ExtraSS A Framework for Joint Spatial Super Sampling and Frame Extrapolation
用一个来同过程时进行超分插帧工作,减少分 pass 的重复计算,来提升性能表现
核心思路¶
- 运动向量和 G-buffer 引导的初始化:用运动向量把前后帧的信息重投影到当前帧,实现时空信息的重用,G-buffer 负责引导匹配,避免把错误的像素带过来。当物体从遮挡中显露出来,没有历史像素可用时,通过G-buffer和时空邻域的引导,更好地补齐空洞或不一致区域。
- 轻量级流模型修复: 即使几何位置对齐了,阴影、高光、反射等随时间也会变化,仅靠几何对齐会导致“几何动了但光照没跟上”的不一致。这步的主要目的就是让阴影、反射、高光在运动时与几何同步、连续且自然。
- Extrass 网络生成高分辨率图像: 统一处理以下两种情况:有低分辨率渲染帧作为输入(仅超分);没有低分辨率渲染帧,只有前后时空信息(超分+插帧)。
基本目标:根据输入的当前帧低分辨率图像 \(i_{t}\) 、当前帧以及下一帧的 G-buffer \(g_{t},g_{t+1}\) 来生成单签真和下一针的高清图像 \(I_{t},I_{t+1}\)
相关技术¶
- 运动向量与重投影:利用引擎提供的运动向量可以实现较为准确的重投影来复用历史信息,但是依然会在一些部位出现错误导致重影拖影(显露区、遮挡问题、阴影光照反射等),因此需要用当前帧作为额外信息来矫正
- 空间超采样:
- 经验/启发式融合:TAAU、FSR 用手工权重融合抖动的低分图与历史高分输出的重投影图。
- 学习式融合:训练网络做更聪明的时空融合以提升稳定性;也有直接用多帧低分预测当前高分的做法,但容易闪烁。
- 抗锯齿(AA):可用多重采样(SSAA/MSAA)、纯空间滤波(FXAA/SMAA)、或时间抗锯齿(TAA)
设计原理¶
总体设计¶
算法大致可以拆分为一下几个步骤 - G-buffer 指导的重投影 - 着色细化:主要针对不随集合刚体移动的着色分量进行修复,如高光反射、阴影等等 - 超分插帧融合网络 Extrass
G-buffer 引导的重投影¶
使用一种 G-buffer 指导的重投影,可以高效进行重投影的同时减少鬼影并保持锐度:
- 解调与调制:对图像做如下拆解 最终图像=基础颜色*光照
- 首先解调得到纯粹的光照和阴影信息(除去了纹理本身的颜色)
