教程地址:主页 - LearnOpenGL CN
常用库¶
GLFW¶
- 用于窗口管理、处理输入、创建 opengl 上下文等
- GLFW 封装了底层窗口系统的实现,提供了跨平台的接口
- GLFW 提供了键盘、鼠标和游戏手柄的输入支持
- GLFW 支持 Windows、macOS 和 Linux,帮助你实现一次编写、跨平台运行的代码
基本使用¶
-
参数配置:以键值对的形式进行配置
- 如配置版本号位
3.3glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3); glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
- 如配置版本号位
-
创建一个简单的窗口对象并设置为上下文
GLFWwindow* window = glfwCreateWindow(800, 600,"LearnOpenGL", NULL, NULL); glfwMakeContextCurrent(window); -
注册回调,当窗口大小调整时自动调整视口的大小
void framebuffer_size_callback(GLFWwindow* window, int width, int height) { glViewport(0, 0, width, height); } glfwSetFramebufferSizeCallback(window,framebuffer_size_callback); -
最简答的事件循环
while(!glfwWindowShouldClose(window)) { glfwSwapBuffers(window); glfwPollEvents(); } - glfwWindowShouldClose函数在我们每次循环的开始前检查一次GLFW是否被要求退出
- glfwPollEvents函数检查有没有触发什么事件(比如键盘输入、鼠标移动等)、更新窗口状态,并调用对应的回调函数。
- glfwSwapBuffers函数会交换颜色缓冲,它在这一迭代中被用来绘制,并且将会作为输出显示在屏幕上。
- 双缓冲:下一帧完全渲染完之后再进行交换,避免由于渲染过程造成闪烁
-
在循环中可以进行输入检查控制
void processInput(GLFWwindow* window) { if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS) glfwSetWindowShouldClose(window, true); } -
完整的代码
#include <glad\glad.h> #include <GLFW\glfw3.h> #include <iostream> void framebuffer_size_callback(GLFWwindow* window, int width, int height) { glViewport(0, 0, width, height); } void processInput(GLFWwindow* window) { if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS) glfwSetWindowShouldClose(window, true); } int main() { //参数设置 glfwInit(); glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3); glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3); glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE); //创建上下文 GLFWwindow* window = glfwCreateWindow(800, 600, "LearnOpenGL", NULL, NULL); if (window == NULL) { std::cout << "Failed to create GLFW window" << std::endl; glfwTerminate(); return -1; } glfwMakeContextCurrent(window); //板顶函数 if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)) { std::cout << "Failed to initialize GLAD" << std::endl; return -1; } //设置视口大小 glfwSetFramebufferSizeCallback(window, framebuffer_size_callback); while (!glfwWindowShouldClose(window)) { // 输入 processInput(window); // 渲染指令 glClearColor(0.2f, 0.3f, 0.3f, 1.0f);//设置清除用的颜色 glClear(GL_COLOR_BUFFER_BIT); // 检查并调用事件,交换缓冲 glfwSwapBuffers(window); glfwPollEvents(); } //释放资源 glfwTerminate(); return 0; } - glClear 用于清除缓冲,可选参数如:GL_COLOR_BUFFER_BIT,GL_DEPTH_BUFFER_BIT和GL_STENCIL_BUFFER_BIT 用于清除不同的数据
GLAD¶
- 是一个 OpenGL 扩展加载器,一个基于 OpenGL 函数指针的加载库,用于加载不同 OpenGL 版本的函数
- OpenGL 本身并不包含所有的函数定义和实现,因此你需要一个加载器来动态加载这些函数地址
-
由于不同操作系统和驱动支持不同版本的 opengl,因此不能直接调用这些函数,而是通过函数加载器来获取这些函数的地址
-
加载函数
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress)) { std::cout << "Failed to initialize GLAD" << std::endl; return -1; } - 函数指针的地址只有在创建了 OpenGL 上下文后才能正确获取。GLFW 负责初始化和创建这个 OpenGL 上下文,这是 GLAD 开始加载 OpenGL 函数的前提条件。(提供了获取函数地址的方法)
- GLAD 就可以通过
glfwGetProcAddress动态加载所有 OpenGL 函数,而不需要开发者关心平台差异。 - 基本流程就是:使用 GLFW 创建 OpenGL 上下文->使用 GLAD 加载 OpenGL 函数->程序可以调用 OpenGL 函数
stb_image¶
- 可以使用
stb_image.h下载来进行文件图像加载,加载为char*字节量
unsigned int loadTexture(char const* path)
{
unsigned int textureID;
glGenTextures(1, &textureID);
int width, height, nrComponents;
unsigned char* data = stbi_load(path, &width, &height, &nrComponents, 0);
if (data)
{
GLenum format;
if (nrComponents == 1)
format = GL_RED;
else if (nrComponents == 3)
format = GL_RGB;
else if (nrComponents == 4)
format = GL_RGBA;
glBindTexture(GL_TEXTURE_2D, textureID);
glTexImage2D(GL_TEXTURE_2D, 0, format, width, height, 0, format, GL_UNSIGNED_BYTE, data);
glGenerateMipmap(GL_TEXTURE_2D);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
stbi_image_free(data);
}
else
{
std::cout << "Texture failed to load at path: " << path << std::endl;
stbi_image_free(data);
}
return textureID;
}
unsigned int diffuseMap = loadTexture("container2.png");
GLM¶
- 用于opengl的数学库
- GLM库从0.9.9版本起,默认会将矩阵类型初始化为一个零矩阵(所有元素均为0),而不是单位矩阵
- 需要初始化为单位矩阵
glm::mat4 mat = glm::mat4(1.0f) glm是一个头文件库,它不生成动态链接库(.dll)或静态库(.lib),可以直接在项目中包含glm的头文件来使用它。- 常用头文件内容
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
#include <glm/gtc/type_ptr.hpp>
- 可以用glm快速创建各种变换矩阵
glm::vec4 vec(1.0f, 0.0f, 0.0f, 1.0f);
// 译注:下面就是矩阵初始化的一个例子,如果使用的是0.9.9及以上版本
// 下面这行代码就需要改为:
// glm::mat4 trans = glm::mat4(1.0f)
// 之后将不再进行提示
glm::mat4 trans;
trans = glm::translate(trans, glm::vec3(1.0f, 1.0f, 0.0f));
vec = trans * vec;
//glm::radians(90.0f)将角度转化为弧度
//glm::vec3(0.0, 0.0, 1.0)指定旋转方向
trans = glm::rotate(trans, glm::radians(90.0f), glm::vec3(0.0, 0.0, 1.0));
trans = glm::scale(trans, glm::vec3(0.5, 0.5, 0.5));
-
用同一个矩阵
trans可以进行不同的变化,glm会自动将变化乘到trans上,最终用trans乘以目标矩阵就可以实现所有变化(注意变化倒序执行,上面就是先缩放再旋转) -
将变化矩阵传递给着色器
uniform mat4 transform;就可以传递一个四维矩阵
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoord;
out vec2 TexCoord;
uniform mat4 transform;
void main()
{
gl_Position = transform * vec4(aPos, 1.0f);
TexCoord = vec2(aTexCoord.x, 1.0 - aTexCoord.y);
}
unsigned int transformLoc = glGetUniformLocation(ourShader.ID, "transform");
glUniformMatrix4fv(transformLoc, 1, GL_FALSE, glm::value_ptr(trans));
- 1表示要传递的矩阵数目
- GL_FALSE表示是否需要转置矩阵
- value_ptr将glm矩阵转化为opengl可以接受的
Assimp¶
- 用于模型的加载
- 当使用Assimp导入一个模型的时候,它通常会将整个模型加载进一个场景(Scene)对象,它会包含导入的模型/场景中的所有数据。Assimp会将场景载入为一系列的节点(Node),每个节点包含了场景对象中所储存数据的索引,每个节点都可以有任意数量的子节点。
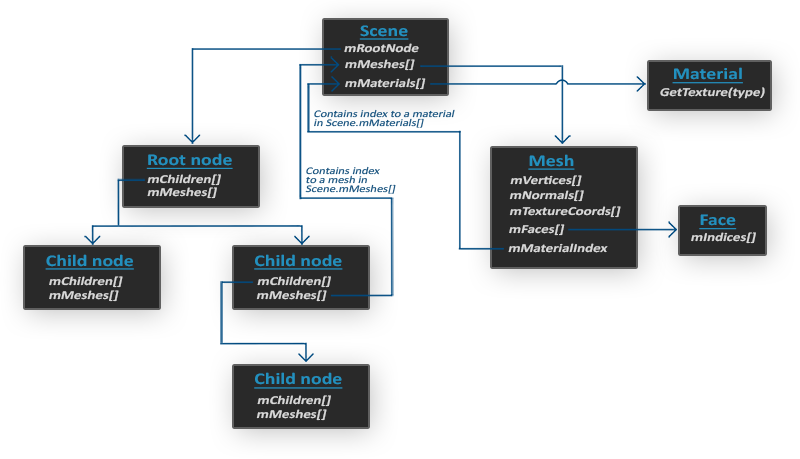
- rootnode存储子节点引用(模型通常不是一个整体,而是由许多子部分组成)
- mesh存储网格信息,如顶点位置、法向量、纹理坐标、面等
-
material
-
Scene中的mMeshes数组是一个全局变量,存储整个场景中所有的网格数据
- 而node中的mMeshes等数组存储的是当前节点所包含的网格数据的索引(实际的数据还是在scene中)
网格加载¶
- 网格数据类
//网格中一点至少包含位置坐标、法向量、uv坐标
struct Vertex {
glm::vec3 Position;
glm::vec3 Normal;
glm::vec2 TexCoords;
};
//储存纹理的id以及它的类型
struct Texture {
unsigned int id;
string type;
};
class Mesh {
public:
/* 网格数据 */
vector<Vertex> vertices;//顶点数据
vector<unsigned int> indices;//索引数据
vector<Texture> textures;//贴图数据
/* 函数 */
Mesh(vector<Vertex> vertices, vector<unsigned int> indices, vector<Texture> textures);
void Draw(Shader shader);
private:
/* 渲染数据 */
unsigned int VAO, VBO, EBO;
/* 函数 */
void setupMesh();
};
Mesh(vector<Vertex> vertices, vector<unsigned int> indices, vector<Texture> textures)
{
this->vertices = vertices;
this->indices = indices;
this->textures = textures;
setupMesh();
}
//建立、绑定数据
void setupMesh()
{
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
glGenBuffers(1, &EBO);
glBindVertexArray(VAO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, vertices.size() * sizeof(Vertex), &vertices[0], GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, indices.size() * sizeof(unsigned int),
&indices[0], GL_STATIC_DRAW);
// 顶点位置
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)0);
// 顶点法线
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Normal));
// 顶点纹理坐标
glEnableVertexAttribArray(2);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, TexCoords));
glBindVertexArray(0);
}
void Draw(Shader shader)
{
unsigned int diffuseNr = 1;
unsigned int specularNr = 1;
for(unsigned int i = 0; i < textures.size(); i++)
{
glActiveTexture(GL_TEXTURE0 + i); // 在绑定之前激活相应的纹理单元
// 获取纹理序号(diffuse_textureN 中的 N)
string number;
string name = textures[i].type;
if(name == "texture_diffuse")
number = std::to_string(diffuseNr++);
else if(name == "texture_specular")
number = std::to_string(specularNr++);
shader.setInt(("material." + name + number).c_str(), i);
glBindTexture(GL_TEXTURE_2D, textures[i].id);
}
glActiveTexture(GL_TEXTURE0);
// 绘制网格
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, indices.size(), GL_UNSIGNED_INT, 0);
glBindVertexArray(0);
}
- 着色器中使用贴图的命名规范:
uniform sampler2D texture_diffuse1;
uniform sampler2D texture_diffuse2;
uniform sampler2D texture_diffuse3;
uniform sampler2D texture_specular1;
uniform sampler2D texture_specular2;
- 完整版,附带切线、骨骼参数的shader类型
#ifndef MESH_H
#define MESH_H
#include <glad/glad.h> // holds all OpenGL type declarations
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
#include <learnopengl/shader.h>
#include <string>
#include <vector>
using namespace std;
#define MAX_BONE_INFLUENCE 4
struct Vertex {
// position
glm::vec3 Position;
// normal
glm::vec3 Normal;
// texCoords
glm::vec2 TexCoords;
// tangent
glm::vec3 Tangent;
// bitangent
glm::vec3 Bitangent;
//bone indexes which will influence this vertex
int m_BoneIDs[MAX_BONE_INFLUENCE];
//weights from each bone
float m_Weights[MAX_BONE_INFLUENCE];
};
struct Texture {
unsigned int id;
string type;
string path;
};
class Mesh {
public:
// mesh Data
vector<Vertex> vertices;
vector<unsigned int> indices;
vector<Texture> textures;
unsigned int VAO;
// constructor
Mesh(vector<Vertex> vertices, vector<unsigned int> indices, vector<Texture> textures)
{
this->vertices = vertices;
this->indices = indices;
this->textures = textures;
// now that we have all the required data, set the vertex buffers and its attribute pointers.
setupMesh();
}
// render the mesh
void Draw(Shader &shader)
{
// bind appropriate textures
unsigned int diffuseNr = 1;
unsigned int specularNr = 1;
unsigned int normalNr = 1;
unsigned int heightNr = 1;
for(unsigned int i = 0; i < textures.size(); i++)
{
glActiveTexture(GL_TEXTURE0 + i); // active proper texture unit before binding
// retrieve texture number (the N in diffuse_textureN)
string number;
string name = textures[i].type;
if(name == "texture_diffuse")
number = std::to_string(diffuseNr++);
else if(name == "texture_specular")
number = std::to_string(specularNr++); // transfer unsigned int to string
else if(name == "texture_normal")
number = std::to_string(normalNr++); // transfer unsigned int to string
else if(name == "texture_height")
number = std::to_string(heightNr++); // transfer unsigned int to string
// now set the sampler to the correct texture unit
glUniform1i(glGetUniformLocation(shader.ID, (name + number).c_str()), i);
// and finally bind the texture
glBindTexture(GL_TEXTURE_2D, textures[i].id);
}
// draw mesh
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, static_cast<unsigned int>(indices.size()), GL_UNSIGNED_INT, 0);
glBindVertexArray(0);
// always good practice to set everything back to defaults once configured.
glActiveTexture(GL_TEXTURE0);
}
private:
// render data
unsigned int VBO, EBO;
// initializes all the buffer objects/arrays
void setupMesh()
{
// create buffers/arrays
glGenVertexArrays(1, &VAO);
glGenBuffers(1, &VBO);
glGenBuffers(1, &EBO);
glBindVertexArray(VAO);
// load data into vertex buffers
glBindBuffer(GL_ARRAY_BUFFER, VBO);
// A great thing about structs is that their memory layout is sequential for all its items.
// The effect is that we can simply pass a pointer to the struct and it translates perfectly to a glm::vec3/2 array which
// again translates to 3/2 floats which translates to a byte array.
glBufferData(GL_ARRAY_BUFFER, vertices.size() * sizeof(Vertex), &vertices[0], GL_STATIC_DRAW);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, indices.size() * sizeof(unsigned int), &indices[0], GL_STATIC_DRAW);
// set the vertex attribute pointers
// vertex Positions
glEnableVertexAttribArray(0);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)0);
// vertex normals
glEnableVertexAttribArray(1);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Normal));
// vertex texture coords
glEnableVertexAttribArray(2);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, TexCoords));
// vertex tangent
glEnableVertexAttribArray(3);
glVertexAttribPointer(3, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Tangent));
// vertex bitangent
glEnableVertexAttribArray(4);
glVertexAttribPointer(4, 3, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, Bitangent));
// ids
glEnableVertexAttribArray(5);
glVertexAttribIPointer(5, 4, GL_INT, sizeof(Vertex), (void*)offsetof(Vertex, m_BoneIDs));
// weights
glEnableVertexAttribArray(6);
glVertexAttribPointer(6, 4, GL_FLOAT, GL_FALSE, sizeof(Vertex), (void*)offsetof(Vertex, m_Weights));
glBindVertexArray(0);
}
};
#endif
模型加载¶
- 加载模型并转化为多个mesh对象
class Model
{
public:
/* 函数 */
Model(char *path)
{
loadModel(path);
}
void Draw(Shader shader);
private:
/* 模型数据 */
vector<Mesh> meshes;
string directory;
/* 函数 */
void loadModel(string path);
void processNode(aiNode *node, const aiScene *scene);
Mesh processMesh(aiMesh *mesh, const aiScene *scene);
vector<Texture> loadMaterialTextures(aiMaterial *mat, aiTextureType type,
string typeName);
};
void Model::Draw(Shader &shader)
{
for(unsigned int i = 0; i < meshes.size(); i++)
meshes[i].Draw(shader);
}
- 使用assimp来加载模型:
aiProcess_Triangulate表示将模型的所有图元变换为三角形aiProcess_FlipUVs表示在处理时翻转y轴纹理坐标aiProcess_GenNormals如果模型不包含法向量的话,就为每个顶点创建法线aiProcess_SplitLargeMeshes将比较大的网格分割成更小的子网格aiProcess_OptimizeMeshes将多个小网格拼接为一个大的网格,减少绘制调用从而进行优化
void Model::loadModel(string path)
{
Assimp::Importer import;
const aiScene *scene = import.ReadFile(path, aiProcess_Triangulate | aiProcess_FlipUVs);
//检查是否加载出错
if(!scene || scene->mFlags & AI_SCENE_FLAGS_INCOMPLETE || !scene->mRootNode)
{
cout << "ERROR::ASSIMP::" << import.GetErrorString() << endl;
return;
}
directory = path.substr(0, path.find_last_of('/'));
//遍历assimp节点树
processNode(scene->mRootNode, scene);
}
void Model::processNode(aiNode *node, const aiScene *scene)
{
// 处理节点所有的网格(如果有的话)
for(unsigned int i = 0; i < node->mNumMeshes; i++)
{
//根据索引从全局数据中取出mesh数据
aiMesh *mesh = scene->mMeshes[node->mMeshes[i]];
meshes.push_back(processMesh(mesh, scene));
}
// 接下来对它的子节点重复这一过程
for(unsigned int i = 0; i < node->mNumChildren; i++)
{
processNode(node->mChildren[i], scene);
}
}
- 实际上可以忽略节点,直接对全局数据中的mesh遍历渲染,但是保留节点层次结构,可以便于进行更多操作
Mesh Model::processMesh(aiMesh *mesh, const aiScene *scene)
{
vector<Vertex> vertices;
vector<unsigned int> indices;
vector<Texture> textures;
for(unsigned int i = 0; i < mesh->mNumVertices; i++)
{
Vertex vertex;
glm::vec3 vector;
//处理坐标
vector.x = mesh->mVertices[i].x;
vector.y = mesh->mVertices[i].y;
vector.z = mesh->mVertices[i].z;
vertex.Position = vector;
vertices.push_back(vertex);
//处理法线
vector.x = mesh->mNormals[i].x;
vector.y = mesh->mNormals[i].y;
vector.z = mesh->mNormals[i].z;
vertex.Normal = vector;
//处理纹理坐标
if(mesh->mTextureCoords[0]) // 网格是否有纹理坐标?
{
glm::vec2 vec;
vec.x = mesh->mTextureCoords[0][i].x;
vec.y = mesh->mTextureCoords[0][i].y;
vertex.TexCoords = vec;
}
else
vertex.TexCoords = glm::vec2(0.0f, 0.0f);
}
// 处理索引
for(unsigned int i = 0; i < mesh->mNumFaces; i++)
{
aiFace face = mesh->mFaces[i];
for(unsigned int j = 0; j < face.mNumIndices; j++)
indices.push_back(face.mIndices[j]);
}
// 处理材质
if(mesh->mMaterialIndex >= 0)
{
aiMaterial *material = scene->mMaterials[mesh->mMaterialIndex];
vector<Texture> diffuseMaps = loadMaterialTextures(material,
aiTextureType_DIFFUSE, "texture_diffuse");
textures.insert(textures.end(), diffuseMaps.begin(), diffuseMaps.end());
vector<Texture> specularMaps = loadMaterialTextures(material,
aiTextureType_SPECULAR, "texture_specular");
textures.insert(textures.end(), specularMaps.begin(), specularMaps.end());
}
return Mesh(vertices, indices, textures);
}
- 首先根据index获取aiMaterial材质对象,然后从中加载漫反射、镜面反射等贴图,
vector<Texture> Model::loadMaterialTextures(aiMaterial *mat, aiTextureType type, string typeName)
{
vector<Texture> textures;
for(unsigned int i = 0; i < mat->GetTextureCount(type); i++)
{
aiString str;
mat->GetTexture(type, i, &str);
Texture texture;
texture.id = TextureFromFile(str.C_Str(), directory);
texture.type = typeName;
texture.path = str;
textures.push_back(texture);
}
return textures;
}
-
进一步优化:全局存储贴图,在加载之前先判断是否已经加载过了
-
完整代码
#ifndef MODEL_H
#define MODEL_H
#include <glad/glad.h>
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
#include <stb_image.h>
#include <assimp/Importer.hpp>
#include <assimp/scene.h>
#include <assimp/postprocess.h>
#include <learnopengl/mesh.h>
#include <learnopengl/shader.h>
#include <string>
#include <fstream>
#include <sstream>
#include <iostream>
#include <map>
#include <vector>
using namespace std;
unsigned int TextureFromFile(const char *path, const string &directory, bool gamma = false);
class Model
{
public:
// model data
vector<Texture> textures_loaded; // stores all the textures loaded so far, optimization to make sure textures aren't loaded more than once.
vector<Mesh> meshes;
string directory;
bool gammaCorrection;
// constructor, expects a filepath to a 3D model.
Model(string const &path, bool gamma = false) : gammaCorrection(gamma)
{
loadModel(path);
}
// draws the model, and thus all its meshes
void Draw(Shader &shader)
{
for(unsigned int i = 0; i < meshes.size(); i++)
meshes[i].Draw(shader);
}
private:
// loads a model with supported ASSIMP extensions from file and stores the resulting meshes in the meshes vector.
void loadModel(string const &path)
{
// read file via ASSIMP
Assimp::Importer importer;
const aiScene* scene = importer.ReadFile(path, aiProcess_Triangulate | aiProcess_GenSmoothNormals | aiProcess_FlipUVs | aiProcess_CalcTangentSpace);
// check for errors
if(!scene || scene->mFlags & AI_SCENE_FLAGS_INCOMPLETE || !scene->mRootNode) // if is Not Zero
{
cout << "ERROR::ASSIMP:: " << importer.GetErrorString() << endl;
return;
}
// retrieve the directory path of the filepath
directory = path.substr(0, path.find_last_of('/'));
// process ASSIMP's root node recursively
processNode(scene->mRootNode, scene);
}
// processes a node in a recursive fashion. Processes each individual mesh located at the node and repeats this process on its children nodes (if any).
void processNode(aiNode *node, const aiScene *scene)
{
// process each mesh located at the current node
for(unsigned int i = 0; i < node->mNumMeshes; i++)
{
// the node object only contains indices to index the actual objects in the scene.
// the scene contains all the data, node is just to keep stuff organized (like relations between nodes).
aiMesh* mesh = scene->mMeshes[node->mMeshes[i]];
meshes.push_back(processMesh(mesh, scene));
}
// after we've processed all of the meshes (if any) we then recursively process each of the children nodes
for(unsigned int i = 0; i < node->mNumChildren; i++)
{
processNode(node->mChildren[i], scene);
}
}
Mesh processMesh(aiMesh *mesh, const aiScene *scene)
{
// data to fill
vector<Vertex> vertices;
vector<unsigned int> indices;
vector<Texture> textures;
// walk through each of the mesh's vertices
for(unsigned int i = 0; i < mesh->mNumVertices; i++)
{
Vertex vertex;
glm::vec3 vector; // we declare a placeholder vector since assimp uses its own vector class that doesn't directly convert to glm's vec3 class so we transfer the data to this placeholder glm::vec3 first.
// positions
vector.x = mesh->mVertices[i].x;
vector.y = mesh->mVertices[i].y;
vector.z = mesh->mVertices[i].z;
vertex.Position = vector;
// normals
if (mesh->HasNormals())
{
vector.x = mesh->mNormals[i].x;
vector.y = mesh->mNormals[i].y;
vector.z = mesh->mNormals[i].z;
vertex.Normal = vector;
}
// texture coordinates
if(mesh->mTextureCoords[0]) // does the mesh contain texture coordinates?
{
glm::vec2 vec;
// a vertex can contain up to 8 different texture coordinates. We thus make the assumption that we won't
// use models where a vertex can have multiple texture coordinates so we always take the first set (0).
vec.x = mesh->mTextureCoords[0][i].x;
vec.y = mesh->mTextureCoords[0][i].y;
vertex.TexCoords = vec;
// tangent
vector.x = mesh->mTangents[i].x;
vector.y = mesh->mTangents[i].y;
vector.z = mesh->mTangents[i].z;
vertex.Tangent = vector;
// bitangent
vector.x = mesh->mBitangents[i].x;
vector.y = mesh->mBitangents[i].y;
vector.z = mesh->mBitangents[i].z;
vertex.Bitangent = vector;
}
else
vertex.TexCoords = glm::vec2(0.0f, 0.0f);
vertices.push_back(vertex);
}
// now wak through each of the mesh's faces (a face is a mesh its triangle) and retrieve the corresponding vertex indices.
for(unsigned int i = 0; i < mesh->mNumFaces; i++)
{
aiFace face = mesh->mFaces[i];
// retrieve all indices of the face and store them in the indices vector
for(unsigned int j = 0; j < face.mNumIndices; j++)
indices.push_back(face.mIndices[j]);
}
// process materials
aiMaterial* material = scene->mMaterials[mesh->mMaterialIndex];
// we assume a convention for sampler names in the shaders. Each diffuse texture should be named
// as 'texture_diffuseN' where N is a sequential number ranging from 1 to MAX_SAMPLER_NUMBER.
// Same applies to other texture as the following list summarizes:
// diffuse: texture_diffuseN
// specular: texture_specularN
// normal: texture_normalN
// 1. diffuse maps
vector<Texture> diffuseMaps = loadMaterialTextures(material, aiTextureType_DIFFUSE, "texture_diffuse");
textures.insert(textures.end(), diffuseMaps.begin(), diffuseMaps.end());
// 2. specular maps
vector<Texture> specularMaps = loadMaterialTextures(material, aiTextureType_SPECULAR, "texture_specular");
textures.insert(textures.end(), specularMaps.begin(), specularMaps.end());
// 3. normal maps
std::vector<Texture> normalMaps = loadMaterialTextures(material, aiTextureType_HEIGHT, "texture_normal");
textures.insert(textures.end(), normalMaps.begin(), normalMaps.end());
// 4. height maps
std::vector<Texture> heightMaps = loadMaterialTextures(material, aiTextureType_AMBIENT, "texture_height");
textures.insert(textures.end(), heightMaps.begin(), heightMaps.end());
// return a mesh object created from the extracted mesh data
return Mesh(vertices, indices, textures);
}
// checks all material textures of a given type and loads the textures if they're not loaded yet.
// the required info is returned as a Texture struct.
vector<Texture> loadMaterialTextures(aiMaterial *mat, aiTextureType type, string typeName)
{
vector<Texture> textures;
for(unsigned int i = 0; i < mat->GetTextureCount(type); i++)
{
aiString str;
mat->GetTexture(type, i, &str);
// check if texture was loaded before and if so, continue to next iteration: skip loading a new texture
bool skip = false;
for(unsigned int j = 0; j < textures_loaded.size(); j++)
{
if(std::strcmp(textures_loaded[j].path.data(), str.C_Str()) == 0)
{
textures.push_back(textures_loaded[j]);
skip = true; // a texture with the same filepath has already been loaded, continue to next one. (optimization)
break;
}
}
if(!skip)
{ // if texture hasn't been loaded already, load it
Texture texture;
texture.id = TextureFromFile(str.C_Str(), this->directory);
texture.type = typeName;
texture.path = str.C_Str();
textures.push_back(texture);
textures_loaded.push_back(texture); // store it as texture loaded for entire model, to ensure we won't unnecessary load duplicate textures.
}
}
return textures;
}
};
unsigned int TextureFromFile(const char *path, const string &directory, bool gamma)
{
string filename = string(path);
filename = directory + '/' + filename;
unsigned int textureID;
glGenTextures(1, &textureID);
int width, height, nrComponents;
unsigned char *data = stbi_load(filename.c_str(), &width, &height, &nrComponents, 0);
if (data)
{
GLenum format;
if (nrComponents == 1)
format = GL_RED;
else if (nrComponents == 3)
format = GL_RGB;
else if (nrComponents == 4)
format = GL_RGBA;
glBindTexture(GL_TEXTURE_2D, textureID);
glTexImage2D(GL_TEXTURE_2D, 0, format, width, height, 0, format, GL_UNSIGNED_BYTE, data);
glGenerateMipmap(GL_TEXTURE_2D);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
stbi_image_free(data);
}
else
{
std::cout << "Texture failed to load at path: " << path << std::endl;
stbi_image_free(data);
}
return textureID;
}
#endif
opengl¶
常用的数据类型¶
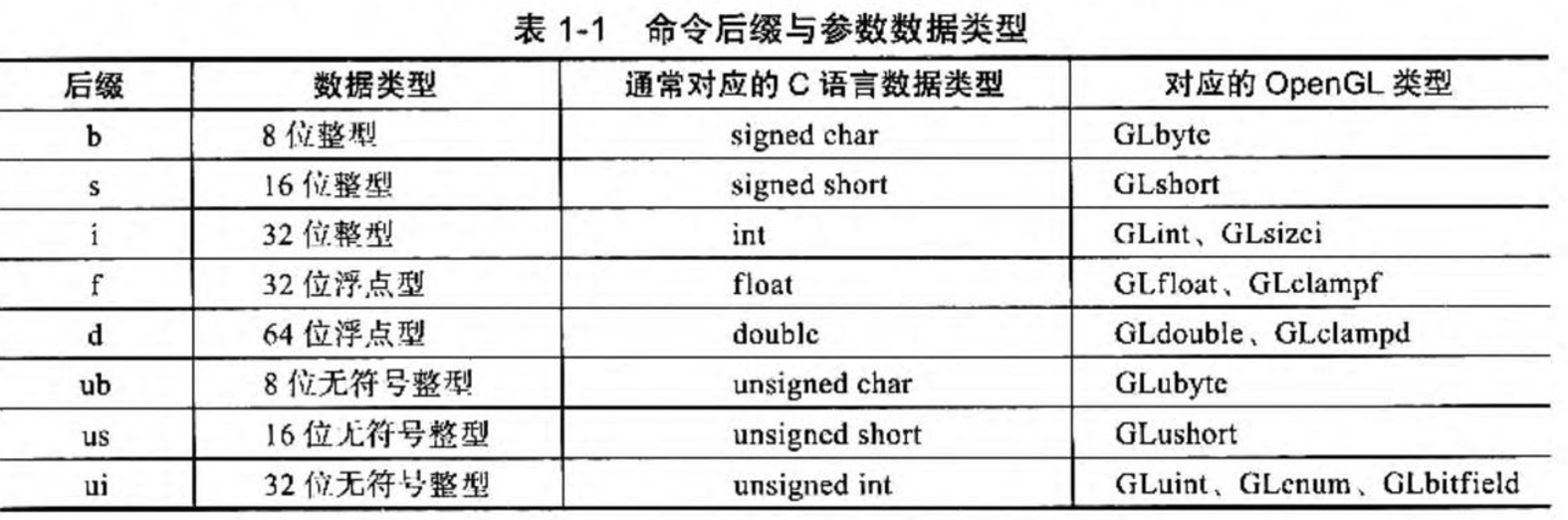 - 最好使用 opengl 提供的数据类型,这样就能避免在不同版本 opengl 之间一直代码出现不匹配的问题
- 最好使用 opengl 提供的数据类型,这样就能避免在不同版本 opengl 之间一直代码出现不匹配的问题
工作流程¶
-
几个重要概念
- 顶点数组对象:Vertex Array Object,VAO
- 顶点缓冲对象:Vertex Buffer Object,VBO
-
元素缓冲对象:Element Buffer Object,EBO 或 索引缓冲对象 Index Buffer Object,IBO
-
渲染管线接受一组 3 D 坐标,最终转化为屏幕上的 2 D 画面
- 渲染管线包含一系列着色器,流水线处理数据,opengl 中的着色器使用 GLSL 语言
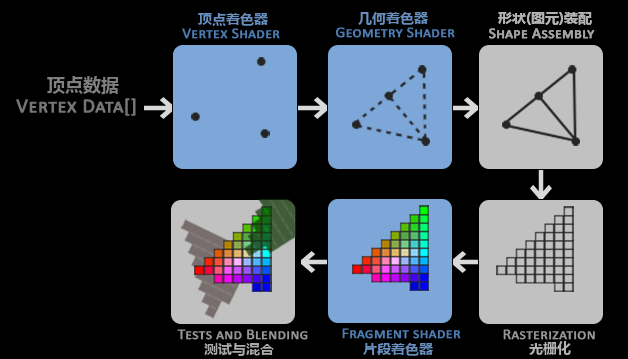
- 图元用于指示 opengl 如何处理输入,如把一系列点绘制成三角形?线?等。即传递绘制指令,如
GL_POINTS、GL_TRIANGLES、GL_LINE_STRIP
基本流程 - 顶点着色器接受单独的顶点作为输入,将 3 D 坐标进行转化(比如转换到 opengl 的可视区域),并对顶点的属性进行一些基本处理 - 几何着色器接受顶点着色器的输出,通过输入的顶点形成图元 - 图元装配阶段将预处理的顶点装配成图元的形状 - 片段着色器就散像素的颜色(结合光照等信息) - 测试与混合阶段进行深度测试,以及不透明度的混合
- opengl 中至少要配置顶点着色器和判断着色器
- opengl 只处理-1~1 立方范围内的信息
- 使用 GLSL 编写着色器,编译之后就可以在程序中使用
链接顶点属性¶
- 上面的三个点以 float 来存储

