树
树上dp¶
树的重心¶
-
选择一个点,使得其子树节点总数的最大值最小
-
可以很好的用这一点进行分治(每个子树的节点数目显然小于n/2)
-
通过一次dfs,一个节点通过其子树的节点数目就能推出上面整体的另一子树的大小,从而进行比较
#include<cstdio>
#include<algorithm>
using namespace std;
const int N = 50005; //最大结点数
struct Edge{ int to, next;} edge[N<<1]; //两倍:u-v, v-u
int head[N], cnt = 0;
void init(){ //链式前向星:初始化
for(int i=0; i<N; ++i){
edge[i].next = -1;
head[i] = -1;
}
cnt = 0;
}
void addedge(int u,int v){ //链式前向星:加边u-v
edge[cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt++;
}
int n;
int d[N], ans[N], num=0, maxnum=1e9; //d[u]: 以u为根的子树的结点数量
void dfs(int u,int fa){
d[u] = 1; //递归到最底层时,结点数加1
int tmp = 0;
for(int i=head[u]; ~i; i=edge[i].next){ //遍历u的子结点。~i也可以写成i!=-1
int v = edge[i].to; //v是一个子结点
if(v == fa) continue; //不递归父亲
dfs(v,u); //递归子结点,计算v这个子树的结点数量
d[u] += d[v]; //计算以u为根的结点数量
tmp = max(tmp,d[v]); //记录u的最大子树的结点数量
}
tmp = max(tmp, n-d[u]); //tmp = u的最大连通块的结点数
//以上计算出了u的最大连通块
//下面统计疑似教父。如果一个结点的最大连通块比其他结点的都小,它是疑似教父
if(tmp < maxnum){ //一个疑似教父
maxnum = tmp; //更新“最小的”最大连通块
num = 0;
ans[++num] = u; //把教父记录在第1个位置
}
else if(tmp == maxnum) ans[++num] = u; //疑似教父有多个,记录在后面
}
int main(){
scanf("%d",&n);
init();
for(int i=1; i<n; i++){
int u, v; scanf("%d %d", &u, &v);
addedge(u,v); addedge(v,u);
}
dfs(1,0);
sort(ans+1, ans+1+num);
for(int i=1;i<=num;i++) printf("%d ",ans[i]);
}
树的直径¶
-
对于不存在负权边的树可以两次dfs找到距离最远的点进而得到树的直径
-
对于存在负权边的树可以使用dp解决
- 记录每一个节点到达叶节点的最短距离,通过调整遍历顺序避免出现重叠问题
- 枚举路径的中结点,一条路径可以表示为一个结点及其子树上的两条链,dp[u]就表示从u向下的最长路径
- 在枚举子节点的过程中,先使用当前路径的最大长度(不包含新节点,防止使用重叠的边)和新边加和更新最大值;再使用新边对dp[u]进行更新
#include<bits/stdc++.h>
using namespace std;
const int N=1e5+10;
struct edge{int to,w; }; //to: 边的终点 w:权值
vector<edge> e[N];
int dp[N];
int maxlen = 0;
bool vis[N];
void dfs(int u){
vis[u] = true;
for(int i = 0; i < e[u].size(); ++ i){
int v = e[u][i].to, edge = e[u][i].w;
if(vis[v]) continue; //v已经算过
dfs(v);//已经遍历过的子树中u为起点的最长路径,加上新指定的子树v的最长路径
maxlen = max(maxlen, dp[u]+ dp[v]+ edge);
//计算max{f[u]}。注意此时dp[u]不包括v这棵子树,下一行才包括
dp[u] = max(dp[u], dp[v] + edge); //计算dp[u],此时包括了v这棵子树
}
return ;
}
int main(){
int n; cin >> n;
for(int i = 0; i < n-1; i++){
int a, b, w; cin >> a >> b >> w;
e[a].push_back({b,w}); //a的邻居是b,路的长度w
e[b].push_back({a,w}); //b的邻居是a
}
dfs(1); //从点1开始DFS
