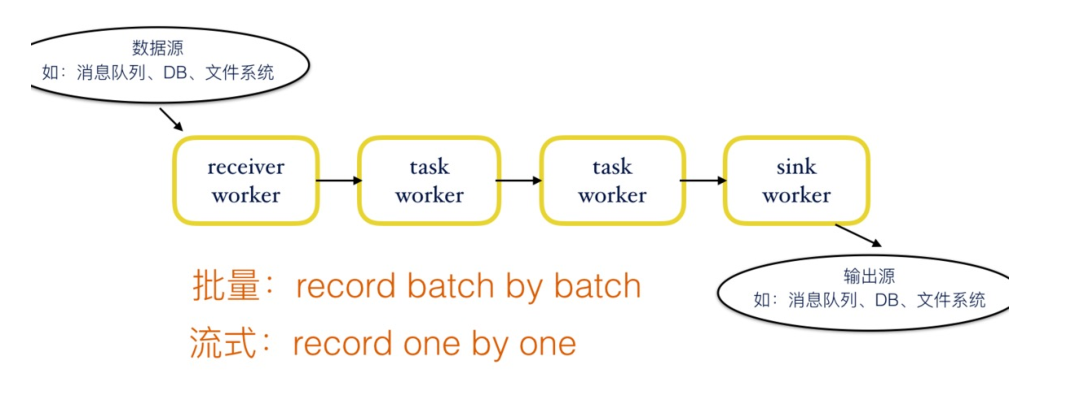
概述¶
-
MapReduce计算模式的缺陷:2阶段固定模式,磁盘计算大量I/O性能低下
-
Spark基于内存计算思想提高计算性能
- Spark提出了一种基于内存的弹性分布式数据集(RDD),通过对RDD的一系列操作完成计算任务,可以大大提高性能
-
Spark的主要抽象是提供一个弹性分布式数据集(RDD),RDD 是指能横跨集群 所有节点进行并行计算的分区元素集合。RDD可以从Hadoop的文件系统中 的一个文件中创建而来(或其他 Hadoop支持的文件系统),或者从一个已有 的Scala集合转换得到。
-
RDDs
- 基于RDD之间的依赖关系组成lineage,通过重计算以及checkpoint等机制来保证整个分布式计算的容错性。
- 只读、可分区,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用,弹性是指内存不够时可以与磁盘进行交换。
*Spark 的生态圈¶
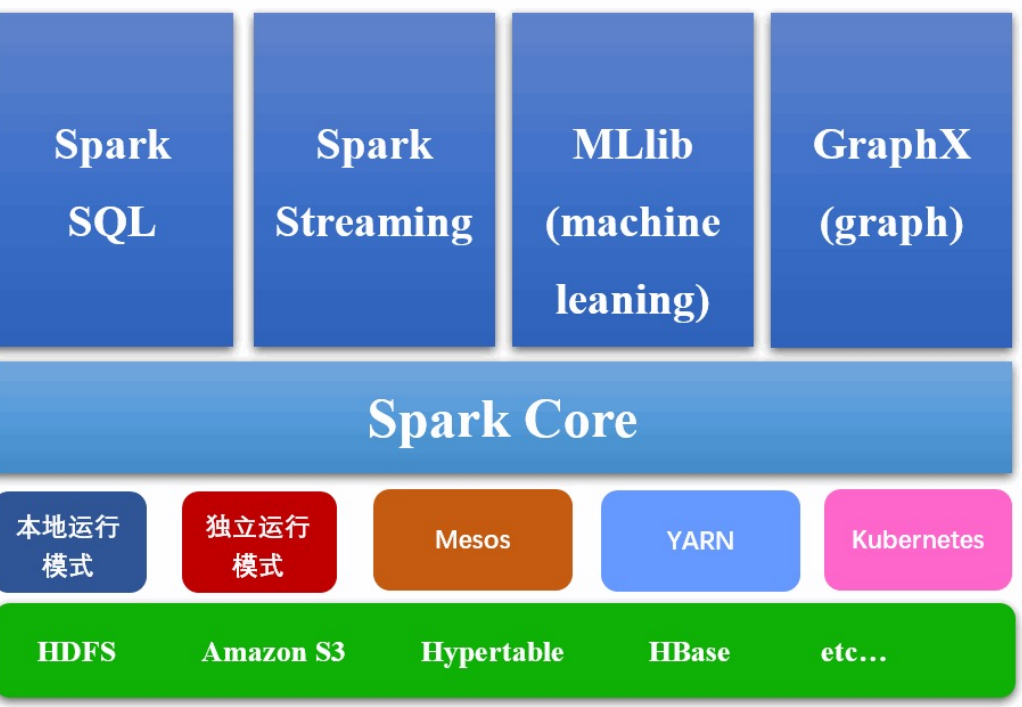
Spark与Hadoop¶
- hadoop
- Hadoop是一个包含了数据存储和分布式处理软件的生态系统。
- Hadoop的核心包括存储部分Hadoop分布式文件系统(HDFS)和处理部分MapReduce。
- Hadoop设计用于批处理,通过在多个节点上分布数据和计算来处理大量数据。
- Hadoop中的数据通常存储在磁盘上,这种方式成本效益高,但与内存解决方案相比可能较慢。
- Hadoop的MapReduce不适合迭代工作负载,如机器学习和图处理中常见的。
-
Hadoop 生态系统包括 Hive(用于 SQL 查询)、Mahout(用于机器学习)等工具,用于各种大数据管理和分析任务。
-
spark
- Spark是一个主要执行分布式处理的计算引擎,但它本身不附带存储系统。
- 它提供内存数据处理,与基于磁盘的处理相比,特别是对于迭代和交互式计算,可以显著加快速度。
- Spark的处理功能不仅限于MapReduce,支持更广泛的计算模式。
- Spark支持多种开发语言,如Scala、Python和Java,并以易用性著称。
- Spark拥有强大的流处理能力,具有Spark Streaming、机器学习库MLlib和图处理GraphX。
-
它可以处理批处理、实时流处理、机器学习等多种任务,经常在同一应用程序中。
-
spark融入hadoop
Spark Core¶
- Spark将用户的代码转换成一个逻辑执行计划,即DAG。这个DAG明确了不同计算任务之间的依赖关系,Spark会基于这个DAG来安排任务的执行顺序。
- Spark Core提供有向无环图DAG的分布式并行计算框架,并提供Cache机制来支持多次迭代计算或者数据共享。
- 引入RDD抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的, 如果数据集一部分丢失,则可以根据Lineage“血统”对它们进行重建,保证 了数据的高容错性。
- 移动计算而非移动数据,RDD Partition可以就近读取分布式文件系统中的数据块到各个节点内存中进行计算。
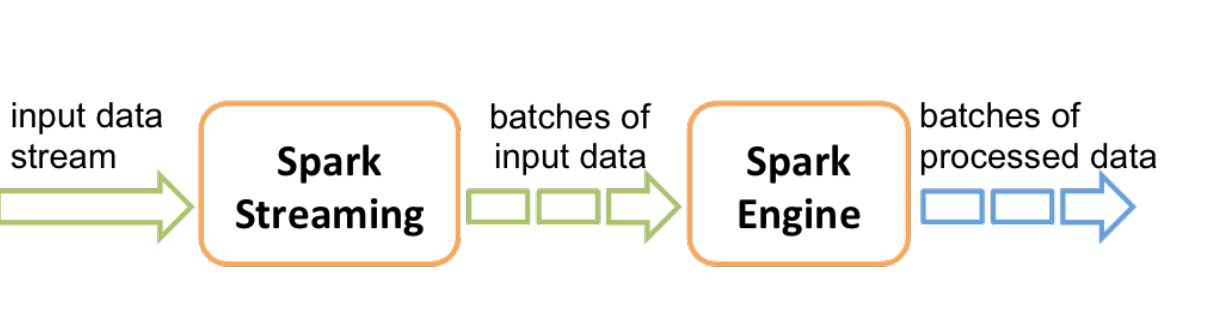
Spark Streaming¶
- Spark Streaming是一个对实时数据流进行高吞吐量、容错处理的流式处理系统, 可以对多种数据源(如Kafka、Flume、Twitter、Zero和TCP 套接字)进行类似 Map、Reduce和Join等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。
- Spark Streaming 的工作机制是对数据流进行分片,使用Spark计算引擎处理分 片数据,并返回相应分片的计算结果。
Spark SQL¶
- Spark SQL(新),与Spark程序无缝对接允许直接处理RDD,同时也可查询例如在Hive上存在的外部数据。统一数据访问接口能够统一处理关系表和RDD,使得开发人员可以轻松地使用SQL命令进行外部查询,同时进行更复杂的数据分析。与Hive高度兼容,使用标准链接。
- 性能提升原因
- 内存列存储: Spark SQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储;
- 字节码生成技术: Spark1.1.0在Catalyst模块的expressions增加了codegen模块,使用动态字节码生成技术,对匹配的表达式采用特定的代码动态编译。另外对SQL表达式都作了CG优化, CG优化的实现主要还是依靠Scala2.10的运行时反射机制;
- Scala代码优化: Spark SQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说接口统一。
Spark MLlib¶
- ML Optimizer会选择它认为最适合的已经在内部实现好了的机器学习算法和相关参数,来处理用户输入的数据,并返回模型或别的帮助分析的结果;
- MLI 是一个进行特征抽取和高级ML编程抽象的算法实现的API或平台;
- MLlib是Spark实现一些常见的机器学习算法和实用程序,包括分类、回归、聚类、协同过滤、降维以及底层优化,算法可以进行扩充;
- MLRuntime 基于Spark计算框架,将Spark的分布式计算应用到机器学习领域。MLlib面向RDD。

Spark ML¶
- 从Spark 2.0开始spark.ml
- Spark ML 是基于DataFrame进行机器学习API的开发,抽象层次更高。把数据处理的流水线抽象出来,算法相当于流水线的一个组件,可以被其他算法随意的替换,这样就让算法和数据处理的其他流程分割开来,实现低耦合。
GraphX¶
- GraphX是Spark中用于图和图并行计算的API。
- GraphX的核心抽象是Resilient Distributed Property Graph,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,有Table和Graph两种视图,而只需要一份物理存储。两种视图都有自己独有的操作符,从而获得了灵活操作和执行效率。
Spark的基本构架和组件¶
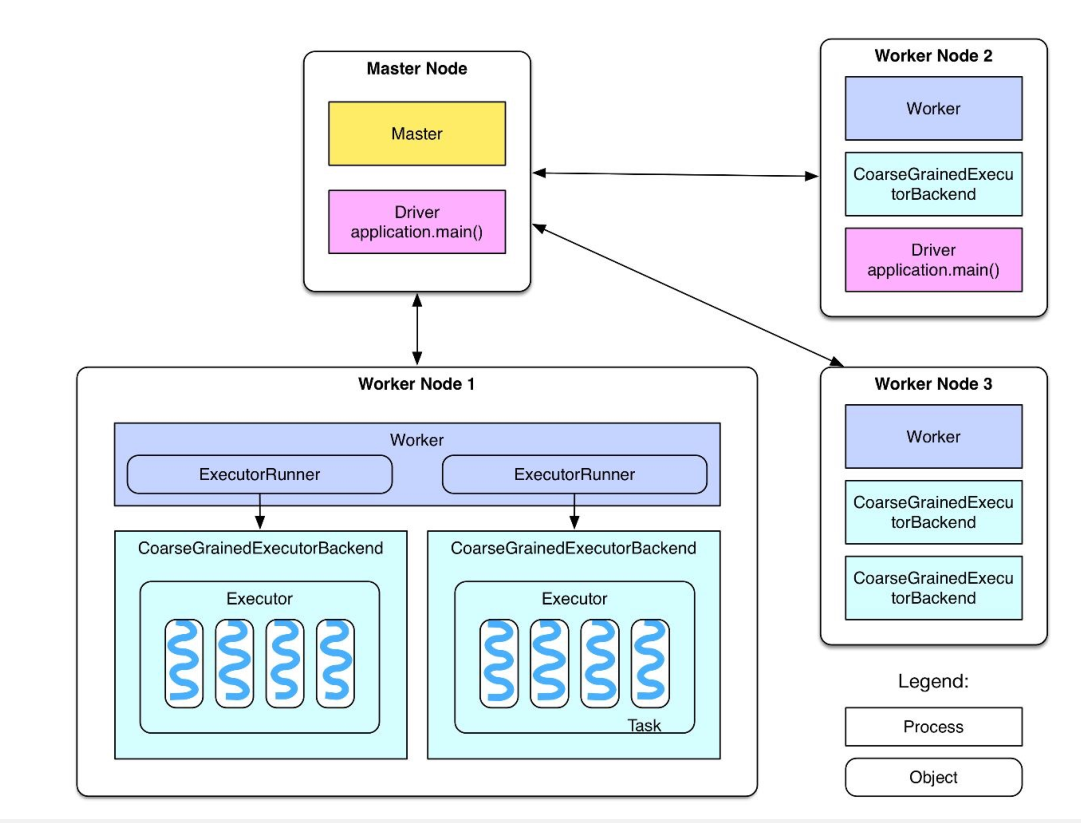
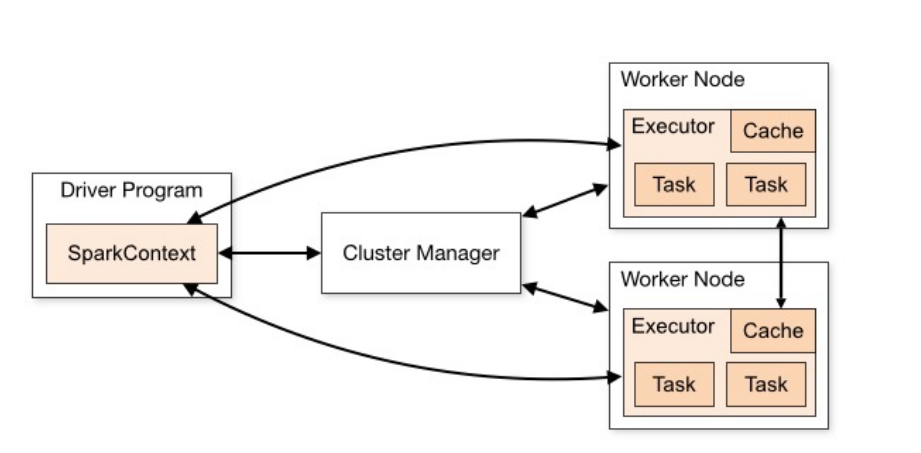
- Master Node(主节点):在集群部署时,Master Node充当控制器的角色,负责管理整个集群的正常运行,以及Worker Nodes的管理。
- Worker Node(工作节点):作为计算节点,Worker Node接收Master Node的命令执行计算任务,并进行状态汇报。
