持久化
物理存储¶
- 希望更大、更多的数据能 “留下来” (并且被操作系统有效地管理起来)
- 持久存储器本质上就是一个巨大的 bit/byte array,允许按照 block 读写
磁存储¶
- 磁带 1 D
- 价格低廉,容量较高,存在机械部件并且存在丢失风险可靠性一般
- 勉强顺序读写,但是几乎不支持随机读写
- 主要用于冷数据的存档和备份

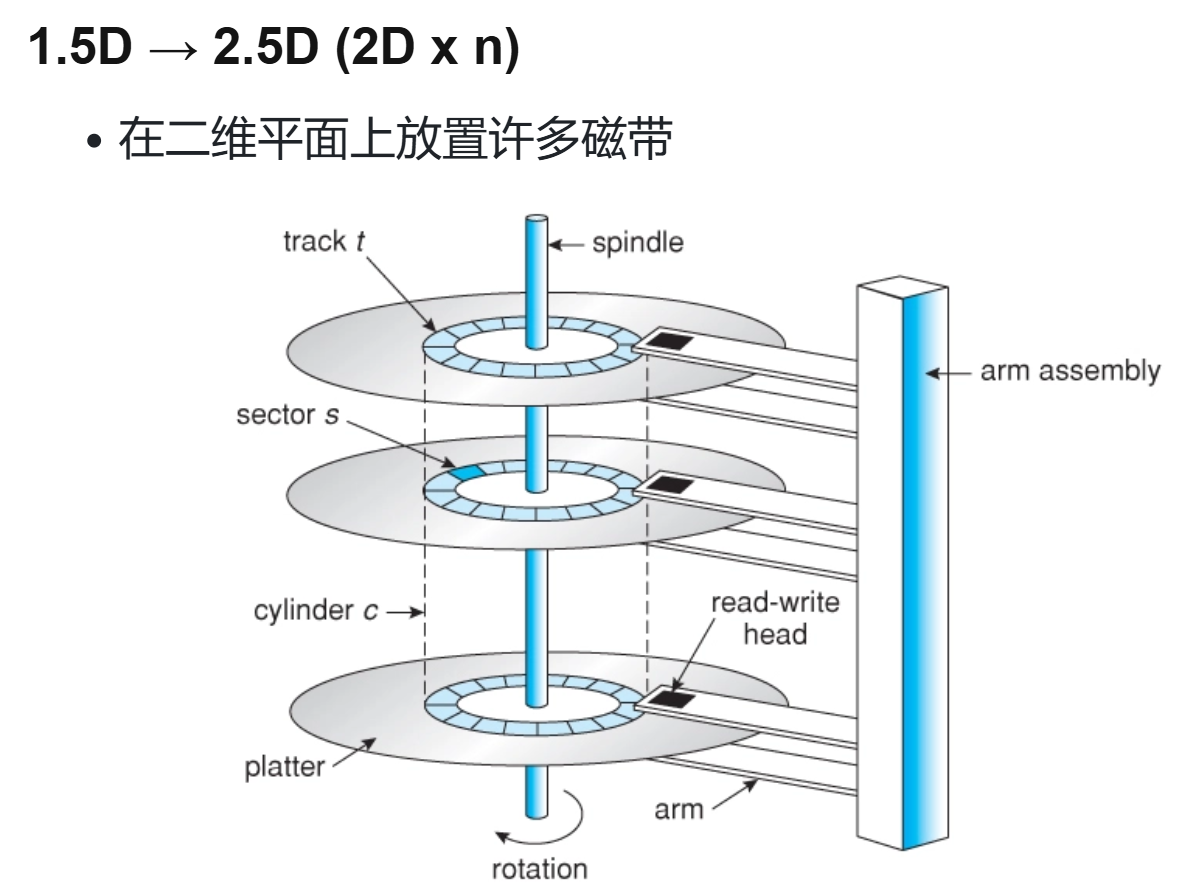
- 价格低容量高,较高数据读写性能,勉强随机读写
- 软盘
- 价格低,容量一般,可靠性低
- 顺序读写随机读写都很慢
坑存储¶
- 光盘:在反射平面上挖出粗糙的坑
- 激光扫过表面,就能读出坑的信息来
- 一种只读的存储介质
- 成本极低(批量生产),容量可靠性较好
- 顺序读取性能一般,随机读取很差
- 主要用于数据分发,逐渐被高速网络替代
电存储¶
- 去除机械部件,降低延迟
- 价格低,容量极高,可靠性高,顺序读取极快,随机读取极快
- 缺点:读写寿命差

-
主控负责将数据均匀的写入到不同的块
- Page (读取的最小单位, e.g., 4KB)
- Block (擦除和写入的最小单位, e.g., 4MB)
- 写时拷贝
-
NAND 闪存技术
- 写入之前从事需要先擦除一大块内存,产生磨损和较大的时间代价
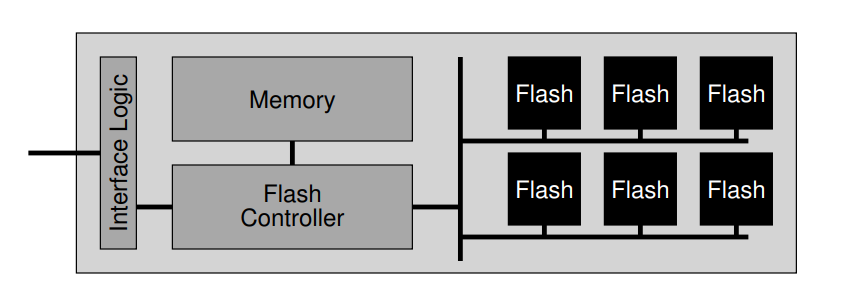
- FLT 负责接收逻辑块上的读写请求,并将其转化为底层物理块和物理页上的低级读取、擦除和编程命令。
- 使用直接(固定)映射效率较低,并且存在磨损寿命问题
- 日志模式:保存一个映射表存储系统中逻辑块对应的物理地址。提升了性能(避免每次写入都擦除将随机写入转化为顺序写入),并且提供了磨损均衡的功能
文件管理¶
- 数据项:文件系统中最低级数据组织形式:
- 基本数据项:描述一个对象的某种属性的一个值(数据中最小逻辑单位)
- 组合数据项:多个基本数据项组成
- 记录:相关数据项的集合,描述对象在某方面的属性
- 文件:具有文件名的一组相关元素的集合。即有名字的对象,是一个字节序列
- 文件有一个 offset 指针,指向访问的位置(就不需要进程自己维护进度)
- read 和 write 都会自动维护 offset,lseek 则可以直接修改 offset 的位置
- open 一个文件时创建一个新的 offset
- 所有命令(cat 等)均是基于这一系列机制和系统调用来实现的
- 文件描述符:指向操作系统对象的指针(操作系统对象的访问都需要指针)
- 文件是以硬盘为载体存储在计算机上的信息集合
-
文件系统用于实现对文件的维护管理
-
文件控制块:操作系统通过文件控制块 FCB来维护文件元数据
- FCB 的有序集合就是文件目录,一个 FCB 就是一个文件目录项(也可以被视为文件-目录文件)
- 存储文件的基本信息(文件名、物理位置);基本控制信息(存取权限);使用信息(上次修改时间)
- 目录结构:由于检索时可能不需要 FCB 完整信息,可以将文件名与文件描述信息分离,将文件描述信息单独为索引节点,文件目录中的每个目录项进包括文件名和索引节点号(这样就减少了单个条目的大小)