cout << maxlen << endl;
return 0;
}
树上背包dp¶
-
把每个子树看作一个分组;
-
节点的目标和由子树不同节点构成,类似一个背包问题,从子树中选择合适的加入转移
-
模板
-
c++ void dfs(vector<vector<int>>&dp,int n,vector<int>&sum){ if(tree[n].children.empty()){//叶节点初始化 dp[n][1]=tree[n].money; dp[n][0]=0; sum[n]=1; return; } dp[n][0]=0;//对于要求严格满足容量等于的要初始化为不可能取到的数,在搜索到时对可能的情况进行初始化 for(int a:tree[n].children){ dfs(dp,a,sum); sum[n]+=sum[a];//逐步加,作为优化 for(int i=sum[n];i>0;i--){ for(int j=1;j<=min(i,sum[a]);j++){//通常用子树的大小来限制循环的范围,实现复杂度的降低 if(dp[n][i-j]==INT_MIN||dp[a][j]==INT_MIN)continue;//不可访问 dp[n][i]=max(dp[n][i],dp[n][i-j]+dp[a][j]-tree[a].cost); } } } } -
由于循环剪枝的优化,复杂度其实为\(O(NK)\)平方复杂度
例题¶
-
路径总长度->每条边被利用的次数(贡献法)
-
将点集划分为边两侧的两部分,边的使用次数就等于边两边点的数目的乘积
-
```c++ void dfs(vector
}} ```
换根dp¶
- 第一次预处理得到子树大小等性质,求出对于一个节点的结果,然后在用一次dfs,从相邻点递推处所有节点的答案
- Problem - D - Codeforces
- 2858. 可以到达每一个节点的最少边反转次数 - 力扣(LeetCode)
树上递归操作¶
例题¶
二叉搜索树¶
特点¶
- 保证一棵树为二叉搜索树,只要保证每一个子树左子树的左右节点都小于根节点,右子树所有节点都大于根节点即可。
- 先序遍历
- 性质:局部递减,总体递增(不会出现231模式)
例题¶
- 255. 验证前序遍历序列二叉搜索树
- 使用单调栈优化
- 285. 二叉搜索树中的中序后继
- 431. 将 N 叉树编码为二叉树
- 可以把N叉树一个节点的第一个孩子都作为二叉树的左节点,然后该节点兄弟挂载在第一个孩子的右节点上。
- P1229 遍历问题
最近公共祖先问题LCA¶
- n个点,进行m次查询
- 暴力法,分别计算根到两点的路径,打标记,复杂度\(O(mn)\)
倍增法¶
-
复杂度\(O((n+m)logn)\)
-
在线算法
-
过程:
-
预处理得到没给点向上跃1、2、4...后的位置复杂度为\(O(nlogn)\)
- 除了预处理父节点也可以预处理路径权值的最大(小)值、已经权值和等。可以用于查询树上两点间的最短距离
- 通过一次dfs找到所有节点的深度
- 先将深度较大的节点向上跃到和另一点一致
- 将两个节点向上跃动(选择1 2 4..中最大的不是公共祖先的点)
- 这样每次可以去掉一半的范围,单次查询的复杂度为\(O(logn)\)
#include <bits/stdc++.h>
using namespace std;
const int N=500005;
struct Edge{int to, next;}edge[2*N]; //链式前向星
int head[2*N], cnt;
void init(){ //链式前向星:初始化
for(int i=0;i<2*N;++i){ edge[i].next = -1; head[i] = -1; }
cnt = 0;
}
void addedge(int u,int v){ //链式前向星:加边
edge[cnt].to = v; edge[cnt].next = head[u]; head[u] = cnt++;
} //以上是链式前向星
int fa[N][20], deep[N];
void dfs(int x,int father){ //求x的深度deep[x]和fa[x][]。father是x的父结点。
deep[x] = deep[father]+1; //深度:比父结点深度多1
fa[x][0] = father; //记录父结点
for(int i=1; (1<<i) <= deep[x]; i++) //求fa[][]数组,它最多到根结点
fa[x][i] = fa[fa[x][i-1]][i-1];
for(int i=head[x]; ~i; i=edge[i].next) //遍历结点i的所有孩子。~i可写为i!=-1
if(edge[i].to != father) //邻居:除了父亲,都是孩子
dfs(edge[i].to, x);
}
int LCA(int x,int y){
if(deep[x]<deep[y]) swap(x,y); //让x位于更底层,即x的深度值更大
