Google MapReduce¶
- 主要目标
-
实现自动并行化计算
- 为程序员隐藏系统层细节
-
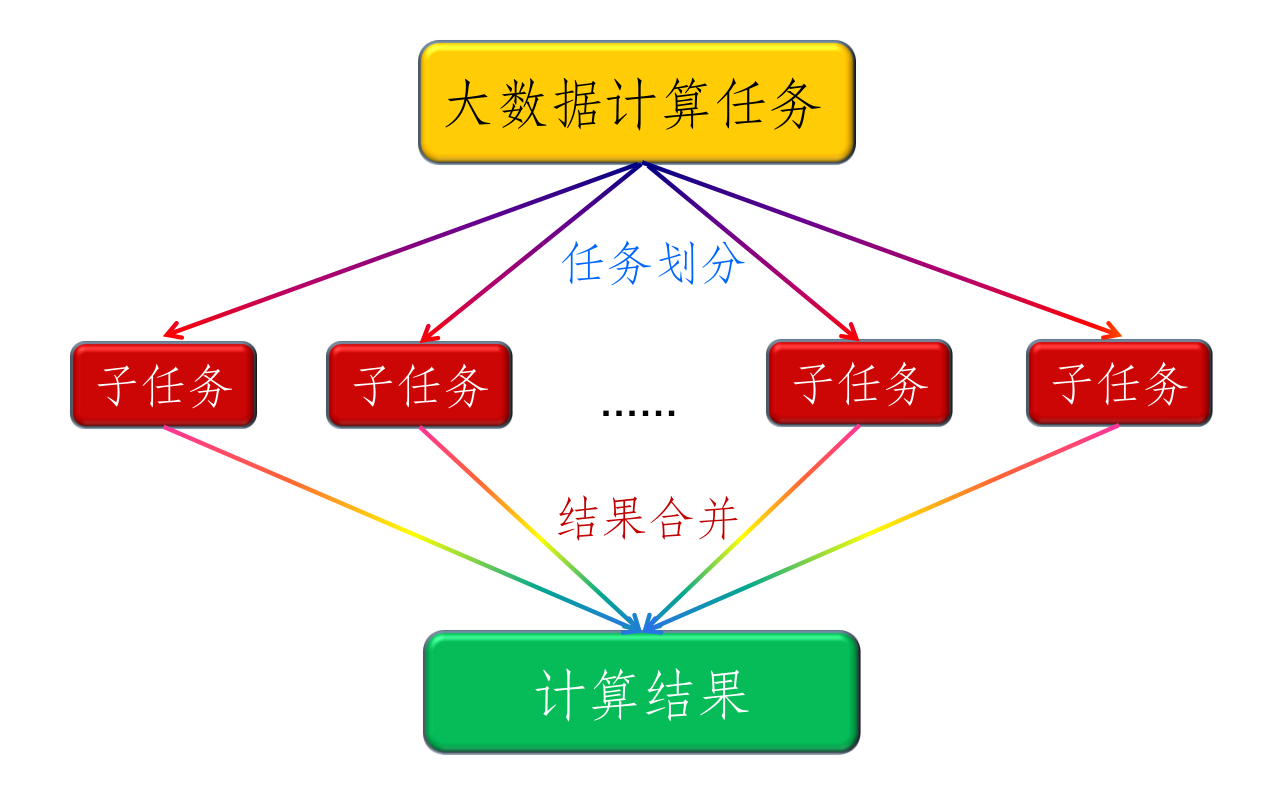
MapReduce 是面向大规模数据并行处理的
- 分而治之的策略
- 基于集群的高性能并行计算平台
- 并行程序开发与运行框架:可以自动执行并行化,划分数据、任务,分布存储,通讯等工作
-
并行程序设计模型与方法:函数式语言中的设计思想,用Map 和 Reduce两个函数编程(高层的并行编程抽象模型)实现基本的并行计算任务,提供了完整的并行编程接口,完成大规模数据处理(为大数据处理过程中的两个主要处理操作提供一种抽象机制)
-
不可分拆的计算任务或相互间有依赖关系的数据无法进行并行计算,如 fib 序列;
- 一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度的最好办法就是并行计算。
Map 和 Reduce¶
- Map: 对一组数据元素进行某种重复式的处理
- \((k1;v1)\to [(k2;v2)]\)
- 输入一个键值对,输出得到的一组中间数据
- Reduce: 对 Map 的中间结果进行某种进一步的结果整理
- \((k2;[v2])\to[(k3;v3)]\)
-
将 map 输出的多组键值对依照键进行合并处理,之后进行进一步整理或处理得到输出结果
-
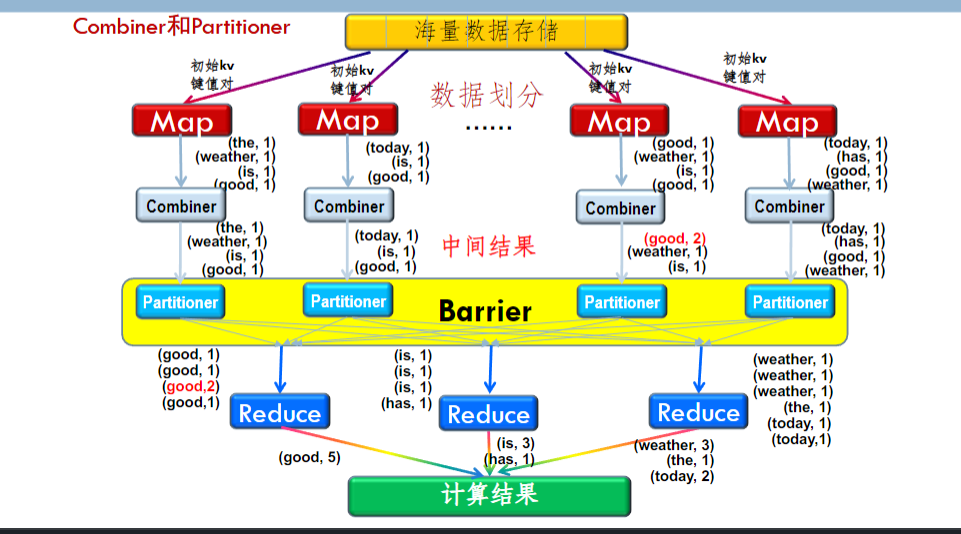
-
进行 reduce 处理之前,必须等到所有的 map 函数做完,因此,在进入 reduce 前需要有一个同步障;这个阶段也负责对 map 的中间结果数据进行收集整理处理 (shuffer),以便 reduce 更有效地计算最终结果
-
以多句话的词频统计为例

