图论¶
链式前向星¶
- 以边的理念进行存储
- 使用静态数组来模拟邻接链表
模板¶
struct Edge
{
int to, w, next;//终点,边权,同起点的上一条边的编号
}edge[maxn];//边集
int head[maxn],cnt;//head[i],表示以i为起点的第一条边在边集数组的位置(编号)
void init()//初始化
{
for (int i = 0; i <= n; i++) head[i] = -1;
cnt = 0;//下标
}
void add_edge(int u, int v, int w)//加边,u起点,v终点,w边权
{
edge[cnt].to = v; //终点
edge[cnt].w = w; //权值
edge[cnt].next = head[u];//以u为起点上一条边的编号,也就是与这个边起点相同的上一条边的编号(类似于反向建立链表)
head[u] = cnt++;//更新以u为起点上一条边的编号
}
int main()
{
cin >> n >> m;
int u, v, w;
init();//初始化
for (int i = 1; i <= m; i++)//输入m条边
{
cin >> u >> v >> w;
add_edge(u, v, w);//加边
/*
加双向边
add_edge(u, v, w);
add_edge(v, u, w);
*/
}
for (int i = 1; i <= n; i++)//n个起点
{
cout << i << endl;
for (int j = head[i]; j != -1; j = edge[j].next)//遍历以i为起点的边
{
cout << i << " " << edge[j].to << " " << edge[j].w << endl;
}
cout << endl;
}
return 0;
}
最小生成树¶
Prime¶
-
每次选择距离最近的点加入
-
使用数组存储复杂度为\(O(V^2+E)\)
模板¶
int minCostConnectPoints(vector<vector<int>>& points) {
vector<int>v(points.size(),1),dis(points.size(),INT_MAX);
int ans=0;
v[0]=0;
dis[0]=0;
for(int i=1;i<points.size();i++)
{
dis[i]=abs(points[i][0]-points[0][0])+abs(points[i][1]-points[0][1]);//以第一个点出发初始化
}
for(int i=1;i<points.size();i++)//依次加点
{
pair<int,int>t{-1,INT_MAX};
for(int j=0;j<points.size();j++)//找到最近的点
{
if(v[j])
{
if(dis[j]<t.second)
{
t.second=dis[j];
t.first=j;
}
}
}
v[t.first]=0;
ans+=t.second;
for(int j=1;j<points.size();j++)//更新最近值
{
if(v[j])
{
dis[j]=min(dis[j],abs(points[j][0]-points[t.first][0])+abs(points[j][1]-points[t.first][1]));
}
}
}
return ans;
}
kruskal¶
-
将边从小到大后排序后加入,结合并查集检查
-
\(O(E*log(E))\)
int minCostConnectPoints(vector<vector<int>>& points) {
initiate(points.size());
int ans=0;
auto cmp=[](tuple<int,int,int>&a,tuple<int,int,int>&b){return get<2>(a)>get<2>(b);};
priority_queue<tuple<int,int,int>,vector<tuple<int,int,int>>,decltype(cmp)>edges(cmp);//用优先队列存储边
for(int i=0;i<points.size();i++)
{
for(int j=i+1;j<points.size();j++)
{
edges.emplace(i,j,abs(points[i][0]-points[j][0])+abs(points[i][1]-points[j][1]));//构图
}
}
int n=points.size()-1;
while(n--)//选n-1边
{
auto[x,y,dis]=edges.top();
while(find(x)==find(y))
{
edges.pop();//成环
x=get<0>(edges.top());
y=get<1>(edges.top());
dis=get<2>(edges.top());
}
ans+=dis;
merge(x,y);
edges.pop();
}
return ans;
}
匈牙利算法¶
-
二分图的最大匹配问题
-
\(O(nm)\)
模板¶
const int maxn=105;
int n,m;
int match[maxn];
int vis[maxn];
int e[maxn][maxn];
int dfs(int u){
for(int i=1;i<=n;i++){
if(!vis[i]&&e[u][i]==1){
vis[i]=1;//标记顶点i已访问过
if(!match[i]||dfs(match[i])){//如果点i未被配对或者找到了新的配对、
match[i]=u;//更新配对关系
match[u]=i;
return 1;
}
}
}
return 0;
}
int main()
{
int u,v;
int sum=0;
scanf("%d %d",&n,&m);
for(int i=1;i<=m;i++){
scanf("%d %d",&u,&v);
e[u][v]=e[v][u]=1;
}
for(int i=1;i<=n;i++)
match[i]=0;
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++)
vis[j]=0;//清空上次搜索时的标记
if(dfs(i)) sum++;//寻找增广路,如果找到,配对数加1
}
printf("%d\n",sum);
return 0;
}
并查集¶
模板¶
vector<int>parents;
vector<int>h;
void initiate(int n)
{
parents=vector<int>(n,0);
h=vector<int>(n,1);
for(int i=0;i<n;i++)
parents[i]=i;
}
int find(int target)
{
if(target!=parents[target])
parents[target]=find(parents[target]);
return parents[target];
}
void merge(int x,int y)
{
x=find(x);
y=find(y);
if(x==y)
return;
if(h[x]<=h[y])
{
h[y]+=h[x];
parents[x]=parents[y];
}
else
{
h[x]+=h[y];
parents[y]=parents[x];
}
}
带权并查集¶
- 跟不同时的等式关系 relation(roota,rootb)=d[b]-d[a]+relation
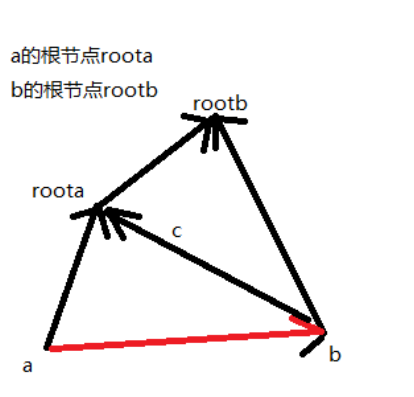
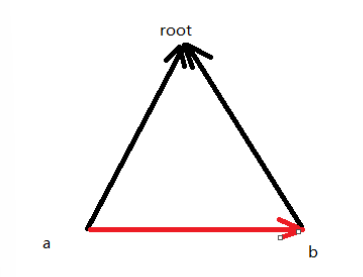
- 根相同时的等式关系 d[a]-d[b]==relation
const int N = 200010;
int s[N]; //集
int d[N]; //权值:记录当前结点到根结点的距离
int ans;
void init_set(){ //初始化
for(int i = 0; i <= N; i++) { s[i] = i; d[i] = 0; }
}
int find_set(int x){ //带权值的路径压缩
if(x != s[x]) {
int t = s[x]; //记录父结点
s[x] = find_set(s[x]); //路径压缩。递归最后返回的是根结点
d[x] += d[t]; //权值更新为x到根结点的权值
}
return s[x];
}
void merge_set(int a, int b,int v){ //合并
int roota = find_set(a), rootb = find_set(b);
if(roota == rootb){
if(d[a] - d[b] != v) ans++;
}
else{
s[roota] = rootb; //合并
d[roota] = d[b]- d[a] + v;
}
}
Dijkstra算法¶
- 堆优化\(O((n+m)logn)\)
模板¶
const long long INF = 0x3f3f3f3f3f3f3f3fLL; //这样定义的好处是: INF <= INF+x
const int N = 3e5+2;
struct edge{
int from, to; //边:起点,终点,权值。起点from并没有用到,e[i]的i就是from
long long w; //边:权值
edge(int a, int b,long long c){from=a; to=b; w=c;}
};
vector<edge>e[N]; //存储图
struct node{
int id; long long n_dis; //id:结点;n_dis:这个结点到起点的距离
node(int b,long long c){id=b; n_dis=c;}
bool operator < (const node & a) const
{ return n_dis > a.n_dis;}
};
int n,m;
int pre[N]; //记录前驱结点
void print_path(int s, int t) { //打印从s到t的最短路
if(s==t){ printf("%d ", s); return; } //打印起点
print_path(s, pre[t]); //先打印前一个点
printf("%d ", t); //后打印当前点。最后打印的是终点t
}
long long dis[N]; //记录所有结点到起点的距离
bool done[N]; //done[i]=true表示到结点i的最短路径已经找到
void dijkstra(){
int s = 1; //起点s = 1
for (int i=1;i<=n;i++) {dis[i]=INF; done[i]=false; } //初始化
dis[s]=0; //起点到自己的距离是0
priority_queue <node> Q; //优先队列,存结点信息
Q.push(node(s, dis[s])); //起点进队列
while (!Q.empty()) {
node u = Q.top(); //pop出距起点s距离最小的结点u
Q.pop();
if(done[u.id]) continue; //丢弃已经找到最短路径的结点。即集合A中的结点
done[u.id]= true;
for (int i=0; i<e[u.id].size(); i++) { //检查结点u的所有邻居
edge y = e[u.id][i]; //u.id的第i个邻居是y.to
if(done[y.to]) continue; //丢弃已经找到最短路径的邻居结点
if (dis[y.to] > y.w + u.n_dis) {
dis[y.to] = y.w + u.n_dis;
Q.push(node(y.to, dis[y.to])); //扩展新邻居,放到优先队列中
pre[y.to]=u.id; //如果有需要,记录路径
}
}
}
// print_path(s,n); //如果有需要,打印路径: 起点1,终点n
}
Johnson 算法¶
- 对 Dijkstra 修改,求所有点对之间的最短距离,效率较高并且可以处理负边的情况
- 新建一个虚拟节点,从这个点向其它所有点连一条边权为 0 的边;接下来用 Bellman-Ford 算法求出从 0 号点到其他所有点的最短路,记为 \(h_i\);对于从 \(u\) 到 \(v\) 边权为 \(w\) 的边将边权设置为 \(w+h_{u}-h_{v}\);之后再以每个点为起点做一次 Dijkstra
- 时间复杂度为 \(O(nm\log m)\)
模板¶
#include <cstring>
#include <iostream>
#include <queue>
#define INF 1e9
using namespace std;
struct edge {
int v, w, next;
} e[10005];
struct node {
int dis, id;
bool operator<(const node& a) const { return dis > a.dis; }
node(int d, int x) { dis = d, id = x; }
};
int head[5005], vis[5005], t[5005];
int cnt, n, m;
long long h[5005], dis[5005];
void addedge(int u, int v, int w) {
e[++cnt].v = v;
e[cnt].w = w;
e[cnt].next = head[u];
head[u] = cnt;
}
bool spfa(int s) {
queue<int> q;
memset(h, 63, sizeof(h));
h[s] = 0, vis[s] = 1;
q.push(s);
while (!q.empty()) {
int u = q.front();
q.pop();
vis[u] = 0;
for (int i = head[u]; i; i = e[i].next) {
int v = e[i].v;
if (h[v] > h[u] + e[i].w) {
h[v] = h[u] + e[i].w;
if (!vis[v]) {
vis[v] = 1;
q.push(v);
t[v]++;
if (t[v] == n + 1) return false;
}
}
}
}
return true;
}
void dijkstra(int s) {
priority_queue<node> q;
for (int i = 1; i <= n; i++) dis[i] = INF;
memset(vis, 0, sizeof(vis));
dis[s] = 0;
q.push(node(0, s));
while (!q.empty()) {
int u = q.top().id;
q.pop();
if (vis[u]) continue;
vis[u] = 1;
for (int i = head[u]; i; i = e[i].next) {
int v = e[i].v;
if (dis[v] > dis[u] + e[i].w) {
dis[v] = dis[u] + e[i].w;
if (!vis[v]) q.push(node(dis[v], v));
}
}
}
return;
}
int main() {
ios::sync_with_stdio(false);
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w;
addedge(u, v, w);
}
for (int i = 1; i <= n; i++) addedge(0, i, 0);
if (!spfa(0)) {
cout << -1 << endl;
return 0;
}
for (int u = 1; u <= n; u++)
for (int i = head[u]; i; i = e[i].next) e[i].w += h[u] - h[e[i].v];
for (int i = 1; i <= n; i++) {
dijkstra(i);
long long ans = 0;
for (int j = 1; j <= n; j++) {
if (dis[j] == INF)
ans += j * INF;
else
ans += j * (dis[j] + h[j] - h[i]);
}
cout << ans << endl;
}
return 0;
}
bellman-ford(SPFA)¶
- 含负权值的单源最短路径/边长有限制的最短路径
- bellman\(O(n^2)\)
- SPFA\(O(mn)\)通常更快\(O(n)\),但最差复杂度较慢
模板¶
- bellman
- 可以通过标记是否还产生更改从而可以提前结束进行优化
//a<出发地,目的地,权值>
vector<int>dp_l(n,1e7),dp(n,1e7);
dp_l[src]=0;
dp[src]=0;
for(int i=0;i<=k;i++)
{
for(auto &a:flights)
{
dp[a[1]]=min(dp[a[1]],dp_l[a[0]]+a[2]);
}
dp_l=dp;
}
- spfa
struct edge {
int v, w;
};
vector<edge> e[maxn];
int dis[maxn], cnt[maxn], vis[maxn];
queue<int> q;
bool spfa(int n, int s) {
memset(dis, 63, sizeof(dis));
dis[s] = 0, vis[s] = 1;
q.push(s);
while (!q.empty()) {
int u = q.front();
q.pop(), vis[u] = 0;
for (auto ed : e[u]) {
int v = ed.v, w = ed.w;
if (dis[v] > dis[u] + w) {
dis[v] = dis[u] + w;
cnt[v] = cnt[u] + 1; // 记录最短路经过的边数
if (cnt[v] >= n) return false;
// 在不经过负环的情况下,最短路至多经过 n - 1 条边
// 因此如果经过了多于 n 条边,一定说明经过了负环
if (!vis[v]) q.push(v), vis[v] = 1;
}
}
}
return true;
}
负环判断¶
- 对于普通的Bellman_ford算法,我们可以在完成DP后,在进行一遍更新,如果存在任意节点与起点之间的最短路径是可以被更新的,那么可以确定图中一定存在负环
for(int i = 1; i <= n; i++) { // 枚举每一个节点
if(dp[i] == 0x3f3f3f3f) { // 无法到达的节点
continue;
}
for(Edge &e : g[i]) { // 枚举从这个节点发出的每一条边
if(dp[i] + e.w < dp[e.v]) {
