机器学习
吴恩达机器学习
- 超参数:以调整但不在训练过程中更新的参数(如批的大小、学习率等)
- 调参:选择超参数的过程
数学补充¶
- \(\theta\) 表示环境对应的参数,\(x\) 表示发生的结果
- 概率:根据参数预测时间发生的概率 \(P(X|\theta)\)
- 似然:基于已经确定的结果,确定可能得环境(参数)\(L(\theta|x)\)
- 极大似然估计 MLE:用结果反推最有可能的模型参数(选择让结果发生概率最大的参数)
- 梯度:由全部变量偏导数汇总而形成的向量,梯度指示的方向 是各点处的函数值减小最多的方向
监督学习¶
- 提供包含输入输出的数据集,算法通过学习数据集,实现对新输入生成输出
- 从有标签和正确答案的数据中学习
- 种类
- 回归:预测一个具体值
- 分类
- 前向传播:从输入数据通过模型逐层计算,最终得到输出,模型使用当前参数对输入数据进行变换,用于推理预测得到结果
- 反向传播:计算损失函数对模型函数的梯度,并将这些梯度用于更新模型参数,用于优化模型参数,使函数损失最小化
线性回归¶
One-hot:正确解标签表示为 1,其他标签表示为 0softmax层:用于将输出正规化(总和为 1)
成本函数¶
- 使用成本函数评估模型的表现
- 通过这个函数评估模型预测结果的偏差大小
- 这个值的大小不应该受到数据集的规模影响
- 平方差成本函数 \(J(w,b) = \frac{1}{m}\sum^m_{i=1}(\hat{y}^{(i)}-y^{(i)})^2\)
梯度下降¶
- 一种计算最佳参数(成本函数代价最低)的方法
- \(\alpha\) 学习率表示“迈的步子的大小”
- \(\mathrm{w=w-\alpha}\frac \partial {\partial w}J(w,b)\)
- \(\mathrm{b=b-\alpha}\frac \partial {\partial b}J(w,b)\)
