大数据概述¶
内容¶
- 三次信息化浪潮:信息处理、信息传输、信息爆炸
- 大数据意指一个超大的、难以用现有常规的数据库管理技术和工具处理的数据集。
-

-
大数据分类:
- 结构:结构化、半结构化、非结构化
- 获取和处理方式:动态/实时数据;静态非实时数据
-
关联特征:无关联/简单关联(键值数据);复杂关联(图数据)
-
软件是大数据的驱动力
-
大数据涉及的技术:
- 海量数据存储技术:分布式文件系统
- 实时数据处理技术:流计算引擎
- 数据高速传输技术:服务器/存储间高速通信
- 搜索技术:文本检索、智能搜索、实时搜 索
- 数据分析技术:自然语言处理、文本情感分析、机器学习、聚类关联、数据模型
题目¶
1.请简要介绍四种科学研究范式。¶
- 实验科学:强调通过实验来收集数据和验证假设的科学方法。。
- 理论科学:理论科学侧重于构建理论模型和框架,以解释自然现象或社会现象的原理和机制,而不一定依赖于实验数据。
- 计算科学:使用计算机来模拟和分析复杂的自然或社会现象,建立数学模型,通过计算机编程求解问题。
- 数据科学:数据科学涵盖了数据收集、清理、分析和解释等过程,以从大规模数据集中提取知识和见解,使用机器学习数据挖掘等方式获取结论和信息。
2.请解释数据、信息、知识的区别和关系。¶
- 数据:数据是原始、未加工的事实、数字、符号或描述性信息的集合。
- 信息:信息是对数据进行组织、解释和赋予意义后的产物。信息通常有上下文,具有可理解的含义,并可用于做出决策或执行某些行动。
- 知识:知识是更高级别的信息,是通过将信息与其他信息或经验相结合来建立的。它涉及对信息的理解、分析、评估和应用,以生成新的见解、规则或模式。
- 总的来说,数据是信息的基础,而信息又是知识的基础。知识是更高层次的认知构建,它不仅包含了信息的含义,还具备了应用和理解的能力。
3.请简述结构化数据/半结构化数据/非结构化数据的区别。¶
- 结构化数据:结构化数据是按照明确定义的数据模型或架构进行组织和存储的数据。这些数据以表格、数据库或电子表格等形式存在,通常包括行和列的结构,每列都有特定的数据类型和字段。
- 半结构化数据:半结构化数据是介于结构化数据和非结构化数据之间的数据类型。它们没有固定的表格结构,但通常包含标记、标签或其他结构性元素(如JSON、XML等),以便在数据中识别和提取信息。
- 非结构化数据:非结构化数据是没有明确结构或组织的数据,通常以自由文本、图像、音频、视频或自然语言的形式存在。这种数据类型不容易按行和列或其他规则进行组织。