- 指出如何来解析顶点数据
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0); glEnableVertexAttribArray(0); 0表示顶点属性所在的位置(对应编译器中的位置location=0)3表示参数类型的大小(由几个值组成),即 Vec 3GL_FLOAT制定参数的类型GL_FALSE表示是否要进行标准化(0~1)映射3 * sizeof(float)表示连续的属性之间的存储间隔,为 0 时由 opengl 自动决定(连续紧密排列)(void*)0表示数据在缓冲中的起始位置的偏移量-
顶点属性是从之前绑定了
GL_ARRAY_BUFFER的 VBO 顶点缓冲对象来获取的 -
基本工作流程如下
// 0. 复制顶点数组到缓冲中供OpenGL使用
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 1. 设置顶点属性指针
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 2. 当我们渲染一个物体时要使用着色器程序
glUseProgram(shaderProgram);
// 3. 绘制物体
someOpenGLFunctionThatDrawsOurTriangle();
- 当然也可以使用更多的属性,比如位置+颜色
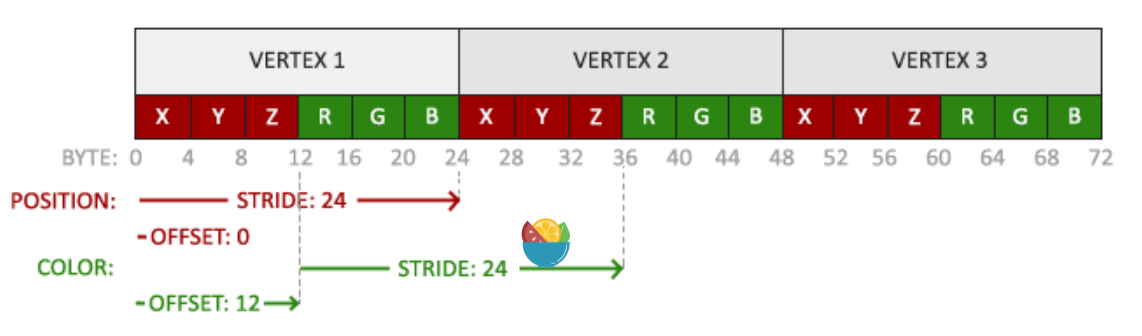
// 位置属性
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 颜色属性
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 6 * sizeof(float), (void*)(3* sizeof(float)));
glEnableVertexAttribArray(1);
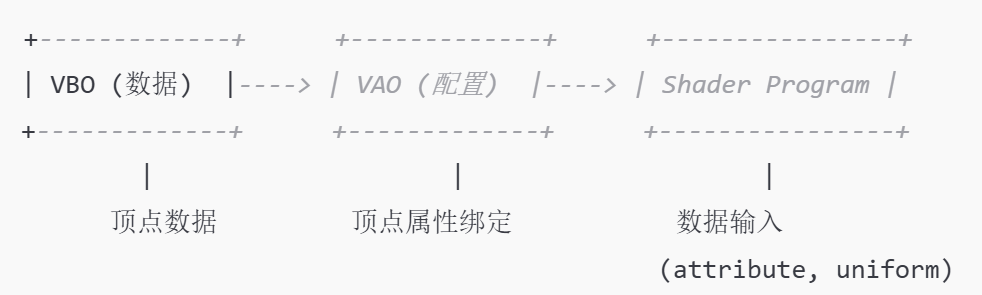
顶点数组对象 VAO¶
- 每次都重新进行绑定设置很麻烦,使用顶点数组对象 VAO可以像顶点缓冲对象那样被绑定,任何随后的顶点属性调用都会储存在这个 VAO 中。
- VAO 是一个容器,用于保存多个 VBO 的状态以及如何解释这些 VBO 中的数据。它记录了如何将 VBO 中的数据绑定到顶点属性上。
- VAO 可以看作是一个“顶点属性的配置快照”。一旦配置好,VAO 会记录下所有与顶点属性相关的状态(例如顶点数据的格式、位置、是否启用等)。
- VAO 本身不直接存储顶点数据,而是保存了 VBO 和顶点属性之间的关联。当绑定 VAO 时,OpenGL 会自动按照配置好的顶点属性状态读取数据。
- VAO 允许我们在绘制不同物体时只需绑定不同的 VAO 就能快速切换顶点属性的配置,方便管理多个物体的不同顶点属性。
- opengl 可以通过 VAO 获取要使用的数据和读取方式
- 即VBO 提供实际的顶点数据,而 VAO 则定义了如何使用这些数据。
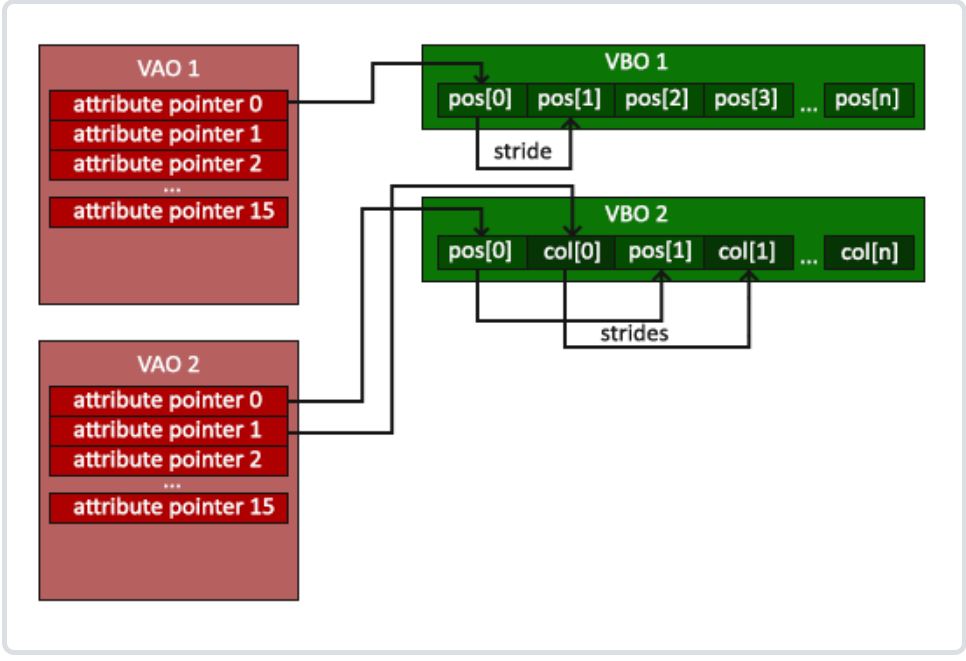
- 只需要使用 glBindVertexArray 绑定 VAO
- 绑定之后,所有与顶点属性的设置操作(例如,绑定 VBO、设置顶点属性指针等)都将与这个 VAO 关联。
- 之后通过绑定不同的 VAO,快速切换不同的顶点数据和状态,而无需重新配置顶点属性指针。
//创建VAO
unsigned int VAO;
glGenVertexArrays(1, &VAO);//创建之后还需要进行绑定才能初始化(可以创建指定多个对象,并存储在数组中)
//glCreateVertexArrays直接创建并初始化 VAO,无需绑定,可以直接通过id进行操作
/*
for (int i = 0; i < 3; ++i) {
// 配置VAO,而无需绑定
glVertexArrayAttribBinding(vaos[i], 0, 0); // 配置属性绑定
glVertexArrayAttribFormat(vaos[i], 0, 3, GL_FLOAT, GL_FALSE, 0);
glEnableVertexArrayAttrib(vaos[i], 0);
}
*/
//绑定VAO
glBindVertexArray(VAO);
//解除绑定
glBindVertexArray(0);
元素缓冲对象 EBO¶
-
EBO 是一个缓冲区,就像一个顶点缓冲区对象一样,它存储 OpenGL 用来决定要绘制哪些顶点的索引(决定点的绘制顺序避免性能浪费,比如两个三角拼接成一个矩形)
-
使用索引来用更少的点进行绘制
float vertices[] = {
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};
unsigned int indices[] = {
// 注意索引从0开始!
// 此例的索引(0,1,2,3)就是顶点数组vertices的下标,
// 这样可以由下标代表顶点组合成矩形
0, 1, 3, // 第一个三角形
1, 2, 3 // 第二个三角形
};
//创建EBO
unsigned int EBO;
glGenBuffers(1, &EBO);
//把索引复制到缓冲里
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
//使用索引进行绘制
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
- 当目标是 GL_ELEMENT_ARRAY_BUFFER 的时候,VAO 会储存 glBindBuffer 的函数调用,这样使用时就只需要绑定 VAO 而不再需要绑定 EBO
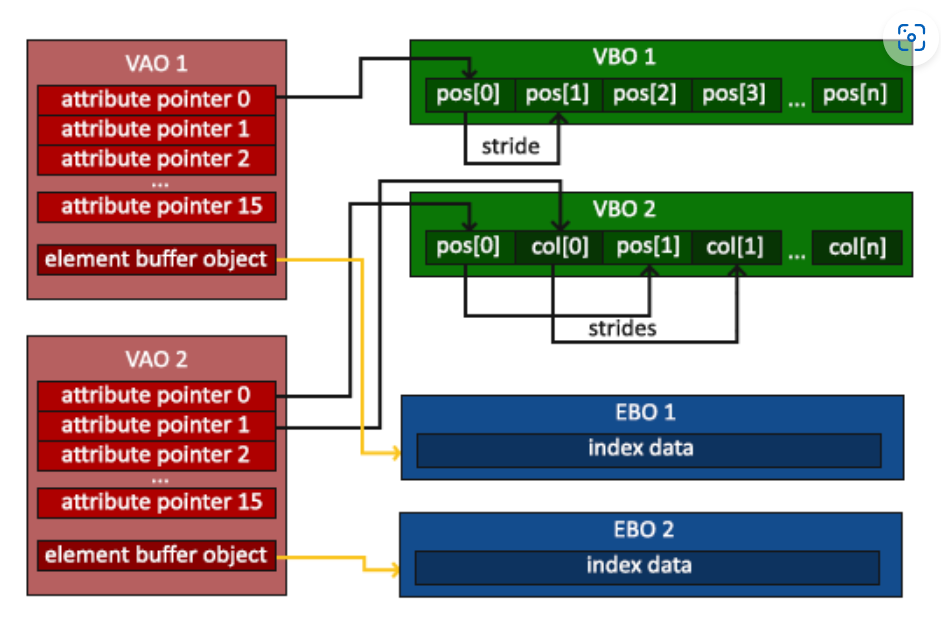
// ..:: 初始化代码 :: ..
// 1. 绑定顶点数组对象
glBindVertexArray(VAO);
// 2. 把我们的顶点数组复制到一个顶点缓冲中,供OpenGL使用
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 3. 复制我们的索引数组到一个索引缓冲中,供OpenGL使用
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
// 4. 设定顶点属性指针
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
[...]
// ..:: 绘制代码(渲染循环中) :: ..
glUseProgram(shaderProgram);
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
glBindVertexArray(0);
顶点着色器¶
- 创建并编译着色器
//着色器代码
const char *vertexShaderSource = "#version 330 core\n"
"layout (location = 0) in vec3 aPos;\n"
"void main()\n"
"{\n"
" gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);\n"
"}\0";
//创建点着色器,同样用id表示
unsigned int vertexShader;
vertexShader = glCreateShader(GL_VERTEX_SHADER);
//传入并编译着色器(要编译的着色器,字符串树木,字符参数)
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);
- 检查编译错误并输出错误信息
int success;
char infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);
if(!success)
{
glGetShaderInfoLog(vertexShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl;
}
片段着色器¶
- 创建与编译与点着色器同理
const char* fragmentShaderSource = "#version 330 core\n"
"out vec4 FragColor;\n"
"void main()\n"
"{\n"
" FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);\n"
"}\n\0";
unsigned int fragmentShader;
fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);
链接着色器¶
- 将编译好的着色器对象链接到用于渲染的程序对象
//创建着色器
unsigned int shaderProgram;
shaderProgram = glCreateProgram();
//附加编译好的着色器
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
//链接
glLinkProgram(shaderProgram);
//同样可以检查是否成功
glGetProgramiv(shaderProgram, GL_LINK_STATUS, &success);
if(!success) {
glGetProgramInfoLog(shaderProgram, 512, NULL, infoLog);
...
}
- 创建好之后激活程序对象
glUseProgram(shaderProgram); - 之后每个着色器调用和渲染调用都会使用这个程序对象
- 创建之后可以释放之前的着色器对象
glDeleteShader(vertexShader); glDeleteShader(fragmentShader);
计算着色器¶
- 计算着色器是一种独立于传统渲染管线的 GPU 程序
- 可以直接访问和修改图像、缓冲区数据
- 适合执行通用的计算任务,如图像处理、物理模拟、人工智能推理、数学运算等
- 常见用途:图像处理;粒子系统模拟;物理计算;神经网络推理;数据处理
工作组¶
- 计算着色器的执行模型基于 工作组,这是 GPU 并行计算的基本单位。
- 计算着色器的执行由大量线程组成,称为 全局工作项。
- 全局工作项被分割为若干 工作组,而每个工作组又包含多个 局部工作项
- 着色器中指定工作组的大小
layout(local_size_x = 16, local_size_y = 16) in;即定义了一个 16x16 的工作组,即每个工作组包含 256 个线程。 - 在全局工作项中指定工作组的数目
glDispatchCompute(num_groups_x, num_groups_y, num_groups_z); - 每个着色器可以通过内置变量得到其在本地工作组中的相对坐标,从而确定自己的分工
设置缓冲区¶
- 通过 VBO 顶点缓冲对象管理存储顶点数据的内存(由 cpu 发送到 gpu 并存储在显存中),之后顶点着色器就能迅速访问显存中的顶点数据
//定义顶点坐标 float vertices[] = { -0.5f, -0.5f, 0.0f, 0.5f, -0.5f, 0.0f, 0.0f, 0.5f, 0.0f }; //存储缓冲区对象id unsigned int VBO; //生成缓冲区对象并获取id glGenBuffers(1, &VBO); //将缓冲对象绑定到上下文,作为数组缓冲区 glBindBuffer(GL_ARRAY_BUFFER, VBO); //复制数据到缓冲区 glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW); - 复制数据的选项:
- GL_STATIC_DRAW :数据不会或几乎不会改变。
- GL_DYNAMIC_DRAW:数据会被改变很多。
- GL_STREAM_DRAW :数据每次绘制时都会改变。
完整代码¶
#include <glad\glad.h>
#include <GLFW\glfw3.h>
#include <iostream>
void framebuffer_size_callback(GLFWwindow* window, int width, int height)
{
glViewport(0, 0, width, height);
}
void processInput(GLFWwindow* window)
{
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}
int main()
{
//参数设置
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
//创建上下文
GLFWwindow* window = glfwCreateWindow(800, 600, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
//板顶函数
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
//设置视口大小
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
float vertices[] = {
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};
unsigned int indices[] = {
// 注意索引从0开始!
// 此例的索引(0,1,2,3)就是顶点数组vertices的下标,
// 这样可以由下标代表顶点组合成矩形
0, 1, 3, // 第一个三角形
1, 2, 3 // 第二个三角形
};
unsigned int VAO;
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
//存储缓冲区对象id
unsigned int VBO;
//生成缓冲区对象并获取id
glGenBuffers(1, &VBO);
//将缓冲对象绑定到上下文,作为数组缓冲区
glBindBuffer(GL_ARRAY_BUFFER, VBO);
//复制数据到缓冲区
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
unsigned int EBO;
glGenBuffers(1, &EBO);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
const char* vertexShaderSource = "#version 330 core\n"
"layout (location = 0) in vec3 aPos;\n"
"void main()\n"
"{\n"
" gl_Position = vec4(aPos.x, aPos.y, aPos.z, 1.0);\n"
"}\0";
//创建点着色器,同样用id表示
unsigned int vertexShader;
vertexShader = glCreateShader(GL_VERTEX_SHADER);
//传入并编译着色器
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);
int success;
char infoLog[512];
glGetShaderiv(vertexShader, GL_COMPILE_STATUS, &success);
if (!success)
{
glGetShaderInfoLog(vertexShader, 512, NULL, infoLog);
std::cout << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl;
}
const char* fragmentShaderSource = "#version 330 core\n"
"out vec4 FragColor;\n"
"void main()\n"
"{\n"
" FragColor = vec4(1.0f, 0.5f, 0.2f, 1.0f);\n"
"}\n\0";
unsigned int fragmentShader;
fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);
unsigned int shaderProgram;
shaderProgram = glCreateProgram();
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
glLinkProgram(shaderProgram);
glUseProgram(shaderProgram);
glDeleteShader(vertexShader);
glDeleteShader(fragmentShader);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
while (!glfwWindowShouldClose(window))
{
// 输入
processInput(window);
// 渲染指令
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
glUseProgram(shaderProgram);
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
glBindVertexArray(0);
// 检查并调用事件,交换缓冲
glfwSwapBuffers(window);
glfwPollEvents();
}
//释放资源
glfwTerminate();
return 0;
}
缓存¶
- 常见的缓存:颜色缓存;深度缓存;模板缓存
清除缓存¶
- 清除缓存:
void glClearBufferfv(GLenum buffer,GLint drawbuffer,const GLfloat *value);- 清除地缓存(如 GL_COLOR)
- 处理多个颜色缓冲的情况
- 清除后的初始值
- 清除不同的数据类型

- 如用
glClearBufferiv清除整数数据模板缓存
glClearBufferfi()可以同时清除深度和模板缓存- 采纳数必须为
GL_DEPTH_STENCIL,0
- 采纳数必须为
缓存掩码¶
- 在 opengl 向颜色、深度或者模板缓存写入数据之前可以对数据进行一次掩码操作

- 通过 bool 来设置是否允许进行写入(即用 1 进行与还是用 0 进行)
混合¶
- 一个输入的片元通过了测试,就可以与当前颜色缓存中当前内容通过某种方式来进行合并了(直接覆盖现有的值就实现深度缓冲遮挡效果、进行计算就是“融混”)
- 开启混合
glEnable(GL_BLEND);
含透明通道贴图¶
- 使用有透明分量的纹理时
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, data); - 要注意使用
GL_RGBA - 在着色器中可以根据 alpha 的值来判断是否丢弃像素(这个点显示为透明)
void main()
{
vec4 texColor = texture(texture1, TexCoords);
if(texColor.a < 0.1)
discard;
FragColor = texColor;
}
- 要注意的是,如果使用 GL_REPEAT 等环绕方式,由于 OpenGL 会对边缘的值和纹理下一个重复的值进行插值导致边框具有颜色,这就可能产生一个半透明有色边框,对于这种图片就要使用 GL_CLAMP_TO_EDGE 环绕方式
颜色混合¶
- 混合方程 \(\bar{C}_{result}=\bar{C}_{source}*F_{source}+\bar{C}_{destination}*F_{destination}\)
- 颜色 1*源因子值+颜色 2*目标因子值
glBlendFunc(GLenum sfactor, GLenum dfactor)函数接受两个参数,来设置源和目标因子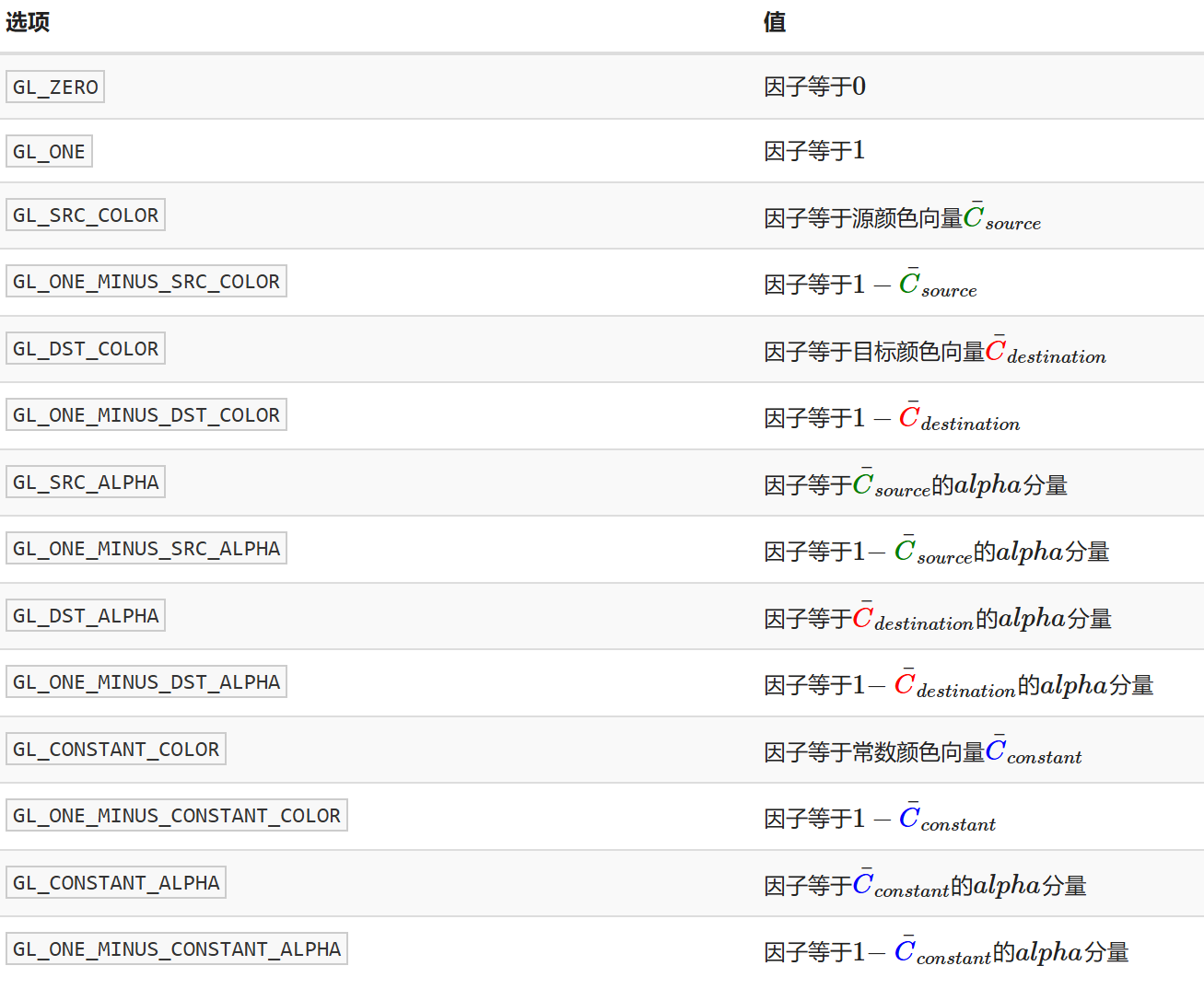
- 比如使用源的 alpha、1-alpha:
glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA); - 也可以使用
glBlendFuncSeparate来分别设置 RGBA 四个通道 glBlendEquation(GLenum mode)设置颜色的运算方式- GL_FUNC_ADD:默认选项,将两个分量相加
- GL_FUNC_SUBTRACT:将两个分量相减
-
GL_FUNC_REVERSE_SUBTRACT:将两个分量相减,但顺序相反
-
同时使用深度测试和混合会存在问题,导致不该被丢弃的内容被丢弃
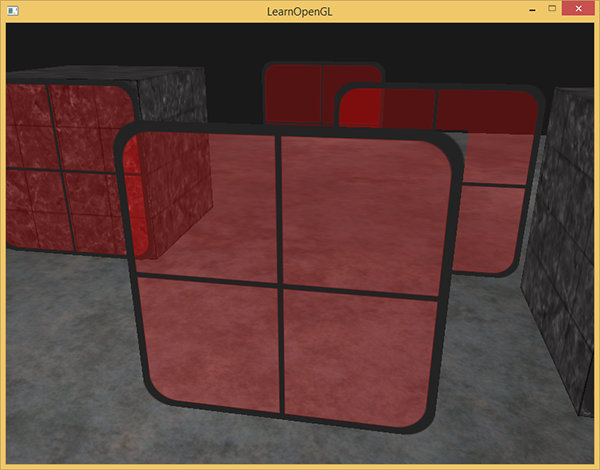
- 对于每一个片段,深度测试会比较它的深度值与深度缓冲的当前值。如果深度测试失败该片段会被丢弃,即使当前值所在的贴图是半透明的!这就丢失了数据
-
要想保证窗户中能够显示它们背后的窗户,我们需要首先绘制背后的这部分窗户。这也就是说在绘制的时候,我们必须先手动将窗户按照最远到最近来排序,再按照顺序渲染。
-
使用混合时的渲染原则
- 先绘制所有不透明的物体。
- 对所有透明的物体排序。
-
按顺序绘制所有透明的物体。
-
排序透明物体:观察者视角获取物体的距离,可以通过计算摄像机位置向量和物体的位置向量之间的距离所获得
std::map<float, glm::vec3> sorted;
for (unsigned int i = 0; i < windows.size(); i++)
{
float distance = glm::length(camera.Position - windows[i]);
sorted[distance] = windows[i];
}
- 渲染时直接从 map 读取排好序的
for(std::map<float,glm::vec3>::reverse_iterator it = sorted.rbegin(); it != sorted.rend(); ++it)
{
model = glm::mat4();
model = glm::translate(model, it->second);
shader.setMat4("model", model);
glDrawArrays(GL_TRIANGLES, 0, 6);
}
面剔除¶
-
丢弃背对观察者的面,只渲染面向观察者的面,节省开销
-
以环绕顺序来定义三角形的顶点
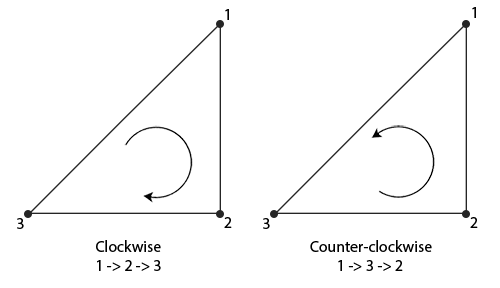
- 全部按照逆时针规则进行定义(对顶点数据的要求)
-
这样从正面看为逆时针的三角形就是面向观察者的面,顺时针的就是背对的面,可以进行剔除
-
启用面剔除:
glEnable(GL_CULL_FACE); - 剔除的面的类型
glCullFace(GL_FRONT); GL_BACK:只剔除背向面。GL_FRONT:只剔除正向面。GL_FRONT_AND_BACK:剔除正向面和背向面。- 正面的方向
glFrontFace(GL_CCW); - GL_CCW 表示逆时针环绕
- GL_CW 表示顺时针环绕
帧缓冲¶
- 颜色缓冲、深度信息缓冲等各种缓冲结合再起来就是帧缓冲,默认的帧缓冲是窗口时生成和配置的
- 帧缓冲是一种容器对象,用于管理多个附件
-
可以用于离屏渲染:将渲染结果输出到纹理或其他附件上而不是直接显示在屏幕
-
创建帧缓冲对象
unsigned int fbo; glGenFramebuffers(1, &fbo); //绑定为当前激活的帧缓冲 glBindFramebuffer(GL_FRAMEBUFFER, fbo); -
绑定帧缓冲之后,所有的读取和写入帧缓冲的操作都会影响绑定的帧缓冲
-
也可以用 GL_READ_FRAMEBUFFER 或 GL_DRAW_FRAMEBUFFER 分别进行绑定
-
完整的帧缓冲:
- 附加至少一个缓冲(颜色、深度或模板缓冲)。
- 至少有一个颜色附件 (Attachment)。
- 所有的附件都必须是完整的(保留了内存)。
- 每个缓冲都应该有相同的样本数 (sample)。
-
检查帧缓冲是否完整
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) == GL_FRAMEBUFFER_COMPLETE) -
之后所有的渲染操作将会渲染到当前绑定帧缓冲的附件中, 要保证所有的渲染操作在主窗口中有视觉效果,我们需要再次激活默认帧缓冲,将它绑定到
0。 glBindFramebuffer(GL_FRAMEBUFFER, 0);
纹理附件¶
-
可以直接采样,适合需要后续处理的情况
-
当把一个纹理附加到帧缓冲的时候,所有的渲染指令将会写入到这个纹理中,所有渲染操作的结果将会被储存在一个纹理图像中
unsigned int texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
//只分配空间,并没有设置纹理数据
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texture, 0);
//创建一个深度&模板缓冲的纹理(正好24+8=32)
glTexImage2D(
GL_TEXTURE_2D, 0, GL_DEPTH24_STENCIL8, 800, 600, 0,
GL_DEPTH_STENCIL, GL_UNSIGNED_INT_24_8, NULL
);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_TEXTURE_2D, texture, 0);
- 将纹理附加到帧缓冲
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texture, 0); target:帧缓冲的目标(绘制、读取或者两者皆有)attachment:我们想要附加的附件类型。当前我们正在附加一个颜色附件。注意最后的0意味着我们可以附加多个颜色附件。我们将在之后的教程中提到。textarget:你希望附加的纹理类型texture:要附加的纹理本身level:多级渐远纹理的级别。我们将它保留为 0。
渲染缓冲对象附件¶
- 用于存储渲染过程中生成的数据,不能直接采样,主要用于中间渲染结果的存储,实际存储了渲染数据
- 直接将多有的渲染数据存储到缓冲中,不进行任何转换,效率很高
- 渲染缓冲对象通常都是只写的:不能采样(通过纹理坐标进行访问),但是可以将数据复制到纹理再进行访问
unsigned int rbo;
glGenRenderbuffers(1, &rbo);
//绑定帧缓冲对象
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
//为渲染缓冲对象分配存储空间
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);
//将渲染缓冲对象附加到帧缓冲对象
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
渲染到纹理¶
- 将一个场景附加到帧缓冲对象上的颜色纹理并在图形上绘制这个纹理
//创建帧缓冲对象
unsigned int framebuffer;
glGenFramebuffers(1, &framebuffer);
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer);
// 生成纹理(颜色纹理需要采样、显示,因此使用纹理附件)
unsigned int texColorBuffer;
glGenTextures(1, &texColorBuffer);
glBindTexture(GL_TEXTURE_2D, texColorBuffer);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, 800, 600, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR );
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glBindTexture(GL_TEXTURE_2D, 0);
// 将它附加到当前绑定的帧缓冲对象
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D, texColorBuffer, 0);
//深度、模板缓冲不需要采样,因此使用帧缓冲对象
unsigned int rbo;
glGenRenderbuffers(1, &rbo);
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, 800, 600);
glBindRenderbuffer(GL_RENDERBUFFER, 0);
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
//检查是否完整
if(glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE)
std::cout << "ERROR::FRAMEBUFFER:: Framebuffer is not complete!" << std::endl;
//接下来将新的帧缓冲绑定为激活的帧缓冲
glBindFramebuffer(GL_FRAMEBUFFER, 0);
- 离屏渲染
glBindFramebuffer(GL_FRAMEBUFFER, framebuffer); // 绑定自定义帧缓冲
glClearColor(0.1f, 0.1f, 0.1f, 1.0f); // 设置清屏颜色
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); // 清空颜色缓冲和深度缓冲
glEnable(GL_DEPTH_TEST); // 启用深度测试
DrawScene(); // 渲染场景
- 屏幕渲染
glBindFramebuffer(GL_FRAMEBUFFER, 0); // 绑定默认帧缓冲(屏幕帧缓冲)
glClearColor(1.0f, 1.0f, 1.0f, 1.0f); // 设置屏幕清屏颜色为白色
glClear(GL_COLOR_BUFFER_BIT); // 清空屏幕的颜色缓冲
screenShader.use(); // 使用屏幕渲染的着色器
glBindVertexArray(quadVAO); // 绑定渲染屏幕四边形的VAO
glDisable(GL_DEPTH_TEST); // 禁用深度测试
glBindTexture(GL_TEXTURE_2D, textureColorbuffer);// 绑定第一阶段的颜色缓冲纹理
glDrawArrays(GL_TRIANGLES, 0, 6); // 绘制屏幕四边形
后期处理¶
- 可以在离屏渲染后,切换使用后期处理着色器,即实现在屏幕渲染阶段的后期处理
- 此时可以实现很多效果,因为可以获得一个像素及其周边像素的数据 (核采样时要小心环绕扩展方式造成的影响)
- 如模糊效果 \(\begin{bmatrix}1&2&1\\2&4&2\\1&2&1\end{bmatrix}/16\)
高级数据¶
- 通过
glBufferData可以创建缓冲对象,并用数据立即进行填充 - 也可以通过
glBufferSubData来填充特定的缓冲区域 glBufferSubData(GL_ARRAY_BUFFER, 24, sizeof(data), &data);- 缓冲目标、偏移量、数据大小、数据源
- 要保证缓冲区有足够大的内存
- 也可以直接
void *ptr = glMapBuffer(GL_ARRAY_BUFFER, GL_WRITE_ONLY);获取缓冲区内存的指针,再通过memcpy等直接修改缓冲区的内容 -
释放指针
glUnmapBuffer(GL_ARRAY_BUFFER); -
除了使用类似结构体那样交替存储顶点数据(123123123123),采用分批的方式进行存储(111122223333)
- 有时获得的时这种分批方式存储的数据
float positions[] = { ... };
float normals[] = { ... };
float tex[] = { ... };
// 填充缓冲
glBufferSubData(GL_ARRAY_BUFFER, 0, sizeof(positions), &positions);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions), sizeof(normals), &normals);
glBufferSubData(GL_ARRAY_BUFFER, sizeof(positions) + sizeof(normals), sizeof(tex), &tex);
//绑定
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), 0);
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)(sizeof(positions)));
glVertexAttribPointer(
2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)(sizeof(positions) + sizeof(normals)));
- 复制缓冲
void glCopyBufferSubData(GLenum readtarget, GLenum writetarget, GLintptr readoffset, GLintptr writeoffset, GLsizeiptr size); readtarget和writetarget参数需要填入复制源和复制目标的缓冲目标。比如说,我们可以将 VERTEX_ARRAY_BUFFER 缓冲复制到 VERTEX_ELEMENT_ARRAY_BUFFER缓冲- 也可以使用提供的专供复制的 GL_COPY_READ_BUFFER 和 GL_COPY_WRITE_BUFFER
float vertexData[] = { ... };
glBindBuffer(GL_COPY_READ_BUFFER, vbo1);
glBindBuffer(GL_COPY_WRITE_BUFFER, vbo2);
glCopyBufferSubData(GL_COPY_READ_BUFFER, GL_COPY_WRITE_BUFFER, 0, 0, sizeof(vertexData));
变换¶
坐标系统¶
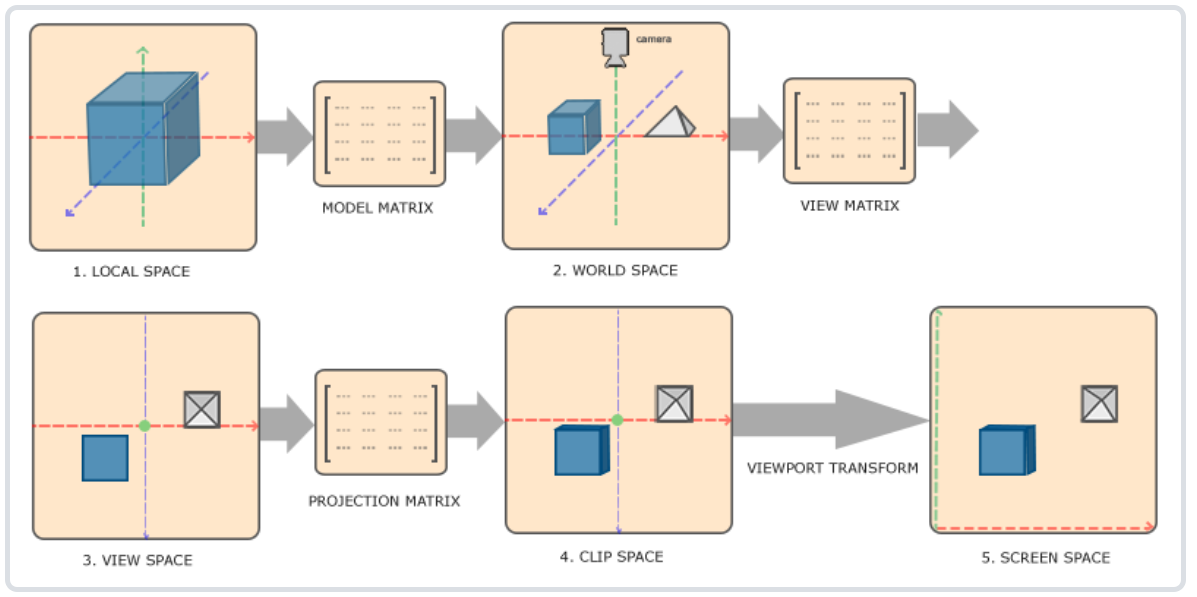
- 局部空间(Local Space):对象相对于局部原点的坐标
- 适合对物体自身进行操作 (如调整模型)
- 通过模型矩阵转换
- 世界空间(World Space):相当于世界的全局原点
- 物体之间的位置关系,对物体进行移动、缩放、旋转等,场景布置
- 通过观察矩阵转换
- 观察空间(View Space):从摄像机/观察者角度观察
- opengl 本身没有摄像机的概念,通过相反移动物体来实现模拟摄像机
-
通过投影矩阵转换
-
裁剪空间(Clip Space):裁剪到 -1~1 的范围
- 将大范围坐标转化到小范围,比如在每个维度上的-1000 到 1000。投影矩阵接着会将在这个指定的范围内的坐标变换为标准化设备坐标的范围 (-1.0, 1.0)。所有在范围外的坐标不会被映射到在-1.0 到 1.0 的范围之间,所以会被裁剪掉。
- 裁剪之后进行投影映射到屏幕空间
-
屏幕空间(Screen Space):屏幕上的坐标
-
正交投影
- 可以使用 glm 创建投影矩阵
glm::ortho(0.0f, 800.0f, 0.0f, 600.0f, 0.1f, 100.0f); - 参数给出了宽度,长度,远近平面的范围
- 主要用于二维渲染、建筑工程
- 透视投影
glm::mat4 proj = glm::perspective(glm::radians(45.0f), (float)width/(float)height, 0.1f, 100.0f);- 参数给出 fov 视野角度,宽高比,远近平面
-
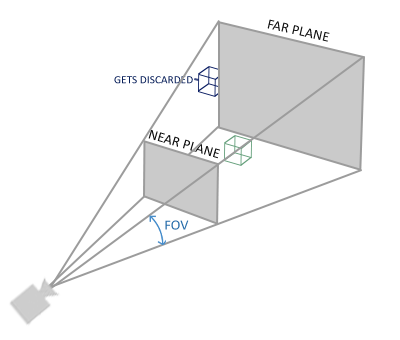
-
完整的变换 \(V_{clip}=M_{projection}\cdot M_{view}\cdot M_{model}\cdot V_{local}\)
- 着色器中
gl_Position = projection * view * model * vec4(aPos, 1.0);
摄像机¶
- 通过构建摄像机三维坐标系矩阵,来对物体进行变换
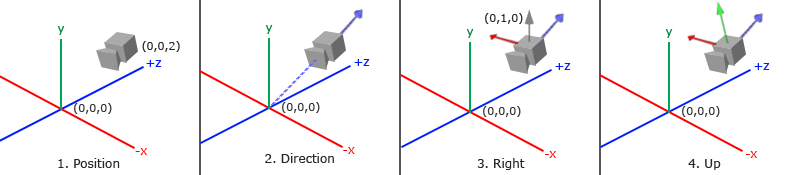
- 首先摄像机的坐标
glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f); - 结合指向计算得到摄像机指向(反方向,图中蓝色)
glm::vec3 cameraTarget = glm::vec3(0.0f, 0.0f, 0.0f);
glm::vec3 cameraDirection = glm::normalize(cameraPos - cameraTarget);
- 右轴:摄像机空间的 x 轴正方向
- 通过定义上向量,与指向叉乘就可以得到右轴
glm::vec3 up = glm::vec3(0.0f, 1.0f, 0.0f);
glm::vec3 cameraRight = glm::normalize(glm::cross(up, cameraDirection));
- 上轴:摄像机空间的 y 轴正方向
-
可以由另外两个轴计算得到
glm::vec3 cameraUp = glm::cross(cameraDirection, cameraRight); -
用这三个向量,和摄像机坐标就能构建变换矩阵 Lookat 矩阵

