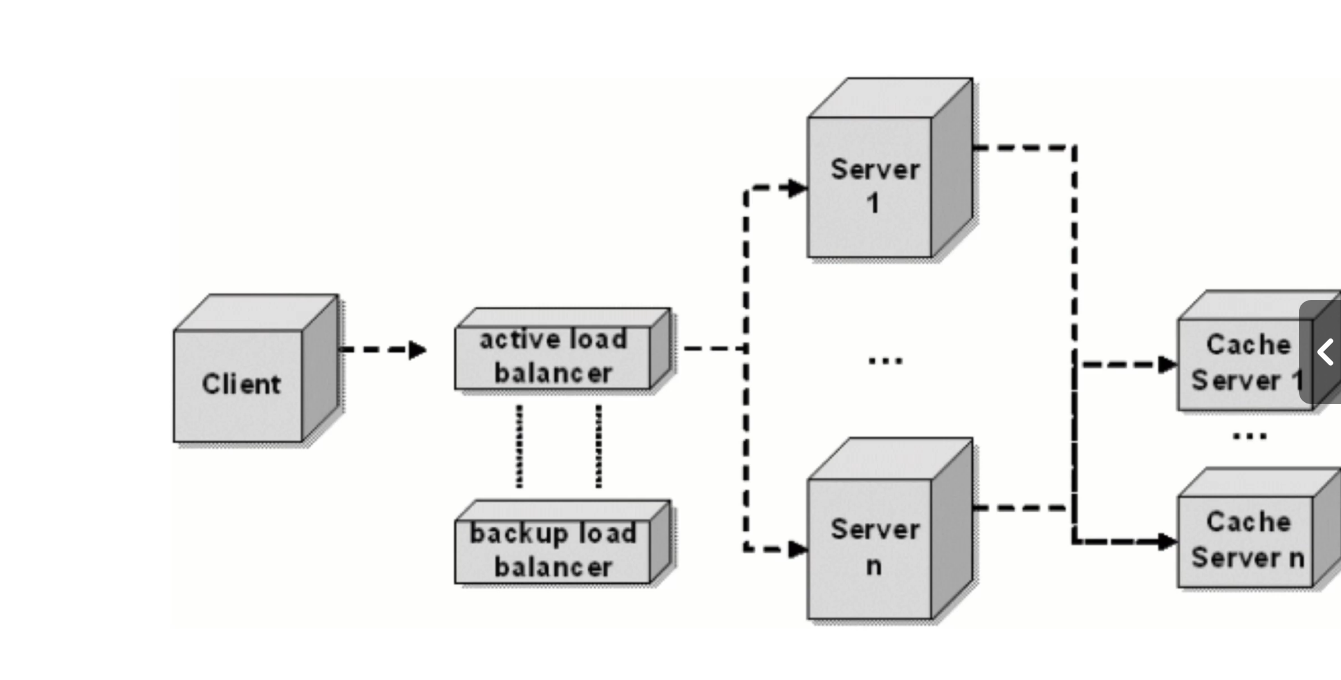
- 使用副歌存储节点,对缓存进行数据分片(去那个缓存节点读取数据),如使用哈希划分
- 为了更好的实现缓存扩充(不像使用%这种简单算法时需要清空缓存,完全重拍),使用一致性散列算法:
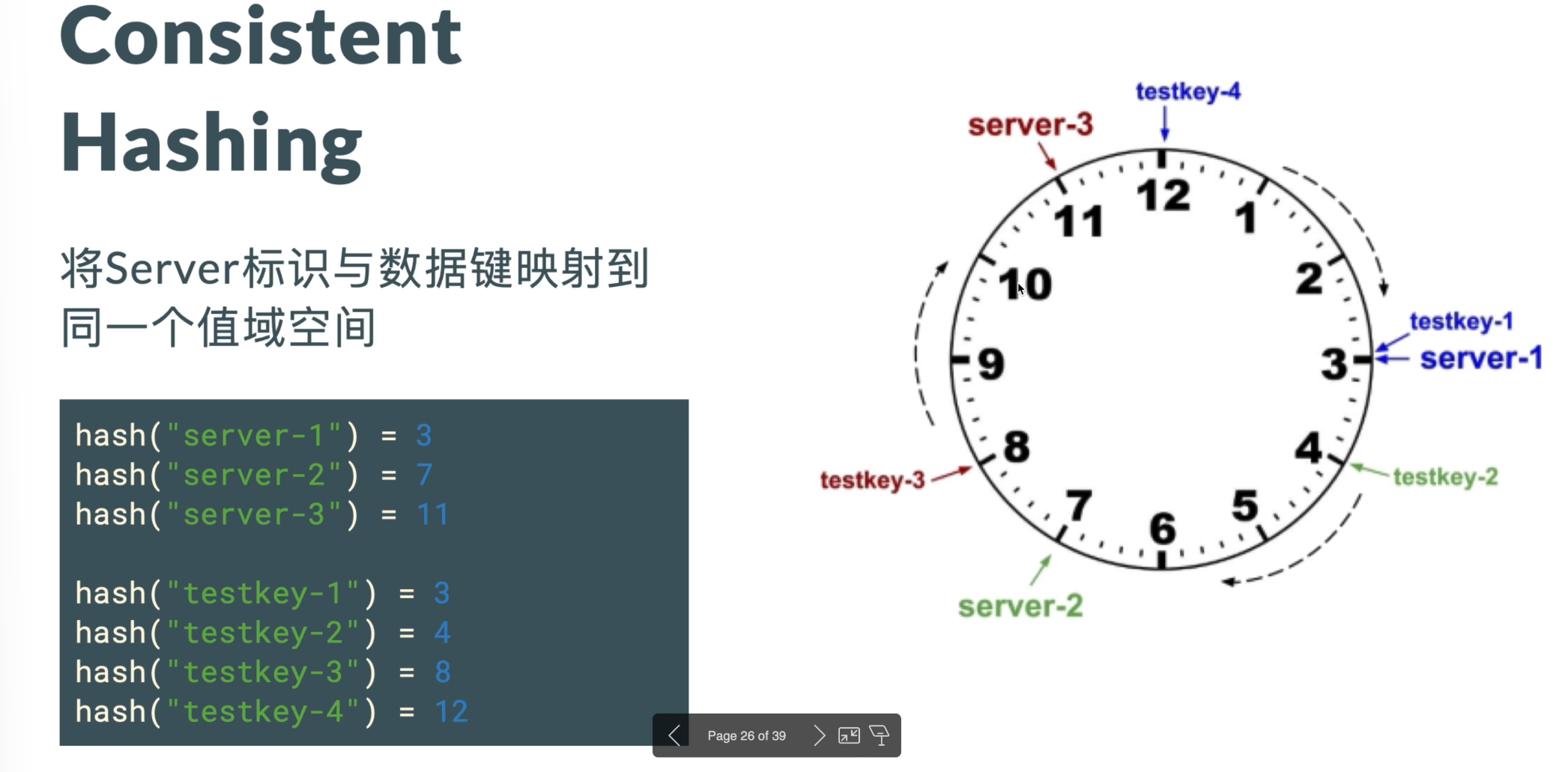
- 对服务器和条目键都计算哈希并映射到圆盘,每次查找按照顺时针查找下一个最近的服务器,这样添加一个服务器也只涉及这个服务器和下一个服务器之间的数据迁移,不会对其他服务器产生影响
Redis¶
