Pytorch
基本概念¶
Tensors 张量¶
- 使用 pytorch 张量组成神经网络,作为神经网络中数据流动的结拜呢单位
- 张量可以表示不同维度的数据
- 标量(0维张量):单个数值,如
torch.tensor(3.14) - 向量(1维张量):一维数组,如
torch.tensor([1, 2, 3]) - 矩阵(2维张量):二维数组,如
torch.tensor([[1, 2], [3, 4]]) - 高维张量:更高维度的数据,如图像(3维:通道×高×宽)
- 标量(0维张量):单个数值,如
基本操作¶
- 直接对变量进行赋值
Y = Y + X实际上会为变量分配新的内存,也就是Y的存储位置会发生改变,如果想原地操作,可以Y[:] = X + Y -
线性代数相关运算
A.T #矩阵转置 -
微积分相关运算
-
梯度:一个向量,表示函数在某点的所有偏导数的集合,指向函数增大的最快方向。\(\nabla f=\left(\frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2},\ldots,\frac{\partial f}{\partial x_n}\right)\)
- 梯度的大小就表示函数值在该方向上的变化率
-
概率计算
fair_probs = torch.ones([6]) / 6 # 设置概率向量 multinomial.Multinomial(10, fair_probs).sample()# 采样十次 # tensor([5., 3., 2., 0., 0., 0.])
Tensors 1D¶
- 一维数组
import torch a = torch.tensor([7, 4, 3, 2, 6]) a[i] #下标访问 a.dtype #张量的数据类型 a.type #张量的类型 a.tolist() #转化为数组 a.size() a.ndimension() #维数 a = a.type(torch.FloatTensor) #进行类型转换 #创建时指定数据类型 a = torch.tensor([7, 4, 3, 2, 6], dtype = torch.int32) - 张量的类型包含设备信息和数据类型,张量的数据类型主要包含数据精度(数据类型的细分)
- CPU 张量:
torch.FloatTensor(浮点型)、torch.IntTensor(整型) - GPU 张量:
torch.cuda.FloatTensor、torch.cuda.IntTensor
- CPU 张量:
- 重塑张量形状
- 新形状的总元素数必须与原张量一致
- 允许使用
-1自动推断某一维度大小a = torch.randn(2, 3) # 形状为 (2, 3) b = a.view(3, 2) # 合法,总元素数 6 c = a.view(4, -1) # 非法,总元素数 6 无法整除 4
- 与 numpy 的转换
form_numpy(numpy_array)numpy()
Tensors 2D¶

- 不同于矩阵乘法,张量相乘的结果就是对应位置的元素相乘
A*b- 也可以进行矩阵乘法
torch.mm(A,B)
- 也可以进行矩阵乘法
模型网络¶
Sequential类¶
- 将多个层按顺序连接,形成数据流动的管道。输入数据依次通过每一层,前一层的输出作为后一层的输入。
- 深度学习框架已实现了常见层(如全连接层、卷积层),用户只需按需组合,无需手动实现底层计算。
- 可以便捷的创建多个层,并定义前向传播
import torch.nn as nn model = nn.Sequential( nn.Linear(784, 256), # 全连接层 784 → 256 nn.ReLU(), nn.Linear(256, 10), # 输出层 256 → 10 nn.Softmax(dim=1) )
微分¶
- 导数的计算
- 深度学习框架通过自动计算导数,即自动微分(来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图, 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。