- 只需要提供摄像机位置、目标位置、上向量就可以用 glm 创建出 lookat 矩阵
glm::mat4 view;
view = glm::lookAt(glm::vec3(0.0f, 0.0f, 3.0f),
glm::vec3(0.0f, 0.0f, 0.0f),
glm::vec3(0.0f, 1.0f, 0.0f));
- 实现一个简单的摄像机环绕
float radius = 10.0f;
float camX = sin(glfwGetTime()) * radius;
float camZ = cos(glfwGetTime()) * radius;
glm::mat4 view;
view = glm::lookAt(glm::vec3(camX, 0.0, camZ), glm::vec3(0.0, 0.0, 0.0), glm::vec3(0.0, 1.0, 0.0));
平移¶
- 要想实现平移效果,可以让目标点与摄像机坐标相关,比如始终值指向前面
glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f);
glm::vec3 cameraFront = glm::vec3(0.0f, 0.0f, -1.0f);
glm::vec3 cameraUp = glm::vec3(0.0f, 1.0f, 0.0f);
view = glm::lookAt(cameraPos, cameraPos + cameraFront, cameraUp);
//用键盘来控制移动
void processInput(GLFWwindow* window)
{
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
float cameraSpeed = 0.05f; // adjust accordingly
if (glfwGetKey(window, GLFW_KEY_W) == GLFW_PRESS)
cameraPos += cameraSpeed * cameraFront;
if (glfwGetKey(window, GLFW_KEY_S) == GLFW_PRESS)
cameraPos -= cameraSpeed * cameraFront;
if (glfwGetKey(window, GLFW_KEY_A) == GLFW_PRESS)
cameraPos -= glm::normalize(glm::cross(cameraFront, cameraUp)) * cameraSpeed;
if (glfwGetKey(window, GLFW_KEY_D) == GLFW_PRESS)
cameraPos += glm::normalize(glm::cross(cameraFront, cameraUp)) * cameraSpeed;
}
- 左右移动方向是根据叉乘再标准化得到的
- 注意这种移动速度和刷新率相关,想要恒定速度要计算时间
旋转¶
- 三种旋转角:俯仰角、偏航角、滚转角
-
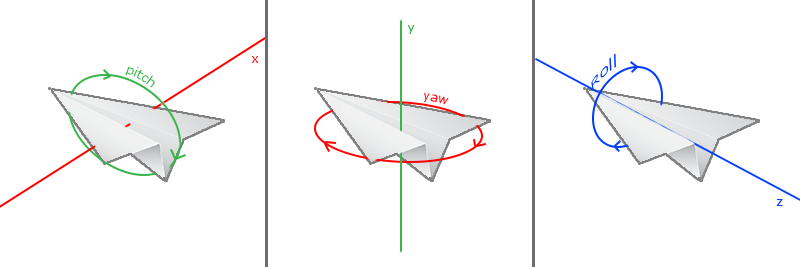
-
通过鼠标输入实现旋转控制:水平的移动影响偏航角,竖直的移动影响俯仰角
-
通过比较两帧之间坐标差距,决定角度的偏移
-
捕捉光标,在窗口内不显示(但是记录位置用于操控)
glfwSetInputMode(window, GLFW_CURSOR, GLFW_CURSOR_DISABLED); -
注册监听
glfwSetCursorPosCallback(window, mouse_callback);
void mouse_callback(GLFWwindow* window, double xpos, double ypos) {
if (firstMouse)
{
lastX = xpos;
lastY = ypos;
firstMouse = false;
}
float xoffset = xpos - lastX;
float yoffset = lastY - ypos;
lastX = xpos;
lastY = ypos;
float sensitivity = 0.05;
xoffset *= sensitivity;
yoffset *= sensitivity;
yaw += xoffset;
pitch += yoffset;
if (pitch > 89.0f)
pitch = 89.0f;
if (pitch < -89.0f)
pitch = -89.0f;
glm::vec3 front;
front.x = cos(glm::radians(yaw)) * cos(glm::radians(pitch));
front.y = sin(glm::radians(pitch));
front.z = sin(glm::radians(yaw)) * cos(glm::radians(pitch));
cameraFront = glm::normalize(front);
}
缩放¶
- 通过监听滚轮调整 fov 来实现¶
示例:摄像机类¶
#ifndef CAMERA_H
#define CAMERA_H
#include <glad/glad.h>
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
// Defines several possible options for camera movement. Used as abstraction to stay away from window-system specific input methods
enum Camera_Movement {
FORWARD,
BACKWARD,
LEFT,
RIGHT
};
// Default camera values
const float YAW = -90.0f;
const float PITCH = 0.0f;
const float SPEED = 2.5f;
const float SENSITIVITY = 0.1f;
const float ZOOM = 45.0f;
// An abstract camera class that processes input and calculates the corresponding Euler Angles, Vectors and Matrices for use in OpenGL
class Camera
{
public:
// camera Attributes
glm::vec3 Position;
glm::vec3 Front;
glm::vec3 Up;
glm::vec3 Right;
glm::vec3 WorldUp;
// euler Angles
float Yaw;
float Pitch;
// camera options
float MovementSpeed;
float MouseSensitivity;
float Zoom;
// constructor with vectors
Camera(glm::vec3 position = glm::vec3(0.0f, 0.0f, 0.0f), glm::vec3 up = glm::vec3(0.0f, 1.0f, 0.0f), float yaw = YAW, float pitch = PITCH) : Front(glm::vec3(0.0f, 0.0f, -1.0f)), MovementSpeed(SPEED), MouseSensitivity(SENSITIVITY), Zoom(ZOOM)
{
Position = position;
WorldUp = up;
Yaw = yaw;
Pitch = pitch;
updateCameraVectors();
}
// constructor with scalar values
Camera(float posX, float posY, float posZ, float upX, float upY, float upZ, float yaw, float pitch) : Front(glm::vec3(0.0f, 0.0f, -1.0f)), MovementSpeed(SPEED), MouseSensitivity(SENSITIVITY), Zoom(ZOOM)
{
Position = glm::vec3(posX, posY, posZ);
WorldUp = glm::vec3(upX, upY, upZ);
Yaw = yaw;
Pitch = pitch;
updateCameraVectors();
}
// returns the view matrix calculated using Euler Angles and the LookAt Matrix
glm::mat4 GetViewMatrix()
{
return glm::lookAt(Position, Position + Front, Up);
}
// processes input received from any keyboard-like input system. Accepts input parameter in the form of camera defined ENUM (to abstract it from windowing systems)
void ProcessKeyboard(Camera_Movement direction, float deltaTime)
{
float velocity = MovementSpeed * deltaTime;
if (direction == FORWARD)
Position += Front * velocity;
if (direction == BACKWARD)
Position -= Front * velocity;
if (direction == LEFT)
Position -= Right * velocity;
if (direction == RIGHT)
Position += Right * velocity;
}
// processes input received from a mouse input system. Expects the offset value in both the x and y direction.
void ProcessMouseMovement(float xoffset, float yoffset, GLboolean constrainPitch = true)
{
xoffset *= MouseSensitivity;
yoffset *= MouseSensitivity;
Yaw += xoffset;
Pitch += yoffset;
// make sure that when pitch is out of bounds, screen doesn't get flipped
if (constrainPitch)
{
if (Pitch > 89.0f)
Pitch = 89.0f;
if (Pitch < -89.0f)
Pitch = -89.0f;
}
// update Front, Right and Up Vectors using the updated Euler angles
updateCameraVectors();
}
// processes input received from a mouse scroll-wheel event. Only requires input on the vertical wheel-axis
void ProcessMouseScroll(float yoffset)
{
Zoom -= (float)yoffset;
if (Zoom < 1.0f)
Zoom = 1.0f;
if (Zoom > 45.0f)
Zoom = 45.0f;
}
private:
// calculates the front vector from the Camera's (updated) Euler Angles
void updateCameraVectors()
{
// calculate the new Front vector
glm::vec3 front;
front.x = cos(glm::radians(Yaw)) * cos(glm::radians(Pitch));
front.y = sin(glm::radians(Pitch));
front.z = sin(glm::radians(Yaw)) * cos(glm::radians(Pitch));
Front = glm::normalize(front);
// also re-calculate the Right and Up vector
Right = glm::normalize(glm::cross(Front, WorldUp)); // normalize the vectors, because their length gets closer to 0 the more you look up or down which results in slower movement.
Up = glm::normalize(glm::cross(Right, Front));
}
};
#endif
1
- 程序代码
#include "shader.h"
#include "camera.h"
#define STB_IMAGE_IMPLEMENTATION
#include "stb_image.h"
#include <glad\glad.h>
#include <GLFW\glfw3.h>
#include <iostream>
#include <glm/glm.hpp>
#include <glm/gtc/matrix_transform.hpp>
#include <glm/gtc/type_ptr.hpp>
glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f);
glm::vec3 cameraFront = glm::vec3(0.0f, 0.0f, -1.0f);
glm::vec3 cameraUp = glm::vec3(0.0f, 1.0f, 0.0f);
float screenWidth = 800;
float screenHeight = 600;
float lastX = screenWidth/2, lastY = screenHeight/2;
float deltaTime = 0.0f;
float lastFrame = 0.0f;
bool firstMouse = true;
Camera camera(glm::vec3(0.0f, 0.0f, 3.0f));
void framebuffer_size_callback(GLFWwindow* window, int width, int height)
{
glViewport(0, 0, width, height);
}
void processInput(GLFWwindow* window)
{
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
if (glfwGetKey(window, GLFW_KEY_W) == GLFW_PRESS)
camera.ProcessKeyboard(FORWARD, deltaTime);
if (glfwGetKey(window, GLFW_KEY_S) == GLFW_PRESS)
camera.ProcessKeyboard(BACKWARD, deltaTime);
if (glfwGetKey(window, GLFW_KEY_A) == GLFW_PRESS)
camera.ProcessKeyboard(LEFT, deltaTime);
if (glfwGetKey(window, GLFW_KEY_D) == GLFW_PRESS)
camera.ProcessKeyboard(RIGHT, deltaTime);
}
void mouse_callback(GLFWwindow* window, double xpos, double ypos) {
if (firstMouse)
{
lastX = xpos;
lastY = ypos;
firstMouse = false;
}
float xoffset = xpos - lastX;
float yoffset = lastY - ypos;
lastX = xpos;
lastY = ypos;
camera.ProcessMouseMovement(xoffset, yoffset);
}
void scroll_callback(GLFWwindow* window, double xoffset, double yoffset)
{
camera.ProcessMouseScroll(static_cast<float>(yoffset));
}
int main()
{
//参数设置
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
//创建上下文
GLFWwindow* window = glfwCreateWindow(screenWidth, screenHeight, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
//板顶函数
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
//设置视口大小
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
glfwSetCursorPosCallback(window, mouse_callback);
glfwSetScrollCallback(window, scroll_callback);
float vertices[] = {
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
0.5f, -0.5f, -0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 1.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
0.5f, -0.5f, -0.5f, 1.0f, 1.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
0.5f, -0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, -0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, -0.5f, -0.5f, 0.0f, 1.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f,
0.5f, 0.5f, -0.5f, 1.0f, 1.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
0.5f, 0.5f, 0.5f, 1.0f, 0.0f,
-0.5f, 0.5f, 0.5f, 0.0f, 0.0f,
-0.5f, 0.5f, -0.5f, 0.0f, 1.0f
};
glm::vec3 cubePositions[] = {
glm::vec3(0.0f, 0.0f, 0.0f),
glm::vec3(2.0f, 5.0f, -15.0f),
glm::vec3(-1.5f, -2.2f, -2.5f),
glm::vec3(-3.8f, -2.0f, -12.3f),
glm::vec3(2.4f, -0.4f, -3.5f),
glm::vec3(-1.7f, 3.0f, -7.5f),
glm::vec3(1.3f, -2.0f, -2.5f),
glm::vec3(1.5f, 2.0f, -2.5f),
glm::vec3(1.5f, 0.2f, -1.5f),
glm::vec3(-1.3f, 1.0f, -1.5f)
};
unsigned int VAO;
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
//存储缓冲区对象id
unsigned int VBO;
//生成缓冲区对象并获取id
glGenBuffers(1, &VBO);
//将缓冲对象绑定到上下文,作为数组缓冲区
glBindBuffer(GL_ARRAY_BUFFER, VBO);
//复制数据到缓冲区
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
Shader shader("vertex_shader.glsl", "fragment_shader.glsl");
shader.use();
// position attribute
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// texture coord attribute
glVertexAttribPointer(1, 2, GL_FLOAT, GL_FALSE, 5 * sizeof(float), (void*)(3 * sizeof(float)));
glEnableVertexAttribArray(1);
int width, height, nrChannels;
stbi_set_flip_vertically_on_load(true);
unsigned char* data1 = stbi_load("container.jpg", &width, &height, &nrChannels, 0);
unsigned int texture1;
glGenTextures(1, &texture1);
glBindTexture(GL_TEXTURE_2D, texture1);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data1);
glGenerateMipmap(GL_TEXTURE_2D);
stbi_image_free(data1);
unsigned char* data2 = stbi_load("awesomeface.png", &width, &height, &nrChannels, 0);
unsigned int texture2;
glGenTextures(2, &texture2);
glBindTexture(GL_TEXTURE_2D, texture2);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, data2);
glGenerateMipmap(GL_TEXTURE_2D);
stbi_image_free(data2);
glUniform1i(glGetUniformLocation(shader.ID, "texture1"), 0); // 手动设置
shader.setInt("texture2", 1); // 或者使用着色器类设置
glEnable(GL_DEPTH_TEST);
glfwSetInputMode(window, GLFW_CURSOR, GLFW_CURSOR_DISABLED);
while (!glfwWindowShouldClose(window))
{
float currentFrame = static_cast<float>(glfwGetTime());
deltaTime = currentFrame - lastFrame;
lastFrame = currentFrame;
// 输入
processInput(window);
// 渲染
// 清除颜色缓冲
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
// 记得激活着色器
shader.use();
// 更新uniform颜色
float timeValue = glfwGetTime();
float greenValue = sin(timeValue) / 2.0f + 0.5f;
shader.setVec4("ourColor", 0.0f, greenValue, 0.0f, 1.0f);
// 绘制三角形
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture1);
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, texture2);
glBindVertexArray(VAO);
glm::mat4 projection;
projection = glm::perspective(glm::radians(camera.Zoom), screenWidth / screenHeight, 0.1f, 100.0f);
unsigned transformLoc = glGetUniformLocation(shader.ID, "projection");
glUniformMatrix4fv(transformLoc, 1, GL_FALSE, glm::value_ptr(projection));
glm::mat4 view;
view = camera.GetViewMatrix();
transformLoc = glGetUniformLocation(shader.ID, "view");
glUniformMatrix4fv(transformLoc, 1, GL_FALSE, glm::value_ptr(view));
for (unsigned int i = 0; i < 10; i++)
{
glm::mat4 model;
model = glm::translate(model, cubePositions[i]);
float angle = 20.0f * i;
model = glm::rotate(model, glm::radians(angle), glm::vec3(1.0f, 0.3f, 0.5f));
transformLoc = glGetUniformLocation(shader.ID, "model");
glUniformMatrix4fv(transformLoc, 1, GL_FALSE, glm::value_ptr(model));
glDrawArrays(GL_TRIANGLES, 0, 36);
}
// 交换缓冲并查询IO事件
glfwSwapBuffers(window);
glfwPollEvents();
}
glDeleteVertexArrays(1, &VAO);
glDeleteBuffers(1, &VBO);
//释放资源
glfwTerminate();
return 0;
}
裁剪¶
- 设置远近平面
void glDepthRange(GLclampd near,GLclampd far); - 用户裁剪:再添加一些任意方向的平面,利用这些平面进行进一步裁剪
- 根据片段到每个裁剪平面的距离来决定是否丢弃该片段。通常,如果该距离小于零,片段会被丢弃
#version 450 core out vec4 fragColor; // 片段颜色 out float gl_ClipDistance[1]; // 裁剪距离 uniform vec4 clipPlane; // 自定义裁剪平面 void main() { // 计算片段到裁剪平面的距离 float distance = dot(gl_FragCoord.xyz, clipPlane.xyz) + clipPlane.w; // 将计算的裁剪距离传递给 gl_ClipDistance gl_ClipDistance[0] = distance; // 输出颜色 fragColor = vec4(1.0, 0.0, 0.0, 1.0); // 红色 }
- 根据片段到每个裁剪平面的距离来决定是否丢弃该片段。通常,如果该距离小于零,片段会被丢弃
- 如果
distance < 0,片段就会被丢弃。gl_ClipDistance:用于片段级裁剪。它控制的是每个片段(像素)是否被裁剪。gl_CullDistance:用于图元级裁剪。它控制的是整个图元(如三角形、线段等)是否被裁剪。
- 多个裁剪平面
#version 450 core out vec4 fragColor; // 输出颜色 out float gl_ClipDistance[3]; // 三个裁剪平面 uniform vec4 clipPlanes[3]; // 裁剪平面,三个平面 void main() { // 计算片段到每个裁剪平面的距离 for (int i = 0; i < 3; ++i) { gl_ClipDistance[i] = dot(gl_FragCoord.xyz, clipPlanes[i].xyz) + clipPlanes[i].w; } // 输出颜色(此处仅为示例,实际颜色处理可能更复杂) fragColor = vec4(1.0, 0.0, 0.0, 1.0); // 红色 }
transform feedback¶
- 用于在图形渲染管线中捕获变换后的顶点数据,并将这些数据输出到缓冲区中,而不是渲染到帧缓冲中。
- 这样可以避免将数据从 GPU 传输到 CPU,再传输回 GPU,从而提高性能。
着色器¶
- 一些运行在 GPU 上的小程序,着色器的功能比较简单,只是接受输入并产生输出
编译着色器¶
- 创建着色器对象
Gluint glCreateShader(GLenum type)- type 可以有
GL_VERTEX_SHADER GL_FRAGMENT_SHADER等
- type 可以有
- 关联着色器代码
void glShaderSource(Gluint shader,GLsizer count,const GLchar** string,const GLint* length) -
编译着色器
void glCompileShader(GLuint shader)- 查询结果
glGetShaderiv(),GL_TRUE 即编译成功 - 查询日志
glGetShaderInfoLog(GLuint shader,GLsizei bufSize,GLsizei*length,char*infoLog)
- 查询结果
-
创建着色器程序
Gluint glCreateProgram(void) - 将着色器附加到着色器程序
void glAttachShader(GLuint program, GLuint shader)- 移除着色器
void glDetchShader(GLuint program,GLuint shader)
- 移除着色器
- 链接生成可执行程序
void GlLinkProgram(GLuint program)- 结果查询
glGetProgramiv() - 日志
glGetProgramInfoLog()
- 结果查询
- 绑定着色器程序
void glUseProgram(GLuint program) - 得到可执行程序 program 后可以释放着色器对象了
glDeleteShader ()- 标记为可删除,当对应的着色器程序不再使用时会自动进行删除
- 删除着色器程序
void glDeleteProgram(Gluint program)
独立着色器对象¶
- 传统方式一个程序绑定一整套多个着色器,如果要更换其中一个着色器就必须更换整个程序
- 独立着色器对象允许开发者将不同的着色器阶段分开管理组合,不需要创建一个完整的着色器程序。即想替换一个着色器只需要重新连接对应的程序
- 每个着色器阶段可以单独编译并存储为一个对象。不同阶段的着色器对象可以在运行时动态组合,而无需重新链接整个程序。
// 顶点和片段着色器代码 const char* vertexShaderSource = "顶点着色器代码..."; const char* fragmentShaderSource = "片段着色器代码..."; // 创建独立着色器对象 GLuint vertexShaderProgram = glCreateShaderProgramv(GL_VERTEX_SHADER, 1, &vertexShaderSource); GLuint fragmentShaderProgram = glCreateShaderProgramv(GL_FRAGMENT_SHADER, 1, &fragmentShaderSource); // 检查编译是否成功 GLint success; glGetProgramiv(vertexShaderProgram, GL_LINK_STATUS, &success); if (!success) { char infoLog[512]; glGetProgramInfoLog(vertexShaderProgram, 512, NULL, infoLog); std::cerr << "ERROR::SHADER::VERTEX::COMPILATION_FAILED\n" << infoLog << std::endl; } // 创建管线对象并绑定 GLuint pipeline; glGenProgramPipelines(1, &pipeline); glBindProgramPipeline(pipeline); // 绑定着色器对象到管线阶段 glUseProgramStages(pipeline, GL_VERTEX_SHADER_BIT, vertexShaderProgram); glUseProgramStages(pipeline, GL_FRAGMENT_SHADER_BIT, fragmentShaderProgram); // 绘制 glBindProgramPipeline(pipeline); glBindVertexArray(VAO); glDrawArrays(GL_TRIANGLES, 0, 3);
GLSL¶
- 着色器程序通常的结构
#version version_number in type in_variable_name; in type in_variable_name; out type out_variable_name; uniform type uniform_name; void main() { // 处理输入并进行一些图形操作 ... // 输出处理过的结果到输出变量 out_variable_name = weird_stuff_we_processed; } - 能声明的顶点属性是有上限的,它一般由硬件来决定,OpenGL确保至少有16个包含4分量的顶点属性可用
-
查询
glGetIntegerv(GL_MAX_VERTEX_ATTRIBS, &nrAttributes); -
glsl 代码与 c 接近,开始于版本声明,与 opengl 类似,如 3.3 版本对应 330
#version 330 core -
invariant添加在 out 变量前面,保证使用相同输入进行相同计算总是得到相同的结果,用于保证多个着色器阶段输出一致#pragma STDGL invariant(all)全局开启- 会关闭一些优化,解决插值、浮点数计算的微小误差
precise保证变量的计算遵循最高的精度标准,避免因为优化引入的不精确计算- 在指定的变量前添加
precise
- 在指定的变量前添加
| 修饰符 | 作用范围 | 主要功能 | 优势 | 注意事项 |
|---|---|---|---|---|
invariant |
输出变量 | 保证跨着色器阶段的一致性 | 避免几何边界上插值出现不连续 | 性能可能降低,慎用 |
precise |
局部变量、计算过程 | 提升计算过程的精度,避免优化引入误差 | 确保高精度计算(如物理模拟) | 可能影响性能,影响有限场景 |
- 控制着色器编译优化 pragma optimize(on/off) |
||||
- 额外诊断信息 pragma debug(on/off) |
数据类¶
- 除了基本数据类型int、float、double、bool等,有两种容器类型:vector和matrix
-
-
向量可以包含2~4个分量
| 类型 | 含义 |
|---|---|
vecn |
包含n个float分量的默认向量 |
bvecn |
包含n个bool分量的向量 |
ivecn |
包含n个int分量的向量 |
uvecn |
包含n个unsigned int分量的向量 |
dvecn |
包含n个double分量的向量 |
- 大部分时候使用vecn即可
- 通过
.x、.y、.z和.w来获取分量 - GLSL也允许对颜色使用
rgba,或是对纹理坐标使用stpq访问相同的分量。
//灵活的组合运算
vec2 someVec;
vec4 differentVec = someVec.xyxx;
vec3 anotherVec = differentVec.zyw;
vec4 otherVec = someVec.xxxx + anotherVec.yxzy;
//创建变量
vec2 vect = vec2(0.5, 0.7);
vec4 result = vec4(vect, 0.0, 0.0);
vec4 otherResult = vec4(result.xyz, 1.0);
输入输出¶
- 使用
in和out关键字来定义输入输出 - 每个着色器使用这两个关键字设定输入和输出,只要一个输出变量与下一个着色器阶段的输入匹配,它就会传递下去。
- 特殊输入:其中顶点着色器是从缓冲区获取顶点元数据,通过设置
location来获取CPU配置的属性,如layout (location = 0) - 特殊输出:片段着色器的输出为
vec4(RGBA) - 点着色器示例
#version 330 core
layout (location = 0) in vec3 aPos; // 位置变量的属性位置值为0
out vec4 vertexColor; // 为片段着色器指定一个颜色输出
void main()
{
gl_Position = vec4(aPos, 1.0); // 注意我们如何把一个vec3作为vec4的构造器的参数
vertexColor = vec4(0.5, 0.0, 0.0, 1.0); // 把输出变量设置为暗红色
}
- 片段着色器示例
#version 330 core
out vec4 FragColor;
in vec4 vertexColor; // 从顶点着色器传来的输入变量(名称相同、类型相同)
void main()
{
FragColor = vertexColor;
}
函数的参数传递¶
- glsl 没有指针类型,通过参数的访问修饰符来进行设定
- 同与外部的通讯 in、out 是类似的
in:仅作输入,用于从调用者向函数传递数据。out:仅作输出,用于从函数向调用者传递数据。inout:作为输入和输出,用于修改调用者提供的数据。(类似引用传递)void example(inout float value) { value *= 2.0; // 修改 value } void main() { float value = 21.0; example(value); // value 被修改为 42.0 }
uniform¶
- 实现从CPU传递数据到GPU上的着色器(如从应用程序直接发送一个颜色给片段着色器)
- uniform是全局作用域的,因此在所有着色器程序中都不能重名
-
uniform vec4 ourColor; -
要注意的是激活新的着色器程序后,必须要重新传递所有的uniform变量
//在片段着色器中使用uniform变量
#version 330 core
out vec4 FragColor;
uniform vec4 ourColor; // 在OpenGL程序代码中设定这个变量
void main()
{
FragColor = ourColor;
}
//在程序循环中设置颜色
float timeValue = glfwGetTime();
float greenValue = (sin(timeValue) / 2.0f) + 0.5f;
int vertexColorLocation = glGetUniformLocation(shaderProgram, "ourColor");//获取uniform变量的位置值
glUseProgram(shaderProgram);
//参数位置+参数(4个)
glUniform4f(vertexColorLocation, 0.0f, greenValue, 0.0f, 1.0f);
glsl中通常的表示类型的后缀
| 后缀 | 含义 |
|---|---|
f |
函数需要一个float作为它的值 |
i |
函数需要一个int作为它的值 |
ui |
函数需要一个unsigned int作为它的值 |
3f |
函数需要3个float作为它的值 |
fv |
函数需要一个float向量/数组作为它的值 |
| ##### 接口块 |
- 通过接口快可以组合要从顶点着色器发送到片段着色器的数据
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec2 aTexCoords;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
out VS_OUT
{
vec2 TexCoords;
} vs_out;
void main()
{
gl_Position = projection * view * model * vec4(aPos, 1.0);
vs_out.TexCoords = aTexCoords;
}
//片段着色器中
in VS_OUT
{
vec2 TexCoords;
} fs_in;
- 这就生命力一个
vs_out接口块,打包了要发送的所有输出变量 - 输入和输出的块名(VS_OUT)要一样,但是实例名可以不一样
数据块接口¶
- 使用 Uniform 缓冲对象可以定义协议系列在多个着色器程序中相同的全局 Uniform 变量,这样就只需要设置相关的 uniform 一次,只需要手动设置每个着色器中不同的 uniform
-
通过 glGenBuffers 创建缓冲,并绑定到 GL_UNIFORM_BUFFER 缓冲目标,并将所有相关的 uniform 数据存入缓冲。
-
uniform 块
- Uniform 块中的变量可以直接访问,不需要加块名作为前缀。
- layout (std 140) 表示当前定义的 Uniform 块对它的内容使用一个特定的内存布局
layout (std140) uniform ExampleBlock
{
float value;
vec3 vector;
mat4 matrix;
float values[3];
bool boolean;
int integer;
};
-
uniform 块的内容是存储在缓冲对象上的,我们还需要告诉 opengl 缓冲对象内存的那一部分对应哪一个 uniform 块成员变量
-
我们需要知道的是每个变量的大小(字节)和(从块起始位置的)偏移量,来让我们能够按顺序将它们放进缓冲中。
-
通常使用std 布局:std 140 布局声明了每个变量的偏移量都是由一系列规则所决定的。同时允许手动计算变量的偏移量
-
在默认的共享布局(Shared Layout)中,变量的实际偏移量需要通过
glGetUniformLocation等API 动态查询,不仅复杂,而且增加了运行时开销。std140布局通过明确的规则直接决定偏移量,使得我们可以手动计算偏移,省去了查询的麻烦。 -
基准对齐量:变量在 Uniform 块中所需的最小对齐空间,包括潜在的填充字节
-
对齐偏移量:变量在块中的实际偏移量,必须是其基准对齐量的整数倍。
-
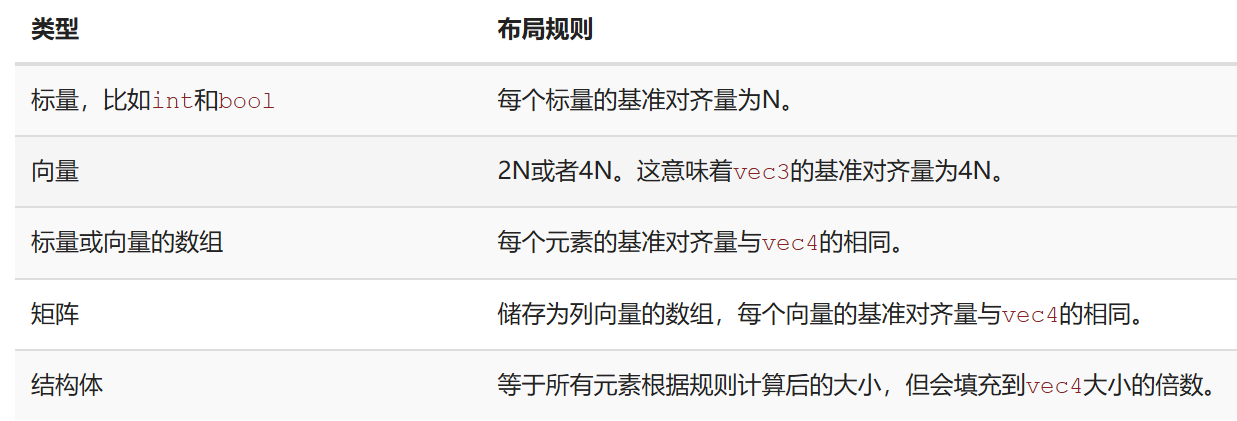
- 通常 N=4 B
layout (std140) uniform ExampleBlock
{
// 基准对齐量 // 对齐偏移量
float value; // 4 // 0
vec3 vector; // 16 // 16 (必须是16的倍数,所以 4->16)
mat4 matrix; // 16 // 32 (列 0)
// 16 // 48 (列 1)
// 16 // 64 (列 2)
// 16 // 80 (列 3)
float values[3]; // 16 // 96 (values[0])
// 16 // 112 (values[1])
// 16 // 128 (values[2])
bool boolean; // 4 // 144
int integer; // 4 // 148
};
- uniform缓冲对象 ubo:GPU 显存中的缓冲区,用于存储 uniform 块的数据
- Uniform 块是 GLSL 中的一个结构,用于统一管理多个
uniform变量 - 绑定点起到了桥梁作用,沟通 ubo 和 uniform 块
- 通过将多个 Uniform 块绑定到相同的缓冲上,就可以实现数据的共享(如果定义了相同的 Uniform 块)
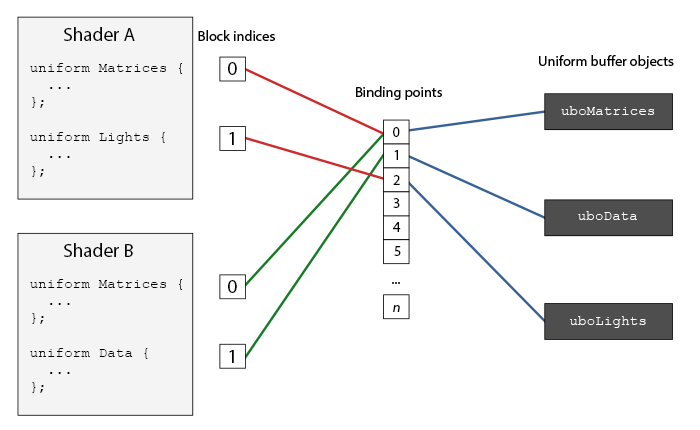
//创建缓冲UBO
unsigned int uboExampleBlock;
glGenBuffers(1, &uboExampleBlock);
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
glBufferData(GL_UNIFORM_BUFFER, 152, NULL, GL_STATIC_DRAW); // 分配152字节的内存
glBindBuffer(GL_UNIFORM_BUFFER, 0);
//Uniform块绑定到一个特定的绑定点中
//获取uniform块的索引
unsigned int lights_index = glGetUniformBlockIndex(shaderA.ID, "Lights");
//将uniform块绑定到2绑定点
glUniformBlockBinding(shaderA.ID, lights_index, 2);
//将ubo绑定到绑定点
glBindBufferBase(GL_UNIFORM_BUFFER, 2, uboExampleBlock);
-
也可以这样讲 uniform 块绑定到绑定点
layout(std140, binding = 2) uniform Lights { ... }; -
修改 uniform 缓冲中的内容
glBindBuffer(GL_UNIFORM_BUFFER, uboExampleBlock);
int b = true; // GLSL中的bool是4字节
glBufferSubData(GL_UNIFORM_BUFFER, 144, 4, &b);
glBindBuffer(GL_UNIFORM_BUFFER, 0);
buffer 块¶
- 着色器的存储缓存对象,比 uniform 块更强大,着色器可以写入块,修改内容并呈现给其他着色器调用、应用程序本身。
- 可以在渲染之前决定大小而不是在编译和链接的时候
buffer BufferObject { int mode; vec points[];//最后一个元素可以是未定大小的数组 }
- 可以在渲染之前决定大小而不是在编译和链接的时候
- 上面的数组就可以在渲染之前再设置大小,着色器中可以使用
length()来获取数组的大小
附:着色器管理类¶
- 从硬盘读取着色器,编译、链接、检查
#ifndef SHADER_H
#define SHADER_H
#include <glad/glad.h>
#include <string>
#include <fstream>
#include <sstream>
#include <iostream>
class Shader
{
public:
unsigned int ID;
// constructor generates the shader on the fly
// ------------------------------------------------------------------------
Shader(const char* vertexPath, const char* fragmentPath)
{
// 1. retrieve the vertex/fragment source code from filePath
std::string vertexCode;
std::string fragmentCode;
std::ifstream vShaderFile;
std::ifstream fShaderFile;
// ensure ifstream objects can throw exceptions:
vShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);
fShaderFile.exceptions (std::ifstream::failbit | std::ifstream::badbit);
try
{
// open files
vShaderFile.open(vertexPath);
fShaderFile.open(fragmentPath);
std::stringstream vShaderStream, fShaderStream;
// read file's buffer contents into streams
vShaderStream << vShaderFile.rdbuf();
fShaderStream << fShaderFile.rdbuf();
// close file handlers
vShaderFile.close();
fShaderFile.close();
// convert stream into string
vertexCode = vShaderStream.str();
fragmentCode = fShaderStream.str();
}
catch (std::ifstream::failure& e)
{
std::cout << "ERROR::SHADER::FILE_NOT_SUCCESSFULLY_READ: " << e.what() << std::endl;
}
const char* vShaderCode = vertexCode.c_str();
const char * fShaderCode = fragmentCode.c_str();
// 2. compile shaders
unsigned int vertex, fragment;
// vertex shader
vertex = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertex, 1, &vShaderCode, NULL);
glCompileShader(vertex);
checkCompileErrors(vertex, "VERTEX");
// fragment Shader
fragment = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragment, 1, &fShaderCode, NULL);
glCompileShader(fragment);
checkCompileErrors(fragment, "FRAGMENT");
// shader Program
ID = glCreateProgram();
glAttachShader(ID, vertex);
glAttachShader(ID, fragment);
glLinkProgram(ID);
checkCompileErrors(ID, "PROGRAM");
// delete the shaders as they're linked into our program now and no longer necessary
glDeleteShader(vertex);
glDeleteShader(fragment);
}
// activate the shader
// ------------------------------------------------------------------------
void use()
{
glUseProgram(ID);
}
// utility uniform functions
// ------------------------------------------------------------------------
void setBool(const std::string &name, bool value) const
{
glUniform1i(glGetUniformLocation(ID, name.c_str()), (int)value);
}
// ------------------------------------------------------------------------
void setInt(const std::string &name, int value) const
{
glUniform1i(glGetUniformLocation(ID, name.c_str()), value);
}
// ------------------------------------------------------------------------
void setFloat(const std::string &name, float value) const
{
glUniform1f(glGetUniformLocation(ID, name.c_str()), value);
}
private:
// utility function for checking shader compilation/linking errors.
// ------------------------------------------------------------------------
void checkCompileErrors(unsigned int shader, std::string type)
{
int success;
char infoLog[1024];
if (type != "PROGRAM")
{
glGetShaderiv(shader, GL_COMPILE_STATUS, &success);
if (!success)
{
glGetShaderInfoLog(shader, 1024, NULL, infoLog);
std::cout << "ERROR::SHADER_COMPILATION_ERROR of type: " << type << "\n" << infoLog << "\n -- --------------------------------------------------- -- " << std::endl;
}
}
else
{
glGetProgramiv(shader, GL_LINK_STATUS, &success);
if (!success)
{
glGetProgramInfoLog(shader, 1024, NULL, infoLog);
std::cout << "ERROR::PROGRAM_LINKING_ERROR of type: " << type << "\n" << infoLog << "\n -- --------------------------------------------------- -- " << std::endl;
}
}
}
};
#endif
//创建对象
Shader myShader("path/to/vertex_shader.glsl", "path/to/fragment_shader.glsl");
//激活程序
myShader.use();
//设置Uniform变量
myShader.setFloat("ourColor", 0.0f, 1.0f, 0.0f, 1.0f);
//渲染循环中使用
while (!glfwWindowShouldClose(window))
{
// 清除屏幕
glClear(GL_COLOR_BUFFER_BIT);
// 激活着色器
myShader.use();
// 动态设置 Uniform 颜色
float timeValue = glfwGetTime();
float greenValue = (sin(timeValue) / 2.0f) + 0.5f;
myShader.setFloat("ourColor", 0.0f, greenValue, 0.0f, 1.0f); // 颜色随时间变化
// 绘制操作
glBindVertexArray(VAO);
glDrawArrays(GL_TRIANGLES, 0, 3);
// 交换缓冲
glfwSwapBuffers(window);
glfwPollEvents();
}
纹理¶
- 为了在图像上显示问题,需要给出图像上坐标和纹理文件的对应关系
- 对于三角形,每个顶点附带一个纹理坐标,用于表示从纹理图像的哪个部分进行采样,其他部分插值处理进行填充
- 纹理(uv)坐标为二维,范围0~1
重复纹理¶
- 坐标超出纹理范围(0~1)时,有如下处理方式