@Cacheable: 这个注解通常用于方法,指示 Spring 在调用方法之前首先检查缓存。如果缓存中存在对应的数据,则直接从缓存返回数据,不执行方法。如果缓存中没有数据,那么执行方法,将结果存入缓存,并返回结果。@CachePut: 这个注解确保方法被执行并且结果被放入缓存,无论缓存中原来是否存在。@CacheEvict: 这个注解用于从缓存中移除数据,通常在数据更新或删除操作后使用。- 具体配置过程:可扩展架构-续 · 语雀
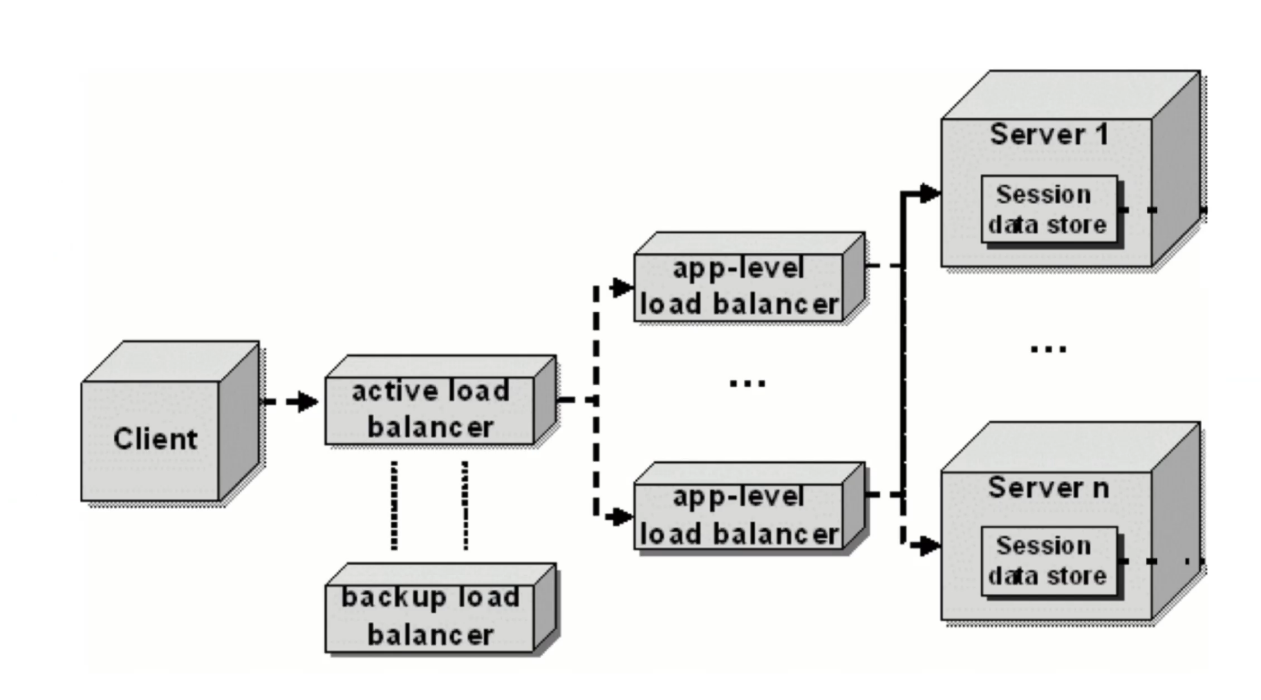
回话:session 与 cookie¶