x = torch.tensor(2, requires_grad=True) # 跟踪计算图 y = x ** 2 y.backward() x.grad #获取计算结果,在x=2处x**2的导数4 #偏导数 u = torch.tensor(1.0,requires_grad=True) v = torch.tensor(2.0,requires_grad=True) f = u * v + u ** 2 f.backward() u.grad v.grad
- 深度学习框架通过自动计算导数,即自动微分(来加快求导。 实际中,根据设计好的模型,系统会构建一个计算图, 来跟踪计算是哪些数据通过哪些操作组合起来产生输出。 自动微分使系统能够随后反向传播梯度。
误差反向传播计算微分¶
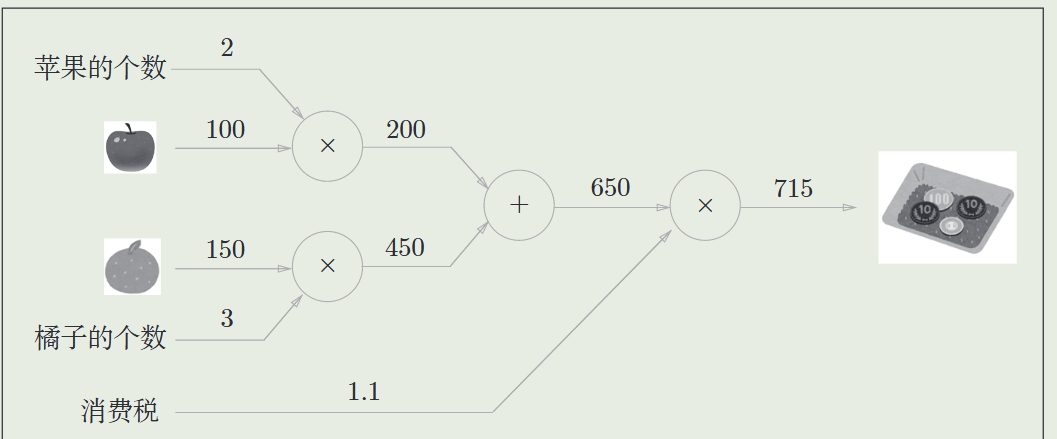
- 从左到右进行计算得到结果,称为正向传播
- 通过计算图上反向传播可以高效计算导数
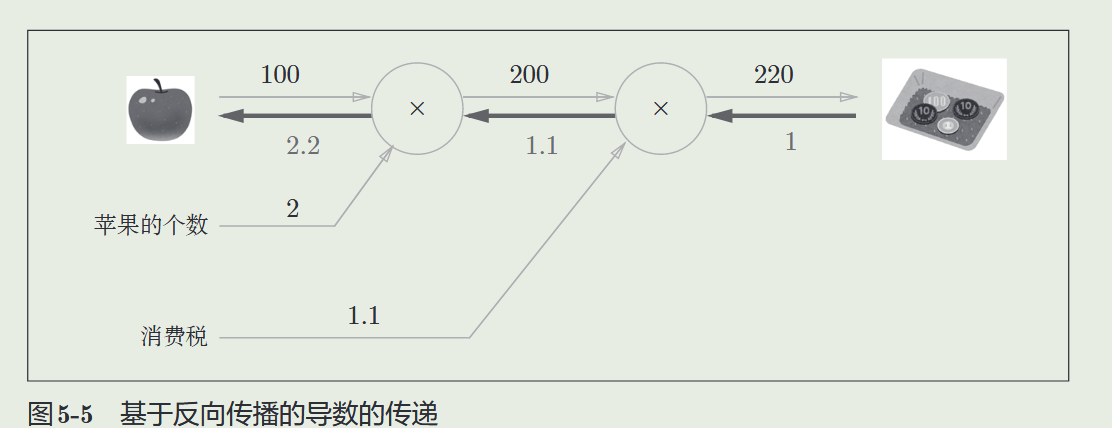
- 从结果反向到苹果,来通过计算图的反向传播计算“支付金额关于苹果的价格的导数”(即 2.2)
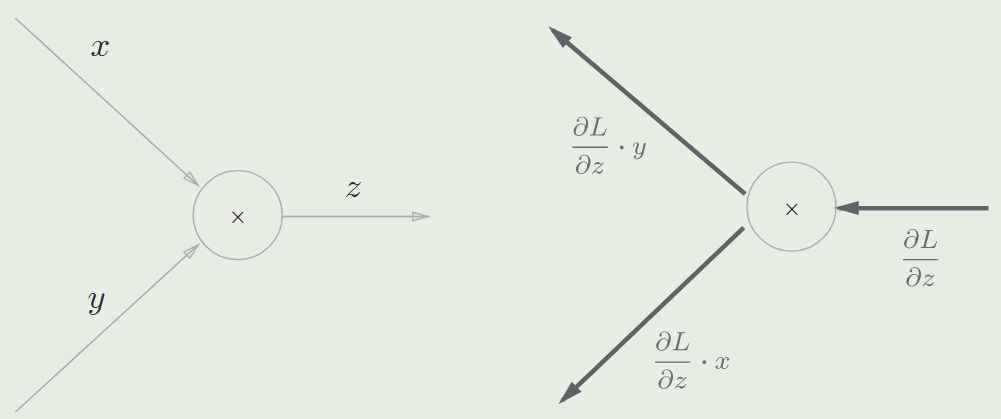
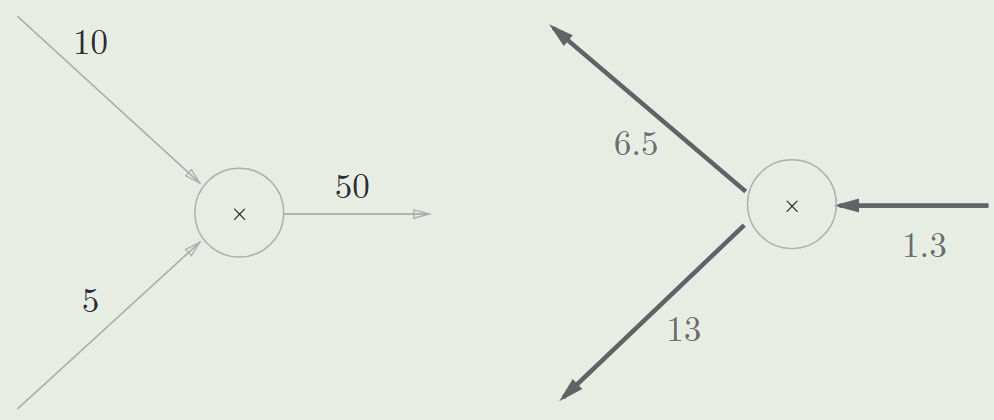
- 实际上是通过链式法则,不断乘以局部导数
-
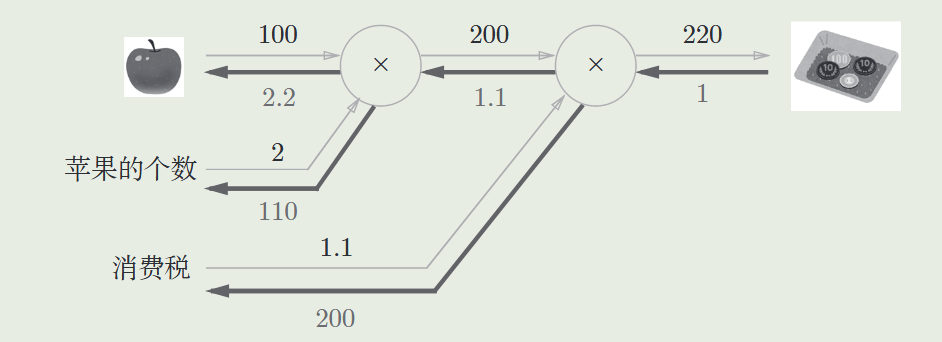
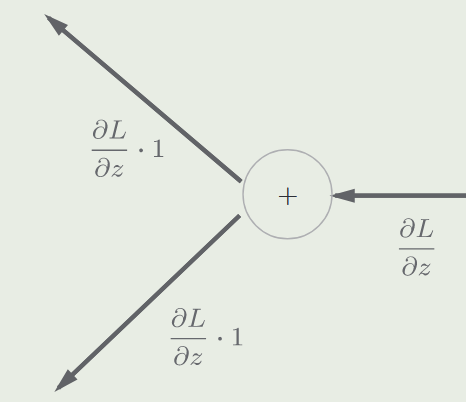
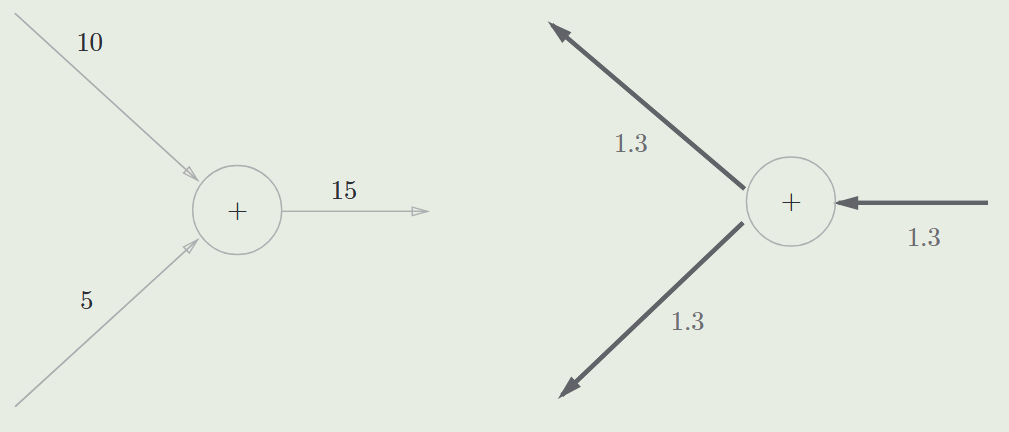
加法节点的反向传播节点视为 1
-
乘法节点的反向传播:将上游的值乘以正向传播时的输入信号的“翻转值” 后传递给下游(即另一个被乘数)
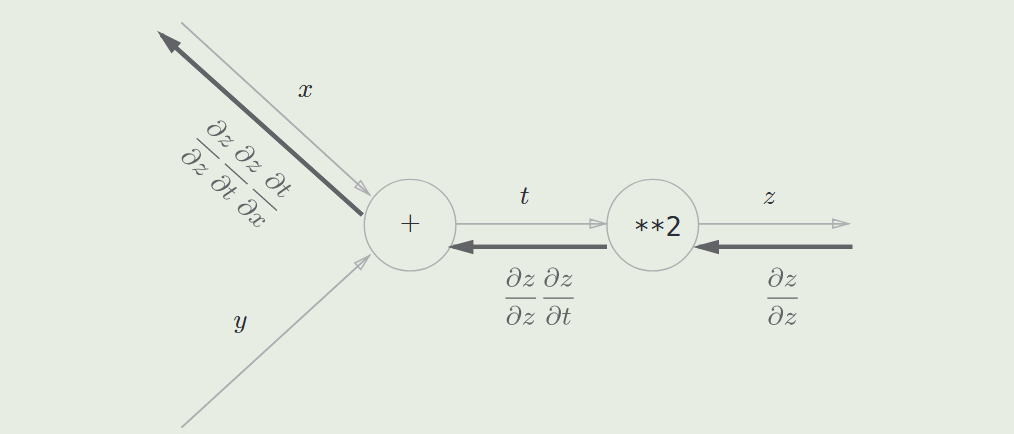
数据集¶
- 使用固定的随机数生成器种子值,确保代码的可重复性
torch.manual_seed(0) 原始数据 → Dataset → 单样本处理 → DataLoader → 批量生成
数据预处理¶
- 从原始数据得到张量格式
- 基本流程:读取数据集-处理缺失值-转化为张量格式
- 缺失值的处理有:插值法和删除法
- 使用平均值进行插值来对缺失数据进行填充:
inputs = inputs.fillna(inputs.mean())¶
构造数据¶
- 为线性回归构造一个有正态分布噪声的数据
def synthetic_data(w, b, num_examples): #@save """生成y=Xw+b+噪声""" X = torch.normal(0, 1, (num_examples, len(w))) y = torch.matmul(X, w) + b y += torch.normal(0, 0.01, y.shape) return X, y.reshape((-1, 1))
Dataset¶
- 定义数据的组织方式
- 提供标准化的数据访问方法
- 重写来实现 Dataset 类
from torch.utils.data import Dataset class toy_set(Dataset): def __init__(self, length = 100, transform = None): self.len = length self.x = 2 * torch.ones(length, 2) self.y = torch.ones(length, 1) self.transform = transform """初始化数据路径、预处理参数等""" def __len__(self): return self.len """返回数据集总样本数""" def __getitem__(self, idx): sample = self.x[index], self.y[index] if self.transform: sample = self.transform(sample) return sample """返回单个样本(支持索引访问)"""