4.大数据有哪几个特征?(5v)¶
- 大体量 Volume:数据规模很大
- 多样性 Varity:包含不同格式和形态的数据
- 时效性 Velocity:需要在一定的可接受的时间内完成数据的处理
- 准确性 Veracity:结果要保证一定的准确性、正确性
- 大价值 Value:大数据具有多维度的价值,可以从中挖掘出巨大的商业价值
5.请简述金融数据的特征。¶
- 数据众多:既有交易记录、账单等结构化数据也有视频音频等非结构化数据
- 高时效性:要求数据在短时间内被快速处理,实时性高。(流数据”特征,需要在短时间内快速处理)
- 可展示需求强:获取的数据需要以表格、曲线等形式清晰展示,便于进一步分析。
- 逻辑性:金融数据具有高时序性、相关性,涉及到交易价格等变化具有前后关系的数据。
- 高频性:股票市场等会在短时间内产生大量交易,需要对实时产生的大量数据进行分析。
- 高度机密性:金融数据通常包含敏感信息,如个人身份、财务账户等,因此需要高度保密和安全性。
- 高波动性:金融市场具有高度的波动性,价格和市场情况可以瞬息万变。
并行计算¶
内容¶
分类¶
- 按数据和指令处理结构:弗林(Flynn)分类
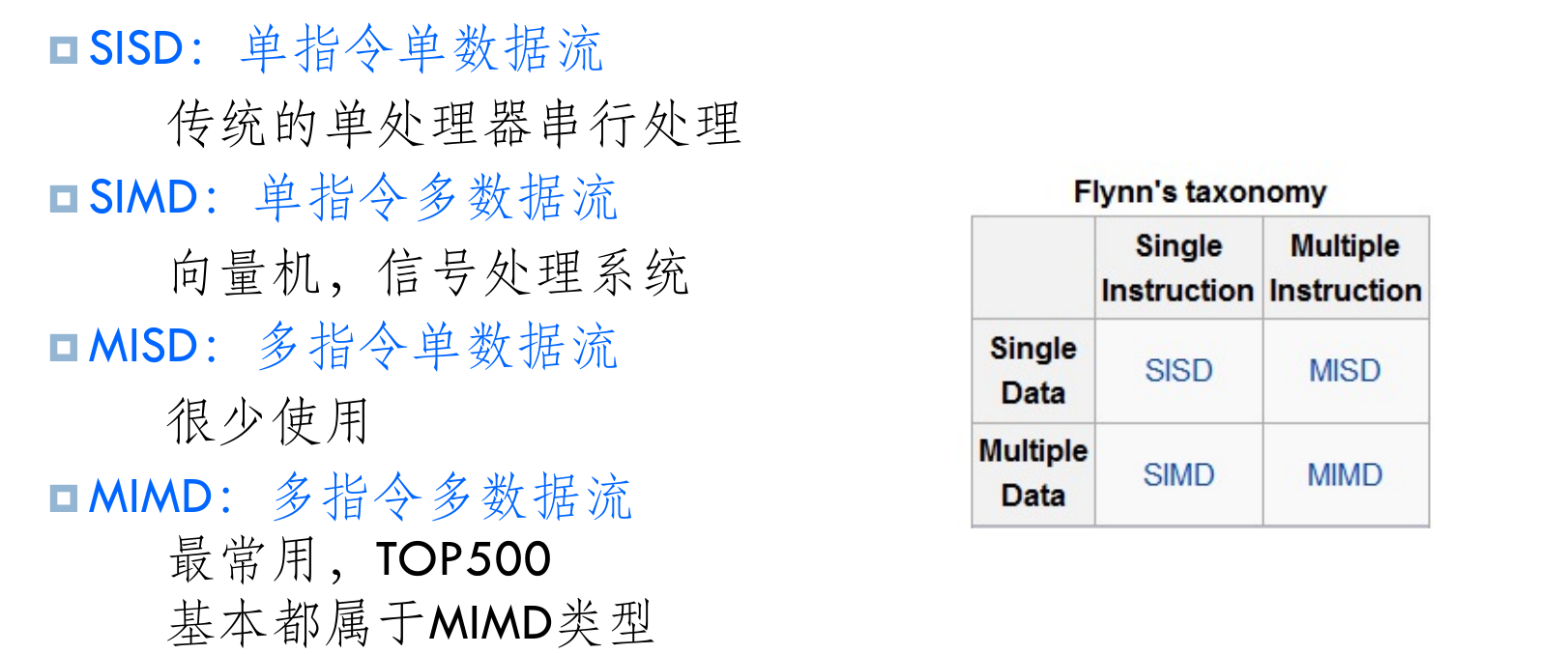
-
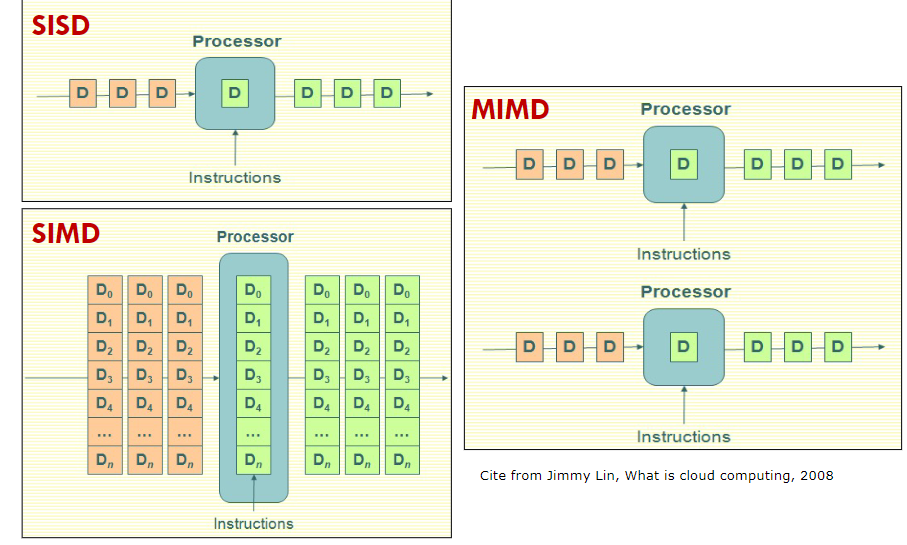
-
按并行类型
- 位级并行
- 指令级并行
-
线程级并行
- 数据级并行:一个大的数据块划分为小块,分别由不同的处理器/线程处理
- 任务级并行:一个大的计算任务划分为子任务,分别由不同的处理器/线程来处理
-
按存储访问构架

- 完全共享、共享&本地、完全本地
重点¶
-
按系统类型

-
多核/众核并行计算系统MC:集成在一个芯片上,使用本地缓存加上全局内存,功耗较低。
- 对称多处理系统 SMP:用独立的处理器和共享内存,以总线结构互联,运行一个操作系统, 定制成本高,难以扩充,规模较小 (2-8 处理器)
- 大规模并行处理MPP:使用独立处理器,具有独立的内存,通过专用内联网连接,扩展性差,规模中等。
- 集群Cluster:使用商品化服务器,通过网络互联,可扩展性强,目前最为常用。
- 网格 Grid:由距离较远的异构服务器构成,较为松散,适合并行度较低的大规模科学计算。
-
云 Cloud:通过互联网访问计算资源,资源托管在云服务提供商的远程数据中心
-
按计算特征
- 数据密集型并行计算:数据量极大、但计算相对简单的并行处理,如大规模Web 信息搜索