- session 需要服务器存储额外的回话信息,并且需要不同服务器均能访问,因此使用分布式回话存储
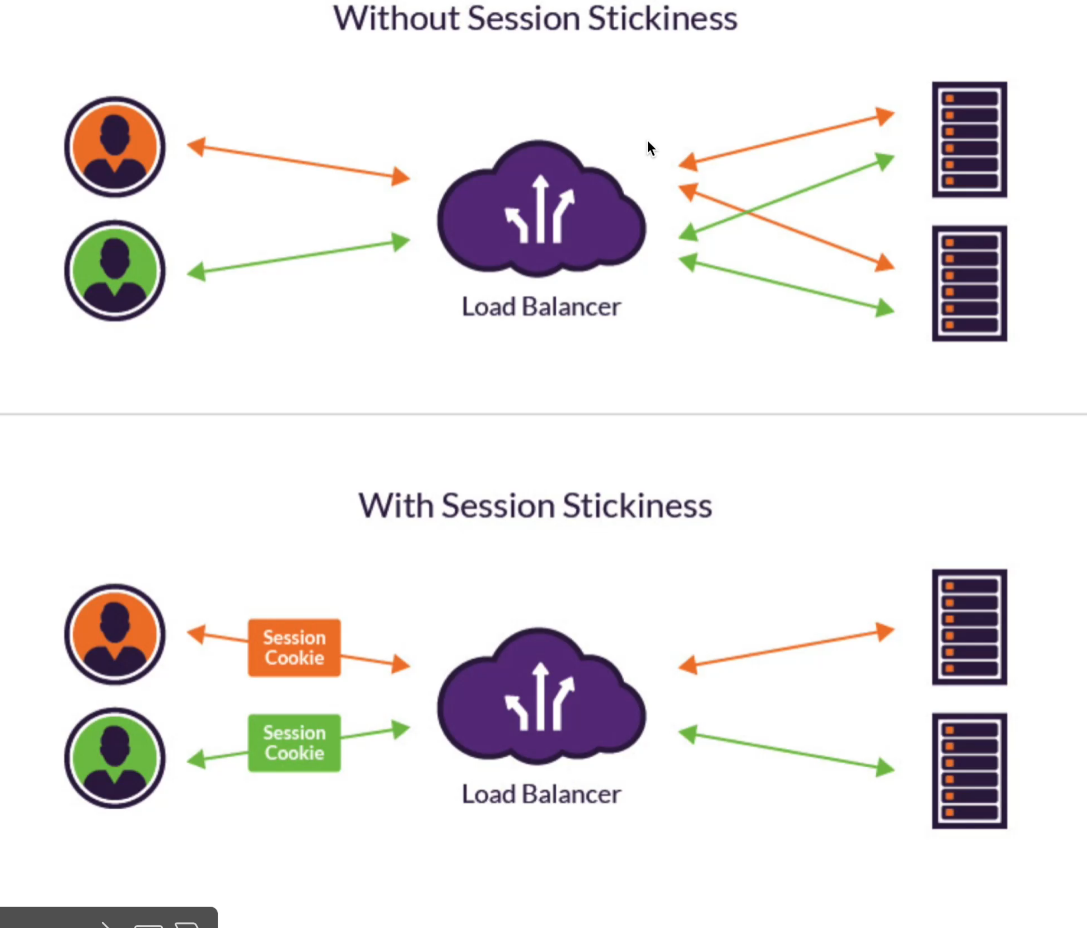
- 或者利用负载均衡实现会话粘性,一个用户请求在会话期间总是被转发到相同的服务器
- 如存储在 JDBC(用户量不大)、redis(适合用户量较大)
压力测试¶
Gatling¶
- 首先安装
gatling- 通过
Gatling运行
- 通过
- 将
scala脚本准备在user-files/simulations文件夹,Gatline会自动扫描,选择需要的脚本运行即可