DataLoader¶
- 从
Dataset中高效生成批量数据 - 原始数据 → Dataset → 单样本处理 → DataLoader → 批量生成 → 模型训练/验证
- 可以方便的实现:
- 批量控制
- 数据打乱
- 并行加载
- 内存管理
trainloader = DataLoader(dataset = dataset, batch_size = 1) w = torch.tensor(-15.0,requires_grad=True) b = torch.tensor(-10.0,requires_grad=True) LOSS_Loader = [] def train_model_DataLoader(epochs): # Loop for epoch in range(epochs): # SGD is an approximation of out true total loss/cost, in this line of code we calculate our true loss/cost and store it Yhat = forward(X) # store the loss LOSS_Loader.append(criterion(Yhat, Y).tolist()) for x, y in trainloader: # make a prediction yhat = forward(x) # calculate the loss loss = criterion(yhat, y) # Section for plotting get_surface.set_para_loss(w.data.tolist(), b.data.tolist(), loss.tolist()) # Backward pass: compute gradient of the loss with respect to all the learnable parameters loss.backward() # Updata parameters slope w.data = w.data - lr * w.grad.data b.data = b.data - lr* b.grad.data # Clear gradients w.grad.data.zero_() b.grad.data.zero_() #plot surface and data space after each epoch get_surface.plot_ps()
变换¶
- 用于变换数据的变换类
class add_mult(object): # Constructor def __init__(self, addx = 1, muly = 2): self.addx = addx self.muly = muly # Executor def __call__(self, sample): x = sample[0] y = sample[1] x = x + self.addx y = y * self.muly sample = x, y return sample #对数据进行转换 a_m = add_mult() data_set = toy_set() a_m(data_set[i]) #也可以在创建数据集时就传递变换 cust_data_set = toy_set(transform = a_m) - 组合多种变换
from torchvision import transforms # 定义第二个变化类 class mult(object): # Constructor def __init__(self, mult = 100): self.mult = mult # Executor def __call__(self, sample): x = sample[0] y = sample[1] x = x * self.mult y = y * self.mult sample = x, y return sample #组合变化 data_transform = transforms.Compose([add_mult(), mult()]) data_transform(data_set[0])