- 计算密集型并行计算:数据量相对不是很大、但计算较为复杂的并行处理,如:3-D建模与渲染,气象预报,科学计算……
-
数据密集与计算密集混合型并行计算:兼具数据密集型和计算密集型特征的并行计算,如3D 电影渲染
-
按并行程序设计模型/方法
- 共享内存变量:多线程共享存储器变量方式进行并行程序设计,会引起数据不一致性,导致数据和资源访问冲突,需要引入同步控制机制;(Pthread,OpenMP)
- 消息传递方式:对于分布式内存结构,为了分发数据和收集计算结果,需要在各个计算节点间进行数据通信,最常用的是消息。(MPI)
- MapReduce方式
问题¶
-
多核/多处理器网络互连结构技术
-
存储访问体系结构
- 共享存储器体系结构
- 分布存储体系结构
-
分布共享存储结构(Cache 的一致性问题)
-
分布式数据与文件管理
-
并行计算任务的分解与算法设计
-
并行程序设计模型和方法
- 共享内存式并行程序设计:为共享内存结构并行计算系统提供的程序设计方法,需提供数据访问同步控制机制(如互斥信号,锁等)
- 消息传递式并行程序设计:为分布内存结构并行计算系统提供的、以消息传递方式完成节点间数据通信的程序设计方法
-
MapReduce 并行程序设计:为解决前两者在并行程序设计上的缺陷,提供一个综合的编程框架,为程序员提供了一种简便易用的并行程序设计方法
-
数据同步访问和通信控制
- 重点在于同步访问机制(竞争问题、保证正确性)
-
可靠性设计与容错技术(最主要的技术问题)
- 大型并行计算系统使用大量计算机,因此,节点出错或失效是常态,不能因为一个节点失效导致数据丢失、程序终止或系统崩溃,因此,系统需要具有良好的可靠性设计和有效的失效检测和恢复技
- 数据失效恢复:大量的数据存储在很多磁盘中,当出现磁盘出错和数据损坏时,需要有良好的数据备份和数据失效恢复机制,保证数据不丢失以及数据的正确性。
- 系统和任务失效恢复:一个节点失效不能导致系统崩溃,而且要能保证程序的正常运行,因此,需要有很好的失效检测和隔离技术,并进行计算任务的重新调度以保证计算任务正常进行。
系统性能评估¶
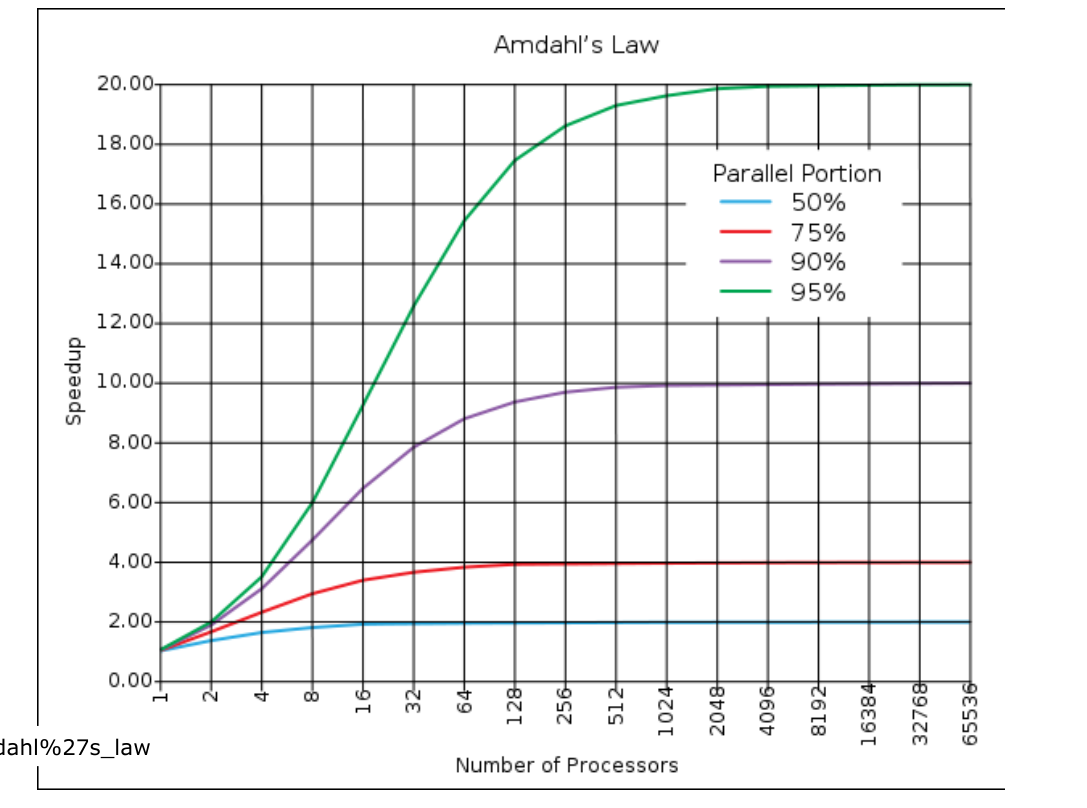
- 并行加速评估公式Amdahl定律:\(S=\frac{1}{(1-p)+\frac{P}{N}}\)
- S为加速比、P是程序可以并行的比例、N是处理器的数目
- 一个并行程序可加速程度是有限制的,并非可无限加速,并非处理器越多越好
MPI¶