return 1; // 还能被更新说明有负环
}
}
}
- 对于SPFA算法,我们可以在更新最短路径的同时,记录每条最短路径上的边数,如果发现某条最短路径的边数大于n−1,那么可以确定图中一定存在负环
floyd算法¶
- 找到所有点之间的最短路径
- \(O(n^3)\)
模板¶
// 遍历每个节点k,看将该节点作为跳板后是否可以更新节点(距离变短则更新)
for(int k = 0; k < n; ++k){
for(int i = 0; i < n; ++i){
for(int j = 0; j < n; ++j){
if(d[i][k] + d[k][j] < d[i][j])
d[i][j] = d[i][k] + d[k][j];
}
}
}
Tarjan算法¶
- 寻找割点/割边
- \(O(n+m)\)
模板¶
vector<int> criticalConnections(int n, vector<vector<int>>& connections) {
vector<vector<int>>edges(n);
vector<int>color(n), discovertime(n);
for (auto& a : connections)
{
edges[a[0]].push_back(a[1]);
edges[a[1]].push_back(a[0]);
}
dfs(edges, 0, color, discovertime,-1);
ans.pop_back();//初始节点会被额外加入,要删除(割边不需要)
return ans;
}
int dfs(vector<vector<int>>& edges, int n, vector<int>& color, vector<int>& discovertime,int parent)
{
color[n] = 1;
discovertime[n] = times;
times++;
int back = times;
for (auto a : edges[n])
{
if (color[a] == 1&&a!=parent)//回溯
{
back = min(back, discovertime[a]);
}
else if(color[a] == 0)
{
int wback = dfs(edges, a, color, discovertime,n);
if (wback >= discovertime[n]&&find(ans.begin(),ans.end(),n)==ans.end())//去重(割边为wback >discovertime[n])
ans.push_back(n);//割边(`ans.push_back(vector<int>{a,n});`)
back = min(back, wback);
}
}
color[n] = 2;
return back;
}
Hierholzer 算法¶
- 寻找欧拉回路(通路)
- 通过图中所有边恰好一次且行遍所有顶点的通路称为欧拉通路,
- 于无向图 G,G 是欧拉图当且仅当 G 是连通的且没有奇度顶点。
- 对于有向图 G,G 是欧拉图当且仅当 G 的所有顶点属于同一个强连通分量且每个顶点的入度和出度相同
- 通过图中所有边恰好一次且行遍所有顶点的回路称为欧拉回路,
- 对于无向图 G,G 是半欧拉图当且仅当 G 是连通的且 G 中恰有 0 个或 2 个奇度顶点。
- 对于有向图 G,G 是半欧拉图当且仅当
- 如果将 G 中的所有有向边退化为无向边时,那么 G 的所有顶点属于同一个连通分量;
- 最多只有一个顶点的出度与入度差为 1;
- 最多只有一个顶点的入度与出度差为 1;
- 所有其他顶点的入度和出度相同。
模板¶
void Hierholzer(int x)
{
for(int i=1;i<=maxn;i++)
{
if(g[x][i])
{
g[x][i]--;
g[i][x]--;
Hierholzer(i);
}
}
st.push(x);
}
拓扑排序(任务调度)¶
模板¶
- dfs
void dfs(int u) {
visited[u] = 1;
for (int v: edges[u]) {
if (visited[v] == 0) {
dfs(v);
if (!valid) {
return;
}
}
else if (visited[v] == 1) {
valid = false;//存在环,没有top序列
return;
}
}
toponum++;
topo[u]=toponum;//利用生命周期结束来标记topo序列
visited[u] = 2;
}
- 多任务并发
for(int i=1;i<=n;i++)//添加入度为零的点
{
if(in[i]==0)
{
q.push(i);
}
}
while(!q.empty())
{
int num=q.size();
while(num-->0)//对学期数计数
{
n=q.pop();
for(auto a:path[n])
{
in[a]--;
if(in[a]==0)
{
q.push(a);
}
}
}
ans++;
}
}
- AOE关键路径
#include <cstring>
#include <iostream>
#include <queue>
#define INF 1e9
using namespace std;
struct edge {
int v, w, next;
} e[10005];
struct node {
int dis, id;
bool operator<(const node& a) const { return dis > a.dis; }
node(int d, int x) { dis = d, id = x; }
};
int head[5005], vis[5005], t[5005];
int cnt, n, m;
long long h[5005], dis[5005];
void addedge(int u, int v, int w) {
e[++cnt].v = v;
e[cnt].w = w;
e[cnt].next = head[u];
head[u] = cnt;
}
bool spfa(int s) {
queue<int> q;
memset(h, 63, sizeof(h));
h[s] = 0, vis[s] = 1;
q.push(s);
while (!q.empty()) {
int u = q.front();
q.pop();
vis[u] = 0;
for (int i = head[u]; i; i = e[i].next) {
int v = e[i].v;
if (h[v] > h[u] + e[i].w) {
h[v] = h[u] + e[i].w;
if (!vis[v]) {
vis[v] = 1;
q.push(v);
t[v]++;
if (t[v] == n + 1) return false;
}
}
}
}
return true;
}
void dijkstra(int s) {
priority_queue<node> q;
for (int i = 1; i <= n; i++) dis[i] = INF;
memset(vis, 0, sizeof(vis));
dis[s] = 0;
q.push(node(0, s));
while (!q.empty()) {
int u = q.top().id;
q.pop();
if (vis[u]) continue;
vis[u] = 1;
for (int i = head[u]; i; i = e[i].next) {
int v = e[i].v;
if (dis[v] > dis[u] + e[i].w) {
dis[v] = dis[u] + e[i].w;
if (!vis[v]) q.push(node(dis[v], v));
}
}
}
return;
}
int main() {
ios::sync_with_stdio(false);
cin >> n >> m;
for (int i = 1; i <= m; i++) {
int u, v, w;
cin >> u >> v >> w;
addedge(u, v, w);
}
for (int i = 1; i <= n; i++) addedge(0, i, 0);
if (!spfa(0)) {
cout << -1 << endl;
return 0;
}
for (int u = 1; u <= n; u++)
for (int i = head[u]; i; i = e[i].next) e[i].w += h[u] - h[e[i].v];
for (int i = 1; i <= n; i++) {
dijkstra(i);
long long ans = 0;
for (int j = 1; j <= n; j++) {
if (dis[j] == INF)
ans += j * INF;
else
ans += j * (dis[j] + h[j] - h[i]);
}
cout << ans << endl;
}
return 0;
}
SCC算法¶
- 有环有向图缩图为DAG
- \(O(n+m)\)
模板¶
void tarjan(int u){
dfn[u]=low[u]=ts++; //记录时间戳
st.push(u);
inStack[v]=true;
for(int i=head[u]; ~i; i=e[i].ne){
int v=e[i].v;
if(dfn[v]==-1){ // 如果(u, v)为树枝边
tarjan(v, u);
low[u]=min(low[u], low[v]);
}
else if(inStack[v]){ // 如果(u, v)为横叉边或者后向边
low[u]=min(low[u], dfn[v]);
}
}
if(dfn[u]==low[u]){ // u是当前的SCC最高点
int v;
++scc_cnt; // 更新强连通分量的数量
do{
v=s.top(); s.pop();
inStack[v]=false;
id[v]=scc_cnt; // 标记该点属于第scc_cnt个强连通分量
}while(u!=v)
}
}
树¶
-
树的层次读取
-
```c++ struct Node{ int val; bool initleft=false; Node left,right,*parent; Node(int x):val(x),left(NULL),right(NULL),parent(NULL){} };
Node*deque[num]; int l=0,r=1; deque[0]=new Node(0); for(int i=1;i
prufer序列*¶
- 解决与度数有关的树上计数问题,prufer序列与树具有唯一对应性
- 长度为\(n-2\)
无根树转化为prufer序列¶
- 找到一个度数为1,且编号最小的点。把这个点的父亲节点加入序列,然后把这个点从树中删除。直至树中只剩下两个点

prufer序列转化为无根树¶
- 取出prufer序列最前面的元素x。取出在点集中的、且当前不在prufer序列中的最小元素y。在x,y之间连接一条边。

性质¶
- 度数为\(d_i\)的点会在\(prufer\)序列出现\(d_i-1\)次
- n个节点的无根树(n个节点的完全图的生成树的数目)有\(n^{n-2}\)种(prufer的可能排列)
- 对于给定每个节点度数的无根树有\(\frac{(n-2)!}{\prod_{i=1}^n(d_i-1)!}\)种
- 由于第\(i\)个点会出现\(d_i-1\)次,这显然就是有重复元素的排列问题
- 另一种表述\(\prod_{i=1}^nC_{left}^{d_i-1}\)
- left表示剩余的位置,是个变化的数
- 一些特殊情况的检查,有且仅有n=1时有点度为0;度之和必须为2n-2
LCA¶
-
离线查询,倍增法
-
n个点,进行m次查询,复杂度\(O((n+m)logn)\)
-
c++ #include <bits/stdc++.h> using namespace std; const int N=500005; struct Edge{int to, next;}edge[2*N]; //链式前向星 int head[2*N], cnt; void init(){ //链式前向星:初始化 for(int i=0;i<2*N;++i){ edge[i].next = -1; head[i] = -1; } cnt = 0; } void addedge(int u,int v){ //链式前向星:加边 edge[cnt].to = v; edge[cnt].next = head[u]; head[u] = cnt++; } //以上是链式前向星 int fa[N][20], deep[N]; void dfs(int x,int father){ //求x的深度deep[x]和fa[x][]。father是x的父结点。 deep[x] = deep[father]+1; //深度:比父结点深度多1 fa[x][0] = father; //记录父结点 for(int i=1; (1<<i) <= deep[x]; i++) //求fa[][]数组,它最多到根结点 fa[x][i] = fa[fa[x][i-1]][i-1]; for(int i=head[x]; ~i; i=edge[i].next) //遍历结点i的所有孩子。~i可写为i!=-1 if(edge[i].to != father) //邻居:除了父亲,都是孩子 dfs(edge[i].to, x); } int LCA(int x,int y){ if(deep[x]<deep[y]) swap(x,y); //让x位于更底层,即x的深度值更大 //(1)把x和y提到相同的深度(注意从大到小倒着跳) for(int i=19;i>=0;i--) //x最多跳19次:2^19 > 500005 if(deep[x]-(1<<i)>=deep[y]) //如果x跳过头了就换个小的i重跳 x = fa[x][i]; //如果x还没跳到y的层,就更新x继续跳 if(x==y) return x; //y就是x的祖先 //(2)x和y同步往上跳,找到LCA for(int i=19;i>=0;i--) //如果祖先相等,说明跳过头了,换个小的i重跳 if(fa[x][i]!=fa[y][i]){ //如果祖先不等,就更新x、y继续跳 x = fa[x][i]; y = fa[y][i]; } return fa[x][0]; //最后x位于LCA的下一层,父结点fa[x][0]就是LCA } int main(){ init(); //初始化链式前向星 int n,m,root; scanf("%d%d%d",&n,&m,&root); for(int i=1;i<n;i++){ //读一棵树,用链式前向星存储 int u,v; scanf("%d%d",&u,&v); addedge(u,v); addedge(v,u); } dfs(root,0); //计算每个结点的深度并预处理fa[][]数组 while(m--){ int a,b; scanf("%d%d",&a,&b); printf("%d\n", LCA(a,b)); } return 0; }
树的直径¶
-
存在负数时要使用dp计算,尤其要注意计算的顺序
-
c++ #include<bits/stdc++.h> using namespace std; const int N=1e5+10; struct edge{int to,w; }; //to: 边的终点 w:权值 vector<edge> e[N]; int dp[N]; int maxlen = 0; bool vis[N]; void dfs(int u){ vis[u] = true; for(int i = 0; i < e[u].size(); ++ i){ int v = e[u][i].to, edge = e[u][i].w; if(vis[v]) continue; //v已经算过 dfs(v);//已经遍历过的子树中u为起点的最长路径,加上新指定的子树v的最长路径 maxlen = max(maxlen, dp[u]+ dp[v]+ edge); //计算max{f[u]}。注意此时dp[u]不包括v这棵子树,下一行才包括 dp[u] = max(dp[u], dp[v] + edge); //计算dp[u],此时包括了v这棵子树 } return ; } int main(){ int n; cin >> n; for(int i = 0; i < n-1; i++){ int a, b, w; cin >> a >> b >> w; e[a].push_back({b,w}); //a的邻居是b,路的长度w e[b].push_back({a,w}); //b的邻居是a } dfs(1); //从点1开始DFS cout << maxlen << endl; return 0; }
搜索¶
启发式搜索¶
A*¶
- 常用于求解确定起点、终点的最短路径
-
A*算法既看起点也看终点,能得到最优解,估价函数
f(i)=g(i)+h(i) -
g(i)表示从s到i的代价,由dj保证最优性 h(i)表示从i到t的代价,由贪心计算-
h函数设计
-
4方向移动:
abs(i.x-t.x)+abs(i.y-t.y) - 8方向:
max{abs(i.x-t.x),abs(i.y-t.y)} - 任意:
sqrt((i.x-t.x)^2+(i.y-t.y)^2) -
原则:
-
g与h采用相同的距离计算方式
- h要正确反映远近关系
- h(i)要小于等于i-t的实际最短距离
IDA*¶
- 期望函数优化剪枝dfs
-
在IDDFS基础上:每次从第一层进行有层数上限的dfs
-
如果当前深度+未来需要的步数>深度限制则立即返回false(剪枝)
-
使用最乐观的方式对未来需要的步数进行估计
-
c++ const int N = 100; //最大层次 int num[N]; //记录一条路径上的数字,num[i]是路径上第i层的数字 int n, depth; bool dfs(int now, int d) { //now:当前路径走到的数字,d:now所在的深度 if (d > depth) return false; //当前深度大于层数限制 if (now == n) return true; //找到目标。注意:这一句不能放在上一句前面 if (now << (depth - d) < n) //剪枝:剩下的层数用最乐观的倍增也不能达到n return false; num[d] = now; //记录这条路径上第d层的数字 for(int i = 0; i <= d; i++) { //遍历之前算过的数,继续下一层 if (dfs(now + num[i], d + 1)) return true; //加 else if (dfs(now - num[i], d + 1)) return true; //减 } return false; } int main() { while(~scanf("%d", &n) && n) { for(depth = 0;; depth++) { //IDDFS:每次限制最大搜索depth层 memset(num, 0, sizeof(num)); if (dfs(1, 0)) break; //从数字1开始,当前层0 } printf("%d\n", depth); } return 0; }