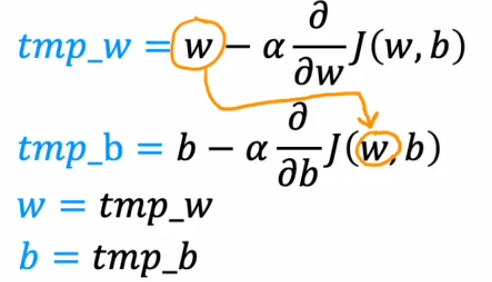
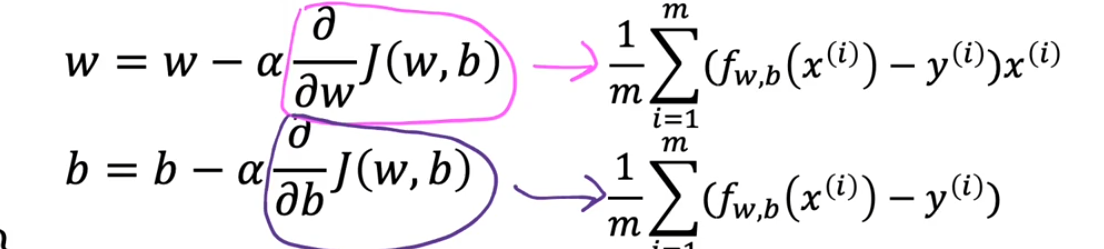
- 这个变化的过程就是梯度下降
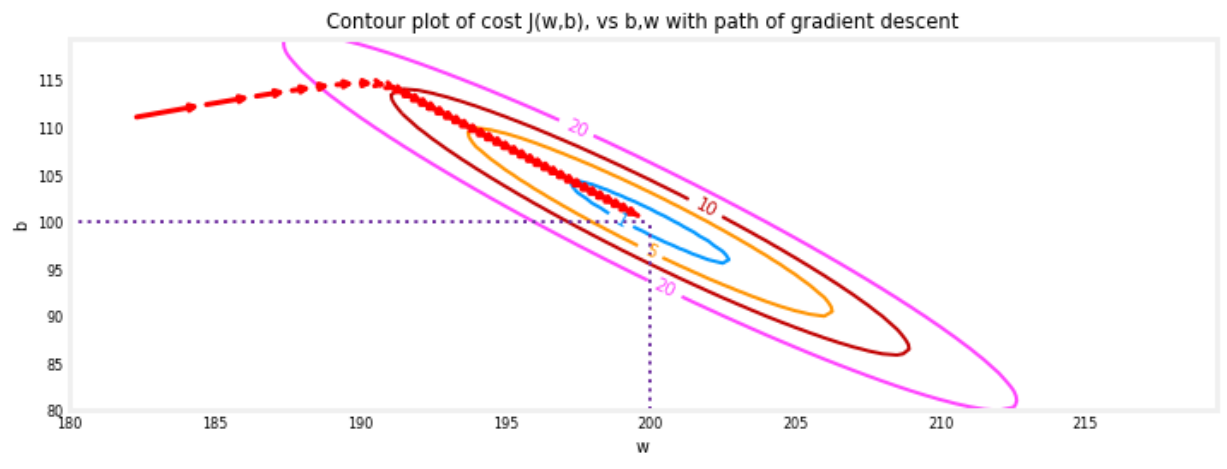
- 与此同时 w 和 b 在逼近使得成本函数最小值的位置
- 学习率设置太小会导致梯度下降起作用速度太慢
- 学习率设置太大可能越过最优点来回震荡
- 可以通过设置较小的学习率来检测是否存在 bug(如果很小的学习率下仍然不收敛)
- 可以先设置一个较小的学习率,之后再逐渐尝试增大学习率,来实现选择尽可能大的学习率
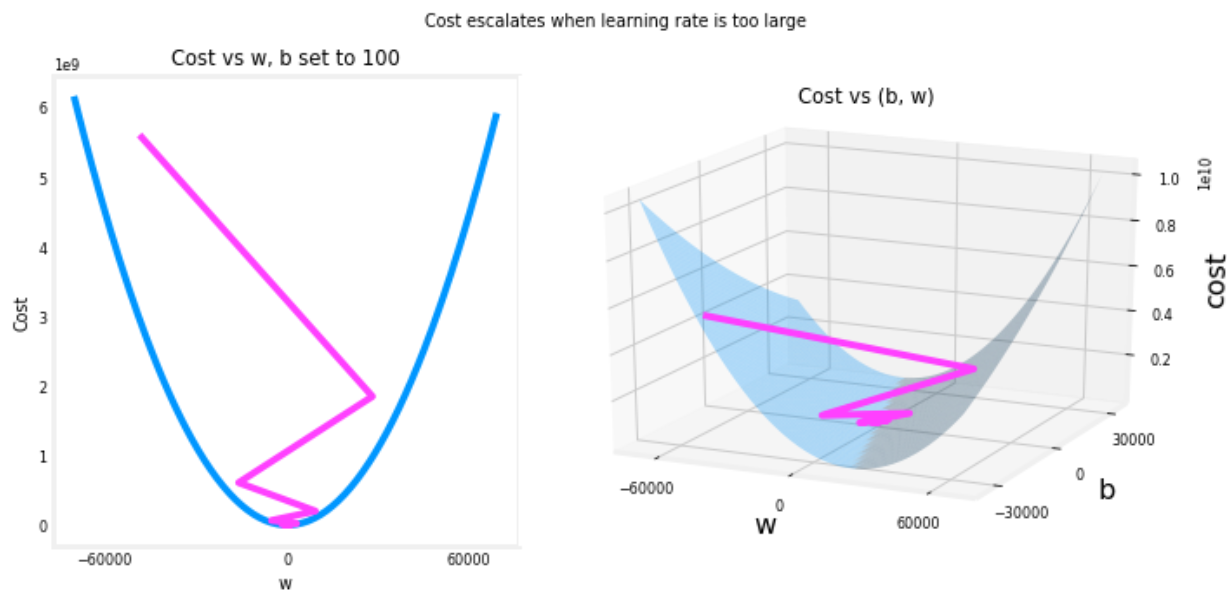
检查梯度下降是否收敛¶
- 随着迭代次数增加,成本函数的值减少的越来越慢
- 除了以迭代次数作为算法结束条件,也可以使用自动收敛测试
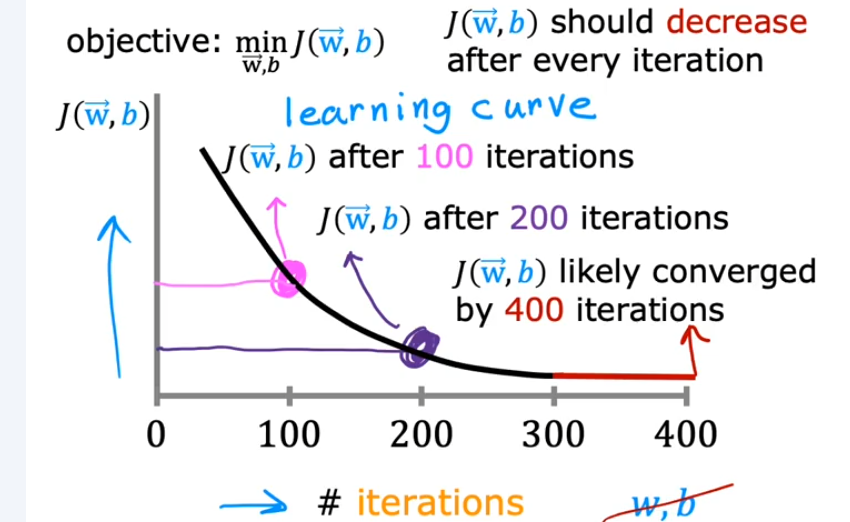
学习率的选择¶
多元线性回归¶
- 从多个指标来预测结果
- 即输入一个向量 \(f_{\overrightarrow{\mathrm{w}},b}(\vec{\mathrm{x}})=\overrightarrow{\mathrm{w}}\cdot\vec{\mathrm{x}}+b\)
- 与循环逐个计算相比,通常向量计算效率更高(因为可以更好的并行利用硬件加速)
梯度下降用于多元线性回归¶
- 成本函数 \(J(\overrightarrow{w},b)\)
- \(w_{j}=w_{j}-\alpha\frac{\partial}{\partial w_{j}}J(w_{1},\cdots,w_{n},b)\)
- \(b=b-\alpha\frac{\partial}{\partial b}J(w_{1},\cdots,w_{n},b)\)
