基本语法¶
基本操作¶
补充¶
- pass写在语句块中,告诉程序该语句块中什么都不需要做(可以用于抽象类的函数中)
注释¶
- 单行:用#开头表示
- 多行"""..."""
输入输出¶
- 输出:print()
- 输入:
text=input('提示文本') - 参数用于显示,对用户提示,返回用户的输入内容(以字符串的格式返回)
编译执行¶
- python是一种解释型脚本语言,和C/C++语言不同,C/C++程序从main函数开始执行,python程序从开始到结尾顺序执行。
- 可以用
if __name__ == '__main__':表示main函数,即程序的入口
分文件编程¶
- 导入模块
import name导入name.py- 使用函数
name.f()需要添加模块名称许作为前缀 - 导入函数
from 文件名 import 函数名,...可以一次导入多个函数- 用*替代函数名可以导入全部函数
-
使用函数无需添加限定,可以直接使用
-
导入类:语法与函数类似
-
as指定别名
- import引入的函数或模块名称后面添加
as name
文件读写¶
读取¶
-
读取整个文件
-
python with open('path') as name: contents=name.read() -
with关键字可以实现文件访问完成后自动关闭
- 也可以用close()手动关闭
- open得到的文件对象只可以在with内部使用
-
这样读取的文件末尾会有一个空行,可以用rstrip去除
-
open模式:
open('path','模式')- w写入
- r读取(默认)
- a附加
- r+读写
-
如果要写入的文件不存在,则会自动创建文件
-
逐行读取
-
python with open('path') as name: for line in name: ... -
提取出每一行,分别进行操作
- 由于每行末尾有换行符,文件末尾会有一个空行,可以用rstrip去除
-
读取到列表
arr=name.readlines()
写入¶
- 全部写入
name.write(...) - 不会自动在每次写入的字符串后添加换行符,可以手动添加/n
- 只能写入字符串;类型
使用json存储数据¶
-
先引入
import json -
写入
-
python with open('path.json','w') as name: json.dump(写入内容, name) -
可以写入非字符串数据类型
-
读取
-
numbers=json.load(name)
异常处理¶
-
try-except-else系统
-
程序发生异常时会抛出一个异常对象
-
可以进行捕获
-
python try: print(5/0)#可能出现异常的部分 except ZeroDivisionError:#捕获异常对象 ...#发生异常进行的操作 else: ....#不发生异常进行的操作 -
异常
-
ZeroDivisionError除数为零
-
FileNotFoundError找不到文件(open触发)
-
断言
-
python import unittest class test(unittest.TestCase):#继承 def name(self):#通过调用测试类内的测试函数来使用断言 self.#调用继承的断言函数 -

数据类型¶
变量¶
- 给多个变量同时赋值
a,b,c=0,0,0- python没有常量,通常可以用全部大写的名称来表示
- None表示变量没有值
- 输出类型
type(name) - 检查是否是特定类型的实例
isinstance(name,type) - 比较是否指向同一个对象
a is b
字符串str¶
- 可以使用单引号或双引号括起来
- 不可修改:
- 可以转化为列表再修改
- 可以通过切片实现
操作¶
- 内容修改(只是临时,不会对原字符串产生影响)
title():转化为首字母大写upper()lower()rstrip():去掉尾部的空格(也可以传入指定字符用于删除)lstrip():去掉头部的空格strip():去掉头尾部的空格
split()以空格切割字符串返回列表join()拼接字符串'sep'.join(seq)- sep:分隔符。可以为空
- seq:要连接的元素序列、字符串、元组、字典
ord()返回ascll码chr()将数字转化为ascll或Unicode码-
reversed()反转 -
在字符串中使用变量的值:f字符串
f"Hello,{first_name}"f""包住,会将或括号内的变量转化为字符串来显示-
使用原始字符串(免转义)
-
s = r'this\has\no\special\characters' -
格式化字符串
-
python template = '{0:.2f} {1:s} are worth US${2:d}' template.format(4.5560, 'Argentine Pesos', 1) # '4.56 Argentine Pesos are worth US$1' - {0:.2f} 表示格式化第一个参数为带有两位小数的浮点数。
- {1:s} 表示格式化第二个参数为字符串。
-
{2:d} 表示格式化第三个参数为一个整数。
-
指定字符串的解码类型
-
python val_utf8.decode('utf-8') val.encode('utf-16') -
查找:
.find("要查找的内容"[,开始位置,结束位置]) - ```python 字符串.isalnum() 所有字符都是数字或者字母,为真返回 Ture,否则返回 False。 字符串.isalpha() 所有字符都是字母,为真返回 Ture,否则返回 False。 字符串.isdigit() 所有字符都是数字,为真返回 Ture,否则返回 False。 字符串.islower() 所有字符都是小写,为真返回 Ture,否则返回 False。
字符串.isupper() 所有字符都是大写,为真返回 Ture,否则返回 False。
字符串.istitle() 所有单词都是首字母大写,为真返回 Ture,否则返回 False。
字符串.isspace() 所有字符都是空白字符,为真返回 Ture,否则返回 False。
```¶
数字¶
- 两个数相除时结果总会是浮点数,即使结果是一个整数
- 数字很大时可以使用下划线分隔来便于阅读,系统在存储数据时会自动去除
age=14_000_000- int边界值
sys.maxsize最大值(inf)-sys.maxsize-1最小值
布尔¶
- 首字母大写:True False
列表list¶
- 用
[,...,]表示 - 索引值-1指向最后一个元素,-2表示倒数第二个元素...