文件的基本操作¶
- 创建文件:为新文件分配外存空间;在目录中创建目录项
- 删除文件:根据文件名查找目录,删除对应的目录项和文件控制块然后回收文件占用的存储空间
- 读写文件:先根据文件名查找目录,找到指定文件的目录项后从中得到文件在外存中的地址,之后利用目录项中的指针进行读写操作
- 访问类型:读、写、执行(装入内存执行)、追加(append)、删除、列表清单(元数据)
-
访问控制
- 根据用户身份进行控制,对用户进行分类:拥有者、组内其他成员、其他
- 3(用户类型)*4(读、写、删除、执行)位表示
-
打开文件:
- 多次读写一个文件时总需要检索目录,为了减少重复操作,系统维护一个包含所有打开文件信息的表(打开文件表)
- open 打开文件后将目录项从外存复制到内存的打开文件表,并向用户返回文件描述符
- 用户再次打开时可以直接用文件描述符从打开文件表获取信息(即只有初次打开才使用文件名)
- close 后从打开文件表移除
- 多进程文件
- 多个进程可以同时打开文件,使用两级表来表示:
- 系统表:包含与进程无关的信息,如文件在磁盘上的位置、大小等
- 进程表:进程对文件的使用信息,如读写指针等
- 一个进程 open 时,在进程表中增加了一个条目,指向系统表的对应条目
- 系统表会维护打开计数器,文件不再(计数器为 0)使用时自动从系统表删除
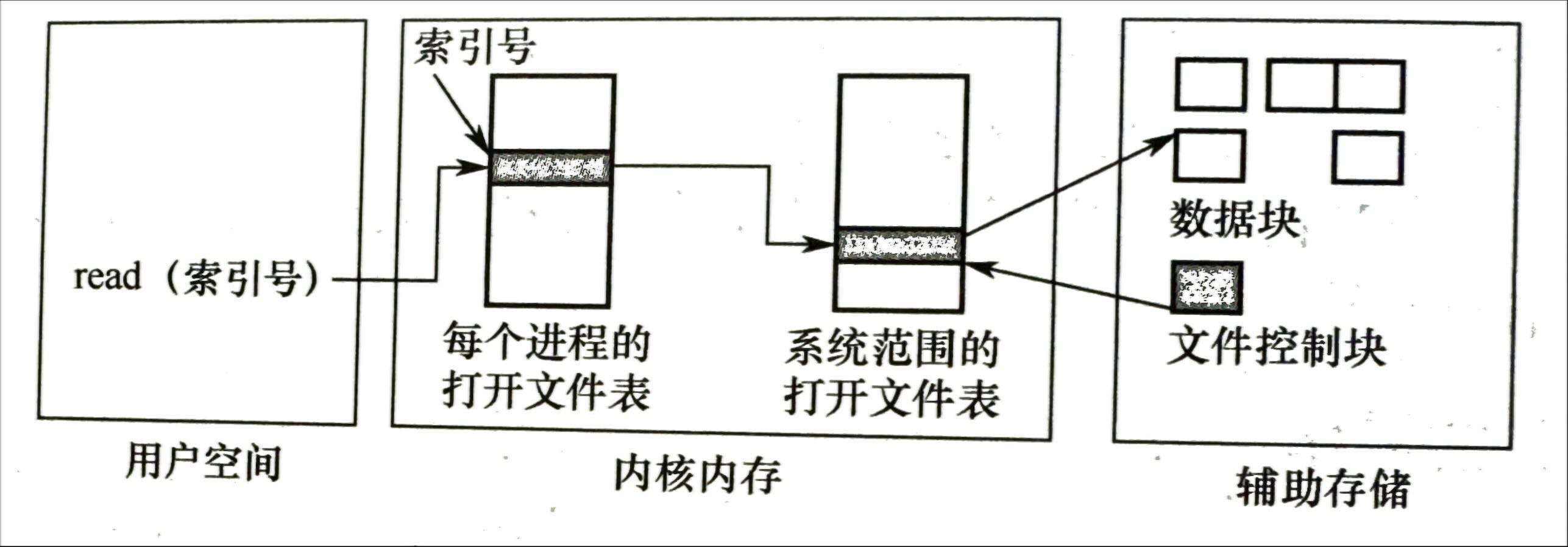
- 多个进程可以同时打开文件,使用两级表来表示:
文件结构¶
逻辑结构¶
- 无结构文件:由字符串流组成(流式文件),通过读写指针以字节的形式进行访问(只能穷举搜索),源程序、可执行文件等都是。
-
有结构文件:由一个以上的记录构成
- 定长记录:文件中所有记录长度都相同,检索较快(随机访问)
- 变长记录:长度不一定相同,只能顺序访问,较慢
-
顺序文件
- 文件中的记录按顺序排序,读写效率较高,但是查找、修改较慢
- 串结构:记录之间的顺序取决于插入顺序,只能顺序查找
- 顺序结构:按关键字排列,可以折半查找
- 索引文件
- 解决变长记录顺序文件不能随机访问的问题
- 索引表包含指向记录的指针和记录长度,索引表本身是一个定长记录的顺序文件
- 索引顺序文件
- 每个索引指向的项为一组记录,通过索引找到组之后再顺序查找
- 最佳划分 \(\sqrt{ n }\) 个索引,每个组 \(\sqrt{ n }\) 个条目,平均查找次数 \(\sqrt{ n }\)
- 即分块查找
- 直接文件/散列文件
物理结构¶
-
连续分配
- 每个文件在磁盘上占用连续的块
- 支持顺序访问、直接访问
- 速度较快,磁头移动距离少
- 产生外部碎片,无法满足动态增长需求,不适合对文件进行增删
-
链接分配
- 消除了外部碎片,提高利用率
- 便于动态增长即管理
- 隐式分配
- 用链表来表示,每个盘块有指向下一个盘块的指针
- 问题:只支持顺序访问、存在稳定性问题(一个块损坏)
- 可以按簇(多个连续块一组)进行分配,可以加速查找并且减少指针,但是会增加内部碎片