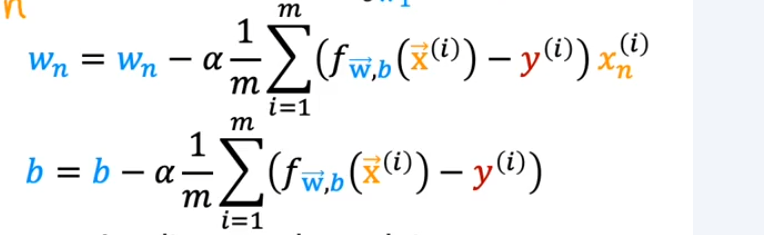
功能缩放¶
- 多元线性回归中不同输入参数的大小范围可能差距很大,为了便于展示,可以对数据进行转换(缩放)
- 梯度下降算法也可以找到通往最小值的更直接的路径(速度更快)
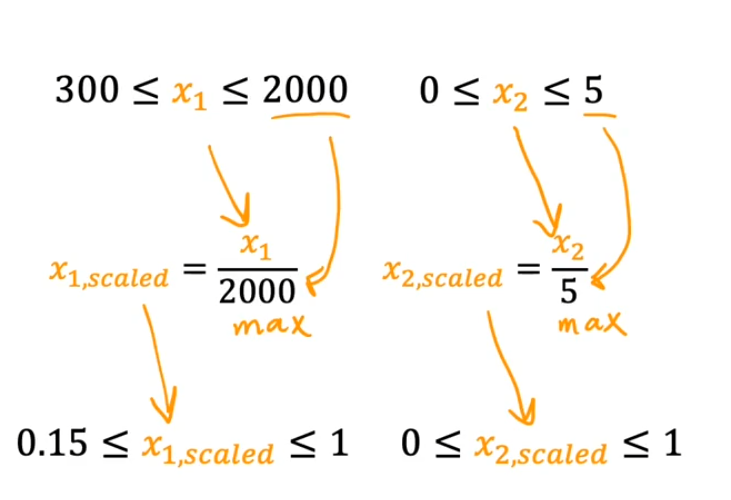
- 即先对数据进行归一化
多项式回归¶
- 有时需要根据输入与输出的关系,对输入的数据进行处理
- 比如结果与输入的平方相关,那么就应该将数据数据改为其平方
- 如输入房子的宽度和长度,而房价与面积相关,就应该将宽度和长度相乘
- 拟合一条多项式曲线
- \(f_{\vec{w},b}(x)=w_{1}x+w_{2}x^{2}+w_{3}x^{3}+b\)
逻辑回归¶
- 用于分类算法
- sigmoid 函数:将任意大小的数映射到 \(0\sim1\) 范围
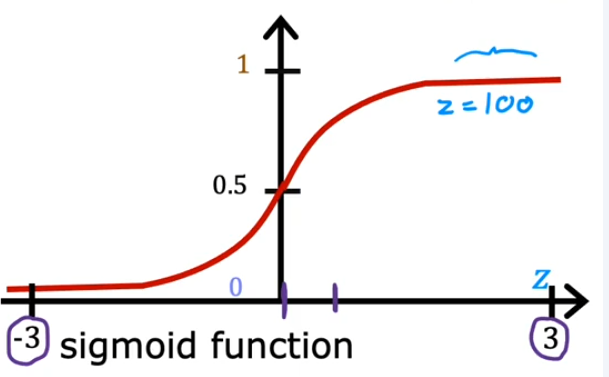
- \(g(z) = \frac{1}{1+e^{-z}}\)
-
逻辑回归方程就是 \(f_{\overrightarrow{\mathrm{W}},b}(\vec{\mathrm{x}})=g(\overrightarrow{\mathrm{w}}\cdot\vec{\mathrm{x}}+b)=\frac1{1+e^{-(\overrightarrow{\mathrm{w}}\cdot\overrightarrow{\mathrm{x}}+b)}}\)
- 计算结果表示有多大的概率为阳性
-
决策边界:以多少为边界,用于判断结果为真还是假(如 0.5)
成本函数¶
- 不能沿用线性回归的成本函数,否则不能保证存在唯一极值点
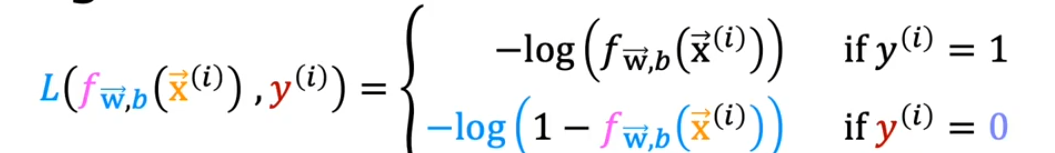
- 预测正确时损失趋近于零。
- 预测错误时损失迅速增加,迫使模型快速调整参数。