//(1)把x和y提到相同的深度(注意从大到小倒着跳)
for(int i=19;i>=0;i--) //x最多跳19次:2^19 > 500005
if(deep[x]-(1<<i)>=deep[y]) //如果x跳过头了就换个小的i重跳
x = fa[x][i]; //如果x还没跳到y的层,就更新x继续跳
if(x==y) return x; //y就是x的祖先
//(2)x和y同步往上跳,找到LCA
for(int i=19;i>=0;i--) //如果祖先相等,说明跳过头了,换个小的i重跳
if(fa[x][i]!=fa[y][i]){ //如果祖先不等,就更新x、y继续跳
x = fa[x][i]; y = fa[y][i];
}
return fa[x][0]; //最后x位于LCA的下一层,父结点fa[x][0]就是LCA
}
int main(){
init(); //初始化链式前向星
int n,m,root; scanf("%d%d%d",&n,&m,&root);
for(int i=1;i<n;i++){ //读一棵树,用链式前向星存储
int u,v; scanf("%d%d",&u,&v);
addedge(u,v); addedge(v,u);
}
dfs(root,0); //计算每个结点的深度并预处理fa[][]数组
while(m--){
int a,b; scanf("%d%d",&a,&b);
printf("%d\n", LCA(a,b));
}
return 0;
}
tarjan算法¶
- 复杂度\(O(n+m)\)
- 离线算法,需要一次性处理所有查询
- 对(x,y1),(x,y2)...的查询进行批量处理
- 使用一个链式前向星存图,另一个用来存储与x对应查询的yi
- 采用后序遍历,处理完子节点再处理父节点,用vis标记已经访问完成的节点,当访问x时如果vis[y]已经访问,那么find(x)就是结果
- 如何保证find(x)就是结果:后序遍历,find(x)还没有向上连接,就是xy的最近公共祖先
#include <bits/stdc++.h>
using namespace std;
const int N=500005;
int fa[N], head[N], cnt, head_query[N], cnt_query, ans[N];
bool vis[N];
struct Edge{ int to, next, num;}edge[2*N], query[2*N]; //链式前向星
void init(){ //链式前向星:初始化
for(int i=0;i<2*N;++i){
edge[i].next = -1; head[i] = -1;
query[i].next = -1; head_query[i] = -1;
}
cnt = 0; cnt_query = 0;
}
void addedge(int u,int v){ //链式前向星:加边
edge[cnt].to = v;
edge[cnt].next = head[u];
head[u] = cnt++;
}
void add_query(int x, int y, int num) { //num 第几个查询
query[cnt_query].to = y;
query[cnt_query].num = num; //第几个查询
query[cnt_query].next = head_query[x];
head_query[x] = cnt_query++;
}
int find_set(int x) { //并查集查询
return fa[x] == x ? x : find_set(fa[x]);
}
void tarjan(int x){ //tarjan是一个DFS
vis[x] = true;
for(int i=head[x]; ~i; i=edge[i].next){ // ~i可以写为i!=-1
int y = edge[i].to;
if( !vis[y] ) { //遍历子结点
tarjan(y);
fa[y] = x; //合并并查集:把子结点y合并到父结点x上(后序思想,处理完之后再练上来)
}
}
for(int i = head_query[x]; ~i; i = query[i].next){ //查询所有和x有询问关系的y
int y = query[i].to;
if( vis[y]) //如果to被访问过
ans[query[i].num] = find_set(y); //LCA就是find(y)
}
}
int main () {
init();
memset(vis, 0, sizeof(vis));
int n,m,root; scanf("%d%d%d",&n,&m,&root);
for(int i=1;i<n;i++){ //读n个结点
fa[i] = i; //并查集初始化
int u,v; scanf("%d%d",&u,&v);
addedge(u,v); addedge(v,u); //存边
}