- 之后只对得到的平滑的光照信息进行重投影(这就避免了高频信息造成的影响,有助于保持纹理细节的清晰锐利)
- 最终完成重投影后将纹理细节重新应该用到图像上
- 联合双边滤波:用于对解调得到的光照域进行滤波
- 用 Gbuffer 进行引导(来计算相似性进而得到权重。如距离越远权重越小、深度法线等特征越接近权重越大)
- 对每个像素 p,在一个邻域内收集邻居像素 q 的值 I(q),然后根据计算得到的权值对光照图做滤波得到更加平滑的光照图
- (其实就是一种更复杂的膨胀,用于给却历史、错历史的区域提供更好的估计,来减少重投影后出现的破碎、闪烁、早点等问题)
- A-trous 层级结构:与联合双边滤波组成多层联合双边滤波,用于在固定小核的前提下逐层扩大采样间距,覆盖更大的范围,以填充新暴露区域,并保边(锐利)
- 基本方法:在不增大卷积核尺寸的前提下,通过在采样点之间插“空格”来扩大感受野的卷积/滤波方式。层 l 的采样偏移为基核偏移乘以 stride s_l(如 1, 2, 4, 8)。
- 用很少的采样点实现很大的覆盖范围,使滤波能跨越较大尺度的空洞或噪声区域,同时计算量可控。
过程梳理:
- 解调——多层 A-trous 联合双边滤波——重调
- \(N(\bar{x})=\{\bar{x}+(k*s,l*s)\mid k\in\{-r,\cdots,r\},l\in\{-r,\cdots,r\},\\r=1,s\in\{1,3,5,9\}\}\) 这里得到的 \(N(\overline x)\) 就是围绕 \(\overline x\) (当前要计算的坐标在上一帧的位置)的候选像素集(用于收集信息进行滤波),其中 \(r\) 表示了采样和的大小 \(3*3\) \(5*5\) 等,\(s\) 表示的则是采样点之间的空格
- 混合权重的计算 \(w_x(y)=G(g_t(x)-g_{t-1}(y)\mid\mu_0,\sigma_0)\times G(\bar{x}-y\mid\mu_1,\sigma_1)\) 由两个高斯项相乘得到:第一项表示两个像素的引导特征的差(G-buffer 信息如 base-color、normal得到的相似度);第二项表示两个像素之间的空间距离