- 由此得到了一个凸函数,可以用于梯度求解
- \(J(\overrightarrow{\mathrm{w}},b)=\frac{1}{m}\sum_{i=1}^{m}L\left(f_{\overrightarrow{\mathrm{w}},b}\left(\vec{\mathrm{x}}^{(i)}\right),y^{(i)}\right)\)
- 统一表示:\(L\left(f_{\overrightarrow{w},b}\left(\vec{x}^{(i)}\right),y^{(i)}\right)=-\:y^{(i)}\mathrm{log}\left(f_{\overrightarrow{w},b}\left(\vec{x}^{(i)}\right)\right)-\left(1-y^{(i)}\right)\mathrm{log}\left(1-f_{\overrightarrow{w},b}\left(\vec{x}^{(i)}\right)\right)\)
模型的选择¶
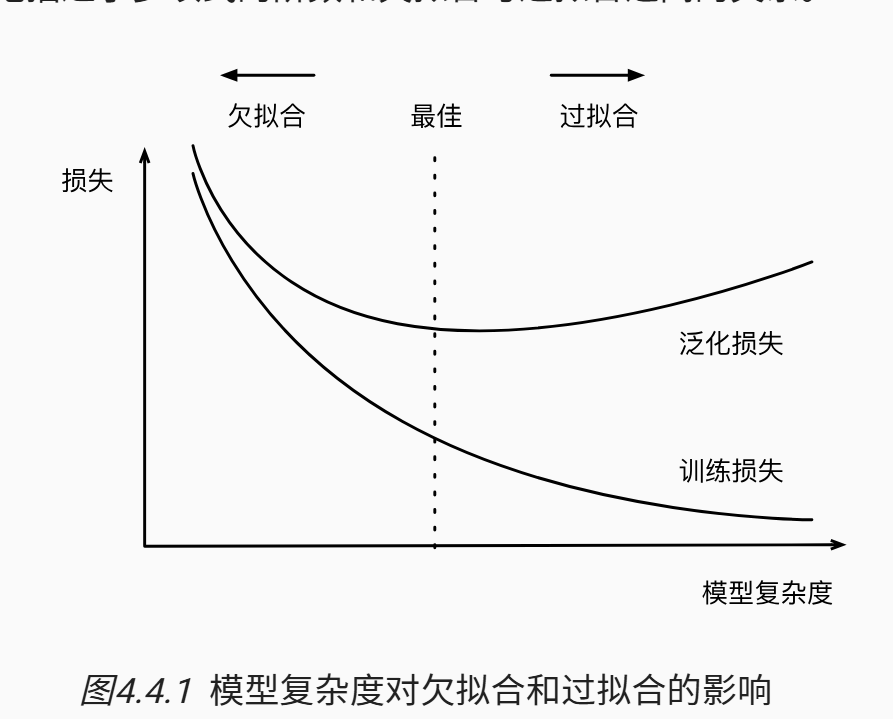
- 训练误差(欠拟合):模型在训练数据集上计算得到的误差,反映模型对已知数据的拟合能力
- 泛化误差(过拟合):无法捕捉真实趋势,在新数据上的误差较大,反映模型对未知数据的预测能力
- 因为不可能穷尽所有的数据,只能用一个独立的数据集来估计泛化误差
- 容易过拟合的条件:
- 可调整参数的数量。当可调整参数的数量很大时,模型往往更容易过拟合。
- 参数采用的值。当权重的取值范围较大时,模型可能更容易过拟合。
- 训练样本的数量。即使模型很简单,也很容易过拟合只包含一两个样本的数据集。而过拟合一个有数百万个样本的数据集则需要一个极其灵活的模型。
- 理想的模型应该同时具有较低的训练误差和泛化误差
- 如果模型不能降低训练误差,则说明模型可能过于简单,无法捕获尝试学习的模式