fa[n] = n; //并查集的结点n
for(int i = 1; i <= m; ++i) { //读m个询问
int a, b; scanf("%d%d",&a,&b);
add_query(a, b, i); add_query(b, a, i); //存查询
}
tarjan(root);
for(int i = 1; i <= m; ++i) printf("%d\n",ans[i]);
应用¶
- 树上两点间最短距离
- dis(x,y)=deep[x]+deep[y]-2*deep[LCA(x,y)]
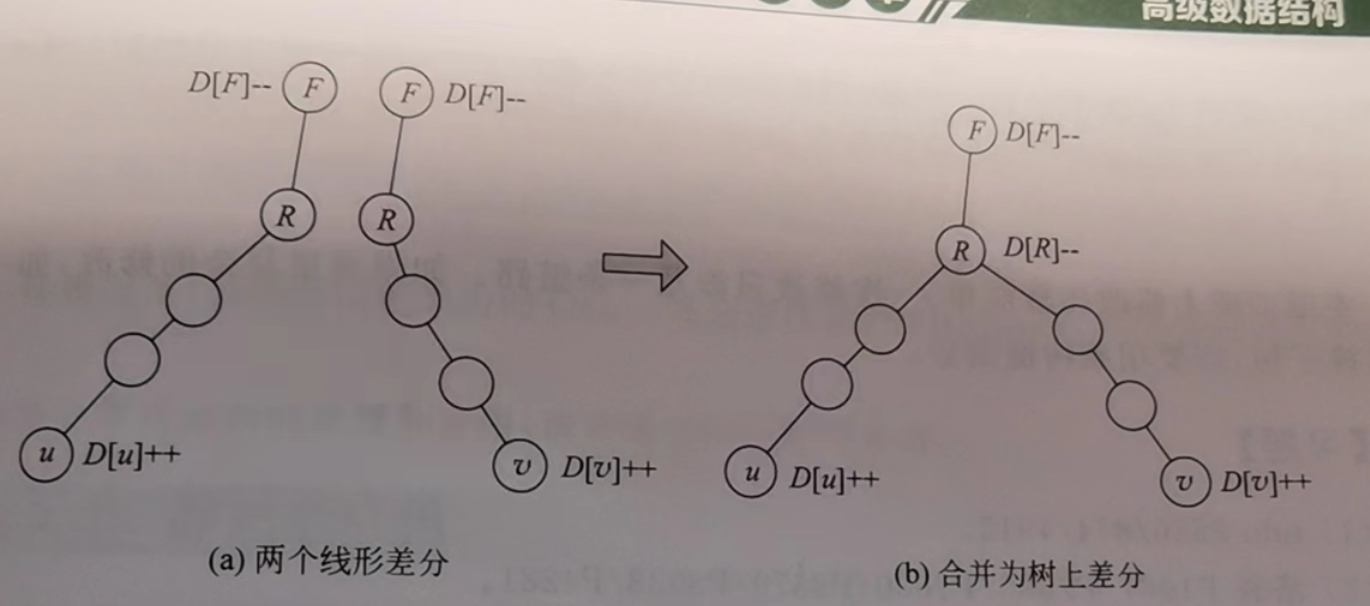
- 树上差分
- 对两点间(最短)路径上节点的权值进行范围修改
- 将路径u-v拆分为u-LCA(u,v)和v-LCA(u,v)
- 设LCA(u,v)为点P,其父节点为F
- 只需要D[u]++,D[v]++,D[F]--,D[R]--(被重复加了两遍)
#include <bits/stdc++.h>
using namespace std;
#define N 50010
struct Edge{int to,next;}edge[2*N]; //链式前向星
int head[2*N],D[N],deep[N],fa[N][20],ans,cnt;
void init();
void addedge(int u,int v);
void dfs1(int x,int father);
int LCA(int x,int y); //以上4个函数和“树上的倍增”中洛谷P3379的倍增代码完全一样
void dfs2(int u,int fath){
for (int i=head[u];~i;i=edge[i].next){ //遍历结点i的所有孩子。~i可以写为i!=-1
int e=edge[i].to;
if (e==fath) continue;
dfs2(e,u);
//注意是从下向上累加
D[u]+=D[e];
}
Ans = max(ans,D[u]);
}
int main(){
init(); //链式前向星初始化
int n,m; scanf("%d%d",&n,&m);
for (int i=1;i<n;++i){
int u,v; scanf("%d%d",&u,&v);
addedge(u,v); addedge(v,u);
}
dfs1(1,0); //计算每个结点的深度并预处理fa[][]数组
for (int i=1; i<=m; ++i){
int a,b; scanf("%d%d",&a,&b);
int lca = LCA(a,b);
D[a]++; D[b]++; D[lca]--; D[fa[lca][0]]--; //树上差分
}
dfs2(1,0); //用差分数组求每个结点的权值
printf("%d\n",ans);
return 0;
}
例题¶
- P1967 货车运输
- P3398 仓鼠找 sugar
- 判断树上两条边是否相交:结论,如果两条边相交,则一定存在其中一条边的端点的LCA在另一条边上
-
如何判断一点是否在树上一条边上:这一点到两端点的距离和等于边的长度
- 求一个点到树上三个点的距离和最小
- 两两求LCA,目标点就是和另外两个不同的(另外两个是相同的)
树上分治¶
- 利用分治n2->nlogn
点分治¶
- 用一个点对树进行划分,使用重心作为分割点使得划分十分均匀,实现\(O(logn)\)
静态点分治¶
-
只查询不修改,常用于处理路径计算问题
-
思想与CDQ分治类似,可以划分为经过重心的路径和不经过重心的路径分别处理
-
如求两点距离<=k的数目
-
求出重心到所有点的距离,并按照大小排序,使用滑动窗口得到符合长度的组合
-
进行去重(从重心出发的两条边可能存在重合),假设存在路径u-a-c+u-a<=k符合要求,在u处已经计数,要避免在a处被重复技术,可以在a处用k-2dis(a,u)代替k进行计数
-
cpp void Divid(int x) { ans+=solve(x,0); vis[x] = 1; for (int i = head[x];i;i = edges[i].net) { edge v = edges[i]; if(vis[v.to]) continue; ans-=solve(v.to,edges[i].cost); S = size[v.to]; root = 0; find(v.to,x); Divid(root); } }- ans += solve(x,0); 这一句的作用是将答案加上经过x的路径答案。 而这一个0是为了解决掉一些,有重复计算的结果;(看不懂先假装没有这个0)
- ans -= solve(v.to,edges[i].cost); 这一句是将在既经过x这个点,又经过v.to这一个点的路径来去重。因为像这种路径会在solve(x,0)和solve(v.to,0)中都计算一次。而题目是要求路径的长度,所以在容斥时要初始化这条边的长度。所以,现在有没有理解这个0和edges[i].cost?