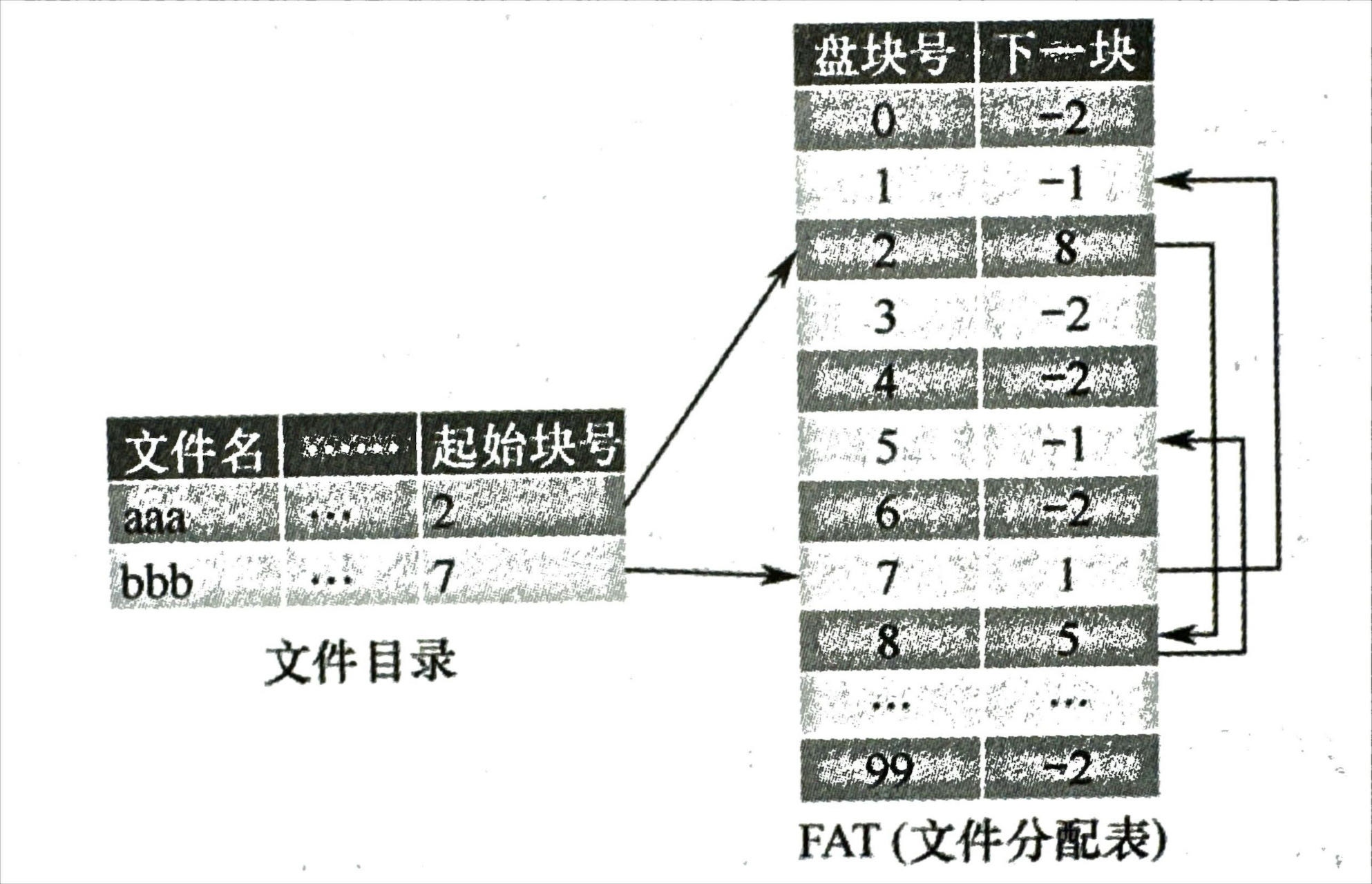
- 显示链接
- 用链接表表示块之间的链接关系,即文件分配表 FAT
- 每个表项存储盘块号和下一块的地址
- 用-1 表示最后一块,-2 表示空闲
- 支持顺序访问(FAT 不大,可以加入内存,处理很快)减少了磁盘访问次数
-
索引分配
- 单级索引
- 将每个文件的盘块号放在一起,访问时调入内存,而不需要将整个 FAT 放在内存
- 索引也作为一个块在磁盘上
- 问题时索引块占用空间,文件很大时还需要很多索引块链接
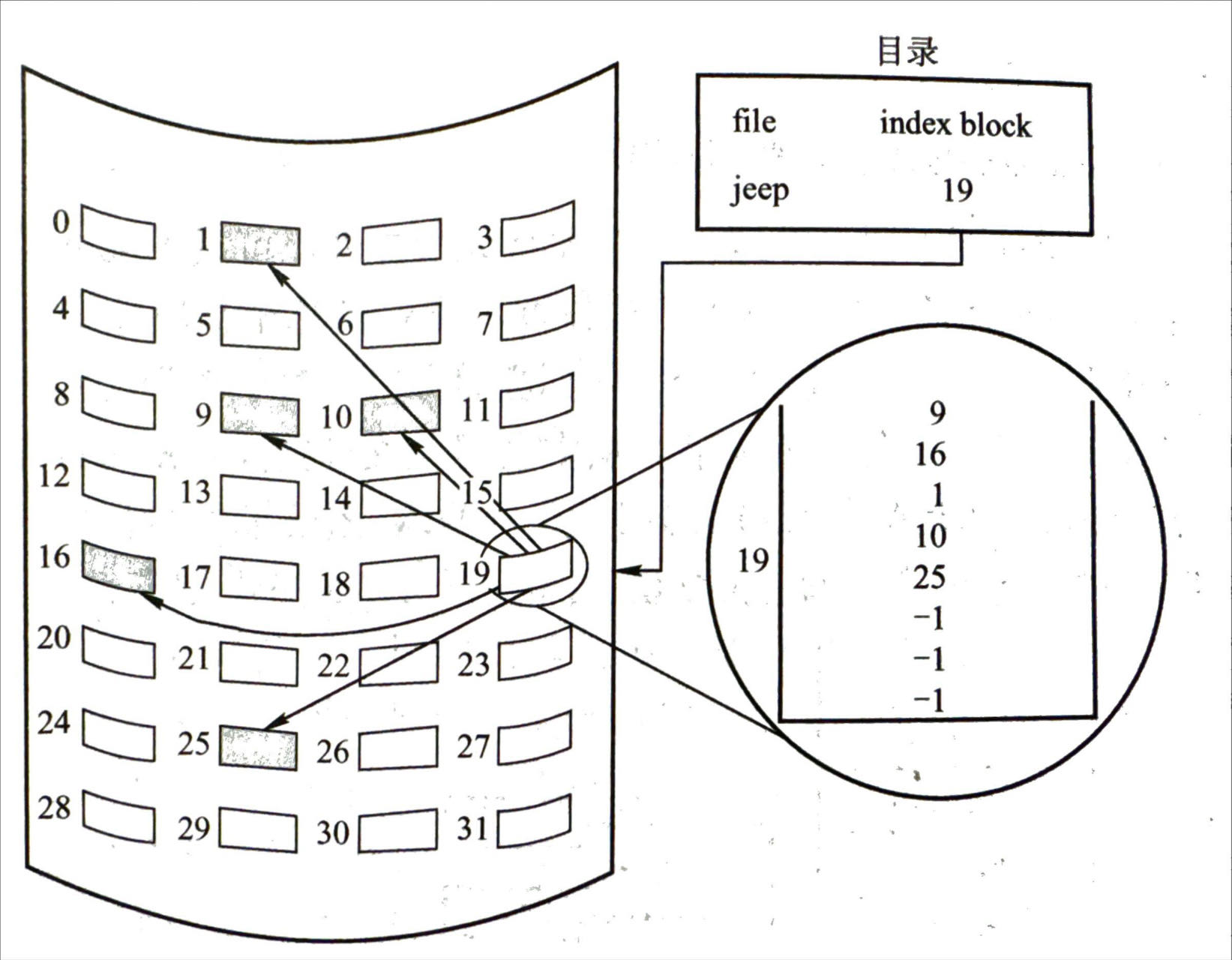
- 多级索引
- 处理索引块太多时的问题
- 问题:需要加载很多索引块,IO 开销较大
- 混合索引
- 兼顾大中小文件,假设一个块 \(4KB\)
- 对于小文件直接将每个盘块地址直接放入 FCB,直接寻址访问;比如设置 10 个直接地址(最多有 10 个块)即支持 \(40KB\)
- 对于中型文件使用单级索引,在 FCB 指向索引表,一次间址 (一个索引块里 1024 个盘块),即同时使用支持 \(4MB+40KB\)
- 对于大文件使用多级索引,如同时使用到三级,就支持 \(4TB+4GB+4MB+40KB\)
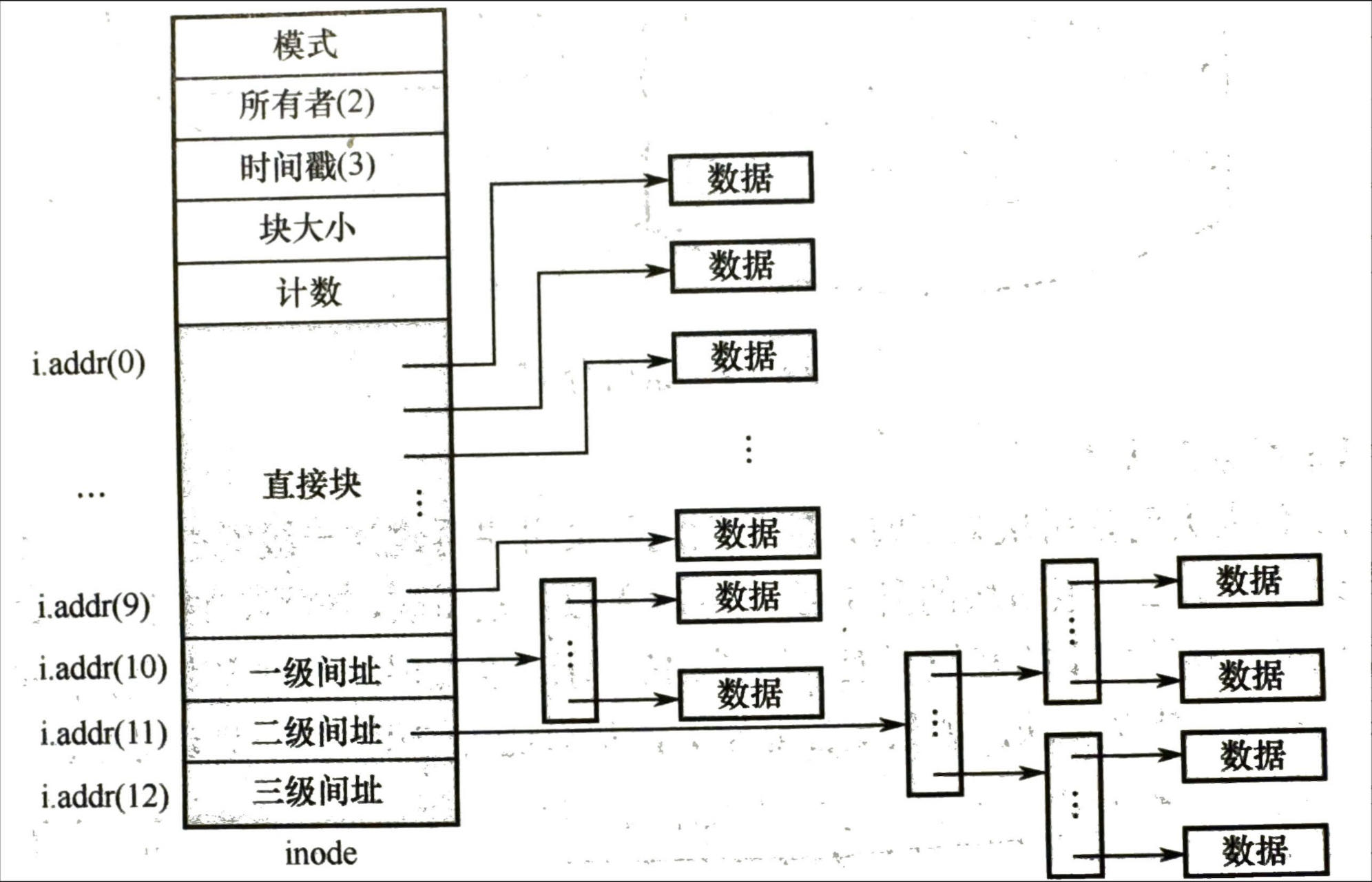
- 单级索引
目录¶
- FCB 作为文件目录项
-
目录提供了文件名到文件的映射(按名存取)
-
单级目录:线性目录表,通过遍历查找,并且不允许重名
- 两级目录:分为主文件目录(记录用户名和相应的用户目录文件的位置)和用户目录(用户所有文件的 FCB)多用户之间可以存在同名文件。但是还不够灵活
- 树形目录:提高目录的检索速度和文件系统的性能,通过文件路径名来访问文件,系统中每一个文件都有唯一的路径(大多操作系统现在都是使用树形目录)。为了避免反复查询,可以添加一个当前工作目录,使用相对路径进行访问(但是非初次访问还是使用文件描述符)
- 层次结构清晰,便于分类管理,但是查询相对较慢,并且有较多磁盘 IO
-
无环图目录:在树形目录的基础上加上一些指向同一节点的有向边,得到一个 DAG,可以更方便的共享目录、文件。
- 在想要删除节点时同样可以使用访问计数来管理
-
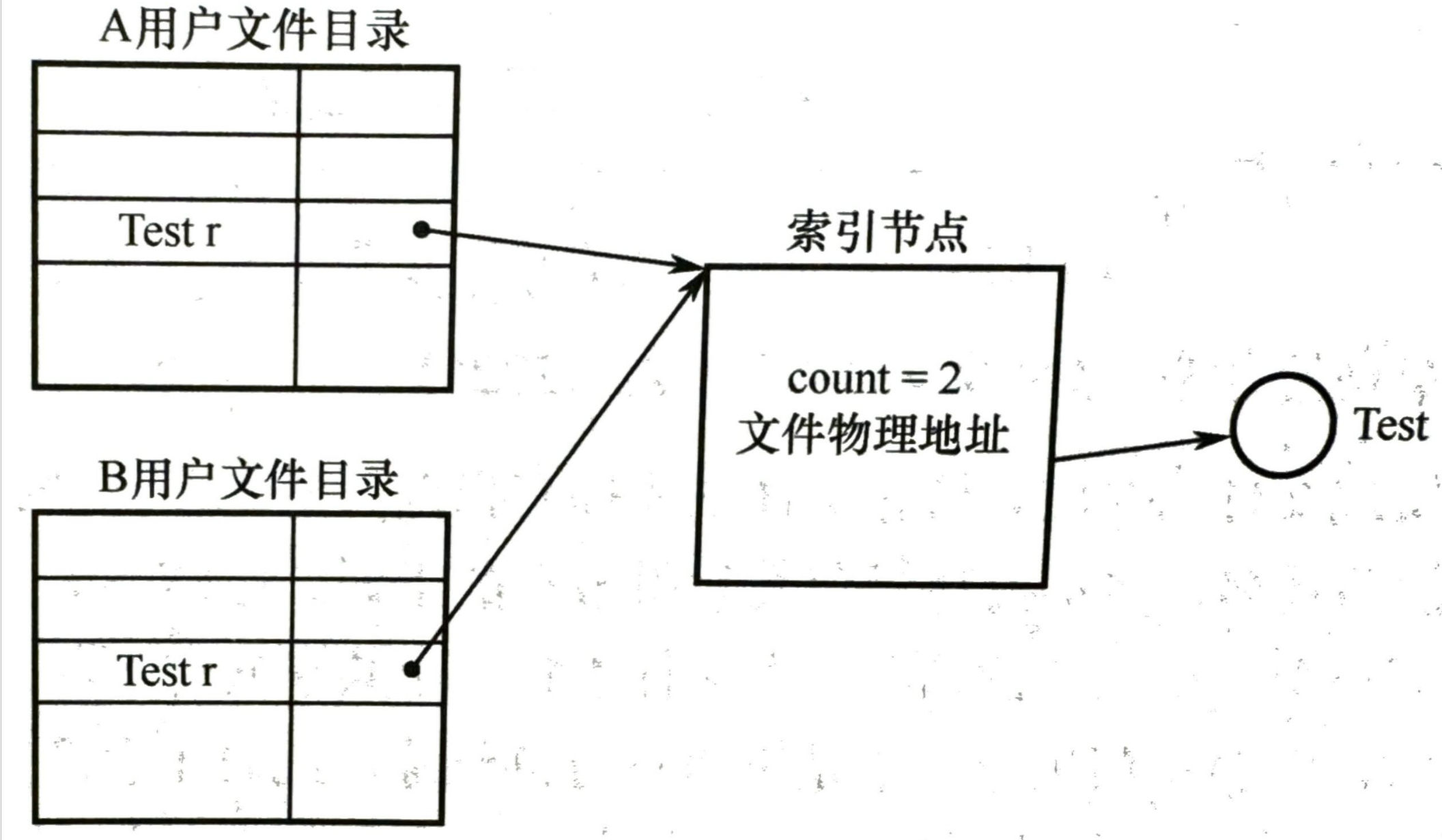
文件共享:多个用户共享一个文件时,系统中只需保留该文件的一个副本
- 硬链接:基于索引节点,两个用户的文件目录指向相同的共享文件的索引节点指针
- 软链接:利用符号链实现文件共享,创建一个 LINK 类型的新文件,指向要共享的文件(类似于快捷方式)操作系统遇到 LINK 文件后会重定位使用其中记录的路径去查询文件 F
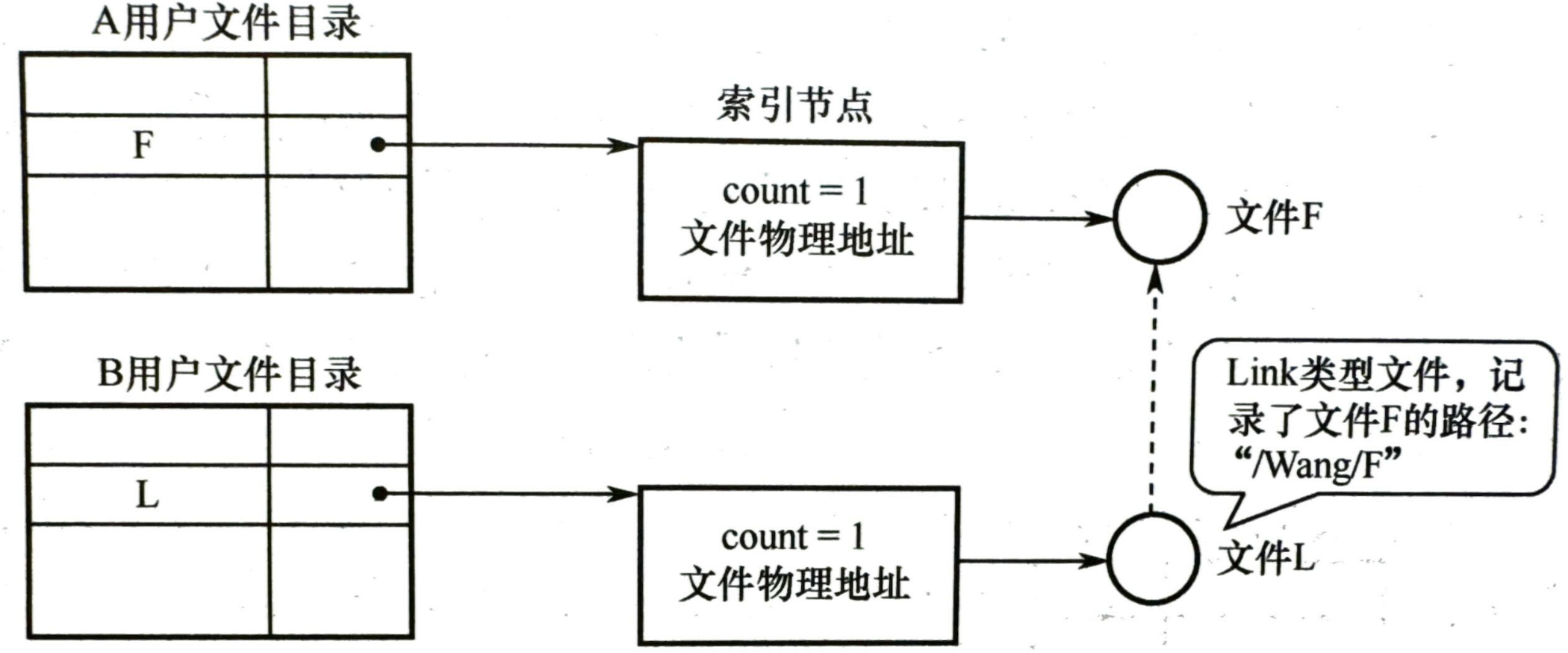
- 当文件所有者删除一个文件之后,其他用户通过 LINK 进行访问就会出错
- 硬链接:基于索引节点,两个用户的文件目录指向相同的共享文件的索引节点指针
- 目录的查询方式:线性法、查询法
文件系统¶
-
如何构建文件系统?