-

-
MapReduce 提供一个统一的计算框架,可完成:
- 计算任务的划分和调度
- 数据的分布存储和划分
- 处理数据与计算任务的同步
- 结果数据的收集整理
- 系统通信、负载平衡、计算性能优化处理
- 处理系统节点出错检测和失效恢复
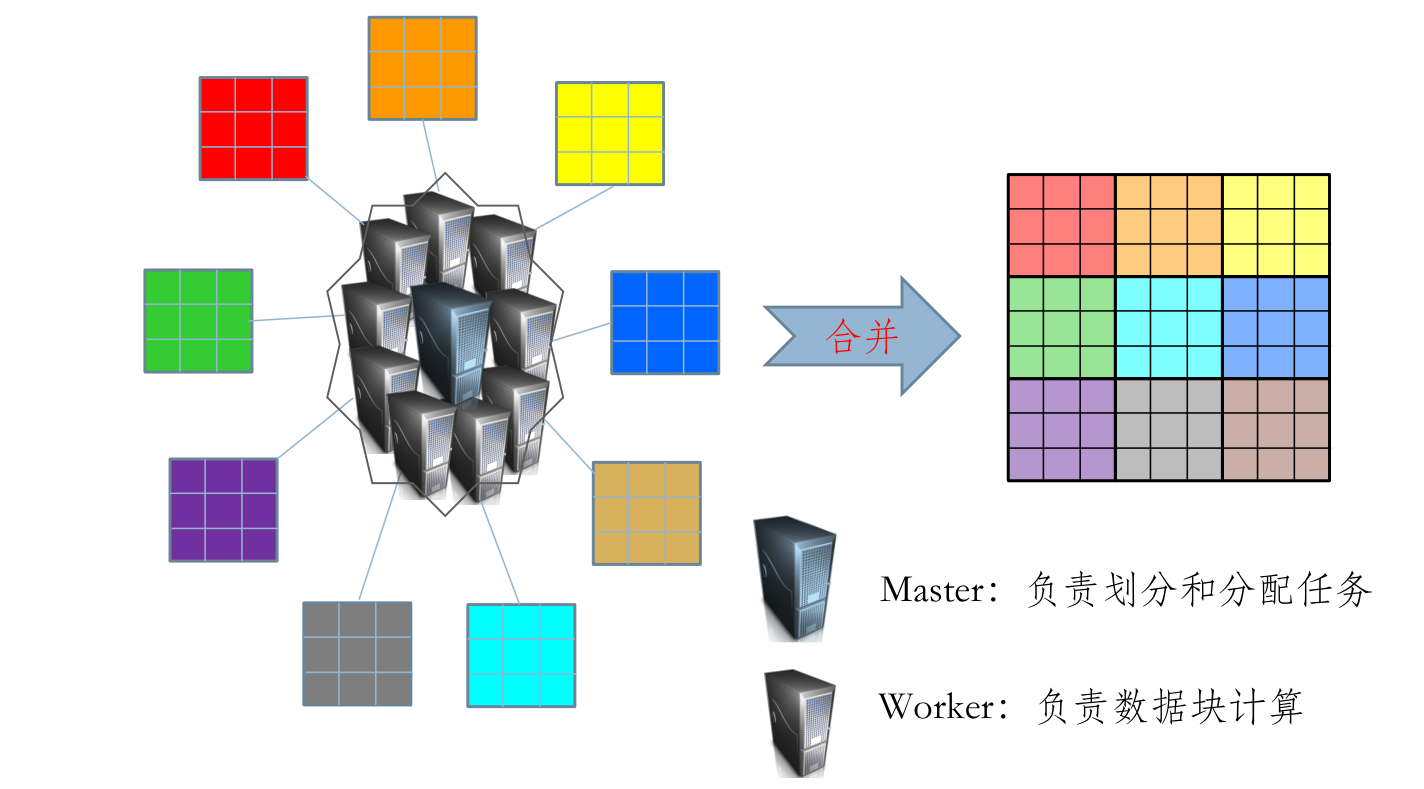
Google MapReduce 基本工作原理¶
-
有一个待处理的大数据,被划分为大小相同的数据块 (如 64 MB), 及与此相应的用户作业程序。系统中有一个负责调度的主节点 (Master), 以及数据 Map 和 Reduce 工作节点 (Worker)。
-
用户作业程序提交给主节点;主节点为作业程序寻找和配备可用的 Map 节点,并将程序传送给 Map 节点;主节点也为作业程序寻找和配备可用的 Reduce 节点,并将程序传送给 Reduce 节点
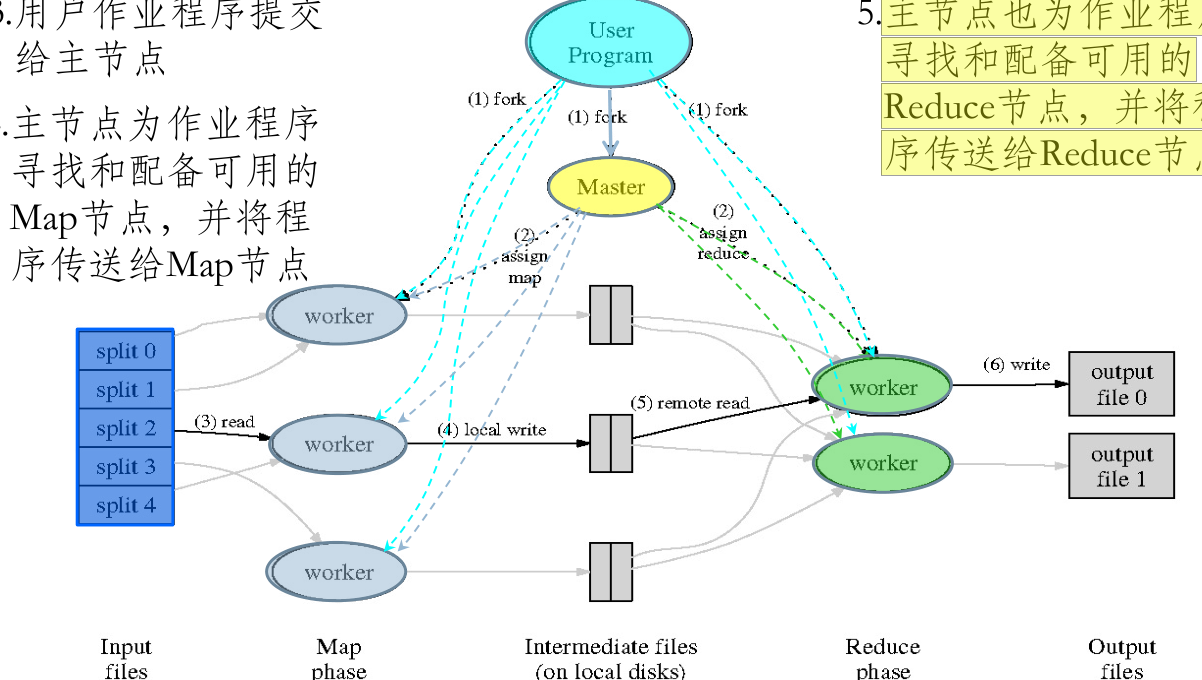
- 主节点启动每个 Map 节点执行程序,每个 Map 节点尽可能读取本地或本机架的数据进行计算; 没个 Map 节点处理读取的数据块,并做一些数据整理工作 (combining, sorting 等)并将中间结果存放在本地;同时通知主节点计算任务完成并告知中间结果数据存储位置。
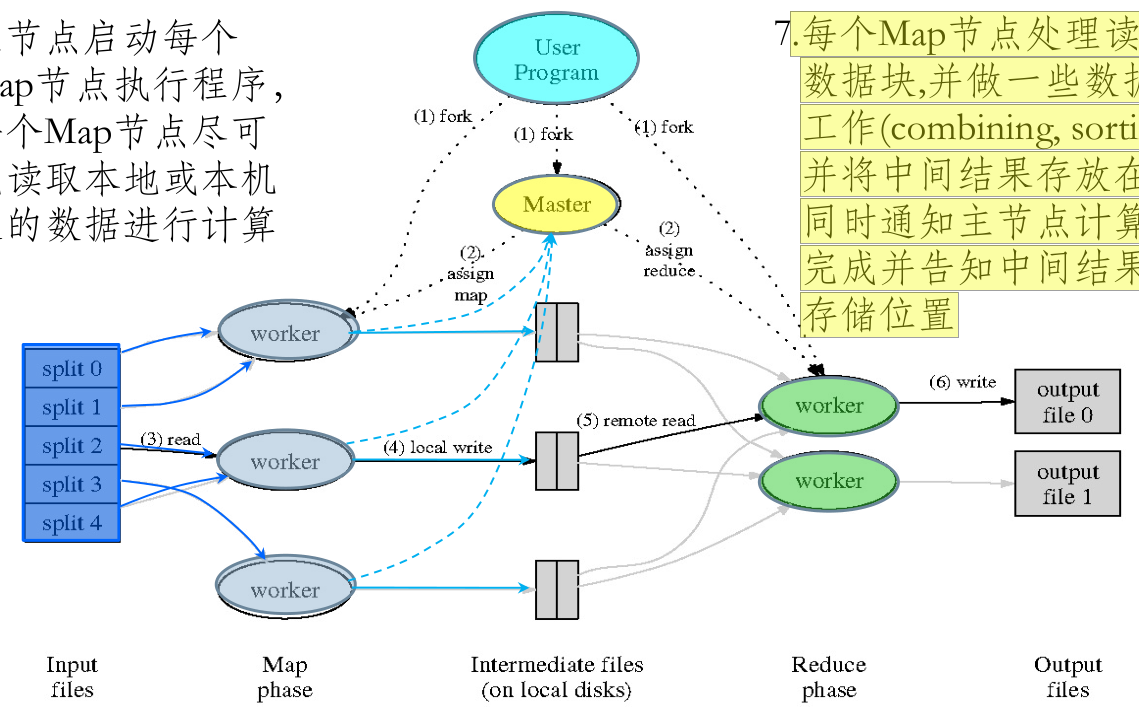
- 主节点等所有 Map 节点计算完成后,开始启动 Reduce 节点运行;Reduce 节点从主节点所掌握的中间结果数据位置信息,远程读取这些数据;Reduce 节点计算结果汇总输出到一个结果文件即获得整个处理结果
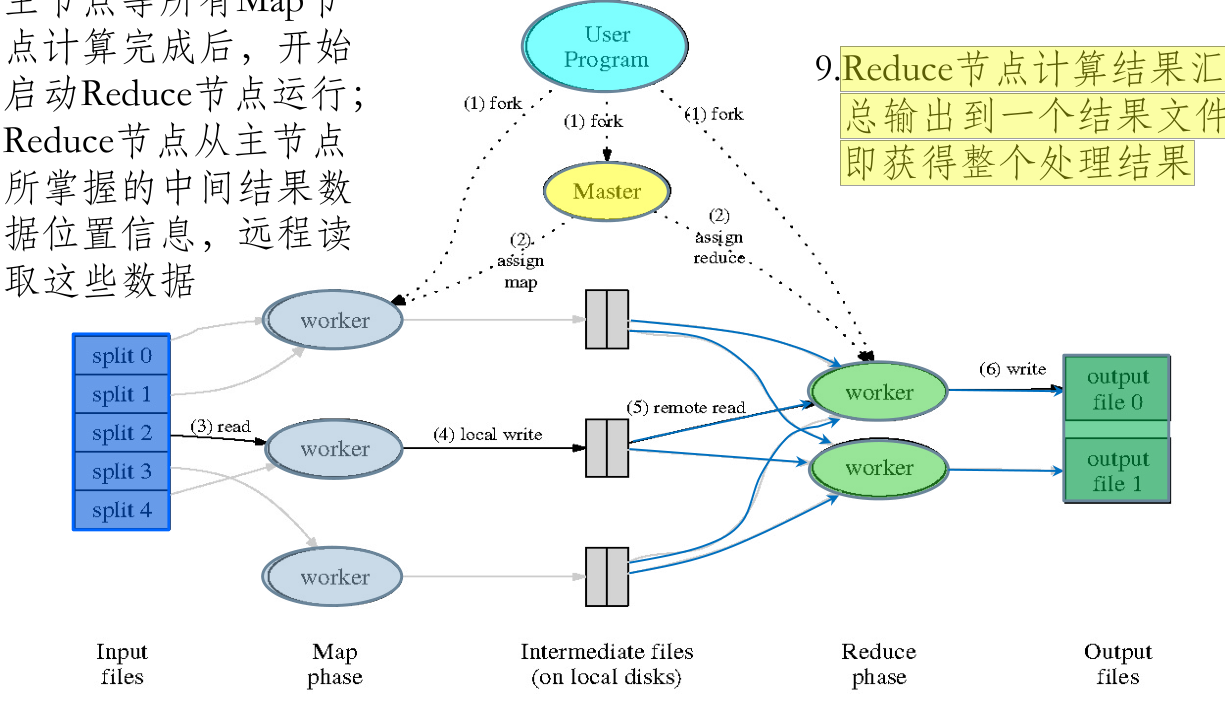
主要功能和设计思想¶
- 主要功能
- 出错处理:由于计算集群以低端商用服务器构成,十分容易出现软件、硬件上的错误,mapreduce 可以检测并隔离出错节点,并调度分配新的节点接管出错节点的计算任务。
- 分布式数据存储与文件管理:把海量数据分布存储在各个节点的本地磁盘上,但保持整个数据在逻辑上成为一个完整的数据文件;并且为了数据的安全,还具有多备份存储能力以及存储容错机制。
- Combiner 和 Partitioner:为了减少数据通信开销,需要在将数据发送到 reduce 处理之前先把具有同样主键的数据合并到一起避免重复传送。map 节点输出的中间结果需使用一定的策略进行适当的划分处理,保证相关数据发送到同一个 reduce 节点。
- 任务调度:提交的计算作业会被划分为很多个计算任务,任务调度主要负责为这些计算任务分配和调度 map 及 reduce 计算节点;并监控节点的执行状况,负责 map 节点执行的同步控制,以及进行一些计算性能优化处理。
-
数据/代码互定位:为了减少数据通讯的开销,让一个计算节点尽可能处理其本地磁盘上所分布存储的数据。当无法进行这种本地化数据处理时,再寻找其它可用节点并将数据从网络上传送给该节点处理。
-
设计思想
- 横向扩展取替向扩展:选用价格便宜、易于扩展的大量低端商用服务器,而非价格昂贵、不易扩展的高端服务器
- 认为失效是常态:MapReduce 集群中使用大量的低端服务器,因此,节点硬件失效和软件出错是常态。任何一个节点失效时,其它节点要能够无缝接管失效节点的计算任务;当失效节点恢复后应能自动无缝加入集群,而不需要管理员人工进行系统配置。要能有效处理失效节点的检测和恢复。
- 处理向数据迁移:将处理向数据靠拢和迁移,取代把数据传送到处理节点。采用数据/代码互定位的技术方法,计算节点将首先尽量负责计算其本地存储的数据,以发挥数据本地化特点,仅当节点无法处理本地数据时,再采用就近原则寻找其它可用计算节点,并把数据传送到该可用计算节点。
- 顺序处理数据、避免随机访问数据:大规模数据处理的特点决定了大量的数据记录不可能存放在内存、而只可能放在外存中进行处理,而磁盘的随机访问比顺序访问慢得多。
- 为应用开发者隐藏系统层细节:MapReduce 提供了一种抽象机制将程序员与系统层细节隔离开来,程序员仅需描述需要计算什么,而具体怎么去做就交由系统的执行框架处理。
- 数据扩展和系统规模扩展:软件算法应当能随着数据规模的扩大而表现出持续的有效性,性能上的下降程度应与数据规模扩大的倍数相当;并且在集群规模上,要求算法的计算性能应能随着节点数的增加保持接近线性程度的增长;
失效处理¶
- 主节点失效:节点中会周期性地设置检查点检查整个计算作业的执行情况,一旦某个任务失效,可以从最近有效的检查点开始重新执行,避免从头开始计算的时间浪费。如果只有一个 Master,它不太可能失败;因此,如果 Master 失败,将中止 MapReduce 计算。
- 工作节点失效:主节点会周期性地给工作节点发送检测命令,如果工作节点没有回应,这认为该工作节点失效,主节点将终止该工作节点的任务并把失效的任务重新调度到其它工作节点上重新执行。
优化¶
- 带宽优化
- 每个 Map 节点处理完成的中间键值对将由 combiner 做一个合并压缩。(相当于预先做一个局部reduce)
- 计算优化
- Reduce 节点必须要等到所有 Map 节点计算结束才能开始执行:把一个 Map 计算任务让多个Map 节点同时做,取最快完成者的计算结果
- 数据分区解决数据相关性
- 在进入 Reduce 节点计算之前,需要把属于一个 Reduce 节点的数据归并到一起。在 Map 阶段进行了 Combining 以后,可以根据一定的策略对 Map 输出的中间结果进行分区(partition),这样即可解决以上数据相关性问题避免 Reduce 计算过程中的数据通信。
分布式文件系统 Google GFS¶
- Google GFS 是一个基于分布式集群的大型分布式文件系统,为 MapReduce 计算框架提供数据存储和数据可靠性支撑;数据存储在物理上分布的每个节点上,但通过 GFS 将整个数据形成一个逻辑上整体的文件。
- 设计原则
- 廉价本地磁盘分布存储:各节点本地分布式存储数据,不需要采用价格较贵的集中式磁盘阵列,容量可随节点数增加自动增加
- 多数据自动备份解决可靠性:采用廉价的普通磁盘,把磁盘数据出错视为常态,用自动多数据备份存储解决数据存储可靠性问题
- 为上层的 MapReduce 计算框架提供支撑:GFS 作为向上层 MapReduce 执行框架的底层数据存储支撑,负责处理所有的数据自动存储和容错处理,因而上层框架不需要考虑底层的数据存储和数据容错问题
基本架构¶
-
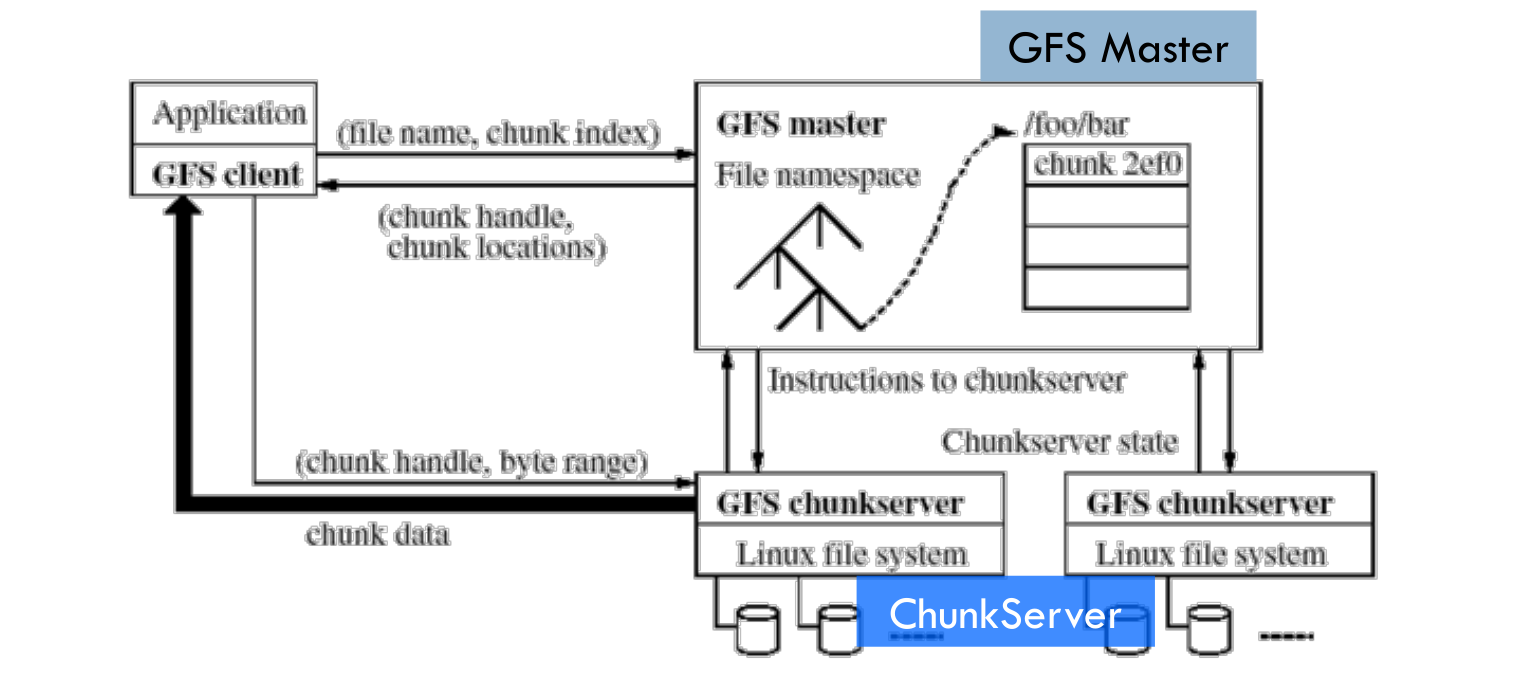
-
GFS Master
- 保存 GFS 文件系统的三种元数据 :
- 命名空间即整个分布式文件系统的目录结构
- Chunk与文件名的映射表
- Chunk 副本的位置信息,每一个 Chunk 默认有 3个副本
- 前两种元数据可通过操作日志提供容错处理能力;
- 第 3 个元数据直接保存在 ChunkServer 上,Master 启动或 Chunk Server 注册时自动完成在 Chunk Server 上元数据的生成;
-
当 Master 失效时,只要 ChunkServer 数据保存完好,可迅速恢复 Master 上的元数据。
-
GFS ChunkServer(用来保存大量实际数据的数据服务器)
- GFS 中每个数据块划分缺省为 64 MB,每个数据块会分别在 3 个不同的地方复制副本;对每一个数据块,仅当 3个副本都更新成功时,才认为数据保存成功。
- 当某个副本失效时,Master 会自动将正确的副本数据进行复制以保证足够的副本数;
- GFS 上存储的数据块副本,在物理上以一个本地的 Linux 操作系统的文件形式存储,每一个数据块再划分为 64 KB 的子块,每个子块有一个 32 位的校验和,读数据时会检查校验和以保证使用未失效的数据。
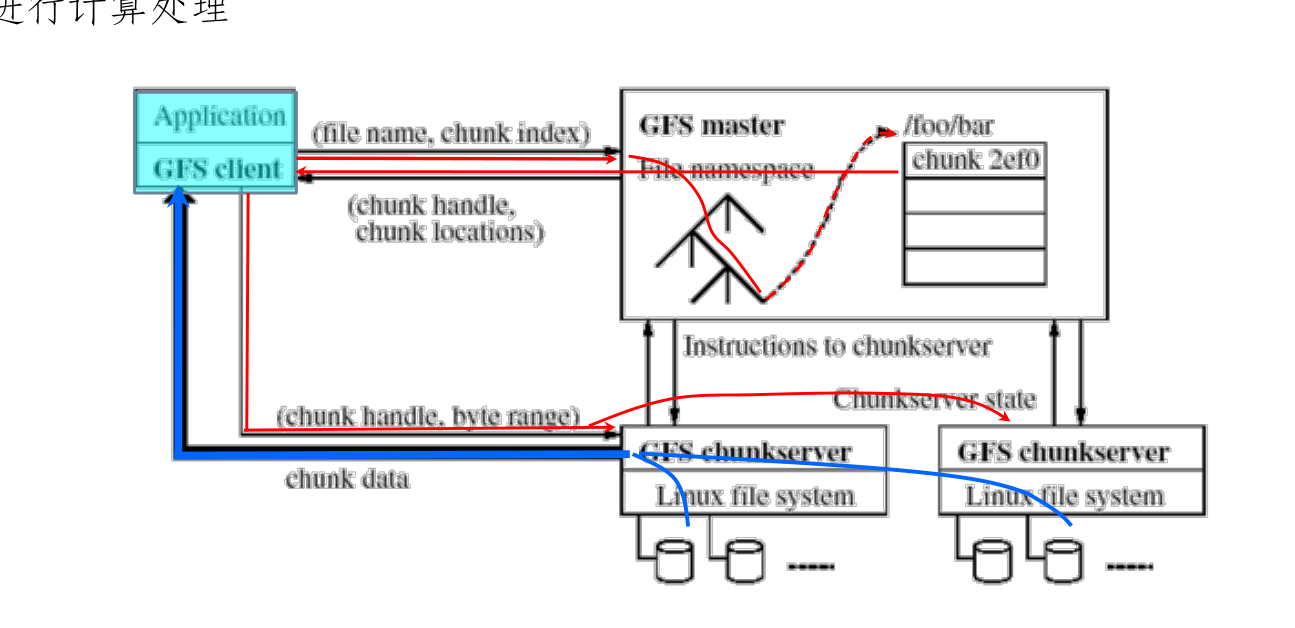
工作原理¶
- 数据访问工作过程
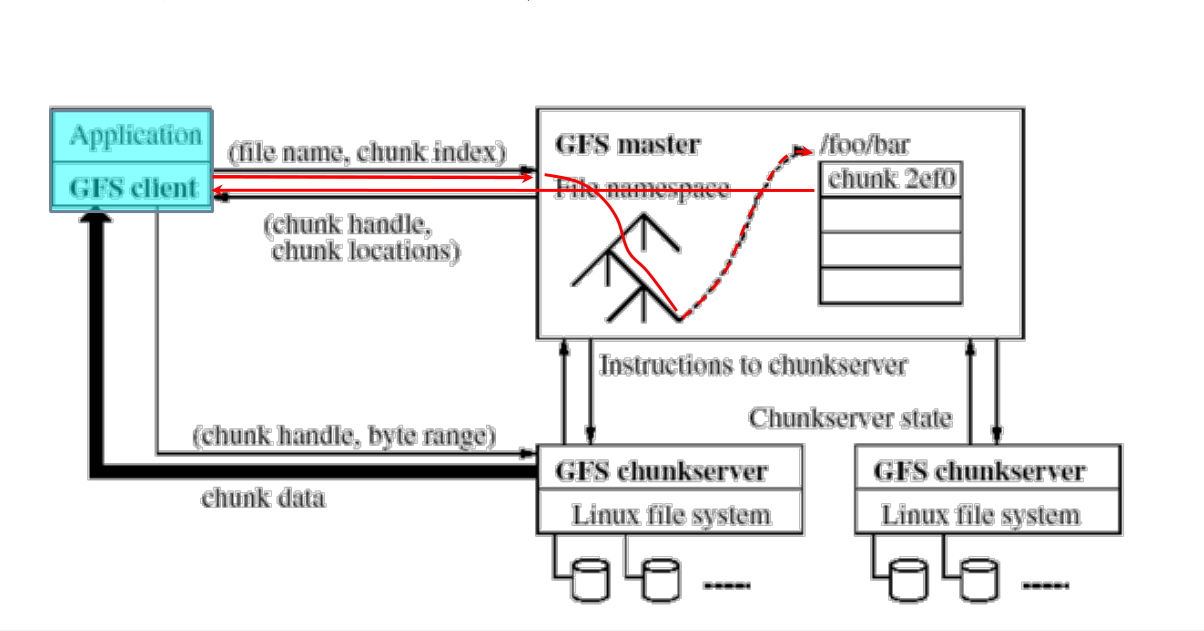
- 在程序运行前,数据已经存储在 GFS 文件系统中;程序运行时应用程序会告诉 GFS Server 所要访问的文件名或者数据块索引是什么
- GFS Server 根据文件名和数据块索引在其文件目录空间中查找和定位该文件或数据块,找出数据块具体在哪些 ChunkServer 上;将这些位置信息回送给应用程序
-
应用程序根据 GFS Server 返回的具体 Chunk 数据块位置信息,直接访问相应的 ChunkServer,直接读取指定位置的数据进行计算处理
-
特点:应用程序访问具体数据时不需要经过 GFS Master,因此,避免了 Master 成为访问瓶颈
-
并发访问:由于一个大数据会存储在不同的 ChunkServer 中,应用程序可实现并发访问
-
GFS 的系统管理技术
- 大规模集群安装技术:在一个成千上万个节点的集群上迅速部署 GFS,升级管理和维护等
- 故障检测技术:GFS 是构建在不可靠的廉价计算机之上的文件系统,节点数多,故障频繁,如何快速检测、定位、恢复或隔离故障节点
- 节点动态加入技术:当新的节点加入时,需要能自动安装和部署 GFS
- 节能技术:服务器的耗电成本大于购买成本,Google 为每个节点服务器配置了蓄电池替代 UPS,大大节省了能耗。
分布式结构化数据表 BigTable¶
- 在 GFS 之上的一个结构化数据存储和访问管理系统 BigTable,为应用程序提供比单纯的文件系统更方便、更高层的数据操作能力。
- 主要解决一些大型媒体数据(Web 文档、图片等)的结构化存储问题。其结构化粒度没有那么高,也没有事务处理等能力,因此,它并不是真正意义上的数据库。
设计目标¶
- 需要存储多种数据:如 URL,网页,图片,地图数据,email,用户的个性化设置等
- 海量的服务请求:Google 是目前世界上最繁忙的系统,因此,需要有高性能的请求和数据处理能力
- 商用数据库无法适用:在如此庞大的分布集群上难以有效部署商用数据库系统,且其难以承受如此巨量的数据存储和操作需求
- 广泛的适用性:可满足对不同类型数据的存储和操作需求
- 很强的可扩展性:根据需要可随时自动加入或撤销服务器节点
- 高吞吐量数据访问:提供 P 级数据存储能力
- 高可用性和容错性:保证系统在各种情况下都能正常运转,服务不中断
- 自动管理能力:自动加入和撤销服务器,自动负载平衡
- 简单性:系统设计尽量简单以减少复杂性和出错率
数据模型¶
- BigTable 主要是一个分布式多维表:通过一个行关键字、一个列关键字、一个时间戳进行索引和查询定位。
- (row: string, column: string, time: int 64)-> 结果数据字节串(cell)
-
支持查询、插入和删除操作
-
BigTable 对存储在表中的数据不做任何解释,一律视为字节串,具体数据结构的实现由用户自行定义。
-
特征:
- 稀疏:这表示 Bigtable 的表中的数据通常是非常稀疏的,也就是说,表中只有一小部分单元格包含有效数据,而绝大多数单元格为空或未定义。这种稀疏性允许 Bigtable 有效地处理大规模数据而不浪费存储空间。
- 分布式:Bigtable 是一个分布式数据库系统,它的表数据分布在多台物理服务器上。
- 持久化:Bigtable 中的数据是持久化存储的,这意味着数据不会因为服务器故障或系统重启而丢失。数据会被持续存储并可靠地保留。
- 多维度:Bigtable 的表是多维度的,这表示数据可以根据多个维度进行组织和检索。
-
有序映射:Bigtable 中的数据可以被视为按照行键和列限定符进行排序的映射(Map),这使得数据的检索和范围查询变得非常高效。
-
存储格式
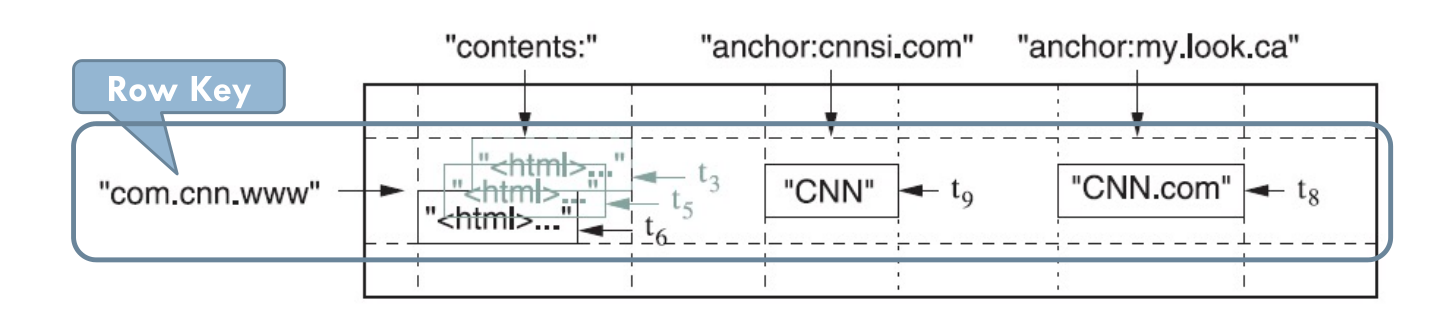
- 行:大小不超过 64 KB 的任意字符串。表中的数据都是根据行关键字进行排序的**。
- URL 地址倒排好处是:同一地址的网页将被存储在表中连续的位置,便于查找;倒排便于数据压缩,可大幅提高数据压缩率
- 子表:一个大表可能太大,不利于存储管理,将在水平方向上被分为 多个子表
- 列
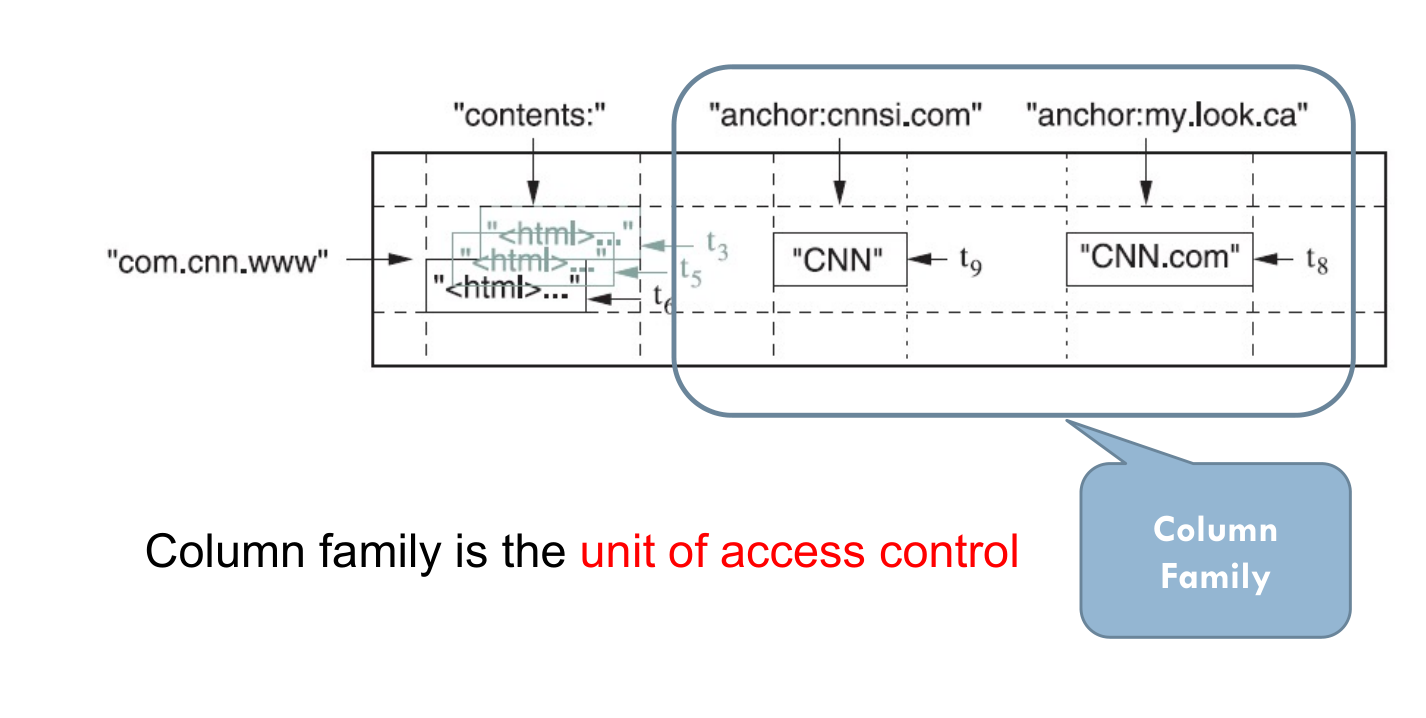
- 多个列构成一个列族,族中的数据属于同一类别,一个列族下的数据会被压缩在一起存放,列族是访问控制的单位。数据库管理员或数据所有者可以为不同的列族设置不同的访问权限和安全策略。
- 查询具体一个列的列键可以由两部分组成(族名:列名)。列族用于将数据分类,而列限定符用于唯一标识特定列族中的数据单元格。通过这种方式,可以方便地对数据库中的数据进行组织和检索。同时,不同的列族可以拥有不同的列限定符,从而允许更灵活的数据模型和查询。
- content、anchor 都是族名;而 cnnsi. com 和 my. look. ca 则是 anchor 族中 的列名。
- 时间戳:很多时候同一个 URL 的网页会不断更新,而 Google 需要保存不同时间的网页数据,因此需要使用时间戳来加以区分。(t 3 t 5 t6)
- 可以保留最近的 n 个版本数据/保留限定时间内的所有不同版本数据
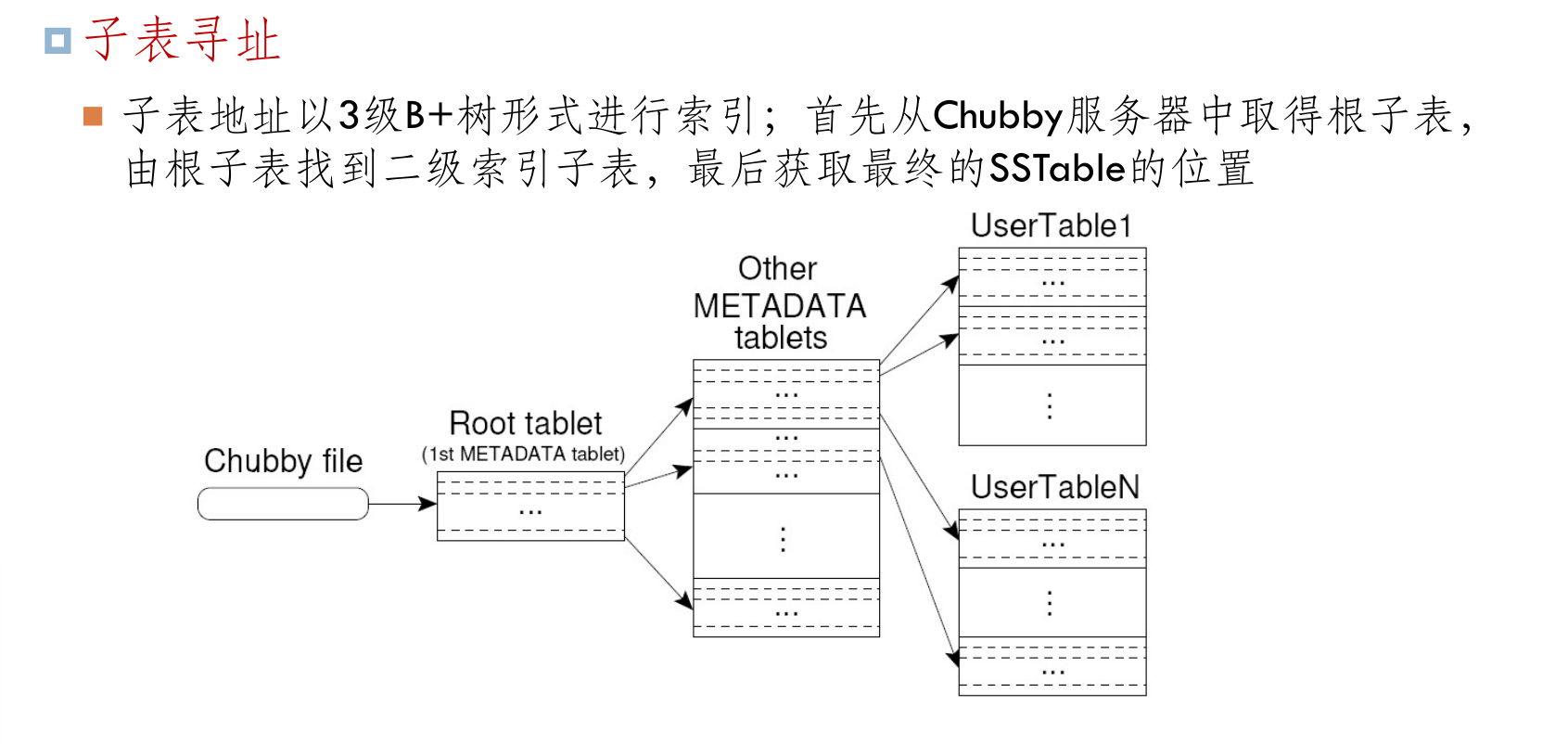
BigTable 基本架构¶
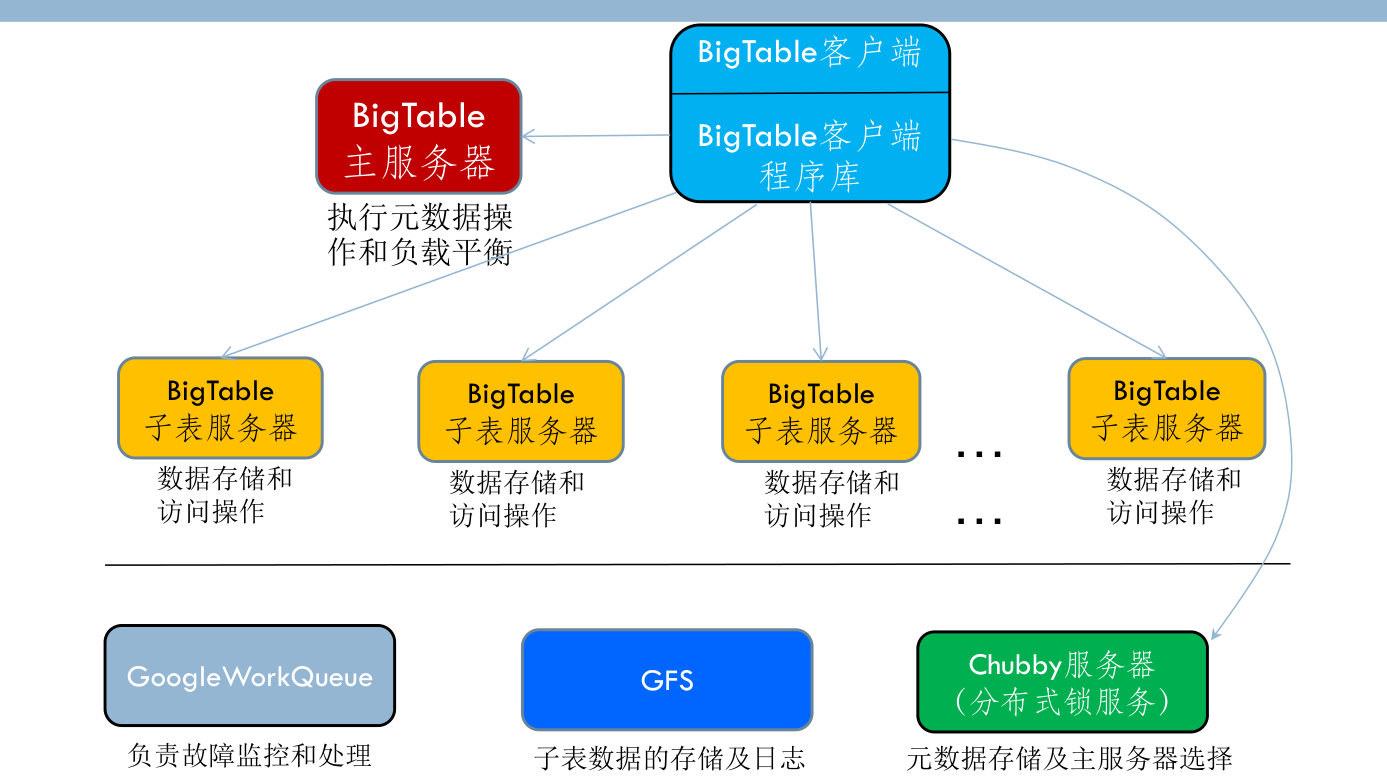
- 主服务器
- 新子表分配:当一个新子表产生时,主服务器通过加载命令将其分配给一个空间足够大的子表服务器;.
- 子表监控:通过 Chubby 完成。所有子表服务器基本信息被保存在 Chubby 中的服务器目录中主服务器检测这个目录可获取最新子表服务器的状态信息。当子表服务器出现故障,主服务器将终止该子表服务器,并将其上的全部子表数据移动到其它子表服务器。
-
负载均衡:当主服务器发现某个子表服务器负载过重时,将自动对其进行负载均衡操作。
-
子表服务器
- BigTable 中的数据都以子表形式保存在子表服务器上,客户端程序也直接和子表服务器通信。
- 分配:当一个新子表产生,子表服务器的主要问题包括子表的定位、分配、及子表数据的最终存储。
-
子表数据结构
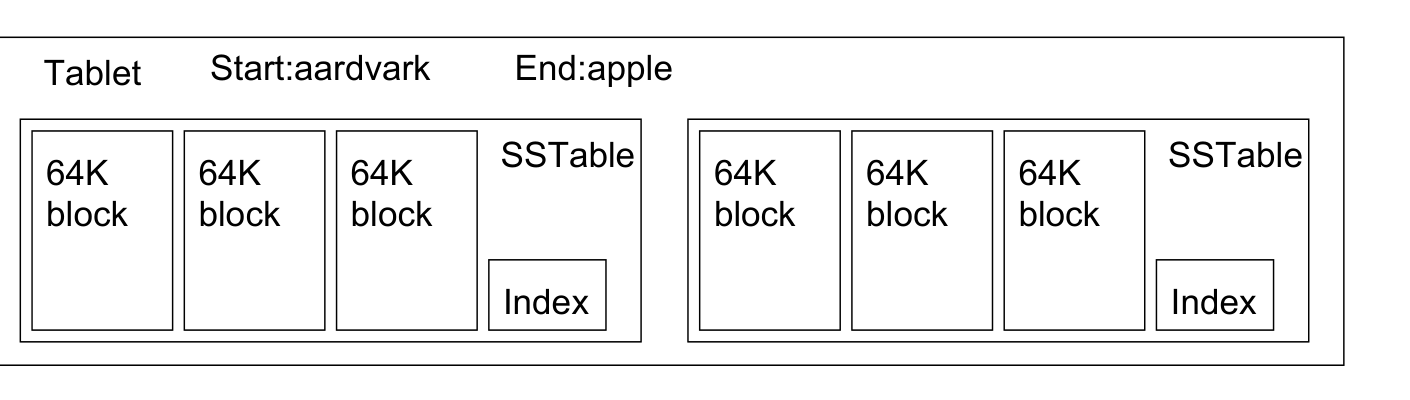
- 子表是整个大表的多行数据划分后构成。而一个子表服务器上的子表将进一步由很多个 SSTable 构成,每个 SSTable 构成最终的在底层 GFS 中的存储单位。
- 一个 SSTable 还可以为不同的子表所共享,以避免同样数据的重复存储。
- SSTable 是 BigTable 内部的基本存储结构,以 GFS 文件形式存储在 GFS 文件系统中。一个 SSTable 实际上对应于 GFS 中的一个64MB 的数据块
- SSTable 中的数据进一步划分为 64 KB 的子块,因此一个 SSTable 可以有多达 1 千个这样的子块。为了维护这些子块的位置信息,需要使用一个 Index 索引。
-
Hadoop与MapReduce¶
- Hadoop 是一个能够对大量数据进行分布式处理的软件框架,并且是以一种可靠、高效、可伸缩的方式进行处理的,
- 特性:高可靠性;高效性;高可扩展性;高容错性;成本低;运行在Linux平台上;支持多种编程语言。
Hadoop安装¶
-
依赖项
-
java:版本查看
java -version
sudo apt update
sudo apt install openjdk-8-jdk # 安装OpenJDK 8
单机安装¶
-
创建文件夹用于存放
mkdir ~/hadoop_installs -
(官网)下载安装包并解压
tar –zxvf hadoop-3.3.6.tar.gz -
配置环境变量
-
查看java安装路径
sudo update-alternatives --config java;设置export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64(后面路径不要)添加到etc/hadoop/hadoop-env.sh文件 -
运行测试(grep):
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar grep input output 'dfs[a-z.]+'
cat output/*
伪分布式安装¶
集群docker安装¶
- 基于Docker搭建hadoop完全分布式集群 - 知乎 (zhihu.com)
- 启动集群容器
docker-compose up -d - ssh进入主节点
docker exec -it hadoop_master1_1 bash - 从主节点进入其他节点
ssh worker1 - 启动集群
./sbin/start-all.sh - 查看节点运行服务
jps
分布式文件系统HDFS¶
- 特征:
- HDFS对顺序读进行了优化,支持大量数据的快速顺序读出
- 基于块的文件存储,默认的块的大小是64MB
- 数据不进行本地缓存
- 数据支持一次写入,多次读取;不支持已写入数据的更新操作。
- 多副本数据块形式存储,按照块的方式随机选择存储节点,默认副本数目是3
主要组件¶
-
-
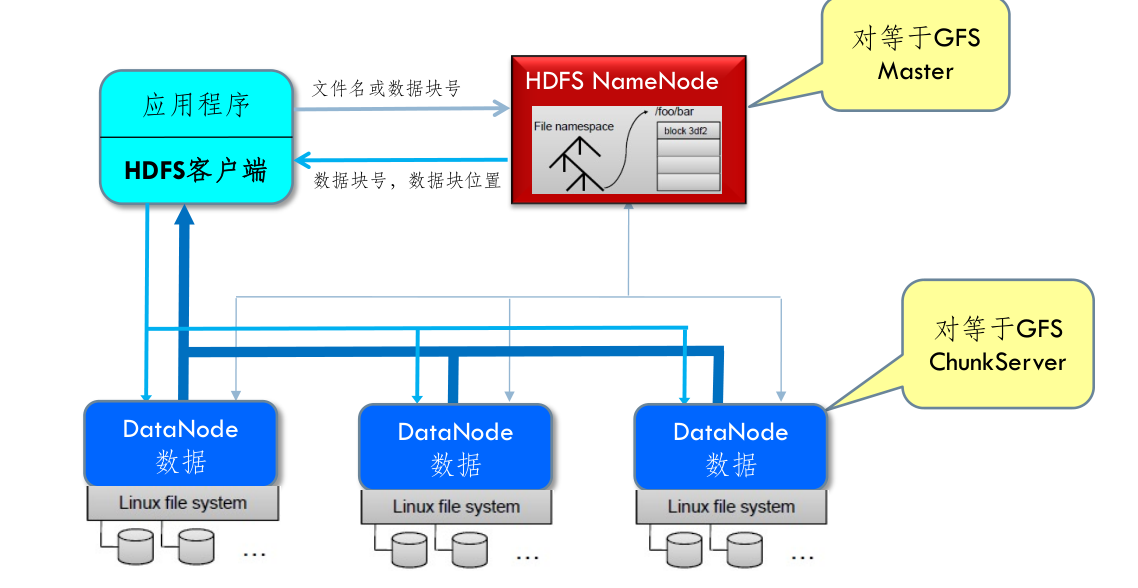
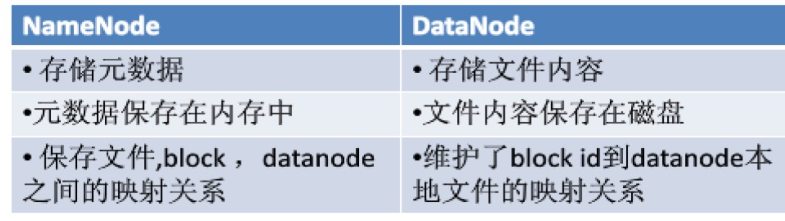
NameNode
- 负责管理分布式文件系统的命名空间:
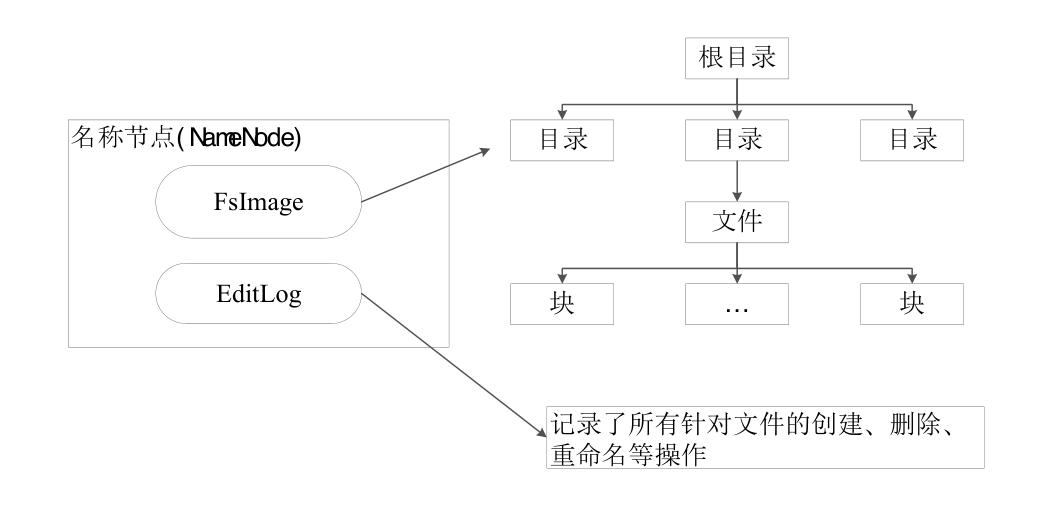
- FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据;
- FsImage文件包含文件系统中所有目录和文件inode的序列化形式。包含此类信息:文件的复制等级、修改和访问时间、访问权限、块大小以及组成文件的块。对于目录,则存储修改时间、权限和配额元数据。
- FsImage文件没有记录文件包含哪些块以及每个块存储在哪个数据节点。而是由名称节点把这些映射信息保留在内存中,当数据节点加入HDFS集群时,此后会定期执行这种告知操作,以确保名称节点的块映射是最新的。
- 操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
- 在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步。一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件和一个空的EditLog文件。之后的更新操作会重新写到EditLog文件中。
-
名称节点记录了每个文件中各个块所在的数据节点的位置信息
-
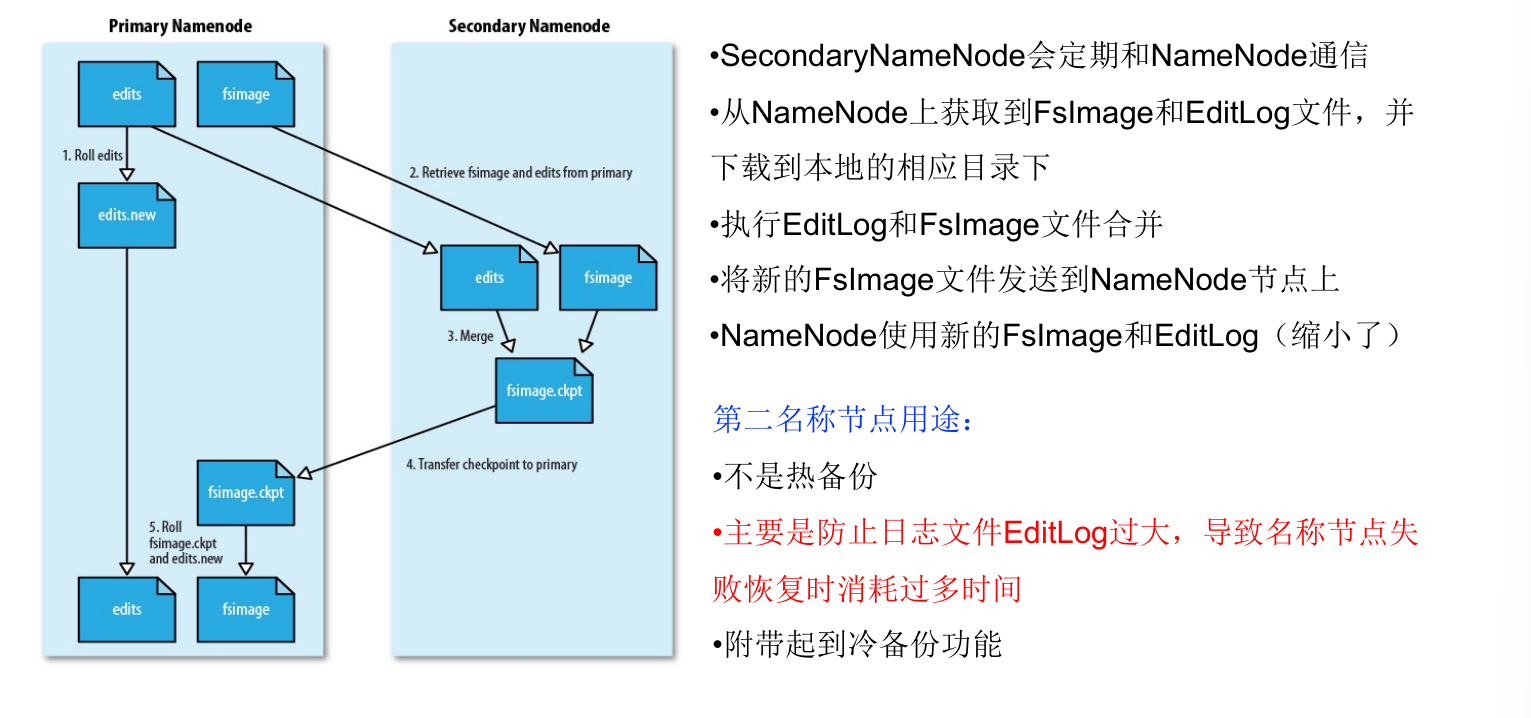
SecondaryNameNode
- 用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。
-
-
DataNode
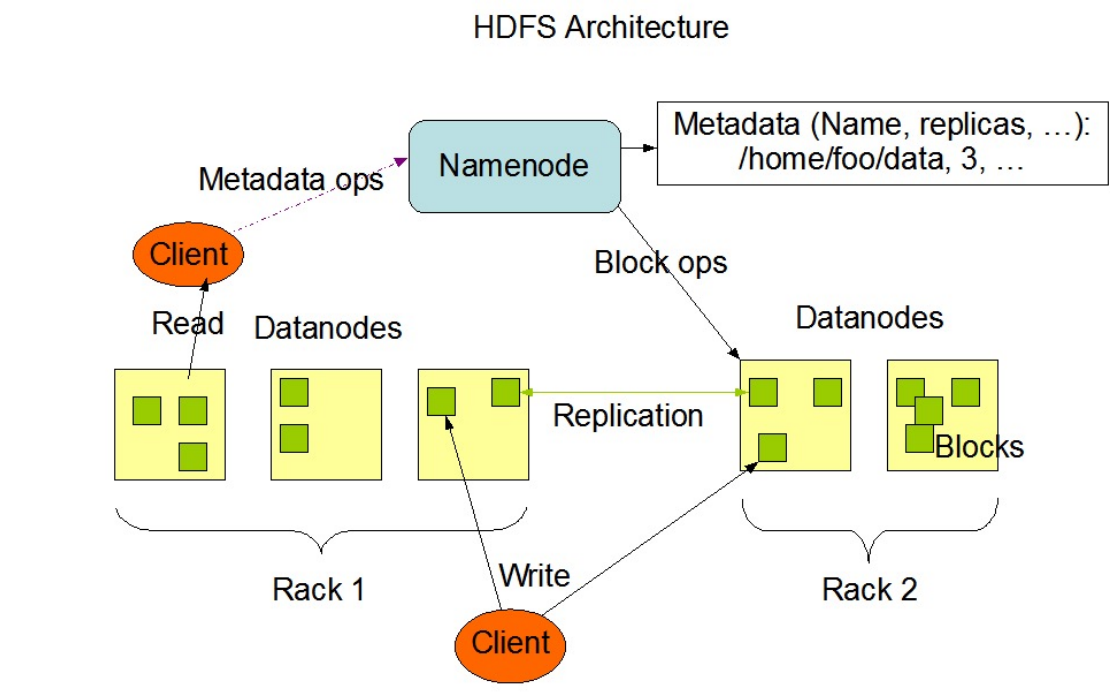
- 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。