- Executor(执行器):Executor是在Worker Node上为每个Application启动的进程,它负责运行Task,将数据保存在内存或磁盘中,并将结果返回给Driver Program。
- Task(任务):Task是由SparkContext发送到Executor上执行的最小工作单元。
- Cluster Manager(集群管理器):负责资源分配的服务,可以是YARN、Kubernetes或Spark自己的集群管理器。
- Driver Program(驱动程序):运行Application main()函数并创建SparkContext的进程,负责提交Job,转化为Task,并协调各Executor间的Task调度。Driver Program可以运行在集群内或集群外。
- Application(应用程序):用户编写的基于Spark的程序,通过调用Spark API来实现数据处理的应用程序,由一个Driver程序和多个Executor程序组成,以用户定义的main方法作为入口。
- SparkContext:Spark的所有功能的主要入口点,是用户逻辑与Spark集群交互的主要接口。通过SparkContext,用户可以连接到Cluster Manager,申请计算资源,以及将应用程序依赖发送到Executors。
-
-
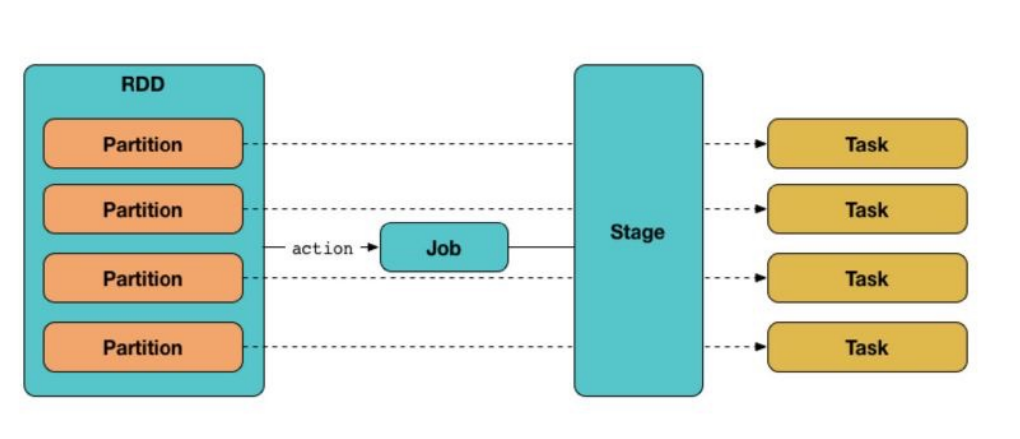
Spark 应用程序的组成结构
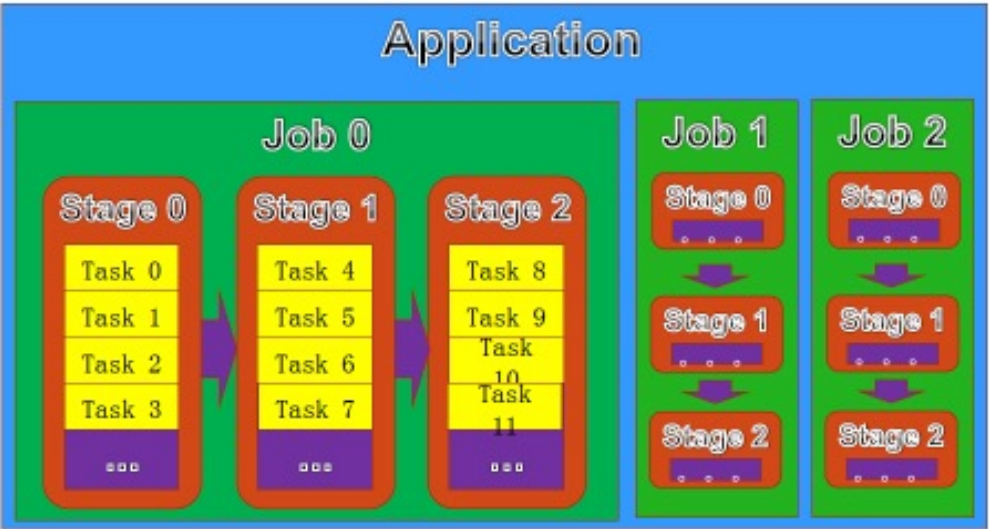
- Job:包含多个Task的并行计算,由SparkAction催生
- Stage:Job拆分成多组Task,每组任务被称为Stage,也可称为TaskSet
- Task:基本程序执行单元,在一个Executor上执行
- SparkContext:SparkContext由用户程序启动,是Spark运行的核心模块,它对一个Spark程序进行了必要的初始化过程:
- 创建SparkConf类的实例:这个类中包含了用户自定义的参数信息和Spark配置文件中的一些信息等等(用户名、程序名、Spark版本等)
- 创建SparkEnv类的实例:这个类中包含了Spark执行时所需要的许多环境对象,例如底层任务通讯的Akka Actor System、block manager、serializer等
-
创建调度类的实例:Spark中的调度分为TaskScheduler和DAGScheduler两种,而它们的创建都在SparkContext的初始化过程中。
-
Spark Driver
-

-
Worker node
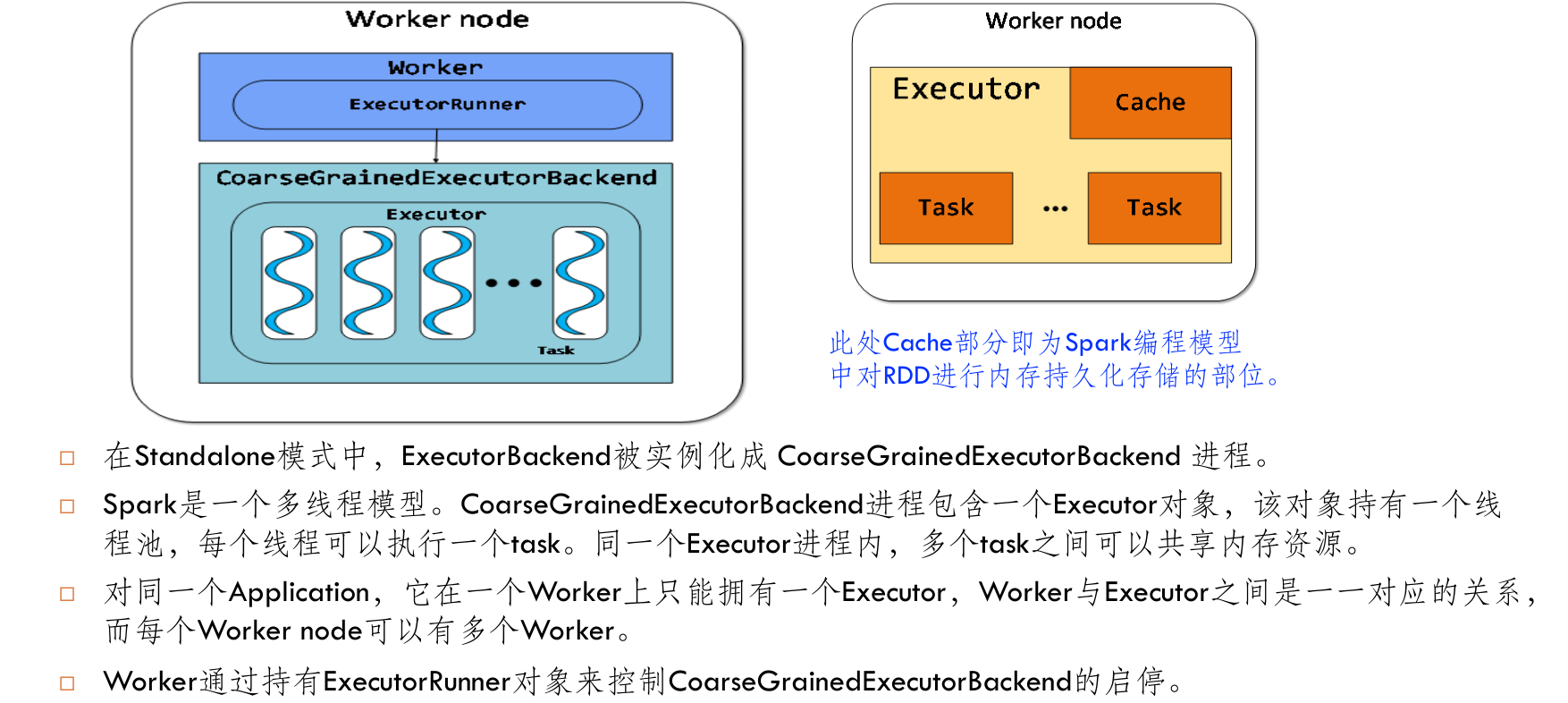
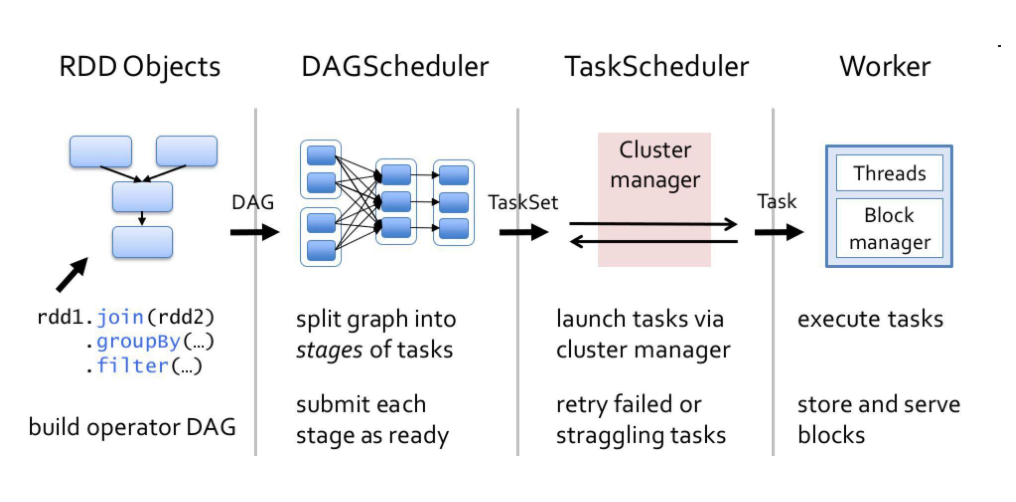
spark的调度¶
- 调度器
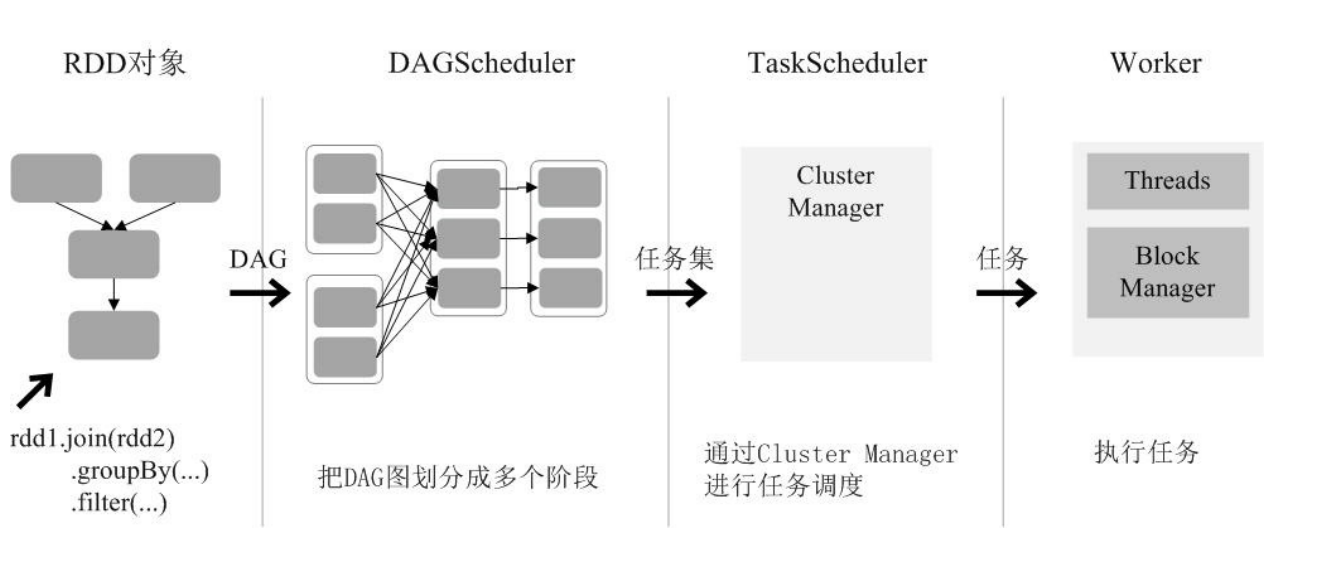
- DAGScheduler 主要是把一个 Job 根据 RDD 间的依赖关系,划分为多个 Stage,对于划分后的每个 Stage 都抽象为一个由多个Task 组成的任务集(TaskSet),并交给 TaskScheduler 来进行进一步的任务调度。
-
TaskScheduler 负责对每个具体的 Task 进行调度。
- 一个 TaskSet 交给 TaskScheduler 后,TaskScheduler会为每个 TaskSet 进行任务调度,Spark 中的任务调度分为两种:FIFO(先进先出)调度和 FAIR(公平调度)调度。
- FAIR 调度:在多个作业间“公平”地分配计算资源,尤其是在有多个 Spark 作业同时运行时。FAIR 调度器允许每个作业获取相等的资源份额,确保没有单个作业会饿死,即长时间得不到足够资源。
-
调度过程
- 创建 RDD 并生成 DAG,由 DAGScheduler 分解DAG 为包含多个 Task(即 TaskSet)的 Stages,再将 TaskSet 发送至TaskScheduler,由 TaskScheduler 来调度每个 Task,并分配到 Worker 节点上执行,最后得到计算结果。
Spark的程序执行过程¶
- 基本过程:
- 程序提交:用户编写的 Spark 程序提交到相应的 Spark 运行框架中
- 创建 SparkContext:Spark 程序启动时,首先会创建一个 SparkContext 对象为本次程序的运行环境,这个对象是程序与 Spark 集群交互的主要接口。
- 集群资源连接:SparkContext 会与集群管理器进行通信,以获取执行程序所需的资源。
- 获取 Executor 节点:一旦资源分配完成,SparkContext 会在集群中可用的节点上启动 Executor 进程。
- 代码分发:SparkContext 将用户程序中的任务代码和函数序列化后发送到各个 Executor。
-
任务执行:最后,SparkContext 根据数据的分区和任务的依赖关系,将任务分发到不同的 Executor 执行。
-
作业(Job):
- 在Spark中,一个Job对应于一个action操作触发的一系列计算任务。每次调用action操作时,Spark会提交一个新的Job。
-
Job 由一系列转换操作(transformations)构成,这些转换定义了从输入数据到获取最终结果所需的计算步骤。
-
阶段(Stage):
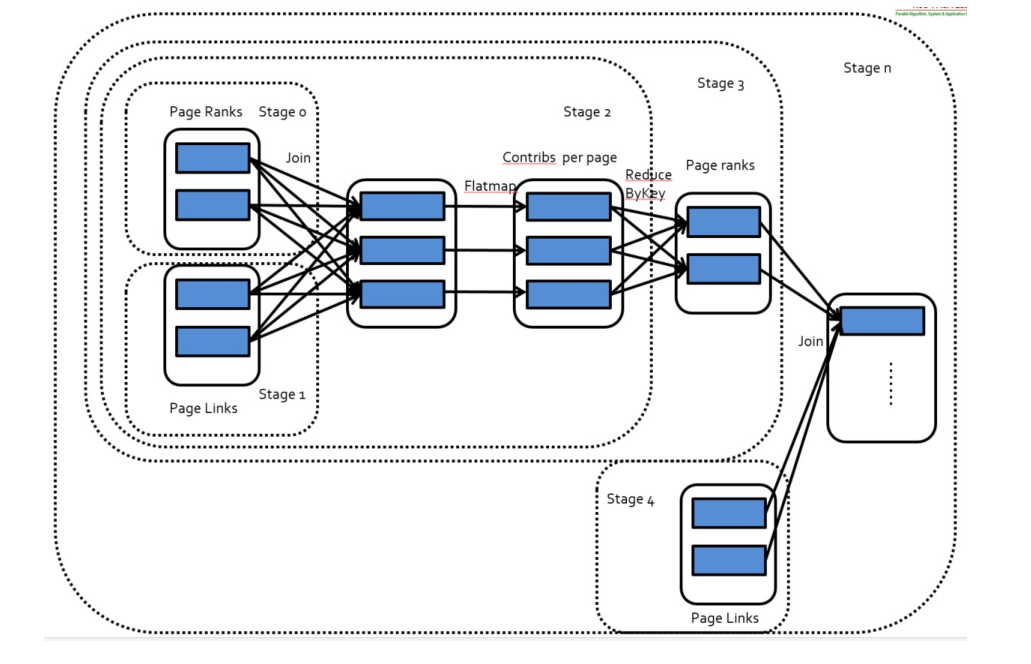
- Stage是Job的中间计算过程。Spark会根据transformation操作之间的依赖关系(窄依赖或宽依赖)将Job划分为多个Stage。
- Shuffle Stage:在宽依赖的情况下会触发Shuffle Stage。宽依赖意味着数据需要重新组织,如通过网络在不同节点的Executors之间进行交换(shuffle)。
- Final Stage:每个Job至少有一个Final Stage,这是Job中最后一个Stage,它产生action操作的最终结果。
- Shuffle操作:
-
Shuffle 是宽依赖操作的结果,它涉及跨越不同Executor 的数据重新分布,以满足特定的 transformation 需求(例如,
reduceByKey、groupBy等)。 -
任务(Task):
- Task是在Executor上执行的最小工作单元。每个Stage被划分为多个Task,这些Task根据RDD的分区来划分,每个Task处理一个分区的数据。
- Task是Stage的具体执行实体,当一个Stage中的所有Task执行完毕,就意味着该Stage的计算完成。
Spark的技术特点¶
- RDD(弹性分布式数据集):
- Spark的核心抽象,代表一个不可变、分布式的数据集合,可以在多个计算节点间进行并行操作。
- Transformation & Action:
- Transformation:这类操作是惰性的,即它们不会立即执行计算,而是建立一个计算的指令链(DAG)。