- 信息具有局限性:在一个树状目录中逻辑相关的数据存放在相近的目录
- 对于"非数据"文件:unix 中一切都是文件都在'/'中;windows 中一个驱动器一个文件树
-
-
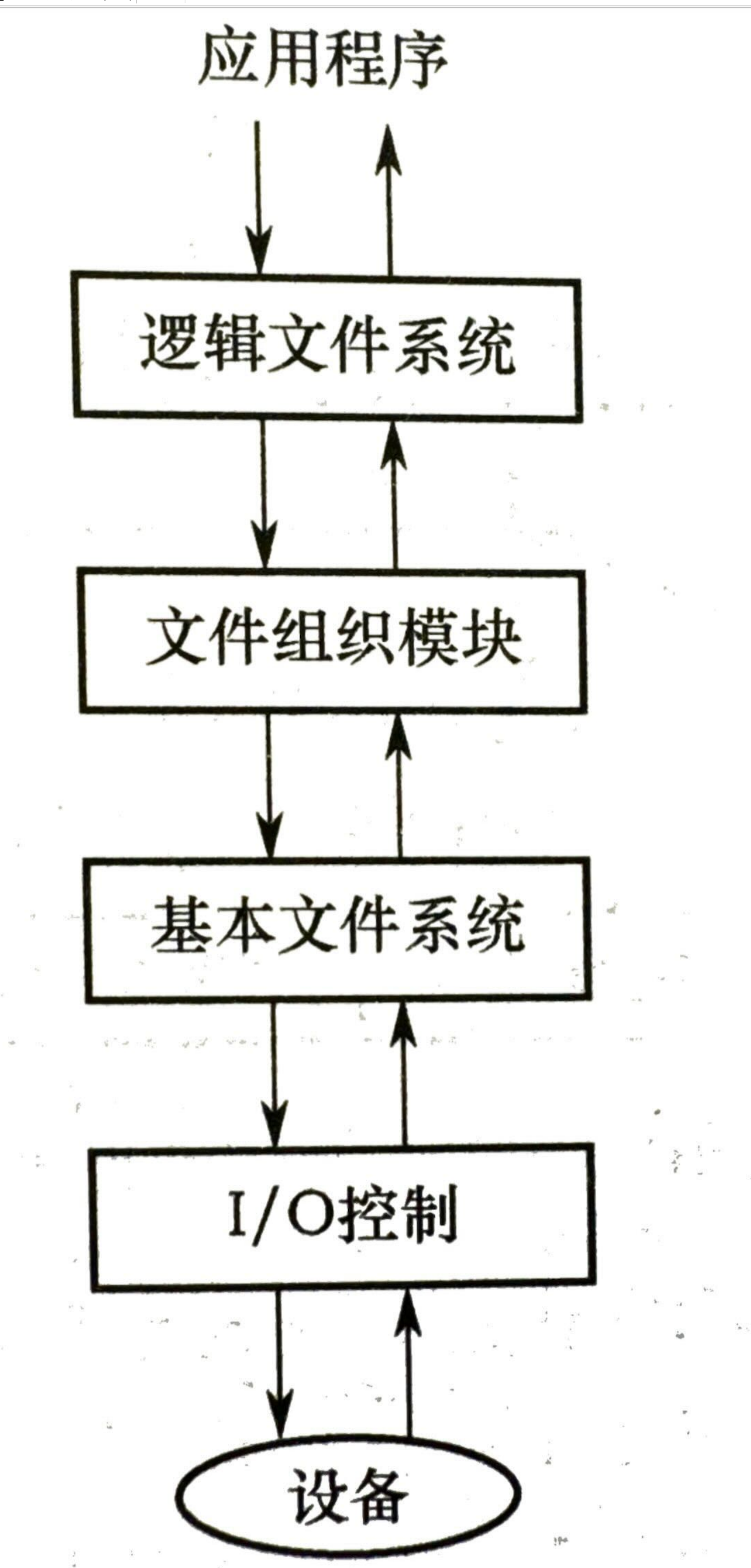
文件系统布局
- 文件系统在磁盘中的结构:磁盘每个分区有一个独立的文件系统
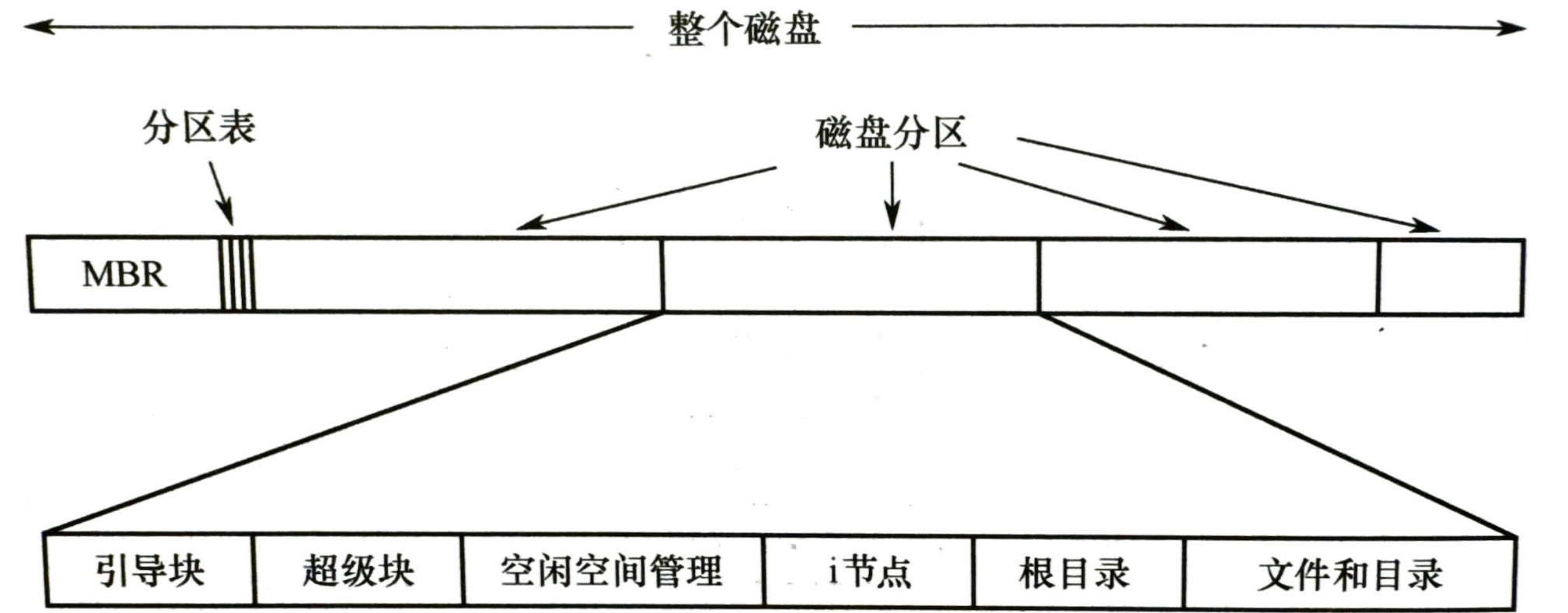
- 主引导记录 MBR:位于磁盘 0 号扇区,MBR 包含主引导程序和分区表(给出每个分区的起始和结束地址),通过 MBR 来确认活动分区,并读入对应的引导块
- 引导块:MBR 执行引导块中的程序之后负责启动该分区中的操作系统
- 超级块:包含文件系统的所有关键信息,在计算机启动时加入内存,包含:分区快的数目、大小、空闲快、空闲 FCB 等
- 文件系统在内存中的结构:用于管理文件系统并通过缓存来提高性能
- 安装表:安装的文件系统的分区的相关信息
- 目录结构和缓存:包含最近访问的目录信息
- 整个系统代开文件表
- 每个进程打开文件表记文件描述符(句柄)
- 文件系统在磁盘中的结构:磁盘每个分区有一个独立的文件系统
-
外存空闲空间的管理
- 一个磁盘可以进行分区(卷),每个分区包含目录区FCB和文件区;多个磁盘也可以通过 RAID 组成一个分区
- 存储设备管理实际上就是对外存中的空闲块进行组织和管理
- 空闲表法:
- 属于连续分配方式,类似于内存的动态分区分配,每个文件分配一段连续的存储空间
- 每个空闲区对应一个空闲表项:包含序号、起始块号和数目
- 分配上也可以使用首次、最佳适应等短发
- 回收时同样考虑进行区间合并
- 具有较高的分配速度
- 空闲链表法:
- 把所有空闲盘区组织为一个空闲链
- 空闲盘块链:一盘块为单位拉成一条链;用户请求时从开始位置选取一定数目空闲狂进行分配;释放时将盘块插入到末尾;效率较低(单位太小了)
- 空闲盘区链:将空闲盘区拉成链(每个盘区包含若干相邻的盘块),类似于动态分区分配,效率相对较高但是比较复杂
- 位示图法:
- 用二进制每一位表示磁盘中盘块的使用情况
- 如 m 个 n 位数表示 \(m\times n\) 个盘块的使用情况
- 成组链接法:
- 更适用于大型文件系统
- 将空闲盘块分组,如 100 个一组,每组第一个盘块记录下一组的数目和空闲盘块号,即由各组的第一块连接成一条链
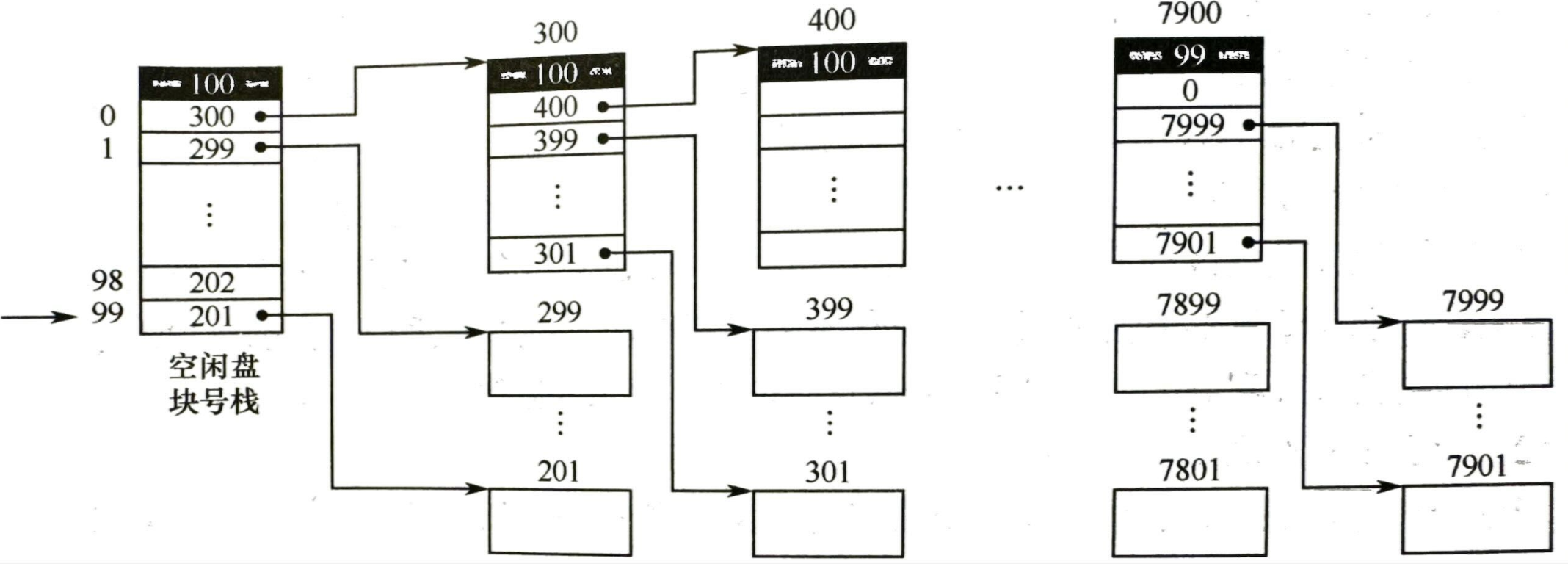
- 分配:移动指针进行分配,移动到栈底时切换到下一个分组继续分配
- 回收:将回收的盘块号放入栈顶并移动指针,已满时创建新栈
-
虚拟文件系统
- 屏蔽差异,为用户提供统一接口
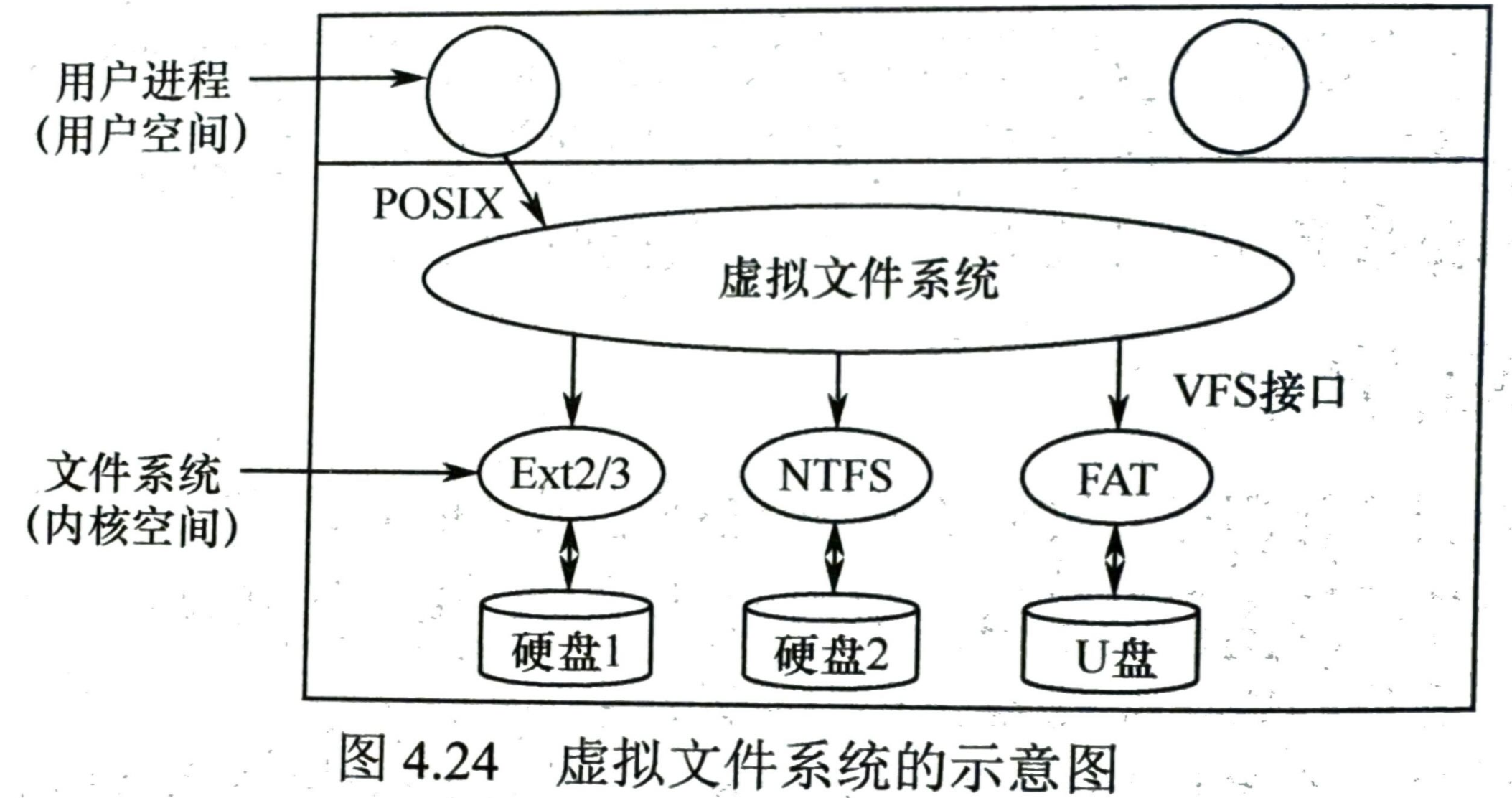
- 文件系统挂载
- 文件系统在使用之前需要先进行挂载(之后能在统一的文件系统树中进行访问,这就是目录树的拼接)
- 挂载到目录之后就可以通过目录访问设备上的文件
- 可以将不同的文件系统挂在到一棵文件系统树上
- 使用:超级块对象;索引节点对象;目录项对象;文件对象;
- 挂载镜像(虚拟磁盘),会自动创建一个新设备(loopback 设备),与镜像内容绑定
文件系统的实现¶
- 除了文件具体数据内容外,文件系统还需要存储文件的元数据信息,通常存储在 inode 结构中,专门存储在文件系统的一块固定区域。此外还需要位图(bit 表示块是否空闲),使用位图记录 inode 和数据区是否空闲。最后还需要超级快来存储一些文件系统相关的信息,如文件系统的组织形式等。
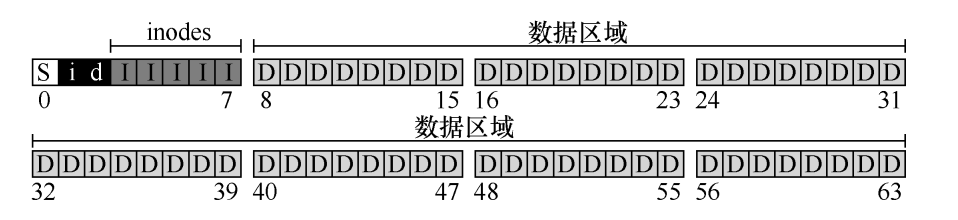
-
inode 描述的是单个文件或目录的元数据,而超级块描述的是整个文件系统的全局元数据
-
文件组织:inode(索引节点)
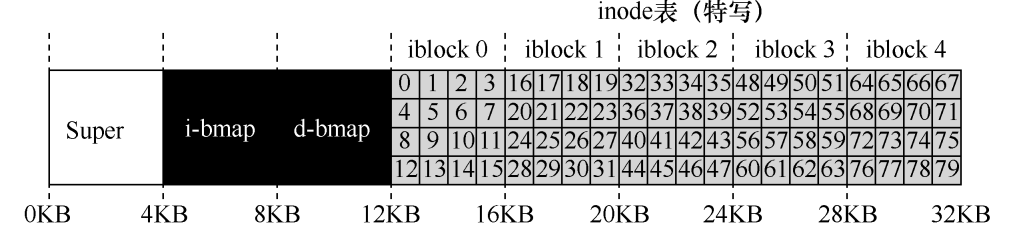
- 对于较小的文件可以直接在 inode 中存储一个或多个指针分别指向属于该文件的磁盘块,对于较大文件使用多级索引