- 末尾添加元素
append(val) - 与del不同的的是pop会返回删除的内容
extend()方法向一个列表的尾部追加另一个列表的所有元素。(等同于直接用+相加)- 插入元素
insert(p,val) - 删除元素
pop(i)不填写参数时默认删除最后一个元素- 删除元素
del arr[i]删除第i个元素 remove(val)根据值删除元素,只删除符合的第一个值,并且也有返回值- 列表解析:用for循环创建新列表
arr=[value**2 for value in range(1,11)]依次执行表达式创建元素- 可以用于创建二维列表
arr = [[0] * (m) for _ in range(n)]
- 创建相同元素:[None]*26
- 截取片段:
arr[begin:end[:step]]与range类似 - begin默认为0,end默认为末尾可以省略
- [-3:0]或[-3:]表示遍历最后三个元素
- [::-1]实现颠倒
- 复制
- 直接
arr2=arr是浅拷贝 arr2=arr[:]可以实现深拷贝- 获取最大最小的元素列表
nlargest(n , iterbale, key=None)获取序列中最大的n个元素nsmallest(n , iterbale, key=None)- 搜索元素
-
使用
in查询元素是否在列表中 -
支持使用+合并列表(创建一个新列表)
- 也可以使用
x.extend([7, 8, (2, 3)])
操作¶
- 排序
sort():对列表进行修改(只能用于列表,是列表的成员函数)- 使用参数key实现自定义比较
functools.cmp_to_key(my_compare)也可以使用函数把比较函数转化为key- key表示以什么为基准来进行比较
key = lambda x:(-x[0],x[1])表示优先按照x[0]逆序比较,x[0]相同时按x[1]比较- lambda表达式:
add = lambda x,y:x+y声明变量和和操作(返回值) - 传入参数
reverse=True降序排列
-
sorted():不修改,以返回值的形式返回 -
reverse():颠倒数组 -
len():获取数组长度 -
min(arr)max(arr)sum(arr) -
set(arr):返回一个不包含重复元素的列表(集合) -
查找元素
listname.count(obj, start, end)常用于查找元素是否存在-
listname.index(obj, start, end)返回元素所在的下标,如果不存在则会报错 -
二分搜索
-
bisect 模块支持二分查找,和向已排序的列表插入值。 bisect.bisect 可以找到插入值后仍保证 排序的位置, bisect.insort 是向这个位置插入值:
-
python import bisect c = [1, 2, 2, 2, 3, 4, 7] bisect.bisect(c, 5) # 6 bisect.insort(c, 6) # [1, 2, 2, 2, 3, 4, 6, 7] -
切片
-
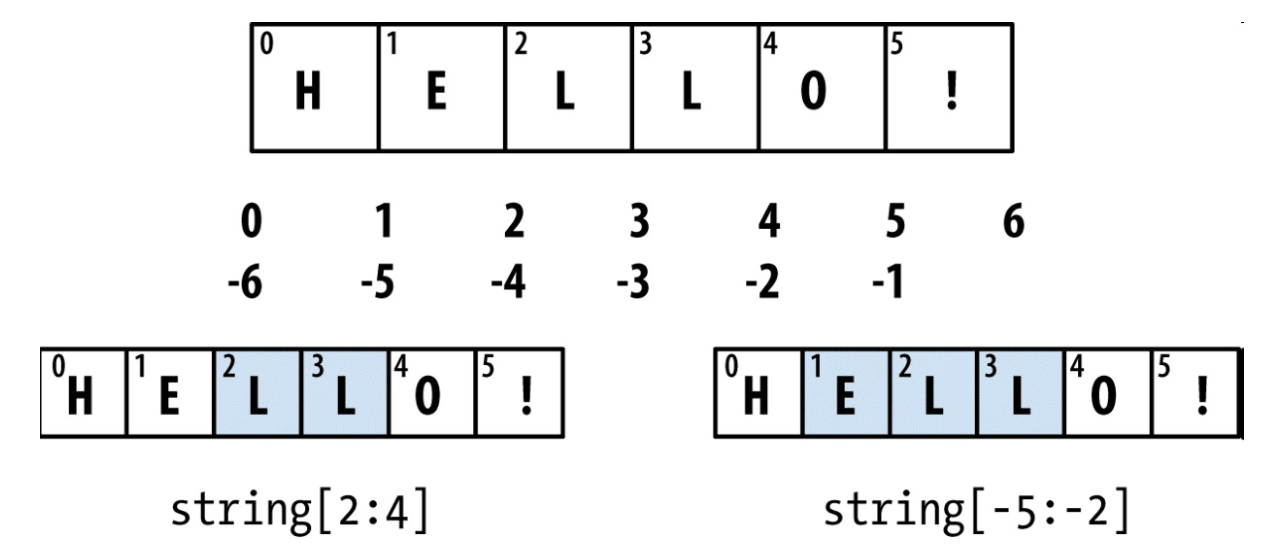
-
python seq = [7, 2, 3, 7, 5, 6, 0, 1] seq[1:5] # 设置步长 seq[::-1]#颠倒返回 -
zip 可以将多个列表、元组或其它序列成对组合成一个元组列表:
-
元素的个数取决于最短的序列
-
python seq1 = ['foo', 'bar', 'baz'] seq2 = ['one', 'two', 'three'] seq3 = [False, True] list(zip(seq1, seq2, seq3)) [('foo', 'one', False), ('bar', 'two', True)] -
可以用于迭代多个序列
-
解压
first_names, last_names = zip(*pitchers) -
列表推导式
-
