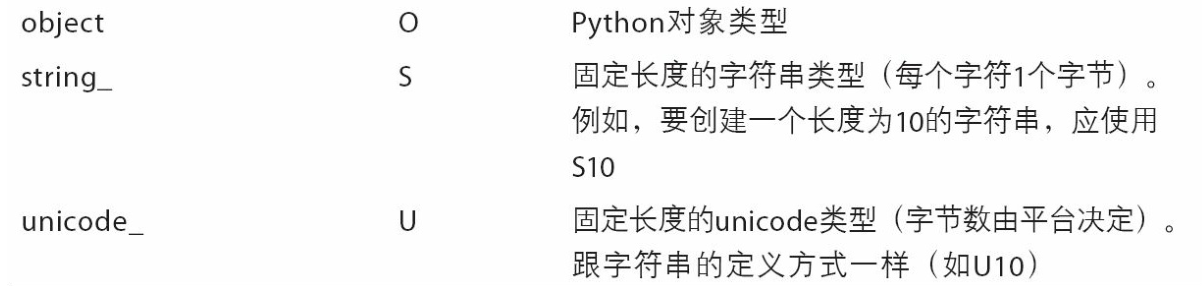
数据分析库¶
-
导入命名规范
-
python import numpy as np import matplotlib.pyplot as plt import pandas as pd import seaborn as sns import statsmodels as sm
Numpy¶
import numpy as npnumpy是以矩阵为基础的数学计算模块,提供高性能的矩阵运算,其中的所有元素必须是相同类型的
-
-
每个数 组都有一个shape(一个表示各维度大小的元组)和一个dtype(一个用于说明数组数据类型的对 象)
基本用法¶
-
它提供了
ndarray,一个同构(数组内数据类型相同)的 n 维数组对象,以及对其进行有效操作的方法。 -
从列表创建
tmp = np.array(arr, dtype='str')输入列表进行初始化 -
dtype为可选择参数用于指代数组的类型
-
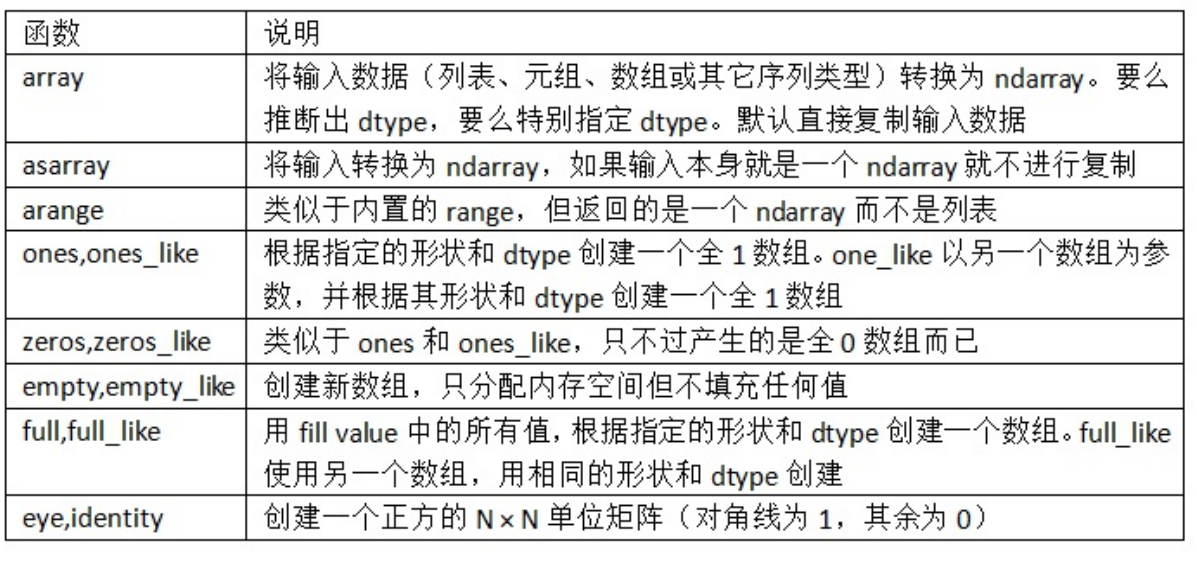
指定形状创建空
np.zeros((3, 6)) -
python array([[ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.], [ 0., 0., 0., 0., 0., 0.]]) -
-
切片:可以对切片进行范围复制,并且会直接反映到原数组上
arr[5:8] = 12- 也可以创教对切片的引用,注意一切修改都是对原数组的修改
- 多维切片
arr2d[:2, 1:]
数据变换¶
.dtype显示数组内的数据类型.astype('str')指定数据类型(以str为例),不会修改原数组,需要用赋值的方式改变.zeros((x,y))x,y二维向量且全是0numpy.arrange(min,max,step)生成等差数列.reshape(x,y)一维数组转化为xy矩阵,y=-1时表示自动计算匹配的数目.sum()求和.T转置矩阵-
高维数组
.transpose((1, 0, 2)) -
.sort()原地排序,矩阵也可以 numpy.ext(a)生成一个新数组,每个元素是eainp.random()生成随机数(矩阵)
获取元素¶
-
多维访问可以
[][]也可以[,] -
a[x,y]获取单个元素 -
a[x,:],a[:,y]获取一行/列 -
布尔型索引:
-
python names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe']) data = np.random.randn(7, 4) # 和字符串比较可以得到布尔型数组 names == 'Bob' # array([ True, False, False, True, False, False, False], dtype=bool) data[names == 'Bob'] # 提取出True对应的行 - 布尔型数组的长度必须跟被索引的轴长度一致。
-
可以使用~直接翻转得到的布尔型数组,也可以使用多个布尔数组,之间可以使用逻辑运算&|
-
花式索引:
-
利用整数数组进行索引
-
用于按照数组顺序获取指定的行(序号可以是负数)
-
python ''' array([[ 0., 0., 0., 0.], [ 1., 1., 1., 1.], [ 2., 2., 2., 2.], [ 3., 3., 3., 3.], [ 4., 4., 4., 4.], [ 5., 5., 5., 5.], [ 6., 6., 6., 6.], [ 7., 7., 7., 7.]]) ''' arr[[4, 3, 0, 6]] ''' array([[ 4., 4., 4., 4.], [ 3., 3., 3., 3.], [ 0., 0., 0., 0.], [ 6., 6., 6., 6.]]) ''' -
传入高维数组,更精确的选取元素:
-
python In [122]: arr = np.arange(32).reshape((8, 4)) In [123]: arr Out[123]: array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23], [24, 25, 26, 27], [28, 29, 30, 31]]) In [124]: arr[[1, 5, 7, 2], [0, 3, 1, 2]] Out[124]: array([ 4, 23, 29, 10])
通用函数ufunc¶
- 一元:
np.sqrt(arr) 

- 二元:
np.maximum(x, y) - 多返回值如返回小数部分和整数部分:
remainder, whole_part = np.modf(arr) 
- 支持一个out可选参数,用于对数组进行原地操作
np.sqrt(arr, arr)
线性代数¶
- 矩阵点积
np.dot(x, y)或x.dot(y)或x @ y
生成伪随机数¶
- 获得4*4正态分布样本
samples = np.random.normal(size=(4, 4)) - 设置随机种子
np.random.seed(1234) - 局部
rng = np.random.RandomState(1234) rng.randn(10) 

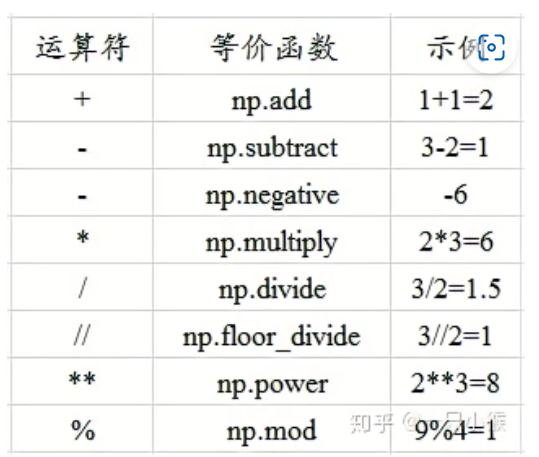
运算¶
-
-
numpy在做运算时,是对数组中每个元素都进行运算,如
a+=10 -
也可以指定行列进行计算
-
where语句
-
如将多有整数替换为2
-
python np.where(arr > 0, 2, arr) # arr > 0 得到 array([[False, False, False, False], [ True, True, False, True], [ True, True, True, False], [ True, False, True, True]], dtype=bool) -
数学和统计
-
可以通过数组上的一组数学函数对整个数组或某个轴向的数据进行统计计算
-
如
arr.sum(axis=0) -
不指定轴时对整个数组操作
-
python arr.mean() # 0.19607051119998253
-
-
如cumsum和cumprod之类的方法则不聚合,而是产生一个由中间结果组成的数组:
-
python arr = np.array([0, 1, 2, 3, 4, 5, 6, 7]) # array([ 0, 1, 3, 6, 10, 15, 21, 28]) -
在多维数组中,累加函数(如cumsum)返回的是同样大小的数组,但是会根据每个低维的切片沿着标记轴计算部分聚类:
-
-

-
用于布尔数组的一些方法
- sum对True计数
- any:是否存在True
- all:是否全部为True
-
排序
-
多维数组可以在任何一个轴向上进行排序,只需将轴编号传给sort即可
arr.sort(1) -
顶级方法np.sort返回的是数组的已排序副本,而就地排序则会修改数组本身。
-
集合运算
-
唯一化
np.unique(ints)去重
-
np.in1d用于测试一个数组中的值在另一个数组中的成员资格,返回一个布尔型数组
python In [211]: values = np.array([6, 0, 0, 3, 2, 5, 6]) In [212]: np.in1d(values, [2, 3, 6]) Out[212]: array([ True, False, False, True, True, False, True], dtype=bool)
-

文件输入输出¶
-
默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中的
-
np.save -
np.save('some_array', arr) -
np.load -
np.load('some_array.npy') -
多个数组保存在一个未压缩的文件
-
python np.savez('array_archive.npz', a=arr, b=arr) arch = np.load('array_archive.npz') # 得到一个字典对象 arch['b'] -
压缩存储:
np.savez_compressed('arrays_compressed.npz', a=arr, b=arr)
Pandas¶
- pandas是基于numpy数组构建的,但二者最大的不同是pandas是专门为处理表格和混杂数据设计的,比较契合统计分析中的表结构,而numpy更适合处理统一的数值数组数据。
- pandas 有两个主要的数据结构,
Series和DataFrame -
from pandas import Series, DataFrame -
import pandas as pd
Series¶
-
是一种一维数据结构
-
创建
s = pd.Series([1,2,3]) -
也可以直接传入一个字典,直接绑定索引
-
python sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000} obj3 = pd.Series(sdata) ''' Ohio 35000 Oregon 16000 Texas 71000 Utah 5000 dtype: int64 ''' # 也可以单独指定,字典会自动进行匹配 states = ['California', 'Ohio', 'Oregon', 'Texas'] obj4 = pd.Series(sdata, index=states) ''' California NaN Ohio 35000.0 Oregon 16000.0 Texas 71000.0 dtype: float64 ''' # 查询bool是否为NaN pd.isnull(obj4) # obj4.isnull() ''' California True Ohio False Oregon False Texas False dtype: bool ''' pd.notnull(obj4) -
