多任务¶
- 实现方式
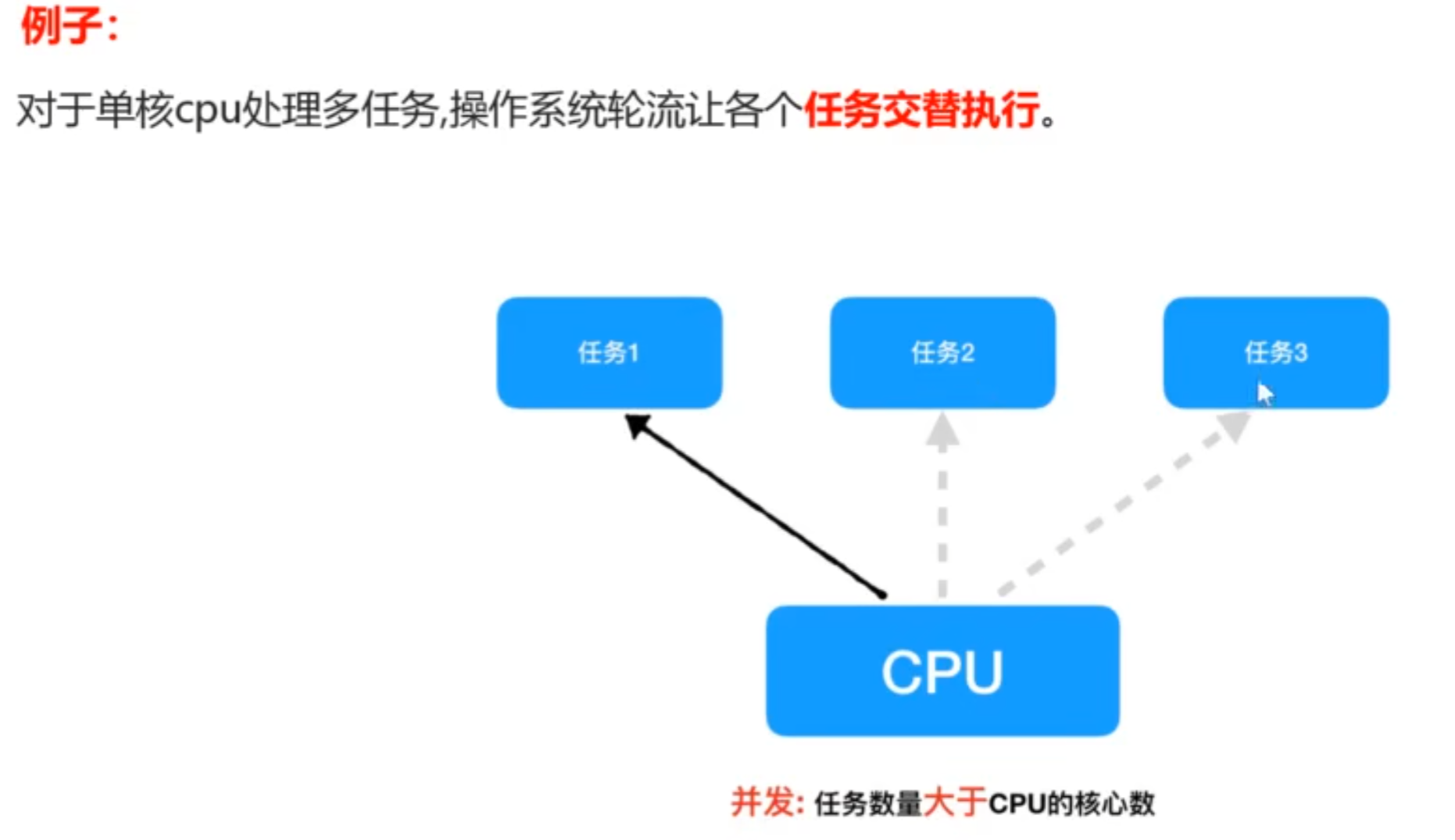
- 并发:
- 在一段时间内交替去执行任务
- 并行
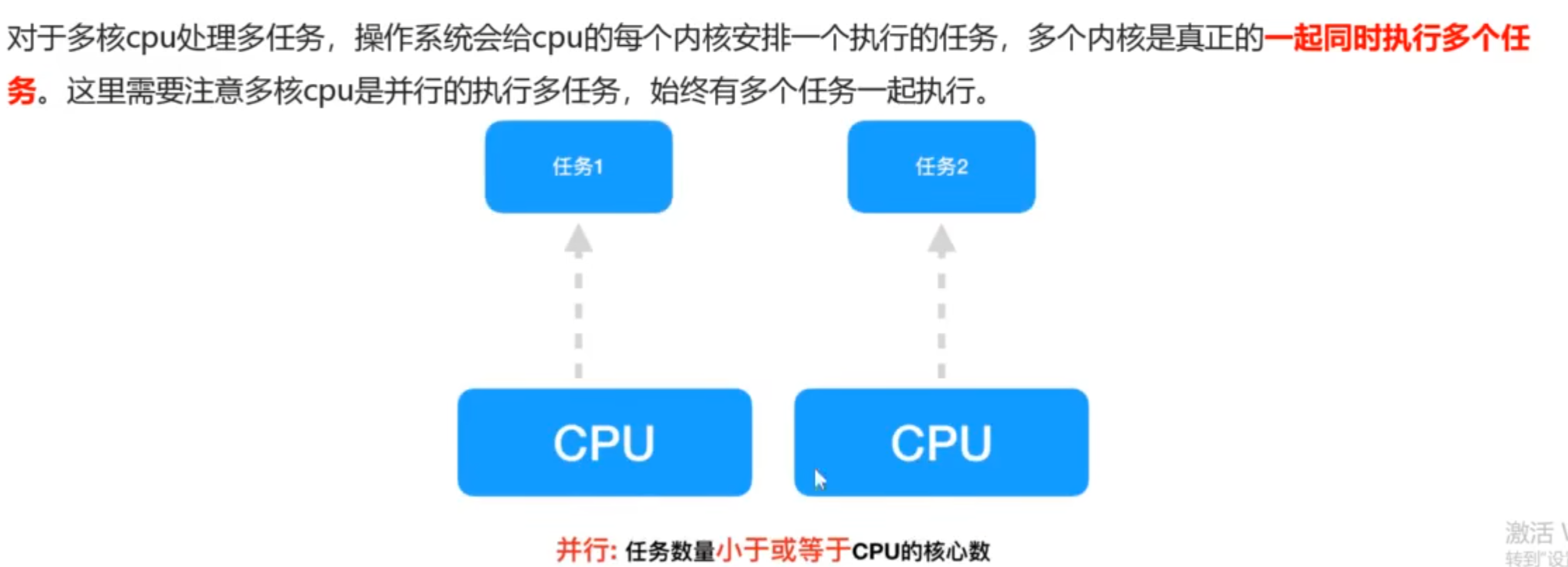
- 同时执行多个任务
多进程¶
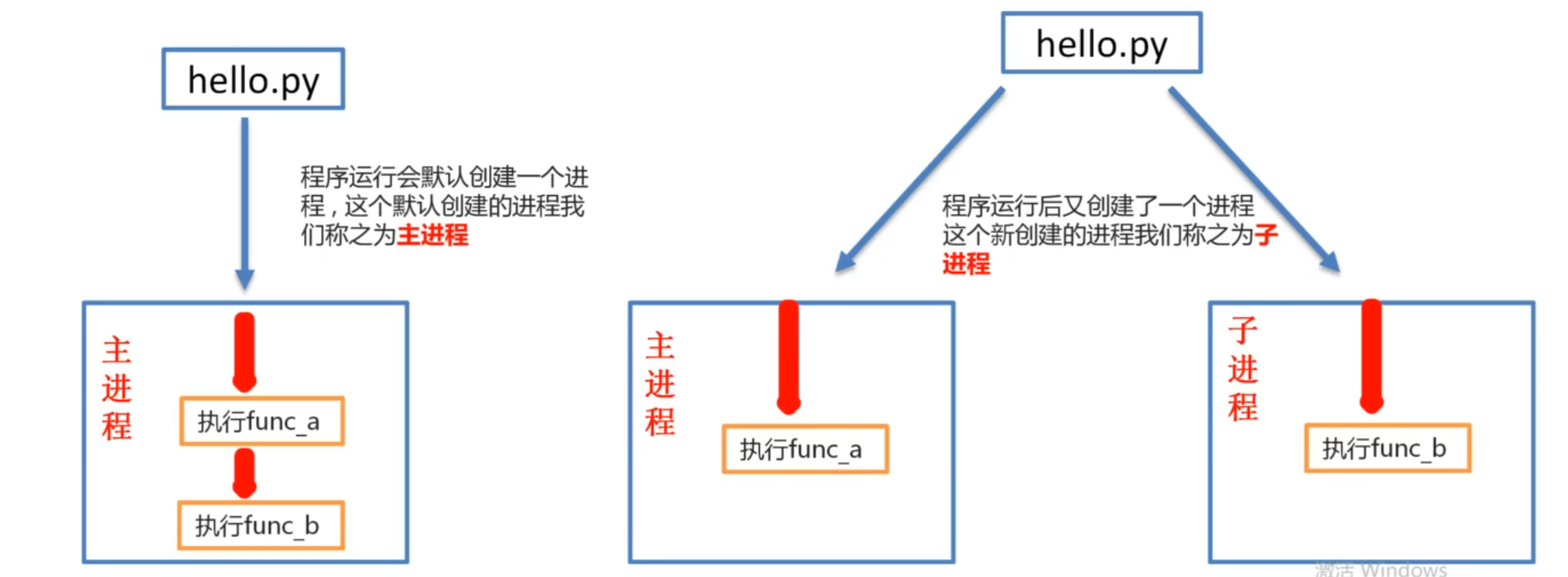
- 进程是资源分配的最小单位,一个运行的程序就是一个进程
- 创建进程
- 引入
import multiprocessing 进程对象=multiprocessing.Process(target,name,group)
- target函数名不需要带括号
- 启动进程
进程对象.start()- 参数传递

- 在创建时指定
Process(target=sing, args=(3,),kwargs={"num":3})(元组中只有一个元素时要在末尾添加,) - 使用字典传递参数时字典中的键一定要与参数的名称一致,元组中的参数则是按照顺序皮欸(字典是按照键)
- 如
def sing(num) - 获取进程编号
- 导入包
import os - 用于区分进程之间的关系
- 获取进程的编号
os.getpid()
- 获取父亲进程的编号
os.getppid()
补充¶
- 主进程会等待所有子进程都结束后再结束
- 如果希望主进程结束时立即结束所有子进程,那么要把子进程设置为守护主进程
进程对象.daemon=True
多线程¶
- 线程是程序执行的最小单位,使用多线程比多进程更加节省资源
- 一个进程可以包括多个线程,共享同一个进程的资源
- 创建
import threading线程对象 = threading.Thread(target=任务名)线程对象.start()join([time]):等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