- 读取操作:不涉及块的分配,不需要使用 bitmap
- 首先获取根目录的 inode 然后递归遍历到所需的 inode,加载到内存并分配文件描述符
- 程序通过文件描述符来访问文件
- 不再使用时文件描述符被释放
-
写入操作:设计空闲块的分配,涉及到对 bitmap、inode 和 data 的读写
-
大多数文件系统会使用系统内存来缓存来减少对文件的 IO 操作,通过批处理加速/避免不必要的操作
FAT 文件系统¶
- 物理存储设备带来的问题:本身并不能真正的随机读取,每次读取写入的都是一个固定大小的块或页
- 问题:读写放大,被迫读写连续的一块数据
- 解决方式:局部性+缓存
- 目录中一般只有十几个文件并且以小文件为主
- 文件的实现:链表表示文件所用的块

- 集中存储(next 数组)性能更好,通过集中存放多份解决安全性问题
- 目录的实现也是普通文件,操作系统根据文件内容对目录解读,使用一个线性表(数组)进行存储
- 快速格式化=FAT 表丢失,但是数据还在
- 适合小文件存储,大文件的随机访问性能较差
ext/unix 文件系统¶
- 为大小文件区分,小文件使用数组,大文件使用平衡树
快速文件系统 FSS¶
- 性能优化:尽可能多顺序存储,在存储文件时也要注意存储布局,避免过于碎片化。
- FSS 通过优化磁盘访问模式和减少磁盘寻道时间来提高文件系统的性能。如 FSS 会将文件的数据块尽量连续地存储在磁盘上,以减少磁盘头的移动次数。
- FSS 通过更有效的空间分配策略来提高磁盘空间的利用率。例如,使用较小的块大小来减少内部碎片,并通过延迟分配和灵活的 inode 管理来优化空间使用。
-
此外还提升了可靠性、一致性(日志机制、冗余机制)、扩展性、灵活性等
-
引入柱面组,每个柱面分别存储 inode、data 等信息而不是集中存储(这样同一文件的 inode 和 data 就位于同一个柱面)。这样 inode 和 data 直接交替访问(这是很常见的)就不需要移动很远的距离,可以提高访问的局部性和效率
- 新目录优先分配到空闲空间较大的 inode,同一目录下的文件尽可能分配在同一柱面,同一文件更是,由此提高局部性
- 大文件会占据整个块组,妨碍了随后的“相关”文件放置在该块组内,因此可能破坏文件访问的局部性。
- 只要平衡块的大小(大文件每个部分占据块的比例)就仍然能保证大部分时间用于有效传输的较高效率

日志文件系统 LFS¶
- 瓶颈主要在于写入性能
-
写入磁盘时,LFS 首先将所有更新缓冲在内存段中。当段已满时,它会在一次长时间的顺序传输中写入磁盘,并传输到磁盘的未使用部分。LFS 总是写入磁盘的未使用部分,然后通过清理回 收旧空间,而不是在原来的位置覆盖文件。
-
顺序写入:不仅仅是 data,需要将所有更新(包含 inode)等全部连续顺序地写入到磁盘
- LFS 会跟踪内存中的更新,收到足够数量(足够大的连续段)的更新时,会立即将它们写入磁盘,从而确保有效使用磁盘
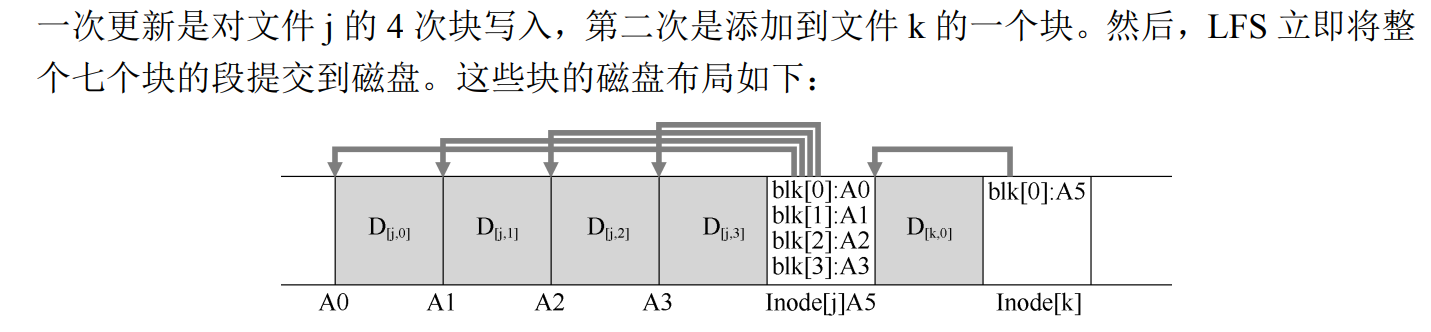
-
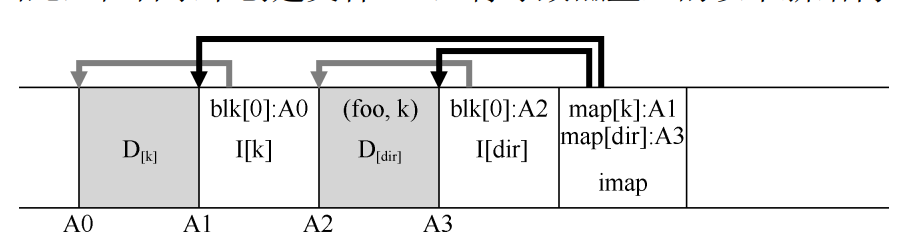
LFS 中的 inode 不再连续分布
- 使用 inode 映射:在 inode 之间引入间接层:imap 以 inode 号作为输入并生成最新版本的 inode 的磁盘地址。每次 inode 写入磁盘是,imap 都会进行更新。
- imap 放置在其他信息的位置旁边(inode 旁边)
- 磁盘上有一个固定的位置,检查点区域 CR 包含了指向 imap 的指针,其定期更新(如 30 s)构成 CR-imap-inode-data 的层次结构
- imap 记录了每个 inode 号到其在磁盘上的最新位置的映射。每次 inode 被修改后,其新位置会被记录在日志中,imap 也会随之更新,指向最新的 inode 位置。当文件系统需要访问某个 inode 时,会首先通过 imap 找到 inode 的位置。(这也避免修改目录时,一个文件该表造成递归全部需要修改,imap 的地址不变就阻断了这种现象)imap 是可以修改的