- Action:这类操作会触发实际的计算过程,因为它们需要Spark提供最终的结果。
- Lineage(血统关系):
- 用于追踪RDD的变化历史,如果某个RDD的部分数据丢失,可以利用Lineage信息重新计算丢失的数据。
- Spark调度:
- 采用事件驱动的库Akka来处理任务调度,优化了资源利用率,减少了开销。
- API:
- Spark主要使用Scala开发,并提供了Scala API。同时,也支持Java和Python等语言的API。
- Spark生态:
- 包括Spark SQL、Spark Streaming和GraphX等,支持多种计算模型,适用于批处理、实时数据处理、交云计算和图计算等多种场景。
- Spark部署:
- 可以以Standalone模式运行,也可以在YARN、Kubernetes等集群管理器上运行。适合大数据处理,尤其是需要频繁读取和处理相同数据集的应用。
- 适用场景:
- 适合需要反复操作特定数据集的应用场合,特别是数据量大且计算密集的任务。
- 不适用场景:
- 不适合需要异步和细粒度更新状态的应用,如实时的web服务存储或增量更新的应用,例如实时的web爬虫和索引。
- 实时统计分析:
- 对于数据量不是非常大但要求实时分析和统计的需求,Spark也提供了相应的解决方案。
- 综上所述,Spark是一种为大规模数据处理而设计的快速通用的分布式计算引擎,适合于完成一些迭代式、关系查询、流式处理等计算密集型任务
Spark编程¶
Spark的部署模式¶
- local
- 常用于本地开发测试
- Standalone
- Spark 自带的一种集群管理模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
- Spark on YARN
- Spark on Kubernetes
本地运行(使用idea+java)¶
- 无需配置spark环境,先下载spark压缩包后解压
- 在idea创建新项目(可以不使用maven)
- 导入spark下的jars文件夹
- file/项目结构选项
-
-
由于程序运行后会自动结束,就看不到web界面了,可以添加
Thread.sleep(100000); -
webui在4040端口
-
程序示例
package org.example; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import org.apache.spark.api.java.function.Function; public class Main { public static void main(String[] args) { // 配置 Spark SparkConf conf = new SparkConf().setAppName("SparkTest").setMaster("local"); JavaSparkContext sc = new JavaSparkContext(conf); // 读取本地文件系统中的文本文件,此处需替换为实际路径 String path = "C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\test.txt"; JavaRDD<String> lines = sc.textFile(path); // 计算文本文件的行数 long numLines = lines.count(); // 打印结果 System.out.println("Number of lines in the file: " + numLines); try { Thread.sleep(100000); } catch (InterruptedException e) { throw new RuntimeException(e); } // 关闭 SparkContext sc.close(); } } -
添加scala支持
- 直接创建scala项目,scala项目内可以直接使用java
Spark编程模型¶
- 以RDD为核心
- RDD弹性分布式数据集
- 是一种分布式的内存抽象,允许在大型集群上执行基于内存的计算
-
RDD只读、可分区,这个数据集的全部或部分可以缓存在内存中,在多次计算间重用
- 一旦创建,RDD 的数据就不能被修改。任何对 RDD 的转换操作都会生成一个新的 RDD。
- RDD 能够在节点失败的情况下恢复数据。
-
scala spark程序示例
import org.apache.spark.{SparkConf, SparkContext} object Main { def main(args: Array[String]) { //定义一个sparkConf,提供Spark运行的各种参数,如程序名称、用户名称等 val conf = new SparkConf().setAppName("Spark Pi").setMaster("local") //创建Spark的运行环境,并将Spark运行的参数传入Spark的运行环境中 val sc = new SparkContext(conf) //调用Spark的读文件函数,从HDFS中读取Log文件,输出一个RDD类型的实例:fileRDD。具体类型:RDD[String] val fileRDD = sc.textFile("C:\\Users\\MSI\\OneDrive\\study\\作业\\金融大数据\\test.txt") //调用RDD的filter函数,过滤fileRDD中的每一行,如果该行中含有ERROR,保留;否则,删除。生成另一个RDD类型的实例:filterRDD。具体类型:RDD[String] //注:line=>line.contains(“ERROR”)表示对每一个line应用contains()函数 val filterRDD = fileRDD.filter(line => line.contains("ERROR")) //统计filterRDD中总共有多少行,result为Int类型 val result = filterRDD.count() //打印结果 println(result) sc.stop() //关闭Spark } }
RDD 的基本概念¶
- RDD 之间地依赖关系
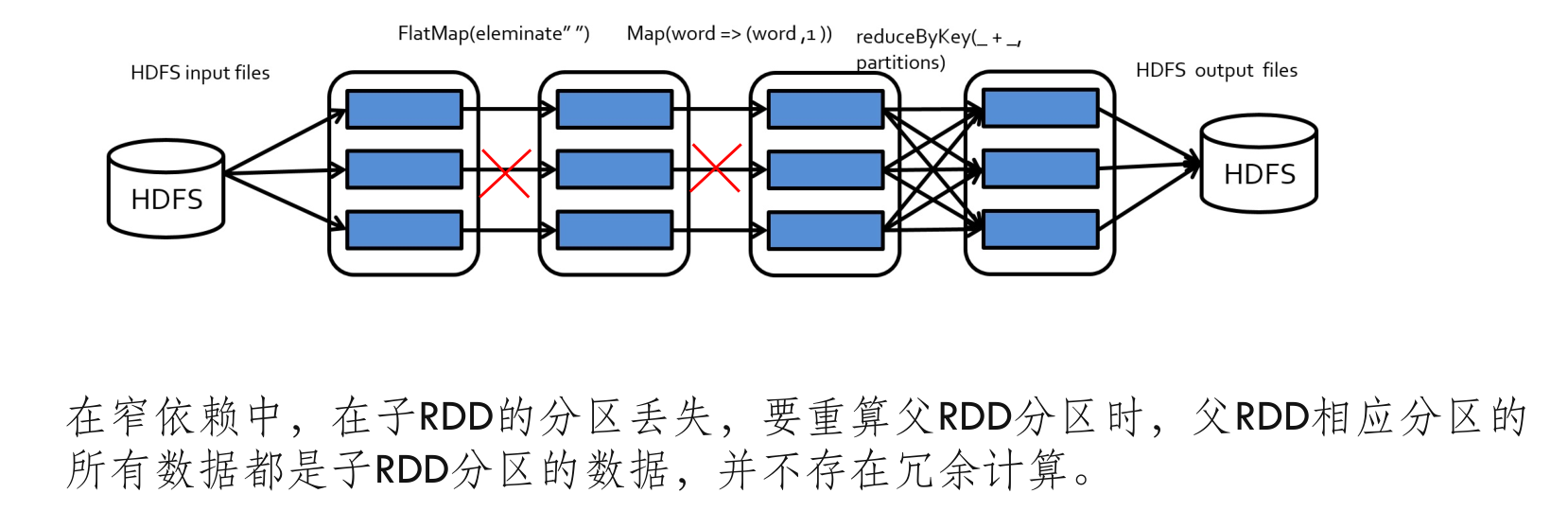
- 窄依赖:窄依赖指的是每个父 DD 分区最多被一个子 RDD 分区使用的情况,因此计算可以在不同的节点上局部进行,而不需要跨节点的数据混洗(如
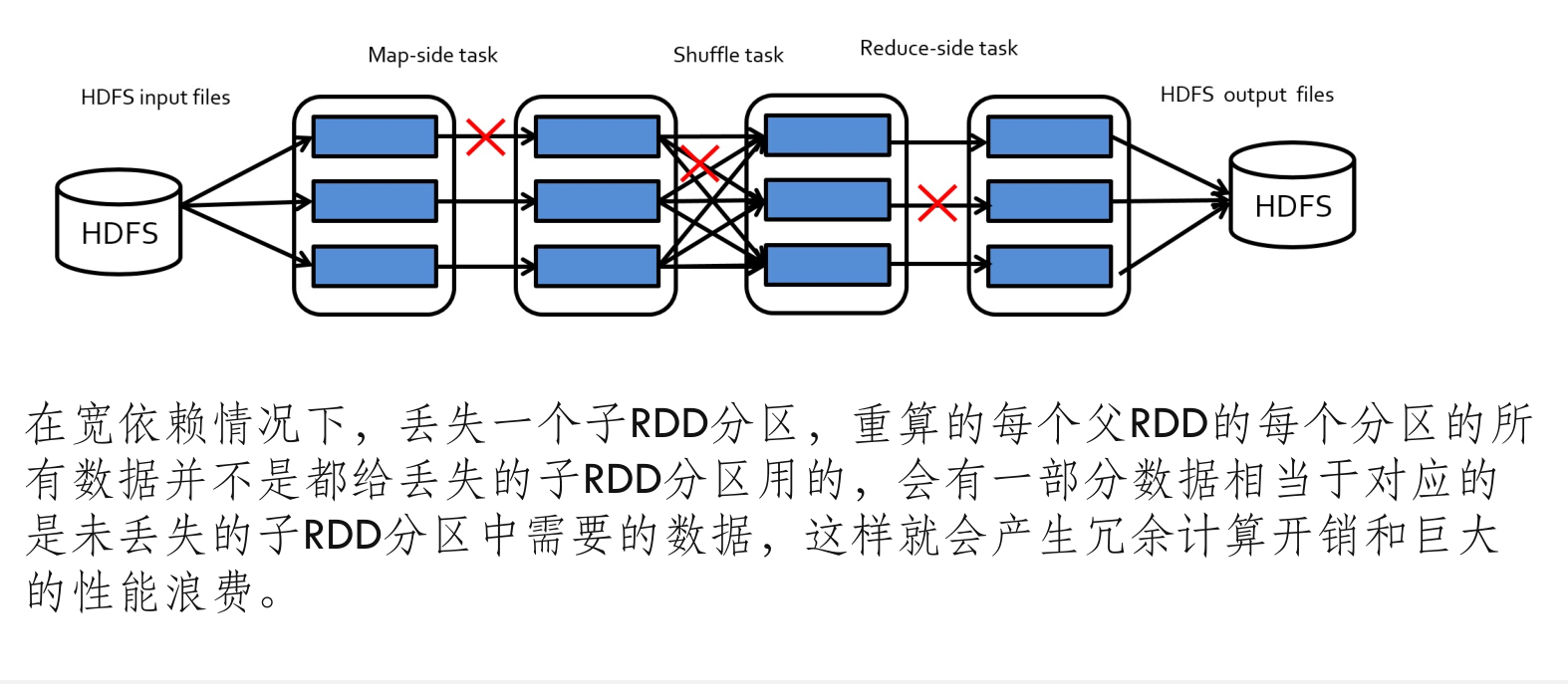
map()或filter()操作) - 宽依赖:宽依赖是指父 RDD 的多个分区被多个子 RDD 分区使用的情况。在宽依赖中,子 RDD 分区的计算依赖于父 RDD 中的多个分区。通常在需要进行数据混洗(Shuffle)的操作中会出现宽依赖,例如
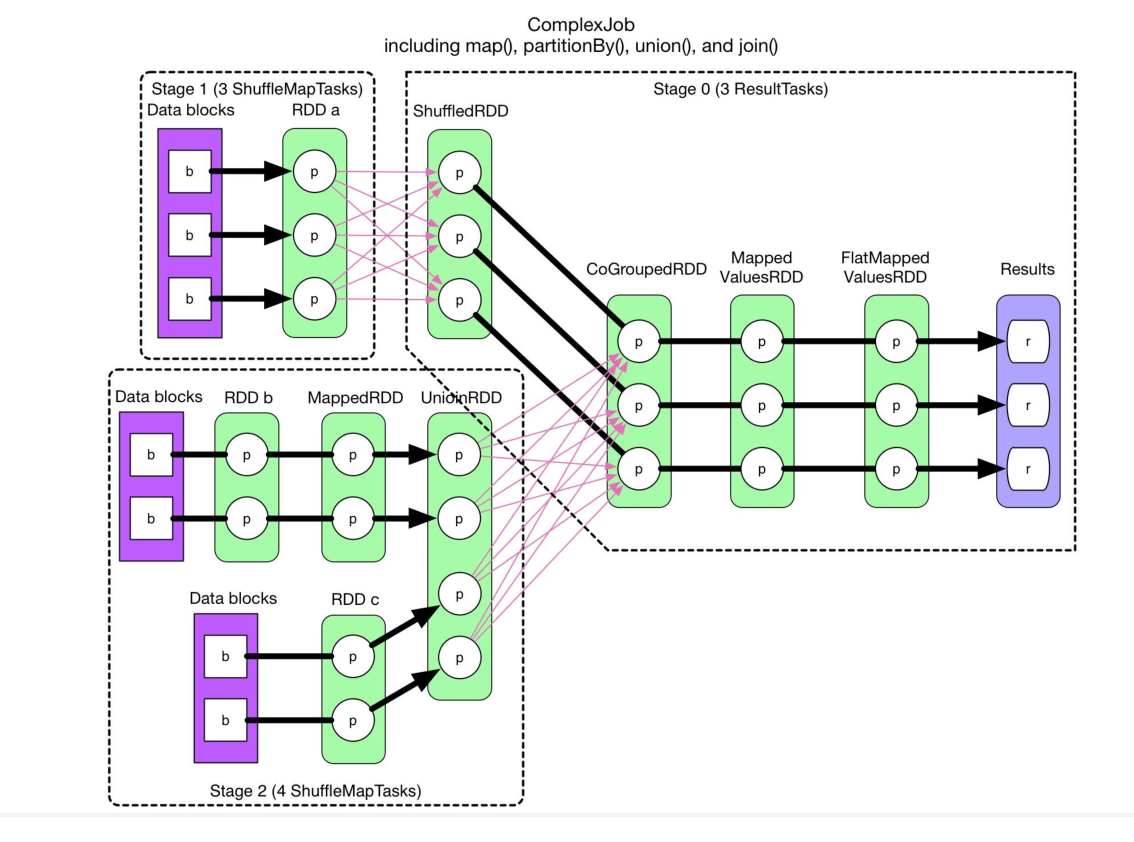
