Hive基本原理¶
- Hive包括一个高层语言的执行引擎,类似于SQL的执行引擎
- 支持使用类似于SQL的语句进行查询等操作(会自动翻译为对应的MapReduce序列执行)
- Hive建立在Hadoop的其它组成部分之上,包括Hive依赖于HDFS进行数据保存,依赖于MapReduce完成查询操作。
-
Hive 目的:对于大量的数据,使得数据汇总、查询和分析更加简单。它提供了 SQL,允许用户简单地进行查询、汇总和数据分析。
-
优点
- 可扩展性:横向扩展,Hive 可以自由的扩展集群的规模,一般情况下不需要重启服务。
- 延展性:Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数。
-
良好的容错性:可以保障即使有节点出现问题,SQL 语句仍可完成执行。
-
缺点
- Hive 不支持记录级别的增删改操作,但是用户可以通过查询生成新表或者将查询结果导入到文件中(新版本支持记录级别的插入操作)
- Hive 的查询延时很严重,因为 MapReduce Job的启动过程消耗很长时间,所以不能用在交互查询系统中。
-
Hive 不是为在线事务处理而设计,所以主要用来做 OLAP(联机分析处理),而不是 OLTP(联机事务处理)。它最适合用于传统的数据仓库任务。
- OLTP 是一种面向事务的数据处理方式。它主要用于管理日常事务和操作,如银行交易、零售销售等。
- OLAP是一种面向分析的数据处理方式。它主要用于复杂的数据分析和查询,包括趋势分析、报告生成等
-
Hive 本身不存储数据,是逻辑表:通过元数据来描述 Hdfs 上的结构化文本数据,通俗点来说,就是定义一张表来描述 HDFS 上的结构化文本,包括各列数据名称,数据类型是什么等。
-
应用
- 日志分析
- 数据挖掘
- 文档索引
- 商业智能信息处理
-
即时查询以及数据验证
-
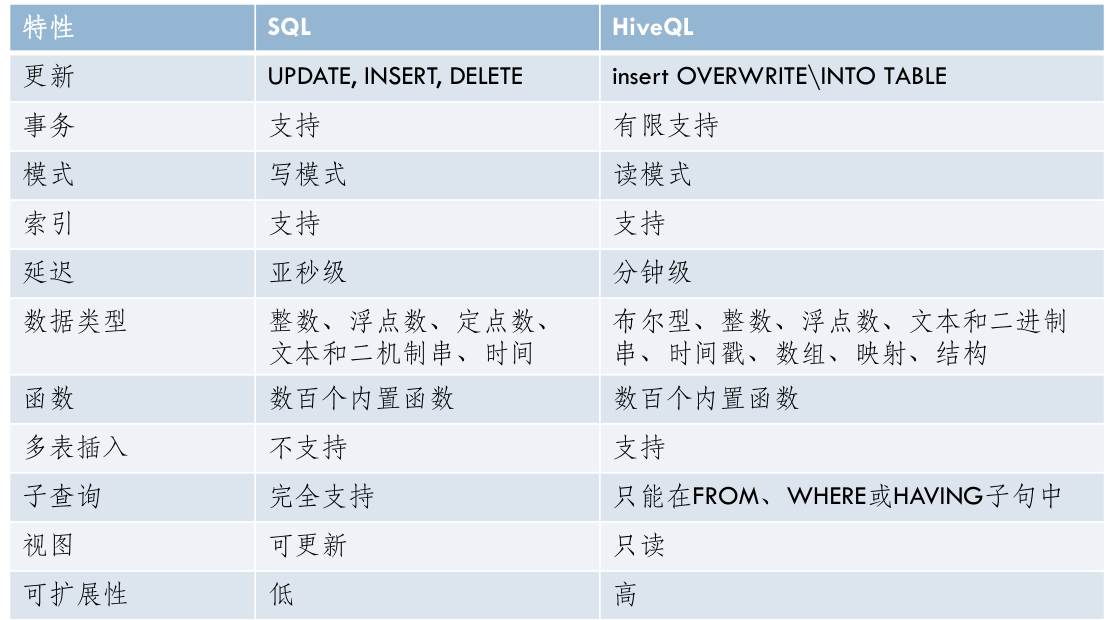
RDBMS与Hive
- Hive虽然使用SQL类似的语句进行查询,但是并不是RDBMS(关系型数据库)
- HiveQL:这是Hive的数据查询语言,与SQL非常类似。Hive提供了这个数据查询语言与用户的接口,包括一个shell的接口,可以进行用户的交互以及网络接口与JDBC接口。JDBC接口可以用于编程,与传统的数据库编程类似,使得程序可以直接使用Hive功能而无需更改。
- Hive使用的是Hadoop的HDFS,关系数据库则是服务器本地的文件系统;
- Hive使用的计算模型是MapReduce,而关系数据库则是自己设计的计算模型;
-
关系数据库都是为实时查询的业务进行设计的,而 Hive 则是为海量数据做数据挖掘设计的,实时性很差
-
HBase与Hive
- HBase与Hive通常是配合使用的,HBase针对OLTP(联机事务处理),Hive针对OLAP(联机分析处理)
- HBase是基于Hadoop的NoSQL的数据库,而Hive严格上来说不是数据库,主要目的是为了让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
