并发
- 线程有自己的程序计数器、用于计算的寄存器,但是不同线程共享地址空间(使用相同的页表),能访问相同的数据
- 线程有自己的本地线程栈
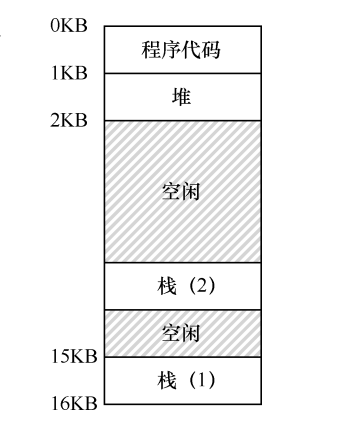
- 这样整个地址空间上就会有不同线程的多个栈
- 如果两个线程运行在相同处理器上那么线程切换时就要进行上下文切换
- 临界区:访问共享资源的代码
- 竞态条件:出现在多个执行线程大致同时进入临界区,都试图更新共享数据
- 如果程序由一个或多个竞态条件组成,那么程序的结果就可能存在不确定性
简化的线程模型¶
- heap 表示共享内存
- 两个线程操作 API(thread.h)
create(fn):创建一个入口是fn的入口函数并立即执行join()等待所有运行线程的返回#include <thread.h> void T_a() { for (int i=0;i<100;i++) { printf("a"); } } void T_b() { for (int i=0;i<100;i++){ printf("b"); } } int main() { create(T_a); create(T_b); join(); printf("finished\n"); return 0; }
- 线程互斥与同步 API
- 提供自旋锁类型
spinlock_t - 上锁、解锁
spin_lock(spinlock_t *lk),spin_unlock(spinlock_t *lk)long volatile sum = 0; spinlock_t lock = SPIN_INIT(); void T_sum(int tid) { for (int i = 0; i < N; i++) { spin_lock(&lock); for (int _ = 0; _ < 10; _++) { sum++; } spin_unlock(&lock); } printf("Thread %d: sum = %ld\n", tid, sum); } int main() { for (int i = 0; i < T; i++) { create(T_sum); } join(); printf("sum = %ld\n", sum); printf("%d*n = %ld\n", T * 10, T * 10L * N); }
- 提供自旋锁类型
- 提供互斥锁
typedef pthread_mutex_t mutex_t; #define MUTEX_INIT() PTHREAD_MUTEX_INITIALIZER #define mutex_init(mutex) pthread_mutex_init(mutex, NULL) #define mutex_lock pthread_mutex_lock #define mutex_unlock pthread_mutex_unlock - 条件变量
typedef pthread_cond_t cond_t; #define COND_INIT() PTHREAD_COND_INITIALIZER #define cond_wait pthread_cond_wait #define cond_broadcast pthread_cond_broadcast #define cond_signal pthread_cond_signal - 信号量
#define P sem_wait #define V sem_post #define SEM_INIT(sem, val) sem_init(sem, 0, val)
什么是线程¶
- 在进程的基础上又引入了线程:减小程序并发执行时付出的额外时空开销,提高操作系统的并发性能
- 由线程 ID、程序计数器、寄存器、栈等组成
- 与其他线程共享所在进程的资源
- 线程不拥有系统资源(很少,如内存、IO 设备等)
- 线程的状态:执行态;就绪态;阻塞态;
-
线程也有控制块 TCB
- 线程标识符、寄存器上下文、运行状态、优先级、堆栈指针等
-
线程的实现方式
- 用户级线程 ULT(如通过线程库):所用的工作(创建删除切换等)都由应用程序在用户态完成
- 此时操作系统的调用以进程为单位
- 切换开销较小
- 用户程序可以自己决定调度算法
- 当一个线程阻塞时整个进程的所有线程都会被阻塞
- 不能发挥多 CPU 的优势,每次内核只会分配给进程一个 CPU
- 内核级线程 KLT:线程的管理工作在内核完成
- 以线程为单位进行调度,更能发挥出多 CPU 的优势(一个进程可以同时在多个 CPU 上执行)
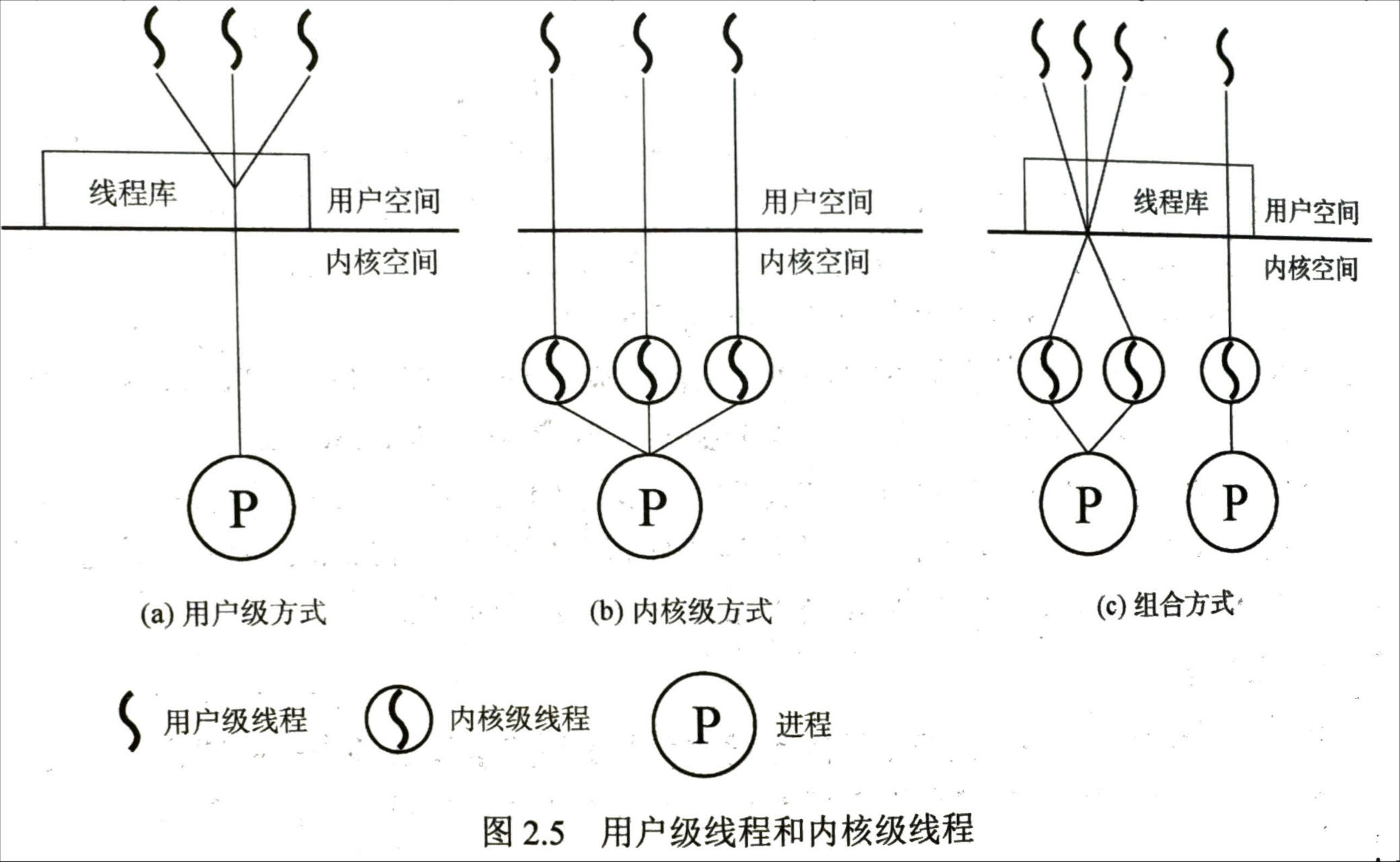
- 用户级线程 ULT(如通过线程库):所用的工作(创建删除切换等)都由应用程序在用户态完成
并发编程中要"放弃"的习惯假设¶
- 状态迁移原子性:
- 共享内存推翻了"原子性"假设
- 比如
i++就不再具有原子性
-
一个简单的 \(1+1\) 程序
long sum = 0; void T_sum() { for (int i = 0; i < N; i++) { sum++; } } int main() { create(T_sum); create(T_sum); join(); printf("sum = %ld\n", sum); printf("2*n = %ld\n", 2L * N); //不相同! } -
程序顺序执行假设:
def T_sum(): for _ in range(3): t = heap.sum sys_sched() t = t + 1 heap.sum = t sys_sched() sys_write(f'sum = {heap.sum}\n') def main(): heap.sum = 0 sys_spawn(T_sum) sys_spawn(T_sum) sys_spawn(T_sum) -
sum 的最小输出结果为 2(无论多少个线程都是 2)
- 要想为 2,则说明最后一步执行的是 \(1\to2\)
- 也就是一个线程执行完成,一个还剩一次,一个第一次执行(拿的 sum=0)
- 第一次执行的执行的执行之后 sum 为 1,还剩一次的拿到 1
- 第一次执行的快速执行完成,还剩一次的执行一次得到 2
-
编译器的优化可能带来不可预测的结果
while (!flag);在优化之后并不会进行反复读取,而是会直接改为死循环,需要添加volatile阻止优化
-
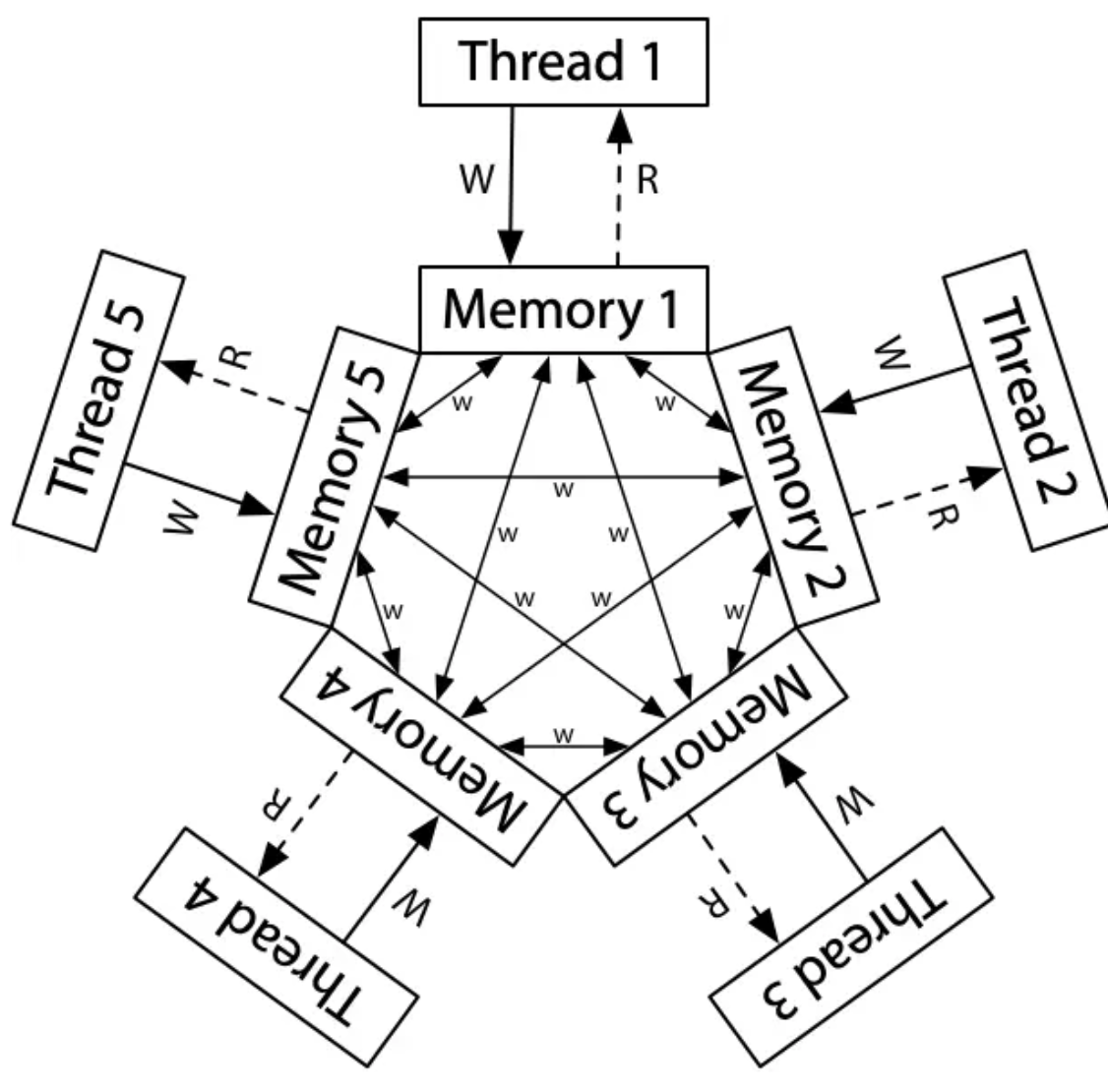
全局指令执行顺序的假设
- 处理器也是编译器,会对执行优化,只是使得指令 "看起来" 顺序完成(可能是针对自己的视角)