groupBy()或reduceByKey()操作。 - Spark 通过分析各个 RDD 的依赖关系生成了 DAG,具体划分方法是:在 DAG 中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的 RDD 加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。
- 把一个 DAG 图划分成多个“阶段”以后,每个阶段都代表了一组关联的、相互之间没有 Shuffle 依赖关系的任务组成的任务集合。
-
-
RDD 的运行
- Spark 采用惰性机制,Transformation 算子的代码不会被立即执行,只有当遇到第一个 Action 算子时,会生成一个 Job,并执行前面的一系列 Transformation 操作。一个 Job 包含 N 个 Transformation 和 1 个 Action。
- 每个 Job 会分解成一系列可并行处理的 Task,然后将 Task 分发到不同的 Executor 上运行。
- Task 是 Spark 执行的最小单元。每个 Task 对应于对 RDD 的一个分区(Partition)的操作。Task 的执行是并行的,但是在一个 Task 内部处理 Partition 的数据是串行的。
- Stage 是一系列宽依赖边界之间的 Task 集合,通常它们可以通过窄依赖串行执行。
-
ShuffleMapTask:在 Stage 的计算结果需要被后续 Stage 使用时,这些 Stage 会执行 ShuffleMapTask。ShuffleMapTask 的输出会被写入磁盘(或内存),以便其他 Stage 的 Task 可以进行 Shuffle 读取。
-
RDD 的容错实现
- Lineage(血统系统、依赖系统):RDD 提供一种基于粗粒度变换的接口,这使得 RDD可以通过记录 RDD 之间的变换,而不需要存储实际的数据就可以完成数据的恢复,使得 Spark 具有高效的容错性。
- CheckPoint(检查点):对于很长的 lineage 的 RDD 来说,通过 lineage 来恢复耗时较长。因此,在对包含宽依赖的长血统的 RDD 设置检查点操作非常有必要。
-
-
RDD 持久化
- 未序列化的 Java 对象,存在内存中:性能表现最优。
- 序列化的数据,存于内存中,将对象的状态信息转换为可存储形式。
-
磁盘存储:适用于 RDD 太大难以在内存中存储的情形。
-
RDD 内部设计
- 每个 RDD 都包含:
- 一组 RDD 分区(partition),即数据集的原子组成部分
- 对父 RDD 的一组依赖,这些依赖描述了 RDD 的 Lineage
- 一个函数,即在父 RDD 上执行何种计算
- 元数据,描述分区模式和数据存放的位置
- 分区
- RDD 是弹性分布式数据集,通常 RDD 很大,会被分成很多个分区,分别保存在不同的节点上。RDD 分区的一个分区原则是使得分区的个数尽量等于集群中的 CPU 核心(core)数目。
- partition 是 RDD 的最小单元,RDD 是由分布在各个节点上的 partition 组成的。partition 的数量决定了 task 的数量,每个 task 对应着一个 partition。
RDD 编程¶
基本RDD操作¶
- 创建
- 从文件读取
val file=sc.textFile(“hdfs:///root/Log”) -
从数组获取
val max5RDD = sc.parallelize(max5) -
转换:懒惰操作,先只定义一个新的RDD,等到使用时再具体计算内部的值
-
val filterRDD=fileRDD.filter(line=>line.contains(“ERROR”)) -
动作:立即计算这个RDD的值,并返回结果给程序,或者将结果写入到外存储中。
val result = filterRDD.count()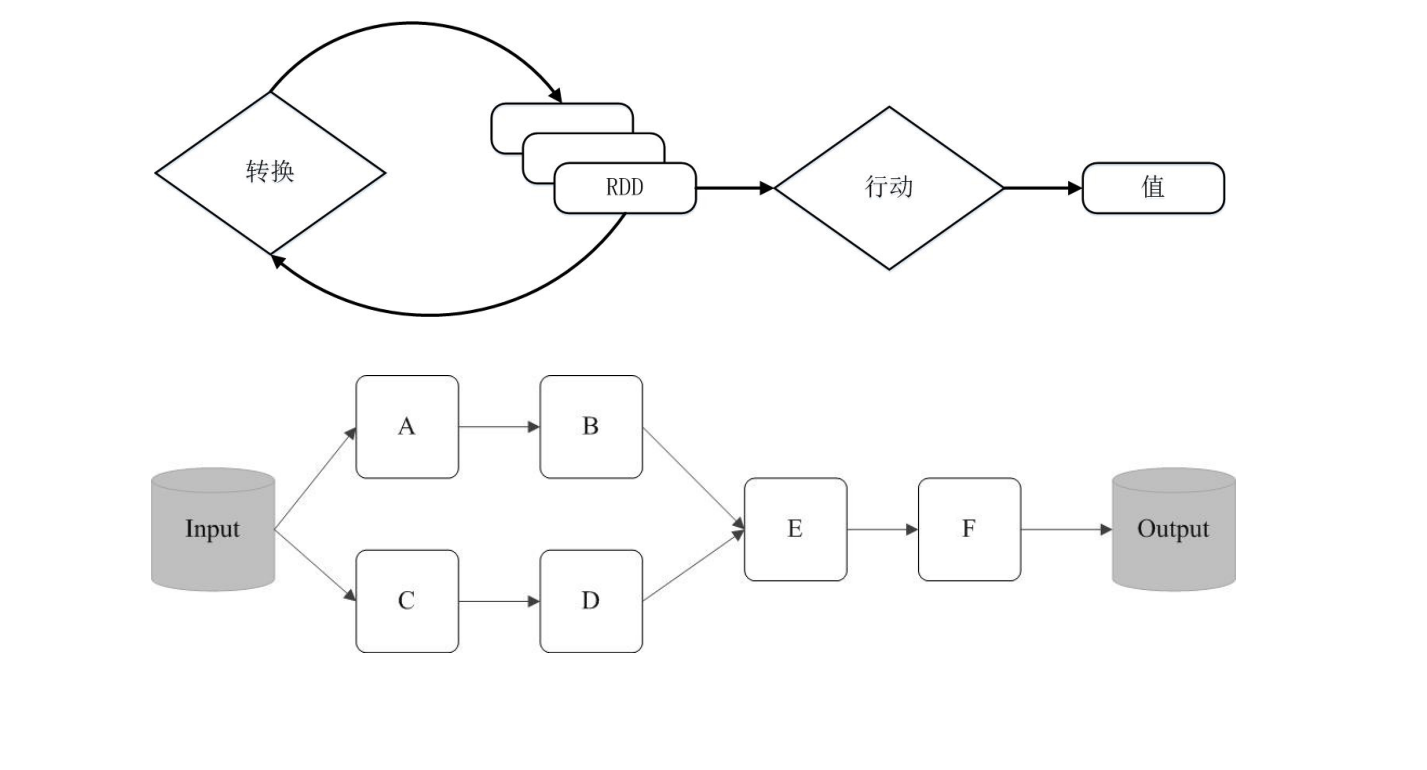
重点¶
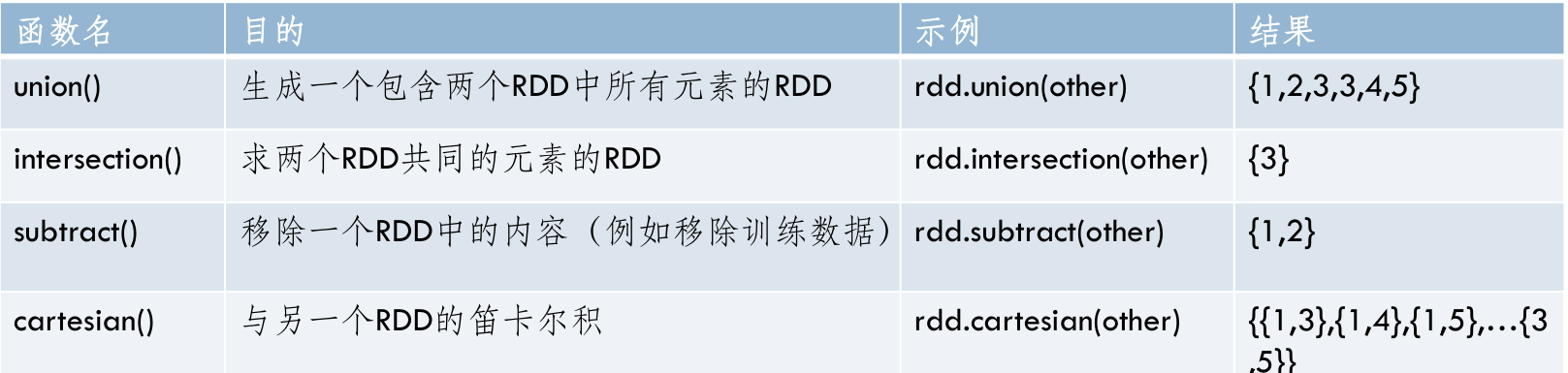
- Spark支持的一些常用transformation操作
- rdd: {1,2,3,3}
- rdd: {1,2,3} 和 other: {3,4,5}
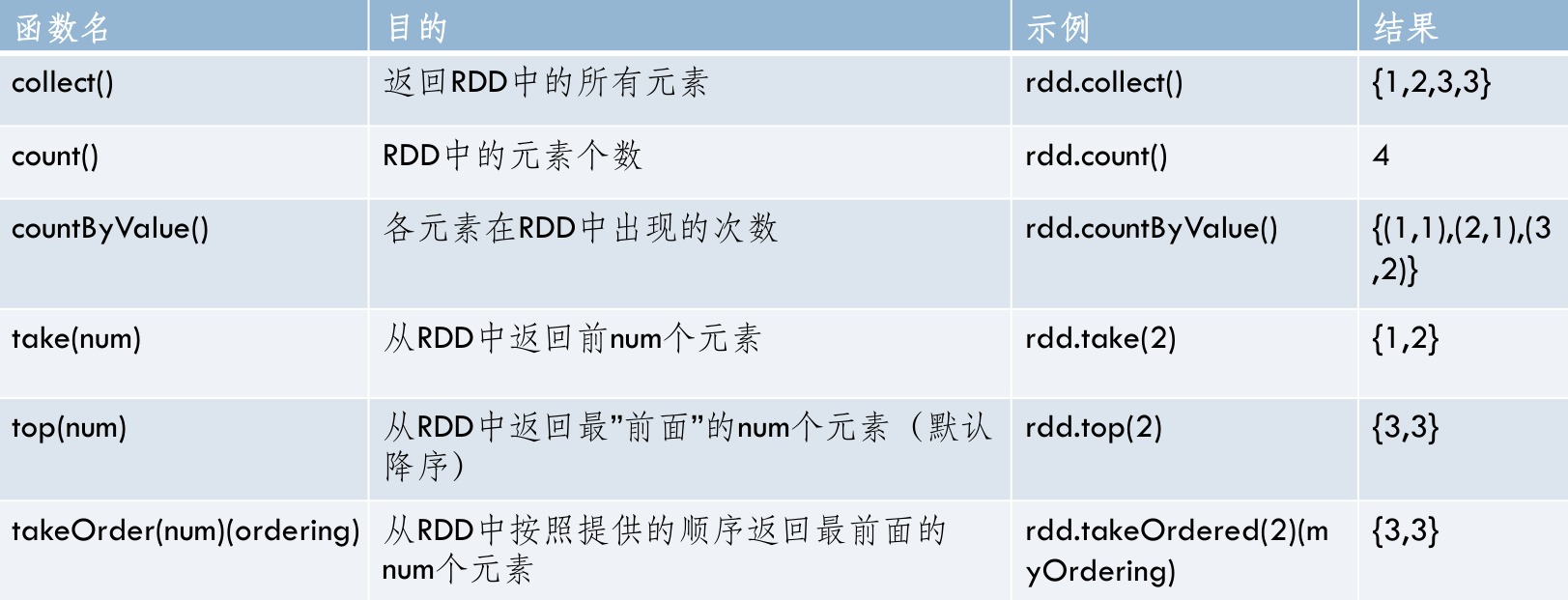
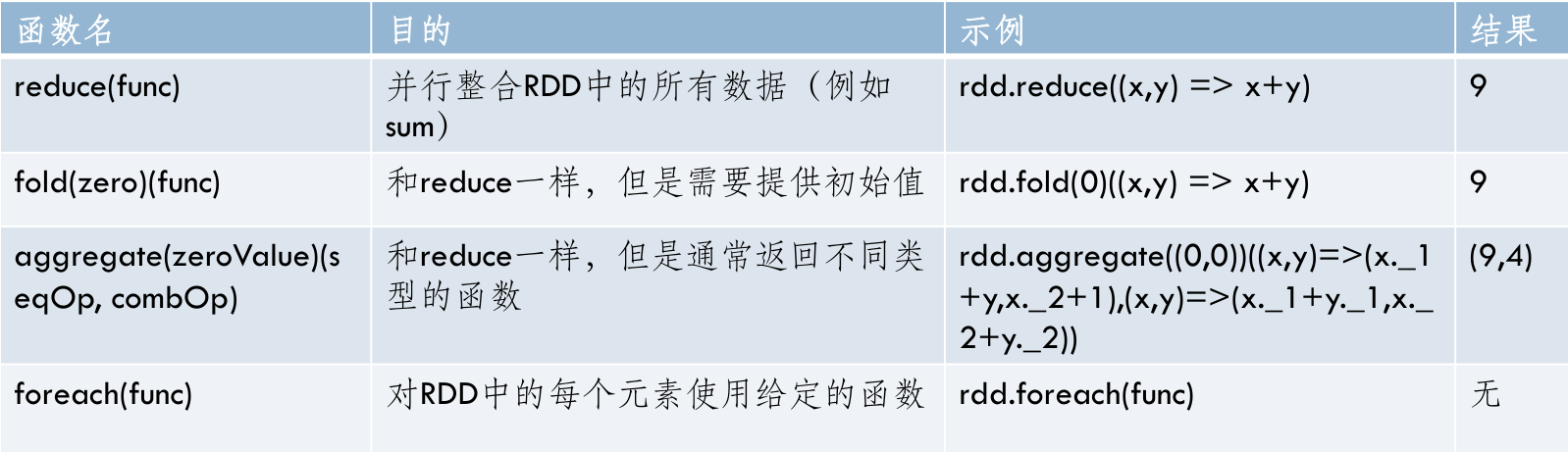
- Spark支持的一些常用action操作
- rdd: {1,2,3,3}
- rdd: {1,2,3,3}

键值对操作¶
- 键值对RDD(Pair RDD)通常用来进行聚合计算
- Pair RDD的Transformation操作
- Pair RDD: {(1,2),(3,4),(3,6)}
-
rdd = {(1,2),(3,4),(3,6)} other = {(3,9)}
-
Pair RDD也还是RDD。Pair RDD支持RDD所支持的函数。
result = paris.filter{case (key, value) => value.length <20}- Pair RDD的Action操作
- RDD = {(1,2),(3,4),(3,6)}
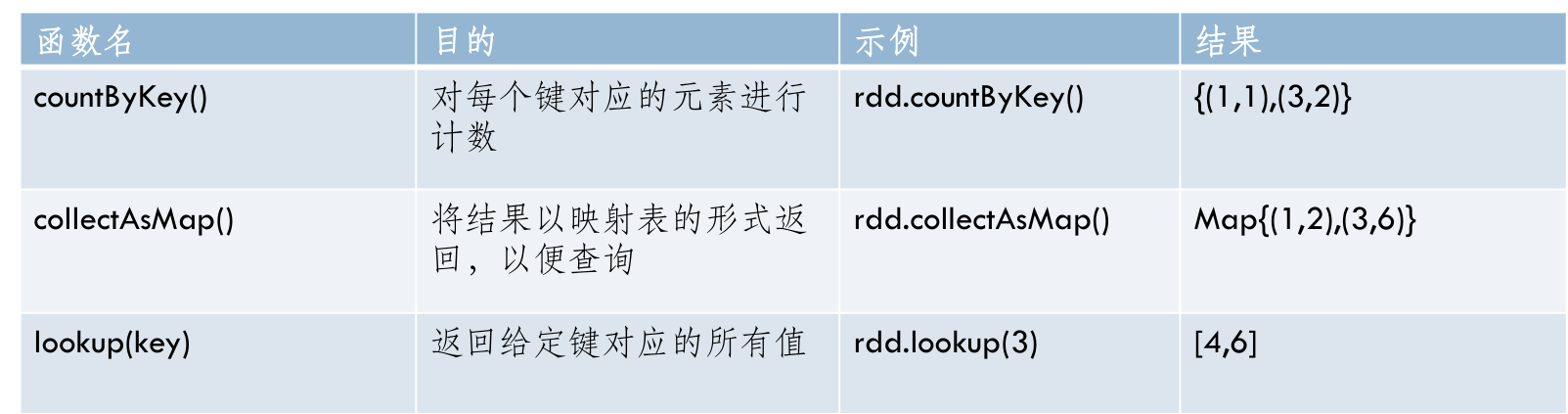
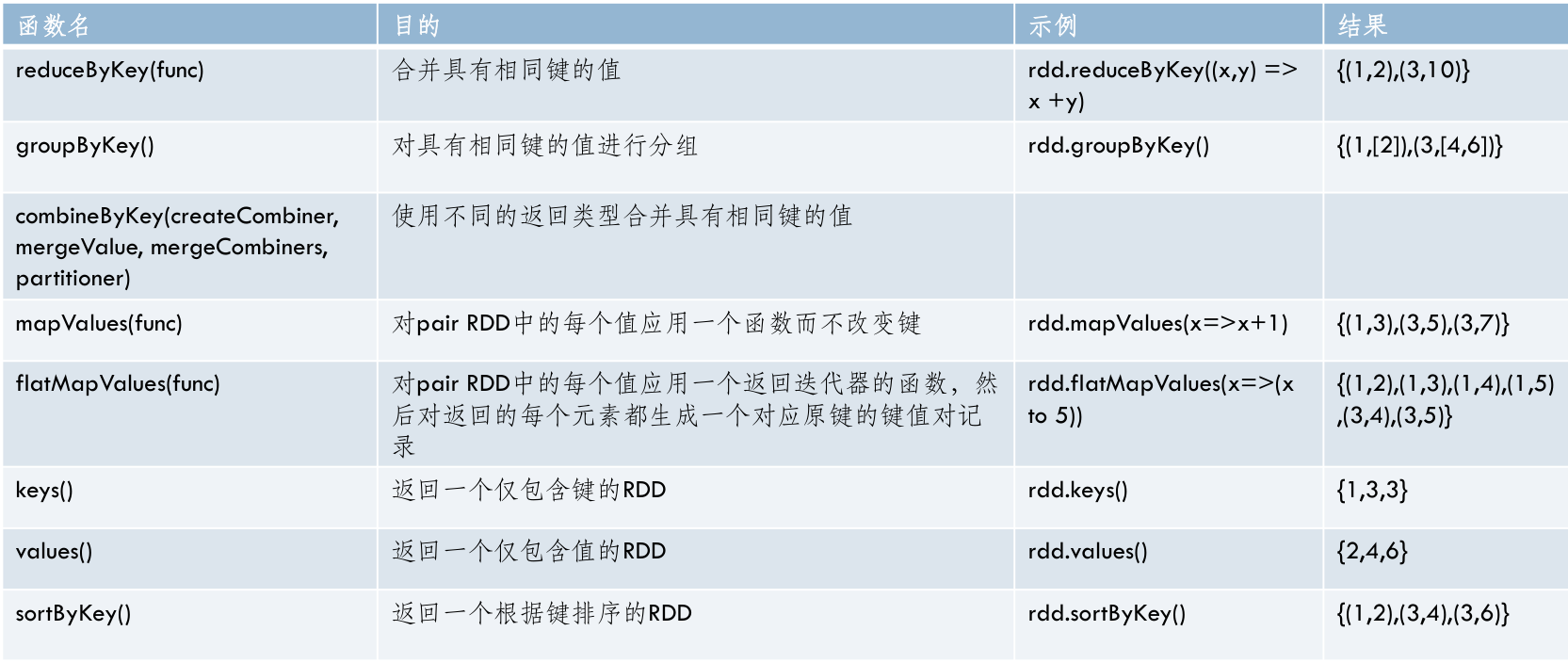

具体说明¶
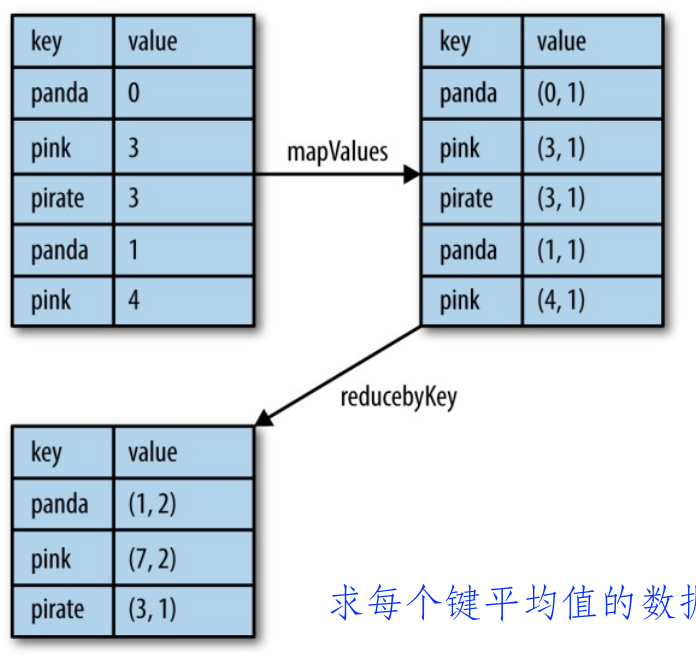
- reduceByKey()
-
rdd.mapValues(x => (x, 1)).reduceByKey((x, y) => x._1 + y._1, x._2 + y._2)) -
combineByKey()
-
包含三个函数:
createCombiner:对每个键的第一个值(新元素)进行转换,并返回一个"combiner"(通常是一个累加器或其他数据结构)。mergeValue:将一个新的值合并到现有的"combiner"中。(如果之前遇到过,将该键的累加器对应的当前值与这个新的值进行合并)mergeCombiners:当两个"combiners"需要被合并时,用于归并两个"combiners"的函数。(如果多个分区都有对应于同一个键的累加器,则需要将各个分区的结果进行合并)
-
groupByKey()
- RDD: [K, V] ->[K, Iterable[V]]
- cogroup()
- 对多个共享同一个键的RDD进行分组
-
RDD: [K, V] & [K, W] -> [(K, (Iterable[V], Iterable[W]))]
-
连接
- 内连接(join):只有两个pair RDD都存在的键才输出。
- 左外连接(leftOuterJoin):源RDD的每个键都有对应的记录。每个键相应的值是由一个源RDD中的值与一个包含第二个RDD的值的Option对象组成的二元组。