s = pd.Series([1,2,3], index=['a', 'b', 'c'])绑定索引 - 加入变量名是arr那么
arr就表示输出变量 -
可以在创建之后直接对索引进行修改
obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan'] -
访问:
arr.iloc[i]通过下标访问arr.loc[".."]通过索引访问- 可以传入数组
obj2[['c', 'a', 'd']] - 可以使用布尔数组
obj2[obj2 > 0] -
切片
[2:4]序号切片;['b','c']标签切片(利用标签的切片运算与普通的Python切片运算不同,其末端是包含的) -
在运算过程中可能出现NaN(异常缺失值),可以删除缺失值,或在计算时设置填充缺失值
arr.dropna()-
arr.add(b,fill_value=0) -
使用NumPy函数或类似NumPy的运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数 等)都会保留索引值的链接:
-
python In [23]: np.exp(obj2) Out[23]: d 403.428793 b 1096.633158 a 0.006738 c 20.085537 dtype: float64 -
根据索引自动对齐数据
-
```python In [35]: obj3 Out[35]: Ohio 35000 Oregon 16000 Texas 71000 Utah 5000 dtype: int64
In [36]: obj4 Out[36]: California NaN Ohio 35000.0 Oregon 16000.0 Texas 71000.0 dtype: float64
In [37]: obj3 + obj4 Out[37]: California NaN Ohio 70000.0 Oregon 32000.0 Texas 142000.0 Utah NaN dtype: float64 ```
-
Series对象本身及其索引有name属性
-
python obj4.name = 'population' obj4.index.name = 'state'
DataFrame¶
-
是一种表格数据结构,我们可以把 DataFrame 看作 Series 组成(series作为列来存在)的字典,每列可以是不同类型的值
-
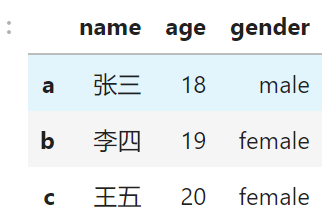
python #通过列表创建 dic = { 'name': ['张三', '李四', '王五'], 'age': [18, 19, 20], 'gender': ['male', 'female', 'female'] } df = pd.DataFrame(dic, index = list('abc')) # 手动指定列的顺序 pd.DataFrame(data, columns=['year', 'state', 'pop']) # 如果没有对应的列会产生缺失值 year state pop debt one 2000 Ohio 1.5 NaN two 2001 Ohio 1.7 NaN three 2002 Ohio 3.6 NaN four 2001 Nevada 2.4 NaN five 2002 Nevada 2.9 NaN six 2003 Nevada 3.2 NaN # 通过字典创建 pop = {'Nevada': {2001: 2.4, 2002: 2.9},'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}} -

- 通过传入由等长列表或numpy数组组成的字典
-
DataFrame会自动加上索引(跟Series一样),且全部列会被有序排列
-
操作¶
-
添加元素到末尾
-
获取列名
-
python frame2.columns # Index(['year', 'state', 'pop', 'debt'], dtype='object') -
通过列名获取列(Series):
-
frame2['state']或frame2.year -
可以赋值对一整列数据进行修改
- 使用数组、列表赋值时长度必须与DataFrame匹配,使用Series时会精确匹配索引,空位会被填上缺失值
-
删除列
del frame2['eastern'] -
reindex,重排索引创建新对象
-
python ''' d 4.5 b 7.2 a -5.3 c 3.6 ''' obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e']) ''' a -5.3 b 7.2 c 3.6 d 4.5 e NaN ''' -
还可以插值(自动填充NaN)
obj3.reindex(range(6), method='ffill')实现前向值填充 -
默认是对行重排,列可以用columns关键字重新索引
frame.reindex(columns=states) -

-
丢弃(行)索引
obj.drop(['d', 'c']),可以传入单个元素或数组,探添加参数axis=1可以丢弃列。就地修改,不会返回新对象。 -
像numpy一样使用布尔数组
-
python In [134]: data < 5 Out[134]: one two three four Ohio True True True True Colorado True False False False Utah False False False False New York False False False False In [135]: data[data < 5] = 0 In [136]: data Out[136]: one two three four Ohio 0 0 0 0 Colorado 0 5 6 7 Utah 8 9 10 11 New York 12 13 14 15
运算¶
- 对两个Dataframe运算得到的结果的索引和列是并集,但对于不同时存在与两个Dataframe位置的元素会被置为NaN
- 指定用于填充的值
df1.add(df2, fill_value=0) 
- r表示会颠倒两个参与运算的数
函数应用ufuncs¶
-
numpy的通用函数可以用于panadas对象,如
np.abs(frame) -
对行/列执行函数
-
python f = lambda x: x.max() - x.min() frame.apply(f)# 默认是在每一列执行 frame.apply(f, axis='columns') # 返回值不一定是值 def f(x): return pd.Series([x.min(), x.max()], index=['min', 'max']) -
元素级处理,对dataframe中每一个元素进行处理
-
python format = lambda x: '%.2f' % x frame.applymap(format)# 对每一个元素进行操作 # Seriesy有个用于对所有元素操作的map(format)
DataFrame和Series之间的运算¶
-
默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播:
-
```python In [181]: frame Out[181]: b d e Utah 0.0 1.0 2.0 Ohio 3.0 4.0 5.0 Texas 6.0 7.0 8.0 Oregon 9.0 10.0 11.0
In [182]: series Out[182]: b 0.0 d 1.0 e 2.0 Name: Utah, dtype: float64
In [183]: frame - series Out[183]: b d e Utah 0.0 0.0 0.0 Ohio 3.0 3.0 3.0 Texas 6.0 6.0 6.0 Oregon 9.0 9.0 9.0 ```
-
如果某个索引值在DataFrame的列或Series的索引中找不到,则对应的列会被赋值为NaN
-
匹配行要用算数运算方式并指定
frame.sub(series3, axis='index') -
传入的轴号就是希望匹配的轴
排序¶
-
Series按照索引的字典序进行排序
.sort_index() -
DateFrame可以指定排序的轴
frame.sort_index(axis=1) -
ascending=False设置升序还是降序排序 -
Series对值进行排序
sort_values()(缺失值会被放到末尾) -
DataFrame依据多个列的值进行排序
frame.sort_values(by=['a', 'b'])传入列名 -
.rank()方法返回排名 -
默认按照大小从小到大排序,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的
python In [215]: obj = pd.Series([7, -5, 7, 4, 2, 0, 4]) In [216]: obj.rank() Out[216]: 0 6.5 1 1.0 2 6.5 3 4.5 4 3.0 5 2.0 6 4.5 dtype: float64
-
也可以根据值在原数据中出现的顺序给出排名:
obj.rank(method='first') -

处理具有重复标签的轴索引¶
-
obj.index.is_unique获取值是否是唯一的 -
Series数据的选取有些变化,如果一个索引对应多个值,则返回一个Series
-
```python ''' a 0 a 1 b 2 b 3 c 4 ''' In [225]: obj['a'] Out[225]: a 0 a 1 dtype: int64
In [226]: obj['c'] Out[226]: 4 ```
-
DataFrame则会返回一个DataFrame