- S = size[v.to]; 现在我们要分治v.to的这一颗子树,So,又将求重心的树的大小改为size[v.to];
-
使用vis标记点,实现分治(树的区域划分)
-
c++ #include <bits/stdc++.h> using namespace std; typedef long long ll; const int N = 1e4+5,M = 1e7+5; int n,m,cnt=0,head[N],mx[N],root=0,_size[N],vis[N],S,ans[M]; struct { int to, next; int w; }edge[2*N]; void init(){ for(int i=0; i<N; ++i) head[i] = -1; for(int i=0; i<N; ++i) edge[i].next = -1; cnt = 0; } void addedge(int u, int v, int w){ edge[cnt].to = v; edge[cnt].w = w; edge[cnt].next = head[u]; head[u] = cnt++; } template <class T> inline void read(T &a) { T s = 0, w = 1; char c = getchar(); while(c < '0' || c > '9') { if(c == '-') w = -1; c = getchar(); } while(c >= '0' && c <= '9') { s = (s << 1) + (s << 3) + (c ^ 48); c = getchar(); } a = s*w; } //寻找重心 void find(int x,int fa){ _size[x]=1; mx[x]=0; for(int i=head[x];i!=-1;i=edge[i].next){ if(edge[i].to==fa||vis[edge[i].to]) continue; find(edge[i].to,x); _size[x]+=_size[edge[i].to]; mx[x]=max(mx[x],_size[edge[i].to]); } mx[x]=max(mx[x],S-_size[x]); //替换 if(mx[x]<mx[root]) root=x; } vector<int>dis; //计算从根节点出发所有路径的长度 void get_dis(int x,int len,int fa){ for(int i=head[x];i!=-1;i=edge[i].next){ if(edge[i].to==fa||vis[edge[i].to]) continue; dis.push_back(len+edge[i].w); get_dis(edge[i].to,len+edge[i].w,x); } } //统计并组合不同长度的路径(存在含重复边的路径) void solve(int s,int len,int type){ dis=vector<int>{len}; get_dis(s,len,0); for(int i=0;i<dis.size();i++){ for(int j=0;j<dis.size();j++){ if(i!=j&&dis[i]+dis[j]<M) ans[dis[i]+dis[j]]+=type; } } } void divide(int x){ solve(x,0,1); vis[x]=1; //对树进行分割,不可跨越 for(int i=head[x];i!=-1;i=edge[i].next){ if(vis[edge[i].to]) continue; //去除有重复边的路径 solve(edge[i].to,edge[i].w,-1); S=_size[x]; root=0; find(edge[i].to,x); divide(root); } } int main() { init(); read(n); read(m); for(int i=1;i<n;i++){ int x,y,z; read(x); read(y); read(z); addedge(x,y,z); addedge(y,x,z); } //树总结点数 S=n; //做根时最大子树节点数目(初始化为最大值) mx[0]=INT_MAX; root=0; //寻找重心 find(1,0); divide(root); for(int i=0;i<m;i++){ int k; read(k); //记录全部答案,离线查询 printf("%s\n",(ans[k]) ? "AYE" : "NAY"); } return 0; }- 复杂度\(O(n^2log(n))\)
-
使用滑动窗口改进到\(O(nmlog(n))\)
-
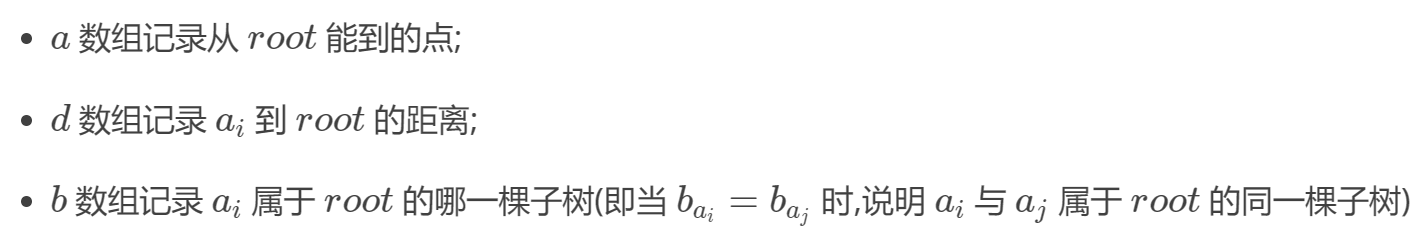
-