- 右外连接(rightOuterJoin):预期结果中的键必须出现在第二个RDD中,二元组中可缺失的部分则来自于源RDD而非第二个RDD。
- collectAsMap() 作用于K-V类型的RDD上,作用与collect不同的是collectAsMap函数不包含重复的key,对于重复的key,后面的元素覆盖前面的元素。
数据读取与保存¶
- 文件格式
-

-
文本文件:输入的每一行都会成为RDD的一个元素;也可以将多个完整的文本文件一次性读取为一个Pair RDD,键是文件名,值是文件内容。
val input = sc.textFile(“file:///home/spark/README.MD”) input.saveAsTextFile(outputFile) val input = sc.wholeTextFiles(“file:///home/spark/salefiles”) -
JSON:将数据作为文本文件读取,然后使用JSON解析器来对RDD的值进行映射操作。
-
CSV:当作普通文本文件读取,再对数据进行处理。每条记录都没有相关联的字段名,只能得到对应的序号。常规做法是使用第一行中每列的值作为字段名。
import Java.io.StringReader import au.com.bytecode.opencsv.CSVReader … val input = sc.textFile(inputFile) val result = input.map{ line => val reader = new CSVReader(new StringReader(line)); reader.readNext(); } -
Spark SQL中的结构化数据源*
-
Hive:Spark SQL可以读取Hive支持的任何表
import org.apache.spark.sql.hive.HiveContext val hiveCtx = new org.apache.spark.sql.hive.HiveContext(sc) val rows = hiveCtx.sql(“SELECT name, age FROM users”) val firstRow = rows.first() println(firstRow.getString(0)) -
JSON:Spark SQL 可以自动推断出 JSON 数据的结构信息
import org.apache.spark.sql.hive.HiveContext val hiveCtx = new org.apache.spark.sql.hive.HiveContext(sc) val tweets = hiveCtx.jsonFile(“tweets.json”) tweets.registerTempTable(“tweets”) val results = hiveCtx.sql(“SELECT user.name, text FROM tweets”) -
Java数据库连接:org.apache.spark.rdd.JdbcRDD
def createConnection() = { Class.forName(“com.mysql.jdbc.Driver”).newInstance(); DriverManager.getConnection(“jdbc:mysql:/localhost/test?user=holden”); } def extractValues(r: ResultSet) = { (r.getInt(1), r.getString(2)) } val data = new JdbcRDD(sc, createConnection, ”SELECT * FROM panda WHERE ? <= id and id <= ?”, lowerBound = 1, upperBound = 3, numPartitions = 2, mapRow = extractValues) println(data.collect().toList) - Spark可以通过Hadoop输入格式访问HBase,这个输入格式会返回键值对数据,其中键的类型为org.apache.hadoop.hbase.io.ImmutableBytesWritable,值的类型为 org.apache.hadoop.hbase.client.Result.
共享变量¶
- 广播变量和累加器
- 广播变量用来把变量在所有节点的内存之间进行共享
-
累加器则支持在所有不同节点之间进行累加计算
-
广播变量
- 在分布式计算中,当同一个数据需要在多个节点上重复使用时,如果每次都通过网络传输这些数据,会造成大量的网络通信开销。为了优化这个过程,Spark 提供了广播变量,允许程序员将大型只读值高效地分发到所有工作节点,而不是在每个任务中发送这些数据。
-
可以通过调用SparkContext.broadcast(v)来从一个普通变量v中创建一个广播变量。这个广播变量就是对普通变量v的一个包装器,通过调用value方法就可以获得这个广播变量的值
val broadcastVar = sc.broadcast(Array(1, 2, 3)) broadcastVar.value//变量值的获取 -
这个广播变量被创建以后,那么在集群中的任何函数中,都应该使用广播变量broadcastVar的值,而不是使用v的值,这样就不会把v重复分发到这些节点上。此外,一旦广播变量创建后,普通变量v的值就不能再发生修改,从而确保所有节点都获得这个广播变量的相同的值。
-
累加器
- 累加器是仅仅被相关操作累加的变量,通常可以被用来实现计数器(counter)和求和(sum)。Spark原生地支持数值型(numeric)的累加器,程序开发人员可以编写对新类型的支持。
- 一个数值型的累加器,可以通过调用SparkContext.longAccumulator()或者SparkContext.doubleAccumulator()来创建。运行在集群中的任务,就可以使用add方法来把数值累加到累加器上,但是,这些任务只能做累加操作,不能读取累加器的值,只有任务控制节点可以使用value来读取累加器的值
al accum = sc.longAccumulator("My Accumulator") sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum.add(x)) accum.value
示例¶
Word count¶
val file = spark.textFile("hdfs://.. ")
val counts = file.flatMap (line => line.split("")) //分词
.map(word =>(word, 1)) //对应mapper的工作
.reduceByKey(_ + _ ) //相同key的不同value之间进行”+”运算
counts.saveAsTextFile ("hdfs://...")