工作框架¶
- 所有的HDFS通信协议都是构建在TCP/IP协议基础之上的
- 客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互。
-
名称节点和数据节点之间则使用数据节点协议进行交互。
-
读过程
- 当客户端读取数据时,从名称节点获得数据块不同副本的存放位置列表,列表中包含了副本所在的数据节点,可以调用API来确定客户端和这些数据节点所属的机架ID,当发现某个数据块副本对应的机架ID和客户端对应的机架ID相同时,就优先选择该副本读取数据,如果没有发现,就随机选择一个副本读取数据
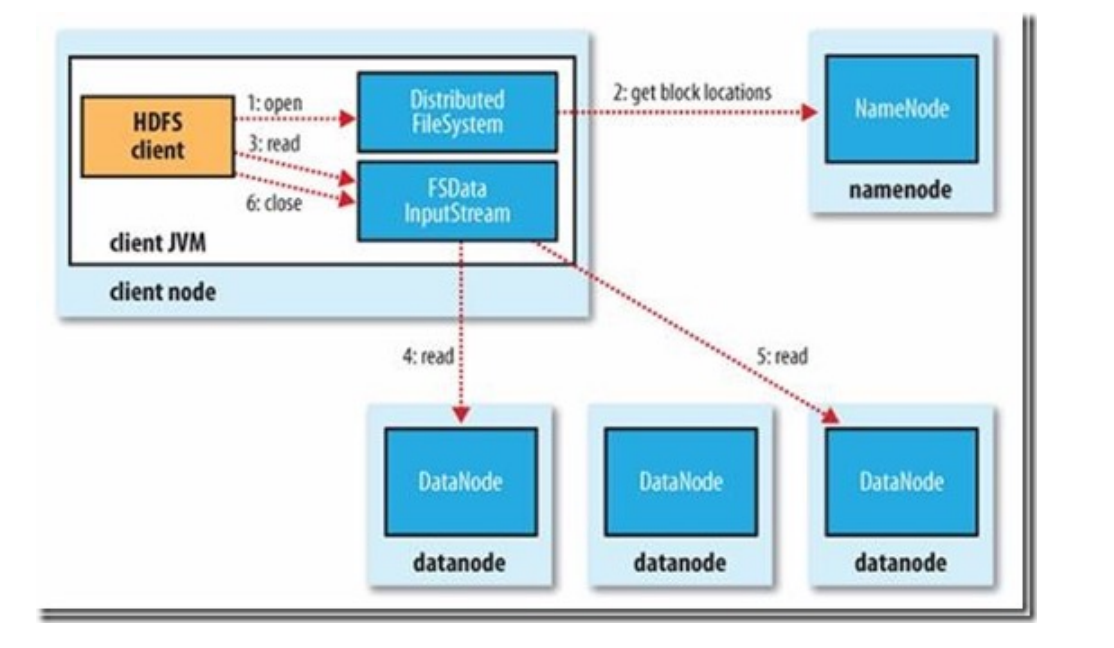
-
import java.io.BufferedReader; import java.io.InputStreamReader; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.FSDataInputStream; public class ReadHdfsFile { public static void main(String[] args) { try { // 创建Hadoop配置对象 Configuration conf = new Configuration(); // 设置Hadoop文件系统的默认URI,连接到localhost的端口9000 conf.set("fs.defaultFS", "hdfs://localhost:9000"); // 设置Hadoop文件系统的实现类为org.apache.hadoop.hdfs.DistributedFileSystem conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); // 获取Hadoop文件系统实例 FileSystem fs = FileSystem.get(conf); // 创建一个Path对象,表示要读取的HDFS文件路径(在这个示例中为名为"test"的文件) Path file = new Path("test"); // 打开HDFS文件并返回一个输入流FSDataInputStream FSDataInputStream getIt = fs.open(file); // 创建一个BufferedReader对象,用于逐行读取文件内容 BufferedReader d = new BufferedReader(new InputStreamReader(getIt)); // 读取文件的一行内容 String content = d.readLine(); // 打印读取的内容到控制台 System.out.println(content); // 关闭BufferedReader d.close(); // 关闭Hadoop文件系统连接 fs.close(); } catch (Exception e) { // 捕获并打印任何可能的异常 e.printStackTrace(); } } } -
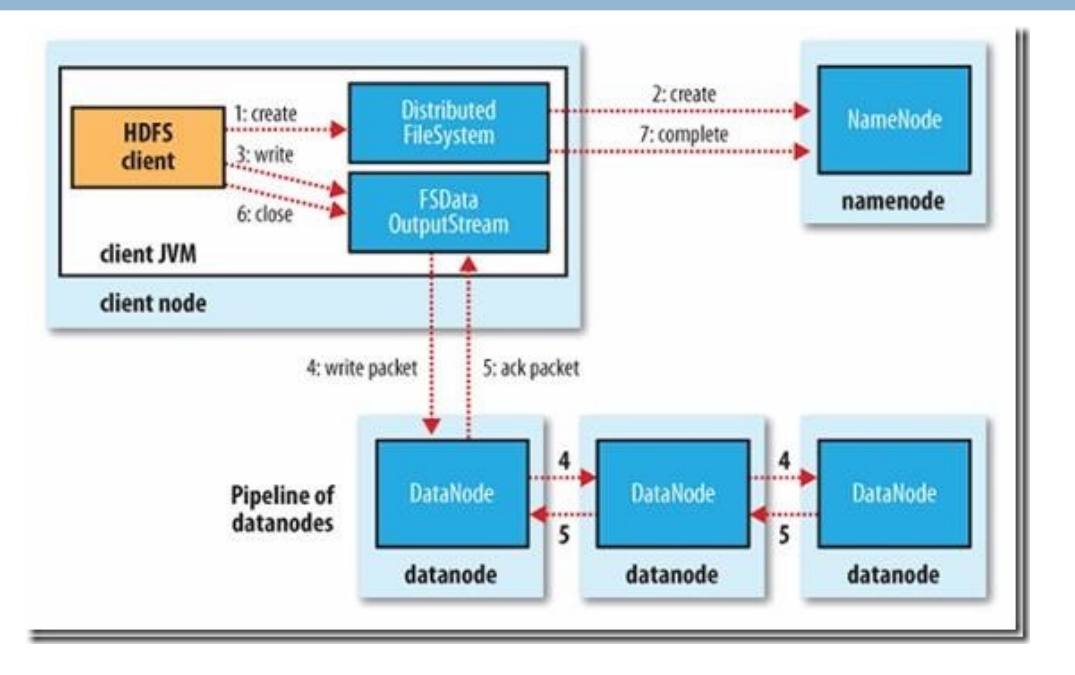
写过程
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.Path; public class WriteHdfsFile { public static void main(String[] args) { try { // 创建Hadoop配置对象 Configuration conf = new Configuration(); // 设置Hadoop文件系统的默认URI,连接到localhost的端口9000 conf.set("fs.defaultFS", "hdfs://localhost:9000"); // 设置Hadoop文件系统的实现类为org.apache.hadoop.hdfs.DistributedFileSystem conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem"); // 获取Hadoop文件系统实例 FileSystem fs = FileSystem.get(conf); // 要写入的内容转换为字节数组 byte[] buff = "Hello world".getBytes(); // 要写入的文件名 String filename = "test"; // 创建一个HDFS文件并返回一个输出流FSDataOutputStream FSDataOutputStream os = fs.create(new Path(filename)); // 将字节数组写入文件 os.write(buff, 0, buff.length); // 打印创建的文件名 System.out.println("Create:" + filename); // 关闭FSDataOutputStream os.close(); // 关闭Hadoop文件系统连接 fs.close(); } catch (Exception e) { // 捕获并打印任何可能的异常 e.printStackTrace(); } } }
错误检验¶
- NameNode
-
HDFS设置了备份机制,把这些核心文件同步复制到备份服务器SecondaryNameNode上。当名称节点出错时,就可以根据备份服务器SecondaryNameNode中的FsImage和Editlog数据进行恢复。
-
DataNode
- 每个数据节点会定期向名称节点发送“心跳”信息,向名称节点报告自己的状态。
- 当数据节点发生故障,或者网络发生断网时,名称节点就无法收到来自一些数据节点的心跳信息,这时,这些数据节点就会被标记为“宕机”,节点上面的所有数据都会被标记为“不可读”,名称节点不会再给它们发送任何I/O请求。
- 名称节点会定期检查这种情况,一旦发现某个数据块的副本数量小于冗余因子,就会启动数据冗余复制,为它生成新的副本。
- 数据出错
- 网络传输和磁盘错误等因素,都会造成数据错误。
- 客户端在读取到数据后,会采用md5和sha1对数据块进行校验,以确定读取到正确的数据。
- 在文件被创建时,客户端就会对每一个文件块进行信息摘录,并把这些信息写入到同一个路径的隐藏文件里面。当客户端读取文件的时候,会先读取该信息文件,然后,利用该信息文件对每个读取的数据块进行校验,如果校验出错,客户端就会请求到另外一个数据节点读取该文件块,并且向名称节点报告这个文件块有错误,名称节点会定期检查并且重新复制这个块。
纠错¶
HDFS EC¶
- 通过对数据进行分块,然后计算出校验数据,使得各个部分的数据产生关联性。当一部分数据块丢失时,可以通过剩余的数据块和校验块计算出丢失的数据块。
- 节约存储空间,但是消耗网络带宽(获取其它数据块),消耗 CPU 资源
- RS(k,m)表示向量由k个数据块和m个校验块构成,最多可容忍m个块(包括数据块和校验块)丢失。
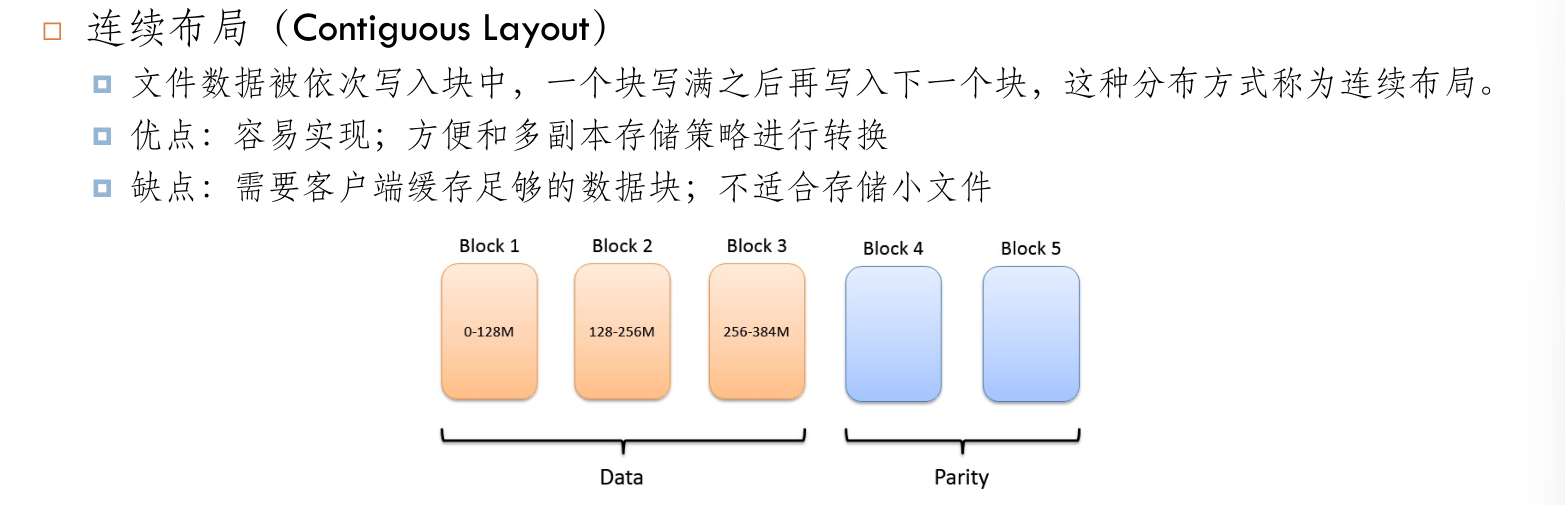
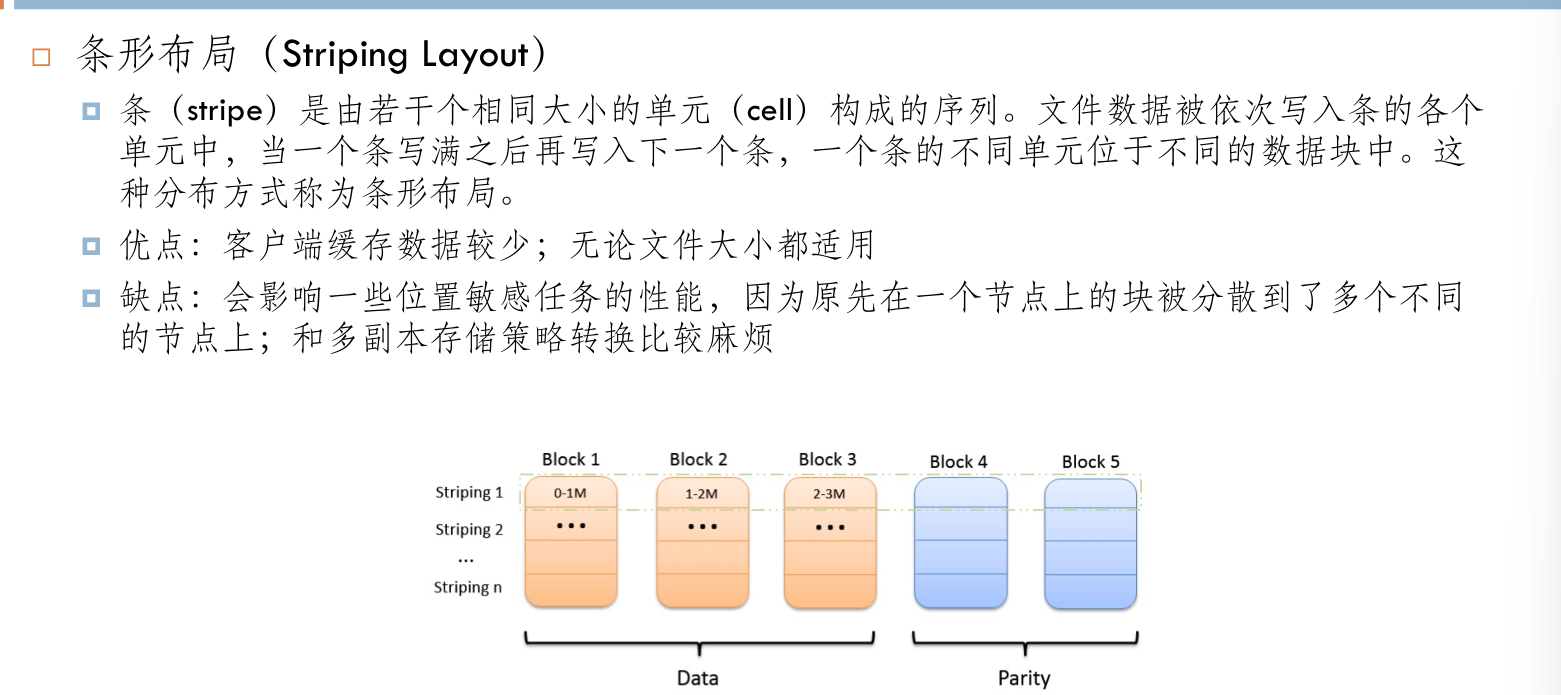
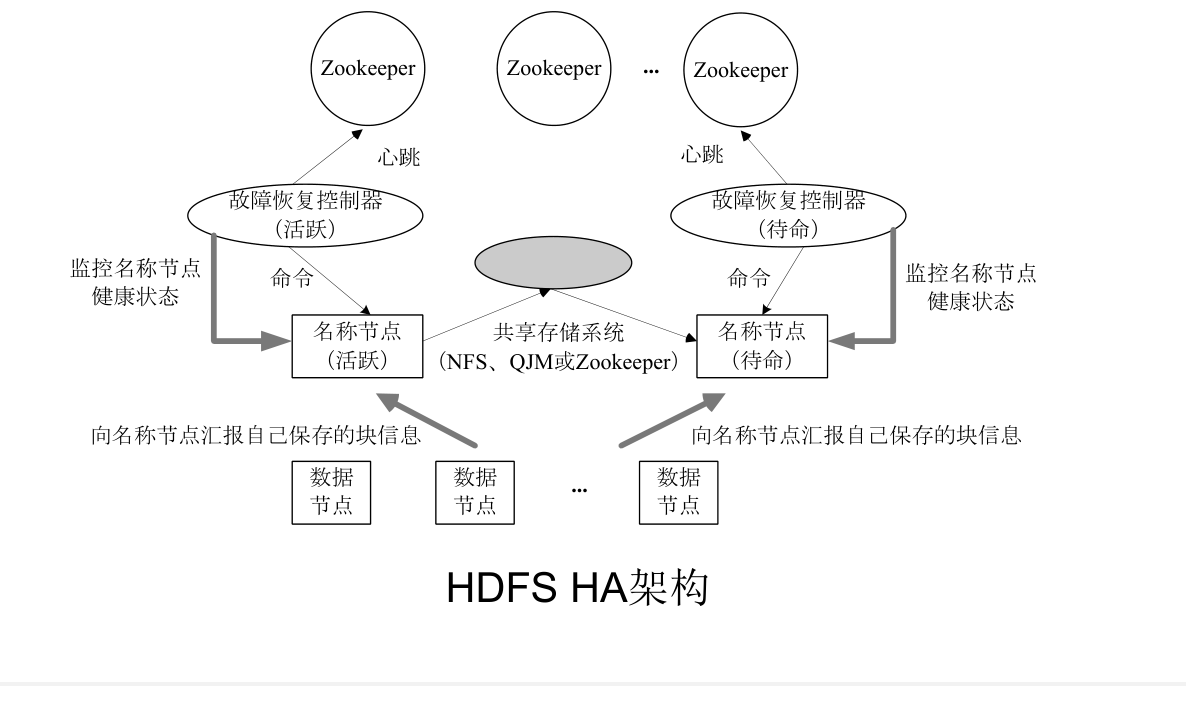
HDFS HA¶
- 为了解决单点故障问题,HA集群设置两个名称节点,“活跃”和“待命”
- 一旦活跃名称节点出现故障,就可以立即切换到待命名称节点,Zookeeper确保一个名称节点在对外服务,名称节点维护映射信息,数据节点同时向两个名称节点汇报信息
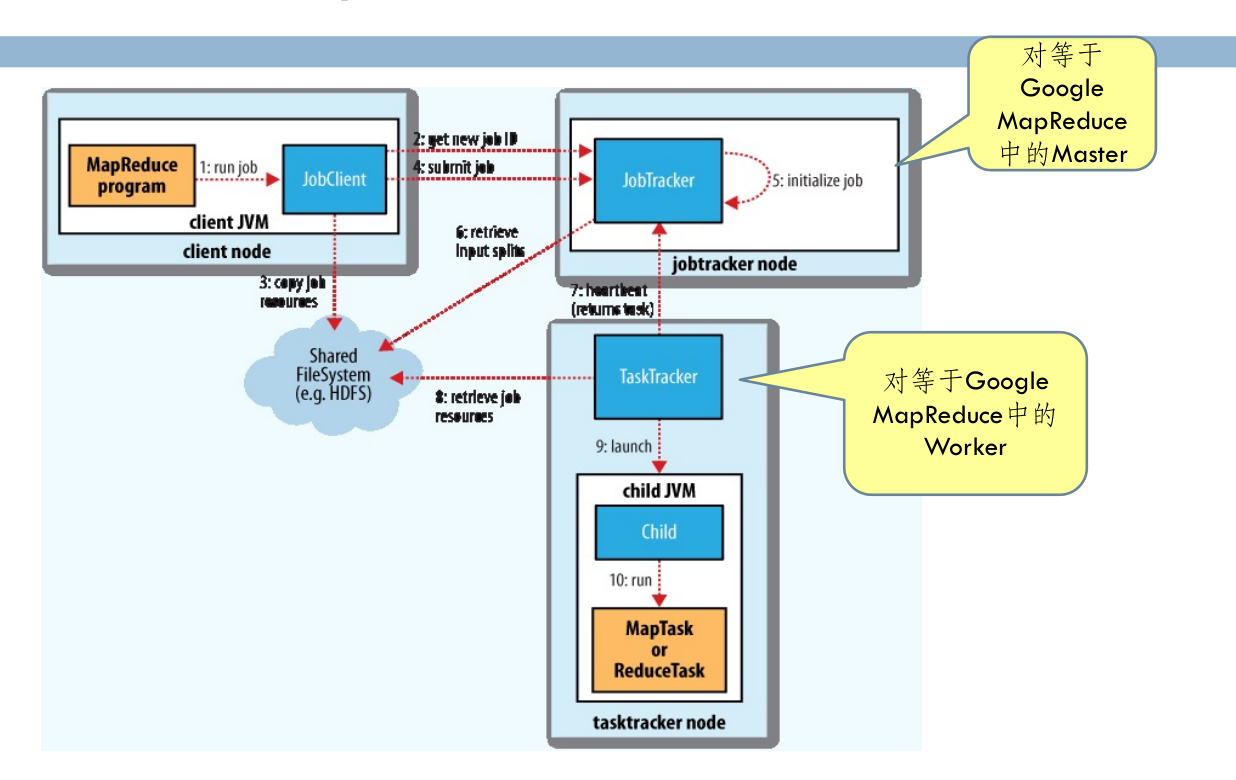
Hadoop MapReduce的基本工作原理¶
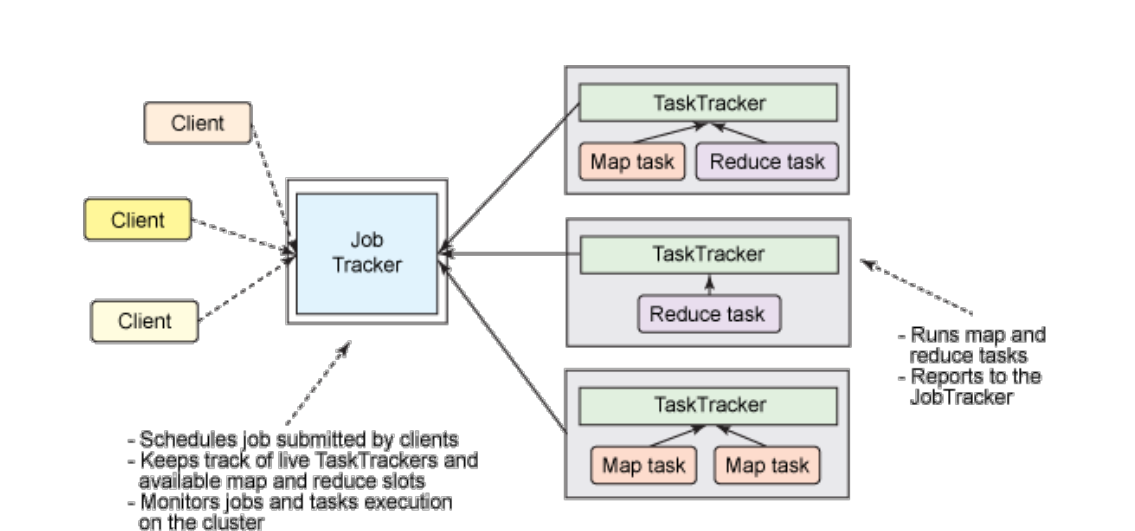
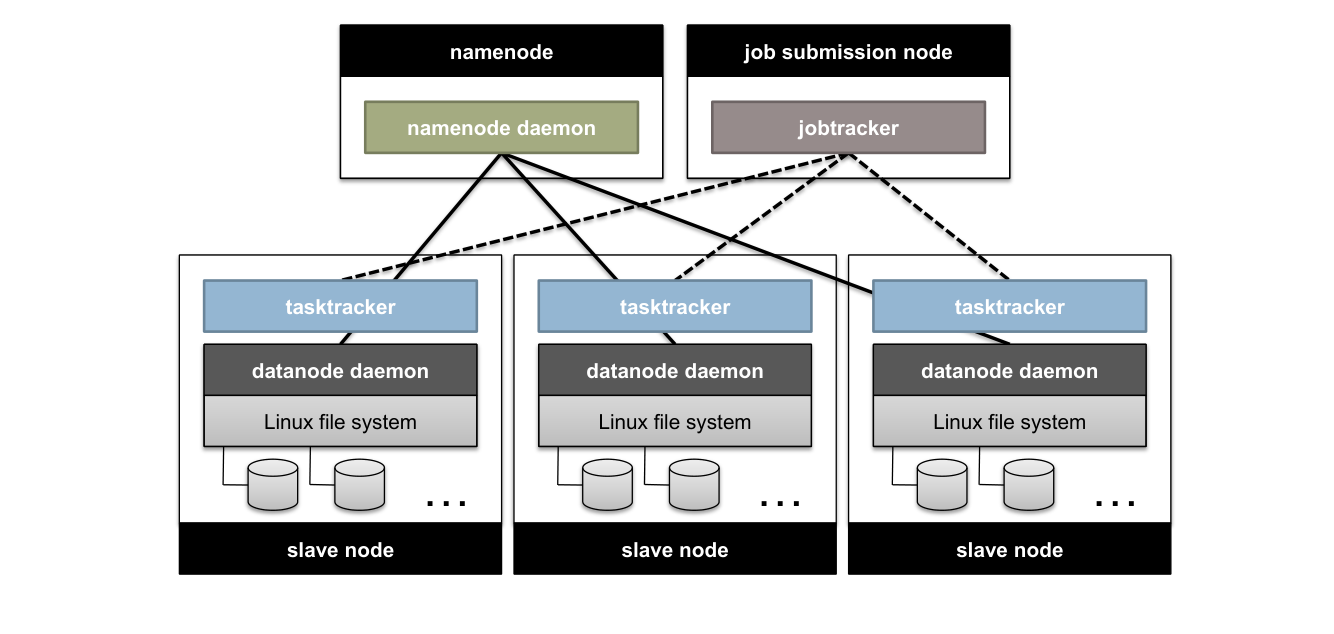