[expr for val in collection if condition] - 过滤出长度在2及以上的字符串,并将其转换成大写
[x.upper() for x in strings if len(x) > 2] -
字典推导
{val : index for index, val in enumerate(strings)} -
嵌套列表推导式
-
python for names in all_data: enough_es = [name for name in names if name.count('e') >= 2] names_of_interest.extend(enough_es) # 转化为 [name for names in all_data for name in names if name.count('e') >= 2] -
for表达式的顺序是与嵌套for循环的顺序一样
-
python [x for tup in some_tuples for x in tup] for tup in some_tuples: for x in tup: flattened.append(x) #也可以写为 [[x for x in tup] for tup in some_tuples] -
对每一项执行操作
apply_to_list(ints, lambda x: x * 2)
元组tuple¶
-
不可变的列表称为元组
-
使用()取代[]来定义,也可以省略括号
tup=1,2,3 -
将序列、迭代器转化为元组
tuple([4,0,2]) -
运算
-
```python In [13]: (4, None, 'foo') + (6, 0) + ('bar',) Out[13]: (4, None, 'foo', 6, 0, 'bar')
In [14]: ('foo', 'bar') * 4 Out[14]: ('foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'bar') ```
-
拆分
-
python tup = 4, 5, (6, 7) a, b, (c, d) = tup # 甚至可以这么用 b, a = a, b -
可以很方便的用于循环获取每一项
-
可以用于多返回值
字典dict¶
- 初始化
map={键:值,...},赋值新增操作与c++类似 - 记录顺序与元素插入的顺序相同
- 创建空字典:使用{}
map={} - 删除元素:使用del关键字
- 使用下标访问不存在的元素时会报错
- 可以使用
get()不存在时返回None - 排序:
table = dict(sorted(table.items(), key=lambda item: item[1][1], reverse=True)[0:4])排序并提取前四项- 字典的键要求是不可变的标量类型或元组,有可哈希性
操作¶
.items():返回键值对列表-
可以用于实现按照下标编号访问
self.booked.items()[i - 1][1] -
.keys():返回键的列表(用for遍历字典时的默认行为) -
.values():遍历所有值 -
clear():请空元素 -
合并字典
d1.update({'b' : 'foo', 'c' : 12}) -
update 方法是原地改变字典,因此任何传递给 update 的键的旧的值都会被舍弃。
-
dict可以接受二元元组的列表
-
python mapping = dict(zip(range(5), reversed(range(5)))) -
有默认返回值的访问
some_dict.get(key, default_value) -
python for word in words: letter = word[0] if letter not in by_letter: by_letter[letter] = [word] else: by_letter[letter].append(word) # 化简代码 for word in words: letter = word[0] by_letter.setdefault(letter, []).append(word) -