- 功能:用常规语言编程方式,所有节点运行同一个程序,但处理不同的数据
- 提供点对点通信:同步/异步
- 提供节点集合通信
- 提供用户自定义的复合数据类型传输

- 通信组:将系统中的处理器划分为不同的通信组
- MPI_COMM_WORLD,指明系统中所有的进程都参与通信
- 一个通信组中的总进程数可以由MPI_Comm_Size调用来确定。
- 进程标识:为每个进程分配一个进程标识
- 进程标识号可以由MPI_Comm_Rank调用来确定。
- 特点:
- 灵活性好,适合于各种计算密集型的并行计算任务
- 独立于语言的编程规范,可移植性好
-
有很多开放机构或厂商实现并支持
-
不足:
- 无良好的数据和任务划分支持
- 缺少分布文件系统支持分布数据存储管理
- 通信开销大,当计算问题复杂、节点数量很大时,难以处理,性能大幅下降
- 无节点失效恢复机制,一旦有节点失效,可能导致计算过程无效
- 缺少良好的构架支撑,程序员需要考虑以上所有细节问题,程序设计较为复杂



题目¶
1.简述为什么需要并行计算?¶
- 传统提升计算机性能的手段(提升芯片集成度、改进指令集并行度、提升主频等)几乎耗尽,单核处理器性能提升接近极限。为了进一步提高计算速度,向多核并行计算发展成为发展的必然趋势。
- 涉及到大规模数据和复杂计算的研究及应用领域需要使用并行计算技术,并且金融、医疗、ai等越来越多的领域对大数据处理具有很高的需求。
- 总的来说,单核处理器性能发展的瓶颈,而多核并行计算具有的体积小、功耗低等诸多技术特点和优势
2.并行计算按照系统类型划分,可以分为哪几种?简述每一种系统类型的特点。¶
- 多核/众核并行计算系统MC:集成在一个芯片上,使用本地缓存加上全局内存,功耗较低。
- 对称多处理系统SMP:多个相同类型的树立起通过总线连接并使用共享内存,扩展性差,规模较小。
- 大规模并行处理MPP:使用独立处理器,具有独立的内存,通过专用内联网连接,扩展性差,规模中等。
- 集群Cluster:使用商品化服务器,通过网络互联,可扩展性强,目前最为常用。
- 网格Grid:有距离较远的异构服务器构成,较为松散,适合并行度较低的大规模科学计算。
- 云Cloud:通过互联网访问计算资源,资源托管在云服务提供商的远程数据中心
3.为什么可靠性设计与容错是并行计算的主要技术问题?¶
- 使用并行计算需要消耗大量计算资源,并且由于系统设备众多、较为复杂,单个节点的出错和失效不可避免,此如果一个节点的错误会导致整个计算的崩溃,那会导致系统频繁发生故障,计算根本无法进行。