-
垃圾清理:由于总是追加写入,磁盘中存在很多已经失效的磁盘碎片
- LFS 清理程序按段工作,从而为后续写入清理出大块空间:FS 清理程序定期读入许多旧的(部分使用的)段,确定哪些块在这些段中存在,然后写出一组新的段,只包含其中活着的块,从而释放旧块用于写入。
- LFS 为描述每个块的每个段添加一些额外信息:包括其 inode 号(它属于哪个文件)及其偏移量,通过段摘要块找到对应的块并进行对比,从而判断是否是已经过时的“垃圾块”
- 更好的方法:当文件被截断或删除时,LFS 会增加其版本号,并在 imap 中记录新版本号。通过在磁盘上的段中记录版本号,LFS 可以简单地通过将磁盘版本号与 imap 中的版本号进行比较,跳过上述较长的检查,从而避免额外的读取
可靠存储¶
- 临时失效:断电
- 部分失效:ECC 纠错失效
- 永久失效:物理损坏等
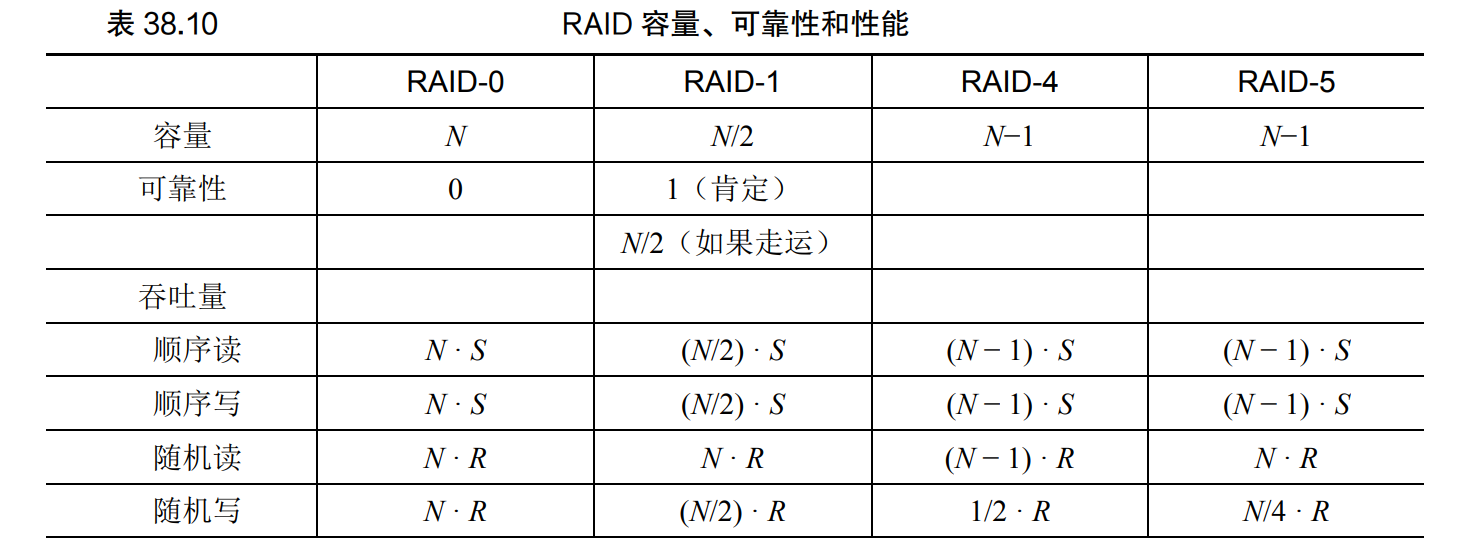
RAID 可靠磁盘¶
- 把多个磁盘虚拟成一块非常可靠并性能极高的虚拟磁盘
- 从虚拟块号到磁盘物理块号的映射

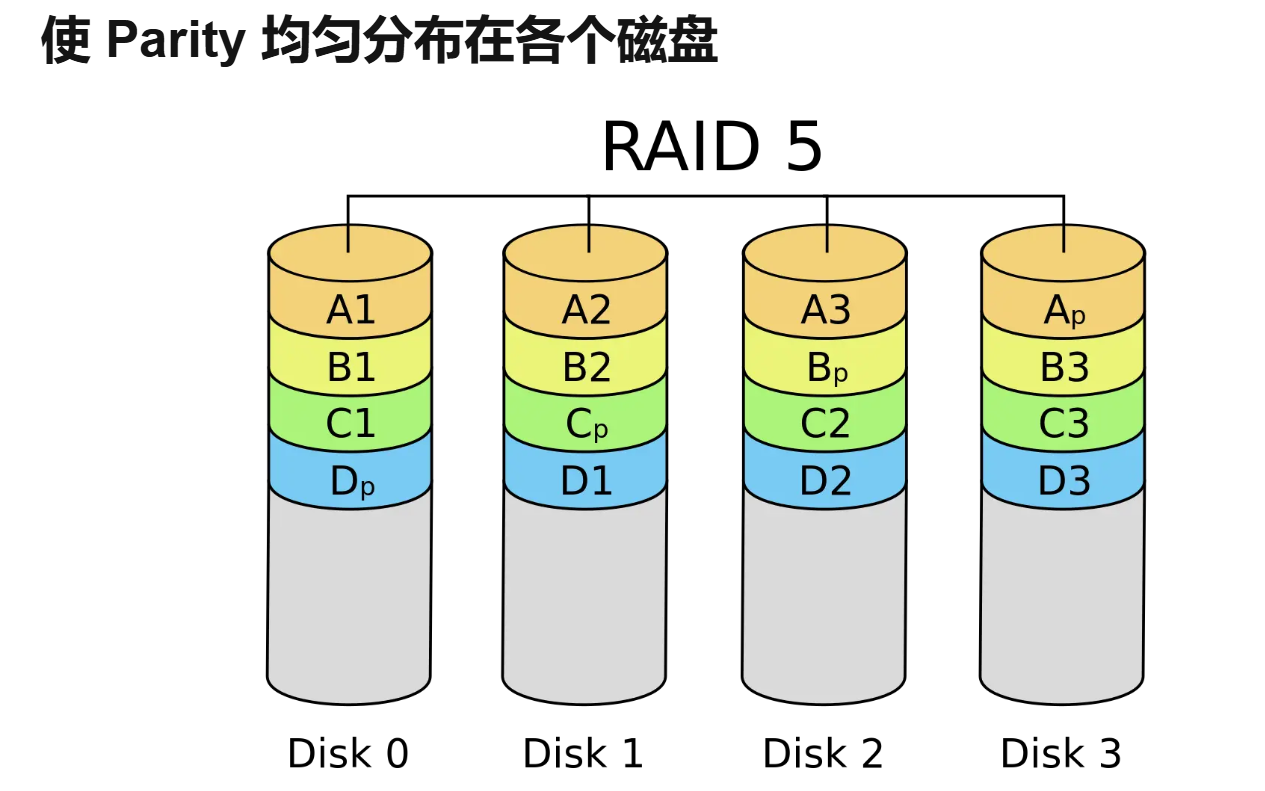
- 大文件访问涉及多个块可以充分利用不同磁盘同时读取带来的加速
- 小问价只涉及单独的块,无法利用 RAID 带来的性能上的提升

可靠文件系统¶
- 一次写入可能分为多个步骤,如修改 FAT 块、修改数据块等,此时发生断电就会出现问题。即对磁盘的操作不是一个原子操作。
- 三个写入:inode、bitmap、data
-
尤其是磁盘是延迟写入的,高速操作系统已经写入时并不一定完成了物理写入,存在崩溃一致性问题
-
FSCK:根据磁盘上已有的信息,恢复出 “最可能” 的数据结构,一种文件检查系统
- 文件系统的检查方法比基于日志的检查方法慢得多(日志大小小的多)
- 假设如下一个追加数据的写入场景


- 涉及到对 inode、bitmap 和 data 的写入,如果写入部分完成时发生崩溃,就会出现问题(比如 inode 说已经完成了但是 data 实际上没有写入,或者 bitmap 没有被更新导致之后的覆盖问题)
- 由此崩溃就导致了不一致的问题,我们希望将文件系统保证从一个一致状态转移到另一个一致状态,这就是崩溃一致性问题
-
文件系统检查:fask 就用于在出现故障之后重新启动时查找不一致并进行修复
- 检查超级块、空闲块、inode 状态等进行检查识别可疑的问题并进行修复。
- 由于需要扫描整个磁盘,十分耗时。
-
磁盘的三种操作:
- bwrite、bread:为了性能优化,没有顺序保证,并且由于缓存也不一定真正存进了磁盘
- bflush:等待已写入的数据落盘(真正存储到了磁盘)
- 预写日志检查
- 使用 appendonly 的方式记录所有历史操作
- 通过重新执行所有操作得到数据结构的当前状态
- 很容易实现崩溃的一致性
- 结合数据结构(文件系统的直观表示)和日志系统就能实现崩溃一致性。高效读写+可靠机制。

- TxBE 表示事务的开始和结束,中间存储的是具体要进行的操作
- 由于缓存机制,磁盘可能不会按顺序写入事务的各个部分(比如 TxE 完成但是 Db 没有正确写入,这就会造成问题)。因此分两步发出事务写入:首先将除了 TxE 之外的块写入,完成之后再发出 TxE 的写入
- 日志写入:将事务的内容(包括 TxB、元数据和数据)写入日志,等待这些写入完成。
- 日志提交:将事务提交块(包括 TxE)写入日志,等待写完成,事务被认为已提交
- 加检查点:将更新内容(元数据和数据)写入其最终的磁盘位置。
- 释放日志:由此可以循环利用日志空间
-
使用日志从崩溃中恢复
- 如果事务还没有提交:跳过待执行的更新,重新进行操作
- 事务已经提交:扫描日志,根据日志检查已经完成的事务,事务被重放,文件系统再次尝试将事务中的块写入它们最终的磁盘位置。即通过日志恢复已经提交的事务
-
优化
- 元数据日志:避免重复写入两次数据,对于数据部分直接先写入到目标位置,仅在日志中记录元数据