setdefault方法用于获取字典中指定键(key)的值,如果该键不存在于字典中,就会将该键及一个默认值设置到字典中。
集合set¶
- 可以用
set={键,...}直接创建集合,或setname = set(iteration),会自动去重
操作¶
-
删除
remove(i)元素不存在时会报错,discard(i)元素不存在时不会报错 -
使用 add() 方法添加的元素,只能是数字、字符串、元组或者布尔类型(True 和 False)值,不能添加列表、字典、集合这类可变的数据
-
不同set间可以使用&|-^运算
-
判断子/父集
-
python {1, 2, 3}.issubset(a_set) a_set.issuperset({1, 2, 3})
类型转化¶
int()float()
运算¶
- **表乘方(用10**n代替1e9,1e9是分数)
- /会返回浮点数
- //取整除法
作用域¶
- 没有块级作用域,局部变量以整个函数为作用域
- 局部变量:在函数内部定义的变量,它的作用域也仅限于函数内部,出了函数就不能使用了
-
nonlocal在封装函数中使用,使得变量可以在外部函数中使用,或者也可以用于声明访问外部变量(可以修改值) -
全局变量
- 在函数外定义或者使用
global修饰局部变量 -
在函数内只能获取全局变量,对全局变量赋值会默认产生一个同名的局部变量
-
可以使用global声明要求使用全局变量
-
```python package_in = 10
def func(): global package_in package_in += 1 ```
- 函数外定义,函数内声明之后再使用
-
操作流¶
- for
- 遍历数组:
for x in arr:- 生成的x是副本,不会对原列表修改
- 计数
for i in range(1,5)i取值1234- range(x,y)可以用于创建数组(不包含y)
range(start, stop, [step])倒序如range(5,-1,-1)- 注意不包括stop
- 遍历字典:
for key, value in map.items)():- 按照插入顺序返回元素
- 不加item时只取出键
- enumerate(words)遍历列表、字典(与item类似,但可以用于列表)
- 返回(下标,数值)
for i, word in enumerate(words):
- if
if a==num:- and表示&& or表示|| not表示!
- 判断元素是否在列表中使用in关键字
- 不在使用not in
- elif表示else if
- 三元运算符
maxNum = a if a > b else b - while
while a==num:breakcontinue- any
- any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
if any(l < end and start < r for l, r in self.booked):
函数¶
- 定义:
def f(): - 列表默认传参是浅拷贝
- 可以传递副本
arr[:]实现深拷贝 - 传递任意数目的实参
def f(*arr)会创建一个空元组并将所有实参存入- 常用名称*args
def f(**arr)创建一个字典用于存储数据,允许修改- 可以用逗号分隔返回多个值
- 如
a,b=dfs()
拷贝¶
- 大多数情况下python中默认是浅拷贝
- 使用
copy.deepcopy(x)可以实现深拷贝
类¶
- 定义:
class Name:类名通常首字母大写 - 类中方法(函数)的第一个参数为self由系统自动传入,是一个指向实例本身的引用
- self.前缀定义的变量可以供类中所有方法使用(类似成员变量)
- 创建实例:
a=A()使用构造函数来生成r - 访问属性和方法
.