- 比如可以同时执行两条不相关的指令
- 实际的共享内存模型:不同处理器可能看到不同的共享内存
并发控制¶
互斥¶
- 互斥(互相排斥):阻止并发
临界区¶
- 进入区:检查是否可以进入临界区,若能进入则设置标志阻止其他进程同时进入
- 临界区:访问临界资源的代码
- 退出区:清除正在访问标志
-
剩余区:代码中其他部分
-
准则:
- 空闲让进
- 忙则等待
- 有限等待
- 让权等待(不能进入时释放处理器)
Peterson 算法 (用于两个线程)¶
- 一种不需要硬件支持的锁机制
- 每个人有一个变量(旗子)表示自己是否要使用临界区资源
- 如果要使用临界区资源:
- 举起自己的旗子(先)
- 把写有对方名字的字条贴在临界区上(后)
- 进入观察者模式:
- 如果对方没有举起旗子或者字条上是自己的名字就可以使用临界区资源(手快的先进入)
- 释放:放下旗子
def T1(): while True: heap.x = '🏴' heap.turn = '❷' while True: t = heap.turn y = heap.y != '' if not y or t == '❶': break heap.cs += '❶' heap.cs = heap.cs.replace('❶', '') heap.x = '' def T2(): while True: heap.y = '🏁' heap.turn = '❶' while True: t = heap.turn x = heap.x if not x or t == '❷': break heap.cs += '❷' heap.cs = heap.cs.replace('❷', '') heap.y = '' def main(): heap.x = '' heap.y = '' heap.turn = '' heap.cs = '' sys_spawn(T1) sys_spawn(T2)
硬件互斥¶
- 原子指令:一小段时间的 “Stop the World” 执行
- 如不可打断的
load+计算+save - 汇编中添加
lock前缀
- 如不可打断的
-
这样就可以更简单的进行互斥
- 但是不能指望所有都依靠硬件提供原子指令来实现
- 有些复杂时实现不可能由硬件来提供
-
在单核 CPU 中,
lock前缀可以阻止指令被中断,从而保证原子性。在多核 CPU 中,lock前缀还可以阻止其他核心访问被锁定的内存地址,直到原子操作完成。(如直接锁定总线)
一些硬件提供的原子指令: - 比较并交换 CAS,期望初始值+新值 (一种无锁同步机制)
int compare_and_swap(int* ptr, int expected, int new) {
int actual = *ptr;
if (actual == expected) {
*ptr = new;
return 1; // 表示成功替换
}
return 0; // 替换失败
}
int FetchAndAdd(int *ptr) {
int old = *ptr;
*ptr = old + 1;
return old;
}
操作系统内核中的互斥-关中断实现¶
- 中断带来了一系列麻烦
- 比如在获得锁(lock ())的状态下发生中断,并且中断程序执行中也要获取这个锁,那么就出现了死锁
- 正确性标准
- 正确实现互斥:关中断(lock 之前关中断,unlock 之后开中断,也不一定要开,比如执行的是一个中断处理程序时就不应该开中断)+自旋保证实现互斥
- 上锁、解锁前后中断状态不变:
- 加锁是想把一段操作作为原子操作,除此之外不该改动其他属性(如关中断状态)
- 不得在关中断时随意打开中断 (例如处理中断时)
- 不得随意关闭中断 (否则可能导致中断丢失)
- 只在很有限的情况下用关闭中断来实现互斥。例如,在某些情况下操作系统本身会采用屏蔽中断的方式,保证访问自己数据结构的原子性,或至少避免某些复杂的中断处理情况。
- 不应该随便允许应用程序关中断,这会有恶意程序
操作系统内核中的 (半)无锁 互斥¶
- 当线程超过一定数目时自旋锁会成为性能瓶颈(甚至 CPU 越多性能反而更差)
- 利用操作系统内核对象“read-mostly”的性质(经常读取但是很少进行修改)
- Read-Copy-Update(RCU)主要用于提高在读操作频繁而写操作较少的情况下的性能和可伸缩性。
- RCU 的基本思想是当数据结构需要更新时,不直接在原有数据结构上进行修改,而是先复制一份数据,在这份副本上做修改。修改完成后,再将读取操作从旧的数据结构切换到这份已修改的副本上。此过程中,旧的数据结构仍然可以被读取操作访问,直到确定没有任何读取操作在使用旧数据后,才将其回收。
- 划分为三个阶段:复制-更新-发布
- 牺牲了一定的数据一致性
应用程序中的互斥-锁¶
- 评价锁:
- 是否有效,真的阻止多个线程进入临界区
- 公平性:是否每一个竞争线程有公平的机会
- 性能:使用锁增加的时间开销
自旋锁¶
- 自旋锁:低开销的忙等待锁,适用于持有时间极短的锁,当一个线程尝试获取的自旋锁已经被其他线程持有时就需要循环检查等待,自旋锁不会使线程进入睡眠状态
-
自旋锁的效率问题:除了进入临界区的线程,其他处理器上的线程都在空转,争抢锁的处理器越多效率越低。如果临界区较长不如把处理器让给其他线程(此外如果持有自旋锁的线程被切换,那甚至还会有 100%的资源浪费)
- 不过在等待时间极短时自旋锁的效率通常高于互斥锁,因为避免了线程的阻塞和唤醒过程(即上下文切换)
-
自旋锁在单 CPU 上无法 使用,因为一个自旋的线程永远不会放弃 CPU。
- 自旋锁通过对锁进行原子操作(自旋)来实现
stomic_xchg同时做两件事:交换值(将第二项赋值给锁),获取锁的旧值作为返回值static inline int atomic_xchg(volatile int *addr, int newval) { int result; asm volatile ("lock xchg %0, %1": "+m"(*addr), "=a"(result) : "1"(newval) : "memory"); return result; } void spin_lock(spinlock_t *lk) { while (1) { int value = atomic_xchg(lk, 1); if (value == 0) { break; } } } void spin_unlock(spinlock_t *lk) { atomic_xchg(lk, 0); }
互斥锁¶
- 使用方式上和自旋锁同样简单,即
lock和unlock操作 - 也就是说与其等待不如把 CPU 让给其他线程来使用