- 但是当训练误差明显低于验证误差时要小心过拟合
- 数据集太小也会大致较大的泛化误差,一般来说更多的数据不会有什么坏处(在数据较少的情况下就应该使用简单的模型)
验证¶
- 在确定所有超参数之前不能使用测试集,在模型训练过程中使用测试数据会有过拟合测试数据的风险
- K 折交叉验证:用于解决数据不足的问题
- 将原始的训练数据分成 K 个不重叠的子集,执行 K 次训练和验证,每次在 K-1 个子集上进行训练并在剩余一个子集上进行验证,最后通过这 K 次实验的结果取平均来估计训练和验证误差
过拟合¶
- \(L_{1}\) 范数:向量中所有元素的绝对值之和 \(\|\mathbf{w}\|_1=\sum_{i=1}^n|w_i|\)
- 倾向于将部分权重压缩为 0,自动筛选重要特征。
- 适用于需要稀疏解的场景(如高维数据)。
- 会导致模型将权重集中在一小部分特征上,而将其他权重清除为零。这称为特征选择
-
\(L_{2}\) 范数:向量中所有元素的平方和的平方根 \(\|\mathbf{w}\|_2=\sqrt{\sum_{i=1}^nw_i^2}\)
- 倾向于将权重均匀压缩到接近 0 的小值,避免极端权重。
- 适用于需要平滑(稠密)解的场景(如低维数据)。
- 也成为权重衰减
-
数据集划分
- 训练数据:用于模型参数学习(如梯度下降优化权重)
- 验证数据:用于超参数调优(如学习率、批量大小选择)
- 测试数据:模拟现实场景,评估模型最终泛化能力
- 典型为70%训练、15%验证、15%测试
-
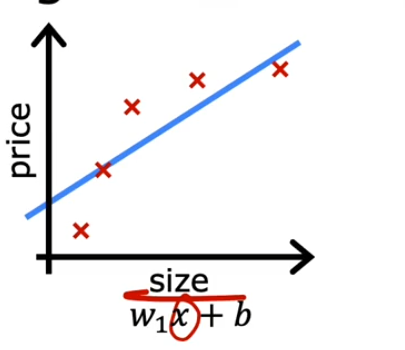
具有较大偏差时称为拟合不足
- 良好的拟合,可以很好的预测
- 既没有高偏差也没有高方差
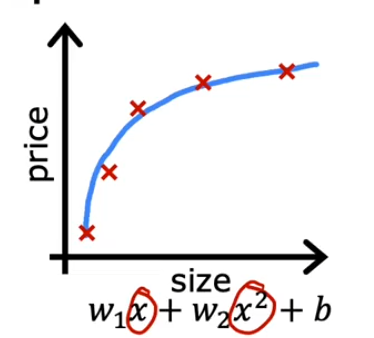
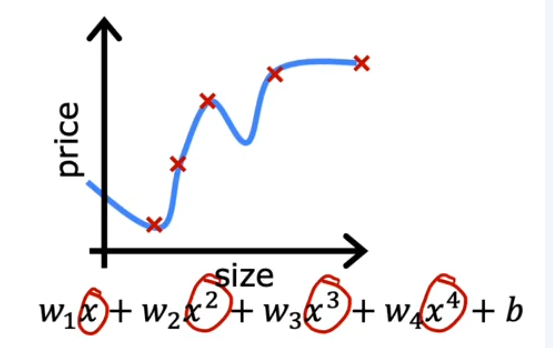