类的特殊成员¶
-
Python类的特殊方法又称为魔术方法,它是以双下划线包裹一个词的形式出现
-
__init__()(与__new__()) -
_new__是用来构造实例的,而__init__只是用来对返回的实例进行一些属性的初始化
-
但通常只使用init就足够了()可以近似当成构造函数来使用
-
__ del__:析构函数 -
__enter__与__exit__就是实现with的类特殊方法。 -
__str__与__repr__将类转化为字符串进行输出 -
其中str用于print输出
-
repr只要输入实例名就可以(pandas就是这样)
-
__call__类做函数(重载()) -
__ contains____ len__ -
contains:给类增添
if in用法 -
len:增添
len() -
运算符重载
-
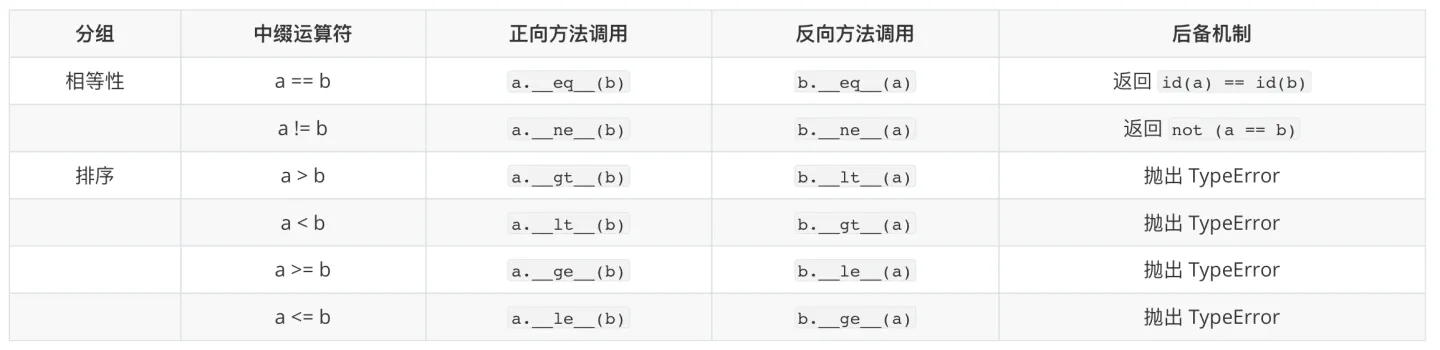
-
运算 代码 特殊方法 加法 a+b __ add__ 减法 a-b __ sub__ 乘法 a*b __ mul__ 除法 a/b __ truediv__ 整除 a//b __ floordiv__ 取余 a%b __ mod__
继承¶
class Son(Father):末尾添加括号super().前缀用于访问父类的方法和属性
异常处理¶
-
可能发生错误的语句放在try模块里,用except来处理异常。
-
首先执行 try 中的代码块,如果执行过程中出现异常,系统会自动生成一个异常类型,并将该异常提交给 Python 解释器,此过程称为捕获异常。
-
当 Python 解释器收到异常对象时,会寻找能处理该异常对象的 except 块,如果找到合适的 except 块,则把该异常对象交给该 except 块处理,这个过程被称为处理异常。如果 Python 解释器找不到处理异常的 except 块,则程序运行终止,Python 解释器也将退出。
-
python try: 可能产生异常的代码块 except [ (Error1, Error2, ... ) [as e] ]: 处理异常的代码块1 except [ (Error3, Error4, ... ) [as e] ]: 处理异常的代码块2 except [Exception]: 处理其它异常 -
raise:自行引发错误raise ValueError('score must between 0 ~ 100!')