- \(f_g^t(i_{t-1})[x]=\sum_{y\in N^*(\bar{x})}\bar{w}_x(y)*i_{t-1}[y]\) 首先根据上式计算 \(N(\overline x)\) 中每一个点的权重 \(w_{x}(y)\) 选出其中最大的四个构成子集 \(N^*(\overline x)\),并对其权重进行归一化得到 \(\overline w_{x}(y)\), 最终得到滤波结果(实际上就是 wrap 的结果,因为 \(\overline x\) 是上一帧的坐标)
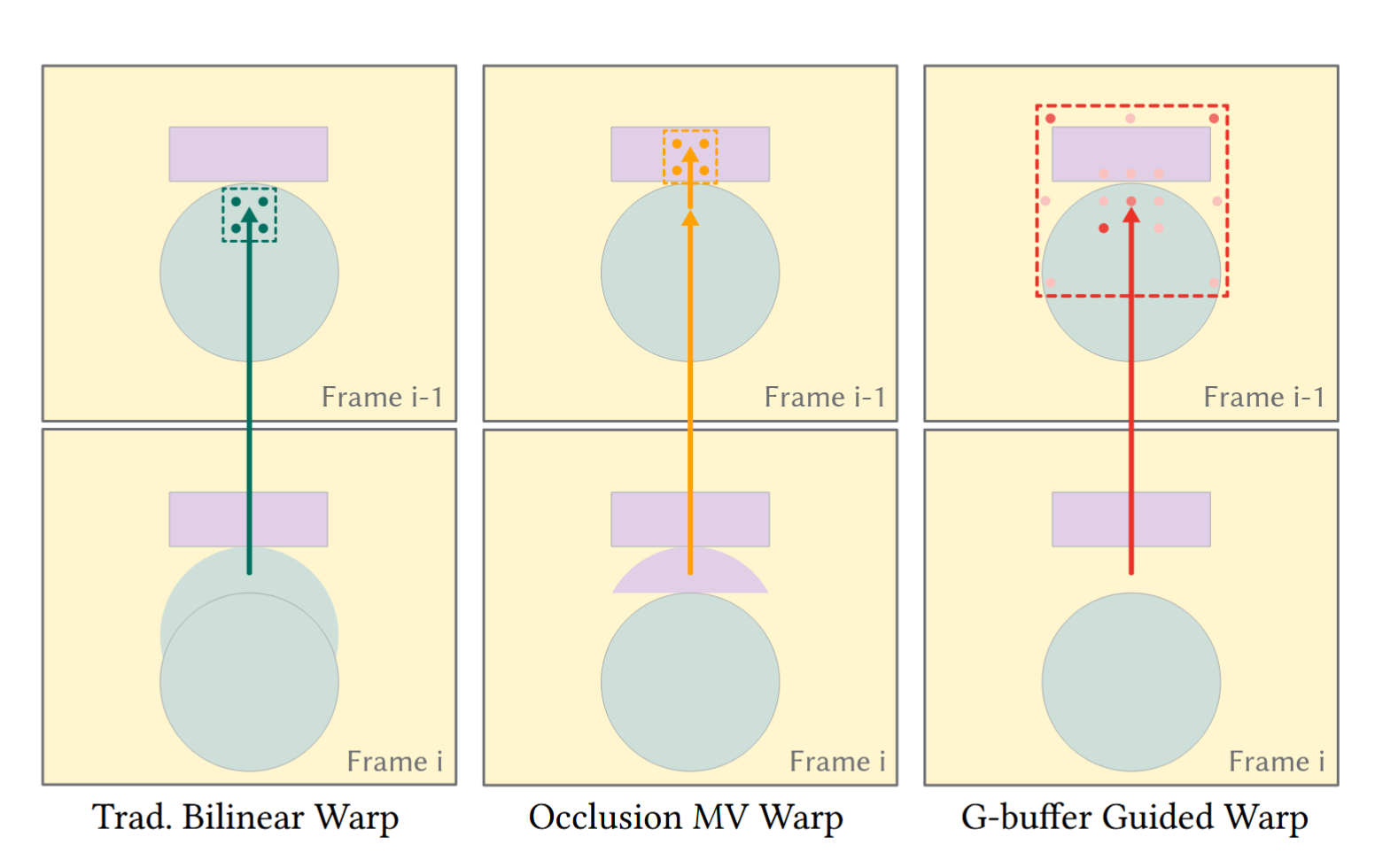
与传统重投影针对遮挡物体的效果对比
FRNet着色细化¶
- 经过上面的重投影,大部分的内容已经被正常重投影,但部分不跟随集合刚性移动的着色成分(如阴影、镜面反射高光、反射纹理等)还不能被正确的对齐
- 因此继续使用一个模块 FRNet(轻量基于流的神经网络) 来对剩余的不正确着色进行校正。它学习/预测必要的细微流动或残差,以修正阴影、镜面反射等“非刚性着色运动”。
- \(\bar{i}_t^-=\text{FRNet}(f_g^t(i_{t-1}^-),f_g^t(i_{t-3}^-),r_t^-)\)
- \(i_{t-1}^-\) \(i_{t-3}^-\) 为输入的两个历史帧的下采样(已经进行了重投影,对齐到当前帧)
- 下采样粗糙度 \(r_{t}^-\) 作为网络的输入提示(这是由材质决定,可以由 G-buffer 来获取)
- 使用下采样并在低分辨率上工作是为了加快速度
- \(\bar{i}_t=U(\bar{i}_t^-)\cdot\hat{m}(U(\bar{i}_t^-),\hat{i}_t)+\hat{i}_t\cdot(1-\hat{m}(U(\bar{i}_t^-),\hat{i}_t))\)
- 由于使用的是下采样的低分辨率输入,为了输出全分辨率的结果,需要把上采样后的 FRNet 结果和高分辨率的 G-buffer 引导重投影按一个权重图进行融合
- \(U()\) 为简单的使用最近邻算法的额上采样算子
- \(\overline i_{\overline t}\) 为前面输出的低分辨率结果(FRNet 的输出结果)
- \(\hat{i}_t\:=\:f_g^t(i_{t-1})\)高分辨率、由G-buffer引导把上一帧对齐到当前帧的结果
- \(\hat{m}(,)\) 为权重预测器,输入两张要融合的图,输出每张图的权重。本质操作就是通过这个函数来对两个图像进行混合(为一个 01 掩码)