高精度¶
-
注意L(数组长度会极大的影响算法效率,应根据需要的数据范围设置)
-
加法
-
c++ const int L=11010; string add(string a,string b)//只限两个非负整数相加 { string ans; int na[L]={0}; int nb[L]={0}; int la=a.size(); int lb=b.size(); for(int i=0;i<la;i++) na[la-1-i]=a[i]-'0'; for(int i=0;i<lb;i++) nb[lb-1-i]=b[i]-'0'; int lmax=max(la,lb); for(int i=0;i<lmax;i++) na[i]+=nb[i],na[i+1]+=na[i]/10,na[i]%=10; if(na[lmax]) lmax++; for(int i=lmax-1;i>=0;i--) ans+=na[i]+'0'; return ans; } -
减法
-
c++ const int L=10010; string sub(string a,string b)//只限大的非负整数减小的非负整数 { string ans; int na[L]={0}; int nb[L]={0}; int la=a.size(); int lb=b.size(); for(int i=0;i<la;i++) na[la-1-i]=a[i]-'0'; for(int i=0;i<lb;i++) nb[lb-1-i]=b[i]-'0'; int lmax=max(la,lb); for(int i=0;i<lmax;i++) { na[i]-=nb[i]; if(na[i]<0) na[i]+=10,na[i+1]--; } while(!na[--lmax]&&lmax>0) lmax++; for(int i=lmax-1;i>=0;i--) ans+=na[i]+'0'; return ans; } -
乘法
-
c++ const int L=100005; string mul(string a,int b)//高精度a乘单精度b { int na[L]; string ans; int la=a.size(); fill(na,na+L,0); for(int i=la-1;i>=0;i--) na[la-i-1]=a[i]-'0'; int w=0; for(int i=0;i<la;i++) na[i]=na[i]*b+w,w=na[i]/10,na[i]=na[i]%10; while(w) na[la++]=w%10,w/=10; la--; while(la>=0) ans+=na[la--]+'0'; return ans; } -
c++ const int L=110; string mul(string a,string b) { string s; int na[L],nb[L],nc[L],La=a.size(),Lb=b.size(); fill(na,na+L,0);fill(nb,nb+L,0);fill(nc,nc+L,0); for(int i=La-1;i>=0;i--) na[La-i]=a[i]-'0'; for(int i=Lb-1;i>=0;i--) nb[Lb-i]=b[i]-'0'; for(int i=1;i<=La;i++) for(int j=1;j<=Lb;j++) nc[i+j-1]+=na[i]*nb[j]; for(int i=1;i<=La+Lb;i++) nc[i+1]+=nc[i]/10,nc[i]%=10; if(nc[La+Lb]) s+=nc[La+Lb]+'0'; for(int i=La+Lb-1;i>=1;i--) s+=nc[i]+'0'; return s; } -
除法
-
c++ using namespace std; string div(string a,int b)//高精度a除以单精度b { string r,ans; int d=0; if(a=="0") return a;//特判 for(int i=0;i<a.size();i++) { r+=(d*10+a[i]-'0')/b+'0'; //求出商 d=(d*10+(a[i]-'0'))%b; //求出余数 } int p=0; for(int i=0;i<r.size();i++) if(r[i]!='0') {p=i;break;} return r.substr(p); } -
max
-
c++ string max(const string& a, const string& b) { if (a.length() > b.length()) { return a; } else if (a.length() < b.length()) { return b; } for (std::size_t i = 0; i < a.length(); ++i) { if (a[i] > b[i]) { return a; } else if (a[i] < b[i]) { return b; } } return a; } -
min
-
c++ string min(const std::string& a, const std::string& b) { if (a.length() < b.length()) { return a; } else if (a.length() > b.length()) { return b; } for (std::size_t i = 0; i < a.length(); ++i) { if (a[i] < b[i]) { return a; } else if (a[i] > b[i]) { return b; } } return a; } -
mod
-
c++ int mod(string a,int MOD) { int left=0; for(int i=0;i<a.size();i++) left=(left*10+(a[i]-'0'))%MOD; return left; }
数论¶
ll powmod(ll a,ll b) {ll res=1;a%=mod; assert(b>=0); for(;b;b>>=1){if(b&1)res=res*a%mod;a=a*a%mod;}return res;}
ll gcd(ll a,ll b) { return b?gcd(b,a%b):a;}
ll lcm(ll a,ll b) {return (a/gcd(a,b))*b;}
gcd与lcm¶
- 性质
- \(gcd(a,b)=gcd(a,k*a+b)\)
- \(k*gcd(a,b)=gcd(k*a,k*b)\)
- \(gcd(a,b)=d\)则\(gcd(a/d,b/d)=1\)(即互素)
- \(gcd(a,b,c)=gcd(a,gcd(b,c))\)
- \(gcd(a,b)=gcd(a/c,b)\)(\(gcd(b,c)=1\))
- gcd区间可以使用st表等结构维护
- 如\(gcd(l,r)=gcd(gcd(l,k_2),gcd(k_1,r))\)只需要直接对重叠区间求gcd
- 裴蜀定理:若ab均为整数,则有整数xy使得\(ax+by=gcd(a,b)\)即\(ax+by\)是\(gcd(a,b)\)的整数倍
逆元¶
-
\(O(n)\)求解范围内全部元素的逆
-
c++ long long inv[N]; void inverse(long long n,long long p){ inv[1]=1; for(int i=2;i<N;i++) inv[i]=(p-p/i)*inv[p%i]%p; } -
\((a/b)modm=(ab^{-1}modm)=(a\mod m)(b^{-1}\mod m)\)
扩展欧几里得¶
- \(O(logn)\)
ll extend_gcd(ll a,ll b,ll &x,ll &y){
if(b == 0){ x=1; y=0; return a;}
ll d = extend_gcd(b,a%b,y,x);
y -= a/b * x;
return d;
}
long long mod_inverse(long long a, long long m){
long long x,y;
extend_gcd(a,m,x,y);
return (x%m + m) % m;
}
//返回1表示无解
欧拉定理¶
-
常用于对指数求模进行化简
-
\(gcd(a,m)=1, \ a^{\varphi(m)}\equiv1(\mod m)\)
-
推论:
-
\[ a^b \equiv \begin{cases} a^{b\mod\varphi(m)} & \text{gcd}(a,m)=1 \\ a^b & b<\varphi(m) \\ a^{b\mod{\varphi(m)}+\varphi(m)} & b\geq\varphi(m) \end{cases} \ (\mod m) \]
费马小定理¶
- \(O(logmod)\)
- 素数且a与mod互素
long lnog mod_inverse(long long a, long long mod){
return fast_pow(a,mod-2,mod);
}
常用运算¶
快速幂¶
long long quickpow(int n,long long num)
{
long long ans=1,sum=n;
while(num)
{
if(num&1)
{
ans=(ans*sum)%mod;
}
sum=(sum*sum)%mod;
num>>=1;
}
return ans;
}
龟速乘¶
- 防止两个较大的longlong在乘法过程中溢出
ll mul(ll a,ll b,ll m){
ll res=0;
while(b>0){
if(b&1) res=(res+a) % m;
a=(a+a) % m;
b>>=1;
}
return res;
}
素数¶
素数判定¶
-
试除法
-
c++ bool is_prime(ll n){ if(n<=1) return false; for(ll i=2;i<=sqrt(n);i++) if(n%i==0) return false; return true; }
线性筛¶
- \(O(n)\)
int prime[N];
bool vis[N];
int euler_sieve(int n){
int cnt = 0;
memset(vis,0,sizeof(vis));
memset(prime,0,sizeof(prime));
for(int i=2;i<=n;i++){
if(!vis[i]) prime[cnt++]=i;
for(int j=0; j<cnt; j++){
if(i*prime[j] >n) break;
vis[i*prime[j]]=1;
if(i%prime[j]==0) break;
}
}
return cnt;
}
质因数分解¶
-
试除法
-
\(O(\sqrt{n})\)
-
c++ int p[20]; //p[]记录因子,p[1]是最小因子。一个int数的质因子最多有十几个 int c[40]; //c[i]记录第i个因子的个数。一个因子的个数最多有三十几个 int factor(int n){ int m = 0; for(int i = 2; i <= sqrt(n); i++) if(n%i == 0){ p[++m] = i, c[m] = 0; while(n%i == 0) n/=i, c[m]++; //把n中重复的因子去掉 } if(n>1) p[++m] = n, c[m] = 1; //没有被除尽,是素数 return m; //共m个 } -
区间元素质因数分解pollard_rho启发式法
-
期望复杂度\(O(n^{\frac14}\log n)\)
-
随机算法,猜测、验证因数
-
c++ typedef long long ll; ll Gcd (ll a,ll b){return b? Gcd(b, a%b):a;} ll mult_mod (ll a,ll b,ll n){ //返回(a*b) mod n a %= n, b %= n; ll ret=0; while (b){ if (b&1){ ret += a; if (ret >= n) ret -= n; } a<<=1; if (a>=n) a -= n; b>>=1; } return ret; } ll pollard_rho (ll n){ //返回一个因子,不一定是质因子 ll i=1, k=2; ll c = rand()%(n-1)+1; ll x = rand()%n; ll y = x; while (true){ i++; x = (mult_mod(x,x,n)+c) % n; //(x*x) mod n ll d = Gcd(y>x?y-x:x-y, n); //重要:保证gcd的参数大于等于0 if (d!=1 && d!=n) return d; if (y==x) return n; //已经出现过,直接返回 if (i==k) { y=x; k=k<<1;} } } void findfac (ll n){ //找所有的素因子 if (miller_rabin(n)) { //用miller_rabin判断是否为素数 factor[tol++] = n; //存素因子 return; } ll p = n; while (p>=n) p=pollard_rho(p); //找到一个因子 findfac(p); //继续寻找更小的因子 findfac(n/p); }
组合数¶
预处理阶乘+逆元¶
- \(C_{n}^{r} = (n! modm)((r!)^{-1}modm)(((n-r)!)^{-1}modm)modm\)
- \(O(n)\)
预处理阶乘+逆元+卢卡斯定理¶
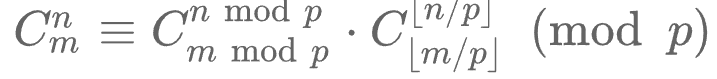
- \(O(p+log_pm)\)
int lucas(LL a, LL b, LL p) { // 注意LL参数类型
if (a < p && b < p) return C(a, b, p);
return (LL)C(a % p, b % p, p) * lucas(a / p, b / p, p) % p; // 递归让其到p范围内求解
}
中国剩余定理¶
int CRT(int a[],int m[],int n) {
int M = 1;
int ans = 0;
for(int i=1; i<=n; i++)
M *= m[i];
for(int i=1; i<=n; i++) {
int x, y;
int Mi = M / m[i];
extend_Euclid(Mi, m[i], x, y);
ans = (ans + Mi * x * a[i]) % M;
}
if(ans < 0) ans += M;
return ans;
}
void extend_Euclid(int a, int b, int &x, int &y) {
if(b == 0) {
x = 1;
y = 0;
return;
}
extend_Euclid(b, a % b, x, y);
int tmp = x;
x = y;
y = tmp - (a / b) * y;
}
组合数学¶
公式¶
- 排列
- \(P_n^r=\frac{n!}{(n-r)!}\)
- 圆排列\(\frac{P^r_n}{r}\)
- 组合
- \(C_n^r=\frac{n!}{r!(n-r)!}\)
- 性质公式
- \(C_n^r=C_n^{n-r}\)
- \(C_n^r=C_{n-1}^r+C_{n-1}^{r-1}\)帕斯卡公式,为了避免阶层及逆元时使用dp思想快速计算组合数
- \(C_n^0+\dots+C_n^n=2^n\)
- 多重集排列
- k个不同元素,每个有无数个,选r个排列\(k^r\)
- k个不同元素,分别\(n_1,\dots,n_k\)个(共n个),排列个数为\(\frac{n!}{n_1!\dots n_k!}\)
- 二项式定理\((a+b)^n=\sum_{r=0}^nC_n^ra^rb^{n-r}\)
- 卢卡斯公式\(C_n^r\equiv C_{n\mod m}^{r\mod m}C_{n/m}^{r/m}(\mod m)\)
- 要求m是一个素数
组合数的计算¶
-
使用递推计算
-
计算多项,复杂度\(O(n^2)\)
-
```c++ const int N = 1005; #define mod 10007 int c[N][N]; int dfs(int n,int m){ //用递推公式求二项式系数 if(!m) return c[n][m]=true; if(m==1) return c[n][m]=n; if(c[n][m]) return c[n][m]; //记忆化 if(n-m<m) m=n-m; return c[n][m]=(dfs(n-1,m)+dfs(n-1,m-1))%mod; }
for (int i = 0; i < N; i++) c[i][0] = 1; for (int i = 1; i < N; i++) for (int j = 1; j <= i; j++) c[i][j] = (c[i - 1][j] + c[i - 1][j - 1])%mod;
``` -
用逆直接计算
-
只计算1项,复杂度\(O(n)\)
-
c++ #define mod 10007 int fac[10001]; //预计算阶乘 int inv[10001]; //预计算逆 ll fastPow(ll a, ll n){ //标准快速幂 ll ans = 1; a %= mod; //防止下面的ans*a越界 while(n) { if(n & 1) ans = (ans*a) % mod; a = (a*a) % mod; n >>= 1; } return ans; } int C(int n,int m){ //算组合数,用到除法取模的逆 return (fac[n]*inv[m]%mod*inv[n-m]%mod)%mod; } int main(){ int a,b,n,m,k,ans; cin >>n>>r; fac[0] = 1; for(int i=1;i<=n;i++){ fac[i] = (fac[i-1]*i)%mod; //预计算阶乘,要取模 inv[i] = fastPow(fac[i],mod-2); //用费马小定理预计算i!的逆 } ans = C(n,r); cout << ans; return 0; } -
卢卡斯定理
-
c++ ll Lucas(ll n,ll r,int m){ //用递归计算C(n, r) mod m if(r==0) return 1; return C(n%m,r%m,m) * Lucas(n/m,r/m,m)%m; } -
卡特兰数
-
\(1,1,2,5,14,42,132,429,1430\dots\)
-
\(C_n=C_{2n}^n-C_{2n}^{n-1}\)
-
路径问题,括号匹配