- 使用 syscall 进入内核,操作系统尝试获取锁,如果失败那么就先切换线程,标记为等待
- 当锁被释放时再唤醒等待锁的线程
- 适用于较长时间等待的情况
- 避免了 CPU 资源的浪费,阻塞的线程不会持续占用 CPU
- 问题:线程阻塞和唤醒过程涉及到上线文切换耗费性能
int status = 0; // 0 表示锁是空闲的 void lock() { while (true) { if (status == 0) { if (compare_and_swap(&status, 0, 1)) { return; // 成功获取锁,退出函数 } } sleep_or_yield(); // 主动让出CPU,休眠 } }
- 使用队列进行优化
- 直接使用互斥锁,当锁被释放时所有相关线程会被唤醒,尝试获取锁,一个获取到了,其他的线程重新休眠,存在大量的上下文切换(只有有较大机会获得锁时再切换)
- 当一个线程尝试获取锁时,如果获取失败就先把他自己加入到队列,之后休眠,当锁被释放时直接从队列里取线程转交锁即可
- 公平性更好,并且性能更高
*基于锁的并发数据结构¶
- 计数器
typedef struct counter_t { int value; pthread_mutex_t lock; } counter_t; void init(counter_t *c) { c->value = 0; Pthread_mutex_init(&c->lock, NULL); } void increment(counter_t *c) { Pthread_mutex_lock(&c->lock); c->value++; Pthread_mutex_unlock(&c->lock); } void decrement(counter_t *c) { Pthread_mutex_lock(&c->lock); c->value--; Pthread_mutex_unlock(&c->lock); } int get(counter_t *c) { Pthread_mutex_lock(&c->lock); int rc = c->value; Pthread_mutex_unlock(&c->lock); return rc; } -
性能很差,多线程时比单线程慢的多得多
-
懒惰计数器(可扩展的计数器)
- 对于有 4 个 CPU 的机器,使用一个全局计数器和 4 个局部计数器(分别有锁)
- 如果一个核心上的线程想增加计数器那就增加局部计数器,访问局部寄存器是通过局部寄存器的锁
- 局部值还需要定期转移给全局计数器,让全局计数器加上局部计数器的值,之后将局部置零
- 转移阈值记为 S,S 越小越趋近于普通计数器
- 懒惰计数器在精确和性能之间折中
#include <pthread.h> #define NUMCPUS 4 // 假设有4个CPU核心,根据实际情况调整 typedef struct counter_t { int global; // 全局计数 pthread_mutex_t glock; // 用于全局计数的互斥锁 int local[NUMCPUS]; // 每个CPU核心的局部计数 pthread_mutex_t llock[NUMCPUS]; // 每个核心的局部锁 int threshold; // 更新频率,达到该值后,局部计数会更新到全局计数 } counter_t; // 初始化计数器 void init(counter_t *c, int threshold) { c->threshold = threshold; c->global = 0; pthread_mutex_init(&c->glock, NULL); // 初始化全局锁 for (int i = 0; i < NUMCPUS; i++) { c->local[i] = 0; pthread_mutex_init(&c->llock[i], NULL); // 初始化每个CPU的局部锁 } } // 更新计数器的函数 void update(counter_t *c, int threadID, int amt) { pthread_mutex_lock(&c->llock[threadID]); // 锁定对应CPU的局部锁 c->local[threadID] += amt; // 更新局部计数 // 如果局部计数达到阈值,则转移到全局计数 if (c->local[threadID] >= c->threshold) { pthread_mutex_lock(&c->glock); // 锁定全局锁 c->global += c->local[threadID]; // 更新全局计数 c->local[threadID] = 0; // 重置局部计数 pthread_mutex_unlock(&c->glock); // 释放全局锁 } pthread_mutex_unlock(&c->llock[threadID]); // 释放局部锁 } // 获取全局计数的函数 int get(counter_t *c) { pthread_mutex_lock(&c->glock); // 锁定全局锁 int val = c->global; // 获取全局计数 pthread_mutex_unlock(&c->glock); // 释放全局锁 return val; // 返回全局计数值,可能不是最新的因为还有未同步的局部计数 }
-
链表
- 操作时对整个链表加锁
// basic node structure typedef struct node_t { int key; struct node_t *next; } node_t; // basic list structure (one used per list) typedef struct list_t { node_t *head; pthread_mutex_t lock; } list_t; void List_Init(list_t *L) { L->head = NULL; pthread_mutex_init(&L->lock, NULL); } void List_Insert(list_t *L, int key) { // synchronization not needed node_t *new = malloc(sizeof(node_t)); if (new == NULL) { perror("malloc"); return; } new->key = key; // just lock critical section pthread_mutex_lock(&L->lock); new->next = L->head; L->head = new; pthread_mutex_unlock(&L->lock); } int List_Lookup(list_t *L, int key) { int rv = -1; pthread_mutex_lock(&L->lock); node_t *curr = L->head; while (curr) { if (curr->key == key) { rv = 0; break; } curr = curr->next; } pthread_mutex_unlock(&L->lock); return rv; // now both success and failure }