- \(\hat{m}\) 混合策略
- 值越大表示更倾向于采用 FRNet 采样的结果来修正非刚性着色区域;越小表示倾向于保留高分辨率的重投影结果
- 也就是说好的权重应该满足如下:既要保留高分辨率细节,又要修正错误着色
- 准则:只有当当前像素与候选历史像素在 G-buffer 上“相似”时,才使用低分辨率的着色结果(即更相信 U(FRNet));否则优先保留高分辨率的几何重投影结果。
- 从而防止引入错误的表面信息,破坏边界
- \(\begin{aligned}\hat{m}(U(\bar{i}_t^-),\hat{i}_t)&=\left((1-\frac{1}{\sqrt{3}}\|U(\alpha_t^-)-\alpha_t\|_2)\odot\det(U(n_t^-),n_t)>\delta_1\right)\\&\cap(\|U(\bar{i}_t^-)-\hat{i}_t\|/\|U(\bar{i}_t^-)\|>\delta_2),\end{aligned}\)
- \(n\) 法线,\(\alpha\) 基础色/反照率(与光照无关的材质颜色),\(\odot\) 逐元素乘法,\(\delta_1,\delta_2\) 两个阈值(这里设置为 0.1)
- 颜色一致性: \(1-\frac{1}{\sqrt{3}}\|U(\alpha_t^-)-\alpha_t\|_2\) 把当前帧低分辨率图像做上采样后与当前帧做欧式距离,本式子最终得到的结果为“越相似值越大”的相似度
- 法线一致性:\(\det(U(n_t^-),n_t)\) 同样值越大说明越相似
- 是否能用低分辨率图像进行修复:逐元素相乘与阈值比较,即只有在同一材质颜色并且发现方向相似的情况下才认为是同意表面,允许用 FRNet 得到的低分辨率图更多的参与混合(条件一)
- 是否有必要进行修复: \(\|U(\bar{i}_t^-)-\hat{i}_t\|/\|U(\bar{i}_t^-)\|>\delta_2\) 当 FRNet上采样输出与 wrap 结果差异比较大时说明有必要用 FRNet 对图像汇总的阴影等进行修复(条件二:避免引入不必要的低分辨率模糊)
- FRNet 网络的训练
- 损失函数由两部分组成:重建损失 \(\mathcal{L}_{r}\) 和特征空间损失 \(\mathcal{L}_{f}\)