- 重复、镜像、拉伸、特定颜色
- 可以对每个坐标轴分别进行设置
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_MIRRORED_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_MIRRORED_REPEAT);
纹理过滤¶
- 决定如何将纹理像素映射到纹理坐标(尤其是纹理分辨率较低的情况)
GL_NEAREST临近过滤(默认),OpenGL会选择中心点最接近纹理坐标的那个像素作为样本颜色,效果上更加清晰(颗粒感)
- GL_LINEAR线性过滤会:于纹理坐标附近的纹理像素,计算出一个插值,近似出这些纹理像素之间的颜色。产生更加平滑的图像

-

-
对放大、缩小纹理的情况分别设置
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
多级渐远纹理¶
- 准备一系列分别率不同(1/2每级)的贴图素材,用于不同显示大小的物体

- 注意:只能用于纹理被缩小的情况
- 通过
glGenerateMipmap进行创建 - 在不同大小纹理图之间还可以制定不同的过滤方式
| 过滤方式 | 描述 |
|---|---|
| GL_NEAREST_MIPMAP_NEAREST | 使用最邻近的多级渐远纹理来匹配像素大小,并使用邻近插值进行纹理采样 |
| GL_LINEAR_MIPMAP_NEAREST | 使用最邻近的多级渐远纹理级别,并使用线性插值进行采样 |
| GL_NEAREST_MIPMAP_LINEAR | 在两个最匹配像素大小的多级渐远纹理之间进行线性插值,使用邻近插值进行采样 |
| GL_LINEAR_MIPMAP_LINEAR | 在两个邻近的多级渐远纹理之间使用线性插值,并使用线性插值进行采样 |
加载与使用¶
- 可以使用
stb_image.h下载来进行文件图像加载
#define STB_IMAGE_IMPLEMENTATION
#include "stb_image.h"
- 加载图片为字节码
int width, height, nrChannels;//宽度、高度、颜色通道个数
unsigned char *data = stbi_load("container.jpg", &width, &height, &nrChannels, 0);
-
纹理的类型
-
生成纹理
//创建纹理对象 unsigned int texture; glGenTextures(1, &texture); //绑定为当前使用的纹理 glBindTexture(GL_TEXTURE_2D, texture); //设置环绕、过滤模式 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); //绑定读取的数据 glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data); glGenerateMipmap(GL_TEXTURE_2D); //释放内存 stbi_image_free(data); -
第一个参数指定了纹理目标(Target)。设置为GL_TEXTURE_2D意味着会生成与当前绑定的纹理对象在同一个目标上的纹理(任何绑定到GL_TEXTURE_1D和GL_TEXTURE_3D的纹理不会受到影响)。
- 第二个参数为纹理指定多级渐远纹理的级别,如果你希望单独手动设置每个多级渐远纹理的级别的话。这里我们填0,也就是基本级别。
- 第三个参数告诉OpenGL我们希望把纹理储存为何种格式。我们的图像只有
RGB值,因此我们也把纹理储存为RGB值。 - 第四个和第五个参数设置最终的纹理的宽度和高度。我们之前加载图像的时候储存了它们,所以我们使用对应的变量。
- 下个参数应该总是被设为
0(历史遗留的问题)。 - 第七第八个参数定义了源图的格式和数据类型。我们使用RGB值加载这个图像,并把它们储存为
char(byte)数组,我们将会传入对应值。 -
最后一个参数是真正的图像数据。
-
也可以不适用 stb
-
为贴图分配空间
-
应用纹理,顶点还要给出纹理坐标
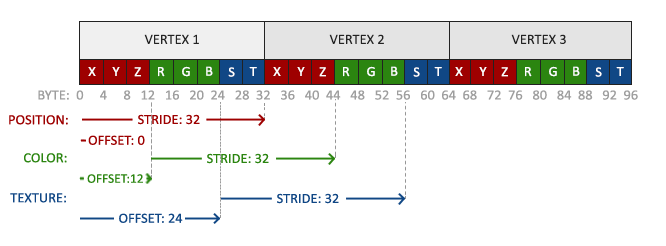

float vertices[] = {
// ---- 位置 ---- ---- 颜色 ---- - 纹理坐标 -
0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f, 1.0f, 1.0f, // 右上
0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, 1.0f, 0.0f, // 右下
-0.5f, -0.5f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, // 左下
-0.5f, 0.5f, 0.0f, 1.0f, 1.0f, 0.0f, 0.0f, 1.0f // 左上
};
//配置VAO属性
// 位置属性
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 颜色属性
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)(3 * sizeof(float)));
glEnableVertexAttribArray(1);
//uv属性
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)(6 * sizeof(float)));
glEnableVertexAttribArray(2);
-
着色器中获取纹理
uniform sampler2D ourTexture; void main() { FragColor = texture(ourTexture, TexCoord) } -
这个uniform不需要手动传入
- 通过纹理单元还可以实现将多个纹理用于同一个片段着色器
- 首先激活纹理单元,然后为纹理单元绑定数据
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture1);
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, texture2);
-
opengl至少保证有16个纹理单元可以使用
-
在着色器中使用两个纹理单元
#version 330 core
...
uniform sampler2D texture1;
uniform sampler2D texture2;
void main()
{
FragColor = mix(texture(texture1, TexCoord), texture(texture2, TexCoord), 0.2);
}
- 默认情况下uniform会自动绑定纹理单元0,也可以手动指定
glUniform1i(glGetUniformLocation(shader.ID, "texture1"), 0); // 手动设置
shader.setInt("texture2", 1); // 或者使用着色器类设置

代理纹理¶
- 每一个标准的纹理目标都可以有一个对应的代理纹理目标,代理纹理的核心思想是通过在低性能计算或渲染场景中替代真实的高分辨率纹理,来减少内存占用和提升渲染速度。只有在必要时(例如相机接近某个物体时),系统才会动态地加载并显示高分辨率的纹理。
纹理数据加载方式¶
- 显示设置
- 直接传入字节流数组作为纹理的数据

glTextureSubImage2D(tex checkerboard, //纹理 0, //mipmap层0 0,0, //x和y偏移 8,8, //宽度和高度 GL RED,GL UNSIGNED BYTE, //格式和类型 tex checkerboard data); /1数据
- 从缓存加载纹理
- 将数据存储到缓存对象当中,之后再传递到纹理对象
// 1. 创建缓存对象 GLuint buf; glCreateBuffers(1, &buf); // 2. 将源数据传递到缓存对象 glNamedBufferStorage(buf, sizeof(tex_checkerboard_data), tex_checkerboard_data, 0); // 3. 创建并分配纹理存储空间 GLuint texture; glCreateTextures(GL_TEXTURE_2D, 1, &texture); glTextureStorage2D(texture, 4, GL_R8, 8, 8); // 为纹理分配内存空间 // 4. 将缓存对象绑定到 `GL_PIXEL_UNPACK_BUFFER` glBindBuffer(GL_PIXEL_UNPACK_BUFFER, buf); // 5. 将纹理数据从缓存对象上传到纹理 glTextureSubImage2D(texture, 0, 0, 0, 8, 8, GL_RED, GL_UNSIGNED_BYTE, NULL); // 清理缓存对象 glDeleteBuffers(1, &buf);
- 将数据存储到缓存对象当中,之后再传递到纹理对象
- 从文件加载
获取纹理数据¶
- 向纹理中传递数据之后可以再次读取数据冰传递回用户程序的本地内存中
void glGetTexturelmage(GLuint texture,GLint level,GLenum format,GLenum type, GLsizei bufSize, void *pixels);
排列纹理数据¶
- 将不同格式排布的纹理数据(如 ABGR)转为为标准的 opengl 使用的 RBGA,并传递给着色器
- 对要重新排列的纹理的每个通道使用
glTextureParameteri()来设置对应的参数值GL TEXTURE_SWIZZLE_R等来指出通道的位置(即如果按正常顺序,纹理中的第几个通道)以及GL_RED等来指出目标的通道 
纹理数据的排列布局¶
压缩纹理¶
- 在线压缩:由 opengl 负责压缩数据,在渲染时实时进行,为了速度,通常质量不高
- 提供 RGTC(单、双通道)、BPTC 两种算法(多通道、RGB)
-
离线压缩:在程序运行之前进行压缩,再吧结果传递给 opengl
-
为纹理分配空间时指定压缩格式
glTexStorage2D(GL_TEXTURE_2D, 1, GL_COMPRESSED_RGBA_S3TC_DXT5_EXT, 512, 512); - 对纹理进行压缩并绑定
glCompressedTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, 512, 512, GL_COMPRESSED_RGBA_S3TC_DXT5_EXT, compressedDataSize, compressedData);
采样器对象¶
- 控制如何从纹理图像中进行读取
GLuint sampler; glGenSamplers(1, &sampler); //绑定采样器到当前活跃的纹理 glActiveTexture(GL_TEXTURE0); // 选择纹理单元 0 glBindTexture(GL_TEXTURE_2D, texture); // 绑定纹理 glBindSampler(0, sampler); // 将采样器对象与纹理单元 0 绑定 - 配置采样器的参数
glSamplerParameteri(sampler, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);- 设置纹理采样的相关参数,例如纹理过滤方式、纹理边缘行为等。
完整代码¶
#include "utils.h"
#define STB_IMAGE_IMPLEMENTATION
#include "stb_image.h"
#include <glad\glad.h>
#include <GLFW\glfw3.h>
#include <iostream>
void framebuffer_size_callback(GLFWwindow* window, int width, int height)
{
glViewport(0, 0, width, height);
}
void processInput(GLFWwindow* window)
{
if (glfwGetKey(window, GLFW_KEY_ESCAPE) == GLFW_PRESS)
glfwSetWindowShouldClose(window, true);
}
int main()
{
//参数设置
glfwInit();
glfwWindowHint(GLFW_CONTEXT_VERSION_MAJOR, 3);
glfwWindowHint(GLFW_CONTEXT_VERSION_MINOR, 3);
glfwWindowHint(GLFW_OPENGL_PROFILE, GLFW_OPENGL_CORE_PROFILE);
//创建上下文
GLFWwindow* window = glfwCreateWindow(800, 600, "LearnOpenGL", NULL, NULL);
if (window == NULL)
{
std::cout << "Failed to create GLFW window" << std::endl;
glfwTerminate();
return -1;
}
glfwMakeContextCurrent(window);
//板顶函数
if (!gladLoadGLLoader((GLADloadproc)glfwGetProcAddress))
{
std::cout << "Failed to initialize GLAD" << std::endl;
return -1;
}
//设置视口大小
glfwSetFramebufferSizeCallback(window, framebuffer_size_callback);
float vertices[] = {
// ---- 位置 ---- ---- 颜色 ---- - 纹理坐标 -
0.5f, 0.5f, 0.0f, 1.0f, 0.0f, 0.0f, 1.0f, 1.0f, // 右上
0.5f, -0.5f, 0.0f, 0.0f, 1.0f, 0.0f, 1.0f, 0.0f, // 右下
-0.5f, -0.5f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, 0.0f, // 左下
-0.5f, 0.5f, 0.0f, 1.0f, 1.0f, 0.0f, 0.0f, 1.0f // 左上
};
unsigned int indices[] = {
// 注意索引从0开始!
// 此例的索引(0,1,2,3)就是顶点数组vertices的下标,
// 这样可以由下标代表顶点组合成矩形
0, 1, 3, // 第一个三角形
1, 2, 3 // 第二个三角形
};
unsigned int VAO;
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
//存储缓冲区对象id
unsigned int VBO;
//生成缓冲区对象并获取id
glGenBuffers(1, &VBO);
//将缓冲对象绑定到上下文,作为数组缓冲区
glBindBuffer(GL_ARRAY_BUFFER, VBO);
//复制数据到缓冲区
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
unsigned int EBO;
glGenBuffers(1, &EBO);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
Shader shader("vertex_shader.glsl", "fragment_shader.glsl");
shader.use();
// 位置属性
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 颜色属性
glVertexAttribPointer(1, 3, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)(3 * sizeof(float)));
glEnableVertexAttribArray(1);
//uv属性
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 8 * sizeof(float), (void*)(6 * sizeof(float)));
glEnableVertexAttribArray(2);
int width, height, nrChannels;
stbi_set_flip_vertically_on_load(true);
unsigned char* data1 = stbi_load("container.jpg", &width, &height, &nrChannels, 0);
unsigned int texture1;
glGenTextures(1, &texture1);
glBindTexture(GL_TEXTURE_2D, texture1);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data1);
glGenerateMipmap(GL_TEXTURE_2D);
stbi_image_free(data1);
unsigned char* data2 = stbi_load("awesomeface.png", &width, &height, &nrChannels, 0);
unsigned int texture2;
glGenTextures(2, &texture2);
glBindTexture(GL_TEXTURE_2D, texture2);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, data2);
glGenerateMipmap(GL_TEXTURE_2D);
stbi_image_free(data2);
glUniform1i(glGetUniformLocation(shader.ID, "texture1"), 0); // 手动设置
shader.setInt("texture2", 1); // 或者使用着色器类设置
while (!glfwWindowShouldClose(window))
{
// 输入
processInput(window);
// 渲染
// 清除颜色缓冲
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
// 记得激活着色器
shader.use();
// 更新uniform颜色
float timeValue = glfwGetTime();
float greenValue = sin(timeValue) / 2.0f + 0.5f;
shader.setVec4("ourColor", 0.0f, greenValue, 0.0f, 1.0f);
// 绘制三角形
glActiveTexture(GL_TEXTURE0);
glBindTexture(GL_TEXTURE_2D, texture1);
glActiveTexture(GL_TEXTURE1);
glBindTexture(GL_TEXTURE_2D, texture2);
glBindVertexArray(VAO);
glDrawElements(GL_TRIANGLES, 6, GL_UNSIGNED_INT, 0);
// 交换缓冲并查询IO事件
glfwSwapBuffers(window);
glfwPollEvents();
}
//释放资源
glfwTerminate();
return 0;
}
//点着色器
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aColor;
layout (location = 2) in vec2 aTexCoord;
out vec3 ourColor;
out vec2 TexCoord;
void main()
{
gl_Position = vec4(aPos, 1.0);
ourColor = aColor;
TexCoord = aTexCoord;
}
//片段着色器
#version 330 core
out vec4 FragColor;
in vec3 ourColor;
in vec2 TexCoord;
uniform sampler2D texture1;
uniform sampler2D texture2;
void main()
{
FragColor = mix(texture(texture1, TexCoord), texture(texture2, TexCoord), 0.2);
}
复杂纹理¶
3 d 纹理¶
- 从 3 d 纹理获取数据使用三维坐标
纹理数组¶
- 将多组尺寸和格式相同的纹理合并到一个集合,生成一个更高维度的纹理
- 虽然压缩后用来索引的纹理坐标会被归一到 [0,1],纹理数组提供了按序号进行访问的方法
GLuint textureArray; glGenTextures(1, &textureArray); glBindTexture(GL_TEXTURE_2D_ARRAY, textureArray); // 定义纹理数组的维度和格式 int width = 512; // 单张纹理的宽度 int height = 512; // 单张纹理的高度 int layers = 10; // 纹理层数 glTexImage3D( GL_TEXTURE_2D_ARRAY, 0, GL_RGBA8, width, height, layers, 0, GL_RGBA, GL_UNSIGNED_BYTE, nullptr ); // 设置纹理过滤和环绕方式 glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_WRAP_T, GL_REPEAT); for (int i = 0; i < layers; ++i) { // 假设已经加载图像数据到 imageData unsigned char* imageData = LoadImage("texture" + std::to_string(i) + ".png"); glTexSubImage3D( GL_TEXTURE_2D_ARRAY, 0, 0, 0, i, // x, y 偏移,z 表示层索引 width, height, 1, // 宽度,高度,层数(1表示只上传一层) GL_RGBA, GL_UNSIGNED_BYTE, imageData ); free(imageData); } glActiveTexture(GL_TEXTURE0); glBindTexture(GL_TEXTURE_2D_ARRAY, textureArray); // 将纹理单元绑定到着色器中的采样器 GLuint shaderProgram = ...; glUniform1i(glGetUniformLocation(shaderProgram, "textureArray"), 0); #version 330 core uniform sampler2DArray textureArray; in vec3 texCoords; // texCoords.z 是层索引 out vec4 FragColor; void main() { FragColor = texture(textureArray, texCoords); // 使用三维纹理坐标采样 }
- 虽然压缩后用来索引的纹理坐标会被归一到 [0,1],纹理数组提供了按序号进行访问的方法
立方体贴图¶
- 立方体贴图由 6 个普通的平面贴图组成