- Hive是逻辑表,通过元数据描述HDFS上的结构化文本数据,而Hive本身不存储数据,完全依赖HDFS和MapReduce,将结构化的数据文件映射为为一张数据库表,并提供完整的SQL查询功能;而HBase则是一个物理表,存储了非结构化数据
- Hive是基于行模式,而HBase基于列模式,适合海量数据随机访问
- HBase的表是疏松的存储的,因此用户可以给行定义各种不同的列;而Hive表是稠密型,即定义多少列,每一行有存储固定列数的数据。
- Hive不能保证处理的低迟延问题;而HBase是近实时系统,支持实时查询。
-
Hive 提供完整的 SQL 实现,通常被用来做一些基于历史数据的挖掘、分析。而 HBase 不适用于有 join,多级索引,表关系复杂的应用场景。
-
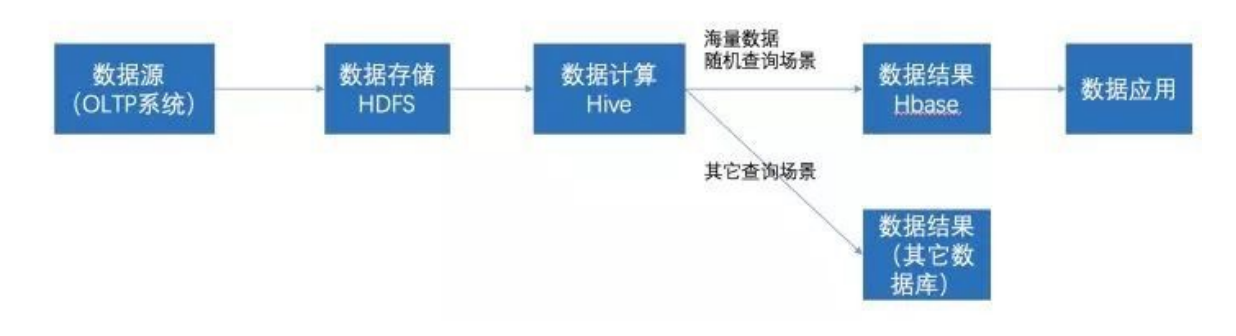
常见工作模式
- 数据源抽取到HDFS存储->通过Hive清洗、处理和计算原始数据->可存入HBase->数据应用从HBase查询数据
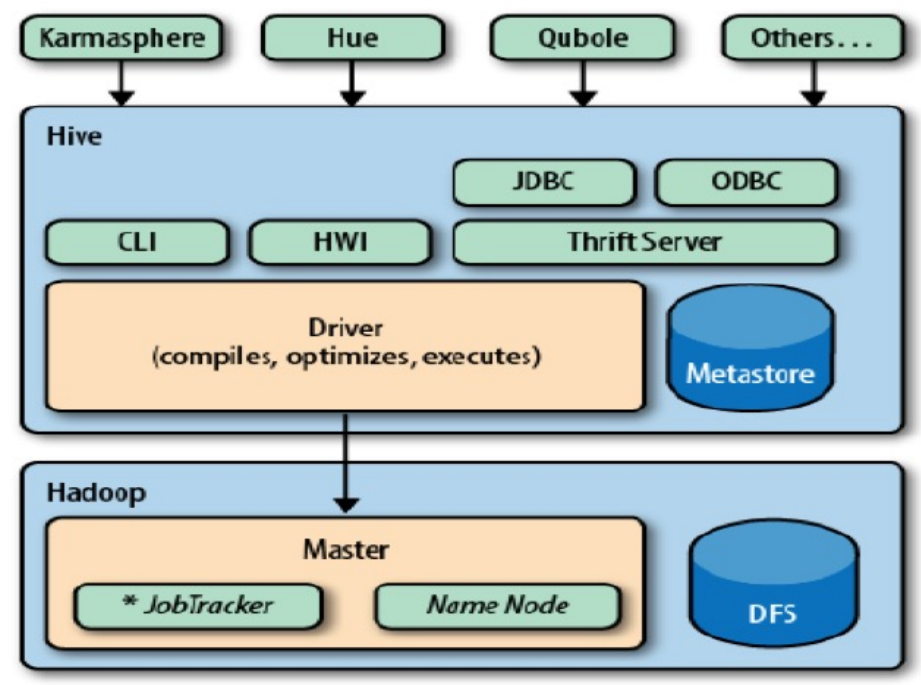
体系结构与组成¶
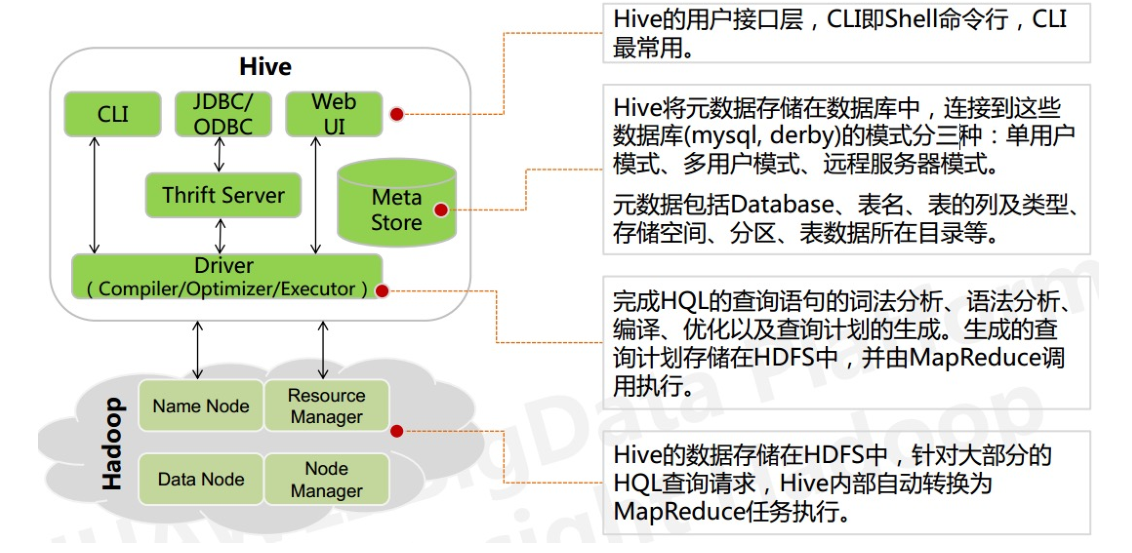
- Driver组件:核心组件,整个Hive的核心。该组件包括Complier、 Optimizer和Executor,它的作用是将我们写的HQL语句进行解析、编译优化,生成执行计划,然后调用底层的MapReduce计算框架。
- Compiler:Hive需要一个编译器,将HiveQL语言编译成中间表示,包括对于HiveQL语言的分析,执行计划的生成等工作
- Optimizer:进行优化
-
Executor:执行引擎,在 Driver 的驱动下,具体完成执行操作,包括 MapReduce 执行,或者 HDFS 操作,或者元数据操作
-
Metastore 组件:数据服务组件,用以存储Hive 的元数据:存储操作的数据对象的格式信息,在 HDFS 中的存储位置的信息以及其他的用于数据转换的信息 SerDe 等。
-
CLI组件:Command Line Interface,命令行接口。
- ThriftServers:提供JDBC和ODBC接入的能力,它用来进行可扩展且跨语言的服务的开发,Hive集成了该服务,能让不同的编程语言调用Hive的接口。
- Hive WEB Interface(HWI):Hive客户端提供了一种通过网页的方式访问hive所提供的服务。这个接口对应Hive的HWI组件(hive web interface)
-
Hive 将通过CLI接入,JDBC/ODBC接入,或者HWI接入的相关查询,通过Driver(Complier、Optimizer和Executor),进行编译,分析优化,最后变成可执行的MapReduce。
-
Hive客户端
- Hive客户端指的是可以与Hive交互的各种工具和接口,用于执行查询、管理Hive服务以及处理Hive中的数据。Hive客户端可以分为几种类型,每种都有其特定的用途和功能:
- 命令行CLI(Hive Shell)