例子¶
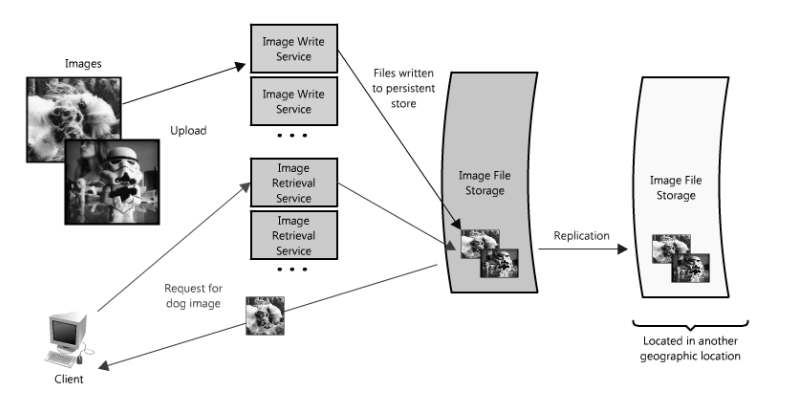
- 考虑如下需求:

- 支持上传、请求照片
- 业务分析:
- 考虑存储扩展性,以图片的数量作为计数单位
- 图片下载、请求需要低延迟
- 如果用户上传了一种图片,那么图片应该始终存在(可靠性)
- 系统应易于维护
- 成本问题
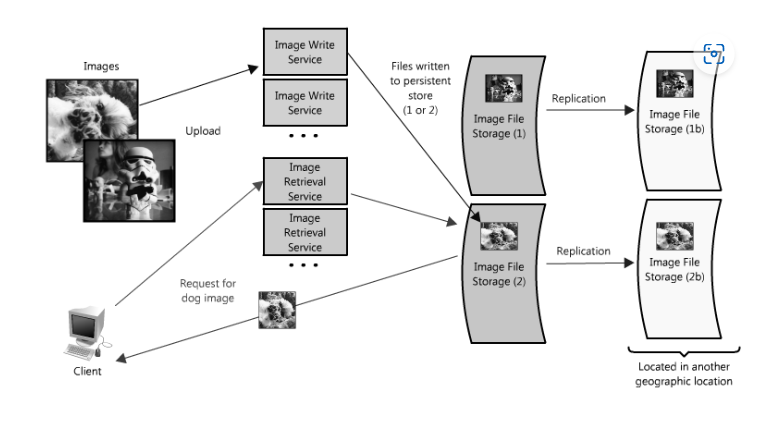
- 拆分上传、下载服务,冗余控制器、存储
- 分区
- 优化:缓存、代理、索引、负载均衡、事务队列