- 操作时对整个链表加锁
-
使用更细粒度的并发(如对节点加锁)并不一定性能更好,因为要更加频繁的加锁
-
队列
- 两个锁一个负责头一个负责尾,使得入队出可以并发执行
#include <pthread.h> #include <stdlib.h> #include <assert.h> typedef struct node_t { int value; struct node_t *next; } node_t; typedef struct queue_t { node_t *head; // 指向队列头部的指针 node_t *tail; // 指向队列尾部的指针 pthread_mutex_t headLock; // 保护队列头部的锁 pthread_mutex_t tailLock; // 保护队列尾部的锁 } queue_t; // 初始化队列 void Queue_Init(queue_t *q) { node_t *tmp = malloc(sizeof(node_t)); // 创建一个哑结点 tmp->next = NULL; q->head = q->tail = tmp; // 头尾都指向哑结点 pthread_mutex_init(&q->headLock, NULL); // 初始化头部锁 pthread_mutex_init(&q->tailLock, NULL); // 初始化尾部锁 } // 入队操作 void Queue_Enqueue(queue_t *q, int value) { node_t *tmp = malloc(sizeof(node_t)); assert(tmp != NULL); // 确保内存分配成功 tmp->value = value; tmp->next = NULL; pthread_mutex_lock(&q->tailLock); // 锁定尾部 q->tail->next = tmp; // 将新结点链接到队列的尾部 q->tail = tmp; // 更新尾部指针 pthread_mutex_unlock(&q->tailLock); // 释放尾部锁 } // 出队操作 int Queue_Dequeue(queue_t *q, int *value) { pthread_mutex_lock(&q->headLock); // 锁定头部 node_t *tmp = q->head; node_t *newHead = tmp->next; if (newHead == NULL) { pthread_mutex_unlock(&q->headLock); // 如果队列为空,释放头部锁 return -1; // 返回-1表示队列为空 } *value = newHead->value; // 将值传递给*value q->head = newHead; // 更新头部指针 pthread_mutex_unlock(&q->headLock); // 释放头部锁 free(tmp); // 释放旧的头结点 return 0; // 返回0表示成功出队 }
- 两个锁一个负责头一个负责尾,使得入队出可以并发执行
-
散列表
- 使用并发链表实现
- 由链表的锁保证正确
同步¶
- 互斥只解决了原子性的问题,保证同时只能有一个相关操作正在进行,但是并不能用于协调相对关系,比如想先完成一件事再做另一件事
- 同步用于对多个线程的执行顺序进行控制:使得两个或两个以上随时间变化的量在变化过程中保持一定的相对关系
- 乐团演奏的简单例子
void T_player() { while (!end) { wait_next_beat(); play_next_note(); } } void wait_next_beat(int expect) { // This is a spin-wait loop. retry: mutex_lock(&lk); // This read is protected by a mutex. int got = n; mutex_unlock(&lk); if (got != expect) goto retry; } -
在拍子内演奏者各自活动,但是在节拍到来后同时行动(完成一个节拍的演奏)
-
对于常用的 join 方法(等待另一个线程的结束)
- 这同样是一种同步
条件变量¶
-
管程:
- 一种同步构造,用于控制多个线程对共享资源的访问,以保证在任何时刻只有一个线程可以执行临界区的代码。
- 包含:管程的名称;对于管程的共享变量的说明;对管程内数据结构的操作;对数据设置初始值的语句;
-
线程可以使用条件变量等待一个条件成真
- 当某些条件不满足时,线程把自己加入到对应的队列,等待条件(此时 CPU 可以先去执行其他的任务)
- 当条件发生变化时,唤醒队列中的等待线程进行检查
生产者消费者模式¶
- 99% 的实际并发问题都可以用生产者-消费者解决
- 存在一个大小有限的缓冲区
- Producer (生产数据):如果缓冲区有空位,放入;否则等待
- Consumer (消费数据):如果缓冲区有数据,取走;否则等待
-
通过括号匹配来检查模型的正确性
-
使用锁的基础实现
- 问题:反复检查占用CPU
#include <thread.h> #include <thread-sync.h> mutex_t lk = MUTEX_INIT(); int n, depth = 0; void T_produce() { while (1) { retry: mutex_lock(&lk); if (!(depth < n)) { mutex_unlock(&lk); goto retry; } assert(depth < n); printf("("); depth++; mutex_unlock(&lk); } } void T_consume() { while (1) { retry: mutex_lock(&lk); if (!(depth > 0)) { mutex_unlock(&lk); goto retry; } assert(depth > 0); printf(")"); depth--; mutex_unlock(&lk); } }