-
\(O(n)\)
-
c++ int main() { ll n; cin>>n; fac[0] = 1; for(int i=1;i<=(n+m);i++){ fac[i] = (fac[i-1]*i)%mod; inv[i] = fastPow(fac[i],mod-2); } ll res=((C(n*2,n)-C(n*2,n-1))%mod+mod)%mod; cout<<res<<endl; return 0; }
-
-
\(C_n=\sum C_kC_{n-k} \ \ \ C_0=1\)
-
应用:构造二叉树
-
\(O(n^2)\)
-
c++ ll C[n+1]; memset(C,0,sizeof(C)); C[0]=C[1]=1; for(int i=2;i<=n;i++){ for(int j=0;j<i;j++){ C[i]=(C[i]+(C[j]*C[i-j])%mod)%mod; } }
-
-
\(C_n=\frac{4n-2}{n+1}C_{n-1} \ C_0=1\)
-
第一类斯特林数
-
\(s(n,k)\)把n个不同元素分到k个圆排列中(不能为空),有多少方案
-
\(s(n,k)=s(n-1,k-1)+(n-1)s(n-1,k), \ 1<=k<=n\)
- \(s(0,0)=1,s(k,0)=0, \ 1<=k<=n\)
-
第二类斯特林数
-
\(S(n,k)\)把n个不同的球分配到k个无差别的盒子,不能有空,分配方式数目
- \(S(n,k)=S(n-1,k-1)+kS(n-1,k), \ 1<=k<=n\)
- \(S(0,0)=1,S(i,0)=0, \ 1<=i<=n\)
计算几何¶
- 基本表示
const int eps=1e-8;
int sgn(double x){ //符号判断
if(fabs(x) < eps) return 0;
else return x<0?-1:1;
}
int dcmp(double x, double y){ //比较两个浮点数
if(fabs(x - y) < eps) return 0;
else return x<y ?-1:1;
}
struct Point{ //点的表示
double x,y;
Point(){}
Point(double x,double y):x(x),y(y){}
Point operator + (Point B){return Point(x+B.x,y+B.y);}
Point operator - (Point B){return Point(x-B.x,y-B.y);}
Point operator * (double k){return Point(x*k,y*k);}//与实数相乘
Point operator / (double k){return Point(x/k,y/k);}
bool operator == (Point B){return sgn(x-B.x)==0 && sgn(y-B.y)==0;}//近似相等
};
double Distance(Point A, Point B){ return hypot(A.x-B.x,A.y-B.y); }
//向量直接使用点来表示
typedef Point Vector;
//向量运算
double Dot(Vector A,Vector B){ return A.x*B.x + A.y*B.y; }
double Len(Vector A){return sqrt(Dot(A,A));}
double Len2(Vector A){return Dot(A,A);}
double Angle(Vector A,Vector B){return acos(Dot(A,B)/Len(A)/Len(B));}
double Cross(Vector A,Vector B){return A.x*B.y - A.y*B.x;}
bool Parallel(Vector A, Vector B){return sgn(Cross(A,B)) == 0;}//检查平行
//向量构成的平行四边形的面积
double Area2(Point A,Point B,Point C){ return Cross(B-A, C-A);}
Vector Rotate(Vector A, double rad){
return Vector(A.x*cos(rad)-A.y*sin(rad), A.x*sin(rad)+A.y*cos(rad));
}
//法向量(逆时针旋转90度并取单位向量)
Vector Normal(Vector A){return Vector(-A.y/Len(A), A.x/Len(A));}
- 二维几何基本表示
struct Line{
Point p1,p2; //(1)线上的两个点
Line(){}
Line(Point p1,Point p2):p1(p1),p2(p2){}
Line(Point p,double angle){ //(4)根据一个点和倾斜角 angle 确定直线,0<=angle<pi
p1 = p;
if(sgn(angle – pi/2) == 0){p2 = (p1 + Point(0,1));}
else{p2 = (p1 + Point(1,tan(angle)));}
}
Line(double a,double b,double c){ //(2)ax+by+c=0
if(sgn(a) == 0){
p1 = Point(0,-c/b);
p2 = Point(1,-c/b);
}
else if(sgn(b) == 0){
p1 = Point(-c/a,0);
p2 = Point(-c/a,1);
}
else{
p1 = Point(0,-c/b);
p2 = Point(1,(-c-a)/b);
}
}
};
//点和直线
int Point_line_relation(Point p, Line v){
int c = sgn(Cross(p-v.p1,v.p2-v.p1));
if(c < 0)return 1; //1:p在v的左边
if(c > 0)return 2; //2:p在v的右边
return 0; //0:p在v上
}
//点和线段
bool Point_on_seg(Point p, Line v){ //点和线段:0 点不在线段v上;1 点在线段v上
return sgn(Cross(p-v.p1, v.p2-v.p1)) == 0 && sgn(Dot(p – v.p1,p- v.p2)) <= 0;
}
//点到直线距离
double Dis_point_line(Point p, Line v){
return fabs(Cross(p-v.p1,v.p2-v.p1))/Distance(v.p1,v.p2);
}
//如果点到直线的投影在线段上,那就是最短距离,否则是到两个端点距离的最小值
double Dis_point_seg(Point p, Segment v){
if(sgn(Dot(p- v.p1,v.p2-v.p1))<0 || sgn(Dot(p- v.p2,v.p1-v.p2))<0)
return min(Distance(p,v.p1),Distance(p,v.p2));
return Dis_point_line(p,v);
}
//投影
Point Point_line_proj(Point p, Line v){
double k = Dot(v.p2-v.p1,p-v.p1)/Len2(v.p2-v.p1);
return v.p1+(v.p2-v.p1)*k;
}
//对称点
Point Point_line_symmetry(Point p, Line v){
Point q = Point_line_proj(p,v);
return Point(2*q.x-p.x,2*q.y-p.y);
}
//直线的位置关系
int Line_relation(Line v1, Line v2){
if(sgn(Cross(v1.p2-v1.p1,v2.p2-v2.p1)) == 0){
if(Point_line_relation(v1.p1,v2)==0) return 1; //1 重合
else return 0; //0 平行
}
return 2; //2 相交
}
//直线的交点
Point Cross_point(Point a,Point b,Point c,Point d){
double s1 = Cross(b-a,c-a);
double s2 = Cross(b-a,d-a); //叉积有正负
return Point(c.x*s2-d.x*s1,c.y*s2-d.y*s1)/(s2-s1);
}
//判断线段是否相交
bool Cross_segment(Point a,Point b,Point c,Point d){
double c1 = Cross(b-a,c-a),c2=Cross(b-a,d-a);
double d1 = Cross(d-c,a-c),d2=Cross(d-c,b-c);
return sgn(c1)*sgn(c2) < 0 && sgn(d1)*sgn(d2) < 0;
}
//判断直线和线段相交
bool Cross_segment(Line l, Point a, Point b)
{
double c1 = Cross(l.p2 - l.p1, a - l.p1), c2 = Cross(l.p2 - l.p1, b - l.p1);
return sgn(c1) * sgn(c2) <= 0;
}
- 多边形
//点和多边形的关系
int Point_in_polygon(Point pt,Point *p,int n){ //点pt,多边形Point *p
for(int i = 0;i < n;i++){ //3:点在多边形的顶点上
if(p[i] == pt) return 3;
}
for(int i = 0;i < n;i++){ //2:点在多边形的边上
Line v=Line(p[i],p[(i+1)%n]);
if(Point_on_seg(pt,v)) return 2;
}
int num = 0;
for(int i = 0;i < n;i++){
int j = (i+1)% n;
int c = sgn(Cross(pt-p[j],p[i]-p[j]));
int u = sgn(p[i].y – pt.y);
int v = sgn(p[j].y – pt.y);
if(c > 0 && u < 0 && v >=0) num++;
if(c < 0 && u >=0 && v < 0) num--;
}
return num != 0; //1:点在内部; 0:点在外部
}
//多边形的面积
double Polygon_area(Point *p, int n){ //Point *p表示多边形
double area = 0;
for(int i = 0;i < n;i++)
area += Cross(p[i],p[(i+1)%n]);
return area/2; //面积有正负,返回时不能简单地取绝对值
}
//多边形的重心
Point Polygon_center(Point *p, int n){ //求多边形重心
Point ans(0,0);
if(Polygon_area(p,n)==0) return ans;
for(int i = 0;i < n;i++)
ans = ans+(p[i]+p[(i+1)%n])*Cross(p[i],p[(i+1)%n]);
return ans/Polygon_area(p,n)/6;
}
//三角形外心
Point circle_center(const Point a, const Point b, const Point c){
Point center;
double a1=b.x-a.x, b1=b.y-a.y, c1=(a1*a1+b1*b1)/2;
double a2=c.x-a.x, b2=c.y-a.y, c2=(a2*a2+b2*b2)/2;
double d =a1*b2-a2*b1;
center.x =a.x+(c1*b2-c2*b1)/d;
center.y =a.y+(a1*c2-a2*c1)/d;
return center;
}
- 凸包
//Convex_hull()求凸包。凸包顶点放在ch中,返回值是凸包的顶点数
int Convex_hull(Point *p,int n,Point *ch){
n = unique(p,p+n)-p; //去除重复点
sort(p,p+n); //对点排序:按x从小到大排序,如果x相同,按y排序
int v=0;
//求下凸包。如果p[i]是右拐弯的,这个点不在凸包上,往回退
for(int i=0;i<n;i++){
while(v>1 && sgn(Cross(ch[v-1]-ch[v-2],p[i]-ch[v-1]))<=0)
v--;
ch[v++]=p[i];
}
int j=v;
//求上凸包
for(int i=n-2;i>=0;i--){//最右点n-1已经在序列里了,故从n-2开始
while(v>j && sgn(Cross(ch[v-1]-ch[v-2],p[i]-ch[v-1]))<=0)
v--;
ch[v++]=p[i];
}
if(n>1) v--;//最左侧点被重复计入
return v; //返回值v是凸包的顶点数
}
Point p[N],ch[N]; //输入点是p[],计算得到的凸包顶点放在ch[]中
int main(){
int n; cin >> n;
for(int i=0;i<n;i++) scanf("%lf%lf",&p[i].x,&p[i].y);
int v = Convex_hull(p,n,ch); //返回凸包的顶点数v
double ans=0;
for(int i=0;i<v;i++) ans += Distance(ch[i],ch[(i+1)%v]); //计算凸包周长
printf("%.2f\n",ans);
return 0;
}
- 圆
struct Circle{
Point c; //圆心
double r; //半径
Circle(){}
Circle(Point c,double r):c(c),r(r){}
Circle(double x,double y,double _r){c=Point(x,y);r = _r;}
};
//点和圆的关系
int Point_circle_relation(Point p, Circle C){
double dst = Distance(p,C.c);
if(sgn(dst – C.r) < 0) return 0; //0 点在圆内
if(sgn(dst – C.r) ==0) return 1; //1 圆上
return 2; //2 圆外
}
//直线和圆的关系
int Line_circle_relation(Line v,Circle C){
double dst = Dis_point_line(C.c,v);
if(sgn(dst-C.r) < 0) return 0; //0 直线和圆相交
if(sgn(dst-C.r) ==0) return 1; //1 直线和圆相切
return 2; //2 直线在圆外
}
//线段和圆的关系
int Seg_circle_relation(Segment v,Circle C){
double dst = Dis_point_seg(C.c,v);
if(sgn(dst-C.r) < 0) return 0; //0线段在圆内
if(sgn(dst-C.r) ==0) return 1; //1线段和圆相切
return 2; //2线段在圆外
}
//直线和圆的交点
//pa, pb是交点。返回值是交点个数
int Line_cross_circle(Line v,Circle C,Point &pa,Point &pb){
if(Line_circle_relation(v, C)==2) return 0;//无交点
Point q = Point_line_proj(C.c,v); //圆心在直线上的投影点
double d = Dis_point_line(C.c,v); //圆心到直线的距离
double k = sqrt(C.r*C.r-d*d);
if(sgn(k) == 0){ //1个交点,直线和圆相切
pa = q; pb = q; return 1;
}
Point n=(v.p2-v.p1)/ Len(v.p2-v.p1); //单位向量
pa = q + n*k; pb = q - n*k;
return 2; //2个交点
}
线性代数¶
矩阵快速幂(加速dp)¶
-
加速线性递推问题
-
斐波那契
- \(\begin{pmatrix} F_n & F_{n-1}\end{pmatrix}=\begin{pmatrix} F_{n-1} & F_{n-2}\end{pmatrix}*\begin{pmatrix} 1 & 1\\ 1 & 0\end{pmatrix}\)
模板¶
struct matrix{ int m[N][N]; }; //定义矩阵,常数N是矩阵的行数和列数
matrix operator * (const matrix& a, const matrix& b){ //重载*为矩阵乘法。注意const
matrix c;
memset(c.m, 0, sizeof(c.m)); //清零
for(int i=0; i<N; i++)
for(int j=0; j<N; j++)
for(int k = 0; k<N; k++)
//c.m[i][j] += a.m[i][k] * b.m[k][j]; //不取模
c.m[i][j] = (c.m[i][j] + a.m[i][k] * b.m[k][j]) % mod;//取模
return c;
}
matrix pow_matrix(matrix a, int n){ //矩阵快速幂,代码和普通快速幂几乎一样
matrix ans;
memset(ans.m,0,sizeof(ans.m));
for(int i=0;i<N;i++) ans.m[i][i] = 1; //初始化为单位矩阵,类似普通快速幂的ans=1
while(n) {
if(n&1) ans = ans * a; //不能简写为ans *= a,这里的*重载了
a = a * a;
n>>=1;
}
return ans;
}
字符串¶
字符串分隔¶
void Stringsplit(string str,const char split)
{
istringstream iss(str); // 输入流
string token; // 接收缓冲区
while (getline(iss, token, split)) // 以split为分隔符
{
cout << token << endl; // 输出
}
}
kmp¶
- \(O(n)\)
模板¶
vector<int> build_next(string&s)//构建next数组
{
vector<int>next{0};//第一位一定为零(因为规定前后缀不能为自身)
int i=1,len=0;//len记录当前位置最大重合长度
while(i<s.size())
{