算法¶
线性回归预测¶
- 使用模型
from torch.nn import Linear # 模型的wb参数会被随机初始化 model = Linear(in_features = 1, out_features = 1, bias=True)# 输入的特征数目、输出的特征数目、是否包含偏置项
工作流程¶
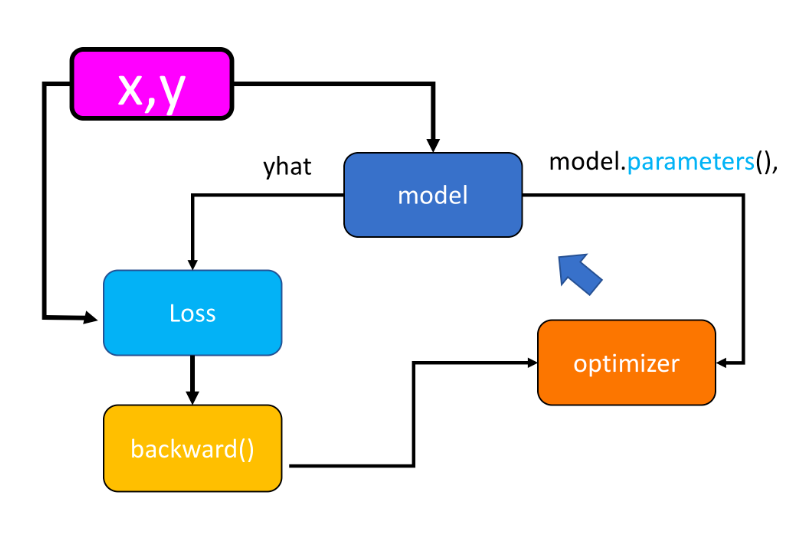
- PyTorch 中的优化流程
- 从
trainloader读取小批量数据x, y。 - 输入
x至模型,计算预测值yhat。 - 使用损失函数计算预测值与真实值之间的误差(
loss)。 - 使用反向传播(
backward())计算梯度。 - 使用优化器(
optimizer.step())更新模型参数。 - 清空梯度(
optimizer.zero_grad()),进入下一轮循环。
- 从
model.state_dict()返回一个字典,包含模型的所有可学习参数(如权重、偏置)及其当前值。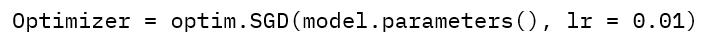
- optim 表示优化器
- lr 为学习率
- 使用 pytorch 提供的一系列类来实现算法[[3 3_PyTorchway_v3.ipynb]]
from torch import nn, optim #线性回归类定义 class linear_regression(nn.Module): # Constructor def __init__(self, input_size, output_size): super(linear_regression, self).__init__() self.linear = nn.Linear(input_size, output_size) # Prediction def forward(self, x): yhat = self.linear(x) return yhat #损失函数与优化器 criterion = nn.MSELoss() # 均方误差损失 model = linear_regression(1, 1) # 实例化模型 optimizer = optim.SGD(model.parameters(), lr=0.01) # 优化器绑定模型参数 trainloader = DataLoader(dataset = dataset, batch_size = 1) #参数手动初始化 model.state_dict()['linear.weight'][0] = -15 model.state_dict()['linear.bias'][0] = -10 #初始化参数 → 数据加载 → 前向传播 → 损失计算 # ↑ ↓ #参数更新 ← 梯度清零 ← 反向传播 ← 损失计算 def train_model_BGD(iter): for epoch in range(iter): for x, y in trainloader: yhat = model(x) # 前向传播 loss = criterion(yhat, y) # 损失计算 get_surface.set_para_loss(...) # 可视化更新 optimizer.zero_grad() # 梯度清零 loss.backward() # 反向传播 optimizer.step() # 参数更新 - 保存模型参数
torch.save(model.state_dict(), 'lol_win_predictor.pth') - 加载模型