- 问题:反复检查占用CPU
-
使用条件变量的方式
- 替代自旋锁,提升效率
- 条件不满足时等待,条件满足时唤醒
-
signal以及notify_one()指令指令唤醒等待线程中的一个;broadcast()以及notify_all会唤醒所有等待线程- 如果无法确认被唤醒的线程能产生动作(如发出新的信号)即可能造成死锁,那么就不能只使用 signal 唤醒唤醒单个线程
- broadcast 就覆盖了所有需要唤醒线程的场景,因此被称为覆盖条件,但是效率较低
-
为什么使用 while 而不是 if:这更安全,有时条件虽然被唤醒,但是条件可能并不满足,还需要进行一下检查
int n, depth = 0; mutex_t lk = MUTEX_INIT(); cond_t cv = COND_INIT(); #define CAN_PRODUCE (depth < n) #define CAN_CONSUME (depth > 0) void T_produce() { while (1) { mutex_lock(&lk); while (!CAN_PRODUCE) { cond_wait(&cv, &lk); //条件不满足时,调用条件变量等待(直到条件变量发生变化)(系统会进行休眠),并且此方法还负责先释放锁,等到继续时再重新加锁 //之后使用while还会额外进行一次检查,因为这里生产者和消费者共用一个锁,这条件变量改变不代表条件一定满足 } assert(CAN_PRODUCE); printf("("); depth++; //条件变量发生改变时进行唤醒广播 cond_broadcast(&cv); mutex_unlock(&lk); } } void T_consume() { while (1) { mutex_lock(&lk); while (!CAN_CONSUME) { cond_wait(&cv, &lk); } printf(")"); depth--; cond_broadcast(&cv); mutex_unlock(&lk); } } -
使用缓冲区的例子(不是产生了一个就必须立即消费一个)
int buffer[MAX]; int fill = 0; int use = 0; int count = 0; void put(int value) { buffer[fill] = value; fill = (fill + 1) % MAX; count++; } int get() { int tmp = buffer[use]; use = (use + 1) % MAX; count--; return tmp; } cond_t empty, fill; mutex_t mutex; void *producer(void *arg) { int i; for (i = 0; i < loops; i++) { Pthread_mutex_lock(&mutex); // p1 while (count == MAX) // p2 Pthread_cond_wait(&empty, &mutex); // p3 put(i); // p4 Pthread_cond_signal(&fill); // p5 Pthread_mutex_unlock(&mutex); // p6 } } void *consumer(void *arg) { int i; for (i = 0; i < loops; i++) { Pthread_mutex_lock(&mutex); // c1 while (count == 0) // c2 Pthread_cond_wait(&fill, &mutex); // c3 int tmp = get(); // c4 Pthread_cond_signal(&empty); // c5 Pthread_mutex_unlock(&mutex); // c6 printf("%d\n", tmp); } } - 使用数组存储“事务“,每一项是一个 int,即表示一次生产的事务,以及要一次进行消费的事务

同步机制的应用¶
-
将任务分解为有向无环图,调度者(生产者)进行任务拓扑分配,将任务分配给消费者来执行
- 只要调度器 (生产者) 分配任务效率够高,算法就能并行
- (将任务丢到线程池)
-
使用条件变量的实现
- 为每一个节点设置一个条件变量
- 一个节点 \(v\) 能执行的条件是所有 \(u\to v\) 都已经完成
- \(u\) 完成之后,signal 每一个 \(v\)
-
一个问题能不能很好的并行化,就是取决于其计算图(有向无环图)的结构,是否能很好的划分,当紧密依赖(如类似链表形式)就很难进行并行化
-
例子:多个线程分别输出<>_中的某一种,要求只能输出这几种图案<>< 和><>
- 使用状态机表示,一个线程能够打印的条件就是当前状态可以使用当前字符进行状态转移
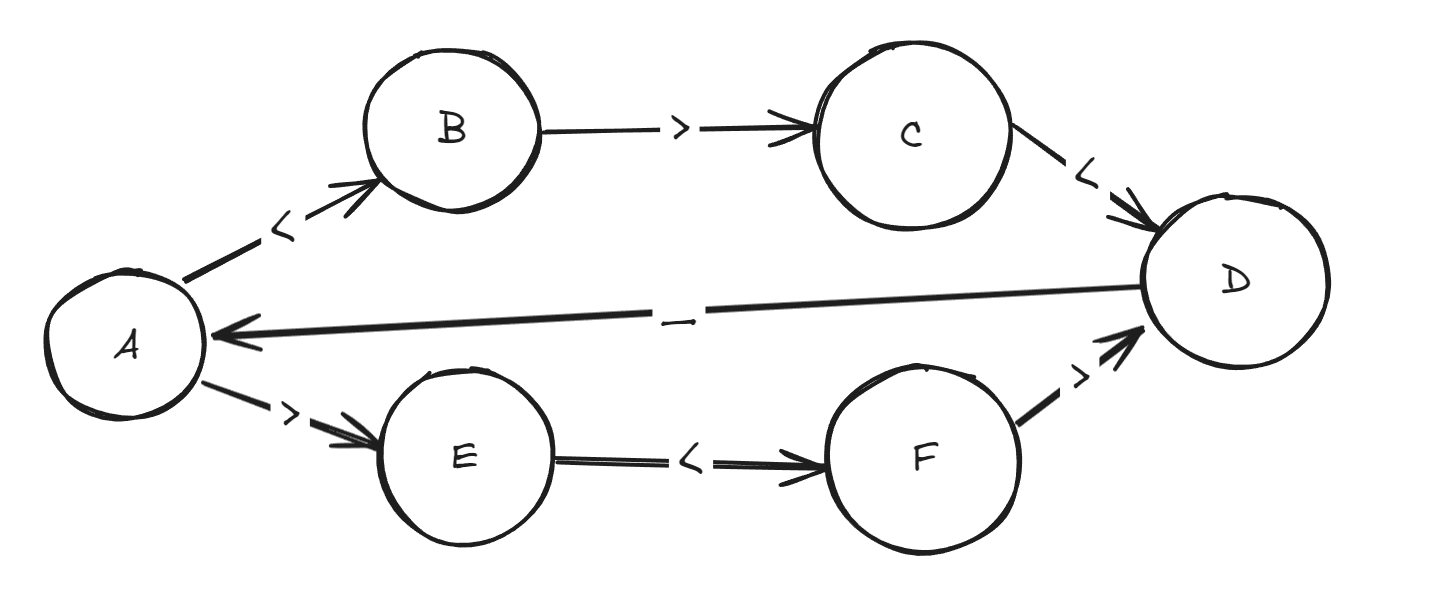
- 根据当前状态(节点)判断当前线程是否应该输出
- fish
信号量¶
- 信号量的初始值为允许同时使用的数目,最小负值(这个负值表示有多少人在等)为 \(最大允许数目-最大消费线程数目\)
- 首先考虑使用互斥锁实现同步,还是音乐演奏,指挥者负责对锁进行解锁,演奏者尝试获得锁,得到锁之后进行演奏,完成后上锁(注意要求锁的实现必须支持跨线程操作)
- 信号量是一种可以计数的互斥锁
-
使用互斥锁实现计算图:
- 为每一条边分配互斥锁,初始化时全部锁定
- 对于一个节点,需要获得所有入边的锁才能继续
- 计算完成后,释放出边对应的锁
void T_worker(int id) { for (int i = 0; i < LENGTH(edges); i++) { struct Edge *e = &edges[i]; if (e->to == id) { mutex_lock(&e->mutex); } } printf("Start %d\n", id); sleep(1); printf("End %d\n", id); sleep(1); for (int i = 0; i < LENGTH(edges); i++) { struct Edge *e = &edges[i]; if (e->from == id) { mutex_unlock(&e->mutex); } } } int main() { for (int i = 0; i < LENGTH(edges); i++) { struct Edge *e = &edges[i]; mutex_lock(&e->mutex); } for (int i = 0; i < N; i++) { create(T_worker); } }