- 在日志中存储要写入数据的完整信息的称为完整数据日志

- 批处理:多次系统调用合并为一个事务,减少日志记录的大小和频率
- 校验和,用校验和验证日志的完整性,这就不再标记事务开始(TxBegin)和事务结束(TxEnd)。
IO¶
IO 设备¶
-
IO 设备就是一个能与 CPU 交换数据的接口/控制器
- 使用几组约定好功能的线,通过握手信号从线上(寄存器中)读出/写入数据
- 可以给设备寄存器赋予内存地址,使得 CPU 可以直接使用指令和设备交换数据
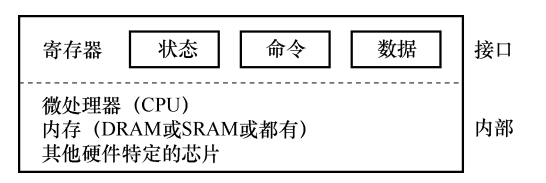
- 状态寄存器用于读取并查看设备的当前状态
- 命令寄存器用于通知设备执行某个任务
- 数据寄存器用于传给设备或从设备接受数据
- 通常的工作流程:查看状态寄存器等待就绪状态;下发数据到数据寄存器;将命令写入命令寄存器;设备开始执行命令;操作系统检查设备等待并判断设备是否执行完成命令(或者使用中断方式以及 DMA)
-
设备分类:
- 独占设备:同一时刻只能由一个进程占用的设备,如低速设备(打印机)
- 共享设备:同一时间段之内允许多个进程同时访问(并不是同时访问)
- 虚拟设备:如 SPOOLing 技术将独占设备转化为共享设备,一个物理设别转化为多个逻辑设备
-
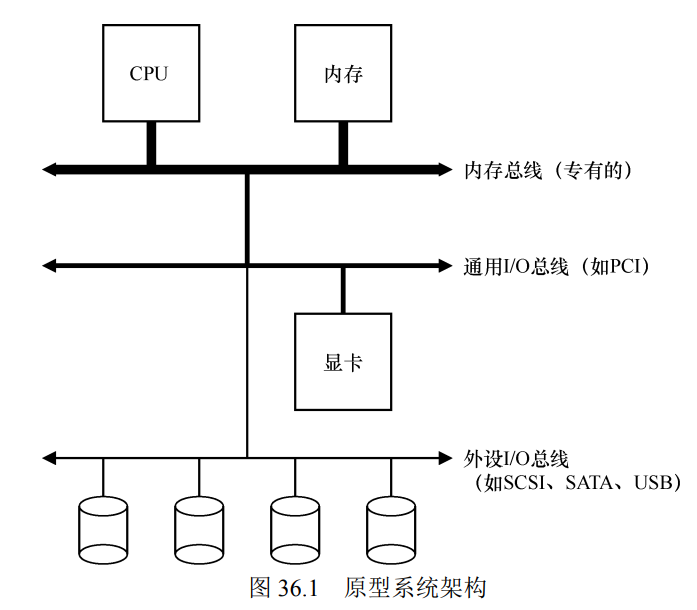
为了让计算机可以不只连接到固定的设备,引入特殊的 IO 设备:总线
- 提供设备的虚拟化:注册、转发
- 把收到的地址 (总线地址) 和数据转发到相应的设备上,这样 CPU 只需要直连这一个设备就可以了
- CPU 只负责和总线交互,总线负责将数据传递给 io 设备进行地址映射等任务
- 通过总线简化了设备的管理,实现了管理更多不同的 IO 设备
-
中断控制器
- 负责收集各个设备产生的中断,并选择发送给 CPU(根据优先级等)
- 以及完成对设备的应答
- DMA
- 负责进行数据的拷贝,解放 CPU 算力
- 位移的功能就是 memorycopy
-
GPU
- 专门画图的"CPU"做大量重复简单工作
-
设备交互方式
- 通过特定的特权指令与设备进行交互
- 通过内存映射 IO 的方式进行交互
设备驱动程序¶
- 把系统调用 “翻译” 成与设备能听懂的数据
IO 层次结构¶
以下是 I/O 层次结构及每一层特点和功能的表格:
| 层次 | 特点 | 功能 |
|---|---|---|
| 用户层(User Level) | - 用户层是程序和操作系统的接口。 - 用户应用程序通过系统调用请求 I/O 操作。 |
- 提供易于使用的 I/O 操作接口,例如文件读写、网络通信等。 - 将用户的 I/O 请求传递给操作系统内核。 |
| 系统调用层(System Call Interface) | - 是用户层和操作系统内核之间的桥梁。 - 提供一组标准的系统调用,用于执行各种 I/O 操作。 |
- 接收来自用户层的 I/O 请求并进行验证。 - 将经过验证的请求传递给内核进行处理。 |
| 设备无关软件层(Device-Independent Software) | - 提供与具体硬件设备无关的 I/O 操作。 - 处理设备独立的 I/O 管理任务。 |
- 缓冲区管理:实现数据的临时存储和传输,减小 I/O 操作对 CPU 的影响。 - 缓存管理:提高 I/O 操作的效率,通过缓存减少对设备的直接访问。 - 设备分配:管理系统中可用的设备资源,处理设备的分配和释放。(逻辑设备与物理设备的映射) - 错误处理:处理 I/O 操作中的错误,确保系统稳定性。 |
| 设备驱动层(Device Drivers) | - 是操作系统内核的一部分,专门负责与具体硬件设备的交互。 - 每种设备都有相应的设备驱动程序。 |
- 将设备无关的软件层的 I/O 请求转换为设备特定的操作。 - 与硬件设备进行通信,控制设备的操作。 - 处理设备的中断请求,确保 I/O 操作的正确完成。 |
| 中断处理层(Interrupt Handlers) | - 负责处理来自硬件设备的中断信号。 - 在硬件设备完成某个 I/O 操作时,触发中断处理。 |