c++ void get_dis(int u,int fa,int dis,int from){ a[++tot]=u;//加入一个新结点 d[u]=dis; b[u]=from; for(int i=head[u];i;i=edge[i].nxt){ int v=edge[i].to; if(v==fa||vis[v])continue; get_dis(v,u,dis+edge[i].val,from); } } void calc(int u){ tot=0; a[++tot]=u; d[u]=0; b[u]=u;//别忘了加上root自己 for(int i=head[u];i;i=edge[i].nxt){ int v=edge[i].to; if(vis[v])continue; get_dis(v,u,edge[i].val,v); } sort(a+1,a+tot+1,cmp); for(int i=1;i<=m;i++){ int l=1,r=tot; if(ok[i])continue; while(l<r){ if(d[a[l]]+d[a[r]]>query[i]){//当和比询问的长度大时,右指针左移 r--; } else if(d[a[l]]+d[a[r]]<query[i]){//类似上边 l++; } else if(b[a[l]]==b[a[r]]){//和为询问的长度,但同属一棵子树,继续下一种情况 if(d[a[r]]==d[a[r-1]])r--; else l++; } else{ ok[i]=true; break; } } } }
-
动态点分治(点分树)¶
- 查询又修改¶
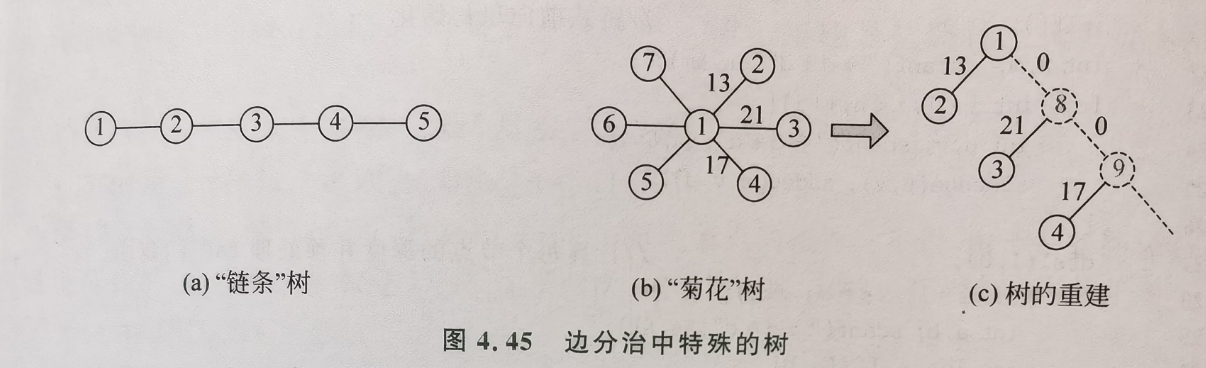
边分治¶
- 选中一条边将一颗树分成两半
- 对于链条树效率很高\(O(logn)\)次分治,但如果树呈现放射状则效率很差,退化到\(O(n)\),可以对树进行重建,获得近似\(O(logn)\)的复杂度(总复杂度为\(O(nlogn)\))
树链刨分¶
-
按照一定的规则,把树刨分成一条条线性不相交的链
-
通常使用重链刨分,对于一个非叶子节点,最大的儿子是重儿子(以其为根的子树的节点数目最多),其它的称为轻儿子
-
连接两个重儿子的边叫做重边,连续的重边连接形成重链,重链以轻儿子为起点,也可以把单独的一个叶节点看作一条重链
-
一条链上深度最小的点是链头
-
性质:
-
从任一点出发,到根节点上经过的重链(轻边)不会超过log2n条(每经过一条轻便,子树节点数目至少除以2)
-
两次dfs
-
1先计算出每个节点子树节点数目,并确定重儿子
-
2标记每个节点所在链的链头
-
```c++ void dfs1(int x, int father){
deep[x]=deep[father]+1; //深度:比父结点深度多1 fa[x]=father; //标记x的父亲 siz[x]=1; //标记每个结点的子树大小(包括自己) for(int i=head[x];~i;i=edge[i].next){ int y=edge[i].to; if(y!=father){ //邻居:除了父亲,都是孩子 fa[y]=x; dfs1(y,x); siz[x] += siz[y]; //回溯后,把x的儿子数加到x身上 if(!son[x] || siz[son[x]]<siz[y]) //标记每个非叶子结点的重儿子 son[x]=y; //x的重儿子是y } } } void dfs2(int x,int topx){
//id[x] = ++num; //对每个结点新编号,在下一小节用到 top[x] = topx; //x所在链的链头 if(!son[x]) return; //x是叶子,没有儿子,返回 dfs2(son[x],topx); //先dfs重儿子,所有重儿子的链头都是topx for(int i=head[x];~i;i=edge[i].next){ //再dfs轻儿子 int y=edge[i].to; if(y!=fa[x] && y!=son[x])
dfs2(y,y); //每一个轻儿子都有一条以它为链头的重链 } }```
-
先dfs重儿子再dfs轻儿子
应用¶
- 解决LCA问题
- 如果两点在同一条重链上则深度较小的点就是lca
- 否则深度小的点向上跳到上面一条重链
树链刨分与线段树¶
- 实现路径/子树权值修改/权值和查询
- 每条重链内部dfs序是连续的,可以很方便的用线段树进行区间修改
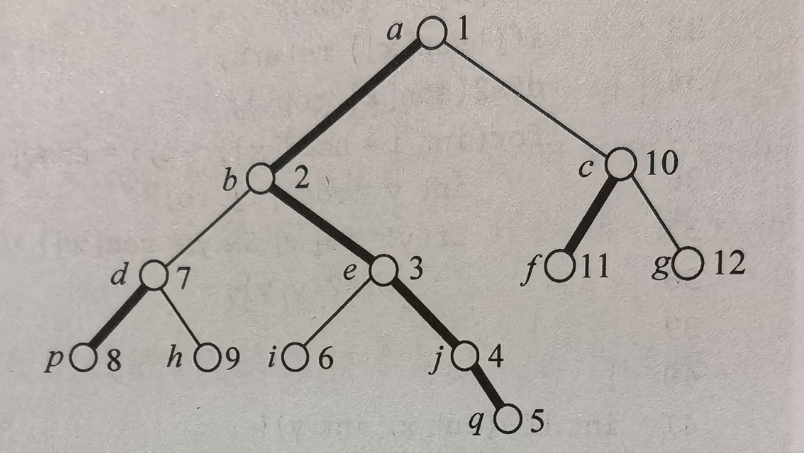
- 根据dfs序将节点安排在线段树上,每条重链看作连续区间,对重链内部的修改和查询用线段树处理修改/查询最短路径上节点权值
- 如修改p-q路径上的权值,则同样方式找到lca,并对途中经过的重链对应的区间使用线段树进行修改/查询
- 修改/查询字数上各点权值,子树由多条重链组成,同样可以使用线段树维护
- 边权转化为点权(处理点权时可以忽略轻边!重链已经覆盖了所有的路径上的点)
- 只需要把边权赋值给两点中的子节点(根节点赋值为0)即可
- P3384 【模板】重链剖分/树链剖分
#include<bits/stdc++.h>
using namespace std;
const int N=100000+10;