-
只使用互斥锁的灵活性较差,比如游泳馆需要先拿手环才能进入更衣室,但是不是一次只能进一人,而是希望控制同时有 n 人在更衣室,这就要使用"能计数"的互斥锁,就是信号量
- 信号量分为 P (wait) V(post)两种操作
- 当信号量容量限制为 1 时就是互斥锁
void P(sem_t *sem) { // P - prolaag // try + decrease/down/wait/acquire atomic {//只是一个实现的示意,可以使用条件变量来实现 wait_until(sem->count > 0) { sem->count--; } } } void V(sem_t *sem) { // V - verhoog // increase/up/post/signal/release atomic { sem->count++; } }
- 当信号量容量限制为 1 时就是互斥锁
信号量的应用¶
- 使用 PV 代替加锁解锁操作,代替互斥锁实现同步;
-
管理计数型资源;
-
join 的实现
int count; sem_t done; void worker_init(int T) { count = T; SEM_INIT(&done, 0); } void worker_done(int id) { V(&done);//完成一个任务,信号量加一 } void worker_join() { for (int i = 0; i < count; i++) { P(&done);//需要三个信号量,即任务全部完成才能继续 } } //使用方式 int main() { worker_init(4); for (int i = 0; i < 4; i++) { create(T_worker); } worker_join(); printf("Workers joined.\n"); } -
读者锁-写者锁:
- 只能有一个写者进入临界区,但是多个读者可以同时进入(一个读者能进,别的也都应该能进)
- 第一个读者获得锁,最后一个完成的读者释放锁
typedef struct _rwlock_t { sem_t lock; // binary semaphore (basic lock) sem_t writelock; // used to allow ONE writer or MANY readers int readers; // count of readers reading in critical section } rwlock_t; void rwlock_init(rwlock_t *rw) { rw->readers = 0; sem_init(&rw->lock, 0, 1); sem_init(&rw->writelock, 0, 1); } void rwlock_acquire_readlock(rwlock_t *rw) { sem_wait(&rw->lock); rw->readers++; if (rw->readers == 1) sem_wait(&rw->writelock); // first reader acquires writelock sem_post(&rw->lock); } void rwlock_release_readlock(rwlock_t *rw) { sem_wait(&rw->lock); rw->readers--; if (rw->readers == 0) sem_post(&rw->writelock); // last reader releases writelock sem_post(&rw->lock); } void rwlock_acquire_writelock(rwlock_t *rw) { sem_wait(&rw->writelock); } void rwlock_release_writelock(rwlock_t *rw) { sem_post(&rw->writelock); }
-
使用互斥锁来实现
#include <pthread.h> typedef struct _rwlock_t { pthread_mutex_t lock; // mutex for protecting the readers count pthread_mutex_t writelock; // mutex for allowing ONE writer or MANY readers int readers; // count of readers reading in critical section } rwlock_t; void rwlock_init(rwlock_t *rw) { rw->readers = 0; pthread_mutex_init(&rw->lock, NULL); pthread_mutex_init(&rw->writelock, NULL); } void rwlock_acquire_readlock(rwlock_t *rw) { pthread_mutex_lock(&rw->lock); rw->readers++; if (rw->readers == 1) { pthread_mutex_lock(&rw->writelock); // first reader locks writelock } pthread_mutex_unlock(&rw->lock); } void rwlock_release_readlock(rwlock_t *rw) { pthread_mutex_lock(&rw->lock); rw->readers--; if (rw->readers == 0) { pthread_mutex_unlock(&rw->writelock); // last reader releases writelock } pthread_mutex_unlock(&rw->lock); } void rwlock_acquire_writelock(rwlock_t *rw) { pthread_mutex_lock(&rw->writelock); // writer locks writelock } void rwlock_release_writelock(rwlock_t *rw) { pthread_mutex_unlock(&rw->writelock); // writer releases writelock } -