装饰器¶
- 就是在特定条件下为某些函数再不改动函数体的时候为函数新添加一些功能,这就是装饰器
- 基于@语法和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内置函数),执行函数时再在内层函数中执行闭包中的原函数
内置装饰器¶
@decorator写在函数前面,当函数被调用时会打印输出
函数转化为成员进行控制¶
-
@property:我们可以使用@property装饰器来创建只读属性,@property装饰器会将方法转换为相同名称的只读属性(函数->属性) -
```python class DataSet(object): @property def method_with_property(self): ##含有@property return 15 def method_without_property(self): ##不含@property return 15
l = DataSet() print(l.method_with_property) # 加了@property后,可以用调用属性的形式来调用方法,后面不需要加()。 print(l.method_without_property()) #没有加@property , 必须使用正常的调用方法的形式,即在后面加() ```
-
@\*.setter@*.setter装饰器必须在@property装饰器的后面,且两个被修饰的函数的名称必须保持一致,* 即为函数名称。 -
作用:对要存入的数据进行预处理;设置可读属性(不可修改)。
-
当对变量赋值时会自动进行调用
-
```python @property def score(self): return self._score
@score.setter def score(self, value): if value < 0 or value > 100: raise ValueError('score must between 0 ~ 100!') self._score = value```
-
@deleter可以通过del s.score来轻松删掉原来的值了 -
python @score.deleter def score(self): del self._score
标准库¶
类¶
datetime¶
-
python from datetime import datetime, date, time dt = datetime(2011, 10, 29, 20, 30, 21) -
直接访问属性
dt.day dt.minute -
也可以提取date和time
at.date() -
生成格式化字符串
dt.strftime('%m/%d/%Y %H:%M') -
转化字符串
datetime.strptime('20091031', '%Y%m%d') -

-
修改
dt.replace(minute=0, second=0) -
实际上产生了一个新对象
-
支持做差等运算
容器¶
Counter¶
- Counter 是 dict 字典的子类,Counter 拥有类似字典的 key 键和 value 值
- 如果要使用 Counter,必须要进行实例化,在实例化的同时可以为构造函数传入参数来指定不同类型的元素来源(从 string(字符为list列表的元素)、list 和 tuple 这些可迭代对象中获取元素。)。
x = Counter()- 自动统计列表中个元素的数目
- 如果在 Counter 中查找一个不存在的元素,不会产生异常,而是会返回 0
方法¶
- elements 方法:可以通过 list 或者其它方法将迭代器中的元素输出,输出的结果为对应出现次数的元素。
print(list(c.elements()))most_common([n])是 Counter 最常用的方法,返回一个出现次数从大到小的前 n 个元素的列表。- most_common()[]
- subtract:将两个 Counter 对象中的元素对应的计数相减。
c.subtract(d):两个字典相减
collections.deque¶
- 初始化
q = collections.deque([]) - 添加元素
q.append"()q.appendleft() - 按照列表顺序添加多个元素:
extend([])extendleft() - 删除元素
q.pop()q.popleft() - 获取元素,直接下标访问,如
q[0]
collections.heapq堆¶
-
建立堆:(默认为小顶堆,可以通过取负数实现大顶堆)
-
heapq.heappush(heap, item):向堆内添加元素,如果不是堆会自动转化为堆 -
heapq.heapify(list):将列表转化为堆 -
heapq.heappop(heap)弹出并返回元素 -
可以使用下标访问
-
不支持自定义比较,可以用类来包装数据,在类中重载比较运算符号
-
python class P(): def __init__(self,a,b): self.a = a self.b = b def __lt__(self, other):#重载<运算符 if self.b<other.b: return True else: return False
queue¶
-
from queue import PriorityQueue需要引入 -
分类
- queue.Queue 先进先出队列
- queue.LifoQueue 后进先出队列(栈)
- queue.PriorityQueue 优先级队列
- queue.deque 双线队列
- 使用时可以不带queue.前缀
- 初始化:
deque([])使用列表初始化
方法¶
put()放数据get()取数据empty()如果队列为空,返回True,反之Falseqsize()显示队列中真实存在的元素长度pop()- deque还有popleft
- 会返回pop的值
有序容器sortedcontainers¶
SortedListSortedDictSortedSet- 导入:
from sortedcontainers import SortedList - 操作:
- 初始化:
arr = SortedList([[初始数据列表]], [ket..]) - 操作与set类似
算法¶
二分¶
bisect(listname,num)相当于C++中的upper_boundbisect_left(listname,num)相当于C++中的lower_bound
re正则¶
-
引入
import re re.findall(pattern,string ,flags=0):搜索所有满足条件的字符串re.match(pattern,string ,flags=0):从第一个字符开始匹配模式,匹配失败返回Nonere.search(pattern,string ,flags=0):搜索第一个满足条件的字符串,查找到第一个停止re.sub(pattern,repl,string ,count=0,flags=0):替换满足条件的字符串- 正则表示
r".*"添加前缀i
例题¶
-
python import re class Solution: def strongPasswordCheckerII(self, password: str) -> bool: return re.match(r"^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*[!@#$%^&*()\-+])(?!.*(.)\1+).{8,}$", password) != None
记忆化搜索¶
- 函数前添加语句
@cache - 结合tuple实现记忆化搜索