K-Means¶
- 算法流程
- 从HDFS上读取数据转化为RDD,将RDD中的每个数据对象转化为向量形成新的RDD存入缓存,随机抽样K个向量作为全局初始聚类中心
- 计算RDD中的每个向量p到聚类中心cluster centers的距离,将向量划分给最近的聚类中心,生成以
- 聚合新生成的RDD中Key相同的
- 对生成的RDD中每一个元素
- 判断是否达到最大迭代次数或者迭代是否收敛,不满足条件则重复步骤2到步骤5,满足则结束,输出最后的聚类中心
//读取数据初始化聚类
val lines = sc.textFile("data/mllib/kmeans_data.txt" )
/*
1.0 2.0 3.0
4.0 5.0 6.0
7.0 8.0 9.0
*/
val data = lines.map(s => s.split(" ").map(_.toDouble)).cache()
/*
Array[Array[Double]] = Array(
Array(1.0, 2.0, 3.0),
Array(4.0, 5.0, 6.0),
Array(7.0, 8.0, 9.0)
)
*/
val kPoints= data.takeSample(false, K, 42).map(s => spark.util.Vector(s))
//takeSample(Boolean, Int, Long)采样函数,false表示不使用替换方法采样,K表示样本数,42表示随机种子
/*
Array[Vector] = Array(
Vector(1.0, 2.0, 3.0),
Vector(7.0, 8.0, 9.0)
)
*/
//划分数据给聚类中心
val closest = data.map //产生<ClusterID, (p, 1)>键值对
(p => ( closestPoint(spark.util.Vector(p), kPoints), (p, 1) )
//closestPoint计算最近的聚类中心,产生ClusterID (spark.util.Vector(p), 1)
)
/*
Array[(Int, (Array[Double], Int))] = Array(
(0, (Array(1.0, 2.0, 3.0), 1)),
(0, (Array(4.0, 5.0, 6.0), 1)),
(1, (Array(7.0, 8.0, 9.0), 1))
)
*/
//聚合生成新的聚类中心
//同一个聚类下所有向量相加并统计向量个数
val pointStats= closest.reduceByKey{
case ((x1, y1), (x2, y2)) => (x1 + x2, y1 + y2) //产生(pm, n)
} //将同一clusterID的所有(p, 1)的两个分量分别相加,得到<ClusterID, (pm, n)>
/*
Array[(Int, (Array[Double], Int))] = Array(
(0, (Array(5.0, 7.0, 9.0), 2)),
(1, (Array(7.0, 8.0, 9.0), 1))
)
*/
//计算生成新的聚类中心
val newPoints= pointStats.map {
pair => (pair._1, pair._2._1/ pair._2._2)}.collectAsMap()
//由<ClusterID, (pm, n)>产生(ClusterID, pm/n)。其中,pair._1表示聚类的ClusterID,pair._2._1表示聚类中所有向量之和pm ,pair._2._2表示聚类中所有向量的个数n
/*
Map[Int, Array[Double]] = Map(
(0 -> Array(2.5, 3.5, 4.5)),
(1 -> Array(7.0, 8.0, 9.0))
)
*/
高级编程¶
Spark SQL¶
- 用来操作结构化和半结构化数据
- 可以从各种结构化数据源中(例如JSON、Hive、Parquet等)读取数据;
- 不仅支持在Spark程序内使用SQL语句进行数据查询,也支持从外部工具中通过JDBC/ODBC连接Spark SQL进行查询;
- 支持SQL与常规的Python/Java/Scala代码高度整合,包括连接RDD与SQL表、公开的自定义SQL函数接口等。
-

-
特点
- 数据兼容:兼容Hive,还可以从RDD、Parquet文件、JSON文件中获取数据,可以在Scala代码里访问Hive元数据,执行Hive语句,并且把结果取回作为RDD使用。支持Parquet文件读写。
- 组件扩展:语法解析器、分析器、优化器
- 性能优化:内存列存储、动态字节码生成、内存缓存数据
- 支持多种语言
-
-
SparkContext是 Spark 的早期编程接口,主要用于 RDD 操作。而SparkSession是 Spark 2.0 之后引入的新接口,是 DataFrame 和 DataSet API 的主要入口点。val conf = new SparkConf().setAppName("Spark Pi").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder.appName("Spark").master("local").getOrCreate() -
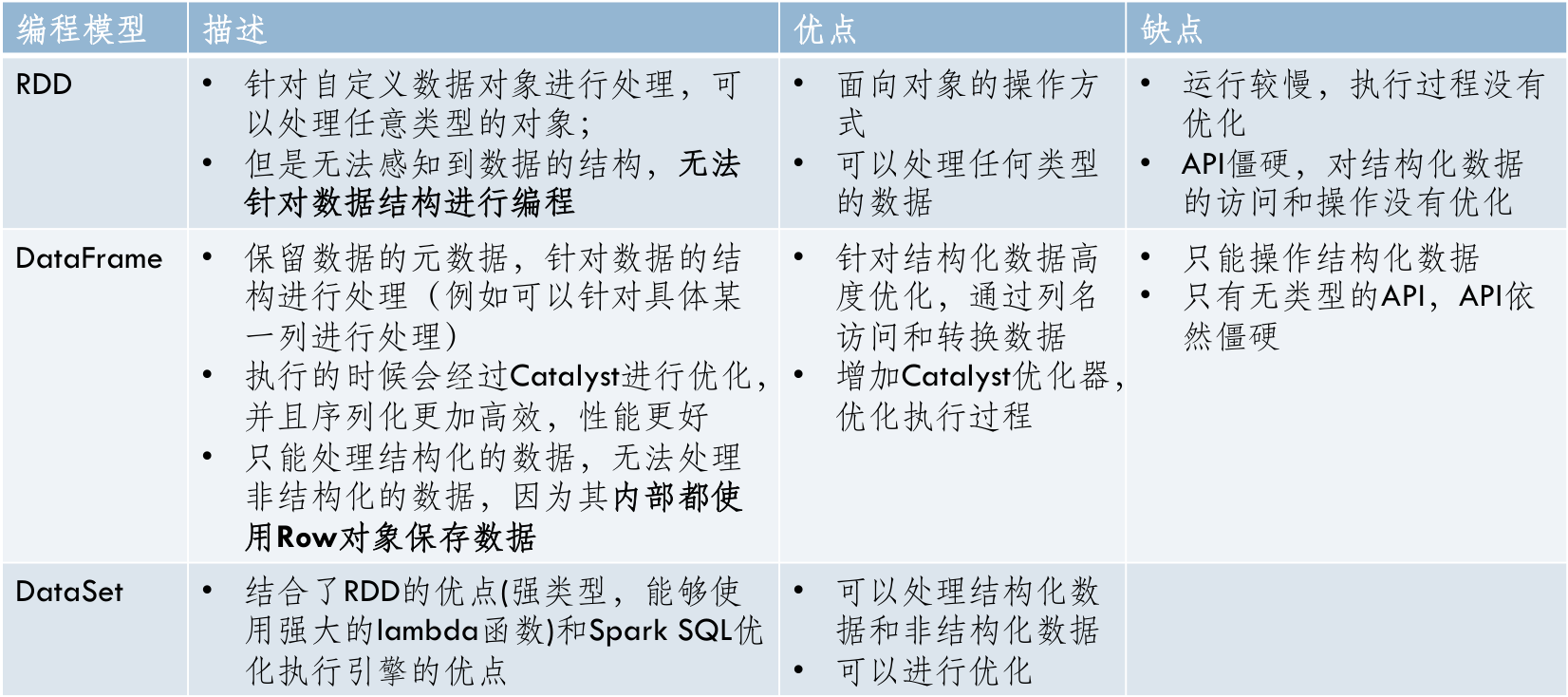
RDD、DataFrame、DataSet的区别
- RDD (Resilient Distributed Dataset):
- RDD 是 Spark 的基本抽象,提供了一个不可变、分布式的数据集合,可以并行操作。
- 特点:
- 支持底层的数据处理抽象。
- 提供了详细的控制,允许用户手动优化。
- 支持各种数据类型。
- RDD 更适合低层次的数据处理和需要精细控制的场景
- DataFrame:
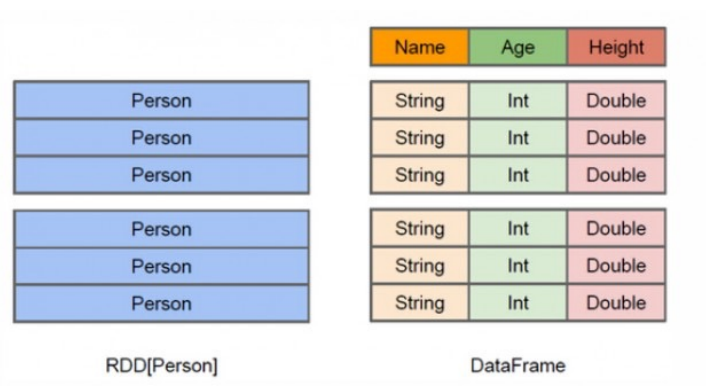
- DataFrame 是一个分布式的数据集合,类似于关系型数据库中的表,具有列和行的概念。
- 特点:
- 高级抽象,构建在RDD之上。
- 提供了针对结构化和半结构化数据的操作接口。
- 支持多种数据源。
- 能够通过提供的 schema 自动推断数据类型。
- DataFrame 提供了一个高效的接口,适用于结构化数据的查询操作
- DataSet:

- DataSet API 是 DataFrame API 的一个扩展,提供了类型安全的对象接口。
- 特点:
- 结合了RDD的类型安全和DataFrame的优化能力。
- 提供了编译时类型检查。
- 支持各种数据类型,包括用户定义的类。
- 通过 Encoder 进行序列化,比RDD更高效。
- DataSet 结合了两者的优点,适用于需要类型安全和高效处理能力的场。
Spark SQL 编程¶
DataFrame¶
DataFrame代表一个表格形式的数据结构,其中包含了行和列。每列有一个名称和类型。-
与 RDD 类似,
DataFrame的操作也是懒执行的。即操作不会立即执行,只有在行动操作(如collect、show)被调用时才会触发真正的计算 -
读取数据创建 DataFrame:
val df = spark.read.json("path/to/jsonfile.json") -
显示 DataFrame: 为了查看 DataFrame 的内容,可以使用
show()方法。df.show() -
打印 Schema: 要查看 DataFrame 的结构(即 Schema),可以使用
printSchema()方法。df.printSchema() -
选择列和过滤行: 使用
select()选择特定的列,使用filter()或where()过滤行。df.filter($"columnName" > value).show() //选择的同时附加对列的操作 df.select(df("name"), df("age") + 1).show() //重命名 df.select(df("name").as("username"), df("age")).show() -
新建列:
withColumnval newDf = df.withColumn("id_times_two", col("id") * 2) -
删除列
dropval dfWithoutColumn = df.drop("column_to_drop") -
聚合操作: 使用诸如
groupBy()和agg()等方法执行聚合操作。df.groupBy("columnName").agg(count("columnName")).show() -
SQL 查询: 注册 DataFrame 为临时视图,然后使用 SQL 语句查询。
codedf.createOrReplaceTempView("tableName") spark.sql("SELECT * FROM tableName WHERE columnName > value").show() -
将数据写入外部存储: 使用
write()方法将 DataFrame 数据写入到外部存储系统,如文件、数据库等。df.write.format("json").save("path/to/output") -
df.groupBy("age").count().show(): 按"age"列的值进行分组,并计算每个年龄组中的记录数(即每个不同年龄值有多少条记录),然后展示结果。 df.sort(df("age").desc, df("name").asc).show(): 按"age"列降序和"name"列升序(多列排序)对 DataFrame 进行排序,并展示结果。
Dataset¶
- 是
DataFrame的一个扩展,DataSet提供了静态类型安全。 - 对每行的数据添加了类型约束,每行数据是一个 Object
- DataSet与DataFrame可以相互住转化, Dataset包含了DataFrame的功能(推荐使用Dataset)
- RDD转换DataFrame后不可逆,但RDD转换Dataset是可逆的
Spark MLBase(机器学习)¶

- MLlib是常用机器学习算法的实现库
- MLI是进行特征抽取和高级ML编程抽象的算法实现的API
- ML Optimizer优化器会选择最合适的,已经实现好了的机器学习算法和相关参数
*MLlib¶
- MLlib:把数据以RDD的形式表示,然后在分布式数据集上调用各种算法。引入一些数据类型(比如点和向量),给出一系列可供调用的函数的集合。

数据类型¶
- 本地向量
- MLlib支持两种类型的本地向量:密集向量和稀疏向量。密集向量的值由Double型的数据表示,而稀疏向量由两个并列的索引和值表示。
//导入MLlib import org.apache.spark.mllib.linalg.{Vector, Vectors} //创建(1.0, 0.0, 3.0)的密集向量 val dv: Vector = Vectors.dense(1.0, 0.0, 3.0) //通过指定非零向量的索引和值,创建(1.0, 0.0, 3.0)的数组类型的稀疏向量 val sv1: Vector = Vectors.sparse(3, Array(0,2), Array(1.0, 3.0)) //通过指定非零向量的索引和值,创建(1.0, 0.0, 3.0)的序列化的稀疏向量 val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0))) -
读取并创建稀疏向量
val examples: RDD[LabeledPoint] = MLUtils.loadLibSVMFile(sc, “data/MLlib/sample_libsvm_data.txt”) -
标记点
- 标记点是由一个本地向量(密集或稀疏)和一个标签(Int型或Double型)组成。在MLlib中,标记点主要被应用于回归和分类这样的监督学习算法中。标签通常采用Int型或Double型的数据存储格式
-
算法可以学习特征和标签之间的关系,并用于预测新样本的标签。
import org.apache.spark.mllib.linalg.Vectors import org.apache.spark.mllib.regression.LabeledPoint //通过一个正相关的标签和一个密集的特征向量创建一个标记点 val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0)) //通过一个负向标签和一个稀疏特征向量创建一个标记点 val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0,2), Array(1.0, 3.0))) -
本地矩阵
- Mllib支持密集矩阵,密集矩阵的值以列优先方式存储在一个Double类型的数组中
-

val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0)) //稀疏矩阵 val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8)) -
分布式矩阵
- 分布式矩阵由(Long类型行索引,Long类型列索引,Double类型值)组成,分布存储在一个或多个RDD中。
- 行矩阵 RowMatrix
- 行索引矩阵 IndexedRowMatrix
- 三元组矩阵 CoordinateMatrix
- 块矩阵 BlockMatrix
工作流程¶
- 如果要用MLlib来完成文本分类的任务,只需如下操作:
- 首先用字符串RDD来表示你的消息
- 运行 MLlib 的一个特征提取算法来把文本数据转换为数值特征(向量),该操作会返回一个向量 RDD
- 对向量RDD调用分类算法(比如逻辑回归),这步会返回一个模型对象,可以使用该对象对新的数据点进行分
-
使用MLlib的评估函数在测试数据集上评估模型
-
Iris数据集(花的三个属性,实现分类)为例
- 首先需要将Iris-setosa,Iris-versicolour,Iris-virginica转化成0,1,2来表示。生成LabeledPoint类型RDD
-
先用textFile 读取数据,然后对string类型的RDD调用map操作,转换成LabeledPoint类型的RDD。
val rdd: RDD[String] = sc.textFile(path) var rddLp: RDD[LabeledPoint] = rdd.map(x => { val strings: Array[String] = x.split(",") regression.LabeledPoint( strings(4) match { case "Iris-setosa" => 0.0 case "Iris-versicolor" => 1.0 case "Iris-virginica" => 2.0 }, Vectors.dense(strings(0).toDouble, strings(1).toDouble, strings(2).toDouble, strings(3).toDouble) ) }) //数据集划分 val Array(trainData,testData): Array[RDD[LabeledPoint]] = rddLp.randomSplit(Array(0.8,0.2))//4:1划分数据集 -
训练模型及模型评估
- 对于分类问题可以使用:朴素贝叶斯,决策树,随机森林,支持向量机,logistics 回归等算法
- 决策树
//训练决策树模型 val decisonModel: DecisionTreeModel = DecisionTree.trainClassifier(trainData,3, Map[Int, Int](),"gini",8,16) //评估模型(进行预测) val result: RDD[(Double, Double)] = testData.map(x => { val pre: Double = decisonModel.predict(x.features) (x.label, pre) }) //计算准确率 val acc: Double = result.filter(x=>x._1==x._2).count().toDouble /result.count()