通过信号量直接实现哲学家吃饭会存在死锁
void Tphilosopher(int id) { int lhs = (id + N - 1) % N; int rhs = id % N; while (1) { // Come to table // P(&table); P(&avail[lhs]); printf("+ %d by T%d\n", lhs, id); P(&avail[rhs]); printf("+ %d by T%d\n", rhs, id); // Eat. // Philosophers are allowed to eat in parallel. printf("- %d by T%d\n", lhs, id); printf("- %d by T%d\n", rhs, id); V(&avail[lhs]); V(&avail[rhs]); // Leave table // V(&table); } } - 使用条件变量改进,只有当两个叉子都可用时才同时拿起
avail[lhs] && avail[rhs] - 从桌子上赶走一个人,添加一个信号量控制上桌吃饭的人数
- 一个人反着拿,如都先拿编号小的叉子
同步方式间的关系与对比¶
- 信号量
- 互斥锁的自然推广
- 干净、优雅:没有条件变量的 “自旋”
-
条件变量
- 万能:适用于任何同步条件,能处理更加复杂的问题
- 不太好用:代码总感觉不太干净
-
用条件变量实现信号量
void P(sem_t *sem) { hold(&sem->mutex) { while (!COND) cond_wait(&sem->cv, &sem->mutex); sem->count--; } } void V(sem_t *sem) { hold(&sem->mutex) { sem->count++; cond_broadcast(&sem->cv); } } -
用信号量实现条件变量
void wait(struct condvar *cv, mutex_t *mutex) { mutex_lock(&cv->lock); //更新正在等待的数目 cv->nwait++; mutex_unlock(&cv->lock); //释放原先线程的锁进行休眠 mutex_unlock(mutex); //!!此处放弃了mutex的锁,那么如果此时其他线程执行了broadcast,而这里还没到P就会造成信号量的丢失,即信号量可能被其他线程抢走,造成生产者唤醒生产者的死锁 // 信号量无法实现这种机制,其实还是需要条件变量来实现release-wait的原子操作 //等待信号量 P(&cv->sleep); //重新加锁 mutex_lock(mutex); } void broadcast(struct condvar *cv) { mutex_lock(&cv->lock); //加入对应等待者数目的信号量 for (int i = 0; i < cv->nwait; i++) { V(&cv->sleep); } cv->nwait = 0; mutex_unlock(&cv->lock); } - 出现了消费者唤醒消费者的问题
并发 bug¶
- bug 的触发需要:编译器+编译选型+特别的机器+运气
- 初学者应该只用"绝对正确"的实现
atomic_xchgpthread_mutex_lock
调试理论¶
-
需求-设计-代码(Fault/Bug 目标)-执行(Error)-失败(Failure 可以观测的结果错)
- 调试困难的原因:error 和 failure 距离太远。应该频繁进行检查(如 assert)缩短距离
如果我们能判定任意程序状态的正确性,那么给定一个 failure,我们可以通过二分查找定位到第一个 error 的状态,此时的代码就是 fault (bug)。
- 调试困难的原因:error 和 failure 距离太远。应该频繁进行检查(如 assert)缩短距离
-
调试 = 观察状态机执行 (trace) 的某个侧面
- 缩小错误状态可能产生的位置(对程序进行划分)
- 提出假设,作出验证
-
printf:灵活可控、能快速定位问题大概位置、适用于大型软件;无法精确定位、大量的 logs 管理起来比较麻烦
-
gdb:精确、指令级定位、任意查看程序内部状态;耗费大量时间
-

-
-fsanitize=address使用动态程序分析,如判断是否有数组越界
常见的并发 bug 及处理¶
死锁¶
-
AA 死锁:一个程序两次索要一个锁(在持有锁的情况下继续 lock)
- 由于函数调用、嵌套的问题,可能不是那么容易被发现
-
ABBA 死锁
- A: lock (1), lock (2)
- B: lock (2), lock (1)
- 即哲学家吃饭问题
-
死锁产生的必要条件(看成袋子里的球)
- 互斥,一个口袋一个球,得到球才能继续
- 得到球的人想要更多的球
- 不能抢别人的持有的球
- 形成了循环等待的关系、
-
就是说打破上面任何一个条件就可以实现预防死锁
- 打破条件一:无等待数据结构(通过更强大的硬件原子指令),不许要获取锁,通过原子指令就能实现操作
- 打破条件二:原子取锁,要不取走,要不都不取
- 打破条件三:一个线程加锁失败就放弃所有已经持有的锁,重新开始整个过程
- 打破条件四:任何时刻操作系统中锁有限,给所有锁按照从小到大编号,在获取锁时总是按照从小到大获取
-
通过调度避免死锁
- 在每次分配资源时分析分配带来的死锁风险,只有在不产生死锁的情况下,系统才分配资源
- 通过避免会发生死锁的两个线程同时执行来避免发生死锁
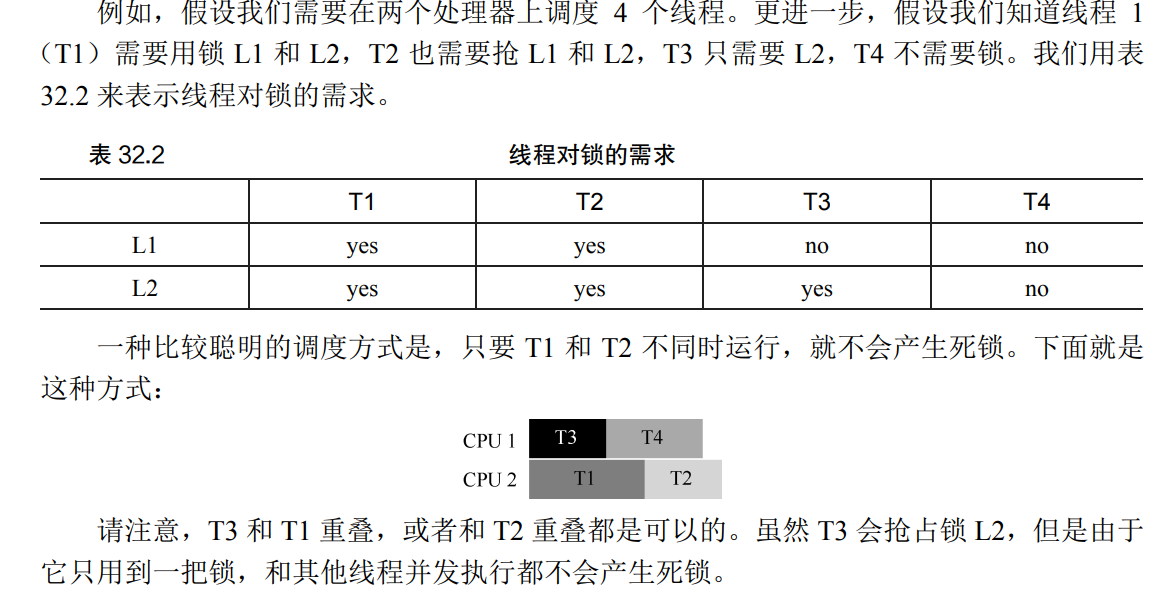
-
线程安全算法
- 调度算法就是避免程序进入不安全状态(安全状态:系统能按照某种进程推进顺序为每个进程分配资源,直至满足每个进程对资源的需求,使进程都可以顺利完成,这就是一个安全序列,如果找不到一个安全系列,那么系统就处于不安全状态)
- 系统处于安全状态则一定有不会发生死锁的调度,在不安全状态下可能会发生死锁
银行家算法¶
- 数据结构
- 可利用资源向量 Available:含有 \(m\) 个元素的数组,\(Available[j]=K\) 表示系统中有 \(K\) 个 \(j\) 类资源可用
- 最大需求矩阵 MAX:\(n\times m\),定义系统中 \(n\) 个进程对 \(m\) 种资源的需求 \(Max[i,j]=K\) 表示进程 \(i\) 对资源 \(j\) 的最大需求为 \(K\)