#先创建模型然后加载参数 # 创建新模型实例(需保持与原模型相同结构) loaded_model = LogisticRegressionModel(input_dim=X_train_tensor.shape[1]) loaded_model.load_state_dict(torch.load('lol_win_predictor.pth'))
超参数调优¶
- 将数据集划分为训练、验证、测试数据集
- 训练阶段:使用训练集更新模型参数(梯度下降)。
- 验证阶段:使用验证集评估不同超参数配置的性能。
- 测试阶段:使用测试集仅进行一次最终评估。
- 训练集
- 直接用于模型参数的训练(如通过梯度下降优化权重和偏置)
- 占数据总量的 60%~80%(依数据规模调整)
- 验证集
- 用于 超参数调优(如学习率、正则化系数、网络层数等)。
- 评估模型的泛化能力,防止过拟合训练数据。
- 占数据总量的 10%~20%。
- 需与训练集独立分布,反映真实场景数据特性。
- 测试集
- 最终评估 模型在未知数据上的性能(模拟真实场景)。
- 仅在模型完全确定(超参数固定、训练完成)后使用一次。
- 占数据总量的 10%~20%。
- 严禁参与训练或调参,否则会导致过拟合测试集。
- 为什么区分训练集和验证集:
- 如果在训练集上多次尝试不同学习率(或其他超参数),模型会间接“记住”验证集的特征,导致验证集上的性能被高估(本质是过拟合验证集)。
- 训练集的损失反映模型对已知数据的拟合程度,而验证集的损失反映模型对未知数据的预测能力。
- 利用验证集进行超参数调优可以提升模型的泛化能力,保证在未知数据(测试集上的表现) [[3 6_training_and_validation_v3.ipynb]]
随机梯度下降¶
- 每次迭代只使用一个样本(依次选择) 计算成本,而不是使用所有的样本
- 通过 单个样本 的梯度来近似全体数据的梯度,迭代更新模型参数。
- 迭代表示用一个元素进行计算,计算一趟称为一个周期



# The function for training the model
LOSS_SGD = []
w = torch.tensor(-15.0, requires_grad = True)
b = torch.tensor(-10.0, requires_grad = True)
def train_model_SGD(iter):
# Loop
for epoch in range(iter):
# SGD is an approximation of out true total loss/cost, in this line of code we calculate our true loss/cost and store it
Yhat = forward(X)
# store the loss
LOSS_SGD.append(criterion(Yhat, Y).tolist())
for x, y in zip(X, Y):
# make a pridiction
yhat = forward(x)
# calculate the loss
loss = criterion(yhat, y)
# Section for plotting
get_surface.set_para_loss(w.data.tolist(), b.data.tolist(), loss.tolist())
# backward pass: compute gradient of the loss with respect to all the learnable parameters
loss.backward()
# update parameters slope and bias
w.data = w.data - lr * w.grad.data
b.data = b.data - lr * b.grad.data
# zero the gradients before running the backward pass
w.grad.data.zero_()
b.grad.data.zero_()
#plot surface and data space after each epoch