ML¶
- Spark 的 ML 库基于DataFrame提供高性能的 API,帮助用户创建和优化实用的机器学习流水线,包括特征转换独有的 Pipelines API,ML 把整个机器学习的过程抽象成 Pipeline,一个 Pipeline 由多个 Stage 组成,每个 Stage 由 Transformer 或者 Estimator 组成。
重点¶
- Spark ML的流水线含义
- Spark ML 库中的流水线是一个由多个阶段组成的工作流程,用于构建和调优机器学习模型。在 Spark ML 中,一个流水线代表了一个完整的数据处理和学习过程,它将数据转换、特征提取、模型训练等步骤串联起来,形成一个可以顺序执行的工作流,主要由 Transformer 和 Estimator 两种算法组成。
- Transformer:可以将一个 DataFrame 转换为另一个 DataFrame。实现 transform ()方法。
- Estimator:可以拟合(训练)数据并产生一个 Transformer 的算法,用于构建训练模型。一个机器学习算法(如逻辑回归)被实现为一个
Estimator。fit方法是Estimator的核心。当调用一个Estimator的fit方法时,它会尝试从提供的数据中“学习”或“训练”。学习的结果是一个Transformer,**它封装了从数据中学到的模型。
- Pipeline:指定连接多个 Transformers 和 Estimators 的 ML 工作流。
- Parameter:全部的 Transformers 和 Estimators 共享一个指定 Parameter 的通用 API。
- 工作流程:首先使用几个
Transformer对原始数据进行预处理,然后使用一个Estimator来拟合一个模型,最后使用该模型(作为一个Transformer)对新数据进行预测。 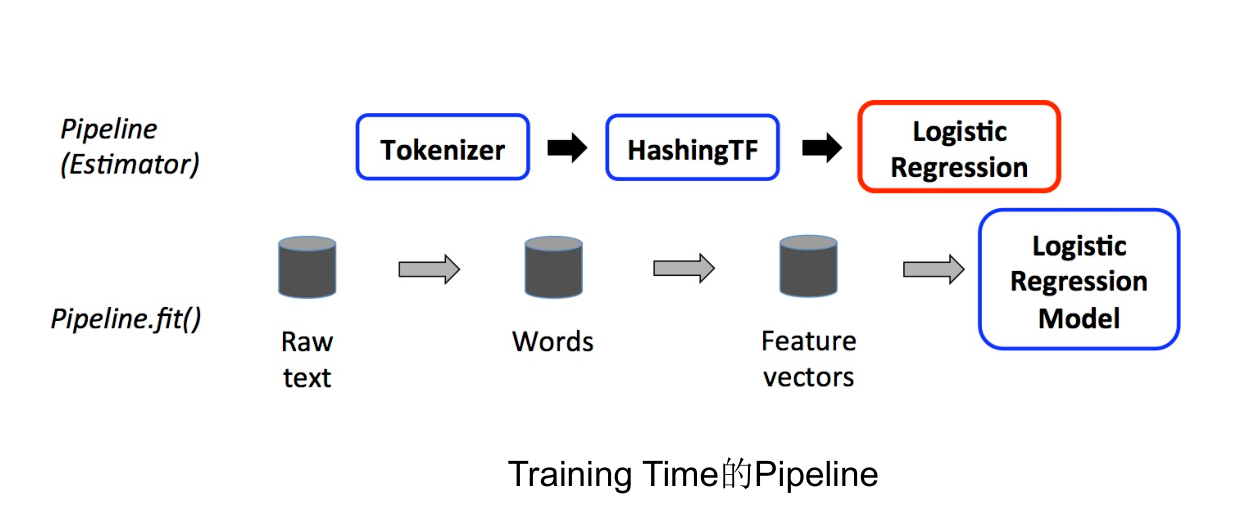
-
一个流水线被指定为一系列由 Transformer 或 Estimator 组成的阶段(Stage)。这些阶段按照顺序运行,输入的 DataFrame 在运行的每个阶段进行转换
-
对比
-

-
KMeans示例
import org.apache.spark.ml.clustering.Kmeans val spark = SparkSession.builder.appName("CSV to DataFrame").getOrCreate() val dataset = spark.read.format("libsvm").load("data/mllib/sample_kmeans_data.txt") // Estimator val kmeans = new KMeans().setK(2).setSeed(1L) val model = kmeans.fit(dataset) // Transformer得到结果 val predictions = model.transform(dataset) // 评估 val evaluator = new ClusteringEvaluator() val silhouette = evaluator.evaluate(predictions) // 打印出聚类模型的簇中心 println("Cluster Centers: ") model.clusterCenters.foreach(println) -
Iris鸢尾花示例
val df: DataFrame = sparkSession.read.format("csv") .option("inferSchema", "true")//自动推断字段类型 .option("header", "true")//使用文件的第一行作为列名 .option("sep", ",")//分隔符 .load(path) //将4个特征整合为一个特征向量 val assembler: VectorAssembler = new VectorAssembler() .setInputCols(Array("sepal_length", "sepal_width", "petal_length", "petal_width")) .setOutputCol("features") //将特征向量附加到新的features列 val assemblerDf: DataFrame = assembler.transform(df) //将类别型class转变为数值型 val stringIndex: StringIndexer = new StringIndexer() .setInputCol("class") .setOutputCol("label") val stringIndexModel: StringIndexerModel = stringIndex.fit(assemblerDf) val indexDf: DataFrame = stringIndexModel.transform(assemblerDf) //将数据切分成两部分,分别为训练数据集和测试数据集 val Array(trainData,testData): Array[Dataset[Row]] = indexDf.randomSplit (Array(0.8,0.2)) // 准备计算,设置特征列和标签列 val classifier: DecisionTreeClassifier = new DecisionTreeClassifier() .setFeaturesCol("features") .setMaxBins(16) .setImpurity("gini") .setSeed(10) val dtcModel: DecisionTreeClassificationModel = classifier.fit(trainData) // 完成建模分析 val trainPre: DataFrame = dtcModel.transform(trainData) // 预测分析 val testPre: DataFrame = dtcModel.transform(testData) // 评估 val acc: Double = new MulticlassClassificationEvaluator() .setMetricName("accuracy") .evaluate(testPre)
Spark Streaming¶
- Spark Streaming 将流式计算分解成一系列短小的批处理作业
- 能线性扩展至超过数百个节点;
- 实现亚秒级延迟处理;
- 可与 Spark 批处理和交互式处理无缝集成;
- 提供了一个简单的 API 实现复杂的算法;
- 更多的网络流方式支持,包括 Kafka、Flume、Kinesis、Twitter、ZeroMQ
DStream¶
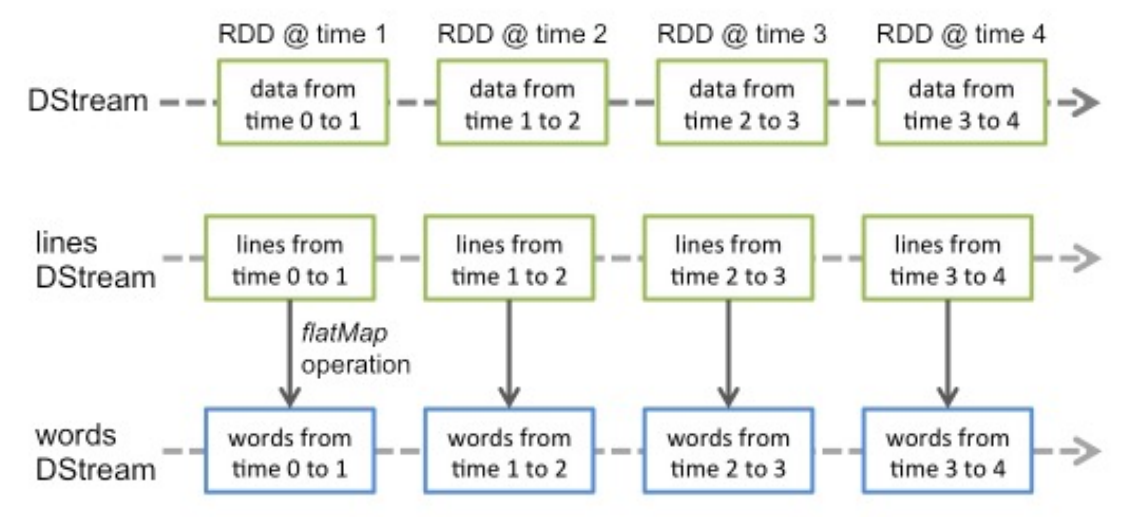
- 在许多实时计算或流处理场景中,数据是通过网络连续、实时地传输的。使用 DStream,我们可以在全部数据到达之前开始进行计算,实现所谓的 "在线算法" 或 "流式处理"。
- DStream 的核心思想是将实时计算分解为一系列小的、时间间隔内的批处理任务。这些任务独立而确定,易于管理和调度。
- 在每个时间间隔内,系统会接收输入数据并将其可靠地存储在集群中,形成一个输入数据集。这些输入数据集按时间间隔组织,允许系统处理流数据,就像在批处理模式下处理静态数据一样。
- 当一个时间间隔结束时,Spark 对应的数据集会并行地进行 Map、Reduce、groupBy 等操作,产生中间数据或新的输出数据集,这些数据被存储在 RDD 中。这种方式确保了数据处理的可扩展性和容错性。
-
任务间的状态可以通过重新计算 RDD 来维持。如果某个 RDD 在计算过程中丢失,它可以通过其父 RDD 重新计算得到。这种设计使得 Spark Streaming 在处理流数据时既具有高效性也具有容错性。
-
操作:生成一个新的DStream;把数据写入外部系统中
- 输入源:
- 每一个输入流DStream和一个Receiver对象关联,这个Receiver从源中获取数据,并将数据存入内存中进行处理。
-

-
基本流程
- 首先创建StreamingContext
- 通过创建输入DStream来创建输入数据源。
- 一个SparkContext可以创建多个StreamingContext,只要上一个先用stop(false)停止,再创建下一个即可。(一个JVM同时只能有一个StreamingContext启动)
- 通过对DStream定义transformation和output算子操作,来定义实时计算逻辑。
- 调用StreamingContext的start()方法,来开始实时处理数据。
- 调用StreamingContext的awaitTermination()方法,来等待应用程序的终止。可以使用CTRL+C手动停止,或者就是让它持续不断的运行进行计算。
-
也可以通过调用StreamingContext的stop()方法,来停止应用程序。
- stop之后不能再start
- 调用stop()方法时,会同时停止内部的SparkContext,如果不希望如此,还希望后面继续使用SparkContext创建其他类型的Context,比如SQLContext,那么就用stop(false)。
-
从监听TCP套接字的数据服务器获取文本数据,然后计算文本中包含的单词数。
import org.apache.spark._ import org.apache.spark.streaming._ import org.apache.spark.streaming.StreamingContext._ object WordCount { def main(args: Array[String]) { // 创建一个本地的 StreamingContext,使用两个工作线程,批处理间隔设置为1秒 val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount") val ssc = new StreamingContext(conf, Seconds(1)) // 定义监听的 TCP 源:服务器 IP 和端口 val lines = ssc.socketTextStream("localhost", 9999) // 将每行文本拆分为单词 val words = lines.flatMap(_.split(" ")) // 为每个单词计数并打印结果 val wordCounts = words.map(word => (word, 1)).reduceByKey(_ + _) wordCounts.print() // 开始接收数据并处理 ssc.start() // 等待处理停止(不是必须的,但如果要手动停止处理则需要) ssc.awaitTermination() } } -
DStream操作¶
-
转换操作:允许在DStream运行任何RDD-to-RDD函数,比如map,flatMap, filter, reduce, join等
-
状态操作:
updateStateByKey:允许对 DStream 中的数据保持跨批次的状态。这种方法可以让你追踪例如每个键的运行计数或其他状态。- 该操作会为每个键维护一个状态,并不断用新的数据来更新这个状态。这是通过提供一个函数实现的,该函数会接收两个参数:一个是当前批次该键的新值,另一个是该键的旧状态(如果存在的话)。
- 这个函数的输出是键的新状态,会被 Spark Streaming 保存下来,以便在下一个批次中使用。
- 这允许开发者在整个数据流的生命周期内维护和更新状态信息,如总计数器或者窗口内的平均值。
window:允许对指定时间范围内的数据进行转换处理,而不是仅仅对单个批次的数据进行操作。- 窗口长度:这是窗口的持续时间,意味着在这个时间范围内的数据会被包含在内进行处理。
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
// 使用updateStateByKey来更新状态
val stateDstream = wordDstream.updateStateByKey[Int](updateFunc)
- 滑动间隔:这是窗口操作执行的时间间隔,意味着每隔多长时间窗口会向前滑动并进行一次计算。
- 输出操作
- 缓存及持久化:
-

-
检查点:
- Metadata checkpointing:保存流计算的定义信息到容错存储系统如HDFS中。这用来恢复应用程序中运行worker的节点的故障。
- Configuration
- DStream operations
- Incomplete batches
- Data checkpointing:保存生成的RDD到可靠的存储系统中,这在有状态transformation(如结合跨多个批次的数据)中是必须的。有状态的transformation的中间RDD会定时存储到可靠存储系统中。
Apache Kafka¶
- 一个分布式流处理平台。用于构建实时的数据管道和流式的app。
- 流处理平台的三种特性
- 可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。
- 可以储存流式的记录,并且有较好的容错性。
-
可以在流式记录产生时就进行处理。
-
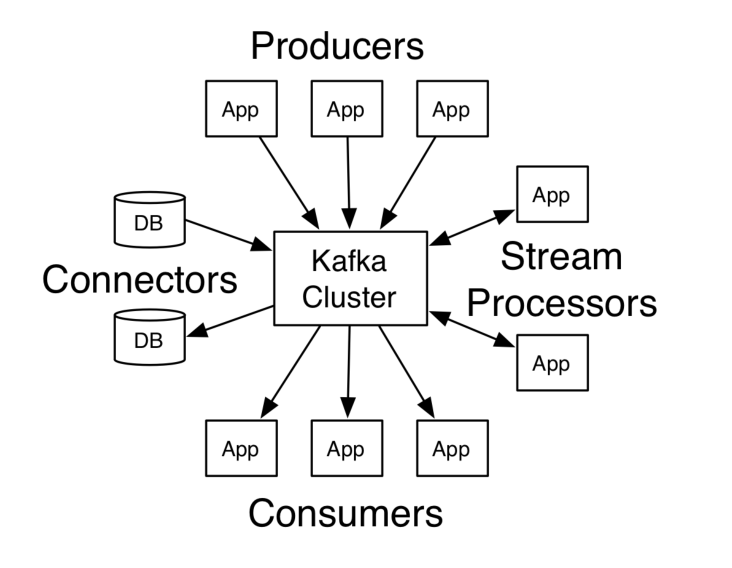
- Kafka维护按类区分的消息,称为主题(topic)
- 生产者(producer)向Kafka的主题发布消息
- 消费者(consumer)向主题注册,并且接收发布到这些主题的消息
- Kafka以一个拥有一台或多台服务器的集群运行着,每一台服务器称为broker
流式计算¶
- 批量计算和流式计算的区别
- 处理数据粒度:批量和流式处理数据粒度不一样,批量每次处理一定大小的数据块(输入一般采用文件系统),一个task处理完一个数据块之后,才将处理好的中间数据发送给下游。流式计算则是以record为单位,task在处理完一条记录之后,立马发送给下游。
- 数据处理单位:
- 批量计算:以数据块为单位进行处理。在批量计算中,每个任务(或作业)接收一定大小的数据块进行处理。这意味着系统会等待直到收集到足够的数据后才开始处理。
- 流式计算:以单条数据记录为单位进行处理。流式计算的算子处理完一条数据后会立即将其发送给下游算子,因此数据的处理延迟通常很短,适合需要低延迟处理的场景。
- 数据源:
- 批量计算:通常处理静态的、有限的数据集,这些数据集被存储在文件系统如 HDFS 或数据库中。数据处理开始时已经存在,大小是已知的。
- 流式计算:用于处理连续生成的、潜在无限的数据流。数据源通常是实时的消息队列系统,这些系统不断地推送数据到流计算系统中。
-
任务类型:
- 批量计算:任务通常是一次性的,也就是说,每个任务在处理完分配给它的数据块后就会结束。批量作业通常有明确的开始和结束。
- 流式计算:任务通常是持久运行的,也称为长任务。这些任务不停地从数据源接收数据,处理后即时产出结果。流式计算的任务可能永远不会结束,除非显式停止。
-
离线=批量?实时=流式?
-
离线和实时应该指的是:数据处理的延迟;批量和流式指的是:数据处理的方式。两者并没有必然的关系。事实上 Spark streaming 就是采用小批量(batch)的方式来实现实时计算。
-
流式计算框架
- Apache Storm
- Apache Spark Streaming
- Apache Flink
Spark Structured Streaming(vs Spark Streaming)¶
- 流模型:
- Spark Streaming 是Spark最初的流处理框架,使用微批处理的方法。提供了基于RDDs的Dstream API,每个时间间隔内的数据为一个RDD,源源不断对RDD进行处理来实现流计算.