YARN¶
-
另一种资源协调者。它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
-
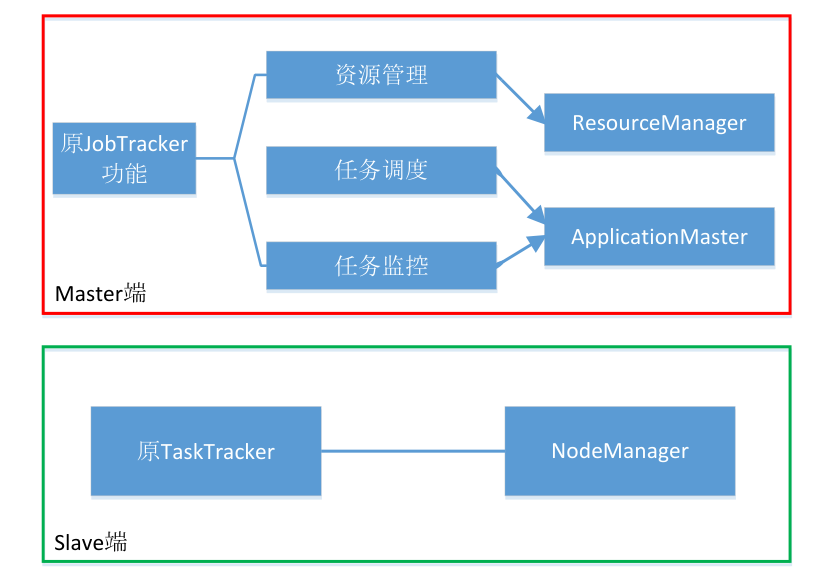
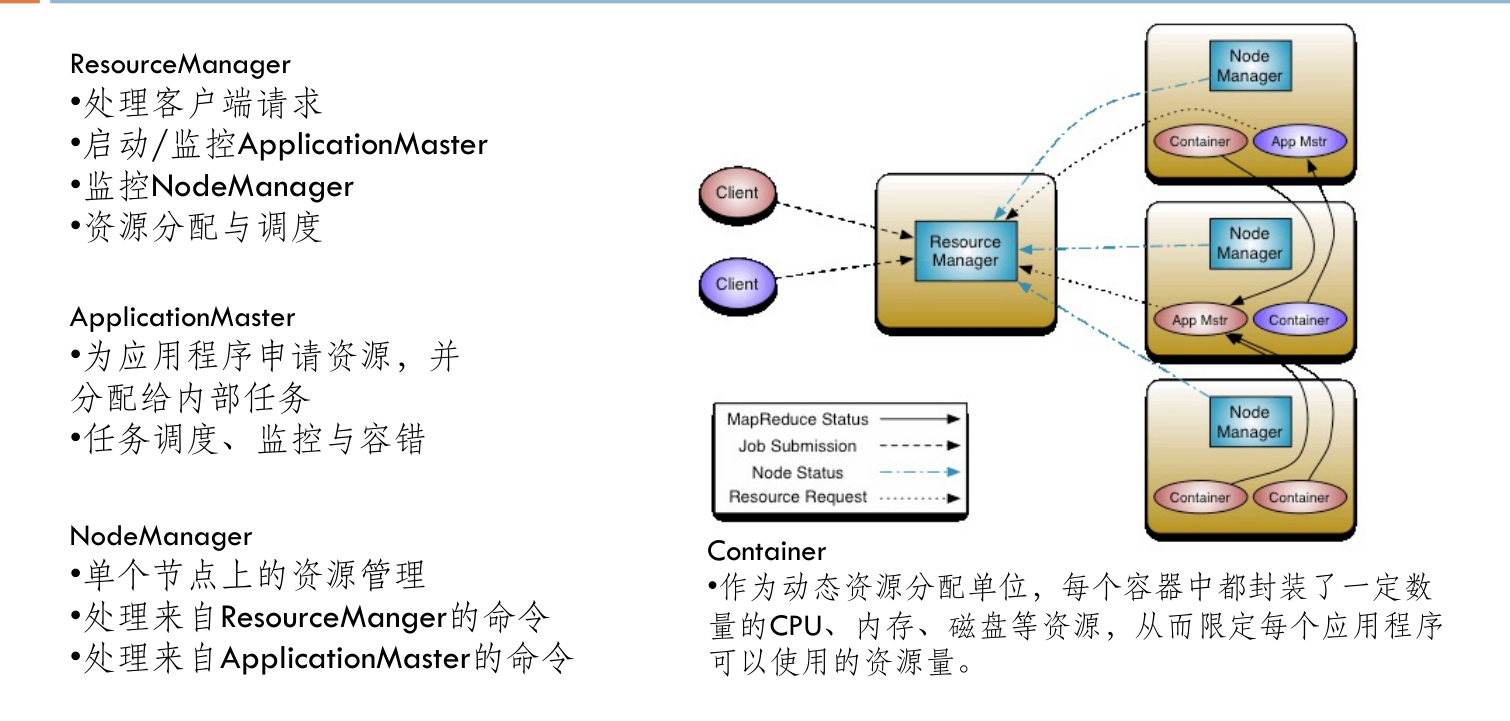
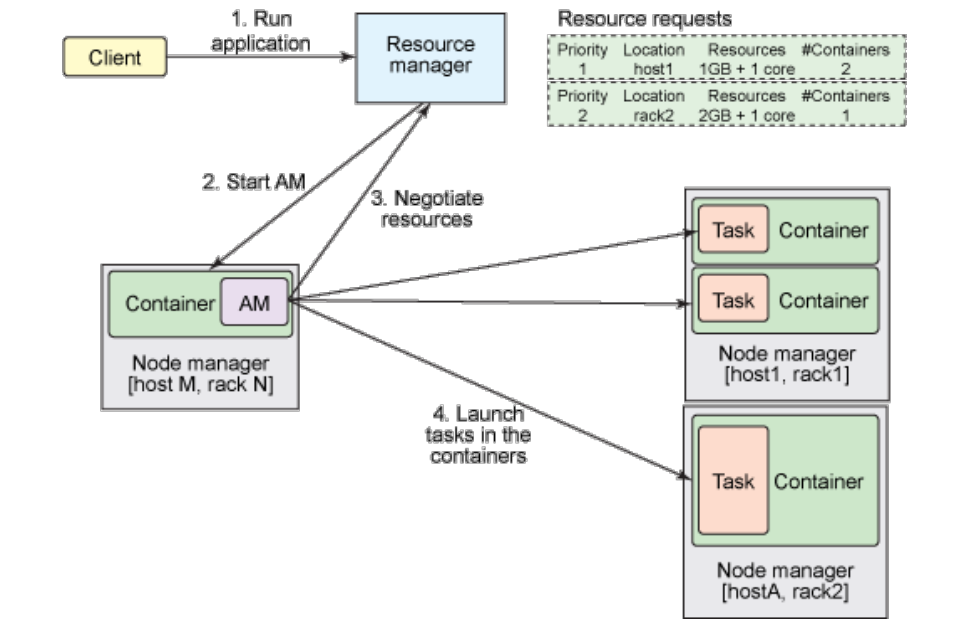
- 解决的问题:
- 更高的集群利用率,一个框架未使用的资源可由另一个框架进行使用,充分的避免资源浪费。
- 在新的Yarn中,通过加入ApplicationMaster是一个可变更的部分,用户可以针对不同的编程模型编写自己的ApplicationMaster,让更多的编程模型运行在Hadoop集群中。
- JobTracker一个很大的负担就是监控Job的tasks运行情况,现在,这个部分下放到了ApplicationMaster中。
- 设计目标:在一个集群上部署一个统一的资源调度管理框架YARN,在YARN之上可以部署其他各种计算框架。
- 实现:
- 由YARN为这些计算框架提供统一的资源调度管理服务,并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源共享和资源弹性收缩。
- 可以实现一个集群上的不同应用负载混搭,有效提高了集群的利用率。
- 不同计算框架可以共享底层存储,避免了数据集跨集群移动。
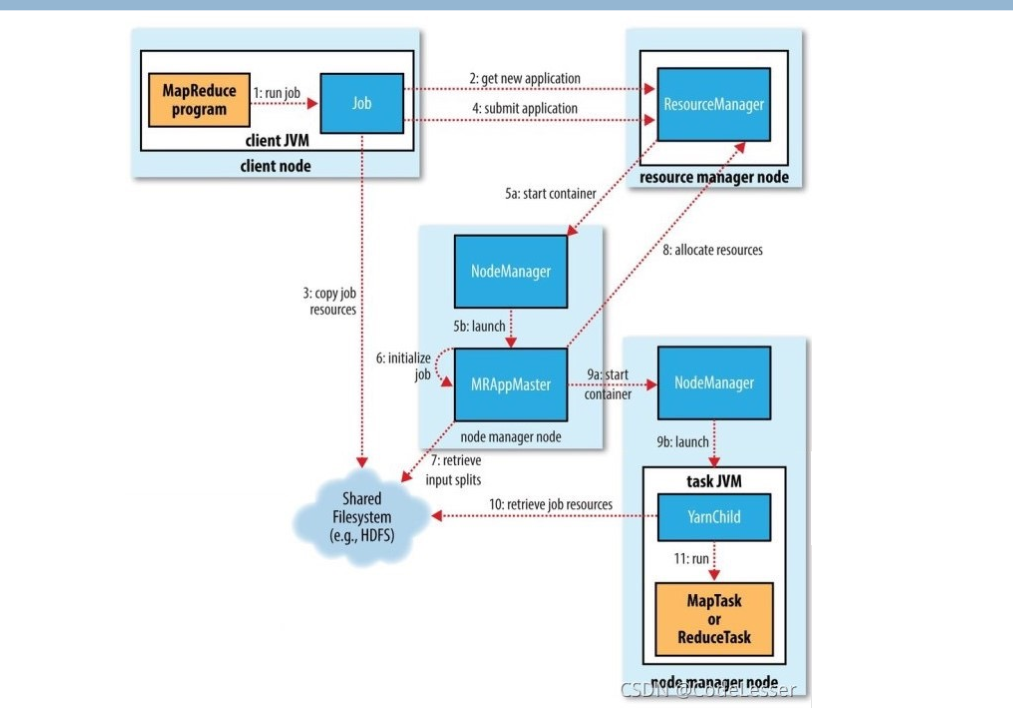
- YARN资源管理器(ResourceManager):YARN引入了ResourceManager,它是集群资源的主要调度和分配管理者。ResourceManager负责接收客户端提交的应用程序,为它们分配资源,并监控它们的运行情况。这使得集群资源的管理更加灵活,不仅限于MapReduce作业,还支持其他计算框架。
- NodeManager:每个集群节点上都运行着NodeManager,它负责监控节点上的资源使用情况,并报告给ResourceManager。NodeManager还负责启动和监控容器,容器是资源的抽象,可用于运行应用程序的不同组件,如Map任务和Reduce任务。
- 应用程序主管(ApplicationMaster):每个应用程序(例如,一个MapReduce作业)都有一个ApplicationMaster,它负责协调应用程序的执行。ApplicationMaster会与ResourceManager协商资源分配,监控任务的进度,并处理失败的任务。这种设计允许不同的应用程序有自己的资源管理器,以确保它们不会互相干扰。
- MapReduce框架:基于YARN的MapReduce框架与旧版MapReduce框架的编程模型基本相同,包括Map任务和Reduce任务。不过,它现在是建立在YARN之上的,通过ResourceManager和NodeManager来分配和管理资源。
- 支持多种应用程序:基于YARN的MapReduce架构不仅限于MapReduce作业。YARN可以支持各种不同的分布式应用程序,包括批处理、流处理、交互式查询等。这使得Hadoop集群成为一个通用的大数据计算平台。
- 灵活的资源管理:YARN允许更细粒度的资源管理,这意味着不同类型的任务可以获取不同数量和类型的资源。这种灵活性有助于更好地利用集群资源,提高了集群的利用率。
MapReduce编程¶
MapReduce 流水线¶
InputFormat¶
-
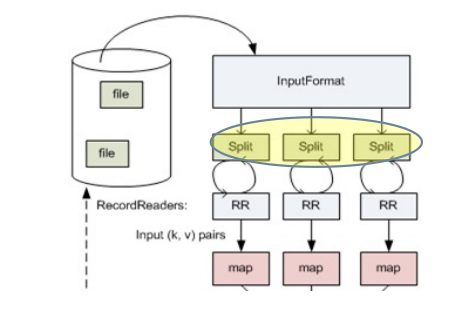
-
数据分片(Splitting):
- 定义数据如何分割和读取
InputFormat通常会将输入数据切分成多个块,称为InputSplit。每个InputSplit都会被分配给一个 Map 任务进行处理。-
InputSplit定义了输入到单个Map任务的输入数据
- HDFS 以固定大小的 block 为基本单位存储数据,而对于 MapReduce 而言,其处理单位是 split。(但是理想的 split 大小是 HDFS 的一个block)
- Hadoop为每个split创建一个Map任务,split 的多少决定了Map任务的数目。
-
记录读取器(Record Reader):
-
InputFormat提供了一个RecordReader实现,用于从InputSplit中读取数据,并将数据转换为键值对,输出到Mapper类中。 -
预定义的 InputFormat 类型:
-
Hadoop 提供了一些预定义的 InputFormat实现,这些实现可以处理常见的数据格式。
TextInputFormat:默认的InputFormat,每行文本都被视为一个记录。键是行的字节偏移量,值是整行文本。KeyValueTextInputFormat:每行都被视为一个键值对,键和值之间由制表符分隔。SequenceFileInputFormat:用于读取 SequenceFiles,这是一种特殊的二进制格式,适用于 Hadoop 的数据存储。
-
自定义 InputFormat:
- 如果内置的
InputFormat不能满足特定的数据格式需求,开发者可以实现自己的InputFormat。为此,需要扩展InputFormat类,并实现相应的方法,如切分数据和生成RecordReader等。
Mapper¶
- Mapper 处理由 InputFormat 产生的键值对,并生成中间键值对。
- 每一个 Mapper 类的实例生成了一个 Java 进程
- Mapper的输出(中间键值对)被存储在本地磁盘上,等待进一步的Shuffle和Sort阶段,然后传输给Reducer。
Combiner¶
- Combiner是一个可选的组件,用于作为Mapper的本地Reduce操作,以减少从Mapper到Reducer的数据传输量。
- Combiner 的功能与 Reducer 相似,但操作在 Mapper 的局部输出上,并产生一个 汇总后的中间键值对。
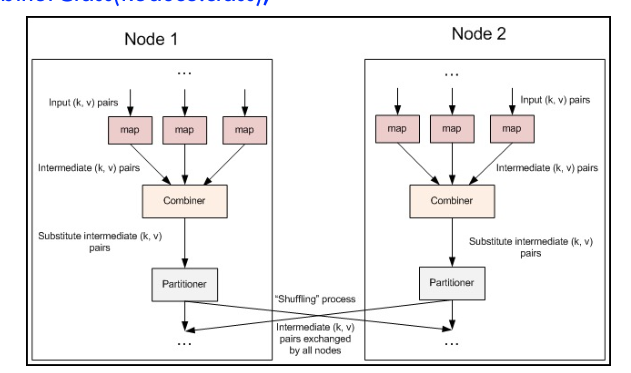
Partitioner & Shuffle¶
- 在 Map 工作完成之后,每一个 Map 函数会将结果传到对应的 Reducer 所在的节点,此时,可以提供一个Partitioner类,用来决定一个给定的(key,value)对传输的具体位置(传输到哪一个 reduce )。
-
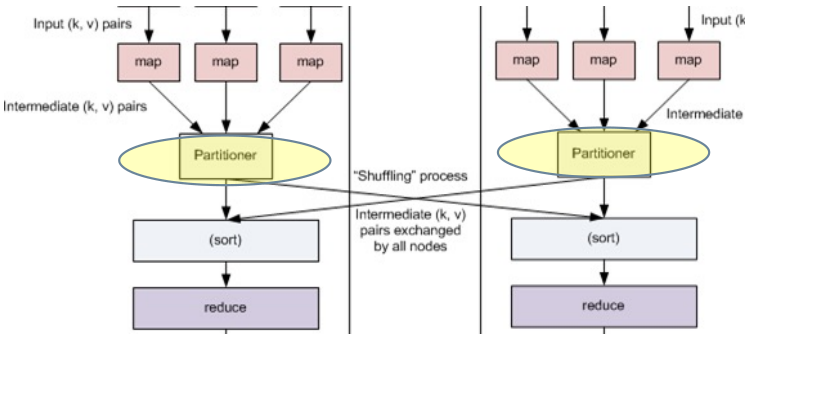
-
Shuffle过程实际执行这个数据传输工作,将 Mapper 的输出按照Partitioner的决策传输到合适的 Reducer。 - Shuffle过程
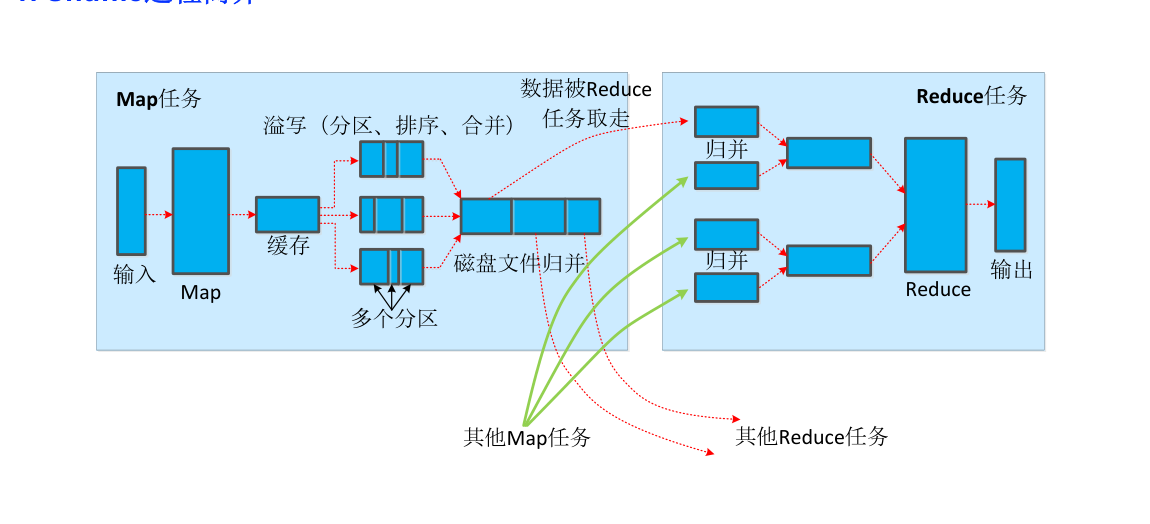
-
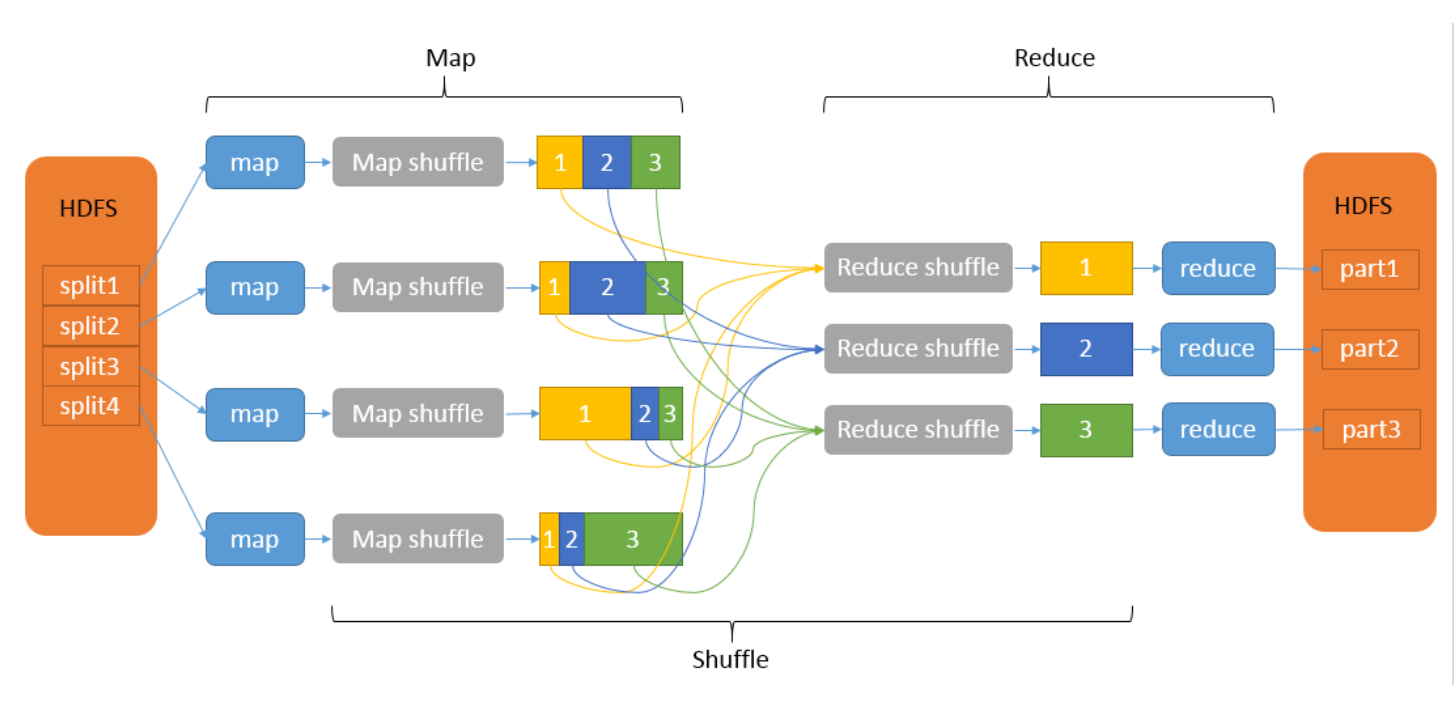
-
Shutter在map端
- 写缓存:
- 当 Map 任务开始处理数据并产生输出(即中间键值对)时,它们首先被写入一个内存缓存中。
- 溢出到磁盘:
- 当缓存快要满时,数据会被溢出写入磁盘,并且自动进行排序合并,依据 partion(哈希)写入到磁盘不同分区,清空缓存,为继续 map 提供空间
- 归并:
- 如果一个 Map 任务多次溢出,那么为一个特定的 Reducer 写入的数据可能分散在多个文件或段中。因此,当 Map 任务完成所有的数据处理后,Hadoop 将为每个 Reducer 归并这些多个文件或段。
- 文件归并时,如果溢写文件数量大于预定值(默认是3)则可以再次启动Combiner