- Web界面
- Thrift客户端:被绑定在多种语言中,包括C++,Java,PHP,Python以及Ruby等
- DBC/ODBC接口:Hive提供了Java数据库连接(JDBC)和开放数据库连接(ODBC)接口,使得可以从各种编程语言或数据工具(如Java、Python、BI工具等)中远程连接到Hive服务器并执行查询
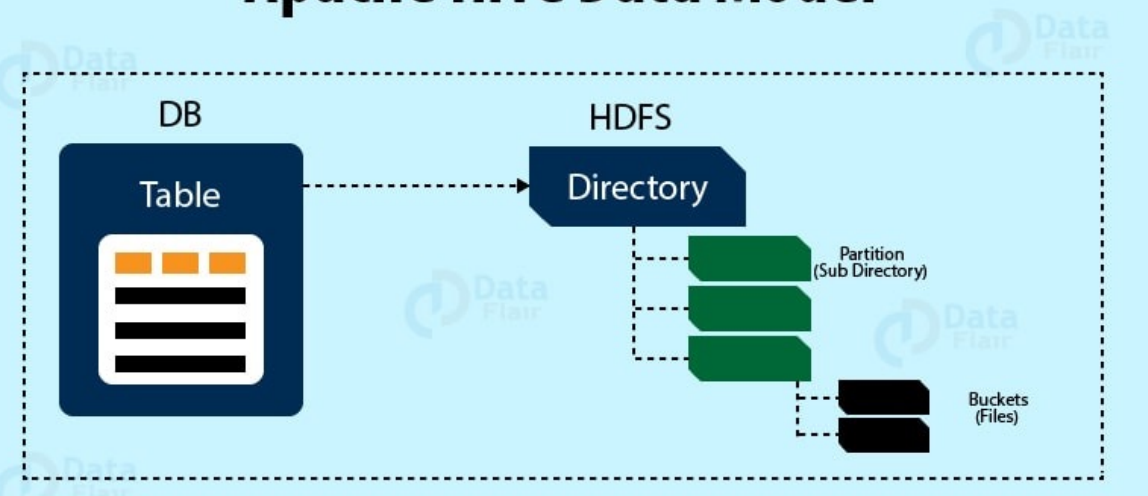
数据模型¶
-
-
Tables(表):Hive的数据模型由数据表组成。数据表中的列是有类型的(int,float, string, data, boolean)也可以是复合的类型,如list, map (类似于JSON形式的数据)
-
逻辑上,数据是存储在 Hive表里面的,而表的元数据描述了数据的布局。我们可以对表执行过滤,关联,合并等操作。在 Hadoop 里面,物理数据一般是存储在 HDFS 的,而元数据是存储在关系型数据库的。
-
Partitions(分区):数据表可以按照一定的规则对表进行划分Partition。例如,通过日期的方式将数据表进行划分。
- Hive根据分区键进行分区,提高了查询数据的效率
- 在查询某一个分区的数据的时候,只需要查询相对应目录下的数据,而不会执行全表扫描,也就是说, Hive在查询的时候会进行分区剪裁。
-
每个表可以有一个或多个分区键。
-
Buckets(桶):数据存储的桶。在一定范围内的数据按照Hash的方式进行划分(对分区进一步划分)
- 桶是更为细粒度的数据范围划分,在桶内数据以行的形式存储,提高查询数据的效率。
-
Hive是针对表的某一列进行分桶。Hive采用对表的列值进行哈希计算,然后除以桶的个数求余的方式决定该条记录存放在哪个桶中。分桶的好处是可以获得更高的查询处理效率,使取样更高效。
-
元数据存储:metastore
- 在Hive中由一系列的数据表格组成一个命名空间,关于这个命名空间的描述信息会保存在metastore的空间中
- 元数据使用SQL的形式存储在传统的关系数据库中,因此可以使用任意一种关系数据库
- 在数据库中,保存最重要的信息是有关数据库中的数据表格描述,包括每一个表的格式定义,列的类型,物理的分布情况,数据划分情况等
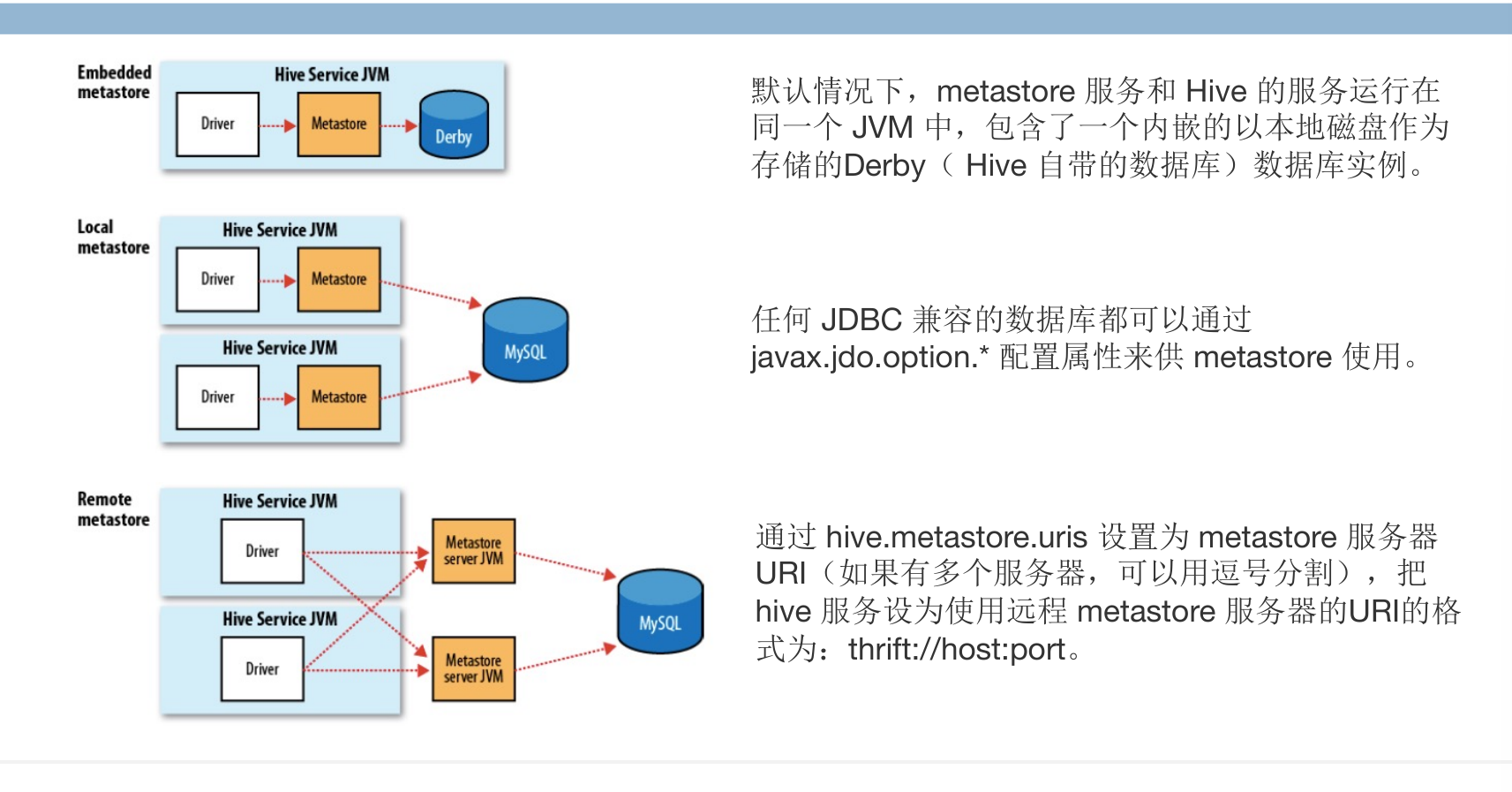
- metastore运行模式
- 内嵌Metastore:Hive的默认设置。在这种模式下,Hive会使用一个内嵌的Derby数据库实例来存储元数据,每次只能被一个Hive会话打开。
- 本地Metastore:在本地Metastore配置中,元数据服务作为Hive服务的一部分运行在同一个JVM进程中。但使用一个独立的数据库来存储元数据,这个数据库可以是MySQL、PostgreSQL等,通过JDBC连接。这样配置允许多个Hive客户端同时访问Metastore,因此比内嵌Metastore更适合于生产环境。