- 并行计算常常用于科学计算、电影渲染等需要长时间持续计算的领域,如频繁因一点小故障而终止那么计算可能根本无法完成
- 并行计算的结果往往是具有重要价值的,错误的结果会带来高昂的代价
- 增加可靠性,避免出错还可以介绍系统维护成本,是提高并行计算竞争力的关键
4.MPI提供哪几种通信方式?简述每种通信方式对应的接口。¶
- 点对点通信
- 同步通信
- 发送:
MPI_Send (buf, count, datatype, dest, tag, comm) - 接收:
MPI_Recv (buf, count, datatype, source, tag, comm, status)
- 发送:
- 异步通信
- 发送:
MPI_ISend (buf, count, datatype, dest, tag, comm, request) - 接收:
MPI_IRecv (buf, count, datatype, source, tag, comm, status, request) - 等待传输完成:
MPI_Wait (request, status) - 检查是否传输完成
MPI_Test (request, flag, status)
- 发送:
- 节点集合通信
- 同步(设置同步障碍,使所有进程的执行同时完成,即等待所有进程达到同步点后才能继续执行。):
int MPI_Barrier(MPI_Comm comm) - 广播发送:
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm) - 收集(多个进程的消息以某种次序收集到一个进程):
int MPI_Gather(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm) - 分散(将一个信息划分为等长的段依次发送给其他进程):
int MPI_Scatter(void *sendbuf, int sendcount, MPI_Datatype sendtype, void *recvbuf, int recvcount, MPI_Datatype recvtype, int root, MPI_Comm comm) - 数据规约(将一组进程的数据按照指定的操作方式规约到一起,并传送给一个进程):
MPI_Reduce(sendbuf, recvbuf, count, datatype, op, root, comm) - 用户自定义的复合数据类型传输