-
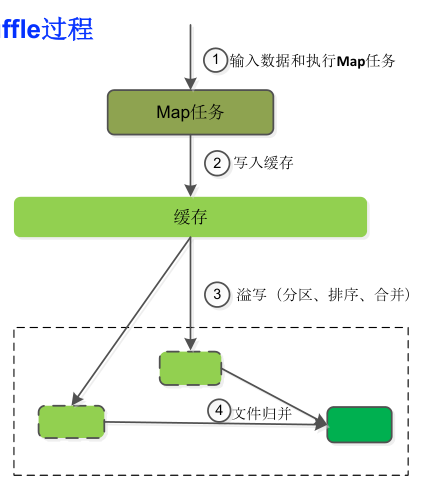
-
Shutter在reduce端
- 拉取阶段:
- Reduce 向 JobTracker 询问任务是否完成,如果完成则从每个 Map 任务节点上拉取为其生成的数据分区。
- 合并阶段:
- Reduce领取数据先放入缓存,来自不同Map机器,先归并,再合并,写入磁盘
- 多个溢写文件归并成一个或多个大文件,文件中的键值对是排序的
- 当数据很少时,不需要溢写到磁盘,直接在缓存中归并,然后输出给Reduce
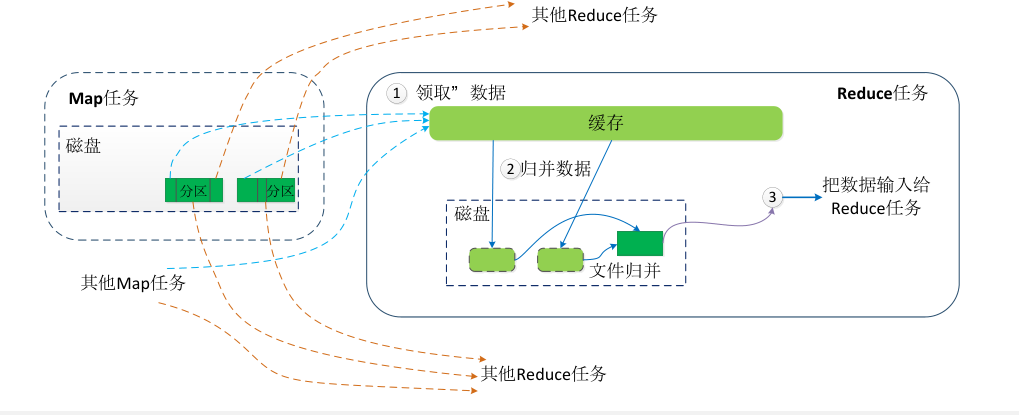
Sort¶
- 传输到每一个节点上的所有的Reduce函数接收到的(key,value)都会被Hadoop自动排序
- 该阶段确保中间键值对按键排序。这意味着当 Reducer 开始处理数据时,相同的键的所有值都是连续的。
Reduce¶
- 执行用户定义的Reduce操作
- 接收到一个OutputCollector的类作为输出
OutputFormat¶
- 记录写入方式:决定如何为每条记录分配存储位置和格式。
-
每一个Reducer都写一个文件到一个共同的输出目录,文件名是part-nnnnn,其中nnnnn是与每一个reducer相关的一个号
-
Hadoop 提供了多种预定义的
OutputFormat实现,包括: - TextOutputFormat:这是默认的 OutputFormat,它为每个键值对生成一行文本。键和值可以用制表符分隔。
- SequenceFileOutputFormat:输出的是 SequenceFile 格式的文件,适合于键值对的二进制表示。
-
MultipleOutputs:这允许 Reducer 为多个输出文件生成不同的格式。这对于多种输出类型的任务特别有用。
-
如果预定义的
OutputFormat不满足需求,也可以自定义OutputFormat。为此,需要继承OutputFormat类并实现其方法,如getRecordWriter、checkOutputSpecs等。
程序设计¶
hdfs基本使用¶
- 查看目录内容:
hdfs dfs -ls /path/in/hdfs
- 创建目录:
hdfs dfs -mkdir /path/in/hdfs
- 上传文件到HDFS:
hdfs dfs -put local-path /path/in/hdfs
- 从HDFS下载文件:
hdfs dfs -get /path/in/hdfs local-path
- 查看文件内容:
hdfs dfs -cat /path/in/hdfs/file
- 删除文件或目录:
hdfs dfs -rm /path/in/hdfs/file
hdfs dfs -rmdir /path/in/hdfs/dir
- 复制文件或目录:
hdfs dfs -cp /source/path /dest/path
- 移动文件或目录:
hdfs dfs -mv /source/path /dest/path
- 查看磁盘空间使用情况:
hdfs dfs -du /path/in/hdfs
- 查看磁盘空间配额和使用情况:
hdfs dfs -df /path/in/hdfs
Hadoop控制台¶
- HDFS:
- NameNode:50070 (Hadoop 2.x) / 9870 (Hadoop 3.x)
- Secondary NameNode:50090 (Hadoop 2.x) / 9868 (Hadoop 3.x)
- DataNode:50075 (Hadoop 2.x) / 9864 (Hadoop 3.x)
- YARN (Yet Another Resource Negotiator):
- ResourceManager:8088(当前/最近完成的任务)
- NodeManager:8042
- MapReduce JobHistory Server:
- 19888(历史任务)
- 需要手动开启
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
编译和运行¶
-
编辑
pow.xml设置依赖项<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-common</artifactId> <version>2.7.3</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.7.3</version> </dependency> </dependencies> -
需要为hadoop提供编译好的jar文件
-
编译并打包
javac src/*.java jar cvfe HelloWorld.jar HelloWorld src/*.class java -jar HelloWorld.jar ``` - 使用idea[windows下用idea编写wordcount单词计数项目并打jar包上传到hadoop执行_wordcount 打jar-CSDN博客](https://blog.csdn.net/weixin_42370346/article/details/88688693) - 使用hadoop运行 - 启动hadoop - 启动服务`start-all.sh` - 关闭`stop-all.sh` - 查看服务运行状态`jps` - 将输入文件放入HDFS:如果你的输入文件还没有在HDFS中,你需要首先使用`hadoop fs`命令将它们复制到HDFS。(一般放在/user/hadoop/) ```bash hadoop fs -mkdir -p /input-dir hadoop fs -put input.txt /input-dir/ -
行MapReduce作业:
hadoop jar p2t1.jar /user/hadoop/input/ /user/hadoop/output/ - 注意运行前输出文件夹要不存在
- 查看输出
hadoop fs -cat /output-dir/*
使用idea远程连接hadoop¶
- 下载和虚拟机版本相同的hadoop安装包解压放在英文路径,并添加到HADOOP_HOME
- HADOOP_USER_NAME设置hadoop用户名
- 将hadoop的/bin路径添加到path变量
- 使用
hadoop version检查 - 注意可能需要手动配置JAVA_HOME,版本太高可能不行(使用JDK11)
- 下载补充文件(3.0.0就行)steveloughran/winutils: Windows binaries for Hadoop versions (built from the git commit ID used for the ASF relase) (github.com)
- 将hadoop.dll添加到C:\Windows\System32
- 用下载的bin替换原先的
- idea下载bigdata插件
- 连接hadoop
- url使用集群/虚拟机ip
- 勾选启用隧道并配置ssh(连接虚拟机)
-
连接hdfs
-
地址为ip+端口
-
connectionError
- 在
core-site.xml文件中更改fs.defaultFS属性的值为Linux服务器的IP地址,例如hdfs://192.168.1.100:9000,然后重启Hadoop服务以使更改生效。
- 在
-
实现文件访问
-
将hadoop的两个xml文件拷贝到resources文件夹
- 同时新建
log4j配置文件
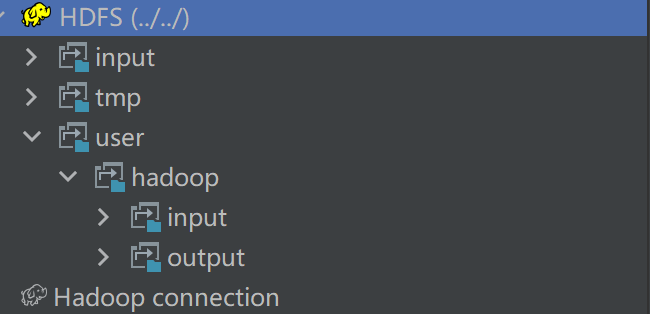
# Root logger option
log4j.rootLogger=INFO, stdout
# Redirect log messages to console
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
pom.xml(仅供参考,我使用的jdk11)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.lg</groupId>
<artifactId>MergeFiles</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.3</version>
</dependency>
<dependency>
<groupId>xalan</groupId>
<artifactId>xalan</artifactId>
<version>2.7.2</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>11</source>
<target>11</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
- 修改后要重新加载
- 配置运行文件(运行-编辑配置-创建maven)
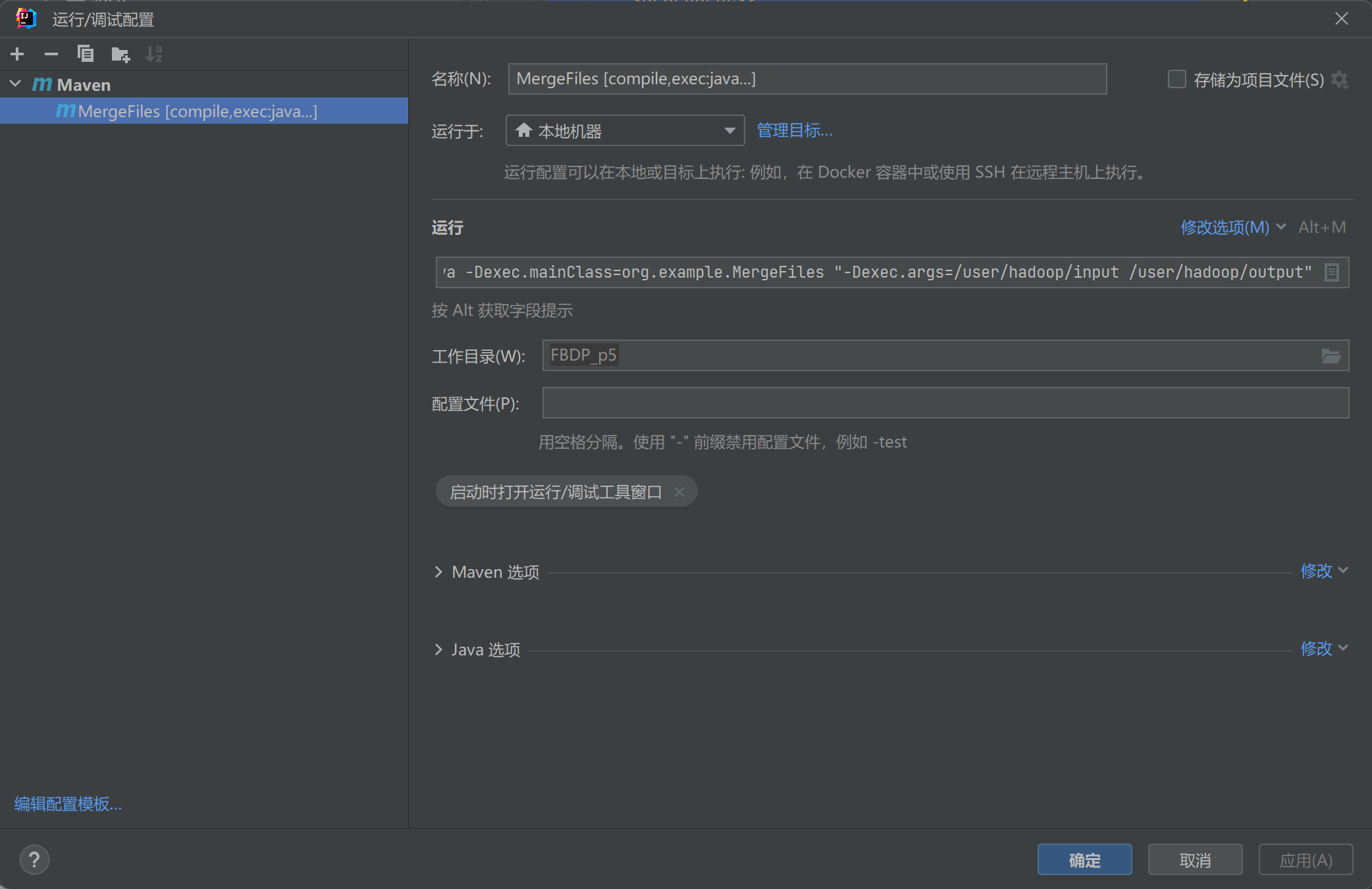
- 运行参数
compile exec:java -Dexec.mainClass=org.example.MergeFiles "-Dexec.args=/user/hadoop/input /user/hadoop/output"- 指出主类和输入输出路径
基本框架¶
- 主要需要实现 Map、Reduce 以及 main(负责运行 job)
- 数据类型
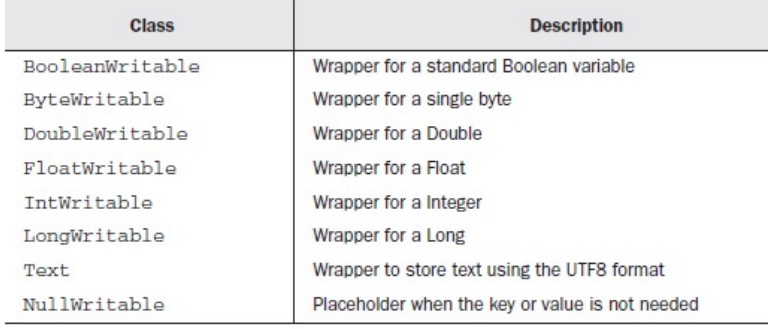
- LongWritable, IntWritable, Text 均是 Hadoop 中实现的用于封装 Java 数据类型的类,这些类都能够被串行化从而便于在分布式环境中进行数据交换,可以将它们分别视为 long, int, String 的替代。
- 使用
set get进行赋值和读取
public class WordCount {
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
// ... mapper code as before
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
// ... reducer code as before
}
public static void main(String[] args) throws Exception {
// ... driver code as before
}
}
Map实现¶
public static class TokenizerMapper
//定义Map类实现字符串分解
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
//实现map()函数
@Override
public void map(Object key, Text value, Context context)
throws IOException, InterruptedException {
//将字符串拆解成单词
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//将分解后的一个单词写入word
context.write(word, one);
//收集<key, value>
}
}
}
- 首先继承
public static class TokenizerMapper extends Mapper<LongWritable, Text, Text, IntWritable> - 这里的泛型参数表示输入输出的键-值类
- 实现(重写)map函数
public void map(Object key, Text value, Context context) - 每次获取一个键值对并将处理后的中间结果存储
context.write(键, 值);
Reduce实现¶
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@override
public void reduce(Text key, Iterable<IntWritable> values, Context context )
throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) { sum += val.get(); }
result.set(sum);
context.write(key, result);
}
}
- 实现reduce
- 输入参数中的(key,values) 是由 Map 任务输出的中间结果,values 是一个Iterator,遍历这个 Iterator,就可以得到属于同一个 key的所有value。(这是由归并造成的)
- reduce就是负责把这样的多个结果进行合并
生命周期函数¶
setup(Context context),这个方法在Mapper或Reducer任务开始之前执行,它只执行一次。- 它常用于一次性的初始化工作,如读取配置、设置计数器或从分布式缓存中读取文件。
cleanup(Context context)这个方法在Mapper或Reducer任务结束时执行,也只执行一次。
Main实现¶
- 在 Hadoop 中一次计算任务称之为一个 Job,main函数主要负责新建一个Job对象并为之设定相应的Mapper和Reducer类,以及输入、输出路径等。
public static void main(String[] args) throws Exception{ //为任务设定配置文件 Configuration conf = new Configuration(); //命令行参数 String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();//处理命令行参数。它将处理Hadoop的标准参数,并返回其他剩余的参数。 if (otherArgs.length != 2){//限制参数的数目(可以提供几种不同的模式) System.err.println("Usage: wordcount <in> <out>"); System.exit(2); }//检查是否提供了正确数量的命令行参数。 Job job = new Job(conf, “word count”); //新建一个用户定义的Job job.setJarByClass(WordCount.class);//指定包含该作业的JAR文件。 //设置执行任务的jar job.setMapperClass(TokenizerMapper.class); //设置Mapper类 job.setCombinerClass(IntSumReducer.class); //设置Combine类 job.setReducerClass(IntSumReducer.class); //设置Reducer类 //设置map的输出类型 job.setMapOutputKeyClass(IntWritable.class); job.setMapOutputValueClass(DoubleWritable.class); //设置reduce(结果)的输出类型 job.setOutputKeyClass(IntWritable.class); job.setOutputValueClass(Text.class); //设置输入文件的路径 FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //设置输出文件的路径 FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); //提交任务并等待任务完成 System.exit(job.waitForCompletion(true) ? 0 : 1); }
全局数据传递¶
-
分布式缓存原先是 Hadoop 的一个特性,允许用户在作业启动之前将文件、归档和符号链接有效地传播到每台机器的本地文件系统,以供 MapReduce 任务使用。
-
应用
- 数据本地化:确保任务可以快速访问其需要的数据而无需跨网络传输,提高了执行效率。
- 少量的、频繁使用的数据:如果你的 MapReduce 任务需要访问一个小而常用的查找表或字典,那么将这个文件放入分布式缓存是一个很好的选择。
-
代码或库的共享:如果你的任务依赖于某些动态链接库,你可以将其放入分布式缓存中以供所有任务使用。
-
传递键值对(通过配置文件进行传递)
- 传递
job.getConfiguration().setBoolean("wordcount.skip.patterns", true); -
获取
boolean skipPatterns = context.getConfiguration().getBoolean("wordcount.skip.patterns", false);- 通常在setup中进行读取
-