- 远程Metastore:在远程Metastore配置中,Metastore服务在独立于Hive服务的不同进程中运行。这意味着一个或多个Metastore服务器可以服务于多个Hive实例。由于Metastore服务是独立运行的,因此提供了更好的可扩展性和容错性。这是一个对于大型集群和多用户环境更加健壮和灵活的配置。
Hive3.x*¶
- Apache Tez成为默认的Hive执行引擎。通过有向无环图(DAG)和数据传输原语的表达式,在Tez下执行Hive查询可以提高性能。

- 设计影响安全性的更改
- Hadoop 3.0 Ambari安装添加了Apache Ranger安全服务。Hive的主要授权模型是Ranger。此模型仅允许Hive访问HDFS。Hive强制执行Ranger中指定的访问控制。
- HDFS权限更改
-
HDFS访问控制列表(ACL)是HDFS中权限系统的扩展。Hadoop 3.0默认打开HDFS中的ACL,在为多个组和用户提供特定权限时,可以提高灵活性方便地将权限应用于目录树而不是单个文件。
-
交易处理变更 ACID v2,对很多事务的特性进行了优化升级,使 之更接近于关系型数据库
- 使用ACID语义修改现有Hive表数据,包括insert, update, delete,merge
- 支持数据库四大特性ACID
- 允许在使用长时间运行的分析查询同时进行并发更新
-
使用MVCC架构
-
客户端
- Hive 3仅支持瘦客户端Beeline,用于从命令行运行查询和Hive管理命令。
- Beeline使用与HiveServer的JDBC连接来执行所有命令。
- Hive客户端的更改要求使用grunt命令行来使用Apache Pig
-
HiveServer现在使用远程而不是嵌入式Metastore。
-
park目录更改
- Spark和Hive现在使用独立的目录来访问相同或不同平台上的SparkSQL或Hive表。Spark创建的表驻留在Spark目录中。Hive创建的表位于Hive目录中。虽然是独立的,但这些表互操作。
- 可以使用HiveWarehouseConnector从Spark访问ACID和外部表。
基本操作¶
Hive QL¶
- DDL:数据定义语句,包括 CREATE, ALTER, SHOW, DESCRIBE, DROP 等
- DML:数据操作语句,包括 LOAD DATA, INSERT。
-
QUERY:数据查询语句,主要是 SELECT 语句。
-
显示所有的数据表
show tables; -
显示所创建的数据表的描述(建时候对于数据表的定义)
DESCRIBE invites; -
创建表CREATE
CREATE TABLE tablename (foo INT, bar STRING);-
CREATE TABLE invites (foo INT, bar STRING) PARTITIONED BY (ds STRING);- 一个额外的分区键
ds
- 一个额外的分区键
-
修改表ALTER
ALTER TABLE pokes ADD COLUMNS (new_col INT);-
ALTER TABLE invites REPLACE COLUMNS (foo INT, bar STRING, baz INT );- 如果之前表中存在这些列,则它们的定义将被更新为新的类型(如果指定了新的类型)。