- 创建并绑定立方体贴图的面
unsigned int loadCubemap(vector<std::string> faces)
{
unsigned int textureID;
glGenTextures(1, &textureID);
glBindTexture(GL_TEXTURE_CUBE_MAP, textureID);
int width, height, nrChannels;
for (unsigned int i = 0; i < faces.size(); i++)
{
unsigned char *data = stbi_load(faces[i].c_str(), &width, &height, &nrChannels, 0);
if (data)
{
glTexImage2D(GL_TEXTURE_CUBE_MAP_POSITIVE_X + i,
0, GL_RGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, data
);
stbi_image_free(data);
}
else
{
std::cout << "Cubemap texture failed to load at path: " << faces[i] << std::endl;
stbi_image_free(data);
}
}
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_CUBE_MAP, GL_TEXTURE_WRAP_R, GL_CLAMP_TO_EDGE);
return textureID;
}
vector<std::string> faces
{
"right.jpg",
"left.jpg",
"top.jpg",
"bottom.jpg",
"front.jpg",
"back.jpg"
};
unsigned int cubemapTexture = loadCubemap(faces);
- 片段着色器中要使用 samplerCube
#version 330 core
layout (location = 0) in vec3 aPos;
out vec3 TexCoords;
uniform mat4 projection;
uniform mat4 view;
void main()
{
TexCoords = aPos;
gl_Position = projection * view * vec4(aPos, 1.0);
}
#version 330 core
out vec4 FragColor;
in vec3 TexCoords;
uniform samplerCube skybox;
void main()
{
FragColor = texture(skybox, TexCoords);
}
天空盒¶
- 立方体贴图可以用于实现天空盒
- 为了在天空盒中有移动效果,可以消除调控和的位移效果(即不因摄像机动而动),但是保留旋转效果
- 先渲染场景物体,最后再渲染天空盒;通过提前深度测试,在天空盒渲染阶段快速丢弃被场景物体遮挡的像素,从而减少片段着色器的运行。(天空盒的深度始终为最大的 1.0)
- 要将条件从小于改为小于等于
glDepthFunc(GL_LEQUAL);
缓存纹理¶
- 允许着色器直接访问缓存对象的内容,将其作为一个巨大的一位纹理使用,即将一个缓存对象作为纹理进行访问和管理
- 将缓存对象绑定到纹理
void glTextureBuffer(GLuint texture,GLenum internalformat,GLuint buffer);
纹理视图¶
- 从一个纹理对象可以创建出多个纹理视图
- 这些视图可以拥有不同的格式或子范围
- 也就是可以利用相同的数据进行不同解读,避免了重复创建纹理
void glTextureView(GLuint texture, GLenum target, GLuint origtexture, GLenum internalformat, GLuint minlevel, GLuint numlevels, GLuint minlayer, GLuint numlayers);texture:新创建的纹理视图的ID。target:视图的目标类型(例如GL_TEXTURE_2D、GL_TEXTURE_2D_ARRAY)。origtexture:原始纹理的ID。internalformat:新视图的内部格式(可以与原始纹理不同,但需兼容)。minlevel:视图的最低mipmap级别。numlevels:视图包含的mipmap级别数。minlayer:视图的最低层索引(对于3D纹理或纹理数组)。numlayers:视图包含的层数。
- 只要还有一个视图正在引用纹理,元数据就不会被删除
滤波方式¶
- 屏幕上的一个像素通常不会刚好对应纹理中的一个像素,
- 玩家喧杂不同的滤波(算法)来决定这个映射关系
线性滤波¶
- 从一组离散的采样信号中选择相邻的采样点,然后将信号曲线拟合成近似线性的形式
- 即将点连成线,将线上的点作为采样点
- (双线性采样)
- 线性滤波可以在 mipmap 层直接进行
// 设置纹理的最小滤波方式(当纹理坐标映射到纹理的多个像素时) glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR_MIPMAP_LINEAR); // 设置纹理的放大滤波方式(当纹理坐标映射到一个像素时) glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
GL_NEAREST:最近点滤波,选择最接近的纹素。GL_LINEAR:线性滤波,对纹素进行线性插值,得到较平滑的效果。GL_NEAREST_MIPMAP_NEAREST:选择最接近的mipmap级别,然后在该级别上使用最近点滤波。GL_LINEAR_MIPMAP_NEAREST:选择最接近的mipmap级别,然后在该级别上使用线性滤波。GL_NEAREST_MIPMAP_LINEAR:选择两个最接近的mipmap级别,然后对这两个级别分别进行最近点滤波,再对结果进行线性插值。GL_LINEAR_MIPMAP_LINEAR:选择两个最接近的mipmap级别,然后对这两个级别分别进行线性滤波,再对结果进行线性插值。
mipmap¶
- 使用 mipmap 要给出纹理从最大尺寸到 1*1 的所有尺寸,按照 2 的幂进行划分
- 由 opengl 快速生成
void glGenerateTextureMipmap(GLuint texture);- 以 texture 为第 0 层生成全部的 mipmap
- 层次计算
- 纹理图像和贴图纹理的尺寸缩放比记为 \(\rho\) ,层次为 \(\lambda{=}\log_{2}\rho{+}lod_{bias}\),其中当 \(\rho=1\) 刚好选择原图,即第 0 层
- \(lod\) 为一个偏移值,通常为常数
- 当两边缩放比例不一致时选择较大值
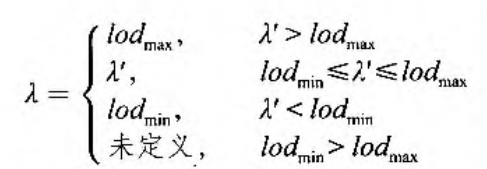
无绑定纹理¶
- opengl 支持一定数目的全局纹理,不需要绑定到纹理单月就可以在采样器中使用
- 通过采样器句柄(64 位数字)来通过采样器访问纹理
- 获得纹理句柄
GLuint64 GetTextureHandleARB(GLuint texture); GLuint64 GetTextureSamplerHandleARB(GLuint texture,GLuint sampler); - 通过把这个句柄传递到着色器实现读取
- 必须预先向驻留纹理列表中添加、删除纹理句柄

- 检查
GLboolean IsTextureHandleResidentARB(GLuint64 handle):
- 使用无绑定纹理比反复更换绑定的纹理效率更高
稀疏纹理¶
- 普通的纹理在显存中连续存储,会占据较大的空间;稀疏纹理将纹理划分为小块,只加载现在需要的部分数据而不是预先全部加载,从而降低了显存的占用
GLuint tex; //首先创建-个纹理对象 glCreateTextures(GL TEXTURE 2D ARRAY,1,&tex); //开启它的稀疏属性 glTextureParameteri(tex,GL TEXTURE SPARSE ARB,GL TRUE); //现在分配纹理的虚拟存储空问 glTexturestorage3D(tex,11,GL RGBA8,2048,2048,2048); - 通过
void TexturePageCommitmentEXT(GLuint texture,GLint level,GLint xoffset,GLint yoffset, GLint zoffset, GLsizei width, GLsizei height, GLsizei depth, GLboolean commit);来控制稀疏纹理页的
环境映射¶
-
通过环境的立方体贴图,给物体反射和折射属性
-
当立方体位于 (0,0,0) 时每个位置向量都是从原点出发的方向向量,这个方向向量正是获取立方体上特定位置的纹理值所需要的(即通过方向向量来获取数据)
反射¶
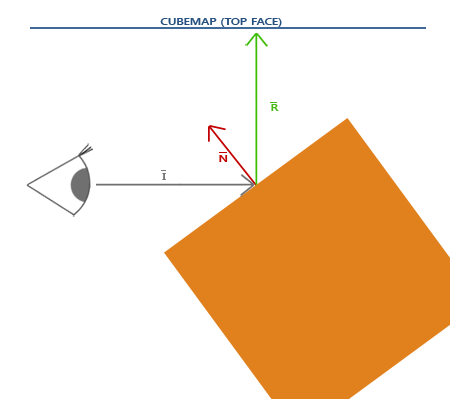
- 计算得到反射向量,通过反射向量采样立方体贴图,返回环境的颜色值
#version 330 core
layout (location = 0) in vec3 aPos;
layout (location = 1) in vec3 aNormal;
out vec3 Normal;
out vec3 Position;
uniform mat4 model;
uniform mat4 view;
uniform mat4 projection;
void main()
{
Normal = mat3(transpose(inverse(model))) * aNormal;
Position = vec3(model * vec4(aPos, 1.0));
gl_Position = projection * view * model * vec4(aPos, 1.0);
}
#version 330 core
out vec4 FragColor;
in vec3 Normal;
in vec3 Position;
uniform vec3 cameraPos;
uniform samplerCube skybox;
void main()
{
vec3 I = normalize(Position - cameraPos);
vec3 R = reflect(I, normalize(Normal));
FragColor = vec4(texture(skybox, R).rgb, 1.0);
}
折射¶
- 类似的,通过折射定律获取方向获取法向量,进而获取材质数据
void main()
{
float ratio = 1.00 / 1.52;
vec3 I = normalize(Position - cameraPos);
vec3 R = refract(I, normalize(Normal), ratio);
FragColor = vec4(texture(skybox, R).rgb, 1.0);
}
程序式纹理¶
程序生成纹理¶
条纹生成¶
- 在顶点着色器生成
#version 330 core uniform vec3 LightPosition; // 光源的位置 uniform vec3 LightColor; // 光源的颜色 uniform vec3 Eyeposition; // 观察者的位置 uniform vec3 Specular; // 镜面反射的颜色 uniform vec3 Ambient; // 环境光的颜色 uniform float Kd; // 漫反射系数 uniform mat4 MVMatrix; // 模型视图矩阵 uniform mat4 MVPMatrix; // 模型视图投影矩阵 uniform mat3 NormalMatrix; // 法线矩阵 in vec3 MCVertex; // 顶点的位置 in vec3 MCNormal; // 顶点的法线 in vec2 TexCoord0; // 纹理坐标 out vec3 DiffuseColor; // 输出漫反射颜色 out vec3 SpecularColor; // 输出镜面反射颜色 out float TexCoord; // 输出纹理坐标的T分量 void main() { // 计算顶点的世界空间位置 vec3 ecPosition = vec3(MVMatrix * vec4(MCVertex, 1.0)); // 计算变换后的法线 vec3 tnorm = normalize(NormalMatrix * MCNormal); // 计算光线方向(从物体到光源) vec3 lightVec = normalize(LightPosition - ecPosition); // 计算视线方向(从物体到观察者) vec3 viewVec = normalize(EyePosition - ecPosition); // 计算光照反射的条纹效果 float scaledT = fract(TexCoord0.t * Scale); // 通过纹理坐标生成条纹效果 float frac1 = clamp(scaledT - Fuzz, 0.0, 1.0); // 计算条纹的起始部分 float frac2 = clamp((scaledT + Width) - Fuzz, 0.0, 1.0); // 计算条纹的结束部分 frac1 = 1.0 - frac2; // 反转条纹效果 frac1 = frac1 * (3.0 - (2.0 * frac1)); // 强调条纹的对比度 // 混合背景色和条纹色,最终得到条纹的颜色 vec3 finalColor = mix(BackColor, StripeColor, frac1); // 最终颜色与光照色的结合 finalColor = finalColor * (DiffuseColor + SpecularColor); // 设置最终的输出颜色 FragColor = vec4(finalColor, 1.0); // 计算顶点位置在裁剪空间的坐标 gl_Position = MVPMatrix * vec4(MCVertex, 1.0); } - 在片段着色器生成
#version 330 core uniform vec3 LightColor; // 光源颜色 uniform vec3 Specular; // 镜面反射颜色 uniform vec3 Ambient; // 环境光颜色 uniform vec3 BackColor; // 背景颜色(条纹的背景) uniform vec3 StripeColor; // 条纹的颜色 uniform float Width; // 条纹宽度 uniform float Fuzz; // 条纹的模糊度 uniform float Scale; // 条纹缩放 in vec3 DiffuseColor; // 漫反射颜色 in vec3 SpecularColor; // 镜面反射颜色 in float TexCoord; // 纹理坐标的T分量 out vec4 FragColor; // 输出颜色 void main() { // 计算条纹效果的强度 float scaledT = fract(TexCoord * Scale); // 缩放后的纹理坐标 float frac1 = clamp(scaledT - Fuzz, 0.0, 1.0); // 条纹模糊的开始部分 float frac2 = clamp((scaledT + Width) - Fuzz, 0.0, 1.0); // 条纹模糊的结束部分 frac1 = 1.0 - frac2; // 调整条纹的显示效果 frac1 = frac1 * (3.0 - (2.0 * frac1)); // 进一步增强条纹效果 // 将背景色和条纹色混合,形成条纹颜色 vec3 finalColor = mix(BackColor, StripeColor, frac1); // 最终的颜色:背景条纹色与漫反射、镜面反射结合 finalColor = finalColor * (DiffuseColor + SpecularColor); // 输出最终颜色 FragColor = vec4(finalColor, 1.0); } - 使用这种复杂的计算方式,是为了产生更柔和(反走样)的图像
五角星玩具球¶
 - 通过五角星的 5 条边建立 5 个半空间,球体上的点根据自身与每个半空间的关系定义为入点或出点
-
- 通过五角星的 5 条边建立 5 个半空间,球体上的点根据自身与每个半空间的关系定义为入点或出点
-  - 通过计数器统计一个片元在半空间内部的数目(初始值为-3,最终大于 0 即说明在五角星内部,可以完全显示)
- 创建了半球的坐标表示,很容易就能通过球心到片元的指向来判断这个片元是否在某一个半球内部
- 通过计数器统计一个片元在半空间内部的数目(初始值为-3,最终大于 0 即说明在五角星内部,可以完全显示)
- 创建了半球的坐标表示,很容易就能通过球心到片元的指向来判断这个片元是否在某一个半球内部
#version 330 core
// Uniform 变量:由主程序传递给着色器的参数
uniform float stripeWidth; // 条纹的宽度
uniform float InOrOutInit; // 初始条纹内外标记值
uniform float Fwidth = 0.005; // 控制条纹平滑过渡的宽度
uniform vec3 StarColor; // 五角星的颜色
uniform vec3 StripeColor; // 条纹的颜色
uniform vec4 BaseColor; // 球体的基础颜色
uniform vec3 LightDir; // 光源方向,必须归一化
uniform vec4 SpecularColor; // 镜面反射颜色
uniform float SpecularExponent; // 镜面反射的指数,控制高光的锐利度
uniform float Ka; // 环境光强度
uniform float Kd; // 漫反射系数
uniform vec3 Ks; // 镜面反射系数
uniform vec3 ECPosition; // 物体在视图空间中的位置
uniform vec3 OCPosition; // 物体在世界空间中的位置
uniform vec4 ECBallCenter; // 球体中心在视图空间中的位置
// 输入变量:从顶点着色器传入的顶点数据
in vec3 MCVertex; // 顶点位置
in vec3 MCNormal; // 顶点法线
in vec2 TexCoord0; // 纹理坐标
// 输出变量:传递到片段着色器的颜色值
out vec4 FragColor; // 最终输出颜色
void main()
{
// 计算得到的法线向量
vec3 normal;
normal = normalize(ECPosition.xyz - ECBallCenter.xyz); // 计算物体表面法线
// 计算表面位置
vec3 pShade;
pShade.xyz = normalize(OCPosition.xyz); // 物体坐标下的表面位置
pShade.w = 1.0;
// 初始化条纹内外标记
float inorout = InOrOutInit; // 初始化为给定的条纹内外值
// 计算与五角星的边界距离
float distance[4];
distance[0] = dot(pShade, HalfSpace[0]); // 计算到五角星半空间的距离
distance[1] = dot(pShade, HalfSpace[1]);
distance[2] = dot(pShade, HalfSpace[2]);
distance[3] = -dot(pShade, HalfSpace[3]);
// 对边界进行平滑过渡,消除硬边界
distance = smoothstep(-Fwidth, Fwidth, distance); // 平滑过渡边界
// 计算条纹的内外效果
distance.x = dot(pShade, HalfSpace[4]);
distance.y = stripeWidth * abs(pShade.z); // 计算条纹纵深效果
distance.xy = smoothstep(-Fwidth, Fwidth, distance.xy); // 平滑条纹边界
inorout += distance.x; // 更新条纹的内外状态
inorout = clamp(inorout, 0.0, 1.0); // 将其限制在0到1之间
// 基础颜色与五角星颜色的混合
vec3 surfColor = mix(BaseColor.rgb, StarColor, inorout);
// 根据条纹的效果混合条纹颜色
surfColor = mix(surfColor, StripeColor, distance.y);
// 计算光照效果:漫反射和镜面反射
// 漫反射光照计算
float intensity = Ka + Kd * clamp(dot(LightDir.xyz, normal), 0.0, 1.0); // 漫反射光照强度
surfColor *= intensity; // 将漫反射强度应用到表面颜色上
// 镜面反射光照计算
float HVectorDotNormal = clamp(dot(HVector.xyz, normal), 0.0, 1.0); // 计算反射向量与法线的点积
intensity = Ks * pow(HVectorDotNormal, SpecularExponent); // 镜面反射强度,SpecularExponent 控制高光锐利度
surfColor.rgb += SpecularColor.rgb * intensity; // 将镜面反射强度加入到最终的表面颜色中
// 输出最终颜色
FragColor = vec4(surfColor, 1.0); // 设置最终输出的颜色
}
法线贴图¶
- 可以使用 2 D 纹理来存储法线数据,xyz 三个方向分辨对应颜色的 rgb
- 通常切线都是指向 Z 轴,因此看起来为蓝色
// 从法线贴图范围[0,1]获取法线
normal = texture(normalMap, fs_in.TexCoords).rgb;
// 将法线向量转换为范围[-1,1]
normal = normalize(normal * 2.0 - 1.0);
- 物体有旋转等变换时不能直接使用法线贴图
切线空间¶
- 在切线空间中,法线指向 z 方向,法线贴图被定义在切线空间
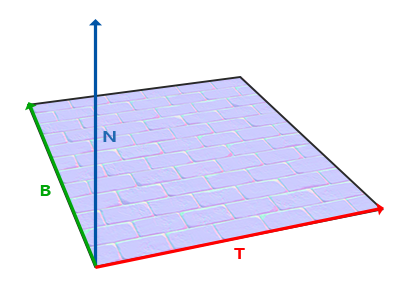
- 从一个三角形的顶点计算切线空间
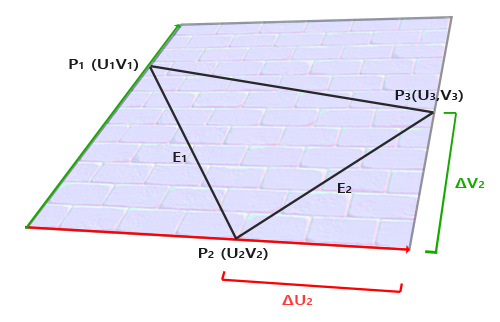
- \(\begin{aligned}(E_{1x},E_{1y},E_{1z})&=\Delta U_1(T_x,T_y,T_z)+\Delta V_1(B_x,B_y,B_z)\\(E_{2x},E_{2y},E_{2z})&=\Delta U_2(T_x,T_y,T_z)+\Delta V_2(B_x,B_y,B_z)\end{aligned}\)
- 计算公式 \(\begin{bmatrix}T_x&T_y&T_z\\B_x&B_y&B_z\end{bmatrix}=\frac1{\Delta U_1\Delta V_2-\Delta U_2\Delta V_1}\begin{bmatrix}\Delta V_2&-\Delta V_1\\-\Delta U_2&\Delta U_1\end{bmatrix}\begin{bmatrix}E_{1x}&E_{1y}&E_{1z}\\E_{2x}&E_{2y}&E_{2z}\end{bmatrix}\)
glm::vec3 edge1 = pos2 - pos1;
glm::vec3 edge2 = pos3 - pos1;
glm::vec2 deltaUV1 = uv2 - uv1;
glm::vec2 deltaUV2 = uv3 - uv1;
GLfloat f = 1.0f / (deltaUV1.x * deltaUV2.y - deltaUV2.x * deltaUV1.y);
tangent1.x = f * (deltaUV2.y * edge1.x - deltaUV1.y * edge2.x);
tangent1.y = f * (deltaUV2.y * edge1.y - deltaUV1.y * edge2.y);
tangent1.z = f * (deltaUV2.y * edge1.z - deltaUV1.y * edge2.z);
tangent1 = glm::normalize(tangent1);
bitangent1.x = f * (-deltaUV2.x * edge1.x + deltaUV1.x * edge2.x);
bitangent1.y = f * (-deltaUV2.x * edge1.y + deltaUV1.x * edge2.y);
bitangent1.z = f * (-deltaUV2.x * edge1.z + deltaUV1.x * edge2.z);
bitangent1 = glm::normalize(bitangent1);
[...] // 对平面的第二个三角形采用类似步骤计算切线和副切线
- 通过参数传递在着色器中获取 tbn 矩阵
#version 330 core
layout (location = 0) in vec3 position;
layout (location = 1) in vec3 normal;
layout (location = 2) in vec2 texCoords;
layout (location = 3) in vec3 tangent;
layout (location = 4) in vec3 bitangent;
void main()
{
[...]
vec3 T = normalize(vec3(model * vec4(tangent, 0.0)));
vec3 B = normalize(vec3(model * vec4(bitangent, 0.0)));
vec3 N = normalize(vec3(model * vec4(normal, 0.0)));
mat3 TBN = mat3(T, B, N)
}
- 法线贴图是在 TBN 坐标系中定义的,要将其转化到世界空间来进行渲染
- 切线空间 → 世界空间:\(\mathrm{Normal}_{{\mathrm{world}}}=\mathrm{TBN}\cdot\mathrm{Normal}_{{\mathrm{tangent}}}\):将贴图的法线转换到世界空间与光照等进行计算
- 世界空间 → 切线空间:\(\mathrm{LightDir}_{{\mathrm{tangent}}}=\mathrm{TBN}^{-1}\cdot\mathrm{LightDir}_{{\mathrm{world}}}\):将光照等转换到切线空间与贴图的法线进行计算
- 更常用:减少片段着色器的计算量,总体上效率更高
使用 assimp 实现复杂物体的切线空间计算¶
- 加载时添加
aiProcess_CalcTangentSpaceAssimp 会为每个加载的顶点计算出柔和的切线和副切线向量
const aiScene* scene = importer.ReadFile(
path, aiProcess_Triangulate | aiProcess_FlipUVs | aiProcess_CalcTangentSpace
);
//获取并保存
vector.x = mesh->mTangents[i].x;
vector.y = mesh->mTangents[i].y;
vector.z = mesh->mTangents[i].z;
vertex.Tangent = vector;
视差贴图¶
- 视差贴图是一种位移贴图
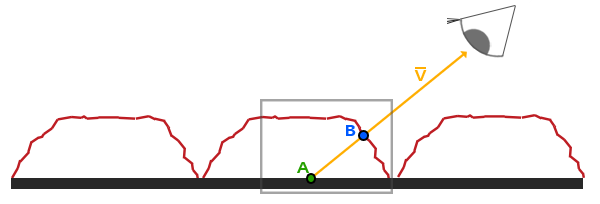
-
在以 \(V\) 方向看向 \(A\) 时通过加一个偏移,使得看到的内容贴近实际应该看到的 \(B\) 处
-
一个算法是取 \(P=AH(A)\) 按照这个高度沿方向偏移,得到点 \(H(P)\) 作为便宜后的问题
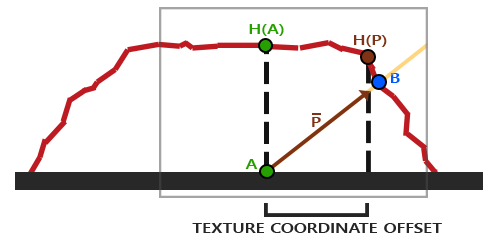
- 这个方法并不精确,有时会产生较大误差
- 因为要计算每个点的说色,因此在片段着色器中进行计算
void main()
{
// Offset texture coordinates with Parallax Mapping
vec3 viewDir = normalize(fs_in.TangentViewPos - fs_in.TangentFragPos);
vec2 texCoords = ParallaxMapping(fs_in.TexCoords, viewDir);
//丢弃错误数据
texCoords = ParallaxMapping(fs_in.TexCoords, viewDir);
if(texCoords.x > 1.0 || texCoords.y > 1.0 || texCoords.x < 0.0 || texCoords.y < 0.0)
discard;
// then sample textures with new texture coords
vec3 diffuse = texture(diffuseMap, texCoords);
vec3 normal = texture(normalMap, texCoords);
normal = normalize(normal * 2.0 - 1.0);
// proceed with lighting code
[...]
}
vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir, sampler2D heightMap)
{
// 从深度贴图中获取高度值
float height = texture(heightMap, texCoords).r; // 高度值范围是 [0, 1]
// 根据高度值和视角方向计算偏移量
vec2 p = viewDir.xy / viewDir.z * (height * scale - bias);
//scale控制视差效果的强度(比例因子)
//bias用于微调,使纹理偏移的起点更自然
// 调整纹理坐标(加还是减取决于view是从摄像机发出还是反之)
vec2 offsetTexCoords = texCoords - p;
// 返回调整后的纹理坐标
return offsetTexCoords;
}
陡峭视差映射¶
- 使用更多的样本来确定从向量到便宜点 B,在陡峭高度变化下有更好的表现
- 即通过增加采样的数目提高了精确性
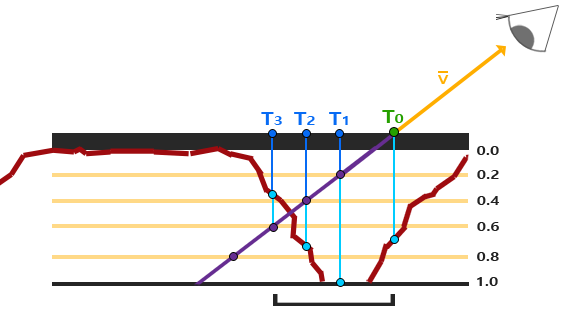
- 将总深度或分为多层,分别与视线方向产生交点
- 从上到下遍历深度层,直到找到第一个层深度大于深度贴图的点(图中的 T 3)
vec2 ParallaxMapping(vec2 texCoords, vec3 viewDir)
{
// number of depth layers
const float numLayers = 10;
// calculate the size of each layer
float layerDepth = 1.0 / numLayers;
// depth of current layer
float currentLayerDepth = 0.0;
// the amount to shift the texture coordinates per layer (from vector P)
vec2 P = viewDir.xy * height_scale;
vec2 deltaTexCoords = P / numLayers;
// get initial values
vec2 currentTexCoords = texCoords;
float currentDepthMapValue = texture(depthMap, currentTexCoords).r;
while(currentLayerDepth < currentDepthMapValue)
{
// shift texture coordinates along direction of P
currentTexCoords -= deltaTexCoords;
// get depthmap value at current texture coordinates
currentDepthMapValue = texture(depthMap, currentTexCoords).r;
// get depth of next layer
currentLayerDepth += layerDepth;
}
return currentTexCoords;
}
- 由于采样点固定,可能会出现锯齿和断层
- 可以通过增加采样数目来解决
- 也可以通过下面方法
视差遮蔽映射¶
- 取边缘的两个点并根据表面高度距离深度层深度值的距离进行线性插值
[...] // steep parallax mapping code here
// get texture coordinates before collision (reverse operations)
vec2 prevTexCoords = currentTexCoords + deltaTexCoords;
// get depth after and before collision for linear interpolation
float afterDepth = currentDepthMapValue - currentLayerDepth;
float beforeDepth = texture(depthMap, prevTexCoords).r - currentLayerDepth + layerDepth;
// interpolation of texture coordinates
float weight = afterDepth / (afterDepth - beforeDepth);
vec2 finalTexCoords = prevTexCoords * weight + currentTexCoords * (1.0 - weight);
return finalTexCoords;
程序式纹理反走样¶
走样的来源¶
- 如果被采样的场景的变化相对于采样点的空间来说频率非常高,呢么一些特性就会重叠和丢失,采样结果无法精确重现场景
- 周期性的样式被采样的次数必须至少是样式本身频率的两倍,否则就会走样(要准确地重建一个信号,采样频率必须至少是该信号最高频率的两倍)
避免走样¶
- 根据采样频率(如屏幕分辨率),选择不同大小的贴图(mipmap)
- 提高分辨率超采样(MSAA 抗锯齿)
噪声¶
- 一种随机的,可以附加到初始周期上的平滑扰动
- 倍频:两个频率值的臂力恰好是 2:1
- 一个程序式着色器中可以叠加多个倍频的噪声,但是如果噪声的频率是擦饲养频率的两倍以上,微粒避免出现走样,也应该停止添加更多细节(高频噪声),让其逐渐恢复到平均采样值
使用噪声¶
- 在 GLSL 中编写噪声函数/使用纹理贴图存储生成的噪声数据
- 可以使用一个 RGBA 贴图存储 4 维噪声(每个倍频的频率都是前一个的两倍,而振幅减半)
- 噪声生成代码
#include <stdio.h> #include <stdlib.h> #include <GL/gl.h> // OpenGL头文件,确保链接OpenGL库 int noise3DTexsize = 128; // 定义噪声纹理的尺寸 GLuint noise3DTexName = 0; // OpenGL纹理对象的名称(句柄) GLubyte *noise3DTexptr; // 指向3D噪声纹理数据的指针 // 用于生成3D噪声纹理的函数 void make3DNoiseTexture(void) { int f, i, j, k, inc; int frequency = 4; // 初始频率 int numOctaves = 4; // 噪声的分辨率(分多次进行采样,增强细节) double ni[3]; // 存储当前采样点的3D坐标 double inci, incj, inck; // 每一维的增量,用于生成不同维度的噪声 int startFrequency = frequency; GLubyte *ptr; // 用于操作噪声纹理数据的指针 double amp = 0.5; // 噪声的振幅(控制噪声的强度) // 分配内存来存储噪声纹理数据 if ((noise3DTexptr = (GLubyte*)malloc(noise3DTexsize * noise3DTexsize * noise3DTexsize * 4)) == NULL) { // 如果内存分配失败,打印错误信息并退出 fprintf(stderr, "ERROR: Could not allocate 3D noise texture\n"); exit(1); } // 生成多频率(Octave)噪声数据 for (f = 0, inc = 0; f < numOctaves; ++f, frequency *= 2, ++inc, amp *= 0.5) { // 设置噪声的频率(调用自定义函数 setNoiseFrequency) setNoiseFrequency(frequency); // 该函数需要定义,假设其用于设置当前噪声的频率 ptr = noise3DTexptr; ni[0] = ni[1] = ni[2] = 0; // 计算各个维度的采样增量 inci = 1.0 / (noise3DTexsize / frequency); // 根据频率设置增量 for (i = 0; i < noise3DTexsize; ++i, ni[0] += inci) { incj = 1.0 / (noise3DTexsize / frequency); // 同理处理第二维 for (j = 0; j < noise3DTexsize; ++j, ni[1] += incj) { inck = 1.0 / (noise3DTexsize / frequency); // 同理处理第三维 for (k = 0; k < noise3DTexsize; ++k, ni[2] += inck, ptr += 4) { // 生成噪声值并写入纹理数据 // noise(ni) 计算当前3D坐标的噪声值,假设该函数已定义 *(ptr + inc) = (GLubyte)(((noise(ni) + 1.0) * amp) * 128.0); } } } } // 生成并绑定 OpenGL 3D 噪声纹理 glGenTextures(1, &noise3DTexName); // 生成一个新的纹理对象 glBindTexture(GL_TEXTURE_3D, noise3DTexName); // 绑定该纹理对象 // 设置纹理参数 glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_S, GL_REPEAT); glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_T, GL_REPEAT); glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_R, GL_REPEAT); // 传递纹理数据到 OpenGL glTexImage3D(GL_TEXTURE_3D, 0, GL_RGBA, noise3DTexsize, noise3DTexsize, noise3DTexsize, 0, GL_RGBA, GL_UNSIGNED_BYTE, noise3DTexptr); // 释放分配的内存 free(noise3DTexptr); } // 假设的噪声生成函数 double noise(double *coord) { // 这里可以使用 Perlin 噪声或者 Simplex 噪声算法来生成噪声值 // 为了简单起见,假设我们返回一个伪随机值 return (rand() % 1000) / 1000.0; } // 假设的噪声频率设置函数 void setNoiseFrequency(int frequency) { // 此处可以用来修改噪声的频率(例如更新噪声生成算法的参数) }
绘制方式¶
图元¶
- opengl 主要支持点、线、三角形图元
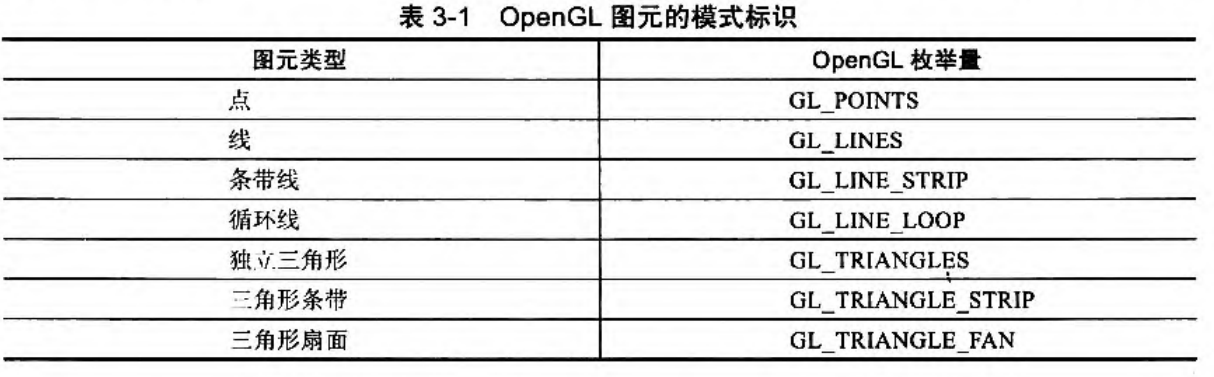
点¶
- 在屏幕上以一个二维的纹理图像或颜色方块呈现
- 在程序中设置点的大小
glPointSize(10.0f); // 设置点大小为10像素 - 在着色器中进行设置
gl_PointSize = 15.0; - 同样的大小坐标不同显示也会不同(位于像素交界处、像素中心)
点精灵¶
- 利用点的坐标渲染具有大小和纹理的图形对象,而不仅仅是像素点
glEnable(GL_POINT_SPRITE);#version 330 core layout(location = 0) in vec3 position; // 粒子的位置 layout(location = 1) in vec4 color; // 粒子的颜色 out vec4 fragColor; // 传递给片段着色器的颜色 uniform mat4 model; uniform mat4 view; uniform mat4 projection; void main() { gl_Position = projection * view * model * vec4(position, 1.0); gl_PointSize = 20.0; // 点的大小 fragColor = color; // 将颜色传递给片段着色器 } #version 330 core out vec4 FragColor; in vec4 fragColor; // 从顶点着色器传来的颜色 uniform sampler2D pointTexture; void main() { FragColor = fragColor * texture(pointTexture, gl_PointCoord); // 混合颜色和纹理 }- 根距纹理(点的形状),对点周边(点大小范围)区域进行绘制
- 常用于粒子系统、光源等
线¶
- 线由两个顶点表示
- 开放的多段线叫条带线;闭合的叫循环线
- 通过
glLineWidth()来设置线段宽度
绘制模式¶
- 设置图元的绘制模式
void glPolygonMode(GLenum face, GLenum mode)face:指定绘制哪一面GL_FRONT GL_BACK GL_FRONT_)AND_BACKmode:指定绘制模式GL_FILL填充绘制(默认)、GL_LINE:只绘制边缘、GL_POINT:只绘制顶点
三角形¶
- 三角形的渲染是通过三个顶点到屏幕以及三条边的链接来完成
- 三角形条带
- 三角形扇面