-
setStrings方法将把一组字符串转换为用“,”隔开的一个长字符串,然后getStrings时自动再根据“,”split成一组字符串,因此,在该组中的每个字符串都不能包含“,”,否则会出错。
-
传递文件
- 传递
job.addCacheFile(new Path("/path/to/myfile.txt").toUri()); -
获取
- 获取文件列表
Path[] localFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration()); - 从文件列表中获取文件
//使用文件名 for (Path localFile : localFiles) { if (localFile.getName().equals("myfile.txt")) { // 这是我们要查找的文件! } } //缓存文件时记录下表 job.getConfiguration().set("fileA.index", "0"); job.getConfiguration().set("fileB.index", "1"); ... int fileAIndex = context.getConfiguration().getInt("fileA.index", -1);//-1给出获取失败时的一个默认值
- 获取文件列表
-
直接根据文件名获取
context.getLocalCacheFiles(name) - 读取文件
BufferedReader br = new BufferedReader(new FileReader(localFiles[0].toString())); String line; while ((line = br.readLine()) != null) { // 处理每一行 } br.close();
自定义数据类型¶
- 必须实现WritableComparable接口
-
实现网络传输和文件存储以及进行大小比较
-
WritableComparable接口的实现示例
public class Point3D implements WritableComparable <Point3D>{ //数据存储 private int x, y, z; public int getX() { return x; } public int getY() { return y; } public int getZ() { return z; } //文件存储方式 public void write(DataOutput out) throws IOException{ out.writeFloat(x); out.writeFloat(y); out.writeFloat(z); } //从文件存储 public void readFields(DataInput in) throws IOException{ x = in.readFloat(); y = in.readFloat(); z = in.readFloat(); } //比较函数 public int compareTo(Point3D p){ //compares this(x, y, z) with p(x, y, z) and //outputs -1(小于), 0(等于), 1(大于) } } write(DataOutput out):序列化方法,用于将数据写入到输出流。readFields(DataInput in):反序列化方法,从输入流读取数据。-
compareTo(Object o):比较方法,用于比较两个键。 -
可选
- 重写
hashCode()和equals()方法
复合键值对¶
- 有时value的量较大无法在本地内存完成排序,可以将value中要排序的部分加入key构成复合键
- 需要自己实现Partitioner,保证相同key的键值要被分配到相同的Reduce结点
- 例子:带频率的倒排索
- 使用复合键
<item,docId>//符合键 public class CompositeKey implements WritableComparable<CompositeKey> { private Text word; private Text docId; public CompositeKey() { this.word = new Text(); this.docId = new Text(); } @Override public void write(DataOutput out) throws IOException { word.write(out); docId.write(out); } @Override public void readFields(DataInput in) throws IOException { word.readFields(in); docId.readFields(in); } @Override public int compareTo(CompositeKey other) { int result = word.compareTo(other.word); if (result == 0) { result = docId.compareTo(other.docId); } return result; } }
//Partitioner
//确保相同单词的所有键值对被分配到同一个 Reducer。
public class WordPartitioner extends Partitioner<CompositeKey, IntWritable> {
@Override
public int getPartition(CompositeKey key, IntWritable value, int numReduceTasks) {
return (key.getWord().hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
//Mapper
public class InvertedIndexMapper extends Mapper<Object, Text, CompositeKey, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private CompositeKey compositeKey = new CompositeKey();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
// 假设文档ID和内容由制表符分隔
String[] parts = value.toString().split("\t");
String docId = parts[0];
String[] words = parts[1].split("\\s+");
for (String word : words) {
compositeKey.setWord(word);
compositeKey.setDocId(docId);
context.write(compositeKey, one);
}
}
}
//Reducer
public class InvertedIndexReducer extends Reducer<CompositeKey, IntWritable, CompositeKey, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(CompositeKey key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
自定义输入输出类型¶
- 自定义输入
-
输入格式完成输入规范检查(比如输入文件目录的检查)、对数据文件进行输入分片,以及提供从输入分块中将数据记录逐一读出,并转换为Map过程的输入键值对等功能。
-
InputFormat
- 定义了输入数据被划分成 InputSplits(输入分片)的方式,以及用于读取这些分片的
RecordReader实例。每个InputSplit由一个单独的 Mapper 处理。
- 定义了输入数据被划分成 InputSplits(输入分片)的方式,以及用于读取这些分片的
-
RecordReader

- 从
InputSplit中提取输入记录。RecordReader的实现取决于InputFormat。例如,TextInputFormat的RecordReader会将输入数据划分为行,每行作为一个记录。 initialize(InputSplit split, TaskAttemptContext context):初始化RecordReader。nextKeyValue():读取下一个键值对。getCurrentKey()和getCurrentValue():返回当前读取的键和值。getProgress():记录读取的进度。
public class CustomInputFormat extends FileInputFormat<LongWritable, Text> {
@Override
public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) {
return new CustomRecordReader();
}
}
public class CustomRecordReader extends RecordReader<Text, Text> {
private Text key = new Text();
private Text value = new Text();
private boolean processed = false;
//会被自动调用
@Override
public void initialize(InputSplit split, TaskAttemptContext context) throws IOException {
FileSplit fileSplit = (FileSplit) split;
Path filePath = fileSplit.getPath();
key.set(filePath.getName());
Configuration conf = context.getConfiguration();
FileSystem fs = filePath.getFileSystem(conf);
BufferedReader br = new BufferedReader(new InputStreamReader(fs.open(filePath)));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
sb.append(line).append("\n");
}
value.set(sb.toString());
br.close();
}
//下面不恰当,key一致时一个,但value应该返回一个单词
@Override
public boolean nextKeyValue() {
if (!processed) {
processed = true;
return true;
}
return false;
}
@Override
public Text getCurrentKey() {
return key;
}
@Override
public Text getCurrentValue() {
return value;
}
@Override
public float getProgress() {
return processed ? 1.0f : 0.0f;
}
@Override
public void close() {
// 通常用于关闭打开的资源,这里不需要实现
}
}
- 还需要在job指定类进行配置
-
job.setInputFormatClass(FileNameLocInputFormat.class); -
自定义输出
- 数据输出格式用于描述MapReduce作业的数据输出规范。
-
OutputFormat
- 确定如何写入输出数据。确保输出目录的正确设置(例如,创建或清理输出目录)和实例化适当的
RecordWriter。import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class MyCustomOutputFormat extends FileOutputFormat<KeyType, ValueType> { @Override public RecordWriter<KeyType, ValueType> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException { // 创建并返回自定义 RecordWriter return new... } }
- 确定如何写入输出数据。确保输出目录的正确设置(例如,创建或清理输出目录)和实例化适当的
-
RecordWriter
-
将
Reducer的输出写入到输出文件。在自定义RecordWriter类时,你需要实现write方法来定义如何处理输出键值对,以及close方法来定义清理过程。import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import java.io.IOException; public class MyCustomRecordWriter extends RecordWriter<KeyType, ValueType> { public MyCustomRecordWriter(/* 你的构造器参数 */) { // 初始化代码 } @Override public void write(KeyType key, ValueType value) throws IOException, InterruptedException { // 定义如何输出键值对 } @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { // 清理资源,如关闭文件流 } } -
MultipleOutputs
- 在传统的 MapReduce 作业中,无论 Map 或 Reduce 阶段的输出都只能被写入到一个指定的输出目录。
-
使用
MultipleOutputs,可以根据需要将数据写入多个文件或目录,甚至可以对每个输出记录使用不同的OutputFormat。public static class CreateReducer extends Reducer<Text, Text, Text, Text> { static MultipleOutputs<Text, Text> multipleOutputs; //创建 @Override protected void setup(Context context) throws IOException, InterruptedException { multipleOutputs = new MultipleOutputs<>(context); } @Override protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { //key,val,name(输出路径) for(Text value : values) { multipleOutputs.write(value, new Text(), key.toString()); } } //关闭 @Override protected void cleanup(Context context) throws IOException, InterruptedException { multipleOutputs.close(); } } -
MultipleOutputFormat
- 允许为每个Reducer任务定义一个不同的OutputFormat。这意味着你可以为每个Reducer任务指定不同的输出目录和输出文件格式。
- 在job中绑定
job.setOutputFormatClass(MyCustomOutputFormat.class);
自定义Partitioner和Combiner¶
- Partitioner
public class WordPartitioner extends Partitioner<CompositeKey, IntWritable> { @Override public int getPartition(CompositeKey key, IntWritable value, int numReduceTasks) { return (key.getWord().hashCode() & Integer.MAX_VALUE) % numReduceTasks; } } - 改变Map中间结果到Reduce节点的分区方式
-
在job中设置
Job. setPartitionerClass(NewPartitioner) -
Combiner
- Combiner是一种用于在Map任务输出数据传递给Reduce任务之前进行本地聚合的机制。它可以减少数据传输到Reduce任务的数据量,从而提高性能。
public static class NewCombiner extends Reducer < Text, IntWritable, Text, IntWritable > { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //去除重复项 context.write(key, new IntWritable(1)); } } - 在MapReduce中,Combiner类实际上应该与Reducer类有相同的签名,因为Combiner和Reducer都执行聚合操作。
- 设置
job.setCombinerClass(IntSumCombiner.class); - 重写Combiner主要是为了性能的提升,即在Map之后Reduce之前执行一个局部的Reduce
- 减少网络传输:通过使用 Combiner,可以在 Map 阶段的节点上对数据进行局部聚合,从而减少需要传输的数据量。
- 减轻 Reducer 负担: Reducer 需要处理的数据量更小,从而减轻了其负担。
- 提高总体处理速度:通过减少网络传输和 Reducer 的数据处理量,Combiner 有助于提高整个 MapReduce 作业的处理速度。
- Combiner不应该改变Map的键值格式
迭代MapReduce¶
- 一些求解计算需要用迭代方法求得逼近结果(求解计算必须是收敛性的)。
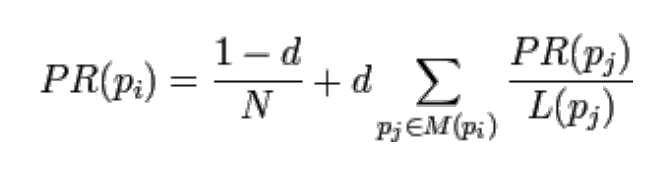
- 这是一个递归式,无法直接进行计算
- 可以先给未知未知的 \(PR(p_j)\) 一个假定的值如 \(0.5\) 用求出的 PR 值反复进行迭代计算时,会 越来越趋近于最终的准确结果。
-
需要用迭代方法循环运行 MapReduce 过程,直至第 n 次迭代后的结果与第 n-1次的结果小于某个指定的阈值时结束,或者通过经验控制循环固定的次数。
-
第一次迭代:
- 编写一个MapReduce程序,用于执行算法的第一次迭代。这个程序包括Map和Reduce阶段,负责处理输入数据并生成中间结果。
-
在驱动程序中配置 MapReduce 任务,设置输入路径和输出路径。
-
迭代阶段:
- 在每次迭代中,使用前一次迭代的输出作为下一次迭代的输入。
-
在每次迭代中,执行与前一次迭代不同的 MapReduce 任务,以便进行下一轮的处理。这些 MapReduce 任务可以包括 Map、Reduce 和 Combiner 等。
-
控制迭代次数:
-
为了控制迭代次数,以在驱动程序中设置一个循环,直到满足停止条件为止。
-
输出结果:
- 在最后一轮迭代后,输出结果将包含算法的最终结果。
链式MapReduce任务¶
- 一些复杂任务难以用一趟MapReduce处理过程来完成,需要将其分为多趟简单些的MapReduce子任务完成。
- 将这些子任务串起来,前面 MapReduce 任务的输出作为后面 MapReduce 的输入,自动地完成顺序化的执行
-
链式MapReduce中的每个子任务需要独立的jobconf,并按照前后子任务间的输入输出关系设置输入输出路径,而任务完成后所有中间过程的输出结果路径都可以删除掉
-
具有两个结果的链
public static void main(String[] args) throws Exception { Configuration conf1 = new Configuration(); Job job1 = Job.getInstance(conf1, "First MapReduce"); // 配置第一个MapReduce任务的输入路径、输出路径、Mapper类、Reducer类等 Configuration conf2 = new Configuration(); Job job2 = Job.getInstance(conf2, "Second MapReduce"); // 配置第二个MapReduce任务的输入路径、输出路径、Mapper类、Reducer类等 // 连接任务 ControlledJob firstJob = new ControlledJob(conf1); firstJob.setJob(job1); ControlledJob secondJob = new ControlledJob(conf2); secondJob.setJob(job2); secondJob.addDependingJob(firstJob); // 第二个任务依赖于第一个任务的完成 // 驱动程序中执行任务 JobControl jobControl = new JobControl("Chained MapReduce"); jobControl.addJob(firstJob); jobControl.addJob(secondJob); Thread jobControlThread = new Thread(jobControl); jobControlThread.start(); while (!jobControl.allFinished()) { Thread.sleep(1000); } } -
这种方法可以并行执行,对于较为简单的程序直接按顺序执行 mapreduce 任务即
-
链式执行map/reduce
- 把这些前后处理步骤实现为一些辅助的Map和Reduce过程
- 效率更高
- ChainMapper
- 连接多个 Mapper 任务,以便它们按照指定的顺序依次执行。每个 Mapper 可以接受上一个 Mapper 的输出作为输入,并将其处理后的输出传递给下一个 Mapper,从而创建一个 Mapper 任务链。
- 配置:
- 创建各个 Mapper 类:定义每个 Mapper 类,实现
Mapper接口中的map方法,以完成数据处理逻辑。 - 创建 Mapper 链:使用
ChainMapper创建 Mapper 任务链,并指定每个 Mapper 类的顺序。 - 配置作业:在驱动程序中配置 MapReduce 作业,并将
ChainMapper对象设置为作业的 Mapper。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
public class ChainedMapExample {
public static class Mapper1 extends Mapper<LongWritable, Text, Text, IntWritable> {
// Mapper 1 的实现
// ...
}
public static class Mapper2 extends Mapper<Text, IntWritable, Text, IntWritable> {
// Mapper 2 的实现
// ...
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Chained Map Example");
// 创建 ChainMapper,并指定 Mapper 1 和 Mapper 2 的顺序
ChainMapper.addMapper(job, Mapper1.class, LongWritable.class, Text.class, Text.class, IntWritable.class, conf);
ChainMapper.addMapper(job, Mapper2.class, Text.class, IntWritable.class, Text.class, IntWritable.class, conf);
// 配置作业的输入路径、输出路径、Reducer 类等
job.setJarByClass(ChainedMapExample.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.setReducerClass(Reducer.class); // 如果没有 Reduce 阶段,则设置为 Reducer.class
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
- 在reduce之后添加map
JobConf reduceConf = new JobConf(false); ChainReducer.setReducer(job, Reduce.class, LongWritable.class, Text.class, Text.class, Text.class, true, reduceConf); JobConf map3Conf = new JobConf(false); ChainReducer.addMapper(job, Map3.class, Text.class, Text.class, LongWritable.class, Text.class, true, map3Conf); JobConf map4Conf = new JobConf(false); ChainReducer.addMapper(job, Map4.class, LongWritable.class, Text.class, LongWritable.class, Text.class, true, map4Conf); JobClient.runJob(job);
补充¶
- 通过Configuration对象获取数据
- 输入输出到关系数据库
- OLTP:联机事务处理:主要是关系数据库应用系统中前台常规的各种事务处理
- OLAP: 联机分析处理:主要是进行基于数据仓库的后台数据分析和挖掘,提供优化的客户服务和运营决策支持
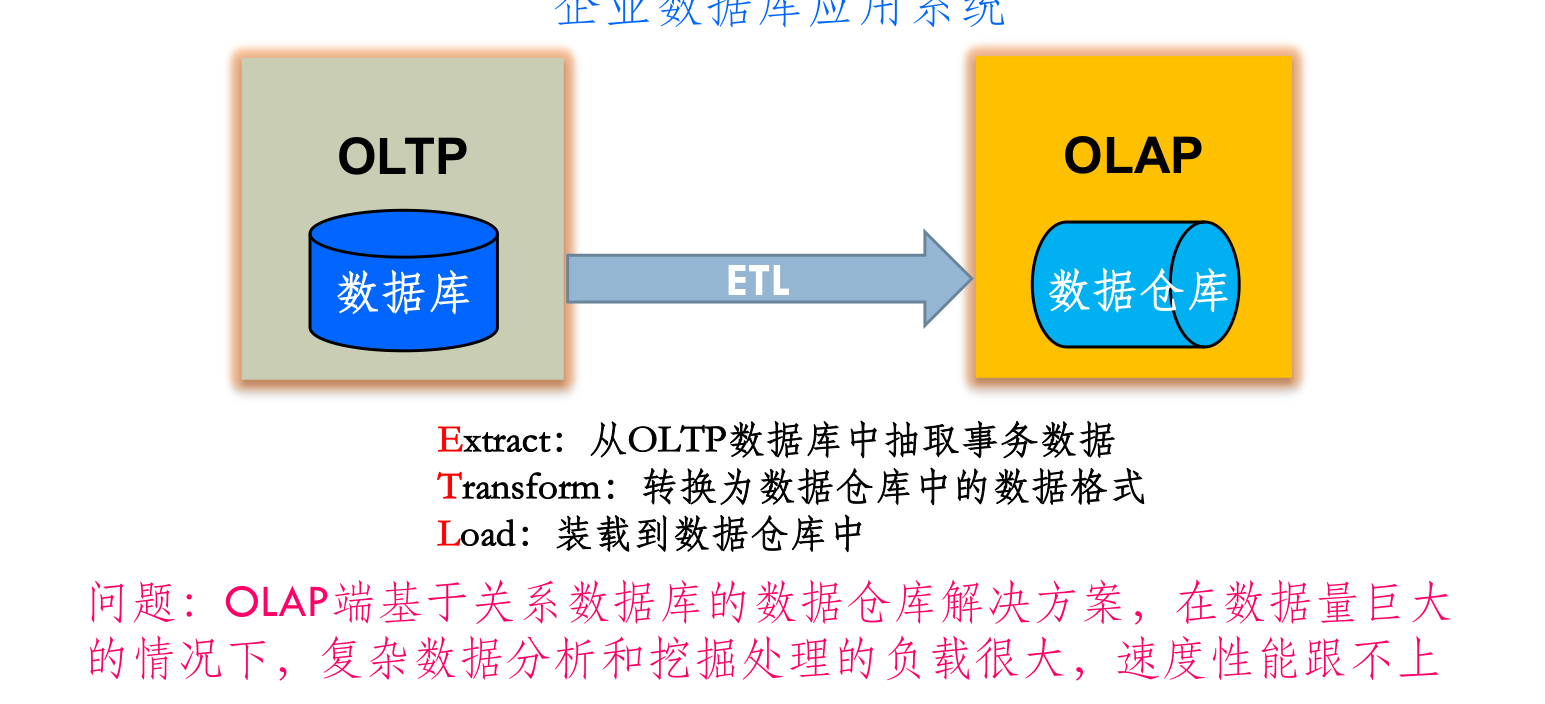
- 解决方案:提供基于MapReduce大规模数据并行处理的OLAP
- Hadoop提供了相应的从关系库查询和读取数据的接口
案例应用¶
难点¶
矩阵乘法¶
- 数据输入:
A 1 1 1 A 1 2 2 A 2 1 3 A 2 2 4 B 1 1 5 B 1 2 6 B 2 1 7 B 2 2 8 -
可以直接使用TextInputFormat读取并获取每一个元素
-
map:
- 输入格式
(matrixID,i,j,value)matrixID是 'A' 或 'B',用于区分两个矩阵。i和j是行号和列号。value是该位置的值。
-
根据输入可以很容易的找到需要用到这个点计算的位置,可以把目标点作为键,
- 如 中的每一个元素 (i, j, value) 会为每个可能的 k 产生一个中间键值对
<(i,k),(A,j,value)>
- 如 中的每一个元素 (i, j, value) 会为每个可能的 k 产生一个中间键值对
-
reduce:

- 合并时对键相同的排序,(j 相同的)相乘、相加就可以得到结果

关系代数运算¶
-
并集 (Union) 目标:合并两个关系的元组,消除重复。
public static class UnionMapper extends Mapper<Object, Text, Text, NullWritable> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException { context.write(value, NullWritable.get()); } } public static class UnionReducer extends Reducer<Text, NullWritable, Text, NullWritable> { public void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key, NullWritable.get()); } } -
差集 (Difference) 目标:从一个关系中选择不在另一个关系中的元组。
-
笛卡尔积 (Cartesian Product)

-
连接(Join)

排序算法¶
- TeraSort 是一种专为 MapReduce 框架优化的排序算法,用于高效地对极大规模的数据集进行排序。
- TeraSort 在 Map 阶段开始之前进行采样操作,以确定数据的分布情况。根据采样结果,TeraSort 创建分区。每个 Reducer 负责一个分区的排序,确保数据在 Reducers 之间均匀分布。(TotalOrderPartitioner)
- 假设有N个reducer,则取得N-1个分割点
- 高效的划分模型:对可以逐字节比较的元素(数字、字符串)可以使用字典树进行快速划分
- Map 阶段的任务是读取输入数据并根据分区规则输出键值对。
- Reduce 阶段的任务是对每个分区进行局部排序并输出结果。
二级排序¶
- 如以
<(left,right),right>对pair键进行排序 - 需要自定义key、Partitioner、比较等
单词同现分析算法¶
- 如有 N 个单词,则同现矩阵是一个 N*N 矩阵
- \(M[i,j]\)表示\(W[i]\)与单词\(W[j]\)在一定范围内同现的次数
 、
、- 可以使用WordPair自定义键,表示单词对,在reduce统计求和即可
- 根据同现关系的要求(段落、句子)需要使用不同的 FileInputFormat 和 RecordReader(一次读取一行、一段...)



