概述
- 进程:指在计算机系统中正在运行的程序的实例。每个进程都有自己的内存空间和执行环境,可以与其他进程进行通信。
- 进程间通信:是指在同一个主机上运行的两个进程之间进行通信的方式。操作系统提供了一种机制来支持进程间的数据传输和交互。
- 应用层协议(App-layer protocol):用于在不同主机上运行的进程之间进行通信的协议。不同的应用程序(如Web、电子邮件、流媒体)使用不同的应用层协议来实现数据交换和通信。
- 用户代理:是介于应用程序和网络之间的接口。它实现了用户界面和应用层协议,使用户能够与应用程序进行交互,同时通过网络与其他主机上的进程进行通信
- 用户层协议的内容
- 消息交换的类型:应用层协议规定了在不同进程之间交换的消息类型。
- 消息类型的语法:应用层协议规定了消息类型的语法。它定义了消息中的字段以及如何划分字段。
- 消息中的字段和字段的语义:应用层协议规定了消息中字段的含义。它确定了字段中包含的信息的含义和解释。
- 进程何时以及如何发送和响应消息的规则:应用层协议定义了进程发送和接收消息的规则。它规定了进程何时发送消息、如何构造消息、如何发送消息以及如何对收到的消息做出响应。
- 分类
- client-server
- client向server发送请求,开启会话,通常具有动态ip
- server始终开机,等待client的信息并进行服务,通常具有固定ip
- peer-to-peer (P2P)
- 不是一直可用,分布式,不一定一直开机
- 节点之间是动态链接的
- 新的节点加入既会索求资源,也会加入服务资源
- BitTorrent, Skype

- client-server
DNS
- 位于应用层
- 功能:实现从域名到ip的映射
- 使用UDP进行传输
- 内容
- 分发数据库:
- 应用层协议:host和服务器沟通获得信息进行映射
- 负载均衡:同一个域名可能被映射到不同ip
- 分布式系统
- 目标:
- 唯一性:域名不能有冲突
- 可扩展性:系统或网络具有应对不断增长的负载和需求的能力,可以频繁进行更新。
- 分布式、自治性管理
- 可以更改自己的信息
- 不需要跟踪(记录)全世界的所有信息
- 高可用性
- 迅速
- 不追求强一致性(可以偶尔出错)
域名层次结构
将命名空间进行划分,即将系统中的命名空间分成多个部分。每个分区的管理将被分配给不同的实体,这样每个实体就可以自主更新自己的机器名称,而不需要追踪其他人的更新。
关键思想:层次结构
- 层次化的命名空间
- 层次化管理
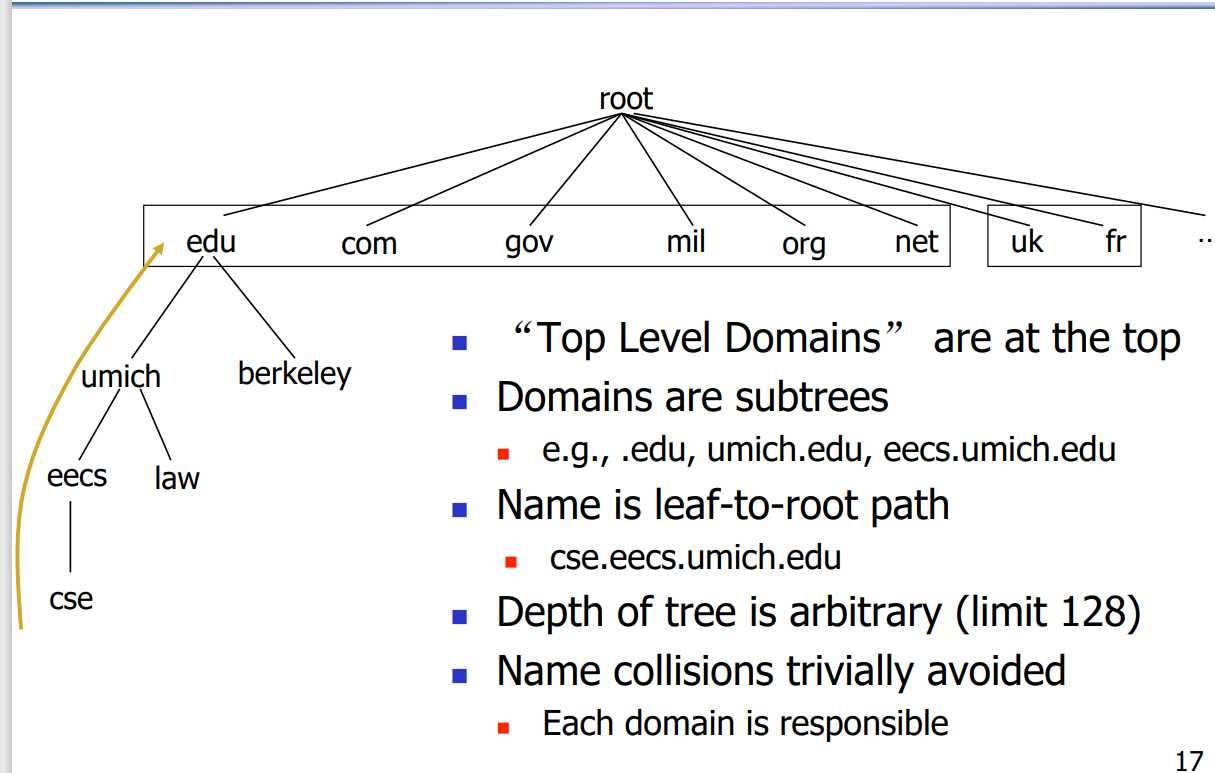
从根节点向下划分域名
完整域名是从根节点从下向上
通常最深128层
使用树形结构可以避免域名冲突