- 如果表中原本还有其他列,那么这些列将被移除,与这些列相关的数据也会丢失。
-
数据装载 LOAD DATA
- 从本地路径加入数据
LOAD DATA LOCAL INPATH './examples/files/kv1.txt' OVERWRITE INTO TABLE pokes;- 装入数据时不会验证数据是否符合表的模式
- 如果是从 HDFS 装入则移除 LOCAL 关键字。
-
当执行
LOAD DATA命令时,Hive不会解析或处理数据。它只是简单地将文件移动到与 Hive 表关联的 HDFS 路径下,数据在查询执行期间被解析。 -
SELECTS and FILTERS
SELECT a.foo FROM invites a WHERE a.ds='2008-08-15' sort by a.foo asc limit 10;- 添加了一个排序和限制条件。它选择分区
ds等于2008-08-15的foo列,然后按foo的值升序排序,只返回前10条记录。
- 添加了一个排序和限制条件。它选择分区
INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='2008-08-15';- 这个命令将
invites表中分区ds等于2008-08-15的所有列的数据写入HDFS的/tmp/hdfs_out目录中。如果目标目录中已经有数据,OVERWRITE关键字会导致现有数据被替换。
- 这个命令将
难点¶
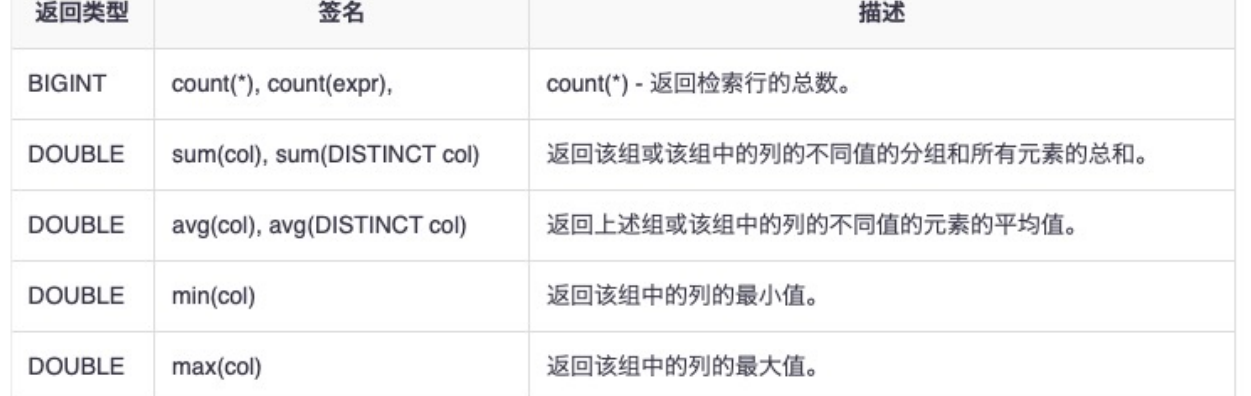
- Group By
- 按照一个或者多个列进行分组,然后对每个组进行聚合操作。
INSERT OVERWRITE TABLE events SELECT a.bar, count(*) FROM invites a WHERE a.foo > 0 GROUP BY a.bar; - SELECT a.bar, count(*):这是要执行的查询。它计算了
invites表中每个不同bar值的数量。count(*)计算了每个组的记录数(聚合函数)。 -
-
Join
-
对两个表通过两个相同的字段进行连接,并查询相关的结果。
SELECT t1.bar, t1.foo, t2.foo FROM pokes t1 JOIN invites t2 ON t1.bar = t2.bar; -
排序
-
order by
- 全局排序:
ORDER BY确保整个数据集全局排序。 - 使用单个 Reducer 因此保证全局有序,不过效率较低
SELECT * FROM emp ORDER BY sal DESC;(默认ASC)
- 全局排序:
-
sort by
- 局部排序:
SORT BY为每个reducer产生一个有序的输出文件。它只保证每个reducer的输出是有序的,但整个数据集不一定全局有序。 - 多个Reducer:可以通过设置多个reducer来提高
SORT BY的处理速度。这样做可以使得排序操作在多个reducer上并行执行。
- 局部排序:
-
distribute by
- 数据分配:
DISTRIBUTE BY子句用于控制哪些行被发送到哪个reducer。这在进行聚合或排序操作时特别有用,因为它可以确保具有特定键的所有行都发送到同一个reducer。 - 工作原理:
DISTRIBUTE BY根据指定字段的哈希值来分配行到不同的reducer。具有相同哈希值的行将被分配到同一个reducer。 -
配合SORT BY使用:通常与
SORT BY一起使用,以便在特定的reducer内对行进行排序。INSERT OVERWRITE LOCAL DIRECTORY '/opt/module/data/distribute-result' SELECT * FROM emp DISTRIBUTE BY deptno SORT BY empno DESC; -
cluster by
- 结合DISTRIBUTE BY和SORT BY:当你需要在相同的字段上执行
DISTRIBUTE BY和SORT BY时,可以使用CLUSTER BY。它实际上是这两个子句的简写形式。 - 只支持升序排序:使用
CLUSTER BY时,只能按升序对数据进行排序。你不能指定ASC或DESC来改变排序顺序。 - 示例:按部门编号进行分区,并在每个分区内按部门编号升序排序。
SELECT * FROM emp CLUSTER BY deptno; //等同于 SELECT * FROM emp DISTRIBUTE BY deptno SORT BY deptno;
Hive 优化¶
- 数据倾斜:
- Key 分布不均匀:
- 使用随机值打散 key(加盐),尤其是在 join 或 group by 操作时,可以将数据更均匀地分布到各个 reducer 上。
- 业务数据本身的原因:
- 分析数据分布,可能需要调整业务逻辑或数据模型来缓解倾斜。
- 建表考虑不周:
- 在建表时考虑数据的分布和查询模式,合理使用分区和分桶策略。
-
SQL 本身导致的数据倾斜:
- 在进行 join 操作时,选择 key 分布最均匀的表作为驱动表。
- 当大小表 join 时,让小表(维度较小的表)先进内存。
- 对于大表 join,可以通过把空值的 key 或倾斜的数据改变成一个字符串加上一个随机数,分散到不同的 reducer 上。
-
优化策略
- MapReduce 优化:
- 尽量减少 MapReduce 作业的数量,合理安排作业的执行流程。
- 配置优化:
- 列裁剪:仅处理需要的列,避免读取不必要的数据。
- 分区裁剪:只查询必要的分区,减少数据扫描量。
- 调整 Hive 参数,如启用 map 端聚合
hive.map.aggr=true,处理倾斜数据的hive.groupby.skewindata=true。
- 程序优化:
- 在 Join 操作中,遵循小表驱动原则,将小表或子查询放在 join 操作符的左边。
- 在 GROUP BY 操作中,利用 Map 端的部分聚合,以及在出现数据倾斜时进行负载均衡。
高级操作¶
表的分区¶
-
可以把数据依照单个或多个列进行分区,通常按照时间、地域进行分区。为了达到性能表现的一致性,对不同列的划分应该让数据尽可能均匀分布。分区应当在建表时设置。