- 分配矩阵 Allocation:\(n\times m\),定义系统没类资源已经分配给每个进程的数目 \(Allocation[i,j]=K\) 表示进程 \(i\) 已经分到 \(j\) 类资源的数目为 \(K\)
- 需求矩阵 Need:\(n\times m\),表示每个进程剩下来还需要多少资源,\(Need[i,j]=K\) 表示进程 \(i\) 还需要资源 \(j\) 的数目位为 \(K\)
- 有 \(Need+Allocation=MAX\)
- 算法过程
- 收到请求 \(Request_{i}[j]=K\) 即进程 i 请求 j 个资源 K
- 首先检查 \(Request_{i}[j]\leq Need[i][j]\),否则说明需要资源数超过了宣称值
- 检查 \(Request_{i}[j]\leq Available[j]\) 即是否有足够的资源
- 尝试进行分配并更新矩阵
- 执行安全性检查算法,如果安全才会真正进行资源分配

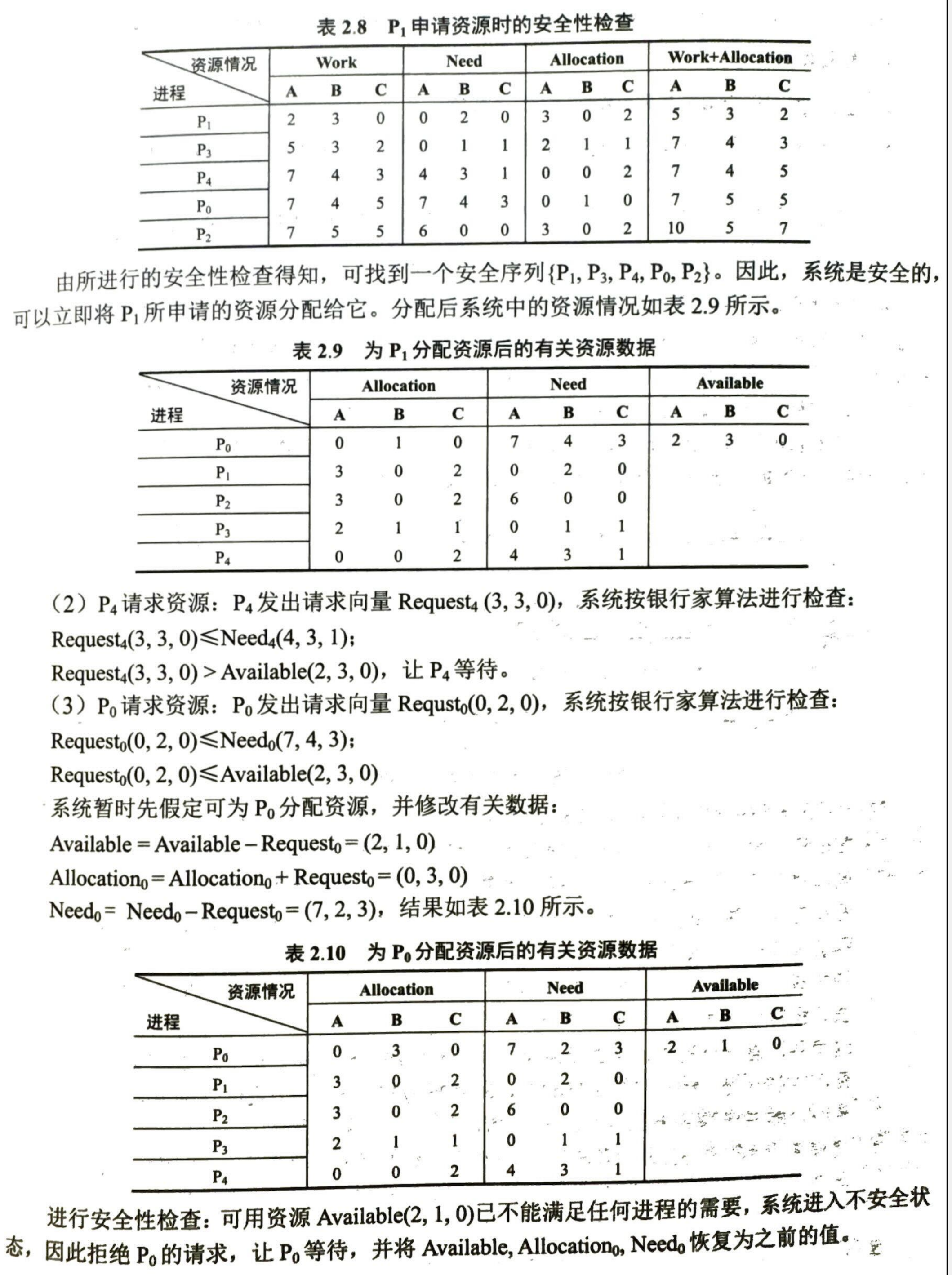
- 安全性检查算法
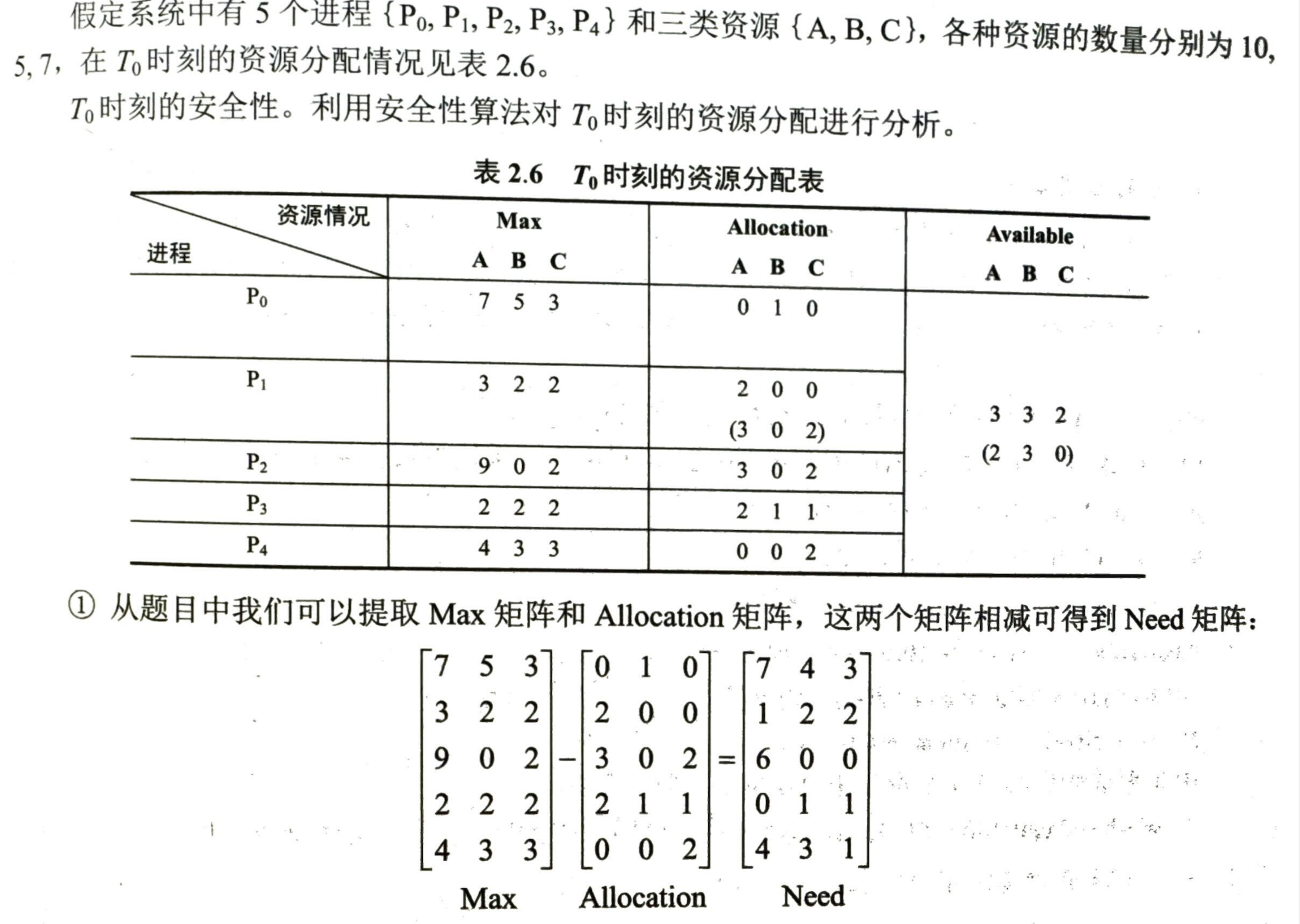
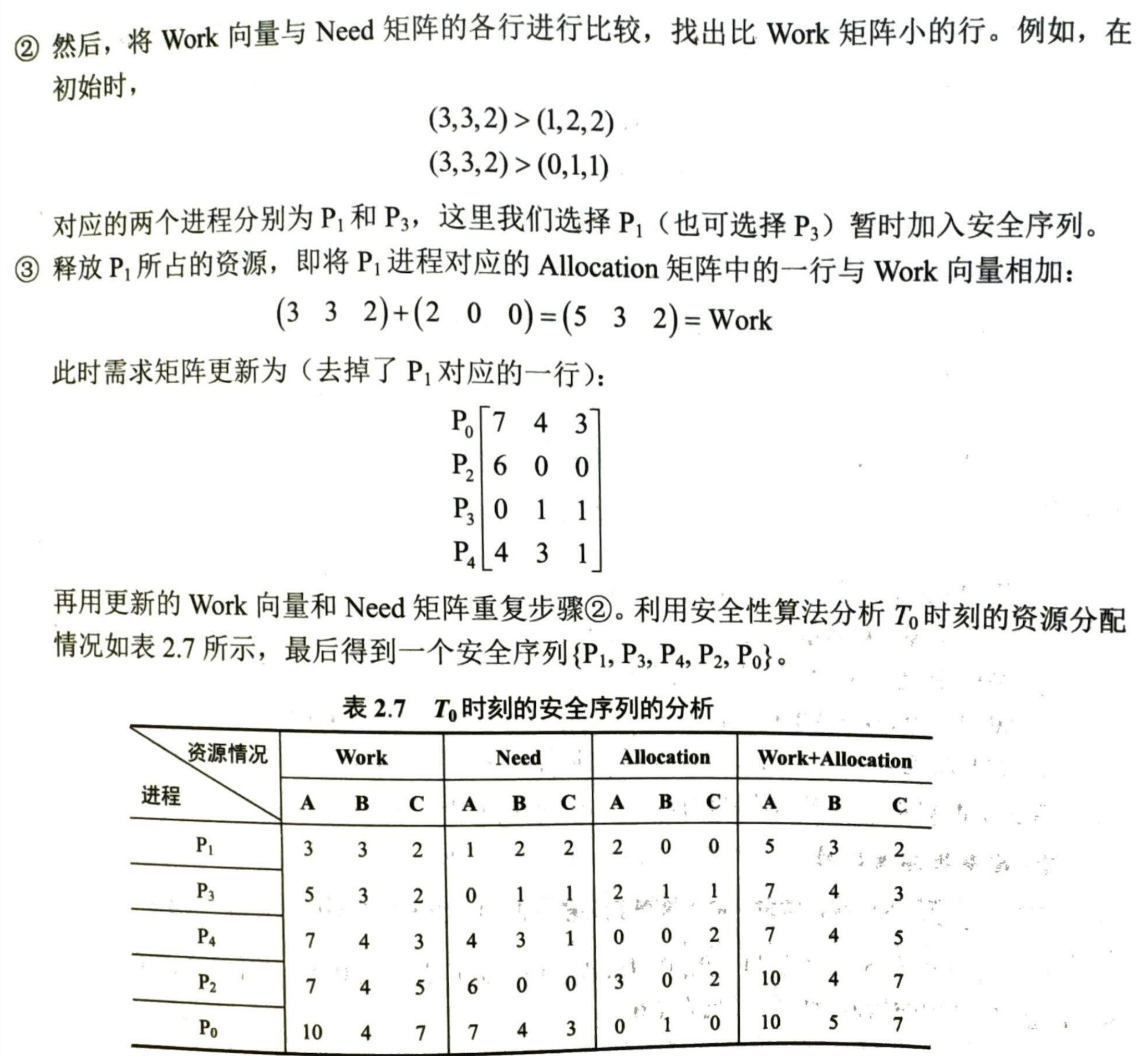
- 工作向量 work,初始时有 \(work=Available\)
- 初始时安全序列为空
- 从 need 序列中寻找不在安全序列中并且小于等于 work 的进程加入安全序列
- 加入图了安全序列的进程可以顺利执行,并释放初始占有的资源,\(work=work+Allocation[i]\)
- 当安全序列已经含有了所有进程,则系统处于安全状态
数据竞争¶
- 不同线程同时访问同一个内存,且至少有一个是写,“谁跑赢谁操作”
- 用锁保护好共享数据,消灭一切数据竞争
- 出现原因
- 上错了锁
- 忘记上锁
原子性、顺序违反¶
- “原子性” 一直是并发控制的终极目标。对编程者而言,理想情况是一段代码的执行要么看起来在瞬间全部完成,要么好像完全没有执行过。代码中的副作用:共享内存写入、文件系统写入等,则都是实现原子性的障碍。
- 但是又不能让什么都是原子的(那就是串行了)
- 做一件事需要被拆解为多个步骤,并且每个步骤需要上正确的锁
- ABA:代码被"插入"
- 即便分别对两段分别执行的代码上锁,还是会出现违反原子性的问题
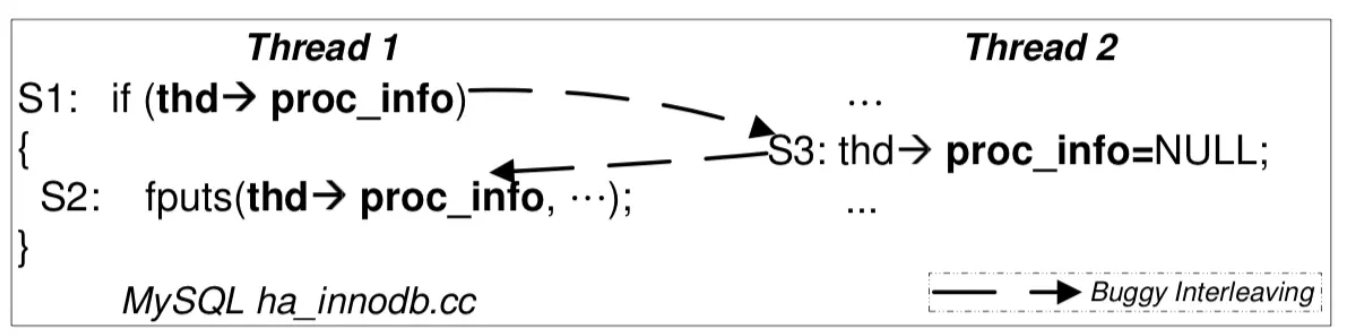
- BA:顺序违反
- 事件未按预定的顺序发生
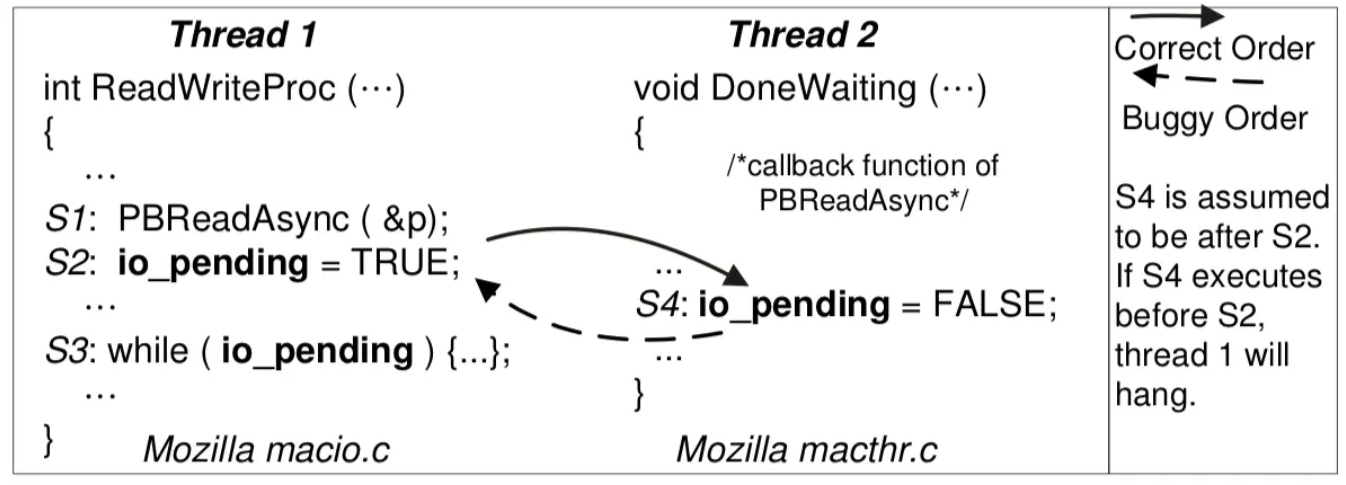
- 在设置为 true 之前就设置为了 false,之后就死循环了
避免并发 bug¶
自动运行时检查¶
-
希望在运行时检查有明确定义的问题
- AA、ABBA 死锁
- 数据竞争
- 溢出
- use after free
-
运行时死锁检查
- 记录一个线程执行过程中上锁解锁的记录

- 上面为两个线程上锁解锁的操作序列
- 每一个节点表示一个锁,当发现线程持有 u 时获取 v 那么就加入边 (u, v),即为每个已持有的锁与新锁之间添加一条边
- 如果存在环那么就存在死锁
- 为了提高性能,将一行初始化的锁认为是同一个锁(即用文件名+行号来表示锁)
-
这是一个逐渐完善建图的过程(随着程序的运行,遇到更多的锁)
-
运行时数据竞争检查
- 对发生在不同线程且至少有一个是写的 x, y 检查是否 x\<y V y\<x 恒定,即是否有明确的 happens-before 关系(如通过互斥锁实现)
-
动态检查工具
- AddressSanitizer(ASAN)非法内存访问检查
- ThreadSanitizer(TSAN)数据竞争检查
- ...
防御性编程¶
-
防止栈溢出
- 如在栈起始和结束位置存储一些特殊数字(Canary)
- 检查这些数字,如果数字发生变化(不再满足 assert)就说明出现了栈溢出
-
更简单的动态检查的实现(比如上面的成熟工具不能再操作系统实验中使用)
- Lockdep
- 在小程序中可以通过请求锁超时来判断是否发生了死锁
int spin_cnt = 0; while (xchg(&lk, ❌) == ❌) { if (spin_cnt++ > SPIN_LIMIT) { panic("Spin limit exceeded @ %s:%d\n", __FILE__, __LINE__); } }
- 在小程序中可以通过请求锁超时来判断是否发生了死锁
- AddressSanitizer
- 对 double malloc/free 可以通过对已分配的区域刷漆进行检查
- 新分配的区域必须是没有被分配的
- free 的区域必须是已经被分配的
// allocation for (int i = 0; (i + 1) * sizeof(u32) <= size; i++) { panic_on(((u32 *)ptr)[i] == MAGIC, "double-allocation"); arr[i] = MAGIC; } // free for (int i = 0; (i + 1) * sizeof(u32) <= alloc_size(ptr); i++) { panic_on(((u32 *)ptr)[i] == 0, "double-free"); arr[i] = 0; }
-
ThreadSanitizer
- 检查数据是否会自己发生变化
int observe1 = x; delay(); int observe2 = x; assert(observe1 == observe2);
- 检查数据是否会自己发生变化
-

#define CHECK_INT(x, cond) \
({ panic_on(!((x) cond), \
"int check fail: " \
#x " " #cond); \
})
#define CHECK_HEAP(ptr) \
({ panic_on(!IN_RANGE((ptr), heap)); })
补充¶
基于事件的并发¶
- 图形界面程序、网络服务器等通常使用基于事件的并发
- 等待某个事件发生,当它发生时,做某些工作
-
基于事件的系统通常围绕一个核心组件——事件循环运作。事件循环不断检查是否有新的事件发生,并将这些事件分发给对应的处理器或回调函数。
-
很多基于事件的并发系统(比喻浏览器 js)本质本质上是单线程循环系统,因此自然不存在并发问题
- 不存在同时读写:无竞态
- 无死锁...
- 由于只有一个线程,需要使用非阻塞 io (异步 IO)保持响应