- 参数传递
-
同样args kargs
-
结束顺序也与进程一致
-
threading.enumerate()返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。 -
自定义线程类
-
使用Threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法:
-
```python import threading import time exitFlag = 0
class myThread (threading.Thread): #继承父类threading.Thread def init(self, threadID, name, counter): threading.Thread.init(self)# 调用父类构造函数 self.threadID = threadID self.name = name self.counter = counter def run(self): #把要执行的代码写到run函数里面 线程在创建后会直接运行run函数 print "Starting " + self.name print_time(self.name, self.counter, 5) print "Exiting " + self.name
def print_time(threadName, delay, counter): while counter: if exitFlag: (threading.Thread).exit() time.sleep(delay) print "%s: %s" % (threadName, time.ctime(time.time())) counter -= 1
创建新线程¶
thread1 = myThread(1, "Thread-1", 1) thread2 = myThread(2, "Thread-2", 2)
开启线程¶
thread1.start() thread2.start()
print "Exiting Main Thread" ```
线程同步(锁)¶
-
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
-
使用Thread对象的Lock和Rlock可以实现简单的线程同步,这两个对象都有acquire方法和release方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到acquire和release方法之间。
-
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
-
过程
-
首先获取锁
lock = threading.Lock() -
使用with控制
python def func(): with lock: # 访问共享资源的代码块
-
手动控制
python def func(): lock.acquire() # 访问共享资源的代码块 lock.release()
线程优先级队列Queuesu¶
- 导入
from queue import Queue - 创建
q = queue.Queue([maxsize=0])可以设置最大容量 - 添加数据
queue.put(item[, block=True, timeout=None]) - block=true时当当前容量等于上限时会阻塞,否则报错
- timeout表示等待一段时间仍没有执行则报错
- 获取数据
queue.get([block=True, timeout=None]) - 如果队列为空,则该语句将被阻塞,直到有数据可供获取。
- 状态
.Empty.Full.qsize()