if(s[len]==s[i])
{
len++;
next.push_back(len);
i++;
}
else
{
if(len==0)
{
next.push_back(0);
i++;
}
else
len=next[len-1];//找到对应的前缀的末尾位置(一种递归思想,长的匹配不上则逐渐缩短去找)
}
}
return next;
}
int kmp(string fs,string ss)//ss为待匹配的子串
{
vector<int>next=build_next(fs);
int i=0,j=0;
while(i<fs.size())
{
if(fs[i]==ss[j])
{
i++;
j++;
}
else if(j>0)
j=next[j-1];前next[j-1]位仍相同,在这之后继续匹配
else
i++;
if(j==ss.size())
return i-j;
}
return -1;
}
Manacher¶
- 找到所有回文子串
-
\(d_1[i] d_2[i]\)分别表示以位置\(i\)为中心的长度为奇数和长度为偶数的回文串个数
-
\(O(n)\)
模板¶
#include<bits/stdc++.h>
using namespace std;
const int N=11000002;
int n,P[N<<1]; //P[i]: 以s[i]为中心的回文半径
char a[N],s[N<<1];
void change(){ //变换
n = strlen(a);
int k = 0; s[k++]='$'; s[k++]='#';
for(int i=0;i<n;i++){s[k++]=a[i]; s[k++]='#';} //在每个字符后面插一个#
s[k++]='&'; //首尾不一样,保证第18行的while循环不越界
n = k;
}
void manacher(){
int R = 0, C;
for(int i=1;i<n;i++){
if(i < R) P[i] = min(P[(C<<1)-i],P[C]+C-i); //合并处理两种情况
else P[i] = 1;
while(s[i+P[i]] == s[i-P[i]]) P[i]++; //暴力:中心扩展法
if(P[i]+i > R){
R = P[i]+i; //更新最大R
C = i;
}
}
}
int main(){
scanf("%s",a); change();
manacher();
int ans=1;
for(int i=0;i<n;i++) ans=max(ans,P[i]);
printf("%d",ans-1);
return 0;
}
Rabin-Karp字符串哈希¶
- base:进制基数
- mod:可以为一个具体值如1e9+7或通过unsigned类型自动实现。
模板¶
//base常用31(对字符串来说),mod:1e9+7
//定义为int类型
for (int i = 1; i <= n; ++i) {
pre[i] = ((LL)pre[i - 1] * base + text[i - 1]) % mod;
mul[i] = (LL)mul[i - 1] * base % mod;//计算base的i次幂
}
hash = (pre[r + 1] - (LL)pre[l] * mul[r - l + 1] % mod + mod) % mod;
//unsigned long long定义,操作方便可以自动取余并且发生哈希冲突的可能性更小(常用)
for (int i = 1; i <= n; ++i) {
pre[i] = pre[i - 1] * base + text[i - 1];
mul[i] = mul[i - 1] * base;
}
hash = pre[r + 1] - (LL)pre[l] * mul[r - l + 1];
字典树¶
class Trie {
public:
Trie() {
root=new TreeNode;
}
void insert(string word) {
TreeNode*p=root;
for(auto a:word)
{
if(p->child[a-'a']==nullptr)
p->child[a-'a']=new TreeNode;
p=p->child[a-'a'];
}
p->check=true;//标记结尾
}
bool search(string word) {
TreeNode*p=root;
for(auto a:word)
{
if(p->child[a-'a']==nullptr)
return false;
p=p->child[a-'a'];
}
return p->check;//查找单词要求必须是结尾
}
bool startsWith(string prefix) {
TreeNode*p=root;
for(auto a:prefix)
{
if(p->child[a-'a']==nullptr)
return false;
p=p->child[a-'a'];
}
return true;//查找前缀不要求结束节点一定可以作为结尾
}
private:
struct TreeNode{
TreeNode(){
for(auto &a:child)
a=nullptr;
check=false;
}
TreeNode*child[26];//也可以使用hash存储
bool check;
};
TreeNode* root;
};
AC自动机¶
- 多模匹配算法,可以在文本串中同时查找不同的模式串
-
核心思想:字典树组织模式串+KMP 避免回溯
-
给定一个长度为 \(n\) 的文本 \(S\) ,以及 \(k\) 个平均长度为 \(m\) 的模式串,搜索这些模式串出现的位置
- 模式匹配的事件复杂度(取决于 fail 跳的次数)最差为 \(O(nm)\) ,但是大多情况下总复杂度近似 \(O(n)\)
模板¶
#include <bits/stdc++.h>
using namespace std;
const int N=1000005;
struct node{
int son[26]; //26个字母
int end; //字符串结尾标记
int fail; //失配指针
}t[N]; //trie[],字典树
int cnt; //当前新分配的存储位置
void Insert(char *s){ //在字典树上插入单词s
int now = 0; //字典树上当前匹配到的结点,从root=0开始
for(int i=0;s[i];i++){ //逐一在字典树上查找s[]的每个字符
int ch=s[i]-'a';
if(t[now].son[ch]==0) //如果这个字符还没有存过
t[now].son[ch]=cnt++; //把cnt位置分配给这个字符
now = t[now].son[ch]; //沿着字典树往下走
}
t[now].end++; //end>0,它是字符串的结尾。end=0不是结尾
}
void getFail(){ //用BFS构建每个结点的fail指针
queue<int>q;
for(int i=0;i<26;i++) //把第一层入队,即root的子结点
if(t[0].son[i]) //这个位置有字符
q.push(t[0].son[i]);
while(!q.empty()){
int now = q.front(); //队首的fail指针已求得,下面求它孩子的fail指针
q.pop();
for(int i=0;i<26;i++){ //遍历now的所有孩子
if(t[now].son[i]){ //若这个位置有字符
t[t[now].son[i]].fail=t[t[now].fail].son[i];
//这个孩子的Fail=“父结点的Fail指针所指向的结点的与x同字符的子结点”
q.push(t[now].son[i]); //这个孩子入队,后面再处理它的孩子
}
else //若这个位置无字符
t[now].son[i]=t[t[now].fail].son[i];//虚拟结点,用于底层的Fail计算
}
}
}
int query(char *s){ //在文本串s中找有多少个模式串P
int ans=0;
int now=0; //从root=0开始找
for(int i=0;s[i];i++){ //对文本串进行遍历
int ch = s[i]-'a';
now = t[now].son[ch];
int tmp = now;
while(tmp && t[tmp].end!=-1){ //利用fail指针找出所有匹配的模式串
ans+=t[tmp].end; //累加到答案中。若这不是模式串的结尾,end=0
t[tmp].end = -1; //以这个字符为结尾的模式串已经统计,后面不再统计
tmp = t[tmp].fail; //fail指针跳转
cout << "tmp="<<tmp<<" "<<t[tmp].son;
}
}
return ans;
}
char str[N];
int main(){
int k;
scanf("%d",&k);
while(k--){
memset(t,0,sizeof(t)); //清空,准备一个测试
cnt = 1; //把cnt=0留给root
int n; scanf("%d",&n);
while(n--){scanf("%s",str);Insert(str);} //输入模式串, 插入字典树中
getFail(); //计算字典树上每个结点的失配指针
scanf("%s",str); //输入文本串
printf("%d\n",query(str));
}
return 0;
}
dp¶
经典问题¶
最长上升子序列¶
- \(O(nlogn)\)
void solve() {
for (int i = 0; i < n; ++i){
dp[i] = INF;
}
for (int i = 0; i < n; ++i) {
*lower_bound(dp, dp + n, a[i]) = a[i]; // 返回一个指针
}
printf("%d\n", *lower_bound(dp, dp + n, INF) - dp;
}
最长公共子序列¶
void solve() {
for (int i = 0; i < n; ++i) {
for (int j = 0; j < m; ++j) {
if (s1[i] == s2[j]) {
dp[i + 1][j + 1] = dp[i][j] + 1;
}else {
dp[i + 1][j + 1] = max(dp[i][j + 1], dp[i + 1][j]);
} } }
}
数位dp¶
- isLimit 表示当前是否受到了 n 的约束。若为真,则第i 位填入的数字至多为 s[i],否则至多为 9。例如n=234,如果前面填了 23,那么最后一位至多填 4;如果前面填的不是 23,那么最后一位至多填 9。如果在受到约束的情况下填了 s[i],那么后续填入的数字仍会受到 n 的约束。
- isNum 表示 i 前面的数位是否填了数字。若为假,则当前位可以跳过(不填数字),或者要填入的数字至少为 1;若为真,则必须填数字,且要填入的数字从 0 开始。这样我们可以控制构造出的是一位数/两位数/三位数等等。对于本题而言。
- mask 表示前面选过的数字集合,换句话说,第 i位要选的数字不能在 mask 中。
模板¶
class Solution {
public:
int arr[10][1024][2][2][2](<../编程语言/c++/笔记(整理前)/2.md>);//dp数组//可以额外添加维数表示是否满足某一性质
//含义:从第i位开始,在islimit,isnum条件下可能的合法方案数
int countSpecialNumbers(int n) {
string s=to_string(n);
return dp(0,0,true,false,s);
}
int dp(int i,int mark,bool islimit,bool isnum, string &n)//mark用了状态压缩储存
{
if(i==n.size())//结束条件
return isnum[&&isre];//isnum=0意味着没有取过数,自然方法数为0
if(arr[i][mark][islimit][isnum]!=0)//记忆化
return arr[i][mark][islimit][isnum];
int sum=0;
if(!isnum)//本位之前没有去数,那没本位可以继续不取数
sum=dp(i+1,mark,false,false,n);
int up=0;
if(islimit)//本位是否受限
up=n[i]-'0';
else
up=9;
for(int j=1-int(isnum);j<=up;j++)//本位填入数字方法数
{
if(((mark>>j)&1)==0)//j没有使用过
sum+=dp(i+1,mark|(1<<j),islimit&&j==up,true,n);
}
arr[i][mark][islimit][isnum]=sum;
return sum;
}
};
背包dp¶
- 背包分类
- 0/1背包:外循环nums,内循环target,target倒序且target>=nums[i];
- 完全背包:外循环nums,内循环target,target正序且target>=nums[i];
- 组合背包:外循环target,内循环nums,target正序且target>=nums[i];
- 分组背包:这个比较特殊,需要三重循环:外循环背包bags,内部两层循环根据题目的要求转化为1,2,3三种背包类型的模板
- 问题分类
- 最值问题: dp[i] = max/min(dp[i], dp[i-nums]+1)或dp[i] = max/min(dp[i], dp[i-num]+nums);
- 存在问题(bool):dp[i]=dp[i]||dp[i-num];
- 组合问题(计数):dp[i]+=dp[i-num];
- 因为考虑排列顺序,这样才可以得到全排列;如果不考虑顺序,那就变成了普通背包问题,不需要调换顺序。
模板¶
void bag_problem()
{
vector<int> weight = {1, 3, 4};
vector<int> value = {15, 20, 30};
int bagWeight = 4;
vector<int> dp(bagWeight + 1, 0);
for (int i = 0; i < weight.size(); i++)
{
for (int j = bagWeight; j >= weight[i]; j--)
{
dp[j] = max(dp[j], dp[j - weight[i]] + value[i]);
}
}
cout << dp[bagWeight] << endl;
}
分组背包¶
-
把物品分成许多组,每组背包只能选择一个物品
-
多一层循环,处理每组内的元素
-
cpp for (int i = 1; i <= n; ++i) for (int j = m; j >= 0; --j) //对于01分组背包,j依然需要倒序(否则出现一个物品使用多次) for (int k = 0; k < s[i]; ++k)//k必须从小到大遍历(否则出现选择同一个组内的多个物品) if (j >= v[i][k]) f[j] = max(f[j], f[j - v[i][k]] + w[i][k]);
多重背包¶
-
物品数目有限,并且不同
-
朴素做法,对物体拆分(拆为n个一,根据二进制位拆分可以优化)
-
使用单调队列优化
-
cpp #include<bits/stdc++.h> using namespace std; const int N=100010; int n,C; int dp[N],q[N],num[N]; int w,c,m; //物品的价值w、体积c、数量m int main(){ cin >> n >> C; //物品数量n,背包容量W memset(dp,0,sizeof(dp)); for(int i=1;i<=n;i++){ cin>>w>>c>>m; //物品i的价值w、体积c、数量m if(m>C/c) m = C/c; //计算 min{m, j/c}(再多的物品也装不下) for(int b=0;b<c;b++){ //按余数b进行循环 int head=1, tail=1; for(int y=0;y<=(C-b)/c;y++){ //y = j/c(这两个循环加一起也就ci*C/ci=C) int tmp = dp[b+y*c]-y*w; //用队列处理tmp = dp[b + xc] - xw while(head<tail && q[tail-1]<=tmp) tail--; q[tail] = tmp; num[tail++] = y; while(head<tail && y-num[head]>m) head++; //约束条件y-min(mi,y)≤x≤y dp[b+y*c] = max(dp[b+y*c],q[head]+y*w); //计算新的dp[] } } } cout << dp[C] << endl; return 0; }
树上背包¶
-
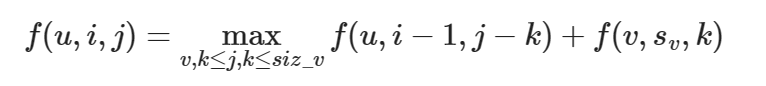
-
在节点u,选取前i个子树,数目为j时的结果
-
c++ void dfs(vector<vector<int>>&dp,int n,vector<int>&sum){ if(tree[n].children.empty()){//叶节点初始化 dp[n][1]=tree[n].money; dp[n][0]=0; sum[n]=1; return; } dp[n][0]=0;//对于要求严格满足容量等于的要初始化为不可能取到的数,在搜索到时对可能的情况进行初始化 for(int a:tree[n].children){ dfs(dp,a,sum); sum[n]+=sum[a];//逐步加,作为优化 for(int i=sum[n];i>0;i--){ for(int j=1;j<=min(i,sum[a]);j++){//通常用子树的大小来限制循环的范围,实现复杂度的降低 if(dp[n][i-j]==INT_MIN||dp[a][j]==INT_MIN)continue;//不可访问 dp[n][i]=max(dp[n][i],dp[n][i-j]+dp[a][j]-tree[a].cost); } } } }
状压dp¶
位运算¶
-
a&(a-1)把最后一个1变为0 -
a&(-a)只保留最后一个1,其余变成0(记为lowbit) -
枚举A的子集
-
c++ for(subset = (A - 1) & A; subset != A; subset = (subset - 1) & A) { ... }
博弈dp¶
模板¶
...dp...//存储结果
bool canWin(string currentState) {
if(...)//特殊情况判断
return...;
return dfs(currentState,1);//记忆化搜索
}
bool dfs(string s,int n)
{
if(...)//访问过,直接返回
return dp[s];
if(...)//游戏结束,判断输赢
{
...