int n,m,r,mod;
//以下是链式前向星
struct Edge{int to, next;}edge[2*N];
int head[2*N], cnt;
void init(){ //链式前向星:初始化
for(int i=0;i<2*N;++i){ edge[i].next = -1; head[i] = -1; }
cnt = 0;
}
void addedge(int u,int v){ //链式前向星:加边
edge[cnt].to = v; edge[cnt].next = head[u]; head[u] = cnt++;
}//以上是链式前向星
//以下是线段树
int ls(int x){ return x<<1; } //定位左儿子:x*2
int rs(int x){ return x<<1|1;} //定位右儿子:x*2 + 1
int w[N],w_new[N]; //w[]、w_new[]初始点权
int tree[N<<2], tag[N<<2]; //线段树数组、lazy-tag操作
void addtag(int p,int pl,int pr,int d){ //给结点p打tag标记,并更新tree
tag[p] += d; //打上tag标记
tree[p] += d*(pr-pl+1); tree[p] %= mod; //计算新的tree
}
void push_up(int p){ //从下往上传递区间值
tree[p] = tree[ls(p)] + tree[rs(p)]; tree[p] %= mod;
}
void push_down(int p,int pl, int pr){
if(tag[p]){
int mid = (pl+pr)>>1;
addtag(ls(p),pl,mid,tag[p]); //把tag标记传给左子树
addtag(rs(p),mid+1,pr,tag[p]); //把tag标记传给右子树
tag[p] = 0;
}
}
void build(int p,int pl,int pr){ //建线段树
tag[p] = 0;
if(pl==pr){
tree[p] = w_new[pl]; tree[p] %= mod;
return;
}
int mid = (pl+pr) >> 1;
build(ls(p),pl,mid);
build(rs(p),mid+1,pr);
push_up(p);
}
void update(int L,int R,int p,int pl,int pr,int d){
if(L<=pl && pr<=R){ addtag(p, pl, pr,d); return; }
push_down(p,pl,pr);
int mid = (pl+pr) >> 1;
if(L<=mid) update(L,R,ls(p),pl,mid,d);
if(R> mid) update(L,R,rs(p),mid+1,pr,d);
push_up(p);
}
int query(int L,int R,int p,int pl,int pr){
if(pl>=L && R >= pr) return tree[p] %= mod;
push_down(p,pl,pr);
int res =0;
int mid = (pl+pr) >> 1;
if(L<=mid) res += query(L,R,ls(p),pl,mid);
if(R> mid) res += query(L,R,rs(p),mid+1,pr);
return res;
}
//以下是树链剖分
int son[N],id[N],fa[N],deep[N],siz[N],top[N];
void dfs1(int x, int father){
deep[x]=deep[father]+1; //深度:比父结点深度多1
fa[x]=father; //标记x的父亲
siz[x]=1; //标记每个结点的子树大小(包括自己)
for(int i=head[x];~i;i=edge[i].next){
int y=edge[i].to;
if(y!=father){ //邻居:除了父亲,都是孩子
fa[y]=x;
dfs1(y,x);
siz[x] += siz[y]; //回溯后,把x的儿子数加到x身上
if(!son[x] || siz[son[x]]<siz[y]) //标记每个非叶子结点的重儿子
son[x]=y; //x的重儿子是y
}
}
}
int num = 0;
void dfs2(int x,int topx){ //x当前结点,topx当前链的最顶端的结点
id[x] = ++num; //对每个结点新编号
w_new[num] = w[x]; //把每个点的初始值赋给新编号
top[x]=topx; //记录x的链头
if(!son[x]) return; //x是叶子,没有儿子,返回
dfs2(son[x],topx); //先dfs重儿子
for(int i=head[x];~i;i=edge[i].next){ //再dfs轻儿子
int y=edge[i].to;