文档倒排索引算法¶
-
给出一个词,取得含有词的文档列表
-
离线处理
- 爬网(Crawling):收集数据内容
-
索引(Indexing):创建一个反向索引的过程,这个索引允许快速查找包含特定词汇的文档。提取关键词或短语,并构建一个数据结构(通常是反向索引),使得给定一个查询词,可以快速找到包含该词的所有文档。
-
在线查找
-
检索(Retrieval):当用户输入一个查询时,检索系统会查找索引,找到所有相关的文档,并根据一定的排名算法对这些文档进行排序。
-
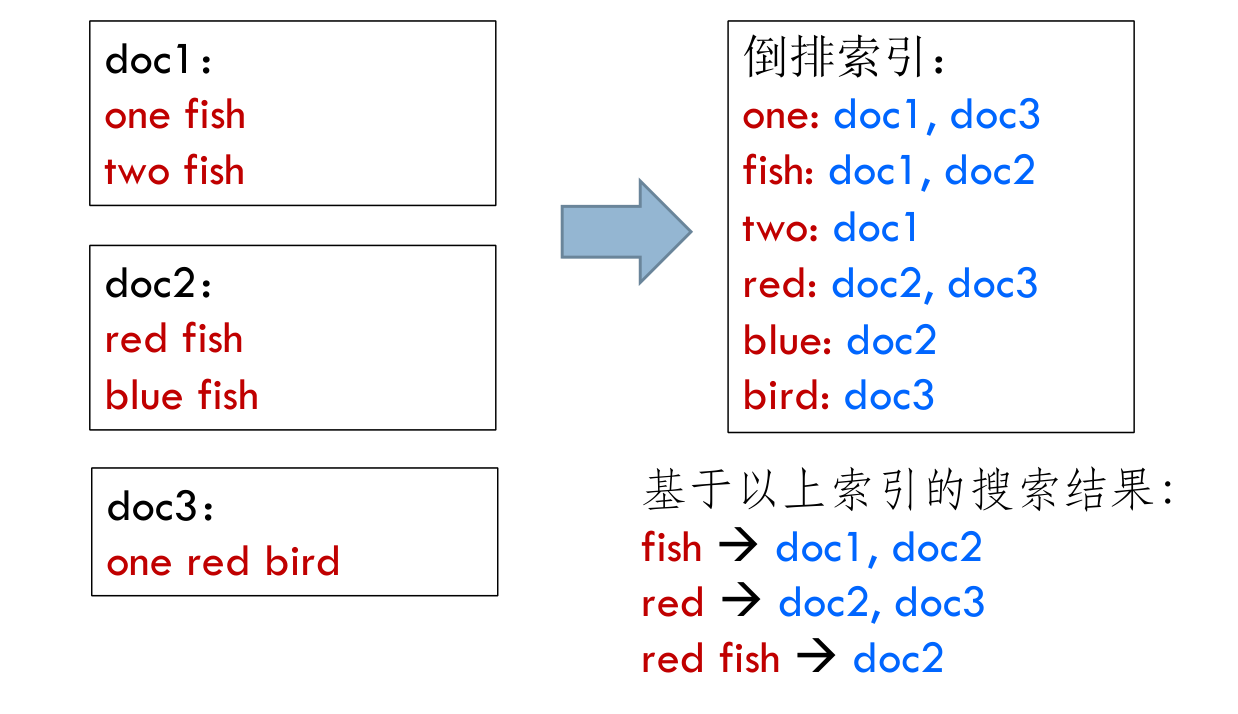
-
简单实现
- Map 阶段:读取文档,对每个单词输出
<(word), (documentId)>。 - Reduce 阶段:合并所有单词的文档列表,并输出
<(word), (list of documentIds)>。
public class InvertedIndexMapper extends Mapper<Object, Text, Text, Text> {
private Text documentId;
private Text word = new Text();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
//从当前分片中获取文件名信息
String filename = ((FileSplit) context.getInputSplit()).getPath().getName();
documentId = new Text(filename);
}
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] tokens = value.toString().split("\\s+");
for (String token : tokens) {
word.set(token);
context.write(word, documentId);
}
}
}
public class InvertedIndexReducer extends Reducer<Text, Text, Text, Text> {
@Override
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//对文档列表去重
Set<String> documentIds = new HashSet<>();
for (Text value : values) {
documentIds.add(value.toString());
}
context.write(key, new Text(String.join(", ", documentIds)));
}
}
public class InvertedIndexDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Inverted Index");
job.setJarByClass(InvertedIndexDriver.class);
job.setMapperClass(InvertedIndexMapper.class);
job.setReducerClass(InvertedIndexReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
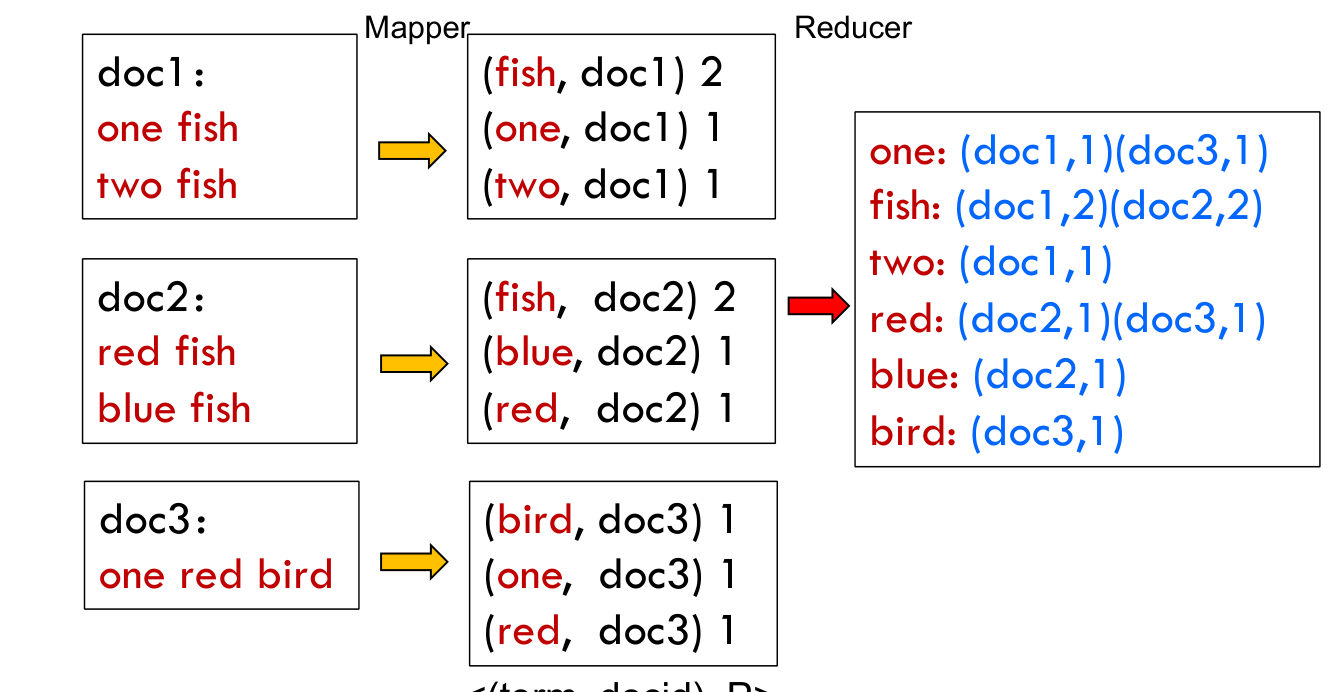
带有词频等属性的文档倒排算法¶
- 考虑单词在每个文档中出现的词频、位置、对应Web文档的URL等诸多 属性
- 如以\
专利文献数据分析¶
- 文章引用关系

- 每个专利的详细内容
-

-
专利被引用统计
public static class MapClass extends Mapper<LongWritable, Text, Text, Text> { public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException // 输入key: 行偏移值;value: “citing专利号, cited专利号” 数据对 { String[] citation = value.toString().split(“,”); context.write(new Text(citation[1]), new Text(citation[0])); } // 输出key: cited 专利号;value: citing专利号 } public static class ReduceClass extends Reducer<Text, Text, Text, Text> { public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { String csv = “”; for (Text val:values) { if (csv.length() > 0) csv += “,”; csv += val.toString(); } context.write(key, new Text(csv)); } // 输出key: cited专利号;value: “citing专利号1, cited专利号2,…” }
综合:搜索引擎算法¶
PageRank¶
-
由搜索引擎根据网页之间相互的超链接计算的网页排名技术。PR 值越高说明该网页越受欢迎
-
基本思想:
- 一个网页要想拥有较高的PR值的条件:
- 有很多网页链接到它 (数量假设)
- 有高质量的网页链接到它(质量假设)
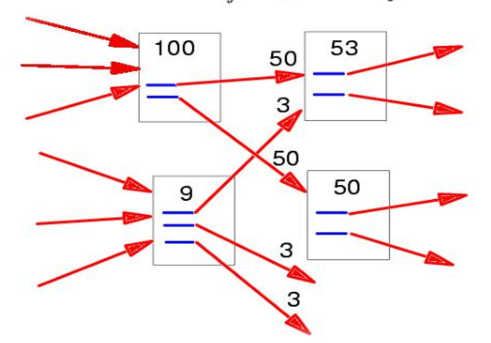
- 如果网页T存在一个指向网页A的连接,则把T的一部分重要性得分赋予A。\(R(T)/L(T)\)
- 即T 的 PR 值除以出链数
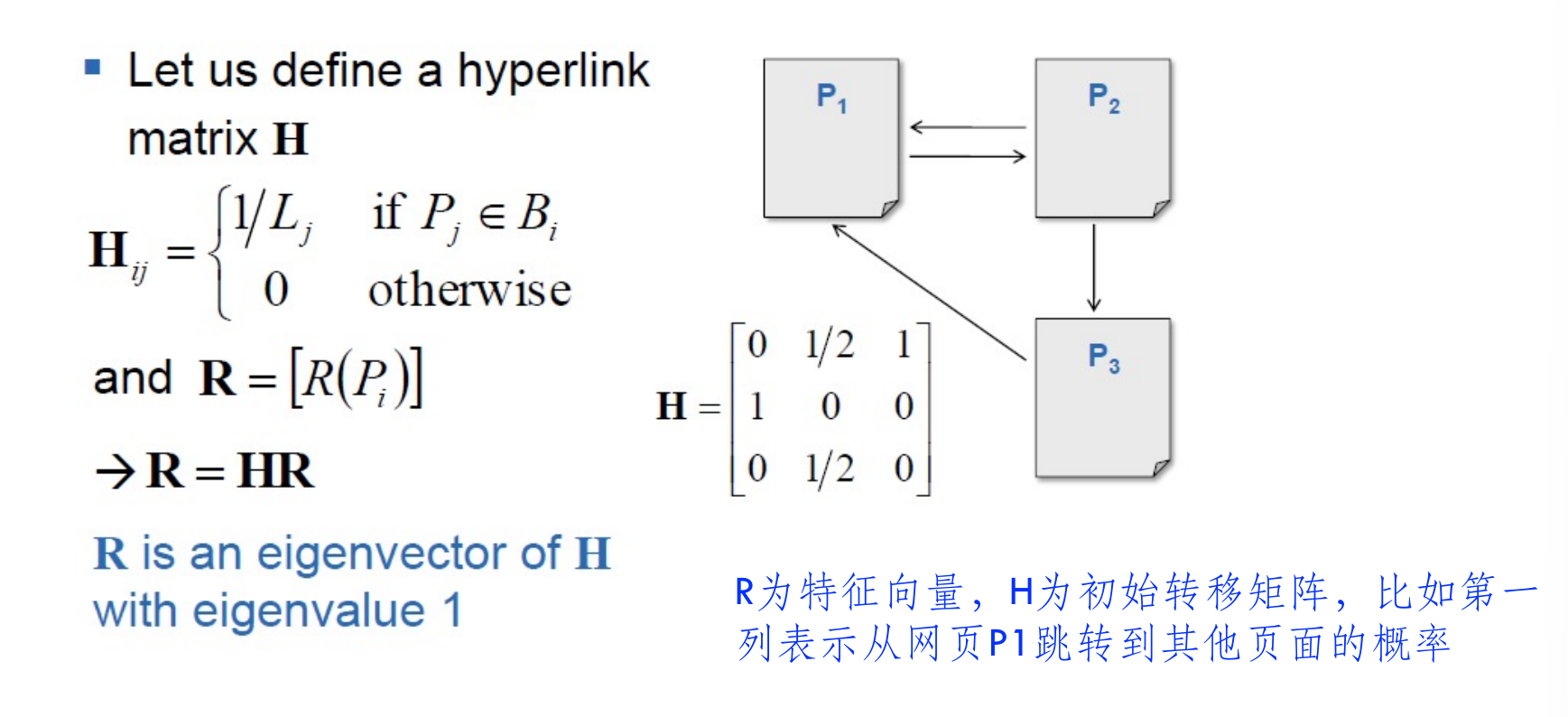
- 即\(R(P_i)=\sum_{P_j\in B_i}\frac{R(P_j)}{L_j}\)
-
-
问题
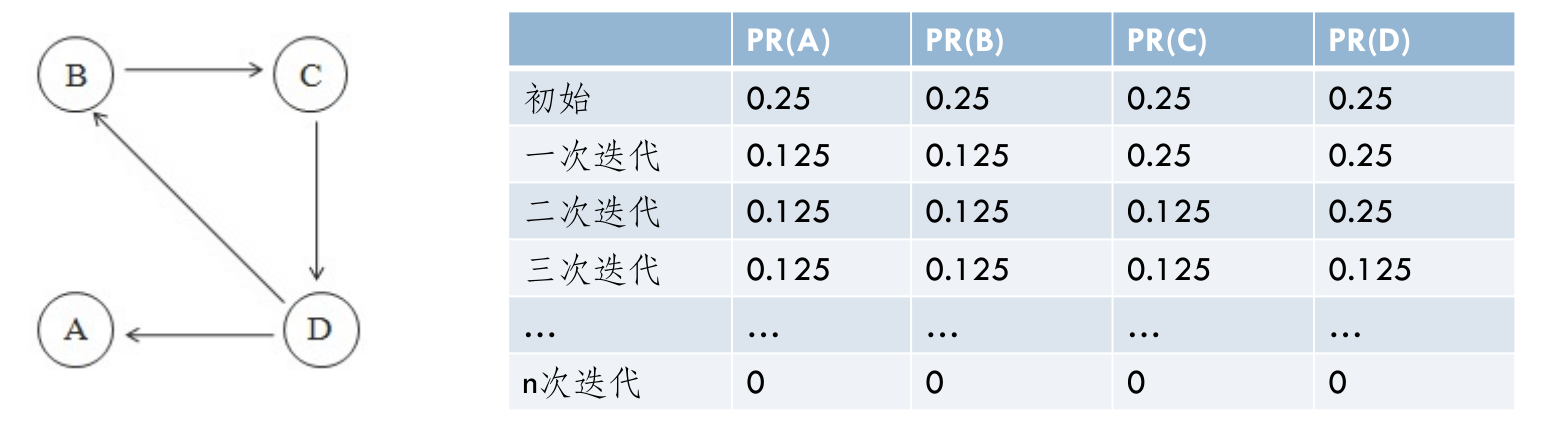
- 排名泄露(Rank leak)
- 一个独立的网页如果没有外出的链接就产生排名泄漏(多次迭代后,所有网页的PR值都趋向于0)。
- 将无出度的节点递归地从图中去掉,待其他节点计算完毕后再添加。
- 或对无出度的节点添加一条边,指向那些指向它的顶点。
-
排名下沉(Rank sink)
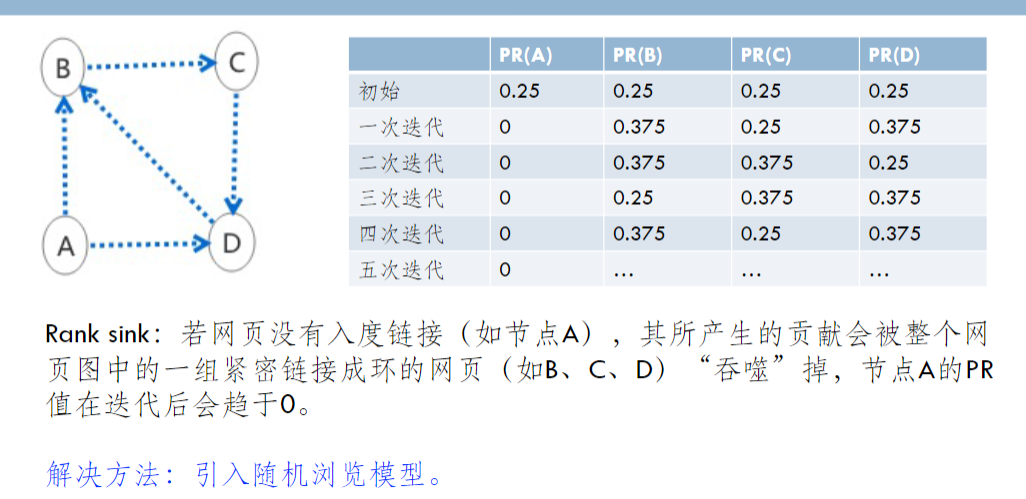
- 若网页没有入度链接,其PR多次迭代后趋向于0
- 引入随机浏览模型
-
随机浏览模型
- 假定一个上网者从一个随机的网页开始浏览
- 上网者不断点击当前网页的链接开始下一次浏览。
- 但是,上网者最终厌倦了,开始了一个随机的网页。(即有几率随机选一个点而不是按照有向图继续浏览)
- 随机上网者访问一个新网页的概率就等于这个网页的PageRank值。因此这个模型更加接近于用户的行为。
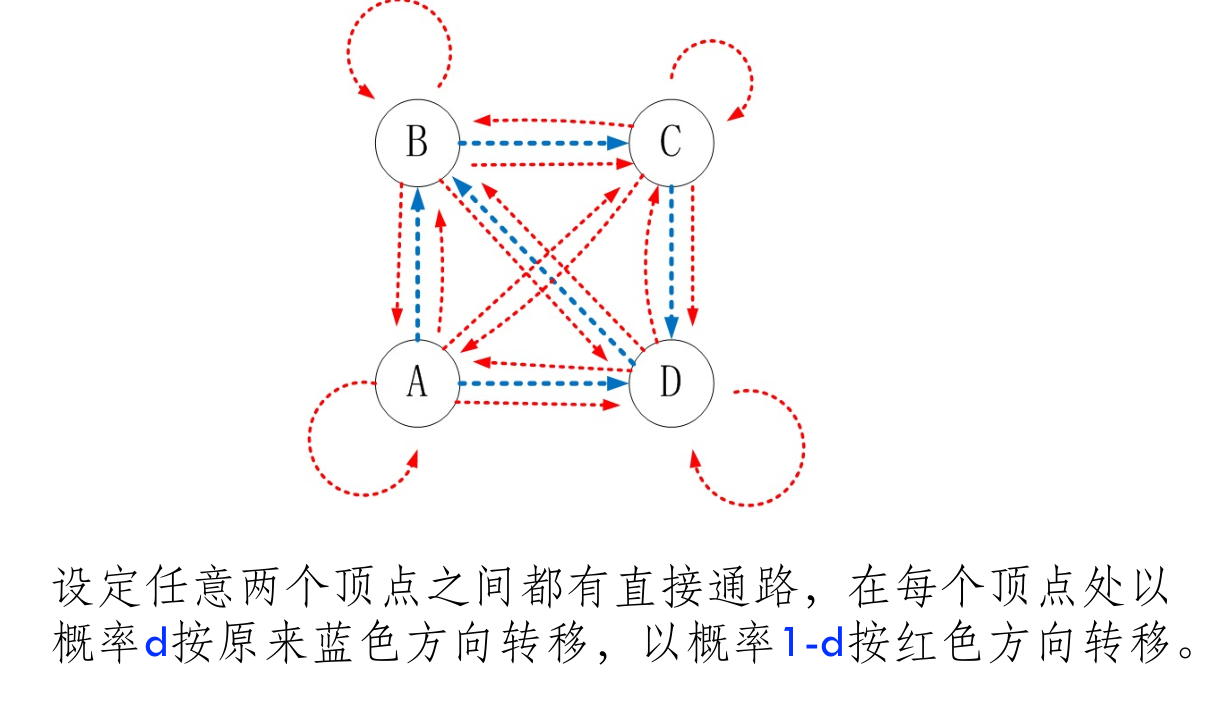
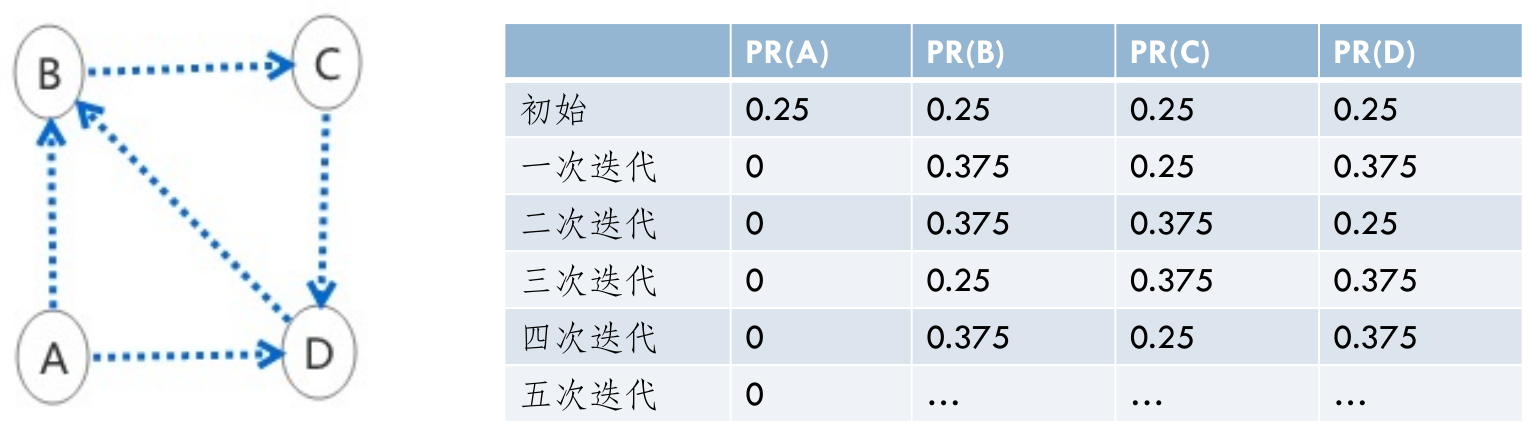
- 随机浏览模型的 PageRank 公式 \(R(P_i)=\frac{1-d}N+d\sum_{P_j\in B_i}\frac{R(P_j)}{L_j}\),收敛存在唯一解(有 \(d-1\) 的概率随机访问一个网站)
使用MapReduce实现¶
- 基本步骤
- 建立网页之间的超链接图
- 迭代计算各个网页的PageRank值
-
按PageRank值从大到小输出
-
Phase1:GraphBuilder
- 原始数据集:每行包含一个网页名,及其所链接的全部网页名。
- Map:逐行分析原始数据, 输出
- 其中网页的URL作为key,PageRank初始值(PR_init)和网页的出度列表一起作为value
-
该阶段的Reduce不需要做任何处理
-
Phase2:PageRankIter
- 迭代计算PR值,直到PR值收敛或迭代预定次数。
- Map对上阶段的
- For each u in link_list, 输出
- 同时在迭代过程中,传递每个网页的链接信息
- For each u in link_list, 输出
-
Reduce 对 Map输出的
- 其中
- u和URL相同的会被分配到相同的reduce进行处理,因而可以得到一个网站的完整信息
- 计算所有val的和,并乘上d,再加上常数(1-d) /N得到new_rank。
- 输出 (u, (new_rank, link_list))。
- 其中
-
Phase3:PageRankViewer
- 将最终结果排序输出。
- 从最后一次迭代的结果读出文件,并将文件名和其PR值读出,并以PR值为key,网页名为value,并且以PR值从大到小的顺序输出
- 可以继承FloatWritable创建自定义类型并重写比较函数实现倒排
public class PageRankDriver {
private static int times = 10;
public static void main(String args[]) throws Exception{
String[] forGB = {"", args[1]+"/Data0"};
forGB[0] = args[0];
GraphBuilder.main(forGB);
String[] forItr = {"Data","Data"};
for (int i=0; i<times; i++) {
forItr[0] = args[1]+"/Data"+(i);
forItr[1] = args[1]+"/Data"+(i+1);
PageRankIter.main(forItr);
}
String[] forRV = {args[1]+"/Data"+times, args[1]+"/FinalRank"};
PageRankViewer.main(forRV);
}
}
MapReduce数据挖掘基础算法¶
一些基本概念¶
数据挖掘¶
- 数据挖掘是通过对大规模观测数据集的分析,寻找确信的关系,并将数据以一种可理解的、且利于使用的新颖方式概括数据的方法。
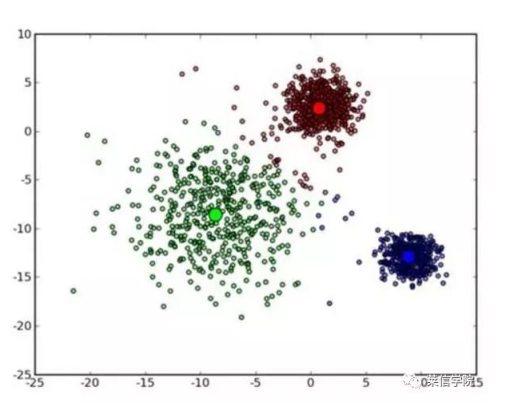
聚类¶
- 聚类所要求划分的类是未知的。聚类的目的是使得属于同类别的对象之间的差别尽可能的小,而不同类别上的对象的差别尽可能的大。即把类似的事物组织在一起。划分后的组为簇
-
聚类是一种无监督学习。也就是说,聚类是在预先不知道欲划分类的情况下,根据信息相似度原则进行信息聚类的一种方法。
-
-
常见的聚类算法包括:K-Means 聚类算法、K-中心点聚类算法、层次聚类、DBScan、EM 聚类等。
-
点集是一种适合于聚类的数据集,每个点都是某空间下的对象。
- 欧氏空间:空间中的点的平均总是存在,并且也是空间 中的一个点。一般用欧几里得距离来衡量两个点之间的距离。
-
非欧空间:Jaccard 距离,Cosine 距离,Edit 编辑距离等多种距离衡量方法。
-
Cluster的表示
- 欧氏空间:取各个数据点的平均值
-
非欧空间:取某个处于最中间的点;取若干个最具代表性的点。
-
相似度的计算
-