python In [229]: df.loc['b'] Out[229]: 0 1 2 b 1.669025 -0.438570 -0.539741 b 0.476985 3.248944 -1.021228
汇总统计¶
- 从Series 中提取单个值(如sum或mean)或从DataFrame的行或列中提取一个Series,都是基于没有缺失数据的假设而构建的。
- 对所有列进行求和
df.sum(),即汇总成一行 - 对行进行运算
df.sum(axis=1) - NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA。通过skipna选项可以禁用该功能:
skipna=False -

-
df.idxmax()返回简介统计(比如达到最小值或最大值的索引) -
df.describe()汇总统计 -
python # 统计数值型数据 one two count 3.000000 2.000000 mean 3.083333 -2.900000 std 3.493685 2.262742 min 0.750000 -4.500000 25% 1.075000 -3.700000 50% 1.400000 -2.900000 75% 4.250000 -2.100000 max 7.100000 -1.300000 # 统计非数值型数据 count 16 unique 3 top a freq 8 dtype: object -

-
Series去重
obj.unique(),统计出现次数obj.value_counts()(默认会进行排序) -
判断值是否在指定列表
-
python ''' 0 c 1 a 2 d 3 a 4 a 5 b 6 b 7 c 8 c dtype: object ''' mask = obj.isin(['b', 'c']) ''' 0 True 1 False 2 False 3 False 4 False 5 True 6 True 7 True 8 True dtype: bool ''' -

属性¶
.info查看数据类型.values以二维ndarray的形式返回DataFrame中的数据.index获取索引对象- 不可变(不可修改)
Index(['a', 'b', 'c'], dtype='object')- ndex的功能也类似一个固定大小的集合,但是可以包含重复的标签

数据获取¶
-

-
df.iloc[i]按行访问(不包含表头name age gender),使用标签索引 - 具体访问
df.iloc[][] - 或
df.loc[x,'列名称'] df[i]表示按照列进行访问df.loc[['a', 'b'], ['name', 'gender']]通过 *索引* 对数据进行索引,使用整数索引- 末尾添加一行
df.loc[len(df.index)] = [name,price] - 提取指定的行列组成的子矩阵

- 对数据筛选
df.loc[(df.age < 20) & (df.gender == 'male')]条件之间使用&进行连接 -
可以实现一些复杂的搜索,如搜索最大值
df_cleansed.loc[df.price==df['price'].max()] -
.head(n)提取前n行.tail(n)提取后n行
表格csv¶
-
导入表格
read_csv函数,它接受一个文件名或一个 URL 作为参数,并返回一个 DataFrame 对象 -
python import pandas as pd df = pd.read_csv("./data.csv") # 读取本地文件 df = pd.read_csv("https://example.com/nba.csv") # 读取网络文件 print(df) -
导出
t.o_csv('目标文件‘,[其他属性]) - 导出特定行,如
columns=['age'] - 是否导出表头及序号
header=False, index=False - 编码方式
encoding默认utf8 - 保留小数位数
float_format='%.3f' - 写入模式;
- 默认值为“ w”,如果指定的路径不存在,则将重新创建该路径,如果存在,则将其覆盖。
- "a",仅将pandas.DataFrame的内容添加到现有文件的末尾。
mode='a'
数据处理¶
-
groupby('')依据某一项对数据进行分组 -
python car_Manufacturers = df_cleansed.groupby('company') # 依据company对数据进行分组 toyotaDf = car_Manufacturers.get_group('toyota') # 从分组后的数据得到新的DataFrame -
对类别进行技术
df_cleansed['company'].value_counts() -
排序
carsDf = df_cleansed.sort_values(by=['price', 'horsepower'], ascending=False) -
ascending设定为False表示颠倒排序
Matplotlib¶
-
用于绘制2d图像
-
导入
-
python import matplotlib.pyplot as plt plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体 plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
图形构成¶
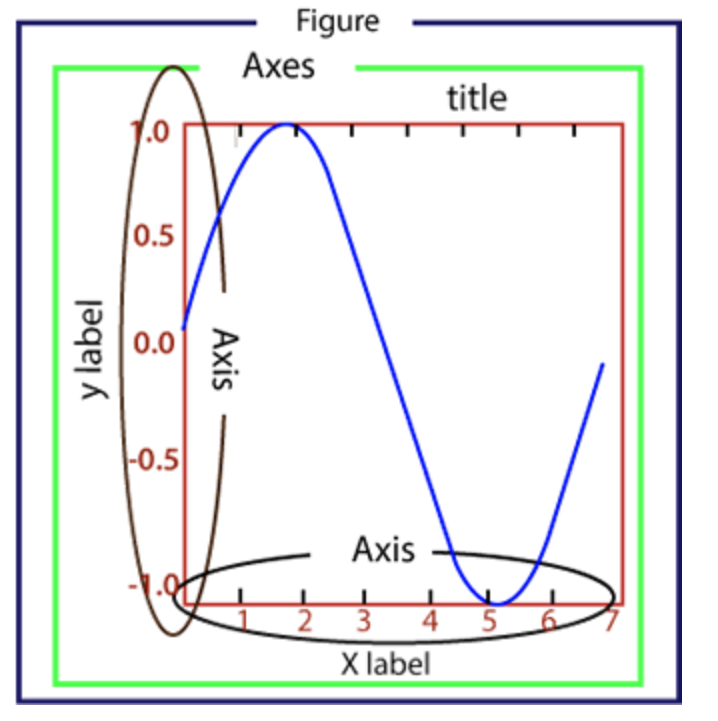
- Figure:指整个图形,可以把它理解成一张画布,它包括了所有的元素,比如标题、轴线等;
- 创建
fig = plt.figure() - Axes:绘制 2D 图像的实际区域,也称为轴域区,或者绘图区;
- Axis:指坐标系中的垂直轴与水平轴,包含轴的长度大小(图中轴长为 7)、轴标签(指 x 轴,y轴)和刻度标签;
- Artist:在画布上看到的所有元素都属于 Artist 对象,比如文本对象(title、xlabel、ylabel)、Line2D 对象(用于绘制2D图像)等。
常用API¶
属性设置¶
- plt.xlabel():设置x轴的标签。
- 使用:
plt.xlabel("xxx") - plt.ylabel():设置y轴标签。
- plt.title:设置图的标题。
- plt.xlim():设置x轴的起始坐标
- plt.ylim():设置y轴的起始坐标。
- plt.legend():显示图例,即图中表示每条曲线的标签和样式的矩形区域。
全局配置¶
-
plt.rc('figure', figsize=(10, 10))设置默认图像大小 -
设置文字样式
-
python font_options = {'family' : 'monospace', 'weight' : 'bold', 'size' : 'small'} plt.rc('font', **font_options
常用操作¶
-
plt.plot()用于画图,它可以绘制点和线, 并且对其样式进行控制。 -
python plt.plot([x], y, [format_string], **kwargs)x传入 x 轴坐标,y传入对应 y 轴坐标。format_string传入格式化字符串。- 包括三部分, "颜色", "点型", "线型"。
- 颜色如c清;r红;w白;k黑...(也可以直接指定颜色码)
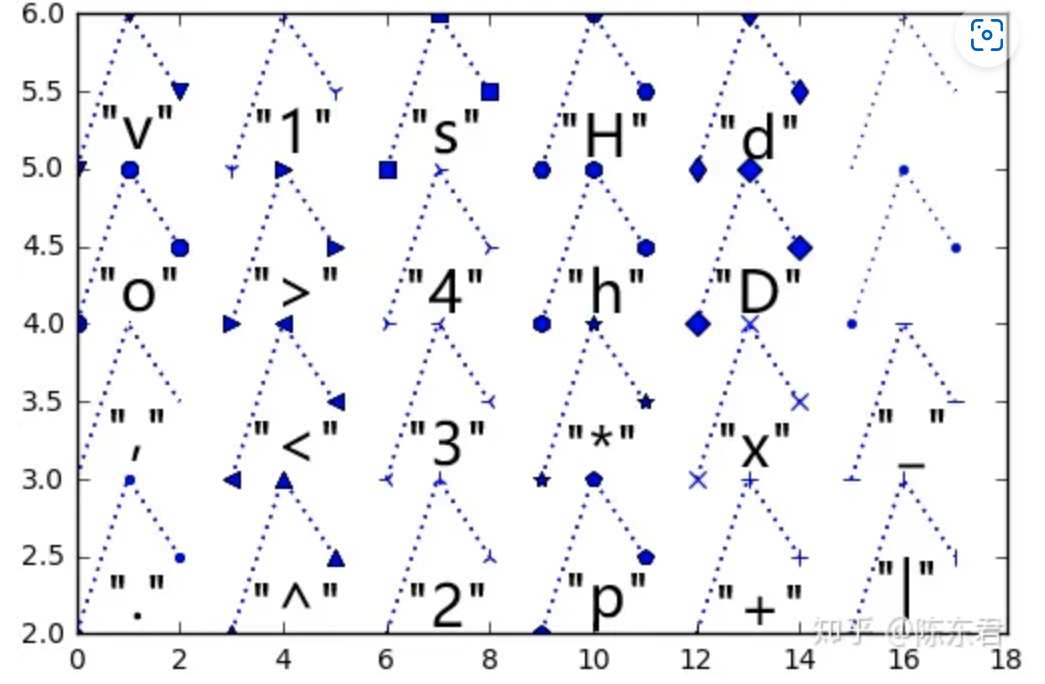
- 点型:
- 线型:
:点线;-.点画线:--短划线;-实线 - 使用时按顺序写在一起
plt.plot(x, y2, 'ro-', ms=3) **kwargs传入关键字参数控制线的粗细等内容。- lw线宽
- ms点直径
-
plot 函数允许多次调用,以在同一张图上绘制多个线条。当你调用 plot 函数时,它会将你提供的数据添加到当前图形的图层中。
-
在调用 show 函数之前,你可以在同一个图形上进行多次绘制操作,包括绘制多个子图、绘制多条曲线等。当你调用 show 函数时,Matplotlib会将所有已添加的图层组合起来,并显示在同一个窗口中。
-
例
- ```python import matplotlib.pyplot as plt import numpy as np
# 创建数据 x = np.linspace(0, 10, 100) y1 = np.sin(x) y2 = np.cos(x)
# 绘制两条线 plt.plot(x, y1) plt.plot(x, y2)
# 添加图例和标题 plt.legend(['Sin', 'Cos']) plt.title('Sin and Cos Waves')
# 显示图形 plt.show() ```
-
xtick:控制标签显示格式(如x轴上的坐标) -
xticks(rotation=90)设置标签旋转显示 -
xticks(ticks=[...])只显示列表内的标签(放置显示过于密集造成重叠) -
刻度、标题及标签
-
设置轴刻度
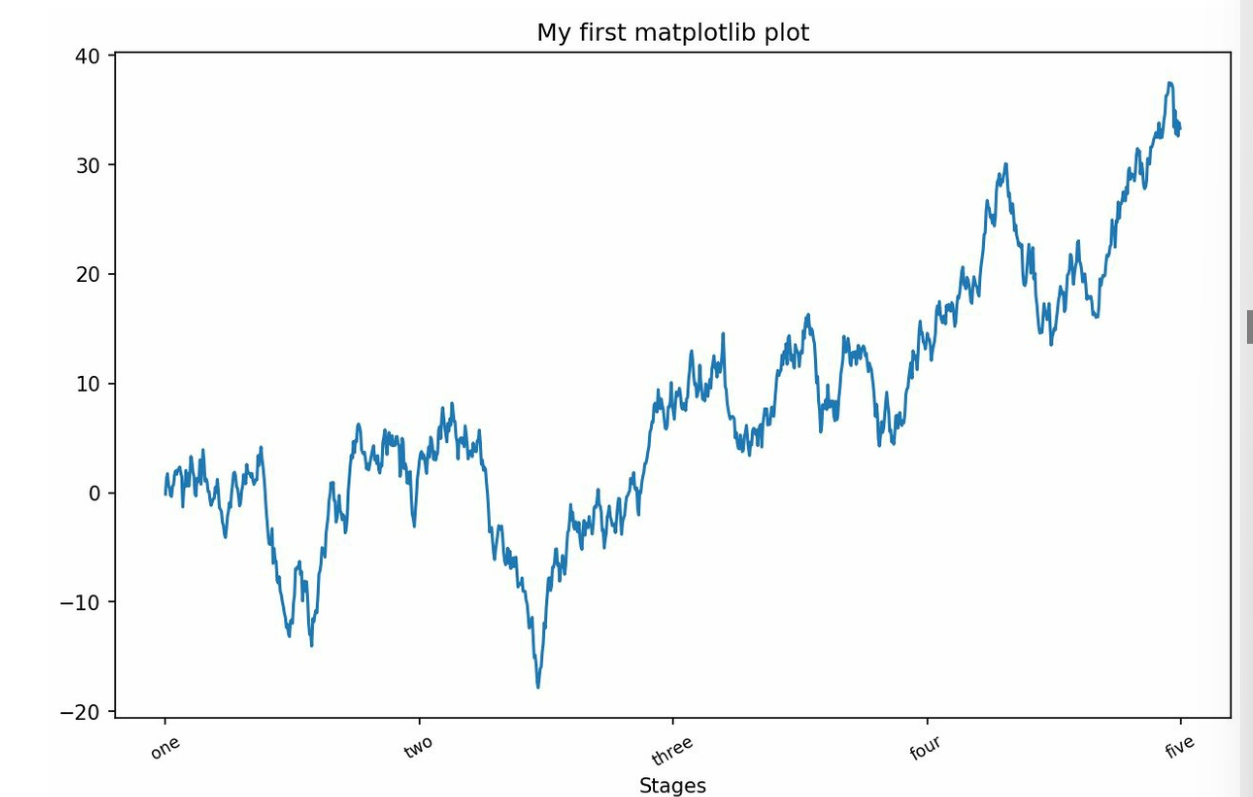
ticks = ax.set_xticks([0, 250, 500, 750, 1000]) -
设置对应的标签及标签的显示样式
labels = ax.set_xticklabels(['one', 'two', 'three', 'four', 'five'],rotation=30, fontsize='small') -
设置图标题
ax.set_title('My first matplotlib plot') -
设置轴标题
ax.set_xlabel('Stages') -
-
使用字典存储图的配置,方便批量配置
python props = { 'title': 'My first matplotlib plot', 'xlabel': 'Stages' } ax.set(**props)
-
图例
-
创建图像时设置标签