-
分区本质
- Hive中的分区实质上是对应于HDFS文件系统上的独立文件夹。
- 分区是按照特定的列(分区键)来组织的,这可以是日期、地区等。
-
在查询时,可以通过
WHERE子句中的条件来选择特定的分区,这样只需扫描相关分区的数据,而不是整个表,从而提高查询效率。 -
分区操作
-
增加分区:
这个命令在ALTER TABLE person ADD PARTITION (dt='20180316');person表中增加了一个新的分区,分区键dt的值为20180316。 -
删除分区:
ALTER TABLE person DROP PARTITION (dt='20180316');
这个命令删除了person表中dt为20180316的分区。
-
查看分区表结构:
这个命令用于查看DESCRIBE FORMATTED person;person表的结构,包括它的分区信息。 -
查看所有分区:
这个命令显示了SHOW PARTITIONS person;person表中的所有分区。 -
二级分区
- Hive也支持多级分区(如二级分区),这允许你按照多个键来组织数据。
-
创建二级分区表示例:
这个命令创建了一个按照day和hour两个字段进行二级分区的表。CREATE TABLE dept_partition2 (deptno INT, dname STRING, loc STRING) PARTITIONED BY (day STRING, hour STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'; -
动态分区
- 动态分区允许在插入数据时动态地创建分区,而不是预先定义分区。
-
设置动态分区:
这些设置允许在插入数据时动态创建分区。SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict; -
动态分区示例:
这个命令从INSERT INTO TABLE dept_par4 PARTITION(loc) SELECT deptno, dname, loc FROM dept;dept表中选择数据,并根据loc字段的值动态地插入到dept_par4表的相应分区中。
表的分桶¶
- 查询某个桶里的数据
SELECT * FROM person TABLESAMPLE (BUCKET 1 OUT OF 3); - TABLESAMPLE (BUCKET x OUT OF y):这是一个采样子句,用于从表中选择一个随机样本。在这个特定的例子中,它用于从桶化的表中选取数据。
- BUCKET 1 OUT OF 3:这表示从表中所有桶中选择第一个桶的数据。如果表被分成了3个桶,这个命令将返回第一个桶的所有数据。
内部表和外部表¶
- 内部表
- 数据和元数据管理:当创建内部表时,Hive将对数据进行管理。如果数据被加载到内部表中,它会移动到Hive的数据仓库目录(通常是
/user/hive/warehouse)。 - 生命周期:删除内部表时,Hive会删除表的元数据和存储在数据仓库中的数据。这意味着删除操作是不可逆的,表和表中的数据都将被永久删除。