return dp[s];
}
bool a=(n%2==0);//对本回合操作者讨论
for(;;)
{
if(n%2)
{
if(a)//剪枝
break;
a|=dfs(temp,n+1);//本回合是我的回合//有选择我能赢
}
else
{
if(!a)//剪枝
break;
a&=dfs(temp,n+1);//本回合是对手回合//他选什么我都能赢
}
}
dp[s]=a;
return dp[s];
}
前缀和与差分¶
二维前缀和¶
模板¶
//生成
vector<vector<int>>arr(mat.size()+1,vector<int>(mat[0].size()+1));
for(int i=1;i<=mat.size();i++)
{
for(int j=1;j<=mat[0].size();j++)
arr[i][j]=arr[i-1][j]+arr[i][j-1]+mat[i-1][j-1]-arr[i-1][j-1];
}
//查询
int getnum(vector<vector<int>>&arr,int x1,int y1,int x2,int y2)
{
return arr[x2+1][y2+1]-arr[x2+1][y1]-arr[x1][y2+1]+arr[x1][y1];
}
二维差分¶
- 查询时通过前缀和还原
模板¶
# 生成差分
state[r1][c1] += 1
state[r1][c2 + 1] -= 1
state[r2 + 1][c1] -= 1
state[r2 + 1][c2 + 1] += 1
# 前缀还原
for i in range(1, len(state) - 1):
for j in range(1, len(state[0]) - 1):
state[i][j] += state[i][j - 1] + state[i - 1][j] - state[i - 1][j - 1]
三维差分¶
D[num(x1[i], y1[i], z1[i])] += d[i];
D[num(x2[i]+1,y1[i], z1[i])] -= d[i];
D[num(x1[i], y1[i], z2[i]+1)] -= d[i];
D[num(x2[i]+1,y1[i], z2[i]+1)] += d[i];
D[num(x1[i], y2[i]+1,z1[i])] -= d[i];
D[num(x2[i]+1,y2[i]+1,z1[i])] += d[i];
D[num(x1[i], y2[i]+1,z2[i]+1)] += d[i];
D[num(x2[i]+1,y2[i]+1,z2[i]+1)] -= d[i];
- 还原
for (int i=1; i<=A; i++)
for (int j=1; j<=B; j++)
for (int k=1; k<C; k++) //把x、y看成定值,累加z方向
D[num(i,j,k+1)] += D[num(i,j,k)];
for (int i=1; i<=A; i++)
for (int k=1; k<=C; k++)
for (int j=1; j<B; j++) //把x、z看成定值,累加y方向
D[num(i,j+1,k)] += D[num(i,j,k)];
for (int j=1; j<=B; j++)
for (int k=1; k<=C; k++)
for (int i=1; i<A; i++) //把y、z看成定值,累加x方向
D[num(i+1,j,k)] += D[num(i,j,k)];
数据结构¶
树状数组¶
应用¶
单点修改,查询全局第k小¶
- 存储格式:第k的元素的数目
- [1,3,2,4,4,3]->[1,1,2,2]
- \(O(logn)\)
// 权值树状数组查询第 k 小
int kth(int k) {
int sum = 0, x = 0;
for (int i = log2(n); ~i; --i) {
x += 1 << i; // 尝试扩展
if (x >= n || sum + t[x] >= k) // 如果扩展失败
x -= 1 << i;
else
sum += t[x];
}
return x + 1;
}
逆序对¶
- 思想与第k大的元素类似,从后向前遍历,维护元素数目,前缀和就是对于当前元素的逆序对数目
int query(int x) {
int ret = 0;
while (x) {
ret += tree[x];
x -= lowbit(x);
}
return ret;
}
for (int i = n - 1; i >= 0; --i) {
ans += bit.query(nums[i] - 1);//统计前缀和
bit.update(nums[i]);//更新
}
区间最值¶
- \(O(log^2n)\)
7int getmax(int l, int r) {
int ans = 0;
while (r >= l) {
ans = max(ans, a[r]);
--r;
for (; r - lowbit(r) >= l; r -= lowbit(r)) {
// 注意,循环条件不要写成 r - lowbit(r) + 1 >= l
// 否则 l = 1 时,r 跳到 0 会死循环
ans = max(ans, C[r]);
}
}
return ans;
}
void update(int x, int v) {
a[x] = v;
for (int i = x; i <= n; i += lowbit(i)) {
// 枚举受影响的区间
C[i] = a[i];
for (int j = 1; j < lowbit(i); j *= 2) {
C[i] = max(C[i], C[i - j]);
}
}
}
模板¶
- 基础模板
int n;
int a[1005],c[1005]; //对应原数组和树状数组(树状数组大小与原数组一致,要求下标从1开始)
int lowbit(int x){
return x&(-x);
}
void updata(int i,int k){ //在i位置加上k(是变化量)
while(i <= n){
c[i] += k;
i += lowbit(i);
}
}
int getsum(int i){ //求A[1 - i]的和
int res = 0;
while(i > 0){
res += c[i];
i -= lowbit(i);
}
return res;
}
- 区间更新,单点查询:使用差分操作替换更改即可
- 区间更新,区间查询:双树状数组维护
int n,m;
int a[50005] = {0};
int sum1[50005]; //(D[1] + D[2] + ... + D[n])
int sum2[50005]; //(1*D[1] + 2*D[2] + ... + n*D[n])
int lowbit(int x){
return x&(-x);
}
void updata(int i,int k){
int x = i; //因为x不变,所以得先保存i值
while(i <= n){
sum1[i] += k;
sum2[i] += k * (x-1);
i += lowbit(i);
}
}
int getsum(int i){ //求前缀和
int res = 0, x = i;
while(i > 0){
res += x * sum1[i] - sum2[i];
i -= lowbit(i);
}
return res;
}
int main(){
cin>>n;
for(int i = 1; i <= n; i++){
cin>>a[i];
updata(i,a[i] - a[i-1]); //输入初值的时候,也相当于更新了值
}
//[x,y]区间内加上k
updata(x,k); //A[x] - A[x-1]增加k
updata(y+1,-k); //A[y+1] - A[y]减少k
//求[x,y]区间和
int sum = getsum(y) - getsum(x-1);
return 0;
}
- 二维树状数组
#include<bits/stdc++.h>
using namespace std;
const int N = 2050;
int t1[N][N],t2[N][N],t3[N][N],t4[N][N];
#define lowbit(x) ((x) & - (x))
int n,m;
void update(int x,int y,int d){
for(int i=x;i<=n;i+=lowbit(i))
for(int j=y;j<=m;j+=lowbit(j)){
t1[i][j] += d; t2[i][j] += x*d;
t3[i][j] += y*d; t4[i][j] += x*y*d;
}
}
int sum(int x,int y){
int ans = 0;
for(int i=x;i>0;i-=lowbit(i))
for(int j=y;j>0;j-=lowbit(j))
ans += (x+1)*(y+1)*t1[i][j] - (y+1)*t2[i][j] - (x+1)*t3[i][j] + t4[i][j];
return ans;
}
int main(){
char ch[2]; scanf("%s",ch);
scanf("%d%d",&n,&m);
while(scanf("%s",ch)!=EOF){
int a,b,c,d,delta; scanf("%d%d%d%d",&a,&b,&c,&d);
if(ch[0]=='L'){
scanf("%d",&delta);
update(a, b, delta); update(c+1,d+1, delta);
update(a, d+1,-delta); update(c+1,b, -delta);
}
else printf("%d\n",sum(c,d)+sum(a-1,b-1)-sum(a-1,d)-sum(c,b-1));
}
return 0;
}
线段树¶
- 一般来说使用静态数组实现二叉树结构,开四倍元素数目数组
- 多种操作
- 加乘赋值,查询和平方立方
- 打3种标记
- change使得add和multi失效
- multi使得add*multi
- down时按照change->multi->add
- 平方与立方和维护三个sum数组
- (a+c)2=a2+c2+2ac:sum2[new]=sum2[old]+(R-L+1)c2+2sum1[old]*c
- (a+c)3=a3+c3+3c(a2+ac):sum3[new]=sum3[old]+(R-L+1)c3+3c(sum2[old]+sum1[old]*c)
吉如一线段树¶
-
进行操作:将[L,R]内 ai替换为min(ai,x)
-
query支持获取区间最大值以及区间和,需要将最值操作与区间和联系起来
-
使用4个tag:区间和sum、区间最大值ma、严格次大值se、最大值个数num
-
更新
-
ma<=x:无需修改
-
se<x<ma:修改只影响最大值,sum-=num(ma-x),ma=x
-
se>=x无法直接修改,递归左右子
-
这么做是为了减少向下push的次数,se起到了类似剪枝的作用
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 1e6 + 10;
ll sum[N<<2], ma[N<<2], se[N<<2], num[N<<2]; //num:区间的最大值个数
ll ls(ll p){ return p<<1; }
ll rs(ll p){ return p<<1|1;}
void pushup(int p) { //从下往上传递
sum[p] = sum[ls(p)] + sum[rs(p)]; //传递区间和
ma[p] = max(ma[ls(p)], ma[rs(p)]); //传递区间最大值
if (ma[ls(p)] == ma[rs(p)]) { //对tag进行更新
se[p] = max(se[ls(p)], se[rs(p)]);
num[p] = num[ls(p)] + num[rs(p)];
}
else {
se[p] = max(se[ls(p)],se[rs(p)]);
se[p] = max(se[p],min(ma[ls(p)], ma[rs(p)]));
num[p] = ma[ls(p)] > ma[rs(p)] ? num[ls(p)] : num[rs(p)];
}
}
void build(int p, int pl, int pr) {
if (pl == pr) { //叶子
scanf("%lld", &sum[p]);
ma[p] = sum[p]; se[p] = -1; num[p] = 1;
return;
}
ll mid = (pl+pr) >> 1;
build(ls(p),pl,mid);
build(rs(p),mid+1,pr);
pushup(p);
}
void addtag(int p, int x) {
if (x >= ma[p]) return;
sum[p] -= num[p] * (ma[p] - x);
ma[p] = x;
}
void pushdown(int p) {
addtag(ls(p), ma[p]); //把标记传给左子树
addtag(rs(p), ma[p]); //把标记传给左子树
}
void update(int L, int R, int p, int pl, int pr, int x) {
if (x >= ma[p]) return; //情况(1)
if (L<=pl && pr<=R && se[p] < x) { addtag(p, x); return;} //情况(2) //情况(3)
pushdown(p);
ll mid = (pl+pr) >> 1;
if (L<=mid) update(L, R, ls(p), pl, mid, x);
if (R>mid) update(L, R, rs(p), mid+1, pr, x);
pushup(p);
}
int queryMax(int L, int R, int p, int pl, int pr) {
if (pl>=L && R >= pr) return ma[p];
pushdown(p);
int res = 0;
ll mid = (pl+pr) >> 1;
if (L<=mid) res = queryMax(L, R, ls(p), pl, mid);
if (R>mid) res = max(res, queryMax(L, R, rs(p), mid+1, pr));
return res;
}
ll querySum(int L, int R, int p, int pl, int pr) {
if (L <= pl && R >= pr) return sum[p];
pushdown(p);
ll res = 0;
ll mid = (pl+pr) >> 1;
if (L<=mid) res += querySum(L, R, ls(p), pl, mid);
if (R>mid) res += querySum(L, R, rs(p), mid+1, pr);
return res;
}
int main(){
int T; scanf("%d", &T);
while (T--) {
int n,m; scanf("%d%d", &n, &m);
build(1, 1, n);
while (m--) {
int q, L, R, x; scanf("%d%d%d", &q, &L, &R);
if (q == 0){ scanf("%d", &x); update(L, R, 1, 1, n, x);}
if (q == 1) printf("%d\n", queryMax(L, R, 1, 1, n));
if (q == 2) printf("%lld\n", querySum(L, R, 1, 1, n));
}
}
return 0;
}
扫描线¶
面积问题¶
-
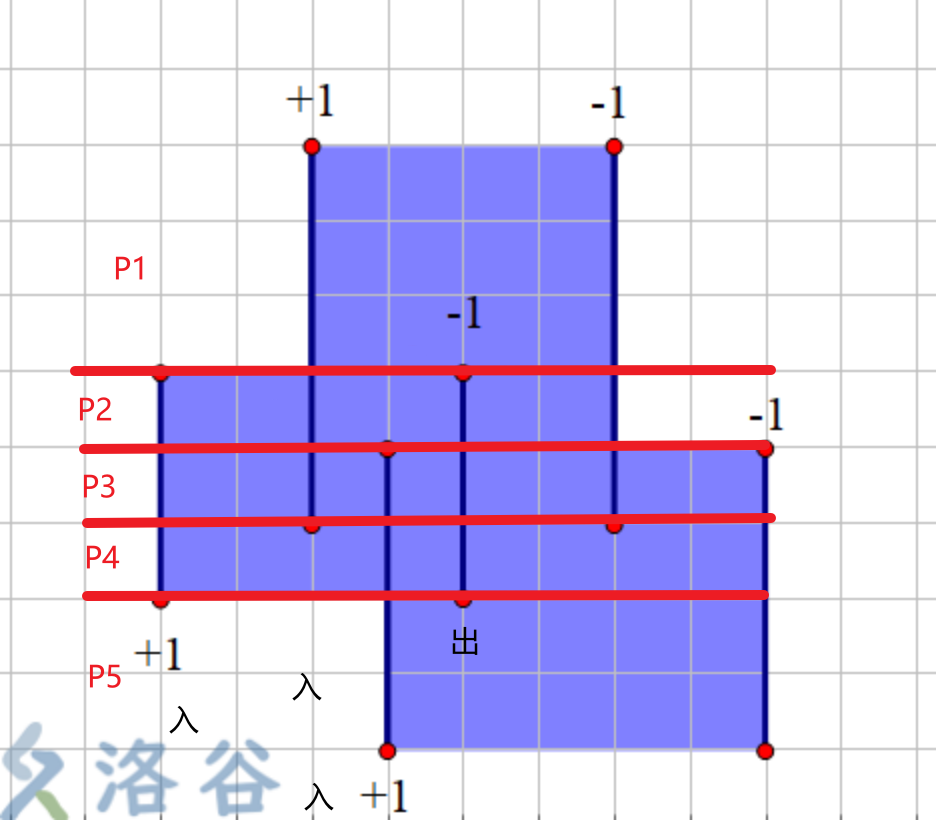
-
算法的基本过程:(与上面这个图差90度)
-
读取矩形,记录入边和出边
-
将所有边按照y进行排序,确定扫描的顺序
-
对x轴做离散化
-
按照从低到高的顺序,用每条扫描线的线段更新线段树,每个节点的值是这层扫描新确定的新矩形面积
-
对所有矩形求和
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef unsigned long long ull;
template<typename T>
inline void read(T &a)
{
T s = 0, w = 1;
char c = getchar();
while(c < '0' || c > '9')
{
if(c == '-') w = -1;
c = getchar();
}
while(c >= '0' && c <= '9')
{
s = (s << 1) + (s << 3) + (c ^ 48);
c = getchar();
}
a = s*w;
}
int ls(int p){ return p<<1;}
int rs(int p){ return p<<1|1;}
const int N =1e6;
int Tag[N];
ll length[N];
int xx[N];
//存储扫描线
struct ScanLine{
ll y;
ll right_x,left_x;
int inout;//入边/出边
ScanLine(){}
ScanLine(ll y,ll left_x,ll right_x,int inout):y(y),right_x(right_x),left_x(left_x),inout(inout){}
bool operator < (const ScanLine &a) const{
return y<a.y;
}
}line[N];
void pushup(int p,int pl,int pr){
if(Tag[p]) length[p] = xx[pr]-xx[pl];//目前还没出,直接用
else if(pl+1 == pr) length[p] = 0;//叶节点
else length[p] = length[ls(p)]+length[rs(p)];
}
void update(int l,int r,int io,int p,int pl,int pr){
if(l<=pl && pr<=r){
Tag[p] += io;
pushup(p,pl,pr);
return;
}
if(pl+1 == pr) return; //避免无限递归
int mid = (pl+pr)>>1;
if(l<=mid) update(l,r,io,ls(p),pl,mid);
if(r>mid) update(l,r,io,rs(p),mid,pr);//注意不是mid+1
pushup(p,pl,pr);
}
int main(){
int n,cnt=0;
read(n);
//存储线,以及x用于离散化
for(int i=0;i<n;i++){
int x1,x2,y1,y2;
cin>>x1>>y1>>x2>>y2;
line[++cnt] = ScanLine(y1,x1,x2,1);
xx[cnt]=x1;
line[++cnt] = ScanLine(y2,x1,x2,-1);
xx[cnt]=x2;
}
sort(xx+1,xx+1+cnt);
//按照y进行排序
sort(line+1,line+1+cnt);
int num=unique(xx+1,xx+1+cnt)-xx-1;
ll ans=0;
//对每一段进行计算、更新
for(int i=1;i<=cnt;i++){
int l,r;
//计算当前段
ans += length[1]*(line[i].y-line[i-1].y);
//离散化找端点
l = lower_bound(xx+1,xx+1+num,line[i].left_x)-xx;
r = lower_bound(xx+1,xx+1+num,line[i].right_x)-xx;
//区间入边/出边更新
update(l,r,line[i].inout,1,1,num);
}
cout<<ans<<endl;
return 0;
}
周长问题¶
#include<bits/stdc++.h>
using namespace std;
int ls(int p){ return p<<1; }
int rs(int p){ return p<<1|1;}
const int N = 200005;
struct ScanLine {
int l, r, h, inout; //inout=1 下边, inout=-1 上边
ScanLine() {}
ScanLine(int a, int b, int c, int d) :l(a), r(b), h(c), inout(d) {}
}line[N];
bool cmp(ScanLine &a, ScanLine &b) { return a.h<b.h; } //y坐标排序
bool lbd[N<<2], rbd[N<<2]; //标记这个结点的左右两个端点是否被覆盖(0表示没有,1表示有)
int num[N << 2]; //这个区间有多少条独立的边
int Tag[N << 2]; //标记这个结点是否有效
int length[N << 2]; //这个区间的有效宽度
void pushup(int p, int pl, int pr) {
if (Tag[p]) { //结点的Tag为正,这个线段对计算宽度有效
lbd[p] = rbd[p] = 1;
length[p] = pr - pl + 1;
num[p] = 1; //每条边有两个端点
}
else if (pl == pr) length[p]=num[p]=lbd[p]=rbd[p]=0;//叶子结点
else {
lbd[p] = lbd[ls(p)]; //和左儿子共左端点
rbd[p] = rbd[rs(p)]; //和右儿子共右端点
length[p] = length[ls(p)] + length[rs(p)];
num[p] = num[ls(p)] + num[rs(p)];
if (lbd[rs(p)] && rbd[ls(p)]) num[p] -= 1; //合并边
}
}
void update(int L, int R, int io, int p, int pl, int pr) {
if(L<=pl && pr<=R){ //完全覆盖
Tag[p] += io;
pushup(p, pl, pr);
return;
}
int mid = (pl + pr) >> 1;
if (L<= mid) update(L, R, io, ls(p), pl, mid);
if (mid < R) update(L, R, io, rs(p), mid+1, pr);
pushup(p, pl, pr);
}
int main() {
int n;
while (~scanf("%d", &n)) {
int cnt = 0;
int lbd = 10000, rbd = -10000;
for (int i = 0; i < n; i++) {
int x1,y1,x2,y2; scanf("%d%d%d%d", &x1,&y1,&x2,&y2); //输入矩形
lbd = min(lbd, x1); //横线最小x坐标
rbd = max(rbd, x2); //横线最大x坐标
line[++cnt] = ScanLine(x1, x2, y1, 1); //给入边赋值