- 重建损失: \(\mathcal{L}_r=\rho(\hat{i}_t-i_t^\mathrm{gt})+\mathcal{L}_{\mathrm{cen}}(\hat{i}_t,i_t^\mathrm{gt})\)
- 由Charbonnier 损失 \(\rho()\) 和census 损失 \(\mathcal{L}_{\mathrm{cen}}()\) 两部分组成
- \(\hat{i}_{t}\) 为 FRNet 的预测帧;\(i_{t}^{gt}\) 为当前帧的真实图像
- 用于学习亮度颜色等信息
- 特征空间损失:\(\mathcal{L}_f=\sum_{k=1}^3\mathcal{L}_{\mathrm{cen}}(\bar{\phi}_t^k,\phi_t^k)\)
- 把预测帧与真值帧分别送入一个特征提取器在多层特征上计算 census 损失并求和
- 分别为预测帧和真值帧在第 k 层的特征图
- 用于学习到更高层的着色形状、布局等信息
- 最终损失函数:\(\mathcal{L}_{\mathrm{FR}}=\mathcal{L}_r+\lambda\mathcal{L}_f\) 其中 \(\lambda=0.001\)
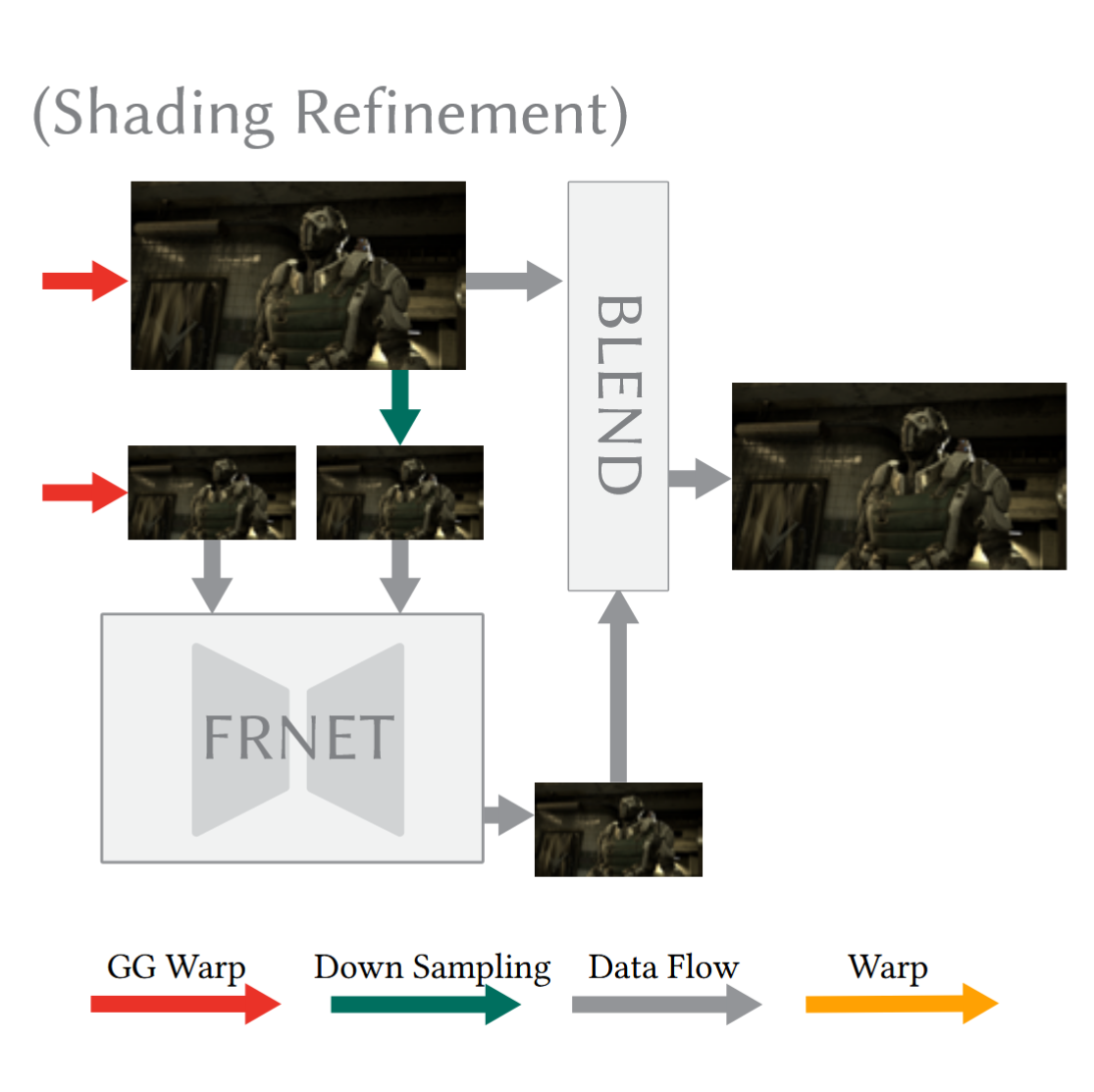
这一阶段的总览
FRNet 修复与混合,作用
EXtraSS 网络¶
-
前两阶段已经能在低分辨率上得到较好的外推帧,本阶段的目标主要是将低分辨率的外推结果提升到目标分辨率,同时进一步改进外推的准确性与细节:
- 从低分辨率重建高分辨率细节与纹理
- 继续修正外推中的时序错误
-
网络结构:
- 首先网络有两种任务输出:SS 只做空间超采样的 t 帧;ESS同时做空间超采样与外推的 t+1 帧
- 两个编码器用于将多输入源融合,提取多尺度的高层数据,之后将数据交给解码器重建高分辨率图像,这样技能节省参数数量,也能保证输出风格的一致性
- 用编码器 E0 来执行 SS:\(\bar{I}_t=D(E_0(i_t,f_r(\bar{I}_{t-1}),d_t))\)
- \(i_{t}\) 当前帧的低分辨率图像,\(d_{}t\) 场景深度,\(f_r(\bar{I}_{t-1})\) 上一帧的高分辨率帧经过重投影的高清图像
- \(D\) 为共享解码器