get_surface.plot_ps()
小批量梯度下降¶
- 将数据集拆分,每次选择一部分计算成本,兼顾效率与准确性 [[3 2_mini-batch_gradient_descent_v3.ipynb]]
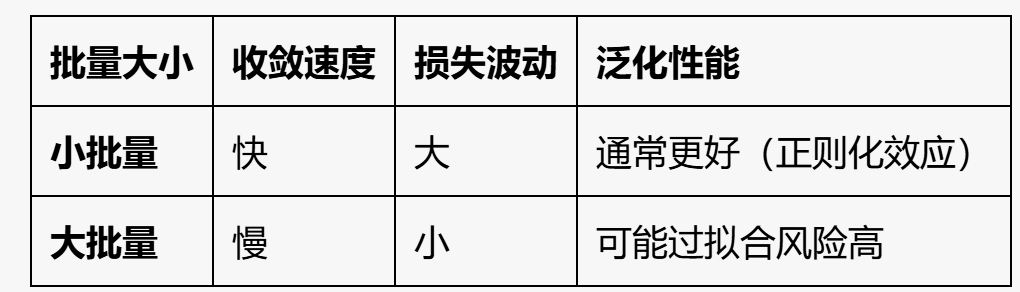
-
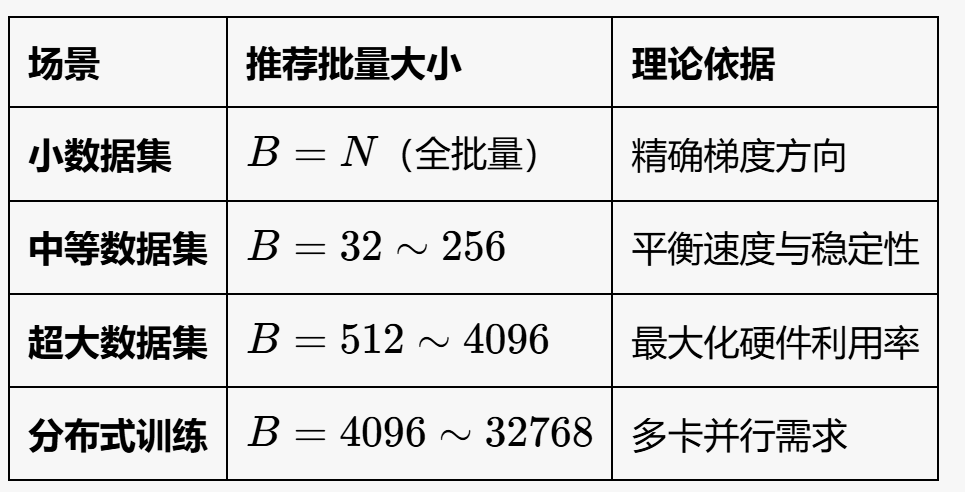
-
通过 dataloader 可以方便的实现以批为单位取出
dataset = Data() trainloader = DataLoader(dataset = dataset, batch_size = 5) w = torch.tensor(-15.0, requires_grad = True) b = torch.tensor(-10.0, requires_grad = True) LOSS_MINI5 = [] lr = 0.1 def train_model_Mini5(epochs): for epoch in range(epochs): Yhat = forward(X) get_surface.set_para_loss(w.data.tolist(), b.data.tolist(), criterion(Yhat, Y).tolist()) get_surface.plot_ps() LOSS_MINI5.append(criterion(forward(X), Y).tolist()) for x, y in trainloader: yhat = forward(x) loss = criterion(yhat, y) get_surface.set_para_loss(w.data.tolist(), b.data.tolist(), loss.tolist()) loss.backward() w.data = w.data - lr * w.grad.data b.data = b.data - lr * b.grad.data w.grad.data.zero_() b.grad.data.zero_()
多元线性回归¶
[[4 2 multiple_linear_regression_training_v2.ipynb]]
多重输出线性回归¶
- 多套参数,有输出输出多个不同的结果
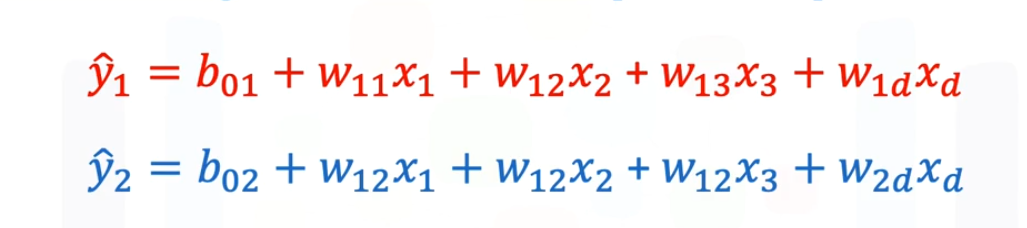
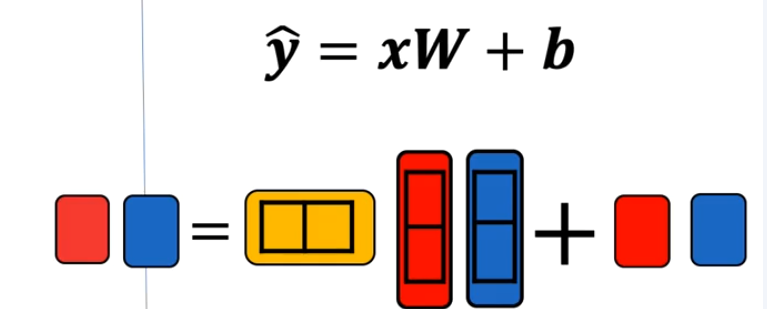
逻辑回归¶
- 如果一个数据中的顶点类型可以通过线性划分,那么称其为线性可分的
- 映射函数:从任意大小映射到
0~1范围sig = nn.Sigmoid() yhat = sig(z) - 此外为了避免阶梯状代价函数(无法收敛到最低处),使用对数代价函数
[[5 3_cross_entropy_logistic_regression_v2.ipynb]]
class logistic_regression(nn.Module): # Constructor def __init__(self, n_inputs): super(logistic_regression, self).__init__() self.linear = nn.Linear(n_inputs, 1) # Prediction def forward(self, x): yhat = torch.sigmoid(self.linear(x)) return yhat model = logistic_regression(1) # 对数成本函数 def criterion(yhat,y): out = -1 * torch.mean(y * torch.log(yhat) + (1 - y) * torch.log(1 - yhat)) return out # Build in criterion # criterion = nn.BCELoss() trainloader = DataLoader(dataset = data_set, batch_size = 3) learning_rate = 2 optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate) def train_model(epochs): for epoch in range(epochs): for x, y in trainloader: yhat = model(x) loss = criterion(yhat, y) optimizer.zero_grad() loss.backward() optimizer.step() get_surface.set_para_loss(model, loss.tolist()) if epoch % 20 == 0: get_surface.plot_ps() train_model(100)
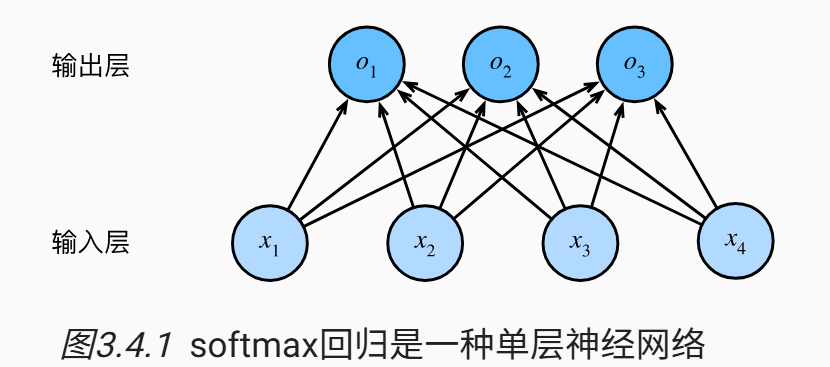
SoftMax 分类¶
- 与简单的逻辑回归相比,对更多(不止两个)类型进行分类
- 通过多个 01 输出(分量和类别数目一样多)来表示类型,具有最大输出值的类型就是预测的目标类型(如 0.1、0.8 和 0.1 就表示第二项为预测结果)
- 为了实现这个效果,还需要对输出进行校准,即限制数字的输出综合为 1 ,这样才可以将输出视为概率
- softmax 函数就是将未规范化的预测变换为非负数且总合为 1
- \(\hat{y}_j=\frac{\exp(o_j)}{\sum_k\exp(o_k)}\)
- 使用多套线性回归方程分别预测每一位
- 代价函数:仍然使用对数似然(### 交叉熵损失)
优化¶
矢量化¶
- 用矢量匀速那(如矩阵、向量乘法)来代替逐个计算(即用 GPU 进行加速)
小批量样本的矢量化¶
- 假设特征维度为 \(d\) 批量大小为 \(n\) 输出 \(q\) 个类别
- \(\text{特征为}\mathbf{X}\in\mathbb{R}^{n\times d}\text{,权重为}\mathbf{W}\in\mathbb{R}^{d\times q},\text{ 偏置为}\mathbf{b}\in\mathbb{R}^{1\times q}\)
实操¶
数据集处理¶
- 将数据集写入到 CSV
import os os.makedirs(os.path.join('..', 'data'), exist_ok=True) data_file = os.path.join('..', 'data', 'house_tiny.csv') with open(data_file, 'w') as f: f.write('NumRooms,Alley,Price\n') # 列名 f.write('NA,Pave,127500\n') # 每行表示一个数据样本 f.write('2,NA,106000\n') f.write('4,NA,178100\n') f.write('NA,NA,140000\n') - 从 CSV 读取数据
import pandas as pd data = pd.read_csv(data_file) print(data) # 转化为numpy进而变为张量格式 X = torch.tensor(inputs.to_numpy(dtype=float)) y = torch.tensor(outputs.to_numpy(dtype=float))
处理缺失值¶
- 插值法:用替代值,弥补缺失值
- 删除法:直接忽略缺失值
- 示例:使用输入的均值弥补缺失值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] inputs = inputs.fillna(inputs.mean())
线性回归¶
# 构建数据集
def load_array(data_arrays, batch_size, is_train=True):
"""构造一个PyTorch数据迭代器"""
dataset = data.TensorDataset(*data_arrays)