line[++cnt] = ScanLine(x1, x2, y2, -1); //给出边赋值
}
sort(line+1, line + cnt+1, cmp); //排序。数据小,不用离散化
int ans = 0, last = 0; //last:上一次总区间被覆盖长度
for (int i = 1; i <= cnt ; i++){ //扫描所有入边和出边
if (line[i].l < line[i].r)
update(line[i].l, line[i].r-1, line[i].inout, 1, lbd, rbd-1);
ans += num[1]*2 * (line[i + 1].h - line[i].h); //竖线
ans += abs(length[1] - last); //横线
last = length[1];
}
printf("%d\n", ans);
}
return 0;
}
模板¶
- 区间和、加法
#include<bits/stdc++.h>
using namespace std;
#define ll long long
const int N = 1e5 + 10;
ll a[N]; //记录数列的元素,从a[1]开始
ll tree[N<<2]; //tree[i]:第i个结点的值,表示一个线段区间的值,例如最值、区间和
ll tag[N<<2]; //tag[i]:第i个结点的lazy-tag,统一记录这个区间的修改
ll ls(ll p){ return p<<1; } //定位左儿子:p*2
ll rs(ll p){ return p<<1|1;} //定位右儿子:p*2 + 1
void push_up(ll p){ //从下往上传递区间值
tree[p] = tree[ls(p)] + tree[rs(p)];
//本题是区间和。如果求最小值,改为:tree[p] = min(tree[ls(p)], tree[rs(p)]);
}//参数中的pl,pr表示节点对应的线段范围
void build(ll p,ll pl,ll pr){ //建树。p是结点编号,它指向区间[pl, pr]
tag[p] = 0; //lazy-tag标记
if(pl==pr){tree[p]=a[pl]; return;} //最底层的叶子,赋值
ll mid = (pl+pr) >> 1; //分治:折半
build(ls(p),pl,mid); //左儿子
build(rs(p),mid+1,pr); //右儿子
push_up(p); //从下往上传递区间值
}
void addtag(ll p,ll pl,ll pr,ll d){ //给结点p打tag标记,并更新tree
tag[p] += d; //打上tag标记
//限制更新父节点,对子树懒更新
tree[p] += d*(pr-pl+1); //计算新的tree
}
void push_down(ll p,ll pl,ll pr){ //不能覆盖时,把tag传给子树
if(tag[p]){ //有tag标记,这是以前做区间修改时留下的
ll mid = (pl+pr)>>1;
addtag(ls(p),pl,mid,tag[p]); //把tag标记传给左子树
addtag(rs(p),mid+1,pr,tag[p]); //把tag标记传给右子树
tag[p]=0; //p自己的tag被传走了,归0
}
}
void update(ll L,ll R,ll p,ll pl,ll pr,ll d){ //区间修改:把[L, R]内每个元素加上d,p为当前节点,plpr为其子树范围
if(L<=pl && pr<=R){ //完全覆盖,直接返回这个结点,它的子树不用再深入了
addtag(p, pl, pr,d); //给结点p打tag标记,下一次区间修改到p时会用到
return;
}
push_down(p,pl,pr); //如果不能覆盖,把tag传给子树(如果需要的话)
ll mid=(pl+pr)>>1;
if(L<=mid) update(L,R,ls(p),pl,mid,d); //递归左子树
if(R>mid) update(L,R,rs(p),mid+1,pr,d); //递归右子树
push_up(p); //更新(下层更新了,上层要保证最新)
}
ll query(ll L,ll R,ll p,ll pl,ll pr){
//查询区间[L,R];p是当前结点(线段)的编号,[pl,pr]是结点p表示的线段区间
if(pl>=L && R >= pr) return tree[p]; //完全覆盖,直接返回
push_down(p,pl,pr); //不能覆盖,递归子树(要先pushdown保证子树的值为真实值)
ll res=0;
ll mid = (pl+pr)>>1;
if(L<=mid) res+=query(L,R,ls(p),pl,mid); //左子结点有重叠
if(R>mid) res+=query(L,R,rs(p),mid+1,pr); //右子结点有重叠
return res;
}
int main(){
ll n, m; scanf("%lld%lld",&n,&m);
for(ll i=1;i<=n;i++) scanf("%lld",&a[i]);
build(1,1,n); //建树
while(m--){
ll q,L,R,d; scanf("%lld",&q);
if (q==1){ //区间修改:把[L,R]的每个元素加上d
scanf("%lld%lld%lld",&L,&R,&d);
update(L,R,1,1,n,d);
}
else { //区间询问:[L,R]的区间和
scanf("%lld%lld",&L,&R);
printf("%lld\n",query(L,R,1,1,n));
}
}
return 0;
}
珂朵莉树¶
-
注意开启c++14
-
```c++ struct Node_t { int l, r; mutable int v; Node_t(const int &il, const int &ir, const int &iv) : l(il), r(ir), v(iv) {} bool operator<(const Node_t &o) const { return l < o.l; } }; set
odt; auto split(int x) { if (x > n) return odt.end(); auto it = --odt.upper_bound(Node_t{x, 0, 0}); if (it->l == x) return it; int l = it->l, r = it->r, v = it->v; odt.erase(it);//分裂区间 odt.insert(Node_t(l, x - 1, v)); return odt.insert(Node_t(x, r, v)).first; }
void assign(int l, int r, int v) { auto itr = split(r + 1), itl = split(l); odt.erase(itl, itr); odt.insert(Node_t(l, r, v)); }
void performance(int l, int r) { auto itr = split(r + 1), itl = split(l); for (; itl != itr; ++itl) { // Perform Operations here //此处直接对v进行操作,因此上面设置为mutable //无论是赋值还是查询都直接进行 } } //使用 odt.insert(Node_t(1, n, 1)); ```
平衡搜索树¶
Treap树¶
c++ #include<bits/stdc++.h> using namespace std; const int M=1e6+10; int cnt = 0; //t[cnt]: 最新结点的存储位置 struct Node{ int ls,rs; //左右儿子 int key,pri; // key:键值;pri:随机的优先级 int size; //当前结点为根的子树的结点数量,用于求第k大和rank }t[M]; //tree[],存树 void newNode(int x){ //初始化一个新结点 cnt++; //从t[1]开始存储结点,t[0]被放弃。若子结点是0,表示没有子结点 t[cnt].size = 1; t[cnt].ls = t[cnt].rs = 0; //0表示没有子结点 t[cnt].key = x; //key: 键值 t[cnt].pri = rand(); //pri:随机产生,优先级(利用随机维护平衡) } void Update(int u){ //更新以u为根的子树的size t[u].size = t[t[u].ls].size + t[t[u].rs].size+1; } void rotate(int &o,int d){ //旋转,参考图示理解。 d=0右旋,d=1左旋 int k; if(d==1) { //左旋,把o的右儿子k旋到根部 k=t[o].rs; t[o].rs=t[k].ls;//图中的x t[k].ls=o; } else { //右旋,把o的左儿子k旋到根部 k=t[o].ls; t[o].ls=t[k].rs; //图中的x t[k].rs=o; } t[k].size=t[o].size; Update(o); o=k; //新的根是k } void Insert(int &u,int x){ if(u==0){newNode(x);u=cnt;return;} //递归到了一个空叶子,新建结点 t[u].size++; if(x>=t[u].key) Insert(t[u].rs,x); //递归右子树找空叶子,直到插入 else Insert(t[u].ls,x); //递归左子树找空叶子,直到插入 if(t[u].ls!=0 && t[u].pri<t[t[u].ls].pri) rotate(u,0); if(t[u].rs!=0 && t[u].pri<t[t[u].rs].pri) rotate(u,1); Update(u); } void Del(int &u,int x){ t[u].size--; if(t[u].key==x){ if(t[u].ls==0&&t[u].rs==0){u=0; return;} if(t[u].ls==0||t[u].rs==0){u=t[u].ls+t[u].rs; return;} if(t[t[u].ls].pri < t[t[u].rs].pri) { rotate(u,0); Del(t[u].rs, x); return;} else{ rotate(u,1); Del(t[u].ls, x); return;} } if(t[u].key>=x) Del(t[u].ls,x); else Del(t[u].rs,x); Update(u); } int Rank(int u,int x){ //排名,x是第几名 if(u==0) return 0; if(x>t[u].key) return t[t[u].ls].size+1+Rank(t[u].rs, x); return Rank(t[u].ls,x); } int kth(int u,int k){ //第k大数是几? if(k==t[t[u].ls].size+1) return t[u].key; //这个数为根 if(k> t[t[u].ls].size+1) return kth(t[u].rs,k-t[t[u].ls].size-1);//右子树 if(k<=t[t[u].ls].size) kth(t[u].ls,k); //左子树 } //可能存在相同元素,因此复杂 int Precursor(int u,int x){//即小的中最大的 if(u==0) return 0; if(t[u].key>=x) return Precursor(t[u].ls,x);//第一个小于的元素 int tmp = Precursor(t[u].rs,x); if(tmp==0) return t[u].key; return tmp; } int Successor(int u,int x){ if(u==0) return 0; if(t[u].key<=x) return Successor(t[u].rs,x); int tmp = Successor(t[u].ls,x); if(tmp==0) return t[u].key; return tmp; } int main(){ srand(time(NULL)); int root = 0; //root是整棵树的树根,0表示初始为空 int n; cin>>n; while(n--){ int opt,x; cin >> opt >> x; switch (opt){ case 1: Insert(root,x); break; case 2: Del(root,x); break; case 3: printf("%d\n",Rank(root,x)+1); break; case 4: printf("%d\n",kth(root,x)); break; case 5: printf("%d\n",Precursor(root,x)); break; case 6: printf("%d\n",Successor(root,x)); break; } } return 0; }
ST¶
-
查询静态数组内区间的最值
-
\(O(nlogn)\)时间预处理,\(O(1)\)时间完成查询
-
cpp void st_init(){ for(int i=1;i<=n;i++){ //初始化区间长度为1时的值 dp_min[i][0] = a[i]; dp_max[i][0] = a[i]; } int p=log2(n);//可倍增区间的最大次方: 2^p <= n for(int k=1;k<=p;k++) //倍增计算小区间。先算小区间,再算大区间,逐步递推 for(int s=1;s+(1<<k)<=n+1;s++){ dp_max[s][k]=max(dp_max[s][k-1], dp_max[s+(1<<(k-1))][k-1]); dp_min[s][k]=min(dp_min[s][k-1], dp_min[s+(1<<(k-1))][k-1]); } } int st_query(int L,int R){ int k = log2(R-L+1); int x = max(dp_max[L][k],dp_max[R-(1<<k)+1][k]); //区间最大 int y = min(dp_min[L][k],dp_min[R-(1<<k)+1][k]); //区间最小 return... }
字典树¶
模板¶
class Trie {
public:
Trie() {
root=new TreeNode;
}
void insert(string word) {
TreeNode*p=root;
for(auto a:word)
{
if(p->child[a-'a']==nullptr)
p->child[a-'a']=new TreeNode;
p=p->child[a-'a'];
}
p->check=true;//标记结尾
}
bool search(string word) {
TreeNode*p=root;
for(auto a:word)
{
if(p->child[a-'a']==nullptr)
return false;
p=p->child[a-'a'];
}
return p->check;//查找单词要求必须是结尾
}
bool startsWith(string prefix) {
TreeNode*p=root;
for(auto a:prefix)
{
if(p->child[a-'a']==nullptr)
return false;
p=p->child[a-'a'];
}
return true;//查找前缀不要求结束节点一定可以作为结尾
}
private:
struct TreeNode{
TreeNode(){
for(auto &a:child)
a=nullptr;
check=false;
}
TreeNode*child[26];//也可以使用hash存储
bool check;
};
TreeNode* root;
};
支持删除的优先队列¶
-
使用set或者双队列模拟
-
懒删除,一个队列维护全部元素,另一个维护要删除的队列,由于使用相同的排列顺序,因此要删除的元素优先级相同
-
```c++ template
> class LazyPriorityQueue { private: std::priority_queue // 私有方法,用于清除标记为删除的元素 void cleanTop() { while (!mainQueue.empty() && !deleteQueue.empty() && mainQueue.top() == deleteQueue.top()) { mainQueue.pop(); deleteQueue.pop(); } }
public: void insert(const T& element) { mainQueue.push(element); }
void lazyDelete(const T& element) {
deleteQueue.push(element);
cleanTop(); // 清理主队列顶部的删除元素
}
T top() {
cleanTop(); // 清理主队列顶部的删除元素
if (mainQueue.empty()) {
throw std::runtime_error("Queue is empty.");
}
return mainQueue.top();
}
bool isEmpty() const {
return mainQueue.empty() && deleteQueue.empty();
}
}; ```
单调队列¶
for(int i=1;i<arr.size();i++)
{
while(!dq.empty()&&arr[i]-arr[dq.front()]>=k)//队首出队
{
ans=min(ans,i-dq.front());
dq.pop_front();
}
while(!dq.empty()&&arr[i]<=arr[dq.back()])//队尾维护
dq.pop_back();
dq.push_back(i);
}
其他¶
杂项算法¶
实数二分¶
cpp while(right-left>1e-7){ double mid=left+(right-left)/2; if(check(mid))right=mid; else left=mid; }
三分¶
-
用于寻找函数的极值,两个点将函数分成三段,通过比较两的点的大小实现每次舍去1/3的区域
-
cpp while(R-L > eps){ //用for也行 double k =(R-L)/3.0; double mid1 = L+k, mid2 = R-k; if(f(mid1) > f(mid2)) R = mid2; else L = mid1; }
分块算法¶
- 一种较为简单的实现区间/单点修改、查询的方式m次操作\(O(m\sqrt{n})\)
- 块的初始化
int block = sqrt(n);
int t = n/block;
if(n%block) t++;
for(int i=1;i<=t;i++){
st[i]=(i-1)*block+1;
ed[i]=i*block-1
}
//下标从0开始
st[i]=i*block;
ed[i]=min((i+1)*block-1,n-1);
ed[t]=n;//不完整块
for(int i=1;i<=n;i++){
pos[i]=(i-1)/block+1;
}
- 分块维护区间和
void change(int L,int R,int d){
int p=pos[L],q=pos[R];
if(p==q){//特殊情况,位于一块
for(int i=L;i<=R;i++)a[i]+=d;
sum[p]+=d*(R-L+1);
}
else{
for(int i=p+1;i<=q-1;i++)add[i]+=d;//先整块处理
for(int i=L;i<=ed[p];i++)a[i]+=d;//对两端进行碎片处理
sum[p]+=d*(ed[p]-L+1);
for(int i=st[q];i<=R;i++)a[i]+=d;
sum[q]+=d*(R-st[q]+1);
}
}
long long ask(int L,int R){
int p=pos[L],q=pos[R];
long long ans=0;
if(p==q){
for(int i=L;i<=R;i++)ans+=a[i];
ans+=add[p]*(R-L+1);
}
else{
for(int i=p+1;i<=q-1;i++)ans+=sum[i]+add[i]*(ed[i]-st[i]+1);
for(int i=L;i<=ed[p];i++)ans+=a[i];
ans+=add[p]*(ed[p]-L+1);
for(int i=st[q];i<=R;i++)ans+=a[i];
ans+=add[q]*(R-st[q]+1);
}
return ans;
}
莫队算法¶
- 复杂度通常为\(O(n\sqrt n)\)一种离线算法,
- 先把数组分块,然后把查询的区间按左端点所在块号进行排序,块号相同时按右端点进行排序
- 左指针每次的移动范围被限定在一个块内,总共的复杂度为\(O(m\sqrt n)\)
- 右指针在每个块内保持递增,因此总共复杂度为\(O(n\sqrt n)\)
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6;
struct node{ //离线记录查询操作
int L, R, k; //k:查询操作的原始顺序
}q[N];
int pos[N];
int ans[N];
int cnt[N]; //cnt[i]: 统计数字i出现了多少次
int a[N];
bool cmp(node a, node b){
//按块排序,就是莫队算法:
if(pos[a.L] != pos[b.L]) //按L所在的块排序,如果块相等,再按R排序
return pos[a.L] < pos[b.L];
if(pos[a.L] & 1) return a.R > b.R; //奇偶性优化,如果删除这一句,性能差一点
return a.R < b.R;
}
int ANS = 0;
void add(int x){ //扩大区间时(L左移或R右移),增加数x出现的次数
cnt[a[x]]++;
if(cnt[a[x]]==1) ANS++; //这个元素第1次出现
}
void del(int x){ //缩小区间时(L右移或R左移),减少数x出现的次数
cnt[a[x]]--;
if(cnt[a[x]]==0) ANS--; //这个元素消失了
}
int main(){
int n; scanf("%d",&n);
int block = sqrt(n); //每块的大小
for(int i=1;i<=n;i++){
scanf("%d",&a[i]); //读第i个元素
pos[i]=(i-1)/block + 1; //第i个元素所在的块
}
int m; scanf("%d",&m);
for(int i=1;i<=m;i++){ //读取所有m个查询,离线处理
scanf("%d%d",&q[i].L, &q[i].R);
q[i].k = i; //记录查询的原始顺序
}
sort(q+1, q+1+m, cmp); //对所有查询排序
int L=1, R=0; //左右指针的初始值。思考为什么?