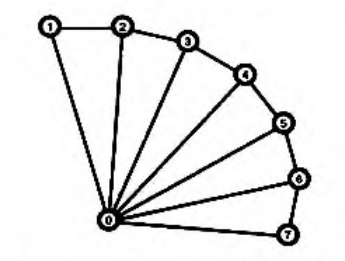
缓存数据¶
- 创建一个缓存对象
void glCreateBuffers(GLsizei n, GLuint*buffers) - 传统方式创建一个缓存对象之后还要将其连接到一个存储空间,即绑定到缓存目标
glBinfBuffer(GLenum target, GLuint buffer)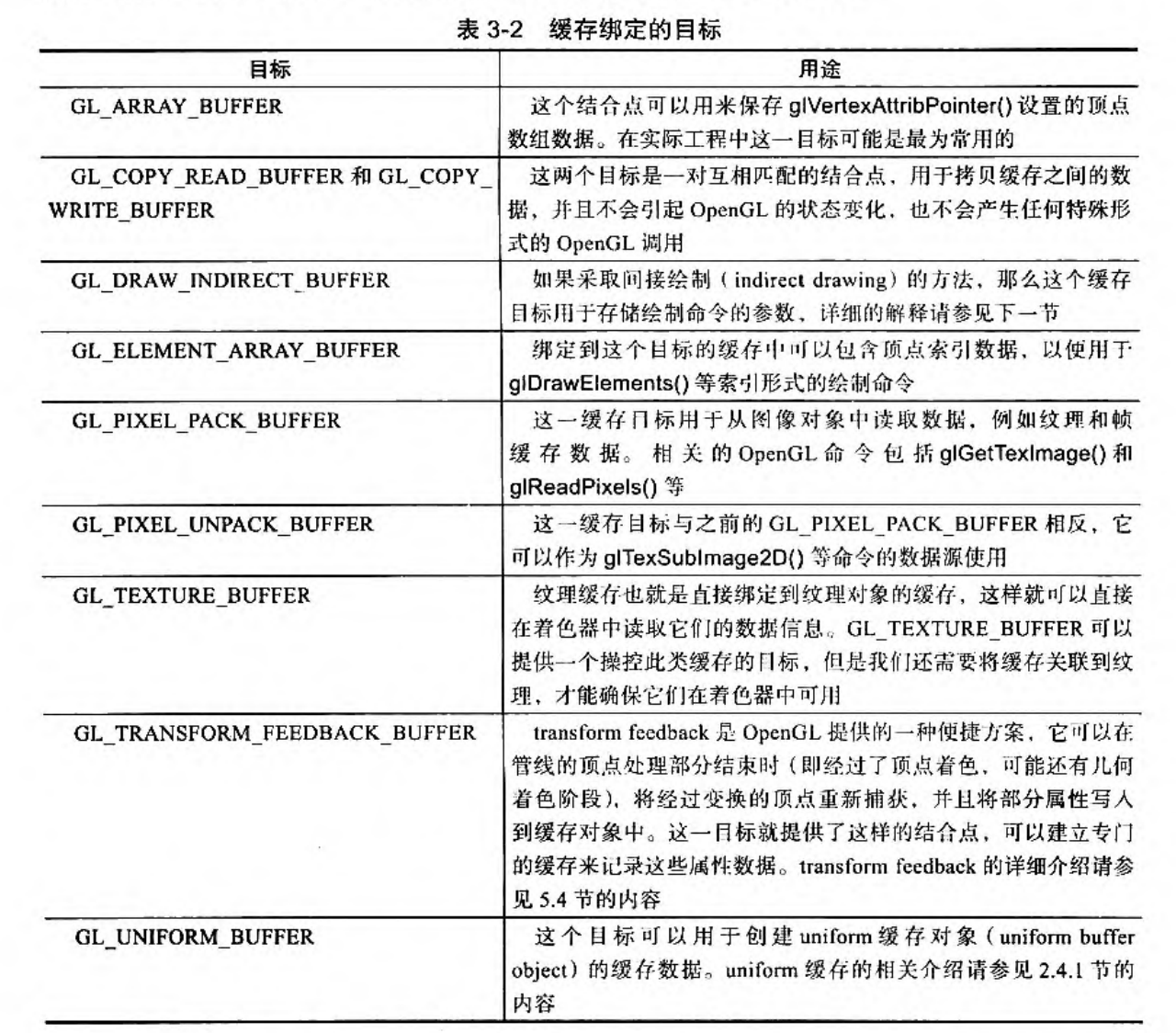
- 也可以直接在创建时传递管理数据
vodi glNamedBufferStorage(GLuint buffer, GLsizeiptr size, const void*data, GLbitfield flags);
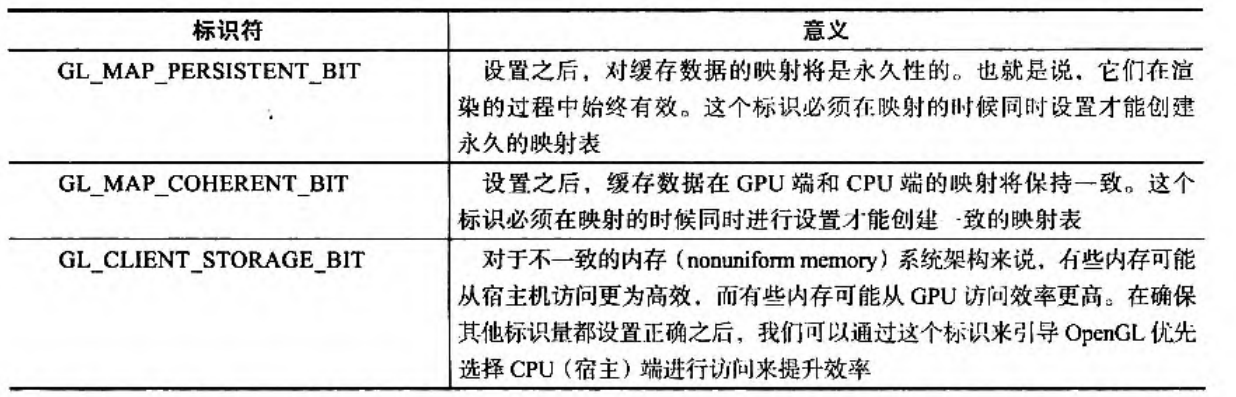
- 对部分数据单独更新
void glNamedBufferSubData(GLuint buffer, HLinptr offset, GLsizeiptr size, const void *data); 
- 这两个方法可以用于清空缓存(当 data=null 时)
- 冲一个缓存复制到另一个
void gLCopyNamedBufferSubData(GLuint readBuffer,GLuint writeBuffer,GLintptr readoffset, GLintptr writeoffset, GLsizeiptr size); - 从缓存读取数据
void glGetNamedBufferSubData(GLenum target,GLintptr offset,GLsizeiptr size,void*data);- 会进行一次数据拷贝,将缓存对象的数据存拷贝到应用程序内存中。
-
将缓存对象映射到客户端地址空间
void*glMapBuffer(GLenum target,GLenum access)
- 解除映射
GLboolean glUnmapNamedBuffer(Gluint buffer); - 通过映射可以方便的访问管理缓存数据
- 更适合频繁或高效的数据访问,尤其是在需要直接操作 GPU 内存的场景。它的性能通常优于
glGetNamedBufferSubData 
-
void gIMapNamedBufferRange(GLuint buffer,GLintptr offset,GLsizeiptr length,GLbitfield access);对部分缓存进行数据映射 - 丢弃不使用的缓存数据


这些缓存实际上都是在 GPU 中的
绘制命令¶
- 基于数组元素绘制几何图元
void glDrawArrays(GLenum mode,GLint first,GLsizei count):- mode 表示图元的类型:
GL_TRIANGLES、GL_LINE_LOOP、GL_LINES、GL_POINTS
- mode 表示图元的类型:
- 基于索引进行绘制
void glerawElements(GLenum mode,GLsizei count,GLenum type,const GLvoid*indices);- 指定开始的索引
void glDrawElementsBaseVertex(GLenum mode,GLsizei count,GLenum type,const GLvoid*indices. GLint basevertex); - 指定索引范围
void glDrawRangeElements(GLenum mode,GLuint start,GLuint end,GLsizei count,GLenum type, const GLvoid*indices);
- 指定开始的索引
- 间接绘制命令:从缓存对象中获取参数
void glDrawArrayslndirect(GLenum mode,const GLvoid*indirect);- 从 GL_DRAW_INDIRECT_BUFFER 缓存中获取结构体数据
- indirect 记录间接绘制缓存中的偏移地址,从在这个偏移地址的结构体中获取缓存的参数
- 类似的也有
void gIDrawElementsIndirect(GLenum mode,GLenum type,const GLvoid*indirect);
- 绘制多个图元
void gIMultiDrawArrays(GLenum mode,const GLint*first,const GLint*count,GLsize primcount);- 传入一系列数组,实现一次进行多个绘制动作

图元重启动¶
- 在同一个渲染命令中进行图元重启动的功能,通过指定一个图元重启动索引,opengl 在渲染时遇到这个重启动索引后就会从这个索引之后的顶点开始重新进行相同图源类型的渲染
- 定义重启动索引
glPrimitiveRestartIndex(GLuint index) 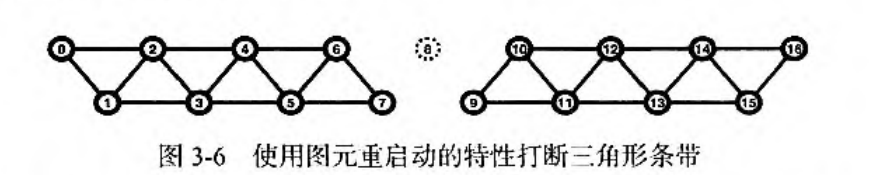
- 定义重启动索引
- 开启功能
glEnable(GL_PRIMITIVE_RESTART)
实例化渲染¶
-
实例化渲染通常会用于渲染草、植被、粒子,基本上只要场景中有很多重复的形状,都能够使用实例化渲染来提高性能。
-
反复绑定 VAO,由 cpu 去告诉 gpu 如何绘制,这样绘制多个物体是较慢的,如果我们能够将数据一次性发送给 GPU,然后使用一个绘制函数让 OpenGL 利用这些数据绘制多个物体,就会更方便了。这就是实例化。
-
即一个渲染调用来绘制多个物体,接受 CPU->GPU 通信
-
有一个额外参数,告诉 GPU 渲染的次数;微粒让物体渲染不同(而不是重复一个位置),着色器中有一个 in 变量
gl_InstanceID - 这个值从 0 开始,每个示例被渲染时递增 1
-
glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);即渲染 100 次 -
利用这个值很容易实现矩阵排列
#version 330 core
layout (location = 0) in vec2 aPos;
layout (location = 1) in vec3 aColor;
out vec3 fColor;
uniform vec2 offsets[100];
void main()
{
vec2 offset = offsets[gl_InstanceID];
gl_Position = vec4(aPos + offset, 0.0, 1.0);
fColor = aColor;
}

- 使用
uniform数组传递偏移数据时,当实例数量较多时会受到 GPU 硬件对uniform变量数量限制的制约。并且每次绘制都需要根据gl_InstanceID从uniform数组中索引数据,这种方式受限于数据带宽和硬件能力。 - 实例化数组:将逐实例的数据存储为顶点属性并通过顶点缓冲对象(VBO)传递,可以突破
uniform数量限制。通过设置更新频率在每个顶点计算时进行更新
#version 330 core
layout (location = 0) in vec2 aPos; // 顶点位置
layout (location = 1) in vec3 aColor; // 颜色
layout (location = 2) in vec2 aOffset; // 偏移量(实例化数组)
out vec3 fColor;
void main()
{
gl_Position = vec4(aPos + aOffset, 0.0, 1.0); // 使用偏移量
fColor = aColor;
}
- 创建实例化 VBO
unsigned int instanceVBO;
glGenBuffers(1, &instanceVBO);
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
// 将偏移量数组的数据传递到VBO
glBufferData(GL_ARRAY_BUFFER, sizeof(glm::vec2) * 100, &translations[0], GL_STATIC_DRAW);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glEnableVertexAttribArray(2); // 启用属性位置 2(aOffset)
glBindBuffer(GL_ARRAY_BUFFER, instanceVBO);
glVertexAttribPointer(2, 2, GL_FLOAT, GL_FALSE, 2 * sizeof(float), (void*)0);
glBindBuffer(GL_ARRAY_BUFFER, 0);
glVertexAttribDivisor(2, 1);//设置更新频率1
glBindVertexArray(quadVAO);
glDrawArraysInstanced(GL_TRIANGLES, 0, 6, 100);
- 即索引获取值的工作从着色器转移到了 CPU
片元测试¶
- 片元在进入当前帧缓存之前要进行一系列的测试:片元可能会在某个测试过程中丢弃
- 剪切测试
- 多重采样的片元测试
- 模板测试
- 深度测试
- 融混
- 逻辑操作
剪切测试¶
- 剪切盒:程序窗口中的一个矩形区域,所有的绘制操作都限制在这个区域之内
glEnable(SCISSOR_TEST)开启测试void glScissor(GLint x, GLint y, GLsizei width, GLsizei height)来设置剪切盒的属性
模板测试¶
- 模版测试是在深度测试之前进行的,每个模板值是 8 位的,可以丢弃或保留具有特定模板值的片段
- 模板测试的目的:利用已经本次绘制的物体,产生一个区域,在下次绘制中利用这个区域做一些效果。
- 启用模板缓冲的写入。
- 渲染物体,更新模板缓冲的内容。
- 禁用模板缓冲的写入。
- 渲染(其它)物体,这次根据模板缓冲的内容丢弃特定的片段。
- 启用模板测试
glEnable(GL_STENCIL_TEST); - 清除模板缓冲
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT); glStencilMask允许我们设置一个位掩码,它会与将要写入缓冲的模板值进行与 (AND) 运算
glStencilMask(0xFF); // 每一位写入模板缓冲时都保持原样
glStencilMask(0x00); // 每一位在写入模板缓冲时都会变成0(禁用写入)
模板函数¶
- 控制模板缓冲通过还是失败,以及如何影响模板缓冲
- 对模板缓冲做什么 (配置模版缓冲条件):
glStencilFunc(GLenum func, GLint ref, GLuint mask) func:设置模板测试函数 (Stencil Test Function)。这个测试函数将会应用到已储存的模板值上和 glStencilFunc 函数的ref值上。可用的选项有:GL_NEVER、GL_LESS、GL_LEQUAL、GL_GREATER、GL_GEQUAL、GL_EQUAL、GL_NOTEQUAL 和 GL_ALWAYS。它们的语义和深度缓冲的函数类似。ref:设置了模板测试的参考值, 模板缓冲的内容将会与这个值进行比较。mask:设置一个掩码,它将会与参考值和储存的模板值在测试比较它们之前进行与 (AND) 运算。初始情况下所有位都为 1。- 如
glStencilFunc(GL_EQUAL, 1, 0xFF) - 更新模板缓冲的值
glStencilOp(GLenum sfail, GLenum dpfail, GLenum dppass) sfail:模板测试失败时采取的行为。dpfail:模板测试通过,但深度测试失败时采取的行为。dppass:模板测试和深度测试都通过时采取的行为。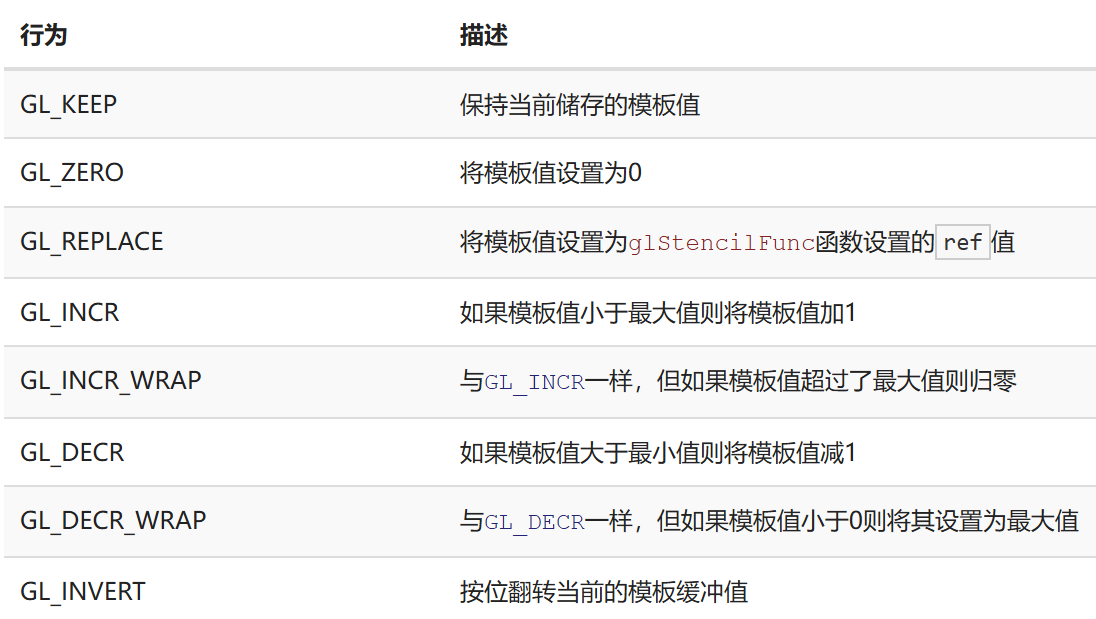
用模板测试实现物体描边¶

- 先绘制物体(原箱子)
glEnable(GL_STENCIL_TEST);
glStencilOp(GL_KEEP, GL_KEEP, GL_REPLACE);//如果模板测试和深度测试都通过了,那么我们希望将储存的模板值设置为参考值(1)
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT | GL_STENCIL_BUFFER_BIT);
glStencilMask(0x00); // 绘制不需要描边的物体
normalShader.use();
DrawFloor()
//绘制需要描边的物体
glStencilFunc(GL_ALWAYS, 1, 0xFF); // 所有的片段都应该更新模板缓冲
glStencilMask(0xFF); // 启用模板缓冲写入
DrawTwoContainers();
- 接下来绘制大一号的箱子作为描边,这次要禁用描边
//绘制描边
glStencilFunc(GL_NOTEQUAL, 1, 0xFF);//GL_NOTEQUAL只绘制模板值不为1的区域
glStencilMask(0x00); // 禁止模板缓冲的写入
glDisable(GL_DEPTH_TEST);
shaderSingleColor.use();
DrawTwoScaledUpContainers();
glStencilMask(0xFF);
深度测试¶
- 通常深度测试是在片段着色器运行之后在屏幕空间进行的
- 提前深度测试:在片段着色器之前运行,提前丢弃永远不可见的片段,减少计算量
- 开启深度测试
glEnable(GL_DEPTH_TEST); - 使用深度测试时,清除缓存是还要清除深度数据
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT); - 将深度缓冲数据设置为只读,禁止修改
glDepthMask(GL_FALSE); - 自定义深度测试比较函数
glDepthFunc(GL_LESS); 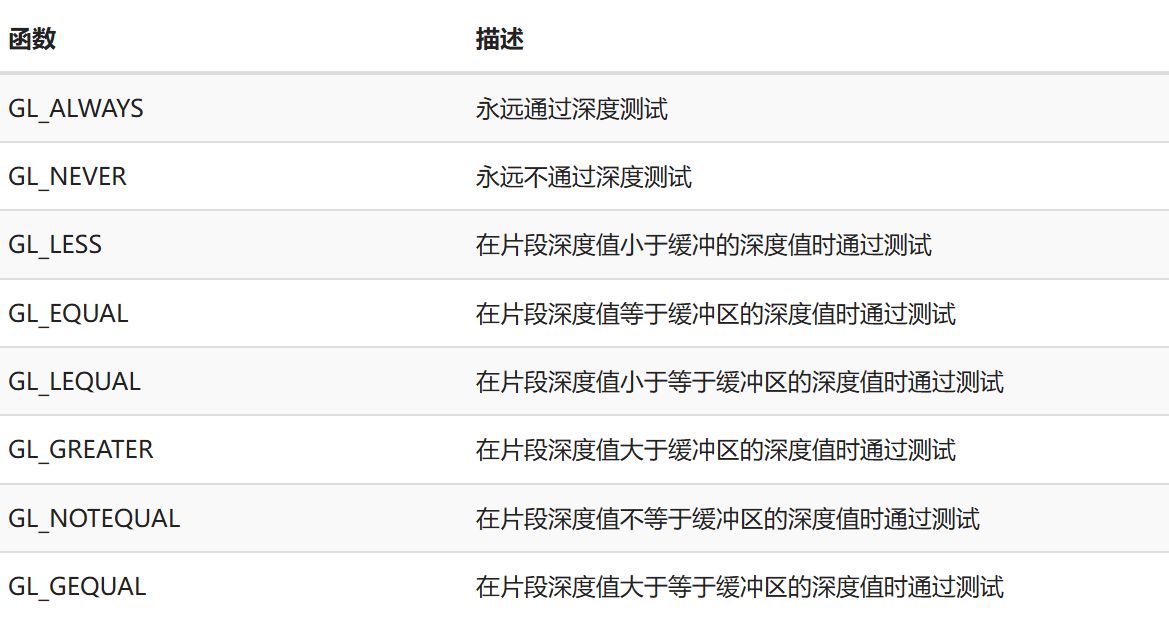
- 通常根据近远平面的值来计算深度值
- 一种线性方程 \(F_{depth}=\frac{z-near}{far-near}\)
- 更常用的是非线性方程,与 \(1/z\) 成正比,即 z 值较小时具有较高的精度 \(F_{depth}=\frac{1/z-1/near}{1/far-1/near}\)
- 深度缓冲精度不足时就会出现深度冲突,结果就是这两个形状不断地在切换前后顺序,这会导致很奇怪的花纹。
- 着色器中通过
gl_FragCoord.z可以直接获取到深度缓冲的值
多边形偏移¶
- 通过调整深度值来解决深度冲突问题
void glPolygonOffset(GLfloat factor, GLfloat uints)来为即将渲染的多边形设置一个深度偏移量- factor 为深度便宜的缩放因子、uints 为控制偏移量的绝对大小
offset = m*factor + r*unitsm 为最大深度斜率(表示多边形的表面倾斜程度),r 为不同深度值之间可识别的最小差值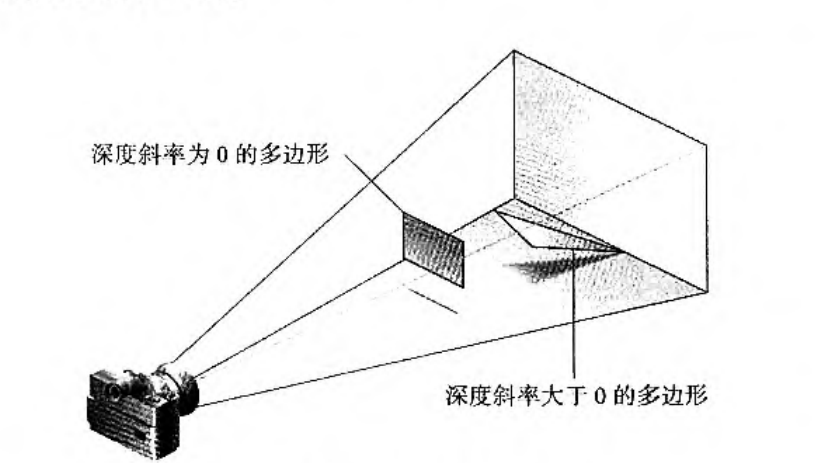
- 通常 factor 设置为一个较大的值(尤其倾斜度较大);uints 设置为一个较小的值
逻辑操作¶
- 对输入的片元数据、颜色缓冲中的数据等进行或、异或、非等操作
- 开启:
glEnable(GL_COLOR_LOGIC_OP) - 定义如何将缓冲区的颜色值与输入颜色值进行逻辑运算,通常在颜色混合之前进行
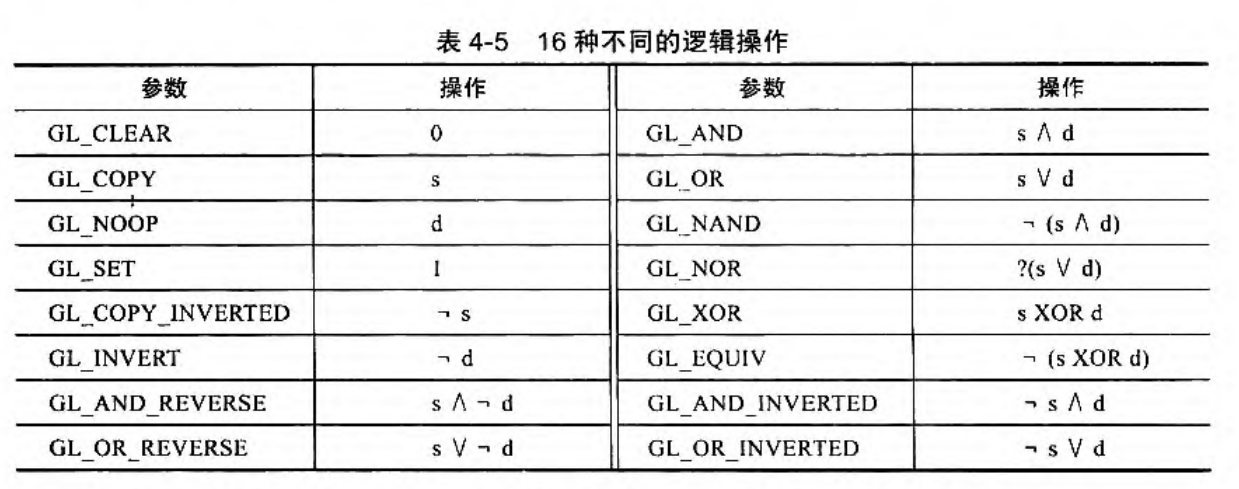
遮挡查询¶
- 遮挡查询利用 GPU 的 深度缓冲区来检测一个物体是否在视锥体内被其他物体完全挡住。通过这种方式,只有在物体可见时,才进行实际的渲染。通过减少无效的绘制操作,避免绘制被遮挡的物体,能够显著提升渲染效率。
- 创建查询对象:存储查询结果的容器
glGenQueries(1, &queryID); - 开始查询:
glBeginQuery(GL_SAMPLES_PASSED, queryID); - 进行绘制
glDrawArrays(GL_TRIANGLES, 0, 36); - 结束查询
glEndQuery(GL_SAMPLES_PASSED); - 获取查询结果
GLuint sampleCount; glGetQueryObjectuiv(queryID, GL_QUERY_RESULT, &sampleCount); - 程序可以依据这个结果进行判断,决定进一步的操作
- 例如,如果一个物体完全被另一个物体遮挡,可以跳过该物体的渲染过程。
GLuint queryID; glGenQueries(1, &queryID); // 创建查询对象 // 开始渲染过程 for (int i = 0; i < numObjects; ++i) { // 启动遮挡查询,查询物体是否通过了深度测试 glBeginQuery(GL_SAMPLES_PASSED, queryID); // 绘制物体(可能会被遮挡) glBindVertexArray(objectVAO[i]); // 绑定当前物体的顶点数组 glDrawArrays(GL_TRIANGLES, 0, objectVertexCount[i]); // 绘制物体 glEndQuery(GL_SAMPLES_PASSED); // 结束查询 // 获取查询结果 GLuint sampleCount = 0; glGetQueryObjectuiv(queryID, GL_QUERY_RESULT, &sampleCount); // 如果物体未被遮挡,继续渲染该物体 if (sampleCount > 0) { // 物体可见,执行后续渲染操作 glUseProgram(shaderProgram); glDrawArrays(GL_TRIANGLES, 0, objectVertexCount[i]); // 再次绘制物体 } // 否则,跳过渲染这个物体 }
- 例如,如果一个物体完全被另一个物体遮挡,可以跳过该物体的渲染过程。

条件渲染¶
- 使用遮挡查询时:opengl 需要暂时停止片元处理,计算样本数目后返回值给程序,这会造成性能损失
- 通过条件渲染来判断遮挡查询可以避免暂停 opengl 的操作
void glBeginCondifionalRender(GLuint id,GLenum mode); void glEndConditionalRender(void); - 系统根据遮挡查询对象 id 的结果来决定是否自动抛弃,mode 设置判断方式