ax.plot(randn(1000).cumsum(), 'k', label='one') - 如一个Figure上可以显示多条折现
-
使用
plt.legend()自动创建图例ax.legend(loc='best') -
注解(在Subplot上绘图)
-
添加文字
ax.text(x, y, 'Hello world!',family='monospace', fontsize=10)- 指出坐标,文字及文字样式
-
使用
annotate创建更为丰富的(如带箭头的注解)plt.annotate('这里有一个峰值', xy=(2, 3), xytext=(3, 4),arrowprops=dict(facecolor='black', shrink=0.05))text是注解文本的字符串。xy是要注解的点的位置(x, y)。xytext是注解文本的位置(默认情况下与xy相同)。xycoords和textcoords是指定xy和xytext坐标系的参数(默认为'data'表示使用数据坐标系)。arrowprops是一个字典,用于定义一个箭头从文本指向被注解的点(如果不需要箭头,则省略此参数)。
-
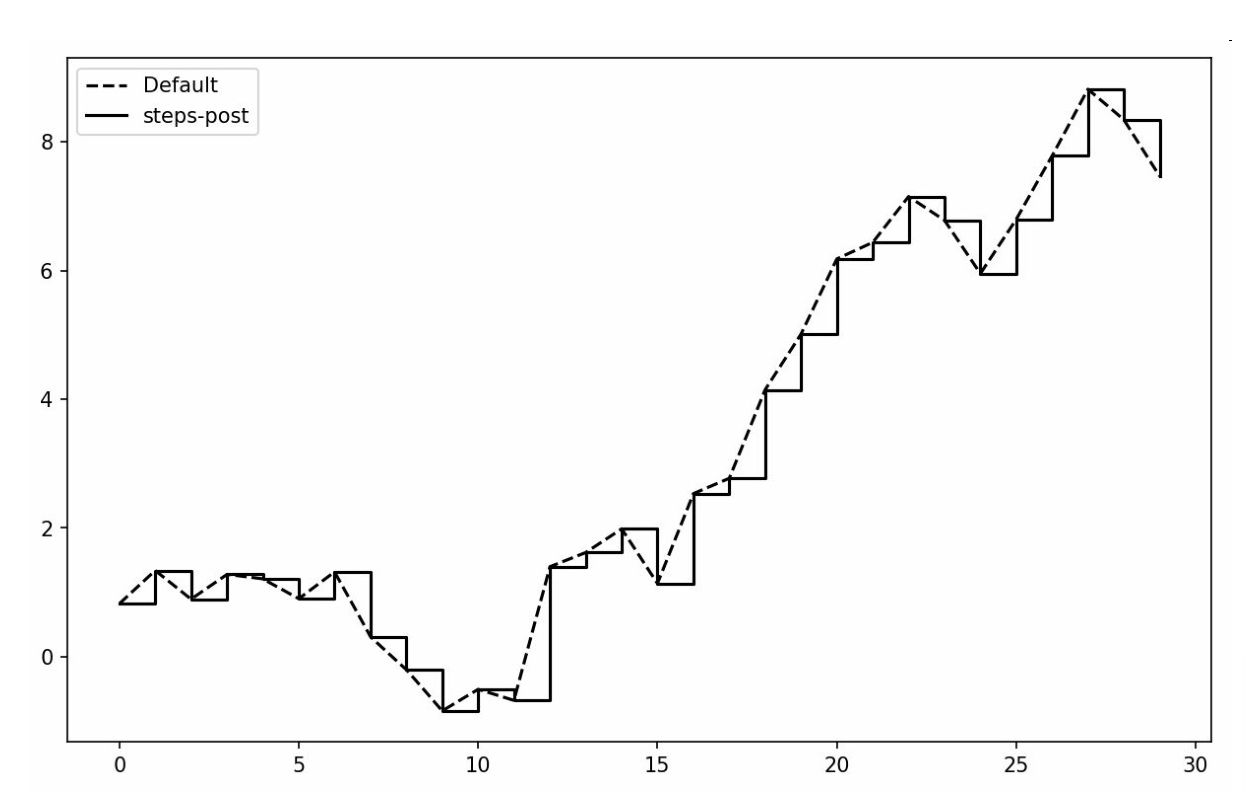
非实际数据点插值方式
-
线型图中默认为线性插值(如折线)
drawstyle='steps-post'
子图¶
-
python ax1 = fig.add_subplot(2, 2, 1) # 2*2共4个图中第一个 ax2 = fig.add_subplot(2, 2, 2) ax3 = fig.add_subplot(2, 2, 3) -
这时执行一条绘图命令会在最后一个用过的subplot上进行绘制
plt.plot(np.random.randn(50).cumsum(), 'k--') -
使用
ax1.对选定的子图进行绘制 -
使用
subplot()子图,返回Numpy数组可以方便的通过索引进行访问 -
```python x = np.array([0, 6]) y = np.array([0, 100])
plt.subplot(2, 4, 1) plt.plot(x,y) plt.title("plot 1") ```
-

-
表示构建2行4列的子图,这是第一个(按从左到右从上到下的顺序编号)
- 1234
- 5678
-
间距调整
- 利用Figure的
subplots_adjust方法进行调整 subplots_adjust(left=None, bottom=None, right=None, top=None,wspace=None, hspace=None)
- 利用Figure的
保存图表到文件¶
- 保存为svg
plt.savefig('figpath.svg') - 更为细致的导出控制
plt.savefig('figpath.png', dpi=400, bbox_inches='tight') 
不同类型的图¶
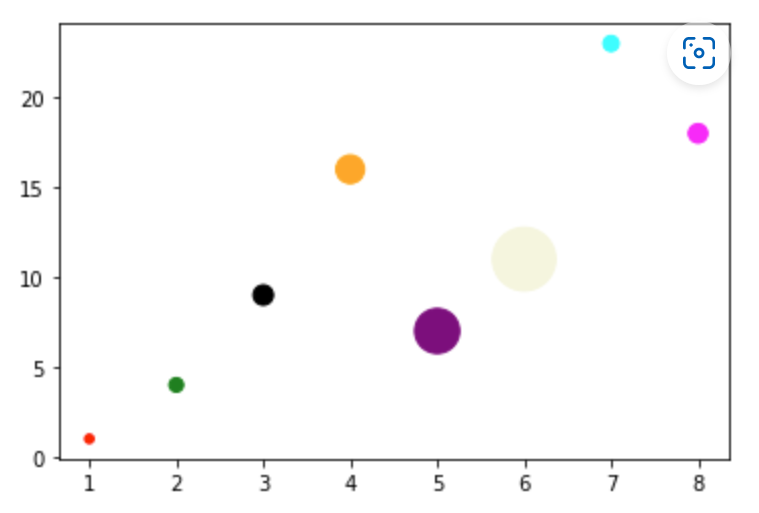
scatter散点图¶
示例¶
- ```python x = np.array([1, 2, 3, 4, 5, 6, 7, 8]) y = np.array([1, 4, 9, 16, 7, 11, 23, 18])
sizes = np.array([20,50,100,200,500,1000,60,90]) colors = np.array(["red","green","black","orange","purple","beige","cyan","magenta"])
plt.scatter(x, y, c=colors, s=sizes) plt.show() ```
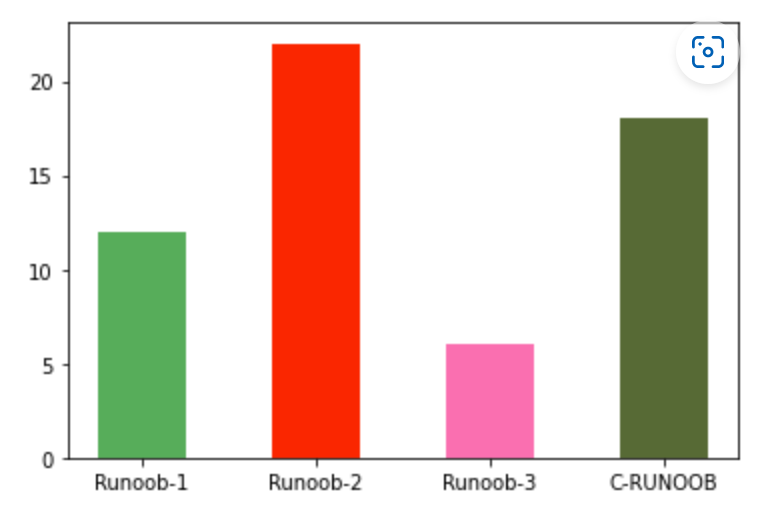
bar柱状图¶
示例¶
- ```python x = np.array(["Runoob-1", "Runoob-2", "Runoob-3", "C-RUNOOB"]) y = np.array([12, 22, 6, 18])
plt.bar(x, y, color = ["#4CAF50","red","hotpink","#556B2F"], width=0.5) plt.show() ```
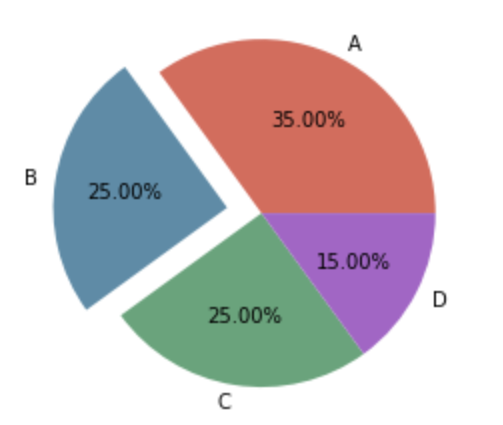
pie饼图¶
示例¶
- ```python y = np.array([35, 25, 25, 15])
plt.pie(y, labels=['A','B','C','D'], # 设置饼图标签 colors=["#d5695d", "#5d8ca8", "#65a479", "#a564c9"], # 设置饼图颜色 explode=(0, 0.2, 0, 0), # 第二部分突出显示,值越大,距离中心越远 autopct='%.2f%%', # 格式化输出百分比 )
plt.show() ```
数据分析流程¶
数据加载、存储与文件格式¶
读写文本格式的数据(csv)¶
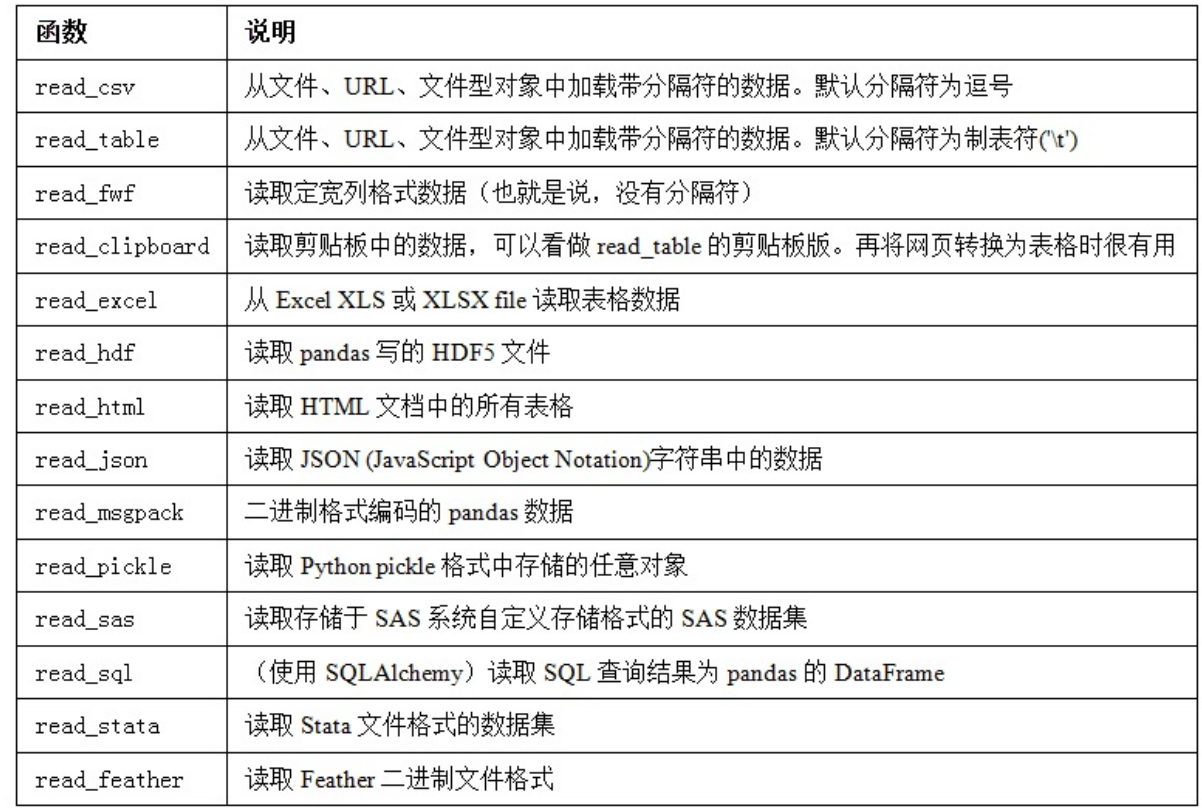
- 常用方法
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、和自定义的缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号 隔开的数值数据)。
读取方法属性¶
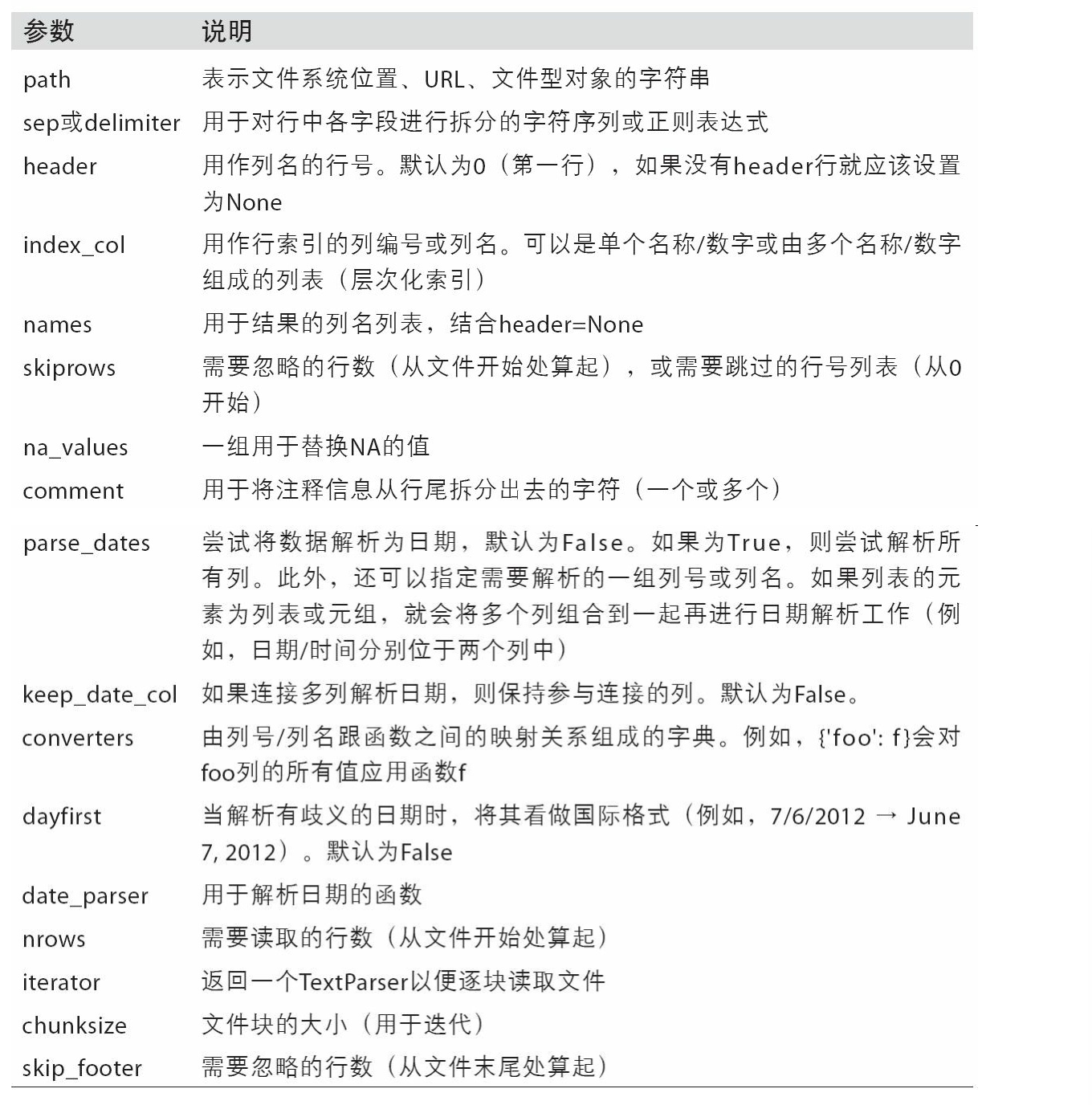
-
读取csv(逗号分隔)
df = pd.read_csv('examples/ex1.csv')或pd.read_table('examples/ex1.csv', sep=',')(sep可以传入一个正则表达式) -
指定列的名称
pd.read_csv('examples/ex2.csv', names=['a', 'b', 'c', 'd', 'message']) -
指定一列作为dataframe的索引
-
python names = ['a', 'b', 'c', 'd', 'message'] pd.read_csv('examples/ex2.csv', names=names, index_col='message') ''' a b c d message hello 1 2 3 4 world 5 6 7 8 foo 9 10 11 12 ''' -
如果希望将多个列做成一个层次化(字典序)索引,只需传入由列编号或列名组成的列表即可:
index_col=['key1', 'key2'] -
skiprows=[0, 2, 3]跳过文件指定的行 -
na_values可以用一个列表或集合的字符串表示缺失值(即数据文字中表示缺失值的字符串) -
常用属性
-

逐块读取文本文件¶
pd.read_csv('examples/ex6.csv', nrows=5)指定读取的行数- 逐块读取
chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000)(chunksize表示一块读取的行数) - chunker是创建的一个可迭代对象,用于进行逐块读取
- 通过for进行迭代,实现逐块读取
写出数据¶
-
写出到csv文件
data.to_csv('examples/out.csv') -
可以使用
sep设置分隔符 -
打印输出
-
python import sys data.to_csv(sys.stdout) -
不输出行列标签
index=False, header=False -
指定输出的列及排列顺序
columns=['a', 'b', 'c']
其他种类数据的处理¶
Excel¶
-
pd.read_excel(xlsx, 'Sheet1')可以指定要读取的表单 -
写入数据
-
python writer = pd.ExcelWriter('examples/ex2.xlsx') frame.to_excel(writer, 'Sheet1') writer.save() # 更简易的方式 frame.to_excel('examples/ex2.xlsx')
JSON¶
-
通过json.loads即可将JSON字符串转换成Python形式:
-
python import json result = json.loads(obj) -
json.dumps则将Python对象转换成JSON格式:
asjson = json.dumps(result) -
将JSON转化为DataFrame对象
-
向DataFrame构造器传入一个字典的列表(就是原先的JSON对象),并选取数据字段的子集(即从JSON中选取符合格式的数据用于创建dataframe)
siblings = pd.DataFrame(result['siblings'], columns=['name', 'age'])
-
直接从JSON读取
data = pd.read_json('examples/example.json') -
从pandas输出到JSON
data.to_json()
WebAPI交互¶
-
使用requests包进行http请求,再对返回的json对象进行处理
-
python import requests url = 'https://api.github.com/repos/pandas-dev/pandas/issues' resp = requests.get(url) data = resp.json() issues = pd.DataFrame(data, columns=['number', 'title','labels', 'state']) # 直接传递数据到DataFrame,并提取感兴趣的字段
使用数据库¶
-
使用SQLAlchemy从SQL数据库读取
-
python import sqlalchemy as sqla db = sqla.create_engine('sqlite:///mydata.sqlite') pd.read_sql('select * from test', db)
数据清洗和准备¶