-
基于划分的聚类方法
- 给定N个对象,构造K个分组,每个分组就代表一个聚类。
- 每个分组至少包含一个对象。
- 每个对象属于且仅属于一个分组。
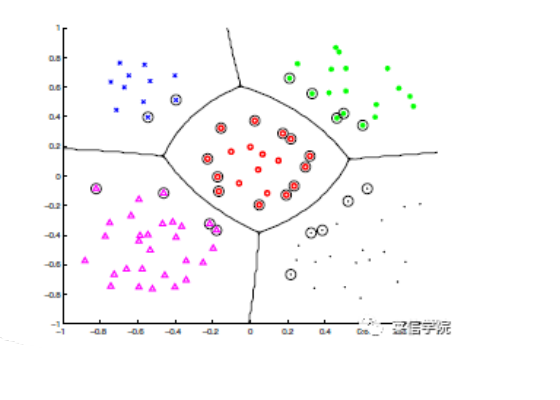
分类¶
- 从一组已经带有分类标记的训练样本数据集来预测一个测试样本的分类结果。
-
分类属于监督学习,每个训练样本的数据对象已经有类标识,通过学习可以形成表达数据对象与类标识间对应的知识。
-
通过对已知分类的数据进行训练和学习,找到不同类的特征,再对未分类的数据进行分类(划分到已有类别中)
-
-
分类规则、决策树、数学公式和神经网络等。
-
训练数据集
- \(TR = {tr1,tr2,\dots}\)
- 每个训练样本tri是一个三元组 \((tid,A,y)\)
- tid为标识符
- A是一组特征属性 \(A={a1,a2,\dots}\)
- y是已知的分类标记
-
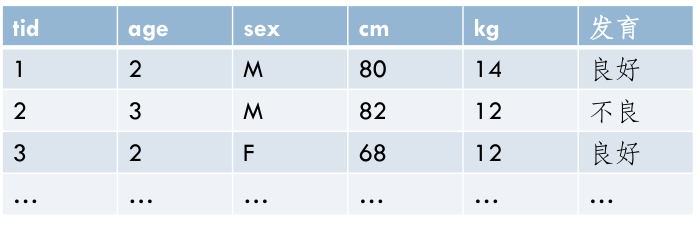
-
测试样本数据集中 y 未知,分类算法要解决的问题就是根据训练数据集结合待预测项的特征属性来预测每个 ts 的分类标记 y
K-Means聚类算法¶
-
欧式空间里的算法
-
过程
- 随机选出K个点作为簇的中心
- 对于所有输入的点计算到各个簇中心的距离,并归入到最近的簇
- 重新计算每个簇的中心点进行更新。
- 根据上一轮迭代中生成的clusters和计算出的cluster centers,进行新一轮的聚类
-
算法不断重复数据点分配和簇中心更新的过程,直到满足收敛条件。收敛条件通常是簇中心的移动距离小于某个阈值,或达到预设的迭代次数。
-
局限性:
- 对初始cluster centers的选取会影响到最终的聚类结果
- 能得到局部最优解,不保证得到全局最优解
- t次迭代的时间复杂度约为 \(O(n*k*t)\)
Mapreduce实现¶
-
对每个点进行计算时,只需要知道各个簇的信息而不需要其他数据点的信息
-
将所有数据分布到不同的node上,每个node只对自己的数据进行计算;并且每个数据都能读取上一次生成的簇中心(这应该是一个全局数据)
-
数据中包含K个\(<id,center>\)
-
Mapper
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class KMeansMapper extends Mapper<Object, Text, IntWritable, Text> { private IntWritable clusterId = new IntWritable(); private Text pointAndCount = new Text(); @Override protected void setup(Context context) throws IOException, InterruptedException { // 读取簇中心数据,可以从 HDFS、配置或其他地方加载 // Centers = ... } @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] point = value.toString().split(","); double minDis = Double.MAX_VALUE; int index = -1; for (int i = 0; i < Centers.length; i++) { double dis = computeDist(point, Centers[i]); if (dis < minDis) { minDis = dis; index = i; } } clusterId.set(index); pointAndCount.set(value.toString() + ",1"); context.write(clusterId, pointAndCount); } private double computeDist(String[] point, Center center) { // 实现计算距离的逻辑 } } -
使用\
-
如果不这样,就不能使用combine提上速度了(不然不知道是有几个点的局部结果)
-
Combiner
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class KMeansCombiner extends Reducer<IntWritable, Text, IntWritable, Text> { private Text result = new Text(); @Override public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { pm = 0.0; n = 数据点列表[(p1,1), (p2,1), …]中数据点的总个数; for i=0 to n pm += p[i]; pm = pm / n; // 求得这些数据点的平均值 emit(ClusterID, (pm, n)); } } -
计算局部结果,可以提升性能
-
Reducer
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class KMeansReducer extends Reducer<IntWritable, Text, IntWritable, Text> { private Text result = new Text(); @Override public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException { // 实现聚类中心的全局计算 pm = 0.0; n=0; k = 数据点列表中数据项的总个数; for i=0 to k { pm += pm[i]*n[i]; n+= n[i]; } pm = pm / n; // 求得所有属于ClusterID的数据点的均值 emit(ClusterID, (pm,n)); // 输出新的聚类中心的数据值 } } -
在第i次迭代后,已经生成了K个聚类。如果满足了终止条件,即可停止迭代,输出K个聚类
- 设定迭代次数;
- 均方差的变化;
- 每个点固定地属于某个聚类;
- ...
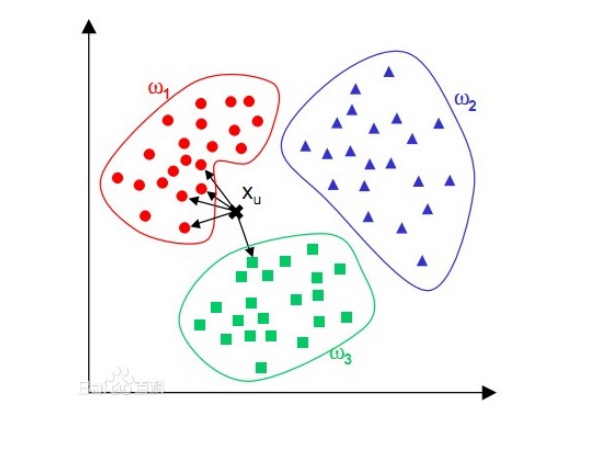
KNN最邻近分类算法¶
-
计算测试样本到各训练样本的距离,取其中距离最小的 K 个,并根据这 K 个训练样本的标记进行投票(这 K 个点中出现次数最多的类别将被选为新数据点的类别)得到测试样本的标记。
-
带加权的分类:根据测试样本与每个训练样本间距离(或相似度,相似度越高权重越大)的大小决定训练样本标记的作用大小 \(y=\frac{\sum S_i*y_i}{\sum S_i}\)
- 加权平均方法的一个优点是它考虑了邻居之间的差异性。相比于简单的多数投票,这种方法能够更好地处理那些在决策边界附近的情况。
-
需要注意的是,这种方法可能不适用于所有类型的分类问题,特别是当类别是非数值型(如标签或名称)时。在这些情况下,传统的多数投票可能更为合适。
-
实现
- 将测试样本数据分块后分布在不同的节点上进行处理,将训练样本数据文件放在DistributedCache中供每个节点共享访问。
- Map:
- 对于每个测试样本计算与每个训练样本的相似度S
- 检查S是否比目前的k个S值中最小的大,若是则将(S, y)计入k个最大者
- 根据所保留的 k 个 S 值最大的(S, y),根据模型 y’ =ΣSi*yi/Σsi 计算出 ts 的分类标记值 y’,发射出(tsid, y’)(加权)
- 或者使用多数投票选择具体的一个分类
- reduce阶段直接输出结果
朴素贝叶斯分类算法¶
- 朴素贝叶斯分类器基于一个简单的假定:给定目标值时属性之间相互条件独立。
- \(P(A|B) = P(A)*P(B|A)/P(B)\)
- 每个数据样本用一个𝑛维特征向量来描述𝑛个属性的值,\(X={x1,\dots,xn}\),有m个类\(Y1,\dots,Ym\)
- 对于一个样本 X 分类给 \(Yi\) 的条件 \(P(Yi|X)>P(Yj|X),1<=j<=m,j!=i\)
- 有贝叶斯定理\(P(Yi|X)=P(X|Yi)*P(Yi)\)
- 由于数据集中有很多具有相关性的属性,导致计算比较复杂,通常假设各属性是独立的,认为\(P(X|Yi)=P(x1|Yi)*\dots*P(xn|Yi)\)
Mapreduce实现¶
- 本质上是统计 \(Yi\) 和每个 \(xj\) 在 \(Yi\) 中出现的概率
- 训练阶段
-
map
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class NaiveBayesTrainMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split(","); String y = fields[fields.length - 1]; // 假设最后一个字段是类别 // 统计类别的频度 word.set(y); context.write(word, one); // 统计类别和特征的联合频度(出现次数) for (int j = 0; j < fields.length - 1; j++) { word.set(y + "," + "x" + j + "," + fields[j]); context.write(word, one); } } } -
对每个类别及特征的频度进行处理
- reduce
import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class NaiveBayesTrainReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } //以字符串的形式统一处理了P(X|Yi)和P(Yi) -
汇总频度
-
预测阶段
- map
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; import java.util.HashMap; import java.util.Map; public class NaiveBayesTestMapper extends Mapper<Object, Text, Text, Text> { private Map<String, Integer> FY = new HashMap<>(); // 类别频率 private Map<String, Integer> FxY = new HashMap<>(); // 属性频率 @Override protected void setup(Context context) throws IOException, InterruptedException { // 初始化,读取数据 FY 和 FxY // FY = ... // FxY = ... } @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] fields = value.toString().split(","); String tsId = fields[0]; // 假设第一个字段是测试样本的ID double MaxF = Double.MIN_VALUE; String bestYi = null; for (String Yi : FY.keySet()) { double FXYi = 1.0; int FYi = FY.get(Yi); for (int j = 1; j < fields.length; j++) { String xnj = "x" + (j - 1); String xvj = fields[j]; String keyFxY = Yi + "," + xnj + "," + xvj; Integer FxYij = FxY.getOrDefault(keyFxY, 0); FXYi *= FxYij; } if (FXYi * FYi > MaxF) { MaxF = FXYi * FYi;//实际上不乘这个FYi才更符合公式 bestYi = Yi; } } context.write(new Text(tsId), new Text(bestYi)); } } - reduce
- 只需要简单记录数据,甚至不需要
决策树分类算法¶
- 结构
- 每个“内部节点”对应于某个属性上的“测试”
- 每个分支对应于该测试的一种可能结构(即该属性的某个取值)
-
每个“叶结点”对应于一个“预测结果”
-
学习过程:通过对训练样本的分析来确定“划分属性”(即内部节点对应的属性)。
- 预测过程:将测试示例从根节点开始,沿着划分属性所构成的“判定测试序列”下行,直到叶结点。
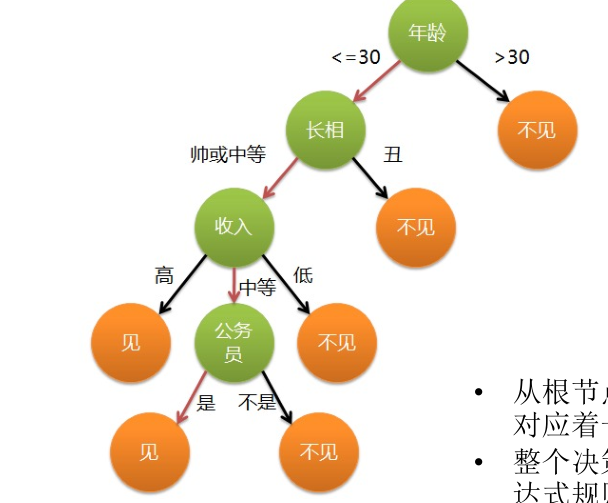
- 结束条件
- 当前结点包含的样本全属于同一类别,无需划分;
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
-
当前结点(属性特定值)包含的样本集合为空,不能划分。
-
决策树的构造
- 生成节点 node:创建一个新的决策树节点。
- 检查是否所有样本同属一类:如果数据集 D 中的所有样本都属于同一类别 C,则:
- 将 node 标记为 C 类叶结点。
- 结束递归:此时,没有进一步的划分需要,因为所有样本都属于同一个类别。
- 检查属性集是否为空或样本在所有属性上取值相同:
- 如果没有更多的属性可用于进一步划分(A 是空的),或者所有样本在所有属性上的取值都相同,则:
- 将 node 标记为叶结点,类别标记为 D 中样本数最多的类。
- 结束递归:这表示我们不能进一步划分数据来提高决策树的精确性。
- 选择最优划分属性 a:从属性集 A 中选择最佳的属性进行数据划分。这通常基于某种准则,如信息增益、增益率或基尼指数。
- 对 a的每个可能的值:
- 为 node 生成一个分支。这个分支对应于属性a上的一个特定值。
- D'是 D 中在a上取值为a'的样本子集。
- 检查D'是否为空:
- 如果 D'为空(没有样本具有该特定属性值),则:
- 将分支节点标记为叶结点,类别标记为 D 中样本数最多的类。
- 结束递归:因为没有样本可用于进一步的学习(不知道这个位置应该是什么类)。
- 递归地构建决策树:
- 如果 D'不为空,则递归地应用 TreeGenerate 函数,即 TreeGenerate( D',A{a})。
- 这意味着对于每个分支,我们都基于剩余的属性(A 中除去a)和相应的子数据集 D'构建子树。
-
以 node 为根节点的一棵决策树:最终输出的是一个决策树,其中每个非叶节点表示一个属性测试,每个分支代表测试的一个可能结果,每个叶节点代表一个预测的类别。
-
最佳划分属性的选择
- 信息增益:
- 信息熵是度量样本集合“纯度”最常用的一种指标。信息增益直接以信息熵为基础,计算当前划分对 信息熵所造成的变化。
- 比较划分前后信息熵变化,进而得到信息增益,进行选择
-
基尼指数:
- 选取那个使划分后基尼指数最小的属性
-
决策树并行算法
- 属性的选择(信息增益率)的计算是决策树生成中耗费资源最大的阶段
- 使用 MapReduce 并行地统计计算增益率所需要的各个属性的相关信息。最后在构造决策树的主程序中利用这些统计好的信息快速地计算出属性的增益率,并选取最佳分裂属性。
- 主构造程序设计:
- 在决策树构造算法需要计算信息增益率时,调用MapReduce过程 在大规模的训练样本上进行统计,获得各个属性的统计信息,然后 利用这些信息计算出属性的信息增益率。
- 决策树路径的构造方法基于层次切分数据的广度优先策略。
- 程序结构:
- 决策树主控程序DecisionTreeDriver
- MapReduce作业配置和执行控制程序
- 决策树算法主控程序
- DecisionTreeMapper
- 对输入的训练样本按照划分条件进行切分的处理,中间结果发射到Reduce端。
- DecisionTreeReducer
- 对Map端发射过来的各个属性下的零散信息,按照相同key值进行累加统计,并将最后统计的结果写入HDFS中,供主控程序计算信息增益率使用。
频繁项集挖掘算法¶
-
频繁项可以看作是两个或多个对象的 “关联”程度,如果同时出现的次数很多,那么这两个或多个对象可以认为是高关联性的。当这些高关联性对象的项集出现次数满足一定阈值时即称其为频繁项。
-

-
满足上述条件的 X、Y 组成组成一个项集 A,则可以认为,数据库 D 中包含 A 的事务超过了某个最小支持度。而所谓频繁项集挖掘,就是将所有满足项数为某个固定整数 k,且支持度高于某阈值的项集计算出来。
-
应用:购物篮分析、推荐算法、搜索引擎(匹配算法)
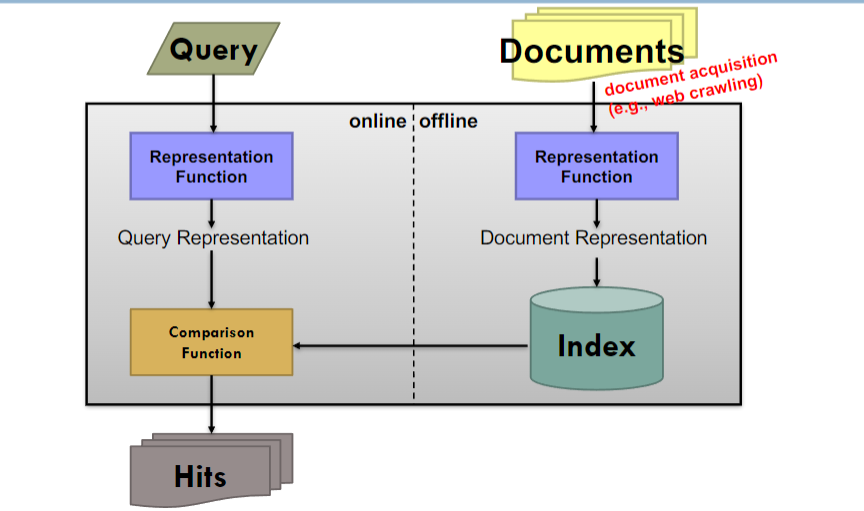
- 文档收集:系统从多个来源(如通过网络爬虫)收集文档(例如网页、文档等)。
- 文档表示:通过表示函数(Representation Function),这些文档被转换成一种内部格式,这样的转换通常涉及到文档内容的索引化,使之适用于快速搜索。
- 索引:转换后的文档表示被存储在索引(Index)中,以便高效地执行查询操作。(如倒排索引)
- 查询:用户输入一个查询(Query),这个查询同样通过表示函数被转换成内部的查询表示。
- 比较:查询表示通过比较函数(Comparison Function)与索引中的文档表示进行比较。
- 命中:最终,系统返回一系列命中(Hits),即那些与用户查询匹配的文档列表
Apriori¶
- 通过多轮迭代的方法来逐步挖掘频繁项集
-
频繁项集的任何非空子集都是频繁的。非频繁项集的任何超集都是非频繁的。
-
思路:
- 生成候选项集:从单个项开始,逐步合并,生成更大的集合。
- 剪枝:删除那些不可能是频繁项集的候选项。
- 计算支持度:计算剩余候选项集的支持度。
- 生成频繁项集:选择满足最小支持度阈值的项集。
-
产生候选1-项集:
- 主进程(或主节点)扫描整个事务数据库(即原始数据集),统计所有单独项的出现频率。
- 产生所有可能的1-项集作为候选项集。
- 计算频繁1-项集:
- 将候选1-项集与原始数据集进行对比,计算每个1-项集的支持度(即出现频率)。
- 将这些支持度与预先设定的最小支持度阈值进行比较,筛选出满足条件的频繁1-项集。
- 产生候选2-项集并计算频繁2-项集:
- 使用频繁1-项集生成候选2-项集(两个项目的组合)。
- 再次扫描数据集,计算这些2-项集的支持度,筛选出频繁2-项集。
- 迭代产生更大的项集:
- 基于当前得到的频繁项集,迭代地生成更大的候选项集(如3-项集、4-项集等)。
- 每一次迭代都需要扫描数据集,计算新生成的候选项集的支持度,并与最小支持度阈值比较,以确定频繁项集。
- 终止条件:
- 这个迭代过程会一直持续,直到某次迭代没有产生新的频繁项集,或者达到了预设的项集大小限制。
- 如果在某次迭代中无法找到频繁的 k-项集,那么最大的频繁项集就是(k-1)-项集。
-
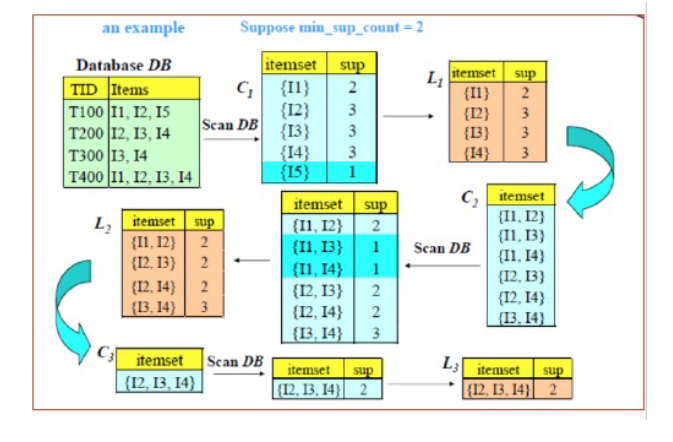
-
map:
- 输出 key 为候选 k-项集,value 为其出现的次数(1)。
- reduce:
- 合并并筛选 k-项集
基于子集求取的频繁项集挖掘算法¶
-
根据事务数据猜测频繁集
-
假设数据库为 D,事务为 T,项集大小为 k
- 首先扫描数据库,对数据库中的每一个事务做如下操作:将该事务所有大小为 k 的子集求出来(Mapper)即生成子集
- 然后,统计输出所有子集的个数,如果某个子集的个数超过了某一阈值 S,那么就可以认为这个子集是频繁项集,将所有这样的子集输出即可(Reducer)
SON¶
-
有限扫描:最多两遍之内发现全部或者大部分频繁项集。只利用数据抽样样本而不是全部数据集进行计算。
-
基本思路:先采样部分样本,在其上运行 Apriori 算法,并调整相应支持度阈值。采样得到的子数据集直接存入主存,之后扫描数据自己不用再次进行 I/O 操作。
- 抽样可能导致完整数据集上的频繁项在样本中不频繁(false negative),样本中频繁但在整个数据集上不频繁(false positive)
-
第一步:找到局部频繁项集
- 计算局部频繁项集:对每个数据块单独计算频繁项集。这里的“频繁”是相对于该块的数据量而言的。也就是说,一个项集在这个特定的块中出现的频率足够高,超过了设定的局部支持度阈值(p * s,其中 s 是全局支持度阈值,p 是块大小占总数据集大小的比例)。
- 合并局部频繁项集:一旦所有的块被处理完毕,算法将所有块中找到的频繁项集合并起来,形成候选频繁项集的集合。
- 第二步:找出全局频繁项集
- 计算全局支持度:对每个候选频繁项集,计算其在整个数据集中的支持度。
- 筛选频繁项集:选择那些全局支持度至少为 s(预设的全局最小支持度阈值)的项集,认定它们为真正的全局频繁项集。(因此可能会漏一些但是不会误判)
分类算法评估¶
-
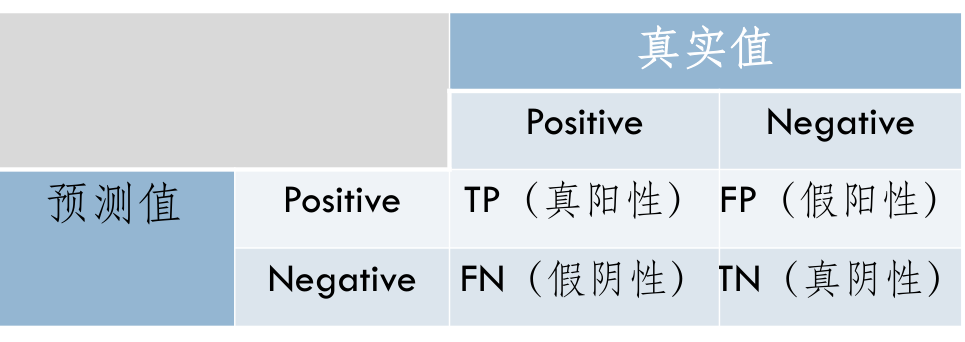
-
Accuracy准确率(正确率)
- 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比
-
\(Accuracy =\frac{TP+Tn}{sum}\)
-
Precision精确率(预测为true中正确的比率)
- 预测结果中符合实际值的比例,可以理解为没有“误报”的情形
-
\(Precision = \frac{TP}{TP+FP}\)
-
Recall召回率
- 正确的数量与应该被正确分类的数量(漏报)
-
\(Recall = \frac{TP}{TP+FN}\)
-
F1 Score
- 精确率和召回率的调和均值
- \(\frac2{F1}=\frac1P+\frac1R\)
-
\(F1 = \frac{2TP}{2TP+FP+FN}\)
-
训练集与测试集
- 对m个样本的数据集拆分为训练集S和测试集T
- 留出法:
- 直接划分为两个互斥集合
- 训练集和测试集的划分要尽可能保持数据分布的一致性
- 一般取若干次随机划分、重复实验取平均值
- 训练/测试样本比例通常为2:1~4:1
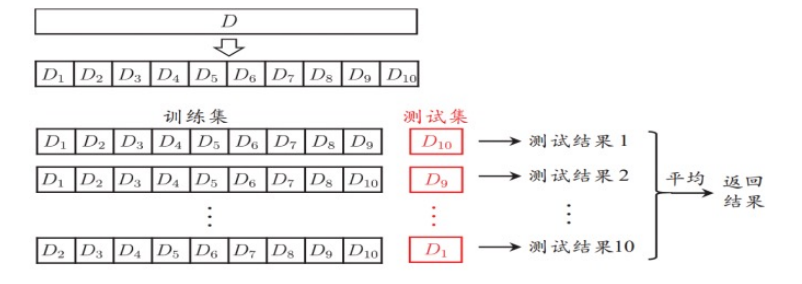
- 交叉验证法:
- 将数据集分层采样划分为k个大小相似的互斥子集,每次用k-1个子集的并集作为训练集,余下的子集作为测试集,最终返回k个测试结果的均值,k最常用的取值是10。
- 假设数据集D包含m个样本,若令k=m,则得到留一法。不受随机样本划分方式的影响,结果往往比较准确,但当数据集比较大时,计算开销难以忍受。