- 用编码器 E1 来执行 ESS:\(\bar{I}_{t+1}=D(E_1(f_g^{t+1}(i_t),\bar{i}_{t+1},f_r(\bar{I}_t),\alpha_{t+1},d_{t+1}))\)
- \(f_g^{t+1}(i_t)\) Gbuffer 重投影把低分辨率图像 \(i_{t}\) 外推到 t+1 帧的结果
- \(\bar{i}_{t+1}\) FRNet 的第 t+1 帧预测结果
- \(f_r(\bar{I}_t)\) 将第 t 帧的高清图像重投影(无 Guffer 的传统方法)到 t+1 帧的结果
- \(\alpha_{t+1},d_{t+1}\) 为来自 Gbuffet 的 t+1 数据
-
损失函数结构
- 遮挡区损失\(\mathcal{L}_{\mathrm{occ}}=\frac{\|m(I_t)\cdot\bar{I}_t-m(I_t)\cdot I_t^\mathrm{gt}\|_1}{\sup(m(i_t))}\)
- 强调“反遮挡/鬼影”区域,让网络更用力修复这些难点
- \(\overline{I}_{t}\) 为输出的高分辨率结果,\(I_{t}^{gt}\) 为真值
- \(m(I_{t})\) 为反遮挡区域的掩码,值越大表示该像素在当前帧中新显露、重投影不可靠,容易出现鬼影。
- 感知损失\(\mathcal{L}_{\mathrm{vgg}}(\bar{I}_t, I_t^{\mathrm{gt}}) = \sum_{l \in \mathcal{S}} w_l \, \big\| \phi_l(\bar{I}_t) - \phi_l(I_t^{\mathrm{gt}}) \big\|_1\)
- 用预训练的 VGG 网络在特征空间比较生成图与真值图(一种现成的方式)
- 空间损失 \(\mathcal{L}_s=\|\bar{I}_t-I_t^\mathrm{gt}\|_1+\lambda_{\mathrm{occ}}\mathcal{L}_{\mathrm{occ}}+\lambda_{\mathrm{vgg}}\mathcal{L}_{\mathrm{vgg}}\mathcal{L}_{\mathrm{vgg}}\)
- 其中 \(\lambda_{occ}=1 \\ \lambda_{vgg}=0.01\)