处理缺失数据¶
- 滤除缺失数据
- 对于一个Series,dropna返回一个仅含非空数据和索引值的Series
data.dropna()等同于data[data.notnull()] - 对于dataframe默认会丢弃任何含有缺失值的行,但可以设置这这阈值,比如之丢弃全为NA的行
data.dropna(how='all')- 也可以丢弃列
axis=1
- 也可以丢弃列
- 设置保留要求的非NA项的最少数目
df.dropna(thresh=2) - 填充缺失数据
- 使用一个数填充缺失数据
df.fillna(0) - 传入字典,对不同列填充不同的值
df.fillna({1: 0.5, 2: 0}) - 设置为就地修改
inplace=True 
- 前向填充并设置最远填充距离
df.fillna(method='ffill', limit=2)
- 前向填充并设置最远填充距离
数据转换¶
-
移除重复数据
-
返回dataframe各行是否是重复行
data.duplicated()- 返回丢弃重复项的新数据
data.drop_duplicates() - 针对特定行进行重复的判断和去重
data.drop_duplicates(['k1'])
- 返回丢弃重复项的新数据
-
duplicated和drop_duplicates默认保留的是第一个出现的值组合。传入
keep='last'则保留最后一个 -
利用函数或映射进行数据转换
-
利用现有的列生成一个新列
-
python ''' food ounces 0 bacon 4.0 1 pulled pork 3.0 2 bacon 12.0 3 Pastrami 6.0 4 corned beef 7.5 5 Bacon 8.0 6 pastrami 3.0 7 honey ham 5.0 8 nova lox 6.0 ''' # 字典作为映射表 meat_to_animal = { 'bacon': 'pig', 'pulled pork': 'pig', 'pastrami': 'cow', 'corned beef': 'cow', 'honey ham': 'pig', 'nova lox': 'salmon' } lowercased = data['food'].str.lower() data['animal'] = lowercased.map(meat_to_animal) # 使用map自动构建字典,也可以传入一个lambda表达式 ''' food ounces animal 0 bacon 4.0 pig 1 pulled pork 3.0 pig 2 bacon 12.0 pig 3 Pastrami 6.0 cow 4 corned beef 7.5 cow 5 Bacon 8.0 pig 6 pastrami 3.0 cow 7 honey ham 5.0 pig 8 nova lox 6.0 salmon ''' -
替换值
-
替换Series中的元素
data.replace(-999, np.nan) - 多种被替换元素
data.replace([-999, -1000], np.nan) -
多对替换
data.replace([-999, -1000], [np.nan, 0])- 也可以传入一个字典
-
重命名轴索引
-
如将index变为大写
python transform = lambda x: x[:4].upper() data.index.map(transform) # Index(['OHIO', 'COLO', 'NEW '], dtype='object')
-
创建的是新对象,需要赋值到原先的对象
-
直接修改
data.rename(index=str.title, columns=str.upper)- 使用字典对部分标签进行更新
data.rename(index={'OHIO': 'INDIANA'},columns={'three': 'peekaboo'}) - 注意都不会对原始的数据进行修改,除非设置
inplace=True
- 使用字典对部分标签进行更新
-
离散化和面元划分
-
为了便于分析,连续数据常常被离散化或拆分为“面元”,如对数据中人员年龄进行划分分组
-
python ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32] bins = [18, 25, 35, 60, 100]# 分界点 cats = pd.cut(ages, bins)# 划分 cats.codes# 获取分类标签 # array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8) -
pd.value_counts(cats)查看结果的统计 -
right=False控制左开右闭还是左闭右开 -
传入一个列表设置面元的名称
pd.cut(ages, bins, labels=group_names) -
如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元
pd.cut(data, 4, precision=2)- 选项
precision=2,限定小数只有两位。
- 选项
-
qcut使用的是样本分位数,因此可以得到大小基本相等(即每个区间内元素的数目相近)的面元pd.qcut(data, 4) -
检测和过滤异常值
-
data[(np.abs(data) > 3).any(1)]获取所有有绝对值大于3的元素的行 -
限制到3以内
data[np.abs(data) > 3] = np.sign(data) * 3 -
排列和随机采样
-
随机排列
python # 获取随机排列数组 np.random.permutation(5) # 对行进行冲排列 df.take(sampler)
-
df.sample(n=3)随机抽取n行数据 -
计算指标/哑变量
-
将非数值属性转化为数值属性,对于有k个不同值的属性,可以派生出一个k列矩阵
-
python # ['b', 'b', 'a', 'c', 'a', 'b'] a b c 0 0 1 0 1 0 1 0 2 1 0 0 3 0 0 1 4 1 0 0 5 0 1 0 -
根据列名自动生成
pd.get_dummies(df['key']) -
指定自动生成的列名的前缀
dummies = pd.get_dummies(df['key'], prefix='key')
字符串操作¶
- 切割字符串
pieces = [x.strip() for x in val.split(',')] - 按照,进行划分,并删除单词前后的空白符
- 合并字符串
':'.join([])使用:合并一个列表 - 查找子串
in返回布尔值index findindex找不到会报错,find返回-1- 返回的都是发现的第一个
rfind返回最后一个
count统计数目- 替换
replace(,) endswith startswith
正则表达式¶
- 使用re模块
- 作为分隔符
re.split('\s+', text) - 编译正则对象
regex = re.compile('\s+') - 可以使用正则对象直接使用方法,如
regex.split(text) - 获取全部匹配
regex.findall(text),返回一个列表,包含全部匹配的子串 search只返回第一个匹配项match只匹配字符串的首部regex.sub('REDACTED', text)替换,返回新字符串- 分组正则
pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})'m = regex.match('wesm@bright.net')获取元组m.groups()- findall会直接返回一个元组列表
- sub可以通过序号对不同分组分别进行替换
regex.sub(r'Username: \1, Domain: \2, Suffix: \3', text)
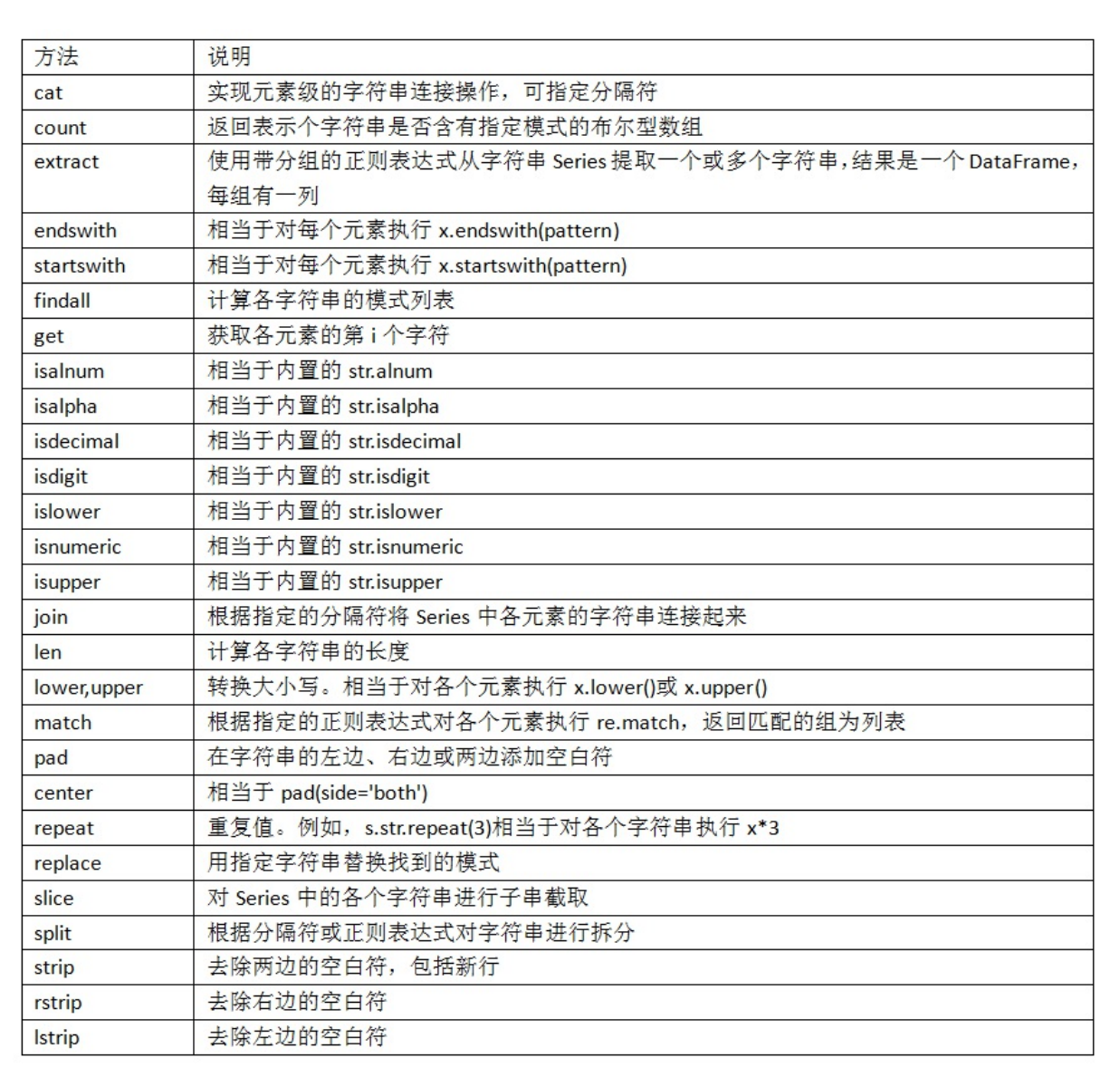
panadas矢量化字符串函数¶
- 通过data.map,所有字符串和正则表达式方法都能被应用于(传入lambda表达式或其他函数)各个值
data.str访问字符串数而忽略其他数据,并且提供了一系列字符串处理方法,这些方法会自动忽略字符串中的NA缺失值data.str.contains('gmail')-
使用正则匹配
data.str.findall(pattern, flags=re.IGNORECASE),还有match等操作 -
数据规整:聚合合并和重塑¶
层次化索引¶
-
在一个轴上拥有多个(两个以上)索引级别
-
python index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],[1, 2, 3, 1, 3, 1, 2, 2, 3]] ''' a 1 -0.204708 2 0.478943 3 -0.519439 b 1 -0.555730 3 1.965781 c 1 1.393406 2 0.092908 d 2 0.281746 3 0.769023 ''' data.index ''' MultiIndex(levels=[['a', 'b', 'c', 'd'], [1, 2, 3]],labels=[[0, 0, 0, 1, 1, 2, 2, 3, 3], [0, 1, 2, 0, 2, 0, 1, 1, 2]]) ''' -
筛选数据
data['b':'c']、data.loc[['b', 'd']]、data.loc[:, 2] -
unstack()展开 -
python 1 2 3 a -0.204708 0.478943 -0.519439 b -0.555730 NaN 1.965781 c 1.393406 0.092908 NaN d NaN 0.281746 0.769023 -
逆运算
stack() -
每一个轴都可以分层索引(index column)
-
可以为每一层指定名字