-
使用场景:如果数据仅在 Hive 内部使用,并且你希望 Hive 完全控制数据的生命周期,那么使用内部表是合适的。
CREATE TABLE managed_table (dummy STRING); LOAD DATA INPATH '/user/tom/data.txt' INTO TABLE managed_table; DROP TABLE managed_table; -
外部表
- 独立的数据和元数据管理:创建外部表时,Hive仅记录数据所在的位置。数据实际存储在Hive外部指定的路径上,Hive不会移动或管理这些数据。
- 生命周期:删除外部表时,Hive只会删除表的元数据,而不会删除实际的数据。这意味着即使表在Hive中被删除,原始数据仍然保留在其存储位置。
- 使用场景:如果数据被其他应用或工具共享,或者你不希望Hive管理数据的生命周期,那么使用外部表更合适。
CREATE EXTERNAL TABLE person (id INT, name STRING, age INT, fav ARRAY<STRING>, addr MAP<STRING, STRING>) COMMENT 'This is the person table' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LOCATION 'hdfs://localhost:9000/root/' STORED AS TEXTFILE;
自定义函数¶
- User Defined Function (UDF)
-
UDF用于对单条数据进行操作,输出一个数据行。例如,可以创建一个UDF来转换字符串格式或计算日期。
-
User Defined Aggregate Function (UDAF)
-
UDAF接受多个数据输入并输出一个数据行。这些函数用于执行聚合操作,例如计算平均值、最小值、最大值等。
-
User Defined Table-Generating Function (UDTF)
-
UDTF作用于单个数据行,同时产生多个输出数据行。例如,一个UDTF可能接受一个字符串,并将其拆分为多个单词,每个单词作为一个输出行。
-
创建和使用自定义函数
- 编写Java代码:首先,需要使用Java编写自定义函数。例如,编写一个UDAF来计算最大值:
public class Maximum extends UDAF {} -
导出 Jar 包:将编写的 Java 代码编译并导出为 Jar 包。
-
在Hive中添加Jar包:
ADD JAR Maximum.jar; -
创建自定义函数:使用
CREATE FUNCTION命令在Hive中注册这个自定义函数:CREATE FUNCTION maximumtest AS 'com.firsthigh.udaf.Maximum'; -
运行函数并检查结果:最后,可以在Hive查询中使用这个自定义函数:
SELECT maximumtest(price) FROM record_dimension;