每个节点各自管理自己为根的子树
每个服务器存储总DNS数据库的一个(小)子集:这意味着DNS数据库被分割成多个部分,并分布在不同的服务器上。每个服务器只存储与其具有管理权限的域相关的资源记录。
如
*.nju.edu.cn
运作原理
- 根域名服务器:这些服务器是DNS系统的顶级服务器,它们保存了顶级域名的信息,例如.com、.org、.net、.edu等,以及所有顶级国家域名,如.cn、.uk、.fr等。当本地名称服务器无法解析某个名称时,它会向根域名服务器发送请求。
- 顶级域名服务器(TLD):这些服务器负责管理顶级域名,如.com、.org、.net、.edu等。它们也管理所有顶级国家域名,如.cn、.uk、.fr等。
- 授权DNS服务器:这些服务器属于组织或机构,提供对应用程序的域名到IP地址的授权映射。它们维护着特定域名的权威信息,当有其他DNS服务器查询特定域名时,授权DNS服务器提供正确的映射。
- 授权DNS服务器存储某个域中所有DNS名称的“资源记录”:授权DNS服务器负责存储其具有管理权限的域中所有DNS名称的资源记录。这包括该域中每个主机名对应的IP地址等信息。
- 授权DNS服务器是组织自己的DNS服务器,用于提供对该组织命名主机的权威域名到IP地址的映射。这些服务器可以由组织自行维护,也可以由服务提供商来维护。
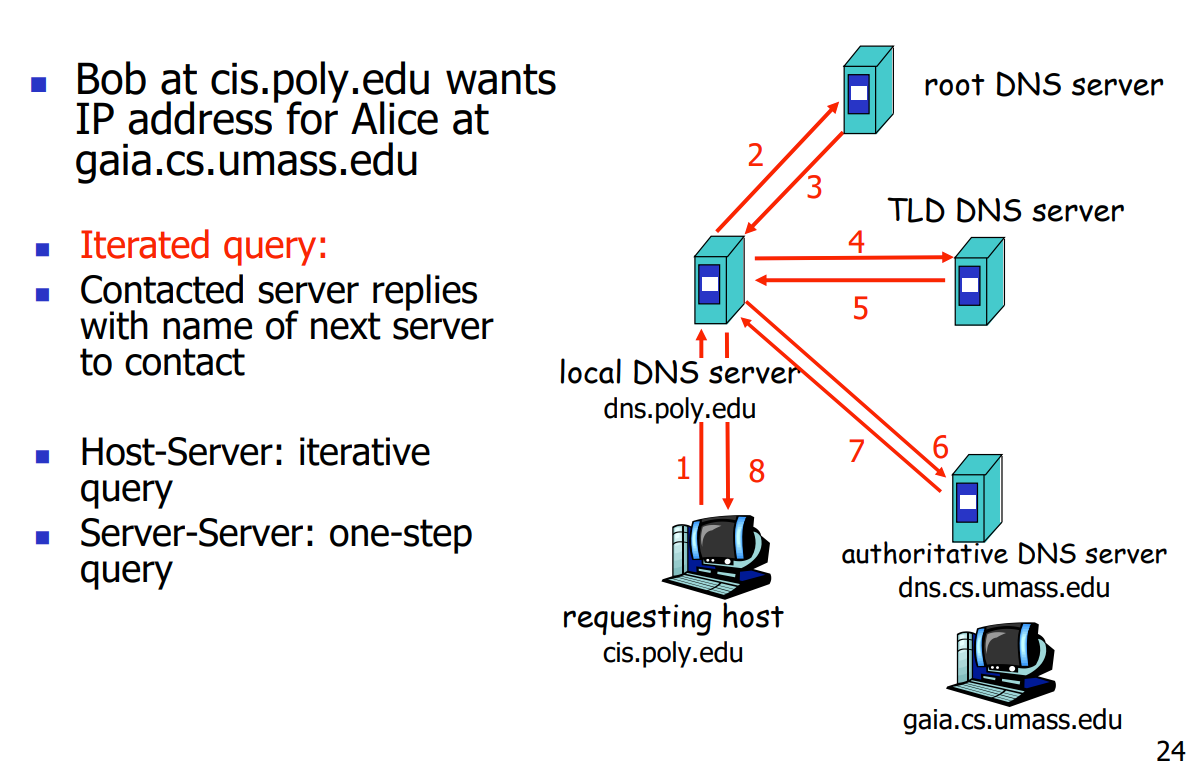
- 本地名称服务器:每个住宅ISP、公司、大学都维护着自己的本地名称服务器。当主机发起DNS查询时,查询被发送到本地名称服务器,它负责处理查询并尝试解析域名。如果本地名称服务器无法解析域名,它会向更高级的DNS服务器发送查询请求。(负责向上查询)
- 本地名称服务器不严格属于DNS层次结构:本地名称服务器不直接属于DNS的层次结构,它是每个ISP(住宅ISP、公司、大学)都拥有的一个服务器。它也被称为“默认名称服务器”。
- 当主机进行DNS查询时,查询会发送到其本地名称服务器。
- 本地名称服务器具有最近的名称到地址转换对的本地缓存(但可能过期):本地名称服务器会缓存最近的名称到地址转换对,以提高查询的性能。但是,这些缓存可能会过期,因此可能不是最新的。
- 本地名称服务器充当代理,将查询转发到层次结构中:本地名称服务器充当代理,将主机的查询转发到DNS层次结构中的其他服务器,以获取所需的解析结果
- 每个服务器需要知道负责其他层次结构部分的其他服务器:为了能够正确解析域名并提供准确的资源记录,每个服务器都需要了解负责其他层次结构部分的其他服务器的存在。这样,当某个服务器无法解析特定域名时,它可以向负责该域名的服务器发送查询请求。
- 每个服务器都知道根服务器:为了建立整个DNS层次结构,每个服务器都需要了解根服务器的存在和位置。根服务器保存了所有顶级域名的信息,并可以提供对其他DNS服务器的查询引导。