frame.index.names = ['key1', 'key2'],frame.columns.names = ['state', 'color']
重排与分级排序¶
-
互换两个轴的级别
frame.swaplevel('key1', 'key2') -
针对某一级进行排序
frame.sort_index(level=1) -
python state Ohio Colorado color Green Red Green key1 key2 a 1 0 1 2 b 1 6 7 8 a 2 3 4 5 b 2 9 10 11 -
针对某一轴汇总信息
frame.sum(level='key2') -
将一个或多个列转化为行索引
frame.set_index(['c', 'd']) -
这些列默认会被从数据集中移出,仅作为索引,可以设置
drop=False -
逆操作,将索引放回到列中
frame2.reset_index()
合并数据集¶
-
merge默认会将重叠列的列名作为键,也可以手动指出pd.merge(df1, df2, on='key')也可以选择两个不同的列进行合并pd.merge(df3, df4, left_on='lkey', right_on='rkey') -
默认情况下做的是内连接,还可以设置为
left right outer 
-
多对多连接产生的行是笛卡尔积
-
解决合并时的重复列
suffixes=('_left', '_right')为双方分别制定作为合并后的列名后缀 -
使用索引作为连接键进行合并
-
left_index=True或right_index=True将左右索引作为键 -
层次化索引中的多建合并
python '''1 data key1 key2 0 0.0 Ohio 2000 1 1.0 Ohio 2001 2 2.0 Ohio 2002 3 3.0 Nevada 2001 4 4.0 Nevada 2002 ''' '''2 event1 event2 Nevada 2001 0 1 2000 2 3 Ohio 2000 4 5 2000 6 7 2001 8 9 2002 10 11 ''' pd.merge(lefth, righth, left_on=['key1', 'key2'], right_index=True) ''' data key1 key2 event1 event2 0 0.0 Ohio 2000 4 5 0 0.0 Ohio 2000 6 7 1 1.0 Ohio 2001 8 9 2 2.0 Ohio 2002 10 11 3 3.0 Nevada 2001 0 1 ''' pd.merge(lefth, righth, left_on=['key1', 'key2'],right_index=True, how='outer') ''' data key1 key2 event1 event2 0 0.0 Ohio 2000 4.0 5.0 0 0.0 Ohio 2000 6.0 7.0 1 1.0 Ohio 2001 8.0 9.0 2 2.0 Ohio 2002 10.0 11.0 3 3.0 Nevada 2001 0.0 1.0 4 4.0 Nevada 2002 NaN NaN 4 NaN Nevada 2000 2.0 3.0 '''
-
按索引合并
join默认为左连接 -
默认使用第一个对象的索引,可以为其他对象指定合并用的类,可以一次合并多个表
-
left2.join([right2, another]) -
轴向连接concat
-
concat用于简单的数据堆叠,适用于结构相似的DataFrame或Series对象的快速拼接。 -
```python # 不存在重叠索引时直接拼接 s1 = pd.Series([0, 1], index=['a', 'b']) s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e']) s3 = pd.Series([5, 6], index=['f', 'g']) pd.concat([s1, s2, s3]) ''' a 0 b 1 c 2 d 3 e 4 f 5 g 6 dtype: int64 ''' pd.concat([s1, s2, s3], axis=1) ''' 0 1 2 a 0.0 NaN NaN b 1.0 NaN NaN c NaN 2.0 NaN d NaN 3.0 NaN e NaN 4.0 NaN f NaN NaN 5.0 g NaN NaN 6.0 '''
```
-
取交集
pd.concat([s1, s4], axis=1, join='inner') -
创建一个层次化索引,区分合并的不同组成部分
result = pd.concat([s1, s1, s3], keys=['one','two', 'three'])axis=1时作为列头(或列的层次化索引)
-
直接拼接不考虑索引
ignore_index=True -

-
concatenate:numpy的合并方法
-
用于连接两个或多个数组。这个函数可以沿着一个已存在的轴将多个数组合并成一个新的数组。
-
numpy.concatenate((a1, a2, ...), axis=0, out=None)
-
合并重复数据
-
根据某些条件对数据进行过滤。它返回一个与原DataFrame形状相同DataFrame,但只有满足条件的元素保持原样,其他的替换为另一个DataFrame中的值或是NaN。
-
python ''' In [111]: a Out[111]: f NaN e 2.5 d NaN c 3.5 b 4.5 a NaN dtype: float64 In [112]: b Out[112]: f 0.0 e 1.0 d 2.0 c 3.0 b 4.0 a NaN dtype: float64 ''' np.where(pd.isnull(a), b, a)# 将a中为空的元素替换为b中对应的元素 # array([ 0. , 2.5, 2. , 3.5, 4.5, nan]) -
b[:-2].combine_first(a[2:])用另一个对象对非缺失值来填补一个对象的缺失值(它检查b[:-2]中的缺失值,并尝试用a中对应位置(即从第三个元素开始)的非缺失值来填充这些缺失值。)(即用新数据为旧数据“打补丁”)
重塑和轴向旋转¶
-
重塑层次化索引
-
利用层次化索引将列转化为行
python ''' number one two three state Ohio 0 1 2 Colorado 3 4 5 ''' result = data.stack() ''' state number Ohio one 0 two 1 three 2 Colorado one 3 two 4 three 5 dtype: int64 '''
-
默认
unstack操作的是最内层,也可以指定分层进行操作result.unstack('state')(stack操作也可以指定) - 在对DataFrame进行unstack操作时,作为旋转轴的级别将会成为结果中的最低级别
长格式与宽格式¶
-
长格式:每行只有一个指标,不同指标分散在多行
-
python Date Item Value 2023-01-01 Revenue 1000 2023-01-01 Expense 800 2023-01-02 Revenue 1500 2023-01-02 Expense 900 -
较为节省空间,不会存储大量的空值
-
data和item作为主键,扩展性较强
-
宽格式:同一时间的观测值出现在同一行
-
进行时间序列分析时更为直观
python Date Revenue Expense 2023-01-01 1000 800 2023-01-02 1500 900
-
长格式转化为宽格式
-
```python import pandas as pd
示例的宽格式DataFrame¶
data = {'Date': ['2023-01-01', '2023-01-02'], 'Revenue': [1000, 1500], 'Expense': [800, 900]} df_wide = pd.DataFrame(data)
id_vars表示保持不变的咧,通常是数据集中唯一标识¶
var_name原本宽格式列名转换后存放的列的名称¶
value_name原本宽格式的值转换后存放的列的名称¶
df_long = df_wide.melt(id_vars=['Date'], var_name='Item', value_name='Value') ''' Date Item Value 0 2023-01-01 Revenue 1000 1 2023-01-02 Revenue 1500 2 2023-01-01 Expense 800 3 2023-01-02 Expense 900 ''' ```
-
宽格式转化为长格式
-
python df_long = pd.DataFrame({ 'Date': ['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02'], 'Item': ['Revenue', 'Expense', 'Revenue', 'Expense'], 'Value': [1000, 800, 1500, 900] }) df_wide = df_long.pivot(index='Date', columns='Item', values='Value') ''' Item Revenue Expense Date 2023-01-01 1000 800 2023-01-02 1500 900 '''
透视表¶
-
pivot_table根据一个或多个键的数据进行分组,然后对每个分组应用聚合函数 -
```python import pandas as pd import numpy as np