if(y!=fa[x] && y!=son[x]) dfs2(y,y);//每个轻儿子都有一条从它自己开始的链
}
}
void update_range(int x,int y,int z){ //和求LCA(x, y)的过程差不多
while(top[x]!=top[y]){
if(deep[top[x]]<deep[top[y]]) swap(x,y);
update(id[top[x]],id[x],1,1,n,z); //修改一条重链的内部
x = fa[top[x]];
}
if(deep[x]>deep[y]) swap(x,y);
update(id[x],id[y],1,1,n,z); //修改一条重链的内部
}
int query_range(int x,int y){ //和求LCA(x,y)的过程差不多
int ans=0;
while(top[x]!=top[y]){ //持续往上跳,直到若x和y属于同一条重链
if(deep[top[x]]<deep[top[y]]) swap(x,y); //让x是链头更深的重链
ans += query(id[top[x]],id[x],1,1,n); //加上x到x的链头这一段区间
ans %= mod;
x = fa[top[x]]; //x穿过轻边,跳到上一条重链
}
if(deep[x]>deep[y]) swap(x,y);
//若LCA(x, y) = y,交换x,y,让x更浅,使得id[x] <= id[y]
ans += query(id[x],id[y],1,1,n); //再加上x, y的区间和
return ans % mod;
}
void update_tree(int x,int k){ update(id[x],id[x]+siz[x]-1,1,1,n,k); }
int query_tree(int x){ return query(id[x],id[x]+siz[x]-1,1,1,n) % mod; }
int main(){
init(); //链式前向星初始化
scanf("%d%d%d%d",&n,&m,&r,&mod);
for(int i=1;i<=n;i++) scanf("%d",&w[i]);
for(int i=1;i<n;i++){
int u,v; scanf("%d%d",&u,&v);
addedge(u,v); addedge(v,u);
}
dfs1(r,0);
dfs2(r,r);
build(1,1,n); //建线段树
while(m--){
int k,x,y,z; scanf("%d",&k);
switch(k){
case 1:scanf("%d%d%d",&x,&y,&z);update_range(x,y,z); break;
case 2:scanf("%d%d",&x,&y); printf("%d\n",query_range(x,y));break;
case 3: scanf("%d%d",&x,&y); update_tree(x,y); break;
case 4: scanf("%d",&x); printf("%d\n",query_tree(x)); break;
}
}
}
补充¶
树的读取¶
- 层次遍历
-
逐层给出树,并在叶节点下一层给出左右子节点(-1表示空),如
1 2 5 3 -1 -1 -1 -1 4 -1 -1 -
使用队列进行读取,对于n个节点会输入2n+1(含n+1个-1)
-
```c++ struct Node{ int val; bool initleft=false; Node left,right,*parent; Node(int x):val(x),left(NULL),right(NULL),parent(NULL){} };
Node*deque[num]; int l=0,r=1; deque[0]=new Node(0); for(int i=1;i
prufer序列¶
- 解决与度数有关的树上计数问题,prufer序列与树具有唯一对应性
- 长度为\(n-2\)
无根树转化为prufer序列¶
- 找到一个度数为1,且编号最小的点。把这个点的父亲节点加入序列,然后把这个点从树中删除。直至树中只剩下两个点

prufer序列转化为无根树¶
- 取出prufer序列最前面的元素x。取出在点集中的、且当前不在prufer序列中的最小元素y。在x,y之间连接一条边。

性质¶
- 度数为\(d_i\)的点会在\(prufer\)序列出现\(d_i-1\)次
- n个节点的无根树(n个节点的完全图的生成树的数目)有\(n^{n-2}\)种(prufer的可能排列)
- 对于给定每个节点度数的无根树有\(\frac{(n-2)!}{\prod_{i=1}^n(d_i-1)!}\)种
- 由于第\(i\)个点会出现\(d_i-1\)次,这显然就是有重复元素的排列问题
- 另一种表述\(\prod_{i=1}^nC_{left}^{d_i-1}\)
- left表示剩余的位置,是个变化的数
- 一些特殊情况的检查,有且仅有n=1时有点度为0;度之和必须为2n-2