- Structured Streaming 把实时数据流看作是一个无界表,每个数据项的到来就像是向表中追加新行。它构建在 Spark SQL 引擎之上,提供了使用 DataFrame 和 DataSet API 处理数据流的能力。
-
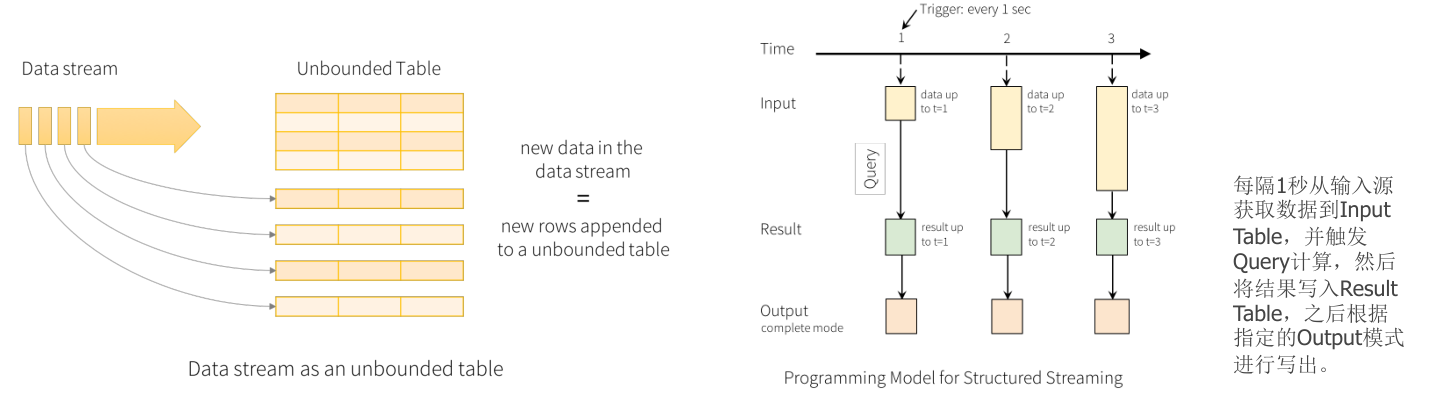
-
编程接口:
- Spark Streaming 提供的是基于 RDD 的 DStream API。
- Structured Streaming 使用 DataFrame 和 DataSet API,允许使用 Spark SQL 的功能来处理数据,使得转换和输出变得更简单。
- 处理时间和事件时间:
- 处理时间:流处理引擎接收到数据的时间
- 事件时间:事件真正发生的时间
- Spark Streaming 主要基于处理时间,即数据到达处理引擎的时间。它没有直接支持事件时间的处理,也就是数据实际发生的时间。
- Structured Streaming 支持基于事件时间的数据处理,允许开发者根据数据中包含的时间戳字段来处理数据,这对于处理乱序数据或实现窗口计算非常重要。
-
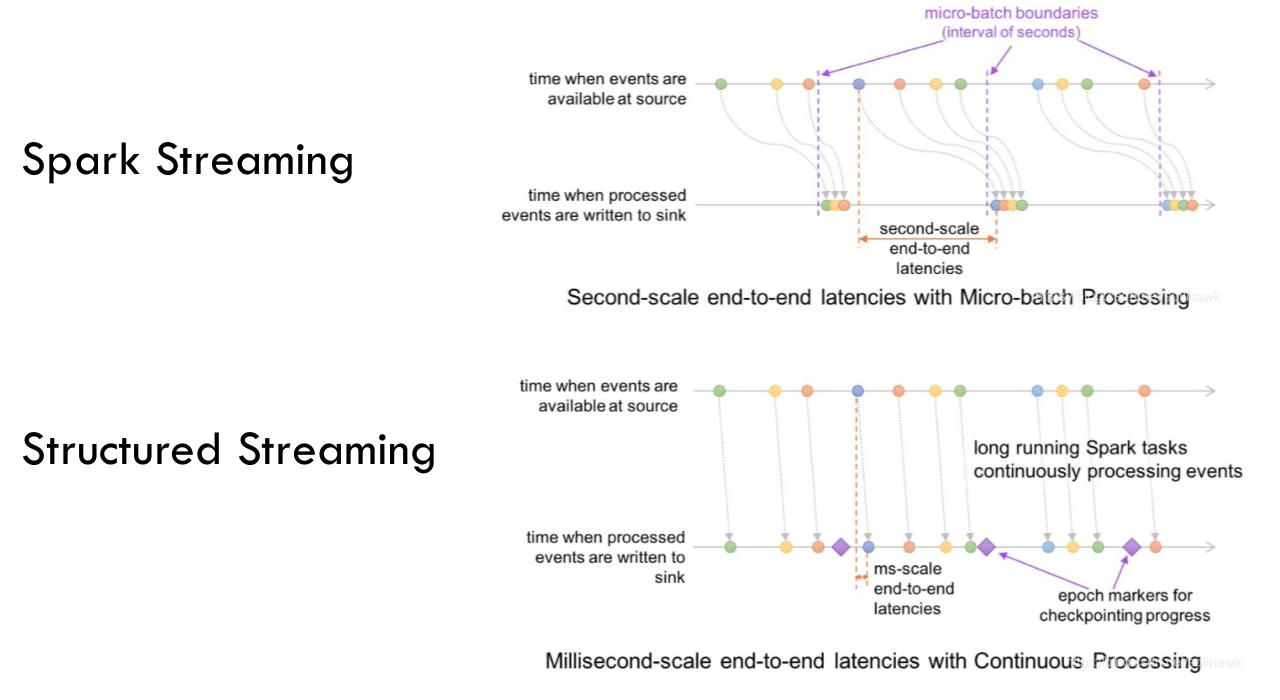
-
可靠性保障:
- Spark Streaming 和 Structured Streaming 都使用了 checkpoint 机制来提供可靠性保证,通过设置检查点将数据保存到文件系统,并在出现故障时恢复数据。
- 在 Spark Streaming 中,如果修改了流程序的代码,从 checkpoint 恢复时可能会出现兼容性问题,因为 Spark 可能无法识别修改后的程序。
-
在 Structured Streaming 中,对于指定的代码更改,通常可以从 checkpoint 中恢复数据而不受影响。
-
输出 Sink:
- Spark Streaming 提供了
foreachRDD方法,允许开发者自行编程来将每个批次的数据写出。 -
Structured Streaming 提供了内置的 sink(如 Console Sink、File Sink、Kafka Sink 等),并通过
DataStreamWriter提供了一个简单的配置接口。对于自定义 sink,它提供了ForeachWriter接口。 -
总结:
- Structured Streaming 提供了更简洁的 API、更完善的流功能,并且更适合于流处理的场景。
- Spark Streaming 可能更适合于处理时间不是非常敏感的场景,它已经成为了一个遗留项目,不再更新,Apache Spark 社区推荐使用 Structured Streaming。
GraphX¶
- GraphX是Spark中用于图和图并行计算的组件。
- GraphX通过扩展Spark RDD引入一个新的图抽象,一个将有效信息放在顶点和边的有向多重图。
- GraphX公开了一系列基本运算,以及一个优化后的Pregel API的变形。包括越来越多的图形计算和builder构造器,以简化图形分析任务。
- 在Spark之上提供了一站式解决方案,可以方便且高效地完成图计算的一整套流水作业。
-
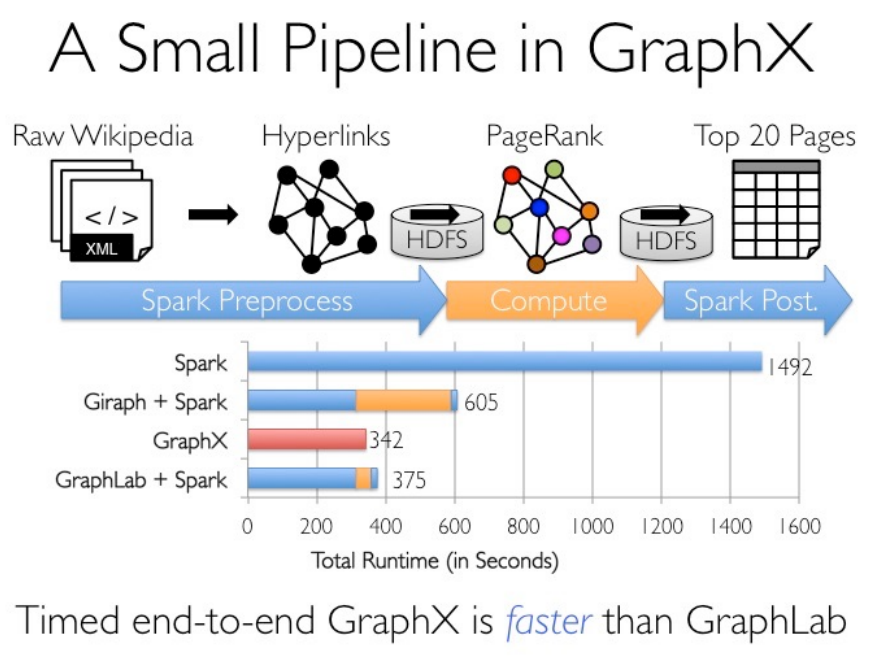
-
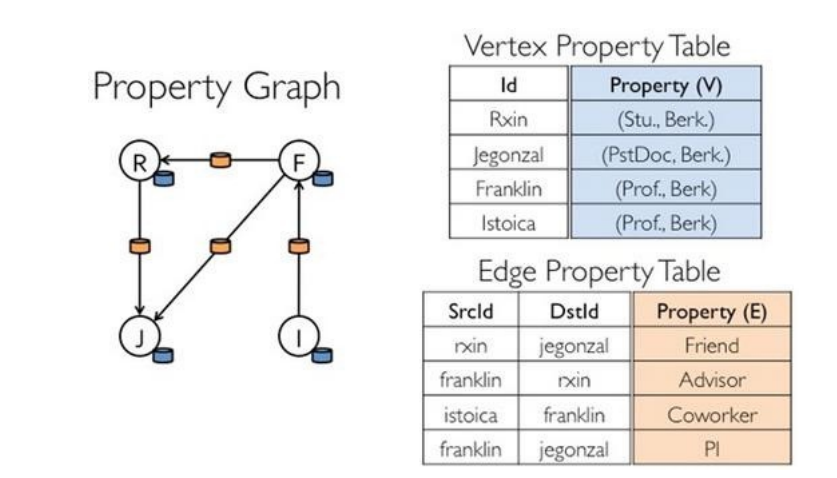
弹性分布式属性图
- 弹性分布式属性图,一种点和边都带属性的有向多重图。它扩展了Spark RDD的抽象,有Table和Graph两种视图,而只需要一份物理存储。两种视图都有自己独有的操作符(适应不同的操作),从而获得了灵活操作和执行效率。
- 对Graph视图的所有操作,最终都会转换成其关联的Table视图的RDD操作来完成。这样对一个图的计算,最终在逻辑上,等价于一系列RDD的转换过程。因此,Graph最终具备了RDD的3个关键特性:Immutable、Distributed和Fault-Tolerant,其中最关键的是Immutable(不变性)。逻辑上,所有图的转换和操作都产生了一个新图;物理上,GraphX会有一定程度的不变顶点和边的复用优化,对用户透明。
- 两种视图底层共用的物理数据,由 RDD[VertexPartition]和 RDD[EdgePartition]这两个 RDD 组成。点和边实际都不是以表 Collection[tuple]的形式存储的,而 VertexPartition/EdgePartition 在内部存储一个带索引结构的分片数据块,以加速不同视图下的遍历速度。不变的索引结构在 RDD 转换过程中是共用的,降低了计算和存储开销。
- 是一种有向多重图,它可能有多个平行边共享相同的源顶点和目标顶点。(可以有属性不同的重边)

GraphX编程与图操作¶
- 构造图
-
通过Graph对象构造图
- 创建两个RDD:一个用于顶点(Vertex RDD),另一个用于边(Edge RDD)。然后,将这两个RDD传递给
Graph类的构造函数。val conf = new SparkConf().setAppName("GraphXExample") val sc = new SparkContext(conf) // 创建顶点RDD val vertices: RDD[(VertexId, (String, Int))] = sc.parallelize(Array( (1L, ("Alice", 28)), (2L, ("Bob", 27)), (3L, ("Charlie", 65)), (4L, ("David", 42)), (5L, ("Ed", 55)) )) // 创建边RDD val relationships: RDD[Edge[String]] = sc.parallelize(Array( Edge(1L, 2L, "friend"), Edge(2L, 3L, "follower"), Edge(3L, 4L, "friend"), Edge(4L, 5L, "colleague"), Edge(5L, 1L, "friend") )) // 定义默认用户,以防有些关系没有对应的用户 val defaultUser = ("John Doe", 0) // 构建图 val graph = Graph(vertices, relationships, defaultUser)
- 创建两个RDD:一个用于顶点(Vertex RDD),另一个用于边(Edge RDD)。然后,将这两个RDD传递给
-
通过Graph Builder构造图
val graph = GraphBuilder .withEdges(relationships) .withVertices(vertices) .withDefaultVertexAttr(defaultUser) .build() -
载入图
-
GraphLoader.edgeListFile提供了一种从磁盘上边的列表载入图的方式。
val conf = new SparkConf().setAppName("GraphXExample") val sc = new SparkContext(conf) // 从文件中加载图(两个Int分别表示顶点和边参数的数据类型) val graph: Graph[Int, Int] = GraphLoader.edgeListFile(sc, "hdfs:/path/to/edge-list-file.txt") -
图操作
-
转换操作
- 转换操作用于改变图中的顶点或边的属性而不改变图的结构。
val newGraph = graph.mapVertices((id, attr) => attr * 2)
- 转换操作用于改变图中的顶点或边的属性而不改变图的结构。
-
结构操作
-
结构操作用于改变图的结构,例如反转边、子图的生成等。
val reversedGraph = graph.reverse -
关联操作
-
关联操作用于将外部RDD数据与图的顶点或边关联起来。
val updatedGraph = graph.joinVertices(externalVertexData) { (id, oldAttr, newAttr) => newAttr } -
聚合操作
-
聚合操作用于聚合图中的信息,例如计算顶点的邻居的属性的总和。
val vertexOutDegrees = graph.outDegrees //计算每个顶点的出度 -
缓存操作
-
缓存操作用于优化图的多次遍历。GraphX中的图操作是惰性的,所以在多次操作同一个图时使用缓存是个好主意。
graph.cache() -
triplets操作:同时访问图中的边和与这些边相连的顶点的属性。 -
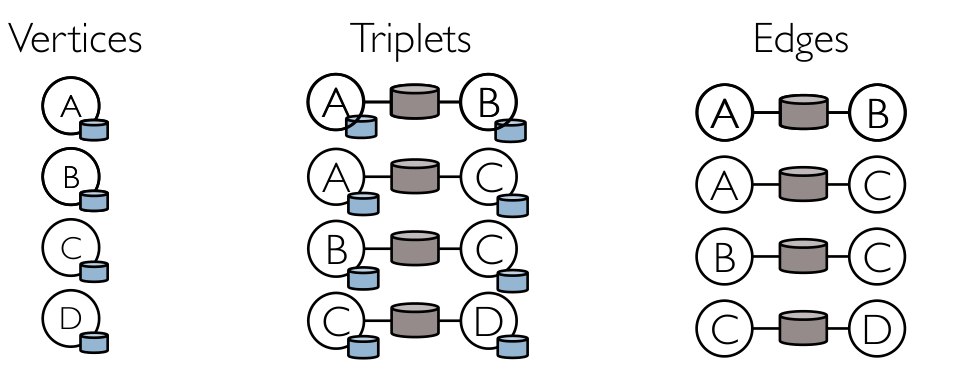
al result = graph.triplets.filter { triplet => (triplet.srcAttr - triplet.dstAttr).abs > 10 } ``` #### 常用图算法 - PageRank算法 - GraphX自带PageRank的静态和动态实现,放在PageRank对象中。静态的PageRank运行固定数量的迭代,而动态的PageRank运行直到排名收敛。(搜索引擎网站排名) ```scala val ranks = graph.pageRank(0.0001).vertices -
三角形计数算法
-
计算通过各顶点的三角形数目,从而提供集群的度。三角形的数量可以用来衡量网络的紧密程度。
val triCounts = graph.triangleCount().vertices -
连接分量算法
- 连接分量算法标出了图中编号最低的顶点所连接的子集。
val cc = graph.connectedComponents().vertices