# 创建一个示例 DataFrame df = pd.DataFrame({ 'A': ['foo', 'foo', 'foo', 'bar', 'bar', 'bar'], 'B': ['one', 'one', 'two', 'two', 'one', 'one'], 'C': ['small', 'large', 'large', 'small', 'small', 'large'], 'D': [1, 2, 2, 3, 3, 4], 'E': [2, 4, 5, 5, 6, 6] })
# 使用 pivot_table pivot_df = df.pivot_table(values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum) ```
-
values:需要聚合的列
-
index:用作透视表的行索引(用于对数据进行分组)
-
aggfunc:使用的聚合函数
-
Columns:类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
-
比如本例中划分为small和large两列
图像绘制¶
- 使用pandas和seaborn绘图
- seaborn是封装好的更便于使用的matplotlib
- 可以简化使用Series和DataFrame绘制图像
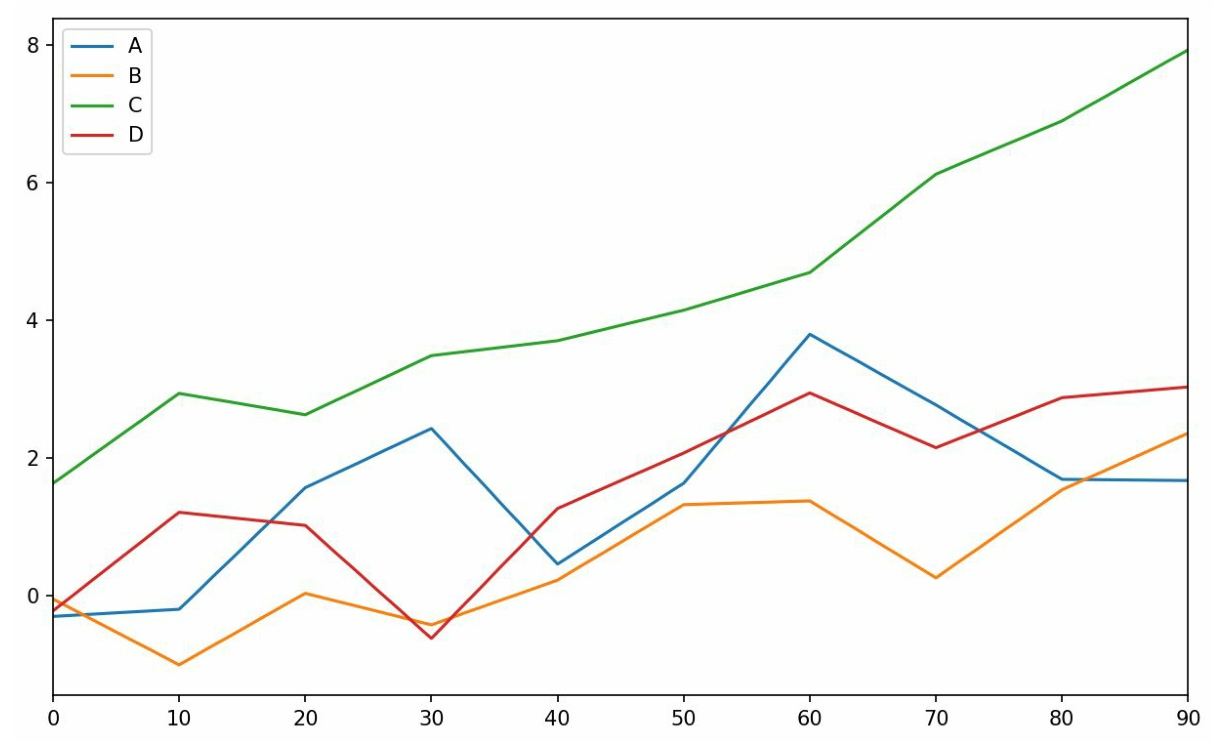
线型图¶
-
使用
plot方法时默认绘制的图象 -
Series有
plot()方法,默认使用索引作为x轴进行绘制 
- DataFrame的plot方法会为每一列绘制一条线并自动创建图例

柱状图¶
plot.bar()水平柱状图,plot.barh水平柱状图- 对于DataFrame默认也会为每一列进行绘制
- 堆积柱状图
stacked=True 
- 使用bins表示分隔的柱形的数目
- seaborn的柱状图
- 可以显示更多的信息,如95%置信区间
sns.barplot(x='tip_pct', y='day', data=tips, orient='h')- 为seaborn设置主题
sns.set(style="whitegrid")
直方图和密度图¶
- 直方图
plot.hist 
- 密度图
.plot.density() -
-
使用seaborn可以同时绘制直方图和密度图
sns.distplot(values, bins=100, color='k')
散点图或点图¶
- 观察两个一维序列之间的关系
sns.regplot('m1', 'unemp', data=trans_data)- 散布图矩阵
- 观察一组变量的散布图
sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2})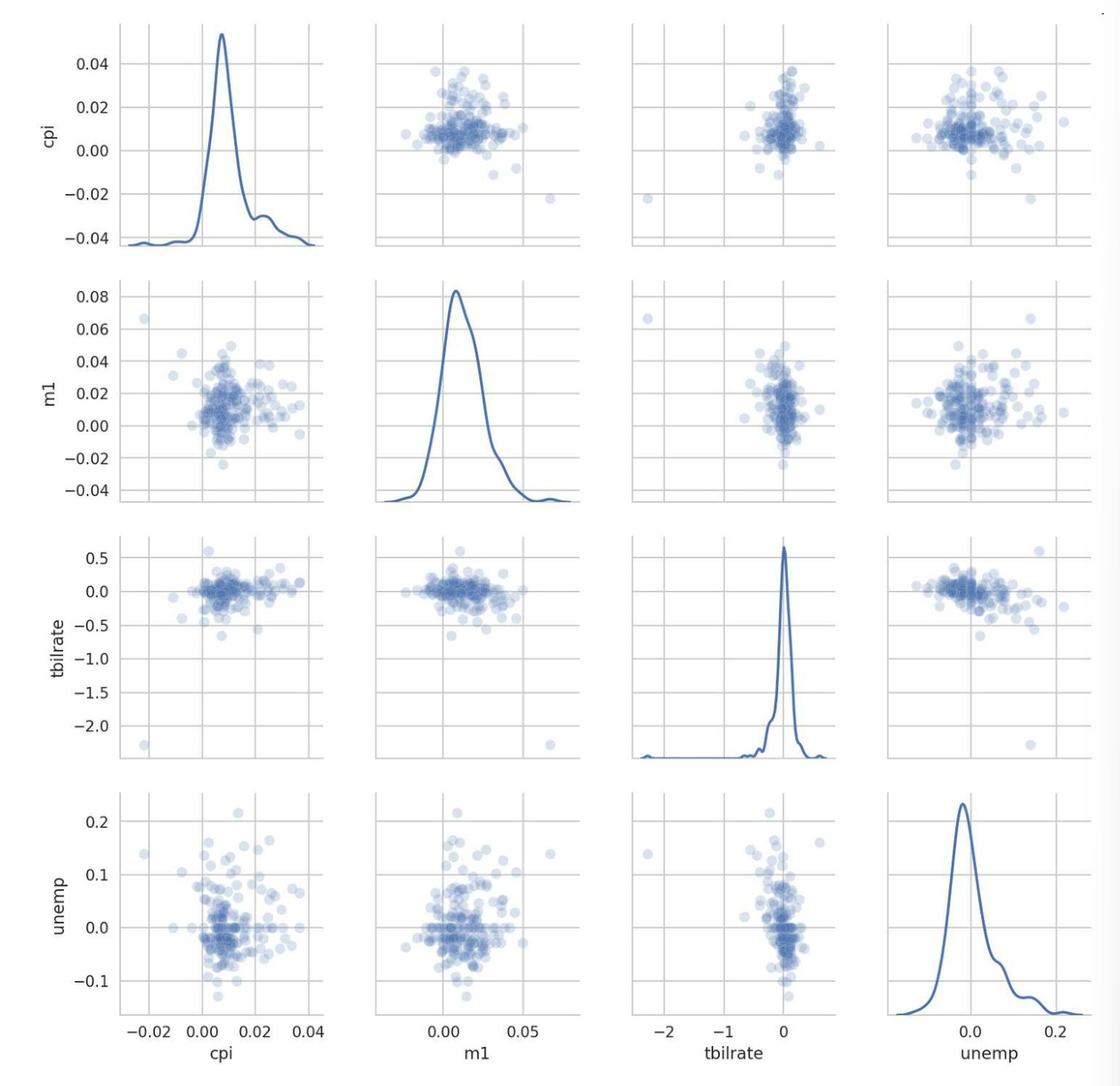
分类统计图¶
-
catplot分类型数据绘图 -
默认为分类散点图
-
ns.catplot(x="day", y="total_bill", data=tips) -
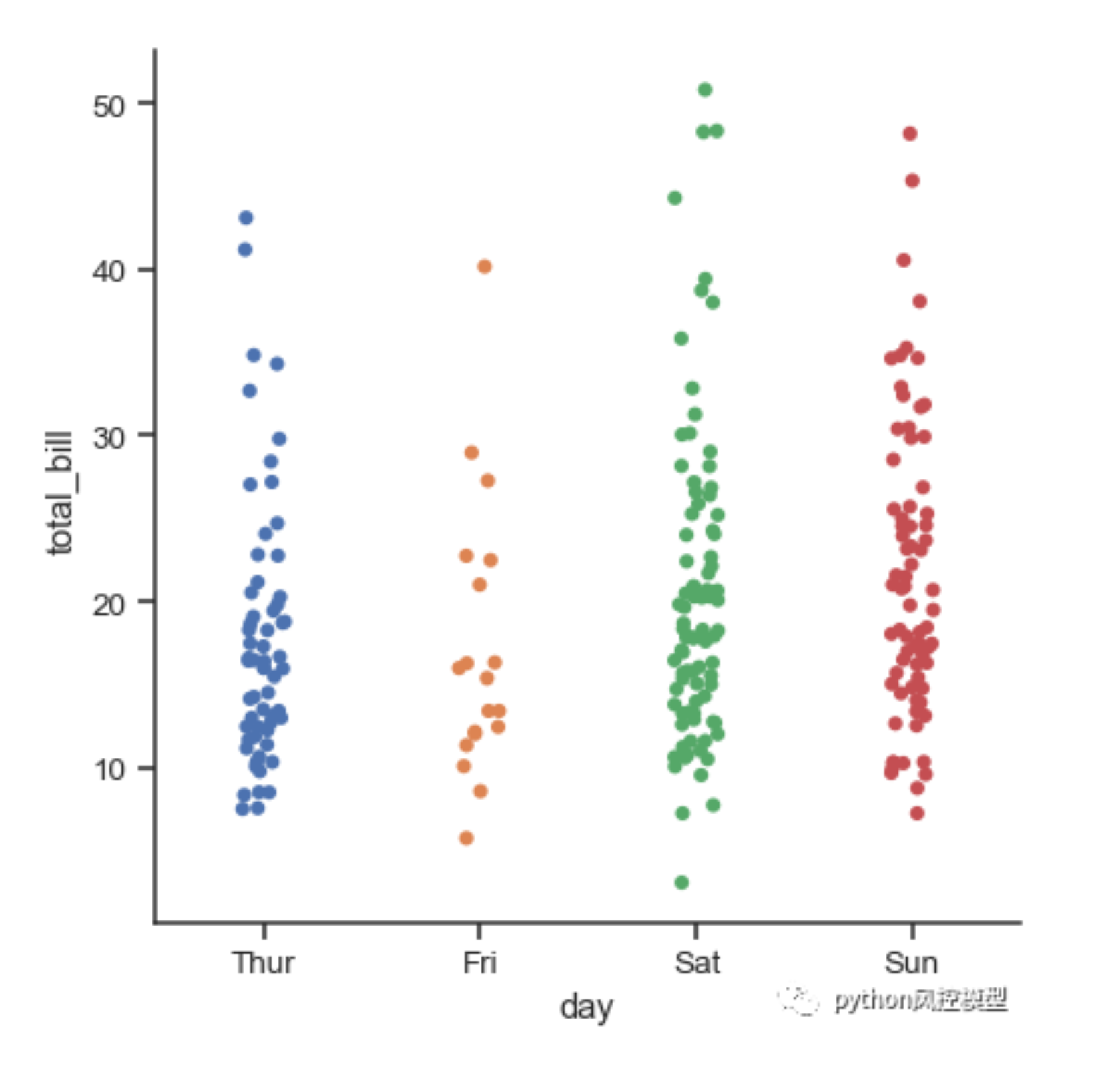
-
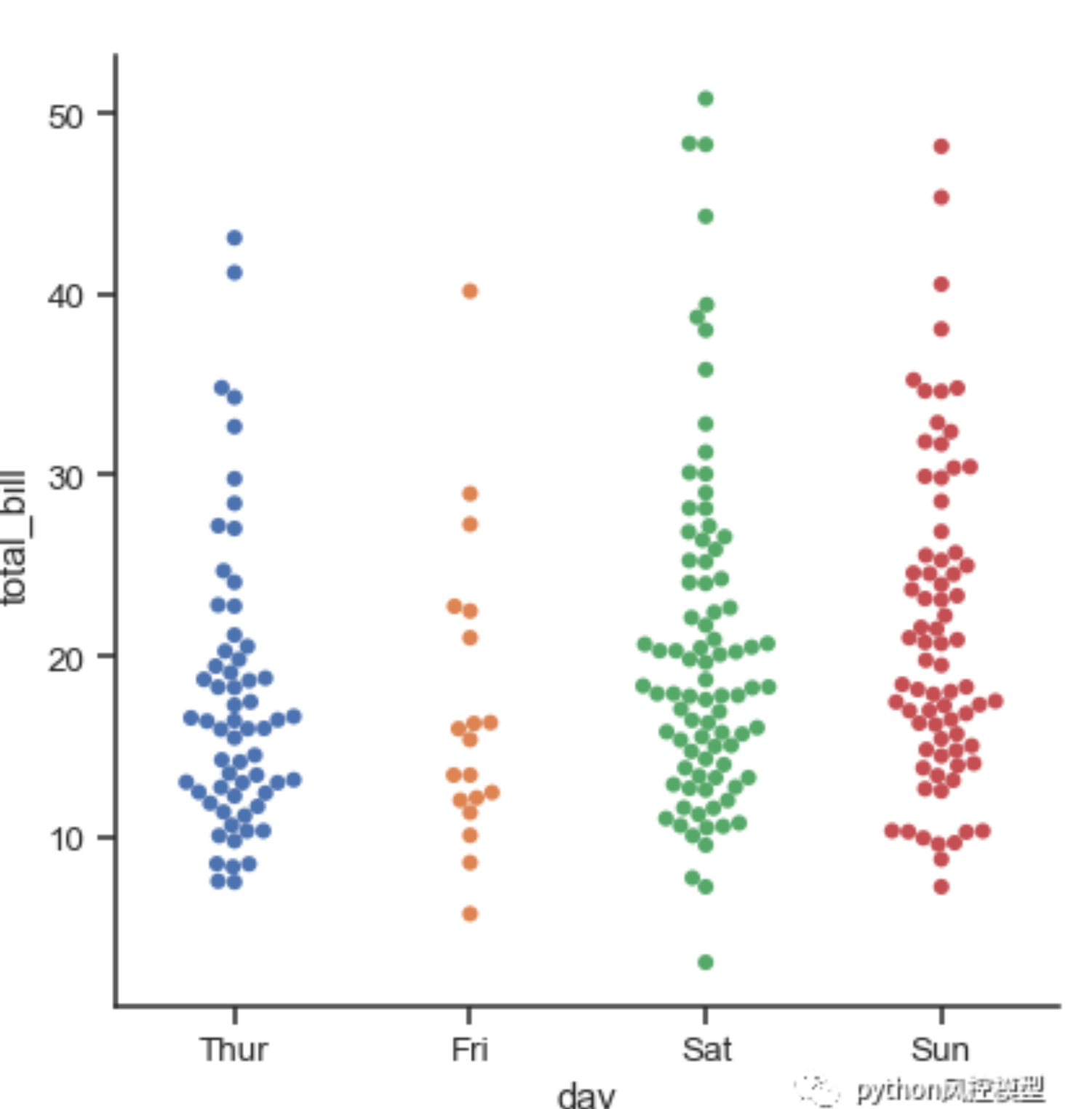
jitter=False禁用随机水平偏移 -
kind="swarm"分散分布 -
箱线图
kind="box" -
小提琴图
kind="violin"
补充¶
数据聚合和分组运算¶
GroupBy机制¶
-
分组-聚合示意
-
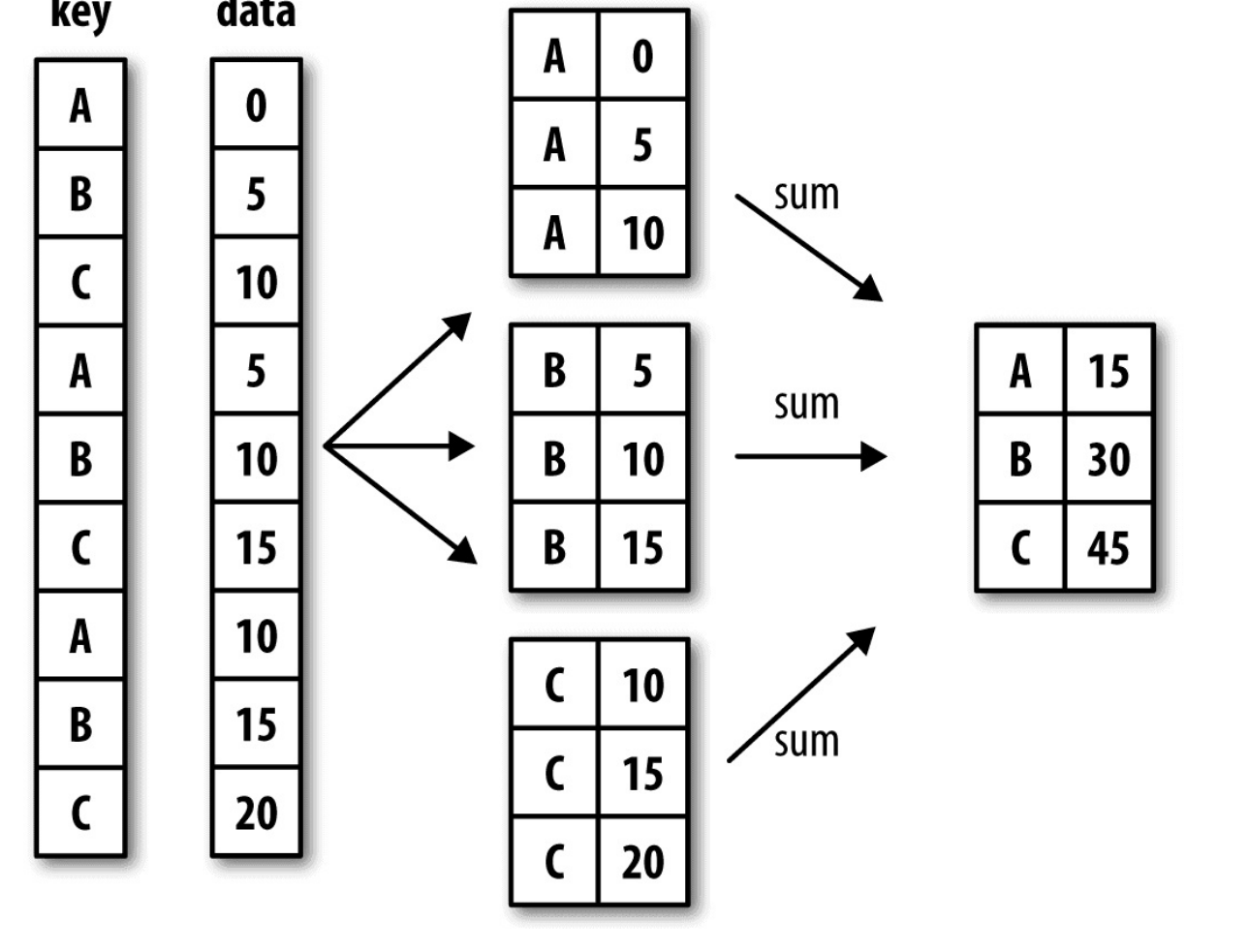
-
grouped = df['data1'].groupby(df['key1'])根据data1对key进行分组,得到一个series,变量grouped是一个GroupBy对象,但它实际上还没有进行任何计算。 -
grouped.mean()计算每一组的平均值,返回一个series -
对多个列进行划分
df['data1'].groupby([df['key1'], df['key2']]).mean(),会得到一个层次化索引python key1 key2 a one 0.880536 two 0.478943 b one -0.519439 two -0.555730 Name: data1, dtype: float64
-
分组键可以是任何长度适当的数组,也不一定要在目标dataframe中
-
获取分组的大小
df.groupby(['key1', 'key2']).size() -
迭代访问分组
-
python for name, group in df.groupby('key1'): ''' a data1 data2 key1 key2 0 -0.204708 1.393406 a one 1 0.478943 0.092908 a two 4 1.965781 1.246435 a one b data1 data2 key1 key2 2 -0.519439 0.281746 b one 3 -0.555730 0.769023 b two ''' -
多重键的情况下返回键的元组
for (k1, k2), group in df.groupby(['key1', 'key2']): -
选取分组后的部分结果
-
python df.groupby('key1')['data1'] # df['data1'].groupby(df['key1']) -
通过字典或Series进行分组
- 输入一个{列键:标签}的字典进行分组
- Series也可以起到相同的作用
- 通过函数进行分组
- 任何被当做分组键的函数都会在各个索引值上被调用一次,其返回值就会被用作分组名称
-
如传入len函数
people.groupby(len).sum() -
根据索引级别分组
- 根据轴索引的一个级别进行聚合
hier_df.groupby(level='cty', axis=1)
数据聚合¶
-

-
使用自定义的聚合方法
-
python def peak_to_peak(arr): return arr.max() - arr.min() grouped.agg(peak_to_peak) -
面向列的多函数应用
-
可以一次执行多个(内置/自定义)操作
grouped_pct.agg(['mean', 'std', peak_to_peak]) -
生成的列会用相应的函数名命名
python mean std peak_to_peak day smoker Fri No 0.151650 0.028123 0.067349 Yes 0.174783 0.051293 0.159925 Sat No 0.158048 0.039767 0.235193 Yes 0.147906 0.061375 0.290095 Sun No 0.160113 0.042347 0.193226 Yes 0.187250 0.154134 0.644685 Thur No 0.160298 0.038774 0.193350 Yes 0.163863 0.039389 0.151240
-
可以传入(name,func)的元组,为生成列命名
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])
-
对于DataFrame,会自动创建新标题构成层次化结构
- 对原先的每一列使用不同函数进行了多次操作
-
对不同的列使用不同的方法
grouped.agg({'tip_pct' : ['min', 'max', 'mean', 'std'],'size' : 'sum'})(使用字典表示) -
默认情况下会将分组的键作为行标签返回聚合后的结果,可以用
as_index=False关闭 -
设置分组键不和原始索引构成层次化索引
group_keys=False
apply方法¶
-
最通用的GroupBy方法是apply,apply会将待处理的 对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起。
-
作用与Series时会对每一个元素进行操作
-
作用于DataFrame时对每一行/列进行操作
-
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')对groupby后的每一个分组执行top(排序并返回前几项)之后使用concat对结果进行合并- 参数可以写在函数的后面。如
apply(top, n=1, column='total_bill')
- 参数可以写在函数的后面。如
-
分位数和同分析
-
与cut方法结合,对数据进行分箱,然后对每个分箱的数据进行聚合分析
-
python # 依据frame.data1进行分箱 quartiles = pd.cut(frame.data1, 4) # 依据分箱进行分组 grouped = frame.data2.groupby(quartiles) # 对每组进行操作 grouped.apply(get_stats).unstack()
时间序列¶
日期及时间数据类型¶
- python事件类型
from datetime import datetime - 获取当前的时间
datetime.now() - 属性
.year .month .day start + timedelta(12)-

-
字符串与datetime转换
-
python # 直接转换 str(stamp) # '2011-01-03 00:00:00' # 格式化转换 stamp.strftime('%Y-%m-%d') # '2011-01-03' # 格式化字符串转化为时间类型 datetime.strptime(value, '%Y-%m-%d')# 提供字符串和格式 # 自动解析 from dateutil.parser import parse parse('2011-01-03') # dayfirst=True表示日出现在月的前面 parse('6/12/2011', dayfirst=True) -

-
使用pandas处理日期组
pd.to_datetime(datestrs),可以自动处理缺失值
时间序列基础¶
-
基本时间序列:以时间戳为索引的Series
-
根据标签选取数据时可以传入一个任何个是的可以被解释为日期的字符串