- 过拟合,对训练数据的拟合很好,但部剧本良好的预测能力
- 通常具有很高的方差
- 解决过拟合
- 使用更大的训练集
- 使用更少的输入特征
- 正则化,降低 \(w_{i}\) 参数的系数,减少维度(x 幂的数目)
权重衰减(正则化)¶
- 正则化成本函数(权重衰减技术,也成为 \(L_{2}\) 正则化)
- \(J(\vec{\mathbf{w}},b)=\frac{1}{2m}\sum_{i=1}^{m}(f_{\vec{\mathbf{w}},b}(\vec{\mathbf{x}}^{(i)})-y^{(i)})^{2}+\frac{\lambda}{2m}\sum_{j=1}^{n}\omega_{j}^{2}\)
- "惩罚"所有的 \(w_{i}\),加入到成本函数使得参数趋向于更小的值
- 利用框架来简单的实现权重衰减
- 只需在优化器中指定
weight_decay参数即可自动在训练时使用权重衰减# 优化器:仅对权重应用权重衰减 optimizer = torch.optim.SGD([ {"params": net[0].weight, "weight_decay": wd}, # 权重衰减 {"params": net[0].bias} # 无衰减 ], lr=lr)
- 只需在优化器中指定
神经网络¶
神经网络模型¶
- 多层结构,每层从上一层获取输入向量,进行一系列处理转换后输出到下一层
- 训练模型就是设置处理转换参数的过程
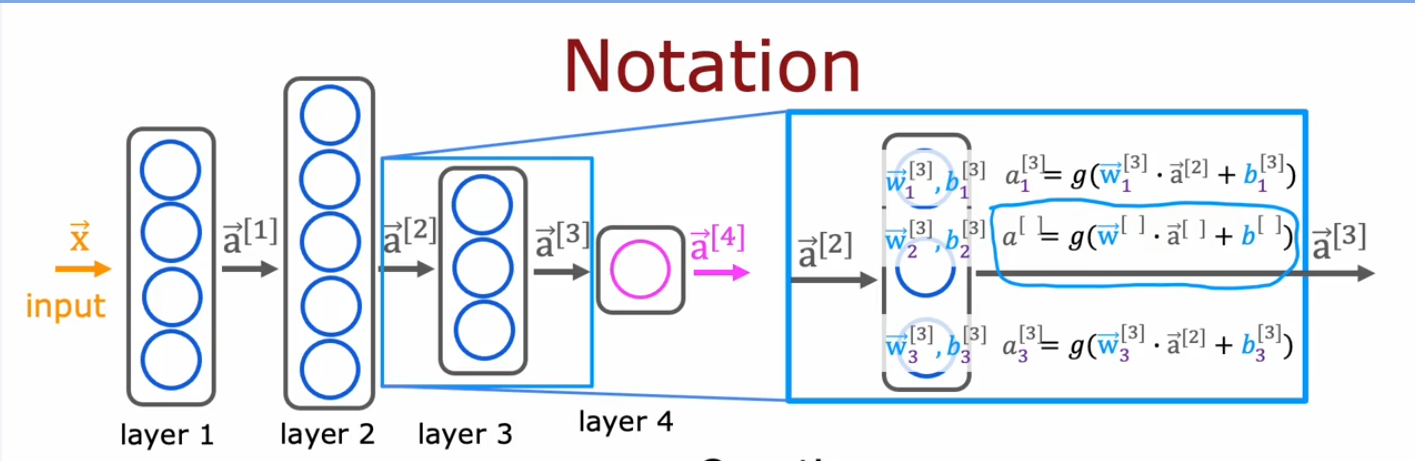
- \(a^{[l]}_{j} = g(\overrightarrow{w}^{[l]}_{j}\cdot \overrightarrow{a}^{[l-1]}+b^{[l]}_{j})\)
无监督学习¶
- 从没有标签的数据中寻找特征
- 种类
- 聚类算法:根据数据的特征对数据进行分组
- 异常检测