- 保存当前 CPU 的状态,确保中断处理后系统能继续正常运行。 - 执行相应的中断处理程序,响应设备的请求。 - 恢复 CPU 状态,返回到中断前的执行状态。 |
| 硬件层(Hardware Level) | - 包含所有的物理 I/O 设备,如磁盘驱动器、网络接口卡、显示器等。 - 直接与设备驱动层进行交互。 |
- 执行具体的 I/O 操作,例如数据的读写、数据传输等。 - 通过中断机制通知操作系统 I/O 操作的完成情况。 |
设备无关软件¶
- 负责执行所有设备的公有操作
高速缓冲¶
- 利用内存来暂存磁盘中的信息,逻辑上属于磁盘,物理上属于内存
- 缓冲区同时只支持单向数据流
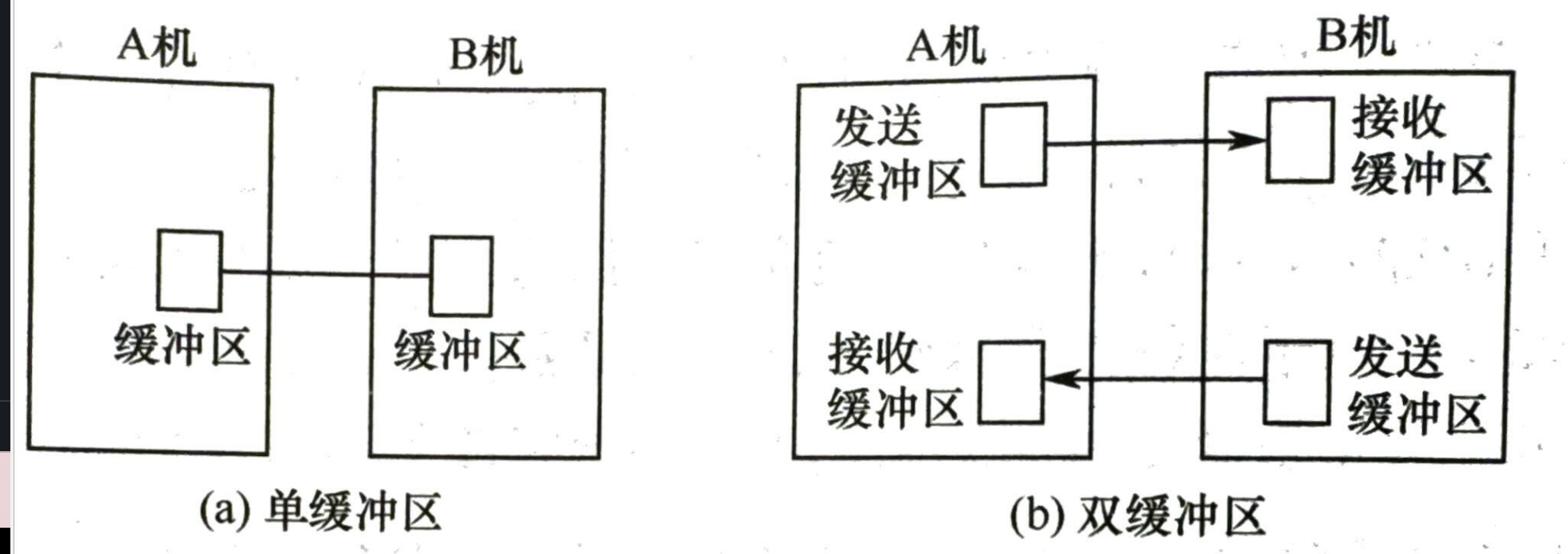
- 单缓冲:每当用户发出一个 io 请求,就分配一个缓冲区(一个块)设备现将数据传送到缓冲区在传送到工作区
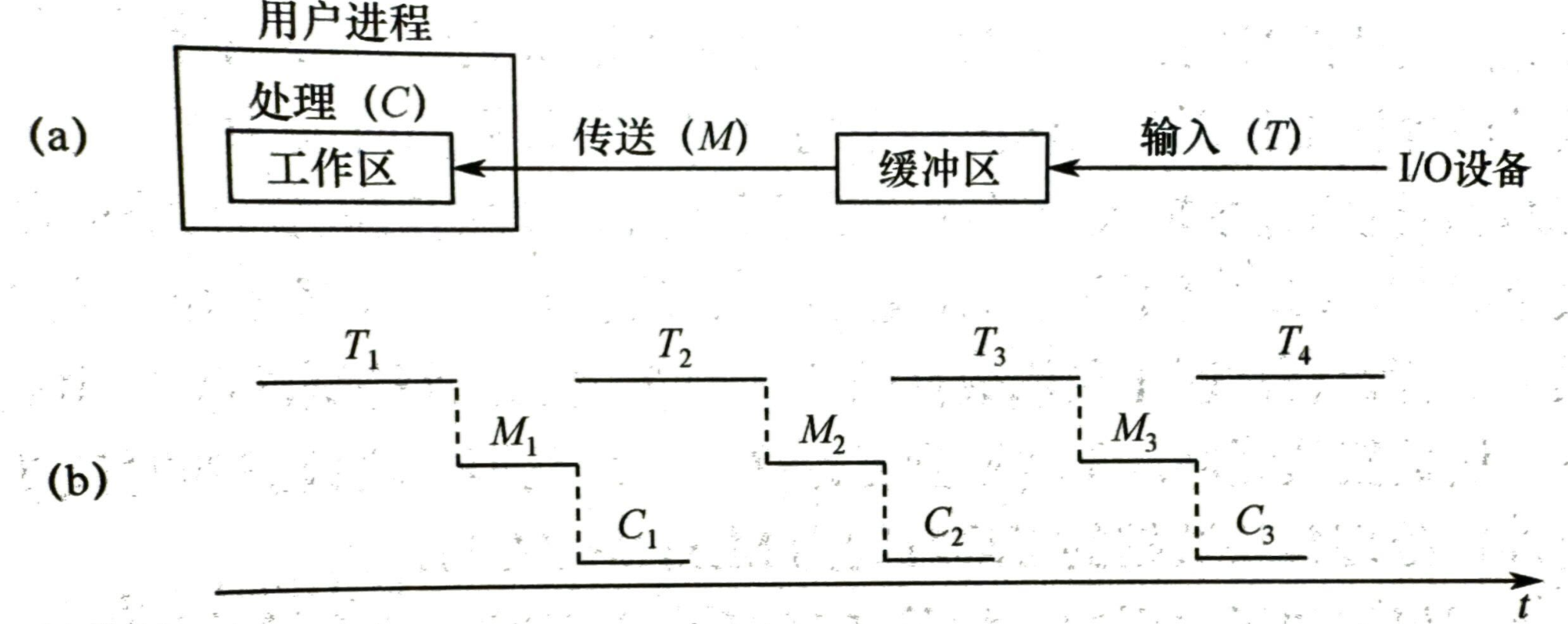
- T 和 C 可以并行,处理每块数据的平均时间 \(Max(C,T)+M\)
- 双缓冲: 设备输入时可以交替使用两个缓冲区
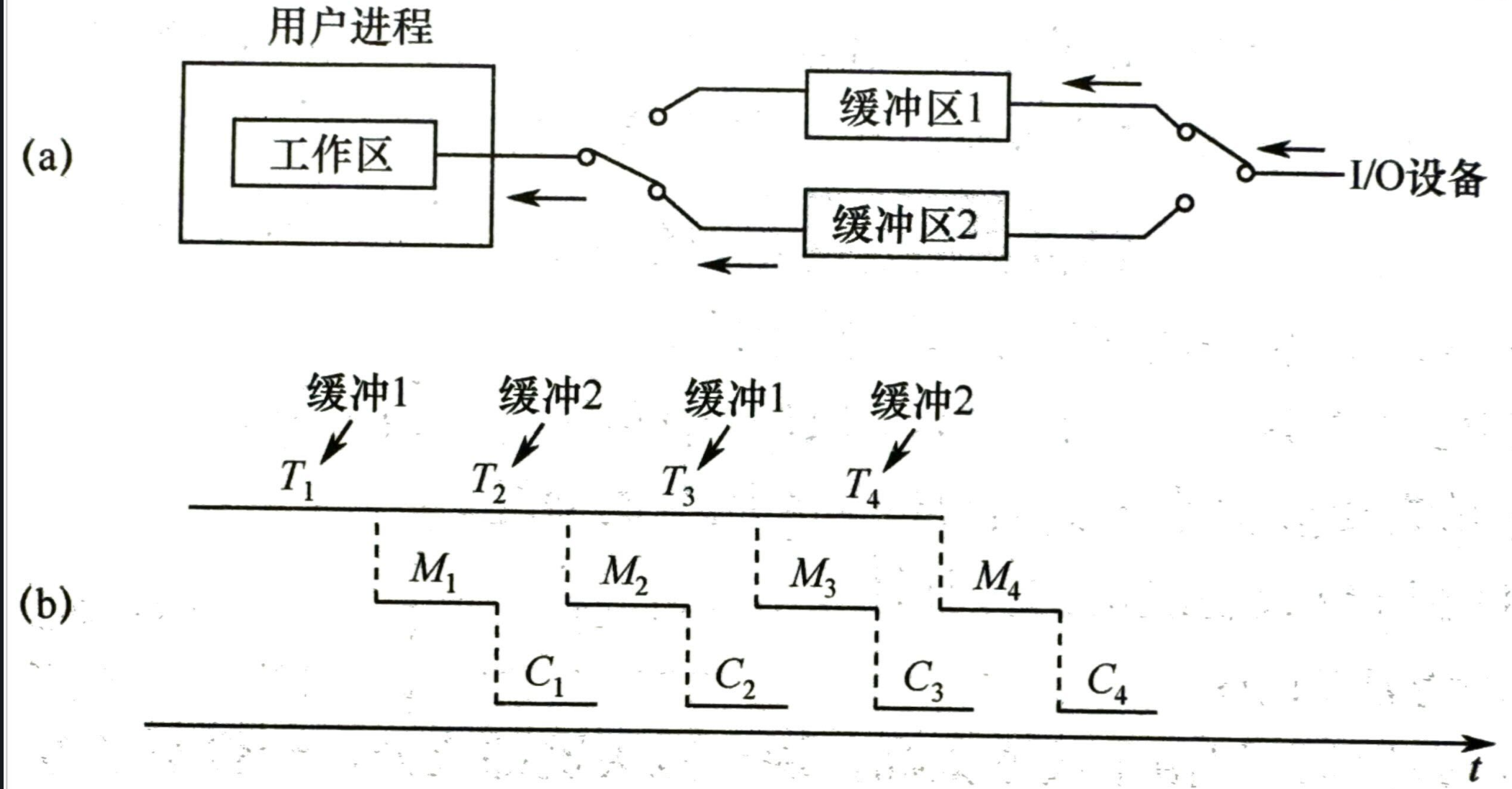
- T 与 C、M 都可以并行 \(Max(T,C+M)\)
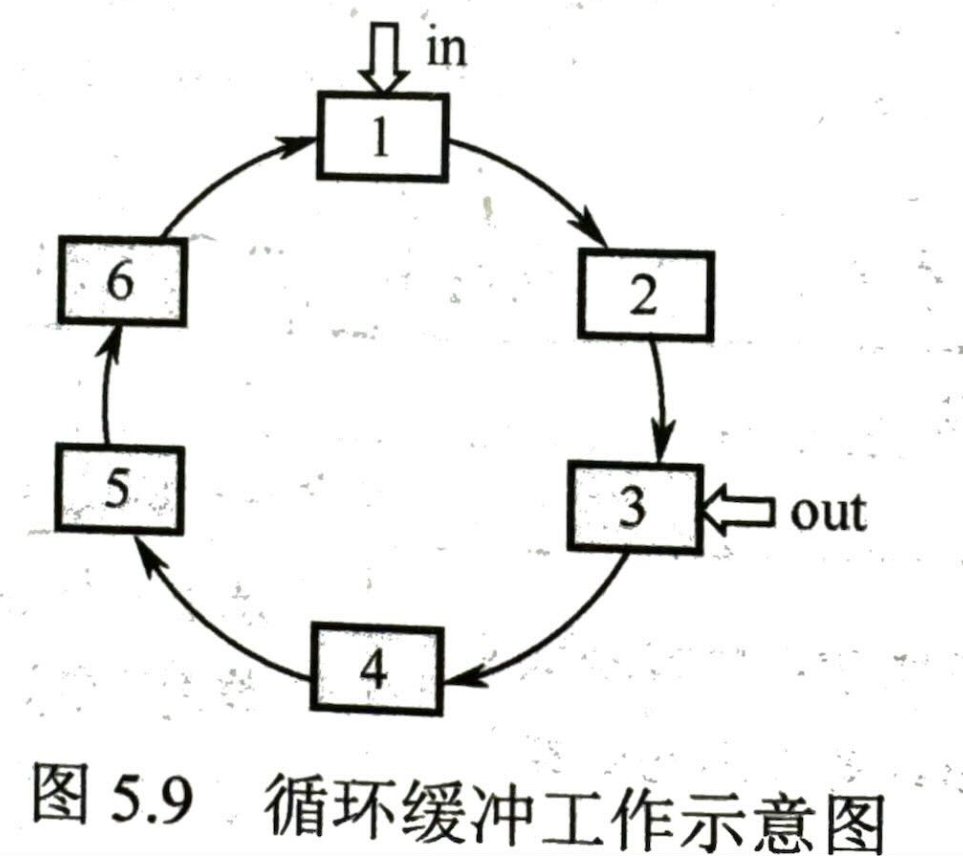
- 循环缓冲:
- 包含许多大小相等的缓冲区,in 指向第一个可以输入数据(缓存)的块;out 指向第一个可以提取数据(进行运算)的块
- 缓冲池:管理多个缓冲区
- 将缓冲区划分为:空缓冲队列;输入队列;输出队列
- 收容输入数据的工作缓冲区 hin:从空缓冲区队列取下缓冲区作为收容输入的工作缓冲区,装满数据后挂到输入队列的队尾
- 提取输入数据的工作缓冲区 sin:从输入队列队首取得缓冲区,作为提取输入工作缓冲区,使用数据后将缓冲区归还到空队列
- 收容输出数据的工作缓冲区 hout
- 提取输出数据的工作缓冲区 sout
设备分配与回收¶
- 根据用户的 IO 请求分配所需的设备,尽可能让设备忙碌,又要避免造成进程死锁
- 设备控制表 DCT:每个设备一张,表项为控制器的属性(如设备类型、标识符、状态、指针等)
- 控制器控制表 COCT:每个设备控制器一张,每个控制器由一个通道控制,有指针指向
- 通道控制表 CHCT:每个通道一张表,一个通道可以为多个控制器服务,可以通过表项查询
-
系统控制表 SDT:整个系统一张,记录所有已链接到系统的物理设备的情况
-
设备分配算法:FCFS(FIFO);最高优先级优先
- 设备分配的基本过程:
- 查找 SDT,寻找目标设备的 DCT,若忙则将进程 PCB 挂载到设备等待队列;否则分配设备
- 分配控制器,根据 DCT 找到 COCT 同样若忙则加入控制器等待队列;否则分配
- 分配通道;
- 只有设备、控制器、通道全部被正确分配才算分配成功
- 为了实现设备的独立性,使用逻辑设备名替代物理名,通过配置逻辑设备表 LUT 实现转换(逻辑设备名、物理设备名、驱动程序入口);也可以为用户也配备 LUT 表项指向系统的 LUT
SPOOLing 技术¶
- 假脱机技术,将独占设备改造成共享设备
- 通过将数据暂存到中间存储介质(如磁盘或内存)中,使得计算机系统可以同时处理多个输入输出任务,从而提高系统的效率和性能。
- 需要输入时直接从磁盘读取
- 需要输出时也是先将数据存储到磁盘
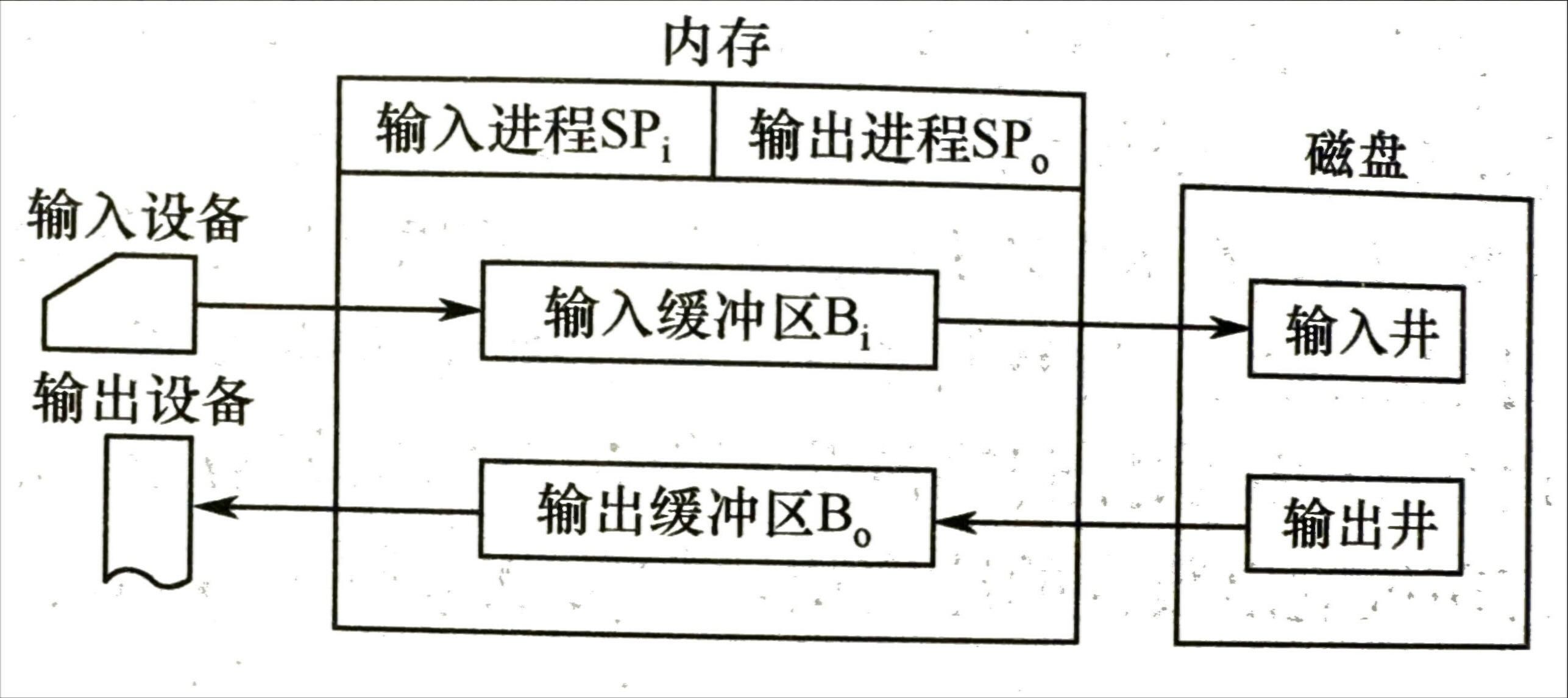
- 输入输出井:模拟脱机输入输出的磁盘,用于收容数据
- 输入缓冲区和输出缓冲区:用于在内存暂存数据
- 输入输出进程:输入进程将用户数据从输入设备到缓冲区在存储在输入井,CPU 需要时再取出;输出进程将用户的数据从内存传输到输出井,等设备空闲时再交给设备
-
井管理程序:控制作业与磁盘之间的信息交互
-
提高速度:将低速 IO 操作转化为对磁盘缓冲区中数据的操作;将独占设备改造为了共享设备;实现了虚拟设备功能