爬虫
基本流程¶
- 第一步:发起请求。一般是通过 HTTP 库,对目标站点进行请求(request)。等同于自己打开浏览器,输入网址。
- 第二步: 获取响应内容(response)。如果请求的内容存在于服务器上,那么服务器会返回请求的内容,一般为:HTML,二进制文件(视频,音频),文档,Json 字符串等。
- 第三步:解析内容。对于用户而言,就是寻找自己需要的信息。对于 Python 爬虫而言,就是利用正则表达式或者其他库提取目标信息。
- 第四步:保存数据。解析得到的数据可以多种形式,如文本,音频,视频保存在本地。
发起请求获取内容¶
- GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快。
- POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息。
requests¶
-
导入
import requests -
requests是 Python 常用的 HTTP 库,能够以简洁的方式处理网络请求。它提供了各种不同请求方式的接口。 - 获取数据:
res = requests.get(url="http://www.baidu.com/") - 得到一个 response 对象
- 使用post发送时还可以同时发送一些信息
requests.post(url, data={key: value}, json={key: value}, args)- url 请求 url。
- data 参数为要发送到指定 url 的字典、元组列表、字节或文件对象。
- json 参数为要发送到指定 url 的 JSON 对象。
- args 为其他参数,比如 cookies、headers、verify等。
常用属性¶
| Response对象常用属性 | 说明 |
|---|---|
| encoding | 查看或者指定响应字符编码 |
| status_code | 返回HTTP响应码 |
| url | 查看请求的 url 地址 |
| headers | 查看请求头信息 |
| cookies | 查看cookies 信息 |
| text | 以字符串形式输出 |
| content | 以字节流(二进制)形式输出,若要保存下载图片需使用该属性。 |
| json | 返回结果的 JSON 对象 |
- 使用content时还需要对二进制进行阶码
print(reponse.content.decode(encoding='指定解码方式'))避免出现乱码(如果text乱码时使用)
数据处理&信息提取¶
正则表达式¶
BeautifulSoup¶
-
引入
from bs4 import BeautifulSoup -
创建对象:
x=BeautifulSoup('str','编码方式') -
解析器种类
- html.parse- python 自带,但容错性不够高,对于一些写得不太规范的网页会丢失部分内容
- lxml- 解析速度快,需额外安装
- xml- 同属 lxml 库,支持 XML 文档
-
html5lib- 最好的容错性,但速度稍慢
-
获取其中的某个结构化元素及其属性:
-
直接通过标签获取数据
soup.title # title 元素
# <title>The Dormouse's story</title>
soup.p # 第一个 p 元素
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class'] # p 元素的 class 属性
# ['title']
soup.p.b # p 元素下的 b 元素
# <b>The Dormouse's story</b>
soup.p.parent.name # p 元素的父节点的标签
# body
-
find (只找第一个)和 find_all(返回列表) 方法
-

- 由于name是第一个变量,不需要指定
fing('a') - 属性要指出是哪一个属性
find(id='') - 或使用字典
find(attrs={'id':'link'}) - 文本内容
find(text='')
- 由于name是第一个变量,不需要指定
-
返回Tag对象
- name:获取标签的名称
- attrs:获取标签的属性的键和值(列表)
- text:标签内容
-
css选择器
soup.select('html head title')
soup.select('p > #link1')
x:-soup-contains(s)选择具有内容s的标签x(并不一定要是直接内容,可以是子元素包含的内容)- 返回一个ResultSet是一个集合(可以通过下标进行访问,每个元素相当于tag元素)
JSON¶
-
引入
import json -
JSON (JavaScript Object Notation, JS 对象标记) 是一种轻量级的数据交换格式。它基于 ECMAScript (w3c制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
-
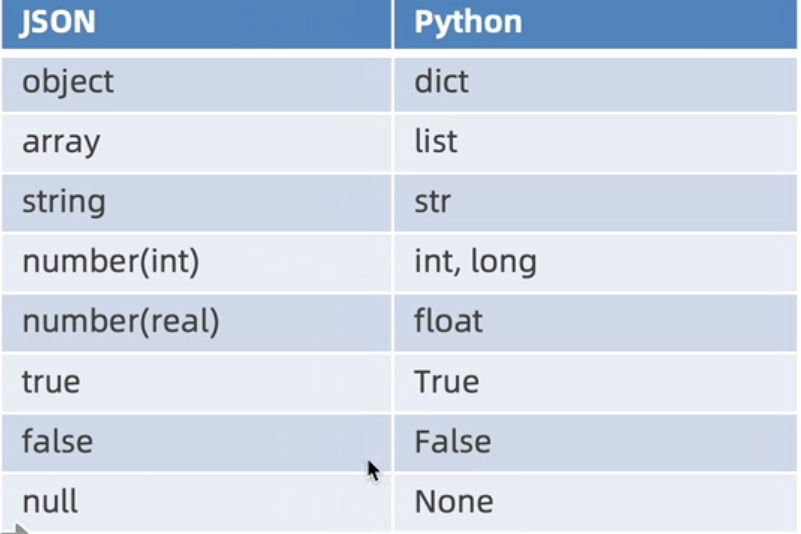
- 常见格式
[{f1: 2, f2: 104673, f3: 17, f4: 177, f12: "ASE", f13: 100, f14: "希腊雅典ASE", f152: 2},…]
json->python¶
json字符串¶
rs=json.loads(json型变量)- 得到的是一个内嵌字典的列表
json格式文件¶
with open('.json') as fp:
arr = json.load(fp)
python->json¶
json.dumps(obj,ensure_ascii=False(是否使用ascii),[fp])- 写入到文件:增加指向文件的变量fp
反爬虫及其处理¶
U-A校验¶
-
浏览器在发送请求的时候,会附带一部分浏览器及当前系统环境的参数给服务器,这部分数据放在 HTTP 请求的 header 部分。我们要做的就是通过 requests 库设置我们的爬虫 U-A。(防止被发现是爬虫)
-
设置
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'
}
res = requests.get(url, headers=headers)
访问频率限制¶
- 可以在每次访问完网站之后就设置一个
time.sleep,限制访问速度。 - 停地更换 ip,就可以伪装成不同的人(从ip池获取代理ip)