return data.DataLoader(dataset, batch_size, shuffle=is_train)
batch_size = 10
data_iter = load_array((features, labels), batch_size)
#定义模型
net = nn.Sequential(nn.Linear(2, 1))
# net[0]访问第一层(Linear)
net[0].weight.data.normal_(0, 0.01)# 用均值为0、标准差为0.01的正态分布初始化权重
net[0].bias.data.fill_(0)# 将偏置参数置为0
# 使用MSE损失函数
loss = nn.MSELoss()
# 定义优化算法
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
# 开始训练
num_epochs = 3 # 训练轮数
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)# 计算损失
trainer.zero_grad()# 梯度清零
l.backward()# 反向传播极速那可训练参数的梯度
trainer.step()# 采纳数更新
softmax回归¶
- 使用Fashion-MNIST 图像数据集 (单通道 1*28*28)
- 首先下载训练和测试数据集
trans = transforms.ToTensor() mnist_train = torchvision.datasets.FashionMNIST( root="../data", train=True, transform=trans, download=True) mnist_test = torchvision.datasets.FashionMNIST( root="../data", train=False, transform=trans, download=True) - 在数字标签索引及其文本名称之间进行联系
# 输入index序列,输出对应的标签文字序列 def get_fashion_mnist_labels(labels): """返回Fashion-MNIST数据集的文本标签""" text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat', 'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot'] return [text_labels[int(i)] for i in labels] - 批量读取,得到数据集
batch_size = 256 def get_dataloader_workers(): #@save """使用4个进程来读取数据""" return 4 train_iter = data.DataLoader( mnist_train, # 训练数据集(已加载的Fashion-MNIST) batch_size, # 批次大小256 shuffle=True, # 每个epoch打乱数据顺序 num_workers=get_dataloader_workers() # 使用4个进程加载数据 ) - 初始化网络
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10)) def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weight, std=0.01) net.apply(init_weights); loss = nn.CrossEntropyLoss(reduction='none') trainer = torch.optim.SGD(net.parameters(), lr=0.1) num_epochs = 10 d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)