GLuint queryID; glGenQueries(1, &queryID); // 创建查询对象 // 开始渲染过程 for (int i = 0; i < numObjects; ++i) { // 启动遮挡查询,查询物体是否通过了深度测试 glBeginQuery(GL_SAMPLES_PASSED, queryID); // 绘制物体(可能会被遮挡) glBindVertexArray(objectVAO[i]); // 绑定当前物体的顶点数组 glDrawArrays(GL_TRIANGLES, 0, objectVertexCount[i]); // 绘制物体 glEndQuery(GL_SAMPLES_PASSED); // 结束查询 // 开始条件渲染,只有在遮挡查询的结果大于 0 时才渲染物体 glBeginConditionalRender(queryID, GL_QUERY_WAIT); // 如果查询结果为 0,则此时的渲染会被跳过 glUseProgram(shaderProgram); glDrawArrays(GL_TRIANGLES, 0, objectVertexCount[i]); // 渲染物体 glEndConditionalRender(); // 结束条件渲染 }
- 与手动进行判断相比:条件渲染的好处是,它允许在 GPU 上进行异步查询,而不需要在 CPU 上主动检查查询结果。GPU 可以在后台处理查询,只有在查询结果可用时才继续渲染。这减少了 CPU 与 GPU 之间的同步开销。
glBeginConditionalRender()使得这种查询结果驱动的渲染控制更加高效,特别适合用于需要频繁查询的场景,例如遮挡查询、性能监控等。
着色器的内建变量¶
顶点着色器¶
gl_PointSize:输出变量,float,可以用于设置点的宽高(像素)、- 默认禁用,需要先
glEnable(GL_PROGRAM_POINT_SIZE); - 可以动态设置,比如根据 z 进行设置,就可以实现距离变远点增大等
gl_VertexID:输入变量,存储了正在绘制的顶点的 ID,使用索引绘制时,这个值就等于索引值;否则为从渲染调用开始的已处理的顶点数量
片段着色器¶
gl_FragCoord:输入变量,Vec 3,xy 分量为片段的窗口坐标(左下角为原点),z 为片段的深度值(只读)gl_FrontFacing:输入百年来那个,bool,可以获取当前片段式属于正向面还是属于北背向面的想(如果你开启了面剔除,你就看不到箱子内部的面了,所以现在再使用 gl_FrontFacing 就没有意义了。)gl_FragDepth:输出变量,float,可以设置深度值- 使用了则会禁用提前深度测试
- 可以使用深度条件进行声明
layout (depth_<condition>) out float gl_FragDepth; 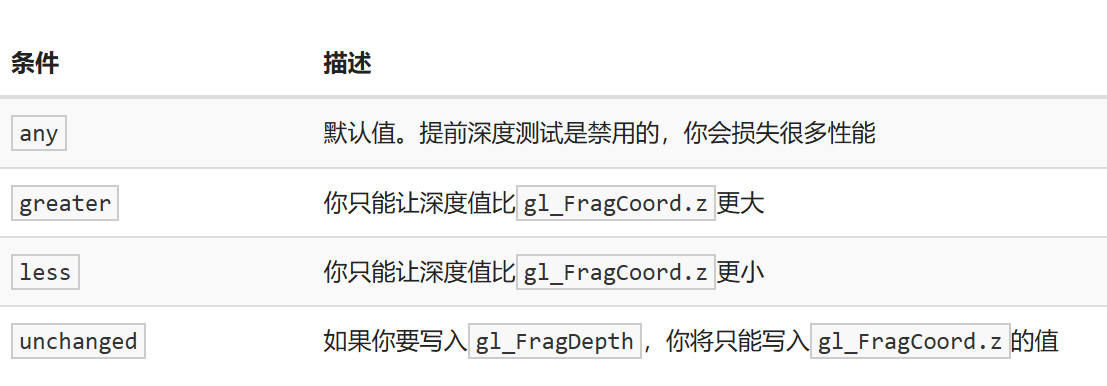
- 这样就能保留部分的提前深度测试
多重采样¶
- 用于对几何图元的边缘进行平滑(反走样)
- 对每个像素点的几何图元进行多次采样,每个像素点记录多个样本值,最终显示时样本值被解析为最终像素的颜色
- 开启多重采样
glEnable(GL_MULTISAMPLE); - 获取每个像素中有多少个样本值用于多重采样
glGetIntegerv(GL_SAMPLES)- 如 4 就是 4xMSAA
- 由缓冲区设置和设备支持决定
glGetIntegerv(GL_MAX_SAMPLES, &maxSamples);设备支持的最大样本数GlEnable(GL_SAMPLE_SHADING)强制 OpenGL 使用采样着色方式glMinSampleShading(GLfloat value)- 0~1 表示至少使用多少比例的样本进行着色,0 表示只用一个,1 表示用全部的
抗锯齿¶
-
要使用 MSAA 需要在每个像素中存储大于 1 个颜色值的颜色缓冲,即多重采样缓冲
-
通过 GLFW 可以快速实现 MSAA
-
glfwWindowHint(GLFW_SAMPLES, 4);之后再创建渲染窗口,每个屏幕坐标就会有一个包含 4 个子采样点的颜色缓冲了。 -
通过
glHint(GLenum target, GLenum mode)可以提示驱动程序如何在某些情况下选择实现特定操作的策略
GL_DONT_CARE:表示驱动程序可以自由选择最适合的方式,不必考虑提示的影响。GL_FASTEST:表示驱动程序应优先选择速度最快的方式,通常会牺牲一些质量或精度。GL_NICEST:表示驱动程序应优先选择质量最好的方式,通常会牺牲一些性能。
- 线段反走样
- 通常要对 alpha 通道进行融混设置

- 多边形反走样
- 也要对 alpha 进行混融
- 并且要保证按顺序进行渲染(防止深度缓冲直接丢弃)
离屏 MSAA¶
-
通过帧缓冲来实现
-
创建支持多采样点的纹理
// 1. 创建多重采样帧缓冲
GLuint multisampledFBO;
glGenFramebuffers(1, &multisampledFBO);
glBindFramebuffer(GL_FRAMEBUFFER, multisampledFBO);
// 1.1 创建并附加多重采样纹理附件
GLuint tex;
glGenTextures(1, &tex);
glBindTexture(GL_TEXTURE_2D_MULTISAMPLE, tex);
glTexImage2DMultisample(GL_TEXTURE_2D_MULTISAMPLE, 4, GL_RGB, width, height, GL_TRUE);
glFramebufferTexture2D(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D_MULTISAMPLE, tex, 0);
// 1.2 创建并附加多重采样渲染缓冲(深度和模板缓冲)
GLuint rbo;
glGenRenderbuffers(1, &rbo);
glBindRenderbuffer(GL_RENDERBUFFER, rbo);
glRenderbufferStorageMultisample(GL_RENDERBUFFER, 4, GL_DEPTH24_STENCIL8, width, height);
glFramebufferRenderbuffer(GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER, rbo);
// 检查帧缓冲完整性
if (glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE)
std::cout << "ERROR::FRAMEBUFFER:: Framebuffer is not complete!" << std::endl;
glBindFramebuffer(GL_FRAMEBUFFER, 0);
// 2. 渲染到多重采样帧缓冲
glBindFramebuffer(GL_FRAMEBUFFER, multisampledFBO);
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glEnable(GL_DEPTH_TEST);
RenderScene();
glBindFramebuffer(GL_FRAMEBUFFER, 0);
// 3. 解析多重采样图像并显示
glBindFramebuffer(GL_READ_FRAMEBUFFER, multisampledFBO);
glBindFramebuffer(GL_DRAW_FRAMEBUFFER, 0);
glBlitFramebuffer(0, 0, width, height, 0, 0, width, height, GL_COLOR_BUFFER_BIT, GL_NEAREST);
- 由于多重采样纹理无法直接在片段着色器中采样,因此无法直接用于后期处理
- 通过将多重采样帧缓冲的内容还原到普通的帧缓冲生成可采样的 2 D 纹理,然后使用该纹理作为输入进行后期处理。
读取像素数据¶
- 渲染工作结束后,可以获取渲染后的图像中的数据用以他用,可以使用
glReadPixels函数从可读的帧缓冲中获取像素void glReadPixels(GLint x,GLint y,GLsizei width,GLsizei height,GLenum format GLenum type, void*pixels);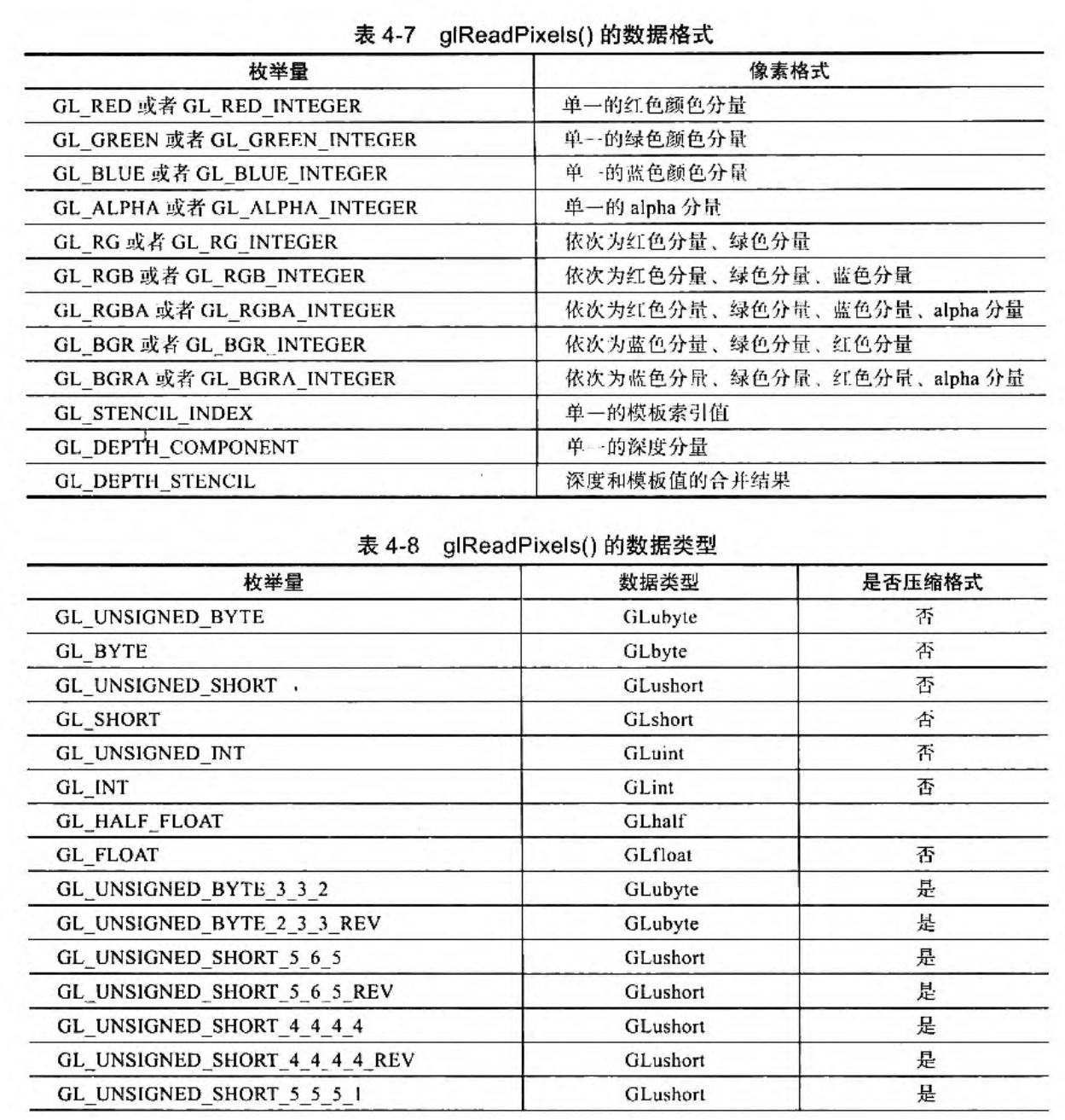
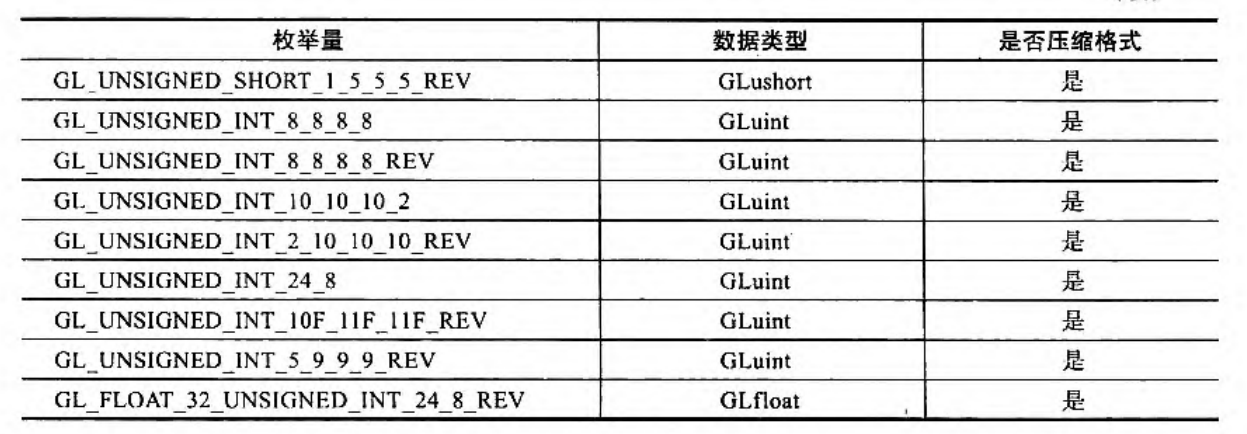
- 将像素数据从一个范围拷贝到另一个范围
void glBlitNamedFramebuffer(GLuint readFramebuffer,GLuint drawFramebuffer,GLint srcXO,GLint sreYO,GLint srcX1,GLint sreY1,GLint dstX0,GLint dstY0,GLint dstX1, GLint dstY1,GLbitfield mask,GLenum filter);
细分着色器¶
- 用于细分图形网格并动态计算细节
- 细分可以根据距离、视角或其他因素动态进行。
- 在细分后的每个小面片上执行额外的计算,可以实现更精细的渲染效果
- 细分着色器允许根据视角和需要来决定细分的程度,可以在接近视点的地方细分更多,而远离视点的地方保持较低的细分,从而减少计算量和内存消耗。
- 分成两个主要阶段
- 细分控制着色器:负责决定每个图形面要细分成多少个子面片,并计算出每个控制点的信息。(接受输入的顶点数据,根据规则决定如何细分,输出细分登记以及细分信息)
- 细分评估着色器:负责在细分后的子面片上计算顶点的最终位置和属性。(在细分后的子面片上进行计算,评估顶点的位置、法线等信息,进行插值计算得到最终属性)
面片¶
- 细分过程只会处理面片这一种图元
- 通常用于表示一个由多个顶点构成的图形单元,在细分渲染管线中,面片是需要进行细分的基本单位。面片的形状和类型可以根据不同的渲染算法和渲染目标而有所不同。
- 分类:三角形面片;四边形面片;曲面面片
- 面片本质上就是传递给着色器的顶点列表,使用面片绘制时还需要告诉 opengl 定点数组中构成一个面片的顶点数目
void glPatchParameteri(GLenum pname,GLint value);- pname 为
GL_PATCH_VERTICESGLfloat vertices [][2]= {-0.75,-0.25},{-0.25,-0.25},{-0.25,0.25},{-0.75,0.25},{0.25,-0.25),{0.75,-0.25},{0.75,0.25},{0.25,0.25} ]: glBindvertexArray(VAO): glBindBuffer (GL_ARRAY_BUFFER,VBO); glBufferData(GL_ARRAY_BUFFER,sizaof(vertices),vertices, GL_STATIC_DRAW): glVertexAttribPointer (vPos,2,GL_FLOAT,GL_FALSE,0,BUFFER_OFFSET(0)): glPatchParameteri (GL_PATCH_VERTICES,4); glDrawArrays (GL_PATCHES,0,8):
- pname 为
细分控制着色器¶
- 内置数组
gl_in即该棉片对应的顶点坐标(数目等于之前设置的) - 细分控制器生成的顶点列表在
gl_out- 通过布局限定
layout (vertices = 16) out可以设置输出顶点gl_out的顶点数目 (这样来设置gl_PatchVerticesOut) gl_InvocationID为当前处理的输出顶点(gl_out中的下标)
- 通过布局限定
- 定点的数据结构
- 示例:直接一对一传送:
#version 420 core layout (vertices 4)out; void main() { gl_out [gl_InvocationID].gl_Position gl_in[gl_InvocationID].gl_Position; //然后设置细分的层级 }z - 外侧细分层级:控制面片边界的细分,边上的顶点数由外侧层级决定。它影响的是面片的轮廓。(对于四边形来说 4 个值分别表示四条边,值越大表示细分越多,生成顶点越多)
float outerLevels[4] = {4.0, 4.0, 4.0, 4.0}; - 内侧细分层级:控制面片内部的细分,决定了内部细分网格的密度,影响的是面片的内部结构。(由两个值,分别对应水平方向的细分和垂直方向的细分
InnerTessLevel[1]) 
gl TessLevelouter [0]=2.0: gl_TessLevelouter [1]=3.0; g1_TessLevelOuter [2]=2.0 gl_TessLevelouter [3]=5.0; gl_TessLevelInner[0]=3.0; g1_TessLevelInner [1]=4.0;- 也可以通过
void glPatchParameterfv(GLenum pname,const GLfloat*values):在着色器外进行设置

细分计算着色器¶
- 设置图元生成域:指的是控制面片如何根据细分等级生成更细的顶点网格。细分计算着色器需要知道这些控制点如何被细分,并根据设置的细分层级进行插值,从而生成最终的顶点。
- 设置生成图元的面朝向
- 设置细分坐标的间隔
- 更多的细分计算着色器 layout 选项
- 设置顶点的位置
- 通常使用
gl_TessCoord来获取细分坐标, 用于表示细分后的顶点在面片内的插值位置(相对位置)gl_Position = (1.0 - gl_TessCoord.x - gl_TessCoord.y) * gl_in[0].gl_Position + gl_TessCoord.x * gl_in[1].gl_Position + gl_TessCoord.y * gl_in[2].gl_Position;
- 通常使用
- 细分计算着色器的变量


示例¶
#version 330 core
layout (vertices = 3) out; // 指定每个面片有 3 个顶点(用于三角形)
in vec3 aPos[]; // 输入的顶点
// 输出顶点数据
out vec3 tcsPosition[];
void main()
{
// 将输入的顶点位置传递给细分计算着色器
for (int i = 0; i < 3; ++i)
{
tcsPosition[i] = aPos[i];
}
// 设置细分等级,越大细分的越细
if (gl_InvocationID == 0)
{
gl_TessLevelOuter[0] = 4.0; // 外侧的细分等级(u方向)
gl_TessLevelOuter[1] = 4.0; // 外侧的细分等级(v方向)
gl_TessLevelOuter[2] = 4.0; // 外侧的细分等级(w方向)
gl_TessLevelInner[0] = 4.0; // 内侧的细分等级
}
}
#version 330 core
layout (triangles, equal_spacing, ccw) in; // 指定细分类型为三角形,使用均匀细分,并且逆时针方向
in vec3 tcsPosition[]; // 输入的细分控制点
out vec4 fragColor; // 输出的颜色
void main()
{
// 使用细分坐标计算每个顶点的位置
vec3 position = (1.0 - gl_TessCoord.x - gl_TessCoord.y) * tcsPosition[0] +
gl_TessCoord.x * tcsPosition[1] +
gl_TessCoord.y * tcsPosition[2];
// 设置最终的顶点位置
gl_Position = vec4(position, 1.0);
// 为了展示,我们将输出一个简单的颜色
fragColor = vec4(1.0 - gl_TessCoord.x, gl_TessCoord.y, 0.0, 1.0); // 基于细分坐标生成颜色
}
几何着色器¶
- 图元是图形渲染管线中绘制几何图形的基本单位
- 点
- 线
-
三角形
-
介于顶点着色器和片段着色器之间
- 给予输入的图元生成新的图元或修改现有的图元
- 比如将点转化为边
- 可以实现很多效果:
- 面位移实现爆破效果
- 显示所有面的法线等等
几何着色器的输入输出¶
#version 330 core
layout (points) in;//输入的图元
layout (line_strip, max_vertices = 2) out;//输出的图元
void main() {
//设置第一个点
gl_Position = gl_in[0].gl_Position + vec4(-0.1, 0.0, 0.0, 0.0);
EmitVertex();//发射(即gl_position中的向量会被添加到图元中)
//设置第二个点
gl_Position = gl_in[0].gl_Position + vec4( 0.1, 0.0, 0.0, 0.0);
EmitVertex();//发射
//图元结束
EndPrimitive();
}
- 这里的 in 和 out 不是具体的变量,而是类型,用于指定集合着色器处理图元的方式
- 几何着色器接受的图元输入
points:绘制 GL_POINTS 图元时(1)。lines:绘制 GL_LINES 或 GL_LINE_STRIP 时(2)lines_adjacency:GL_LINES_ADJACENCY 或 GL_LINE_STRIP_ADJACENCY(4)triangles:GL_TRIANGLES、GL_TRIANGLE_STRIP 或 GL_TRIANGLE_FAN(3)-
triangles_adjacency:GL_TRIANGLES_ADJACENCY 或 GL_TRIANGLE_STRIP_ADJACENCY(6) -
如果定义了几何着色器,那么要手动将顶点着色器的 out 传递给片段着色器
-
通过 glsl 内建变量
gl_in[]获取数据in gl_Vertex { vec4 gl_Position; float gl_PointSize; float gl_ClipDistance[]; } gl_in[]; -
对于从顶点着色器传递的数据 in 也要写成数组形式
-
编译和链接几何着色器
geometryShader = glCreateShader(GL_GEOMETRY_SHADER); glShaderSource(geometryShader, 1, &gShaderCode, NULL); glCompileShader(geometryShader); ... glAttachShader(program, geometryShader); glLinkProgram(program); -
在调用
EmitVertex()时,几何着色器会将当前设置的顶点属性(如gl_Position和自定义的out变量)作为一个新的顶点,保存到输出缓冲区中。 - 也就是说 out 变量也会进行传递
fColor = gs_in[0].color;
gl_Position = position + vec4(-0.2, -0.2, 0.0, 0.0); // 1:左下
EmitVertex();
gl_Position = position + vec4( 0.2, -0.2, 0.0, 0.0); // 2:右下
EmitVertex();
gl_Position = position + vec4(-0.2, 0.2, 0.0, 0.0); // 3:左上
EmitVertex();
gl_Position = position + vec4( 0.2, 0.2, 0.0, 0.0); // 4:右上
EmitVertex();
gl_Position = position + vec4( 0.0, 0.4, 0.0, 0.0); // 5:顶部
fColor = vec3(1.0, 1.0, 1.0);
EmitVertex();
EndPrimitive(); //发送图元,多次创建可以生成多个图元实现几何体扩充
- 利用集合着色器可以实现:
- 几何体裁剪:丢弃部分图元
- 几何体扩充:如在表面生成毛发
几何着色器特殊图元¶
- 邻接图元:
lines_adjacency和triangles_adjacency- 临接表示几何着色器处理一个图元时可以访问与该图元相邻的其他图元的数据,实现生成更加复杂的几何形状