for(int i=1;i<=m;i++){
while(L<q[i].L) del(L++); //{del(L); L++;} //缩小区间:L右移
while(R>q[i].R) del(R--); //{del(R); R--;} //缩小区间:R左移
while(L>q[i].L) add(--L); //{L--; add(L);} //扩大区间:L左移
while(R<q[i].R) add(++R); //{R++; add(R);} //扩大区间:R右移
ans[q[i].k] = ANS;
}
for(int i=1;i<=m;i++) printf("%d\n",ans[i]); //按原顺序打印结果
return 0;
}
带修改的莫队¶
- 莫队算法也能处理比较简单的单点修改,时间复杂度为\(O(mn^{\frac 23})\)
- 比如查询区间内元素种类数目基础上加上可以单点修改一个点的种类
- 也是需要进行离线处理,记录查询操作时增加一个值表示查询前进行了多少次修改(L,R,t)
- 现在点的移动就还需要考虑t(1<=t<=m),当两个查询的t不同时需要暴力修改补上变化
- 此时的莫队算法就对应一个立体空间(L,R,t),计算复杂度仍为曼哈顿距离
const int N = 1e6+10;
int pos[N],cnt[N],res=0,p_l=0,p_r=-1,p_t=0,ans[N],a[N];
vector<pair<int,int>>modify;
struct node{
int l,r,t,k;
node(int l,int r,int t,int k):l(l),r(r),t(t),k(k){}
node(){}
bool operator < (const node &a)const{
if(pos[l]!=pos[a.l]) return pos[l]<pos[a.l];
if(pos[r]!=pos[a.r]) return pos[r]<pos[a.r];
return pos[t]<pos[a.t];
}
}q[N];
//注意l与r的区别,l到x但是不包含x,r到x但是r包含x
void movel(int l){
while(p_l<l){
if(cnt[a[p_l]]==1) res--;
cnt[a[p_l]]--;
p_l++;
}
while(p_l>l){
p_l--;
if(cnt[a[p_l]]==0) res++;
cnt[a[p_l]]++;
}
}
void mover(int r){
while(p_r<r){
p_r++;
if(cnt[a[p_r]]==0) res++;
cnt[a[p_r]]++;
}
while(p_r>r){
if(cnt[a[p_r]]==1) res--;
cnt[a[p_r]]--;
p_r--;
}
}
void movet(int t){
//使用非常巧妙的swap,当前的值就是之后再经过这条修改的目的值(因为t一定是顺序往返修改的)
while(p_t<t){
int x=modify[p_t].first;
//在范围内进行调整
if(p_l<=x&&x<=p_r){
if(cnt[a[x]]==1) res--;
cnt[a[x]]--;
swap(a[x],modify[p_t].second);
if(cnt[a[x]]==0) res++;
cnt[a[x]]++;
}
//不在范围内也要对a修改!!!
else
swap(a[x],modify[p_t].second);
p_t++;
}
while(p_t>t){
p_t--;
int x=modify[p_t].first;
if(p_l<=x&&x<=p_r){
if(cnt[a[x]]==1) res--;
cnt[a[x]]--;
swap(a[x],modify[p_t].second);
if(cnt[a[x]]==0) res++;
cnt[a[x]]++;
}
else
swap(a[x],modify[p_t].second);
}
}
int main(){
int n,m,block,cnt=0,mcnt=0;
read(n);read(m);
block=pow(n,2.0/3);
for(int i=0;i<n;i++){
read(a[i]);
}
//预处理分块结果
for(int i=0;i<N;i++)
pos[i]=i/block;
for(int i=0;i<m;i++){
char c[5];
scanf("%s",c);
int x,y;
read(x);read(y);
if(c[0]=='Q'){
q[cnt]=node(x-1,y-1,mcnt,cnt);
cnt++;
}
else{
//对修改计数
mcnt++;
modify.emplace_back(x-1,y);
}
}
//对查询排序
sort(q,q+cnt);
for(int i=0;i<cnt;i++){
int l=q[i].l,r=q[i].r,t=q[i].t;
//调整坐标
movel(l);
mover(r);
movet(t);
ans[q[i].k]=res;
}
//还原结果
for(int i=0;i<cnt;i++)
printf("%d\n",ans[i]);
return 0;
}
宏¶
typedef long long ll;
mt19937 mrand(random_device{}());
const ll mod=998244353;
int rnd(int x) { return mrand() % x;}
stl¶
杂项¶
-
__builtin_popcount()统计1的数目 -
iota(begin,end,n) -
begin,end为迭代器开始和结束的位置,n为起始元素,自动依次++填充
-
万能头文件:
#include <bits/stdc++.h> -
提升cin cout的性能:
ios::sync_with_stdio(false),cin.tie(0),cout.tie(0); -
memset(a,num,sizeof(a)) -
要注意的是num并不能取任意值,通常只能为0、-1、0x3f(接近INT_MAX)
-
使用c++11:
-std=c++11 -
常用头文件(备用)
-
c++ #include<utility> //pair #include <numeric> // For std::gcd -
gcc命令
-
生成可执行文件
gcc demo.o -o demo -O2开启加速-Wall显示警告-fsanitize=address检测程序的内存错误,比如爆栈等问题-fsanitize=undefined检测程序的未定义行为,比如访问空指针,数组越界访问等问题 (有效检查RE)-
生成可调试
-g(注意不要用-O2优化可能导致打断点出现问题) -
gdb调试
-
调试
gdb ./a.out - 断点
b numnum 为行号- 查看断点
info b
- 查看断点
- 启动
r - 查看源码
l - 显示变量
p n - 跟踪
watch n - 单步调试
n -
继续
c -
队列:front、back
-
栈、优先队列top
-
pq:
-
c++ auto compare = [](const int& a, const int& b) { return a > b; }; std::priority_queue<int, std::vector<int>, decltype(compare)> pq(compare); -
vector:
-
resize()、front()
-
fill(val.begin(),val.end(),0); -
自定义哈希
-
c++ struct Line{ int x,y,dic; Line(int x,int y,int dic):x(x),y(y),dic(dic){}; bool operator==(const Line& other) const { return x == other.x && y == other.y && dic == other.dic; } }; namespace std { template <> struct hash<Line> { size_t operator()(const Line& line) const { return ((hash<int>()(line.x) ^ (hash<int>()(line.y) << 1)) >> 1) ^ (hash<int>()(line.dic) << 1);//借助内置的哈希函数使用左右移动以及异或进行组合可以减少哈希冲突 } }; }
算法¶
-
nth_element(begin,n,end,[cmp])注意输入的都是迭代器,函数的功能与partition类似。将第n小的元素放在指定的位置 -
如
nth_element(arr[i].begin(), arr[i].end() - 2, arr[i].end()) -
reverse(begin,end) -
排列
-
获取下一个排列
next_permutation(vec.begin(), vec.end()) -
如果存在下一个更大的排列,函数会修改序列并返回
true;如果这个排列已经是字典序中的最大排列,则它会重排为最小排列(即升序排列)并返回false。 -
去重
-
仅对相邻元素有效。因此,在使用之前,通常需要先对序列进行排序
-
c++ auto newEnd = std::unique(v.begin(), v.end()); v.erase(newEnd, v.end());
数学¶
round()- 这个函数用于四舍五入一个浮点数到最接近的整数。floor()- 将浮点数向下取整到最接近的整数。ceil()- 将浮点数向上取整到最接近的整数。fabs()- 计算一个浮点数的绝对值。sqrt()- 计算一个数的平方根。pow()- 用于计算一个数的指数幂。exp()- 计算自然对数的底数(e)的指数幂。log()- 计算一个数的自然对数(以e为底)。log10()- 计算一个数的以10为底的对数。sin(),cos(),tan()- 分别计算一个角度(以弧度为单位)的正弦、余弦和正切值。asin(),acos(),atan()- 分别计算一个数的反正弦、反余弦和反正切值。fmod()- 计算两个数的浮点余数。hypot()- 计算直角三角形的斜边长度
string¶
substr(起始位置,截取长度)find():返回搜索字符串在目标字符串中第一次出现的位置。如果未找到,则返回string::nposfind_first_of()函数从字符串的开头开始查找指定字符集合中的任意一个字符,并返回第一个匹配字符的位置。如果未找到匹配字符,则返回string::npos。find_last_of()函数从字符串的结尾开始查找指定字符集合中的任意一个字符,并返回最后一个匹配字符的位置。如果未找到匹配字符,则返回string::npos。- 判断数字(
isdigit):isdigit(int ch) - 判断字母(
isalpha):isalpha(int ch) - 判断字母或数字(
isalnum):isalnum(int ch)。 - 判断小写字母(
islower):islower(int ch) - 判断大写字母(
isupper):isupper(int ch)
set/map¶
- 打包为自定义数据结构,自定义比较
- 用prev(),next()实现++--等操作
- 如prev(it,2)可以指定移动的数目
bitset(位运算)¶
-
初始化 :
-
std::bitset<N>创建一个包含N位的位集,初始值为 0。 - 也可以使用字符串或数字进行初始化。
std::bitset<8> b1; // 默认初始化为 00000000
std::bitset<8> b2(42); // 用数字初始化,00010101
std::bitset<8> b3("1100"); // 用字符串初始化,00001100
-
设置和重置位 :
-
set()方法将所有位设置为 1。 set(pos, value)设置特定位置的位。reset()方法将所有位重置为 0。reset(pos)重置特定位置的位。flip()翻转所有位。-
flip(pos)翻转特定位置的位。 -
访问位和测试位 :
-
使用
[]运算符访问特定位。 -
test(pos)检查特定位置的位是否为 1。 -
查询和操作 :
-
count()返回设置为 1 的位的数量。 all()检查是否所有位都设置为 1。any()检查是否至少有一位设置为 1。-
none()检查是否没有位设置为 1。 -
转换 :
-
to_ulong()或to_ullong()将位集转换为无符号长整数。 to_string()将位集转换为字符串。
离散化¶
-
stl实现
-
c++ sort(X,X+num); int m=unique(X,X+num)-X;//离散化 for(int i=0; i<n; i++) { int l=lower_bound(X,X+m,li[i])-X;//寻找位置 int r=lower_bound(X,X+m,ri[i])-X; update(l,r,i,0,m,1); } -
对区间进行离散化时可以如果两个区间之间不是连续的,应该插入额外元素
-
[1,100][200,500]->[1,2][4,5](如区间覆盖问题,本来来没覆盖,变成覆盖了)
- 重完毕后,进行一个处理,如果相邻数字间距大于1的话,在其中加上任意一个数字。这样会把原来的缝隙留出来.
输入输出¶
| 格式字符 | 意义 |
|---|---|
| a, A | 以十六进制形式输出浮点数(C99 新增)。实例 printf("pi=%a\n", 3.14); 输出 pi=0x1.91eb86p+1。 |
| d | 以十进制形式输出带符号整数(正数不输出符号) |
| o | 以八进制形式输出无符号整数(不输出前缀0) |
| x,X | 以十六进制形式输出无符号整数(不输出前缀Ox) |
| u | 以十进制形式输出无符号整数 |
| f | 以小数形式输出单、双精度实数 |
| e,E | 以指数形式输出单、双精度实数 |
| g,G | 以%f或%e中较短的输出宽度输出单、双精度实数 |
| c | 输出单个字符 |
| s | 输出字符串 |
| p | 输出指针地址 |
| lu | 32位无符号整数 |
| llu | 64位无符号整数 |
快读¶
c++ template<typename T> inline void read(T &a) { T s = 0, w = 1; char c = getchar(); while(c < '0' || c > '9') { if(c == '-') w = -1; c = getchar(); } while(c >= '0' && c <= '9') { s = (s << 1) + (s << 3) + (c ^ 48); c = getchar(); } a = s*w; }
getline¶
istream& getline ( istream &is , string &str [, char delim ]);- is常用cin
- delim表示读取到该字符串时停止,默认为
\n回车