- 时间损失 \(\mathcal{L}_t=\|\bar{I}_t-f_r(\bar{I}_{t-1})\|_1+\sum_{k=1}^4l_1(\bar{\Phi}_t^k,\Phi_t^k)\)
- \(\bar{\Phi}_t^k,\Phi_t^k\) 分别为E0 在第 k 层从“SS-only 输入”提取的特征和E1 在第 k 层从“ESS 输入”提取的特征
- 最终损失函数 \(\mathcal{L}=\mathcal{L}_s+\lambda_t\mathcal{L}_t\) 其中 \(\lambda_{t}=1\)

- 遮挡区损失\(\mathcal{L}_{\mathrm{occ}}=\frac{\|m(I_t)\cdot\bar{I}_t-m(I_t)\cdot I_t^\mathrm{gt}\|_1}{\sup(m(i_t))}\)
复现¶
网络训练参数¶
- FRNet 与 ExtraSSNet 分别训练,先训 FRNet,后训 ExtraSSNet。
- 先把 FRNet 训好后“冻结参数”,作为 ExtraSSNet 的输入来源之一
- FRNet
- Optimizer: Adam
- 学习率: 1e-4
- Batch size: 8
- 训练 100 个 epoch
- ExtraSSNet
- Optimizer: Adam
- 学习率: 4e-4
- Batch size: 12
- 训练 120 个 epoch
网络结构图¶
Extrass
- 左边红色的部分为 E0 E1 编码端,右边黄色的为 D 解码端 - 可以训练时在同一轮里分别前向它们,再把输出喂给同一个“橙色解码器 D”,计算联合损失并共同反传
FRNet
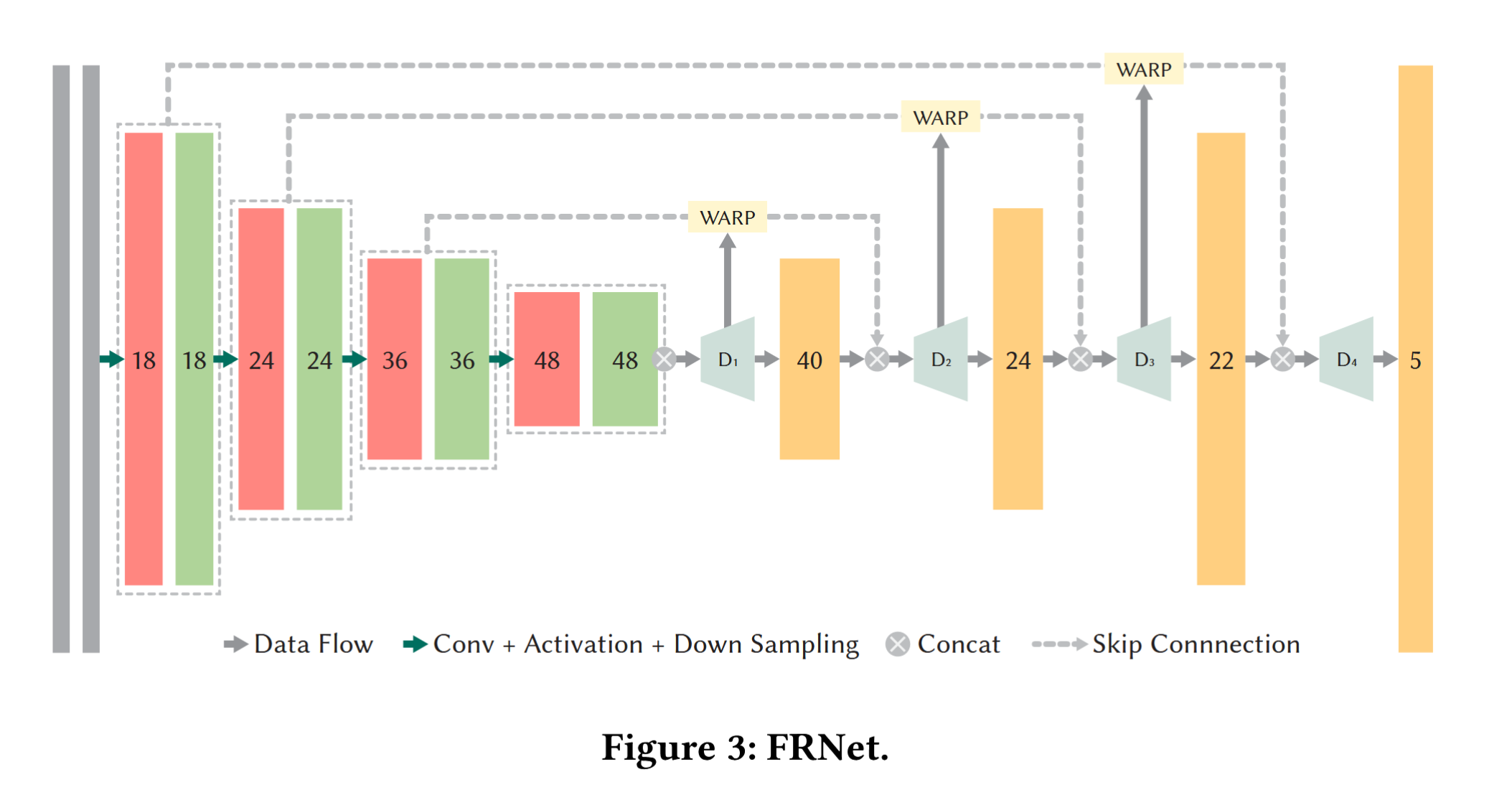
- 多尺度位移头 (D₁…D₄)
- 在 4 个不同尺度上各预测一张 2-D flow(位移场)。
- 预测出的位移立即喂给 WARP 模块,对历史帧做多次渐进式重对齐。
- 这样做相当于在网络内部完成了一个“粗 → 细”的光流级联:
先在 1/16 分辨率对齐一个大致流,再回到 1/8 … 最终在 1/2 分辨率细化。 - 这些 wrap 的目的就是希望把前面 G-buffer wrap 造成阴影等非刚性运动物体的偏移纠正回来
- 输出估计(u, v)两个通道(二维位移场),表示对每个像素的偏移量(wrap)