python ts['1/10/2011'] ts['20110110'] Out[51]: 1.9657805725027142
-
也可以只传入部分数据如年、年月获取对应的分组
-
也可以使用时间区间获取
ts['1/6/2011':'1/11/2011'] -
带有重复索引的时间序列
-
检查
.index.is_unique - 对Series进行索引,如果存在重复时间则会返回一个切片(有多项)
-
对重复时间项进行聚合
grouped = dup_ts.groupby(level=0)对相同时间进行切片,再grouped.mean() -
生成日期范围
- 可以作为其他数据的index
pd.date_range('2012-04-01', '2012-06-01'),默认情况下按照天生成- 设置间隔
freq=BM 

- 设置间隔
- 默认会保留开始和结束的时间信息
- 也可以只传入开始/结束时间加上天数
periods=20 -
normalize=True标准化时间,去除时分秒(改为0点) -
频率和日期偏移量
-
from pandas.tseries.offsets import Hour, Minute -
缩写应用于时间序列的生成
pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4h')2h30min也可以被解析
-
通过偏移量进行偏移
-
now + 3 * Day() -
锚点偏移(如移动到月底)
now + MonthEnd() -
另一种语法
-
python offset = MonthEnd() offset.rollforward(now) Timestamp('2011-11-30 00:00:00')
-
-
WOM日期
-
非常实用的频率类,如每月第三个星期5
WOM-3FRI -
移动数据
-
移动指的是沿着时间轴将数据前移或后移。
-
python ''' 2000-01-31 -0.066748 2000-02-29 0.838639 2000-03-31 -0.117388 2000-04-30 -0.517795 Freq: M, dtype: float64 ''' ts.shift(2) ''' 2000-01-31 NaN 2000-02-29 NaN 2000-03-31 -0.066748 2000-04-30 0.838639 Freq: M, dtype: float64 ''' -
对时间戳进行移位
ts.shift(2, freq='M')- 要求频率已知
时期及算数运算¶
-
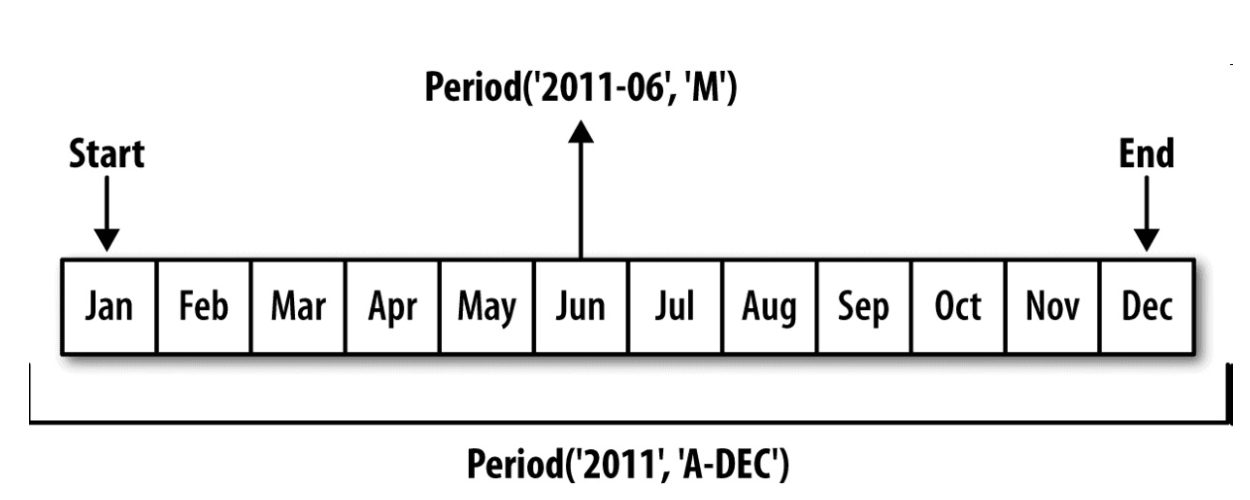
时间区间(时期)的表示
-
pd.Period(2007, freq='A-DEC')表示2007这一年整段时间 - 可以及逆行运算如+2,对时间区间进行偏移
-
两个频率相同的时期可以运算,得到的见过是单位数量
-
时期序列
PeriodIndex -
通过端点根据频率自动创建
pd.period_range('2000-01-01', '2000-06-30', freq='M') -
由数组转化
python values = ['2001Q3', '2002Q2', '2003Q1'] index = pd.PeriodIndex(values, freq='Q-DEC')
-
时期的频率转化
-
python # 将年转化为月 p = pd.Period('2007', freq='A-DEC') p.asfreq('M', how='start') # Period('2007-01', 'M') p.asfreq('M', how='end') # Period('2007-12', 'M') -
低频转高频时要注意,对于
A-JUN2007.8实际上属于2008 -
按极度计算时期频率
-
在以1月结束的财年中,2012Q4是从11月到1月
-
python pd.Period('2012Q4', freq='Q-JAN') # 转化为日频率 p.asfreq('D', 'start') # Period('2011-11-01', 'D') p.asfreq('D', 'end') # Period('2012-01-31', 'D') -
将时间戳转化为时期
-
通过使用
to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引 -
python rng = pd.date_range('2000-01-01', periods=3, freq='M') ts = pd.Series(np.random.randn(3), index=rng) pts = ts.to_period() -
一个时间戳只能属于一个时期,新的periodindex是从时间戳错推断出来的,转化后可能存在重复项
-
python 2000-01-29 0.244175 2000-01-30 0.423331 2000-01-31 -0.654040 2000-02-01 2.089154 2000-02-02 -0.060220 2000-02-03 -0.167933 \ 2000-01 0.244175 2000-01 0.423331 2000-01 -0.654040 2000-02 2.089154 2000-02 -0.060220 2000-02 -0.167933 -
使用
to_timestamp转化会时间戳 -
通过数组创建
PeriodIndex -
有些数组会将时间拆分(比如年和月在不同的列)
- 可以分别传入
pd.PeriodIndex(year=data.year, quarter=data.quarter,freq='Q-DEC')
重采样及频率转换¶
- 将时间序列从一个频率转换到另一个频率的处理过程
- 将高频率数据聚合到低频率称为降采样
- 将低频率数据转换到高频率则称为升采样
- 使用
resample方法转换频率,如ts.resample('M').mean() 
降采样¶
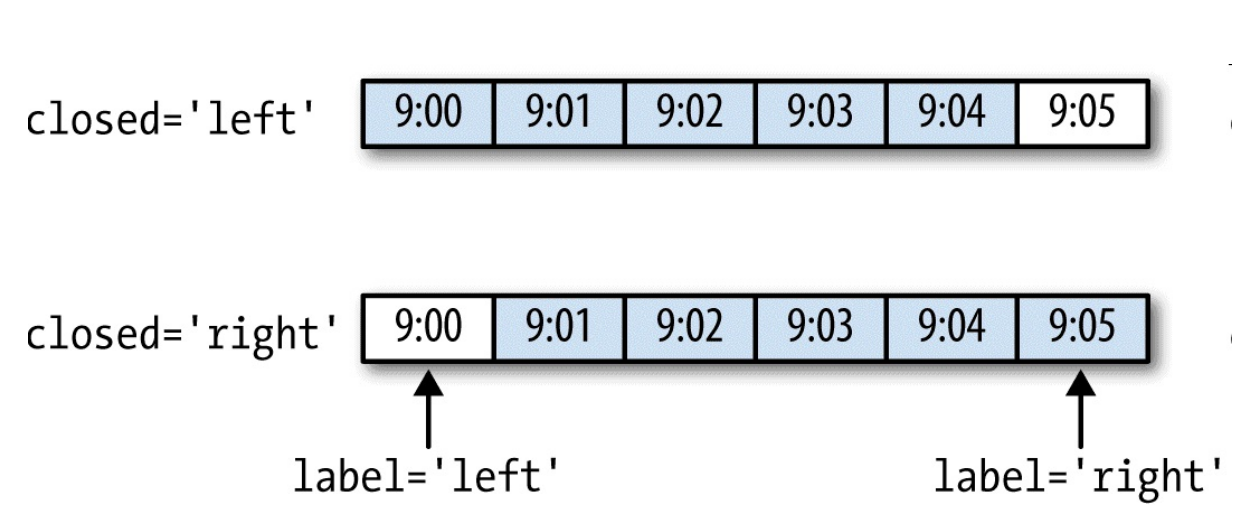
-
python ''' 2000-01-01 00:00:00 0 2000-01-01 00:01:00 1 2000-01-01 00:02:00 2 2000-01-01 00:03:00 3 2000-01-01 00:04:00 4 2000-01-01 00:05:00 5 2000-01-01 00:06:00 6 2000-01-01 00:07:00 7 2000-01-01 00:08:00 8 2000-01-01 00:09:00 9 2000-01-01 00:10:00 10 2000-01-01 00:11:00 11 ''' ts.resample('5min', closed='right').sum() ''' 1999-12-31 23:55:00 0 2000-01-01 00:00:00 15 2000-01-01 00:05:00 40 2000-01-01 00:10:00 11 ''' -
可以添加偏移
loffset='-1s'
OHLC重采样¶
- (open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低)
升采样¶
frame.resample('D').asfreq().asfreq()方法是用来实现索引的频率转换的,不进行任何聚合操作。当使用.asfreq()时,它会在新频率的每个时间点上放置一个数据点,如果在原始数据中没有对应的数据,那么会插入一个NaN值。这可以帮助保持数据的连续性。- 从左侧填充
frame.resample('D').ffill()
时期重采样¶
- 降采样
frame.resample('A-DEC').mean()如可以直接对重复项取平均值- 升采样
- 要指定在新频率中各区间的哪端用于放置原来的值
convention='end'
- 由于时期指的是时间区间,所以升采样和降采样的规则就比较严格:
- 在降采样中,目标频率必须是源频率的子时期
- 在升采样中,目标频率必须是源频率的超时期
- 如果你开始于一个以3月结束的季度,那么在转换到年度数据时,年度区间也应该以3月结束,以保持时间区间的一致性。
- 年度(A或Y)、季度(Q)和月度(M)
移动窗口函数¶
- 使用rolling函数,默认要求窗口中所有值为非NA值
close_px.AAPL.rolling(250).mean().plot()- 也使用时间序列时也可以传递一个时期
20D这样就会计算20天的平均值(you几个算几个)
- 也使用时间序列时也可以传递一个时期
- 对DataFrame调用会自动应用到所有列上
- Rolling:计算一个固定大小窗口的统计数据,如均值、标准差等,窗口在数据索引中滑动。(窗口长度固定)
-
Expanding:计算一个从开始逐渐扩大至整个数据的窗口的统计数据,窗口大小从1逐渐增长到整个数据长度。(窗口长度逐渐增大)
-
指数加权函数
-
定义一个衰减因子,使得近期的观测值会有更大的权数
-
使用ewm替代rolling
-
二元移动窗口函数
-
关系数和协方差等需要在两个时间序列上执行
-
python # 使用pct_change()方法计算了标普500指数的每日百分比变化 spx_rets = spx_px.pct_change() # 对其他证券(在这个例子中是close_px变量代表的股票或资产)也进行了同样的百分比变化计算 returns = close_px.pct_change() corr = returns.AAPL.rolling(125, min_periods=100).corr(spx_rets) -
只需传入一个TimeSeries和一个DataFrame,rolling_corr就会自动计算TimeSeries(本例中就是spx_rets)与DataFrame各列的相关系数。
-
用户自定义函数
-
要求:自定义函数能从数组片段产生单个值
- 如
returns.AAPL.rolling(250).apply(score_at_2percent)