- 如线就包含线的两个端点和前后两个邻接点
transform feedback¶
- 在图形管线的某些阶段直接捕捉顶点数据传输回 GPU 缓冲区,而不再继续经过片元着色器
//预先设置视口 glviewportIndexedf (0,0.of,0.of,wot,hot) glviewportIndexedf (1,wot,0.of,wot,hot); glviewportIndexedf(2,0.Of,hot,wot,hot); glviewportTndexedf(3,wot,hot,wot,hot); //创建缓冲区 GLuint feedbackBuffer; glGenBuffers(1, &feedbackBuffer); glBindBuffer(GL_ARRAY_BUFFER, feedbackBuffer); glBufferData(GL_ARRAY_BUFFER, bufferSize, NULL, GL_DYNAMIC_COPY); //创建反馈对象,用于管理transform feedback GLuint tfObject; glGenTransformFeedbacks(1, &tfObject); //绑定反馈对象 glBindTransformFeedback(GL_TRANSFORM_FEEDBACK, tfObject); glBindBufferBase(GL_TRANSFORM_FEEDBACK_BUFFER, 0, feedbackBuffer); //启用 glBeginTransformFeedback(GL_POINTS); //结束 glEndTransformFeedback(); //读取数据 glBindBuffer(GL_ARRAY_BUFFER, feedbackBuffer); GLfloat* data = (GLfloat*)glMapBuffer(GL_ARRAY_BUFFER, GL_READ_ONLY); // 处理数据 glUnmapBuffer(GL_ARRAY_BUFFER);
多视口与分层渲染¶
视口索引¶
gl_ViewportIndex允许渲染器将数据输出到特定的视口或渲染层,通过设置这个值可以指定每个片元所属的视口- 在几何着色器中将输入顶点数据渲染到不同的视口中
- 即通过几何体扩充并对一个几何体采取不同的变换
// 几何着色器示例 #version 450 core layout (triangles) in; layout (triangle_strip, max_vertices = 3) out; void main() { gl_Position = gl_in[0].gl_Position; gl_ViewportIndex = 0; // 输出到第一个视口 EmitVertex(); // 生成顶点 gl_Position = gl_in[1].gl_Position; gl_ViewportIndex = 1; // 输出到第二个视口 EmitVertex(); gl_Position = gl_in[2].gl_Position; gl_ViewportIndex = 0; // 输出到第一个视口 EmitVertex(); EndPrimitive(); }
分层渲染¶
gl_Layer来制定输出图元的渲染层- 将不同的图元渲染到多个层,从而实现复杂的图形效果。可以通过几何着色器实现将图元渲染到不同的层
#version 330 core layout(triangles) in; // 输入图元为三角形 layout(triangle_strip, max_vertices = 3) out; // 输出为三角形带 in vec3 fragPos[]; // 输入的顶点位置(来自顶点着色器) out vec4 FragColor; // 输出的颜色 void main() { // 设置图元的渲染层 if (fragPos[0].z < 0.0) { gl_Layer = 0; // 如果深度小于0,渲染到层0 } else { gl_Layer = 1; // 否则,渲染到层1 } // 输出顶点 for (int i = 0; i < 3; i++) { gl_Position = gl_in[i].gl_Position; FragColor = vec4(fragPos[i], 1.0); // 使用位置作为颜色 EmitVertex(); } EndPrimitive(); } - 想实现多层缓冲,还要创建支持多层缓冲的帧缓冲颜色附件,比如向颜色附件管理数组纹理,用于不同的层
GLuint framebuffer; glGenFramebuffers(1, &framebuffer); glBindFramebuffer(GL_FRAMEBUFFER, framebuffer); // 假设你需要创建一个有 3 层的帧缓冲 GLuint texture[3]; glGenTextures(3, texture); // 创建 3 个纹理对象 for (int i = 0; i < 3; ++i) { glBindTexture(GL_TEXTURE_2D_ARRAY, texture[i]); glTexImage3D(GL_TEXTURE_2D_ARRAY, 0, GL_RGBA, width, height, 3, 0, GL_RGBA, GL_UNSIGNED_BYTE, nullptr); glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_MAG_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE); glTexParameteri(GL_TEXTURE_2D_ARRAY, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE); } glFramebufferTexture(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, texture[0], 0); glFramebufferTexture(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT1, texture[1], 0); glFramebufferTexture(GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT2, texture[2], 0); // 设置帧缓冲的附件 GLuint attachments[3] = { GL_COLOR_ATTACHMENT0, GL_COLOR_ATTACHMENT1, GL_COLOR_ATTACHMENT2 }; glDrawBuffers(3, attachments); // 检查帧缓冲是否完整 if (glCheckFramebufferStatus(GL_FRAMEBUFFER) != GL_FRAMEBUFFER_COMPLETE) { std::cout << "Framebuffer is not complete!" << std::endl; }
光照¶
颜色¶
- 将光源的颜色与物体的颜色相乘得到物体反射的颜色
- 物体的颜色就是物体从光源反射的颜色分量的大小,由物体自身的性质和光源决定
//白色光源
glm::vec3 lightColor(1.0f, 1.0f, 1.0f);
glm::vec3 toyColor(1.0f, 0.5f, 0.31f);
glm::vec3 result = lightColor * toyColor; // = (1.0f, 0.5f, 0.31f);
//绿色光源
glm::vec3 lightColor(0.0f, 1.0f, 0.0f);
glm::vec3 toyColor(1.0f, 0.5f, 0.31f);
glm::vec3 result = lightColor * toyColor; // = (0.0f, 0.5f, 0.0f);
- 为了实现灯光和普通物体不同的渲染模式,可以使用两套着色器程序(比如灯光固定为白色)
基础光照——phong模型¶
- 模型中由三个分量组成:环境光、漫反射、镜面反射
环境光¶
- 简单的将一个很小的常量颜色添加到物体片段的最终颜色
void main()
{
float ambientStrength = 0.1;
vec3 ambient = ambientStrength * lightColor;
vec3 result = ambient * objectColor;
FragColor = vec4(result, 1.0);
}
漫反射¶
- 光源与平面的夹角决定漫反射的强度
vec3 norm = normalize(Normal);//发现
vec3 lightDir = normalize(lightPos - FragPos);//根据输入的光源位置和着色点计算出入射光线向量
float diff = max(dot(norm, lightDir), 0.0);//计算夹角
vec3 diffuse = diff * lightColor;
FragPos通过输入顶点着色器的点经过模型变换得到(世界坐标系,为了方便的与灯光等计算)
法向量与变换¶
- 由于法向量没有齐次坐标,因此不会进行平移操作,只能缩放和旋转
- 如果模型进行了不等比缩放,法向量可能不再垂直与表面,也就是说通过这样的模型矩阵不能得到正确的法向量
- 因此通过特殊的法线矩阵(模型矩阵左上角3x3部分的逆矩阵的转置矩阵)来进行变换更为恰当
Normal = mat3(transpose(inverse(model))) * aNormal;- 矩阵求逆对着色器开销较大,因此在CPU进行计算之后求逆更为恰当
镜面反射¶
- 由表面发现,光源,摄像机位置共同决定
float specularStrength = 0.5;
vec3 viewDir = normalize(viewPos - FragPos);
vec3 reflectDir = reflect(-lightDir, norm);
float spec = pow(max(dot(viewDir, reflectDir), 0.0), 32);
vec3 specular = specularStrength * spec * lightColor;
代码示例¶
//FragPos = vec3(model * vec4(aPos, 1.0));
void main()
{
//环境光
float ambientStrength = 0.1;
vec3 ambient = ambientStrength * lightColor;
//漫反射
vec3 norm = normalize(Normal);
vec3 lightDir = normalize(lightPos - FragPos);
float diff = max(dot(norm, lightDir), 0.0);
vec3 diffuse = diff * lightColor;
//镜面反射
float specularStrength = 0.5;
vec3 viewDir = normalize(viewPos - FragPos);
vec3 reflectDir = reflect(-lightDir, norm);
float spec = pow(max(dot(viewDir, reflectDir), 0.0), 32);
vec3 specular = specularStrength * spec * lightColor;
//汇总
vec3 result = (ambient + diffuse + specular) * objectColor;
FragColor = vec4(result, 1.0);
}
材质¶
- 创建一个材质结构,将其作为参数进行传递
struct Material {
vec3 ambient;
vec3 diffuse;
vec3 specular;
float shininess;
};
uniform Material material;
- 分别表示环境光照、漫反射光照、镜面光照、反光度
void main()
{
// 环境光
vec3 ambient = lightColor * material.ambient;
// 漫反射
vec3 norm = normalize(Normal);
vec3 lightDir = normalize(lightPos - FragPos);
float diff = max(dot(norm, lightDir), 0.0);
vec3 diffuse = lightColor * (diff * material.diffuse);
// 镜面光
vec3 viewDir = normalize(viewPos - FragPos);
vec3 reflectDir = reflect(-lightDir, norm);
float spec = pow(max(dot(viewDir, reflectDir), 0.0), material.shininess);
vec3 specular = lightColor * (spec * material.specular);
vec3 result = ambient + diffuse + specular;
FragColor = vec4(result, 1.0);
}
//传递数据
lightingShader.setVec3("material.ambient", 1.0f, 0.5f, 0.31f);
lightingShader.setVec3("material.diffuse", 1.0f, 0.5f, 0.31f);
lightingShader.setVec3("material.specular", 0.5f, 0.5f, 0.5f);
lightingShader.setFloat("material.shininess", 32.0f);
光照¶
- 完全在每一个片元着色器中计算光照开销较大,可以在顶点着色器中进行部分计算,片元着色器使用插值的数据
- 像素着色->点着色
光照属性¶
- 通过光照属性影响显示的样式
struct Light {
vec3 position;
vec3 ambient;
vec3 diffuse;
vec3 specular;
};
- 这样计算时就还需要乘以光源属性
vec3 ambient = light.ambient * material.ambient;
vec3 diffuse = light.diffuse * (diff * material.diffuse);
vec3 specular = light.specular * (spec * material.specular);
光照贴图¶
- 漫反射贴图
- 希望对不同的物体片段跟别设置漫反射颜色
- 使用贴图来存储更为详细的漫反射量
struct Material {
sampler2D diffuse;
sampler2D specular;
float shininess;
};
in vec2 TexCoords;
//环境光和漫反射都进行设置
vec3 diffuse = light.diffuse * diff * vec3(texture(material.diffuse, TexCoords));
vec3 ambient = light.ambient * vec3(texture(material.diffuse, TexCoords));
- 类似的也可以使用贴图来控制镜面反射
投光物¶
- 投光物就是将光投射到物体的光源
平行光¶
- 无线远的光源的光通常可以视为平行光
- 物体与光源的相对位置不重要,每个物体的光照计算方式是类似的
- 片段着色器计算时直接使用固定的方向向量进行计算
点光源¶
- 方向各异,向四周发射
- 照亮光源附近的区域,存在距离衰减
- 计算公式\(F_{att}=\frac{1.0}{K_c+K_l*d+K_q*d^2}\)
- 实现这样的衰减曲线:
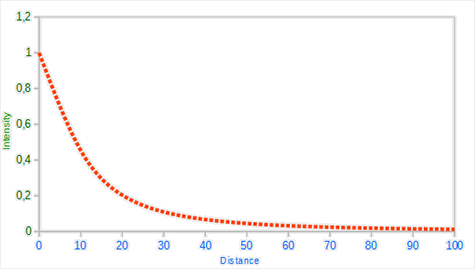
- 着色器代码
struct Light {
vec3 position;
vec3 ambient;
vec3 diffuse;
vec3 specular;
float constant;
float linear;
float quadratic;
};
float distance = length(light.position - FragPos);
float attenuation = 1.0 / (light.constant + light.linear * distance + light.quadratic * (distance * distance));
聚光¶
- 向特定方向发射光线
- 一个坐标,一个方向和一个切光角
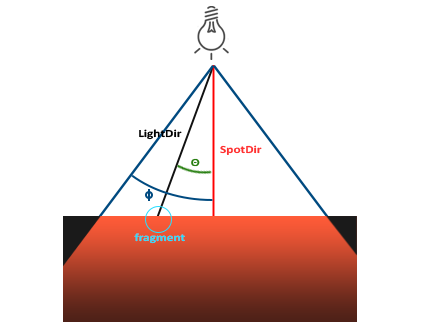
- 通过比较一点与光源连线和聚光方向的夹角和切光角来判断光照的强弱
struct Light {
vec3 position;
vec3 direction;
float cutOff;
...
};
float theta = dot(lightDir, normalize(-light.direction));
if(theta > light.cutOff)
{
// 执行光照计算
}
else // 否则,使用环境光,让场景在聚光之外时不至于完全黑暗
color = vec4(light.ambient * vec3(texture(material.diffuse, TexCoords)), 1.0);
- 添加边缘羽化
- 除了完全照亮的内圆锥额外添加一个外圆锥
- 光从内圆锥逐渐减弱直到外圆锥边界
- $I=\frac{\theta-\gamma}\epsilon $即夹角减去内角除以外角和内角的差值
float theta = dot(lightDir, normalize(-light.direction));
float epsilon = light.cutOff - light.outerCutOff;
float intensity = clamp((theta - light.outerCutOff) / epsilon, 0.0, 1.0);
高级光照¶
半球光照¶
- 在复杂的场景中,特别是没有直接光源的情况下,物体的表面往往会接收到来自多个方向的光照,半球光照通过模拟这种多方向的光源来提供更自然的环境光效果。
- 由上半球和下半球两个虚拟部分组成
- 上半球光照:表示来自大气或环境的直接光源(如阳光、天空光等)。这些光照通常为明亮、柔和的光。
- 下半球光照:表示由地面或周围物体反射的光照。这部分光照通常较为暗淡,且根据反射表面和角度不同,可能会具有不同的强度和颜色。
- 混合公式
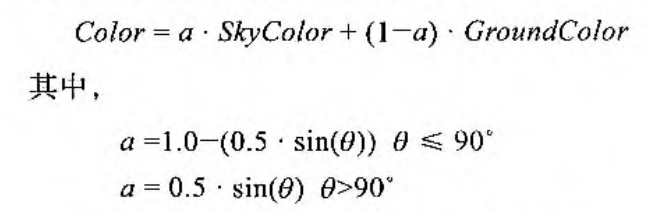
基于图像的光照¶
- 基本步骤
- 使用一个光探头(Light probe, 比如反射球) 来捕获(比如 photograph) 发生在一个真实世界中场景的光照。所捕获的全方位、高动态范围图像经常叫做一个光探头图像。
- 使用光探头图像来创建周围环境的图像(比如,一个环境贴图)。
- 在周围环境里面放置要渲染的合成的物体。
- 使用在第二步创建代表的周围环境来渲染合成的物体。
- 即将场景预先烘焙到材质,用于后面的光照计算
球面光照¶
- 使用球面函数来计算漫反射光,在没有运行时基于光探头图像的内容进行处理
Gamma 矫正¶
- Gamma 用于描述非线性颜色空间中的输入与输出关系(如亮度)
- \(V_{{\mathrm{out}}}=V_{{\mathrm{in}}}^{{\frac1\gamma}}\)
- Gamma = 1.0:线性关系,输入值与输出值成正比。
- Gamma > 1.0:输出值的暗部被压缩,高光部分更明亮。
- Gamma < 1.0:输出值的暗部被拉升,图像整体更亮。
- 物理亮度:物理亮度是指光源发射光子的数量,与光子数量成正比。
- 线性的,比如从亮度值 0.10.10.1 增加到 0.20.20.2,光子数量翻倍。
- 人眼感知亮度:人眼对亮度的感知是非线性的,对暗部亮度变化更敏感,对高亮区域的变化则不敏感。
- 从亮度 0.10.10.1 增加到 0.20.20.2,我们会感受到亮度翻倍。
- 但从亮度 0.40.40.4 增加到 0.80.80.8,感知到的变化程度与前者类似。
- 显示器亮度通常是指数映射(2.2)而不是线性映射(早期技术限制,现在为了兼容 sRGB)
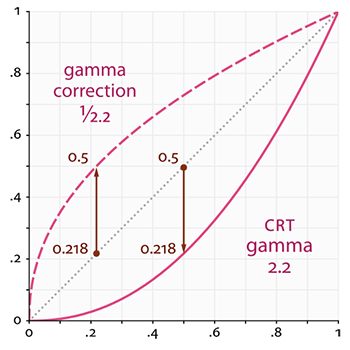
- 因为显示器指数调整亮度,会导致中间值被压暗,因此通过 gamma 矫正进行修正
-
加上个
1/2.2次幂,与显示器的指数中和 -
使用自带的 gamma 矫正
glEnable(GL_FRAMEBUFFER_SRGB); - 手动在着色器中进行矫正
void main()
{
// do super fancy lighting
[...]
// apply gamma correction
float gamma = 2.2;
fragColor.rgb = pow(fragColor.rgb, vec3(1.0/gamma));
}
- 要注意的事对于 sRGB 空间中的纹理不需要再次进行 gamma 矫正
- 可以在创建时指出是 SRGB 纹理
glTexImage2D(GL_TEXTURE_2D, 0, GL_SRGB, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, image);这样 opengl 就会自动把颜色矫正到线性空间 - 有透明通道则要设置为:
GL_SRGB_ALPHA
光线衰减¶
- 物理上光照的衰减和光源的距离的平方成反比
- 但是由于 gamma 矫正,双曲线衰减
float attenuation = 1.0 / distance;在矫正后为 \((1.0/distance^2)^{2.2}\) 更加额规则
阴影¶
平行光阴影¶
- 与深度缓冲类似,只是从光源出发
- 对于平行光还要使用正交投影
- 使用帧缓冲渲染到深度纹理贴图供之后使用
#version 330 core
layout (location = 0) in vec3 position;
layout (location = 1) in vec3 normal;
layout (location = 2) in vec2 texCoords;
out vec2 TexCoords;
out VS_OUT {
vec3 FragPos;
vec3 Normal;
vec2 TexCoords;
vec4 FragPosLightSpace;
} vs_out;
uniform mat4 projection;
uniform mat4 view;
uniform mat4 model;
uniform mat4 lightSpaceMatrix;
void main()
{
gl_Position = projection * view * model * vec4(position, 1.0f);
vs_out.FragPos = vec3(model * vec4(position, 1.0));
vs_out.Normal = transpose(inverse(mat3(model))) * normal;
vs_out.TexCoords = texCoords;
//根据传入的变换矩阵得到光空间下点的对应坐标
vs_out.FragPosLightSpace = lightSpaceMatrix * vec4(vs_out.FragPos, 1.0);
}
- 在片段着色器中,如果根据深度判断一个点在阴影中,则将漫反射和镜面反射的值乘以 0
#version 330 core
out vec4 FragColor;
in VS_OUT {
vec3 FragPos;
vec3 Normal;
vec2 TexCoords;
vec4 FragPosLightSpace;
} fs_in;
uniform sampler2D diffuseTexture;
uniform sampler2D shadowMap;
uniform vec3 lightPos;
uniform vec3 viewPos;
float ShadowCalculation(vec4 fragPosLightSpace)
{
[...]
}
void main()
{
vec3 color = texture(diffuseTexture, fs_in.TexCoords).rgb;
vec3 normal = normalize(fs_in.Normal);
vec3 lightColor = vec3(1.0);
// Ambient
vec3 ambient = 0.15 * color;
// Diffuse
vec3 lightDir = normalize(lightPos - fs_in.FragPos);
float diff = max(dot(lightDir, normal), 0.0);
vec3 diffuse = diff * lightColor;
// Specular
vec3 viewDir = normalize(viewPos - fs_in.FragPos);
vec3 reflectDir = reflect(-lightDir, normal);
float spec = 0.0;
vec3 halfwayDir = normalize(lightDir + viewDir);
spec = pow(max(dot(normal, halfwayDir), 0.0), 64.0);
vec3 specular = spec * lightColor;
// 计算阴影
float shadow = ShadowCalculation(fs_in.FragPosLightSpace);
vec3 lighting = (ambient + (1.0 - shadow) * (diffuse + specular)) * color;
FragColor = vec4(lighting, 1.0f);
}
//shdow的计算
float ShadowCalculation(vec4 fragPosLightSpace)
{
// 执行透视除法
vec3 projCoords = fragPosLightSpace.xyz / fragPosLightSpace.w;
// 变换到[0,1]的范围
projCoords = projCoords * 0.5 + 0.5;
// 取得最近点的深度(使用[0,1]范围下的fragPosLight当坐标)
float closestDepth = texture(shadowMap, projCoords.xy).r;
// 取得当前片段在光源视角下的深度
float currentDepth = projCoords.z;
// 检查当前片段是否在阴影中
float shadow = currentDepth > closestDepth ? 1.0 : 0.0;
return shadow;
}
- 正交投影阴影通常用于平行光;透视投影阴影通常用于点光源和聚光灯
点光源阴影(万向阴影贴图)¶
- 点光源会向各个方向发射光,也就是说阴影可以处于四周,不能像平行光那样使用一张深度贴图
- 使用立方体贴图,存储 6 个面的环境数据、
- 原教程
阴影失真¶
条纹¶
- 阴影失真:出现交替黑线

- 原因:阴影分辨率不足,多个临近片段从深度贴图的同一个值中采样
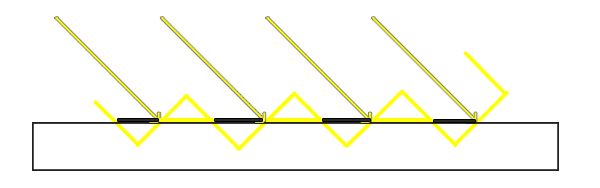
- 解决方法:添加一个偏移小量:防止片段被阴影被错误添加
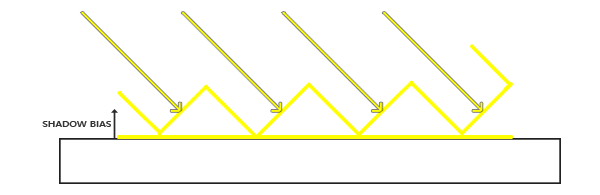
float bias = 0.005;
float shadow = currentDepth - bias > closestDepth ? 1.0 : 0.0;
-
但是由于箱单与对物体的深度进行了平移,可能造成阴影相对实际物体位置的偏移(称为悬浮)
-
另一种解决失真的方式是使用 peter panning 即在渲染深度贴图时使用正面剔除(这样就能使得条纹等渲染错误不会显现出来)
- 但是只适用于不会对外开口的实体物体(如完整的正方体)
超出边界的阴影¶
- 超出深度贴图的区域由于距离超过阈值,会全部处于阴影之中
- 可以将深度贴图中超出范围的深度设置为 1.0 (通过设置环绕方式实现)
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_BORDER);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_BORDER);
GLfloat borderColor[] = { 1.0, 1.0, 1.0, 1.0 };
glTexParameterfv(GL_TEXTURE_2D, GL_TEXTURE_BORDER_COLOR, borderColor);
- 不过处于远平面外的部分要单独丢弃(大于 1 了)
float ShadowCalculation(vec4 fragPosLightSpace)
{
[...]
if(projCoords.z > 1.0)
shadow = 0.0;
return shadow;
}
PCF¶

- 阴影的边缘可能存在较多的锯齿:因为深度贴图有一个固定的分辨率,多个片段对应于一个纹理像素。结果就是多个片段会从深度贴图的同一个深度值进行采样,这几个片段便得到的是同一个阴影,这就会产生锯齿边。
- 可以通过增大阴影纹理的分辨率来改善
- 也可以通过 pcf 来实现更柔和的阴影:核心思想是从深度贴图中多次采样,每一次采样的纹理坐标都稍有不同。每个独立的样本可能在也可能不再阴影中。所有的次生结果接着结合在一起,进行平均化,我们就得到了柔和阴影。
- 如采集九宫格
float shadow = 0.0;
vec2 texelSize = 1.0 / textureSize(shadowMap, 0);
for(int x = -1; x <= 1; ++x)
{
for(int y = -1; y <= 1; ++y)
{
float pcfDepth = texture(shadowMap, projCoords.xy + vec2(x, y) * texelSize).r;
shadow += currentDepth - bias > pcfDepth ? 1.0 : 0.0;
}
}
shadow /= 9.0;
HDR¶
- 解决:多个两光源叠加使得亮度值超过了 1.0,导致高光混成一片难以分辨
- hdr 允许片段的颜色超过 1,最终在映射到 0~1 显示在显示器上(HDR->LDR色调映射)
- 亮的东西可以变得非常亮,暗的东西可以变得非常暗,而且充满细节。
-
HDR 渲染的关键就是指如何将 HDR 转换到 LDR
-
使用浮点帧缓冲,即用
GL_RGB16F(GL_RGB32F)替代GL_RGB,GL_RGB16F为半精度浮点数,可表达的范围比GL_RGB大得多
glBindTexture(GL_TEXTURE_2D, colorBuffer);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGB16F, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGB, GL_FLOAT, NULL);
色调映射¶
- 尽可能小损失的准换浮点颜色值到 LDR 范围
- 最简单的办法是进行线性映射
void main()
{
const float gamma = 2.2;
vec3 hdrColor = texture(hdrBuffer, TexCoords).rgb;
// Reinhard色调映射
vec3 mapped = hdrColor / (hdrColor + vec3(1.0));
color = vec4(mapped, 1.0);
}
- 曝光调色算法:调整曝光值可以调整 hdr 渲染的结果
uniform float exposure;
void main()
{
const float gamma = 2.2;
vec3 hdrColor = texture(hdrBuffer, TexCoords).rgb;
// 曝光色调映射
vec3 mapped = vec3(1.0) - exp(-hdrColor * exposure);
color = vec4(mapped, 1.0);
}
泛光¶
- 通过让明亮的光源(如灯)产生泛光效果,来让用户产生错觉,感觉区域很亮
- 实现思路:提取超过一定亮度阈值的纹理进行模糊处理
-
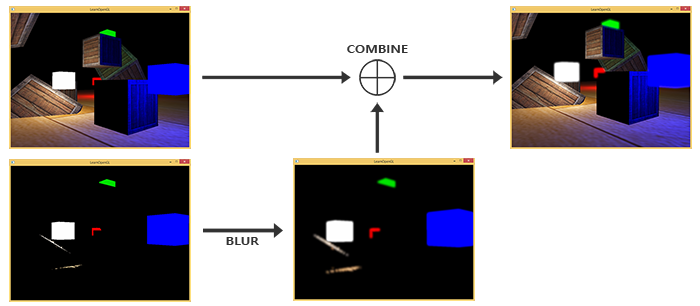
多渲染目标 MRT¶
- 允许像素着色器的多个输出变量同时写入帧缓冲中的不同颜色缓冲区
//为帧缓冲附加两个颜色附件
GLuint hdrFBO;
glGenFramebuffers(1, &hdrFBO);
glBindFramebuffer(GL_FRAMEBUFFER, hdrFBO);
GLuint colorBuffers[2];
glGenTextures(2, colorBuffers);
for (GLuint i = 0; i < 2; i++)
{
glBindTexture(GL_TEXTURE_2D, colorBuffers[i]);
glTexImage2D(
GL_TEXTURE_2D, 0, GL_RGB16F, SCR_WIDTH, SCR_HEIGHT, 0, GL_RGB, GL_FLOAT, NULL
);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glFramebufferTexture2D(
GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0 + i, GL_TEXTURE_2D, colorBuffers[i], 0
);
}
//当前要渲染到哪些附件
GLuint attachments[2] = { GL_COLOR_ATTACHMENT0, GL_COLOR_ATTACHMENT1 };
glDrawBuffers(2, attachments);
//着色器中输出
#version 330 core
layout (location = 0) out vec4 FragColor;
layout (location = 1) out vec4 BrightColor;
void main()
{
// 普通光照计算
vec3 lighting = ...; // 你的光照计算代码
FragColor = vec4(lighting, 1.0f);
// 计算亮度
float brightness = dot(FragColor.rgb, vec3(0.2126, 0.7152, 0.0722)); // 转灰度
if (brightness > 1.0) // 超过阈值
BrightColor = vec4(FragColor.rgb, 1.0);
else
BrightColor = vec4(0.0);
}
高斯模糊¶
- 高斯模糊也是对一定范围的点做平均,不过是加权平均,中心权值大,四周小
- 对于面上的高斯模糊,可以对不同方向分别进行,这样复杂度就从 \(n^2\) 到 \(2n\)
-
对每个点进行如上操作最后将结果叠加
-
乒乓球渲染:两个帧缓冲对象交替渲染:每次渲染将一个帧缓冲的颜色缓冲作为输入纹理,输出到另一个帧缓冲的颜色缓冲。
- 第一步:将
FBO1的颜色缓冲作为输入,渲染到FBO2。 - 第二步:将
FBO2的颜色缓冲作为输入,渲染到FBO1。 - 对于高斯模糊
- 第一步:水平模糊,使用
FBO1的颜色缓冲作为输入纹理,渲染到FBO2,应用水平模糊的着色器。 - 第二步:垂直模糊,使用
FBO2的颜色缓冲作为输入纹理,渲染到FBO1,应用垂直模糊的着色器。 - 根据需求迭代多次,增强模糊效果。
- 高斯模糊的片段着色器
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
uniform sampler2D image;
uniform bool horizontal;
uniform float weight[5] = float[] (0.227027, 0.1945946, 0.1216216, 0.054054, 0.016216);
void main()
{
vec2 tex_offset = 1.0 / textureSize(image, 0); // gets size of single texel
vec3 result = texture(image, TexCoords).rgb * weight[0]; // current fragment's contribution
if(horizontal)
{
for(int i = 1; i < 5; ++i)
{
result += texture(image, TexCoords + vec2(tex_offset.x * i, 0.0)).rgb * weight[i];
result += texture(image, TexCoords - vec2(tex_offset.x * i, 0.0)).rgb * weight[i];
}
}
else
{
for(int i = 1; i < 5; ++i)
{
result += texture(image, TexCoords + vec2(0.0, tex_offset.y * i)).rgb * weight[i];
result += texture(image, TexCoords - vec2(0.0, tex_offset.y * i)).rgb * weight[i];
}
}
FragColor = vec4(result, 1.0);
}
- 高斯模糊就通过乒乓球渲染
延迟着色法¶
-
正向渲染:渲染每个物体的每个片段时都需要去遍历所有灯光,复杂度及哦啊高
-
延迟着色法用于优化有大量光源的场景的渲染:
- 第一阶段渲染场景并获取几何信息,生成G 缓冲(纹理),包含位置、法线、漫反射颜色、镜面反射属性等
- 第二个阶段使用数据显存逐灯光进行计算,这样只计算可见的像素,减少了冗余计算
- 问题:G 缓冲会占用显存空间,并且对透明物体支持差
- 主要用于场景较大动态灯光丰富的场景
- 第一阶段完成后,由于深度测试,其实 G 缓冲中都是需要显示的像素;因此延迟着色时直接读取 G 缓冲中存储的信息并进行渲染即可
延迟渲染的光体积优化、¶
- 在传统延迟渲染中,每个像素都会计算所有光源对其的光照贡献,不论光源是否显著影响该像素
- 光体积: 根据光源的衰减方程,确定光的衰减到“黑暗”状态时的最大距离(光体积半径)。
- 只有在像素位于光体积内时才计算该光源对该像素的光照贡献,跳过体积外的光源。

- 具体方法:
- 渲染一个代表光体积的球体,其位置为光源位置,大小根据光体积半径缩放。
- 只有球体投影到屏幕上的像素会触发光照计算,大大减少了无关像素的计算。
- 每个光源的光照结果独立计算,并最终叠加到帧缓冲中。
SSAO¶
- 环境光遮蔽 AO:通过将褶皱、孔洞和非常靠近的墙面变暗的方法近似模拟出间接光照。这些区域很大程度上是被周围的几何体遮蔽的,光线会很难流失,所以这些地方看起来会更暗一些。

- SSAO 使用了屏幕空间场景的深度而不是真实的几何体数据来确定遮蔽量, 会根据周边深度值估计一个遮蔽因子用来减少或者抵消片段的环境光照分量。
- 计算遮蔽因子
- 以像素为中心点的一个半球形(结合像素所在平面(法向半球体)),在这个范围内进行采样
-
-
- 如果采样点比当前像素更靠近摄像机(即深度值较小),则认为这个点对环境光有遮挡作用。
- 遮蔽因子会根据采样点的距离和角度进行加权。

- 此外还要对生成的 AO 图进行平滑处理,如使用高斯模糊
内存¶
- 除了图像数据之外,纹理也可以用来存储通用数据(如计算结果、表格、物理模拟中的状态数据等),这些数据可以在 GPU 并行处理的场景中方便的进行访问
计算着色器¶
- 用于进行高并行的通用计算任务,如物理模拟、图像处理、粒子系统等
- 使用 GPU 来进行高效的大规模并行计算
- 与顶点、片段等传统的渲染阶段无关,独立于渲染管线。
- 使用 glsl 编写
PBR¶
基于物理的着色: 基于微表面模型 能量守恒 基于物理的 BRDF
理论¶
采用线性颜色空间和HDR在PBR渲染管线中非常重要。如果没有这些操作,几乎是不可能正确地捕获到因光照强度变化的细节,这最终会导致你的计算变得不正确,在视觉上看上去非常不自然。
微表面模型¶
- 微平面越光滑(出射光线广德防线更多的符合镜面反射),镜面反射的效果就越锐利,可以用一个介于0~1的粗糙度参数表示微平面的情况

渲染方程¶
- \(L_o(x,\omega_o)=L_e(x,\omega_o)+\int_\Omega f_r(x,\omega_i,\omega_o)L_i(x,\omega_i)(\omega_i\cdot n)d\omega_i\)


BRDF¶
- 接受入射方向、出射方向、平面法线和一个表示微平面粗糙成都的参数作为函数的输入参数
- 分成漫反射(折射)和镜面反射连个部分 \(f_r=k_df_{lambert}+k_sf_{cook-torrance}\)
- \(f_{lambert}=\frac c\pi\) 表面颜色除以 phi 进行标准化
- 计算镜面反射 \(f_{cook-torrance}=\frac{DFG}{4(\omega_o\cdot n)(\omega_i\cdot n)}\)
- \(L_o(p,\omega_o)=\intop_\Omega(k_d\frac c\pi+k_s\frac{DFG}{4(\omega_o\cdot n)(\omega_i\cdot n)})L_i(p,\omega_i)n\cdot\omega_id\omega_i\)
G几何函数¶
- 描述了微平面自成阴影的属性。当一个平面相对比较粗糙的时候,平面表面上的微平面有可能挡住其他的微平面从而减少表面所反射的光线。
- 近似求得微平面之间相互遮蔽的比率,这种相互遮蔽会损耗光线的能量
- 也是结合材料的粗糙度进行计算,因为粗糙度较高的表面其相互遮蔽的概率就越高
- \(G_{\textit{SchlickGGX}}(n,v,k)=\frac{n\cdot v}{(n\cdot v)(1-k)+k}\)
- 这里的 k 是对粗糙度 a 的重映射 \(\begin{aligned}k_{direct}&=\frac{(\alpha+1)^2}8\\\\k_{IBL}&=\frac{\alpha^2}2\end{aligned}\)

float GeometrySchlickGGX(float NdotV, float k) { float nom = NdotV; float denom = NdotV * (1.0 - k) + k; return nom / denom; } float GeometrySmith(vec3 N, vec3 V, vec3 L, float k) { float NdotV = max(dot(N, V), 0.0); float NdotL = max(dot(N, L), 0.0); float ggx1 = GeometrySchlickGGX(NdotV, k); float ggx2 = GeometrySchlickGGX(NdotL, k); return ggx1 * ggx2; }
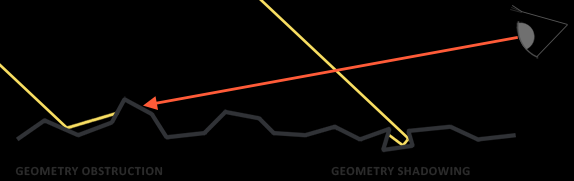
F菲涅尔方程¶
- 菲涅尔方程描述的是在不同的表面角下表面所反射的光线所占的比率。
- 当光线碰撞到一个表面的时候,菲涅尔方程会根据观察角度告诉我们被反射的光线所占的百分比。
- \(F_{Schlick}(h,v,F_0)=F_0+(1-F_0)(1-(h\cdot v))^5\) 其中 \(F_{0}\) 为平面的基础反射率
- 通常垂直平面(90 度)视界来观看时泛光会更加明显
D法线分布函数¶
- 估算在受到表面粗糙度的影响下,朝向方向与半程向量一致的微平面的数量。这是用来估算微平面的主要函数。
- 从统计学上描述了与半程向量 h 取向一致的微平面的比率,如有 35%一致,则返回 35%
- \(NDF_{GGXTR}(n,h,\alpha)=\frac{\alpha^2}{\pi((n\cdot h)^2(\alpha^2-1)+1)^2}\) 其中的 h 为半程向量,a 为表面粗糙度

float D_GGX_TR(vec3 N, vec3 H, float a) { float a2 = a*a; float NdotH = max(dot(N, H), 0.0); float NdotH2 = NdotH*NdotH; float nom = a2; float denom = (NdotH2 * (a2 - 1.0) + 1.0); denom = PI * denom * denom; return nom / denom; }
实例¶
#version 330 core
out vec4 FragColor;
in vec2 TexCoords;
in vec3 WorldPos;
in vec3 Normal;
// material parameters
uniform vec3 albedo;
uniform float metallic;
uniform float roughness;
uniform float ao;
// lights
uniform vec3 lightPositions[4];
uniform vec3 lightColors[4];
uniform vec3 camPos;
const float PI = 3.14159265359;
float DistributionGGX(vec3 N, vec3 H, float roughness)
{
float a = roughness*roughness;
float a2 = a*a;
float NdotH = max(dot(N, H), 0.0);
float NdotH2 = NdotH*NdotH;
float num = a2;
float denom = (NdotH2 * (a2 - 1.0) + 1.0);
denom = PI * denom * denom;
return num / denom;
}
float GeometrySchlickGGX(float NdotV, float roughness)
{
float r = (roughness + 1.0);
float k = (r*r) / 8.0;
float num = NdotV;
float denom = NdotV * (1.0 - k) + k;
return num / denom;
}
float GeometrySmith(vec3 N, vec3 V, vec3 L, float roughness)
{
float NdotV = max(dot(N, V), 0.0);
float NdotL = max(dot(N, L), 0.0);
float ggx2 = GeometrySchlickGGX(NdotV, roughness);
float ggx1 = GeometrySchlickGGX(NdotL, roughness);
return ggx1 * ggx2;
}
vec3 fresnelSchlickRoughness(float cosTheta, vec3 F0, float roughness);
void main()
{
vec3 N = normalize(Normal);
vec3 V = normalize(camPos - WorldPos);
vec3 F0 = vec3(0.04);
F0 = mix(F0, albedo, metallic);
// reflectance equation
vec3 Lo = vec3(0.0);
for(int i = 0; i < 4; ++i)
{
// calculate per-light radiance
vec3 L = normalize(lightPositions[i] - WorldPos);
vec3 H = normalize(V + L);
float distance = length(lightPositions[i] - WorldPos);
float attenuation = 1.0 / (distance * distance);
vec3 radiance = lightColors[i] * attenuation;
// cook-torrance brdf
float NDF = DistributionGGX(N, H, roughness);
float G = GeometrySmith(N, V, L, roughness);
vec3 F = fresnelSchlick(max(dot(H, V), 0.0), F0);
vec3 kS = F;
vec3 kD = vec3(1.0) - kS;
kD *= 1.0 - metallic;
vec3 nominator = NDF * G * F;
float denominator = 4.0 * max(dot(N, V), 0.0) * max(dot(N, L), 0.0) + 0.001;
vec3 specular = nominator / denominator;
// add to outgoing radiance Lo
float NdotL = max(dot(N, L), 0.0);
Lo += (kD * albedo / PI + specular) * radiance * NdotL;
}
vec3 ambient = vec3(0.03) * albedo * ao;
vec3 color = ambient + Lo;
color = color / (color + vec3(1.0));
color = pow(color, vec3(1.0/2.2));
FragColor = vec4(color, 1.0);
}
IBL (基于图片的光照)¶
- 不使用单独的可分解光源,而是将周围环境整体视为一个大光源(如立方体贴图,将立方体贴图的每个像素视为光源,在渲染方程中直接使用它)这种方式可以有效地捕捉环境的全局光照和氛围,使物体更好地融入其环境。
- 可以将立方体贴图的每个纹素视为一个光源。使用一个方向向量 \(w_{i}\) 对此立方体贴图进行采样,我们就可以获取该方向上的场景辐照度。
- 将渲染方程拆分为两部分,下面分别研究如何进行优化加速 \(L_o(p,\omega_o)=\intop_\Omega(k_d\frac c\pi)L_i(p,\omega_i)n\cdot\omega_id\omega_i+\intop_\Omega(k_s\frac{DFG}{4(\omega_o\cdot n)(\omega_i\cdot n)})L_i(p,\omega_i)n\cdot\omega_id\omega_i\)
漫反射¶
- 漫反射 \(L_o(p,\omega_o)=k_d\frac c\pi\int_\Omega L_i(p,\omega_i)n\cdot\omega_id\omega_i\) 只依赖于 \(w_{i}\),可以计算或预计算一个新的立方体贴图,它在每个采样方向中存储漫反射积分的结果