- 查询过程
- DNS记录

- name为字符串
- value为ip值
- type表示类型
- ttl表示生命周期
- 保存在cache中
- 可靠性
- 复制的DNS服务器(主/备份):主服务器是主要的服务器,而备份服务器是在主服务器不可用时提供备份服务的服务器。
- 只要至少有一个复制服务器正常工作,服务就可用
- 查询可以在复制服务器之间进行负载均衡:查询可以在多个复制服务器之间进行负载均衡,以分担服务器的负载和提高性能。
- 如果需要可靠性,必须在UDP上实施可靠性机制,例如通过重试和超时处理来确保查询的可靠传输。
- 如果在查询过程中发生超时,可以尝试使用备用服务器进行查询。
- 在重试相同服务器时,可以使用指数退避策略,逐渐增加重试的间隔时间,以避免对服务器造成过大的负载。
- 对于同一个查询,所有的复制服务器都使用相同的标识符,以便可以识别和跟踪查询的状态和结果。
- 对于发起查询的客户端来说,并不关心哪个复制服务器响应查询,只要能够获得有效的解析结果即可。
- 复制的DNS服务器(主/备份):主服务器是主要的服务器,而备份服务器是在主服务器不可用时提供备份服务的服务器。
- 快速查询
- 进行所有这些查询需要时间:执行所有的DNS查询需要一定的时间。这些查询包括从根服务器到顶级服务器再到授权DNS服务器的一系列查询,这可能导致下载之前的延迟。
- 缓存可以大大减少开销:DNS缓存可以大大减少DNS查询的开销。因为顶级服务器很少更改,并且访问频率较高的常用网站的信息通常被本地DNS服务器缓存。
- DNS缓存的工作原理:DNS服务器会缓存对查询的响应结果。响应结果中包括一个“存活时间”(TTL)字段,它指示了该条目在缓存中的有效期。当TTL到期后,服务器会删除缓存中的条目。
- 常见协议
- SMTP(简单邮件传输协议):用于传递简单文本消息的协议。它是电子邮件系统中用于发送邮件的主要协议。
- MIME(多用途互联网邮件扩展):用于传递各种类型的数据,例如声音、图像、视频剪辑等,扩展了SMTP协议的功能。
- POP(邮局协议):用于从服务器中检索邮件的协议,包括授权和下载邮件。当用户通过邮件客户端下载邮件时,通常使用POP协议。
- IMAP(互联网邮件访问协议):用于在服务器上操作存储的邮件的协议。IMAP允许用户在不下载邮件到本地计算机的情况下,在邮件服务器上直接管理和操作邮件。
- 用户代理(客户端)(User Agent):用户代理是指用于组织、编辑和阅读邮件消息的软件应用程序。例如,Eudora、Outlook、Foxmail、Netscape Messenger等都是常见的用户代理。用户可以使用用户代理来编写、编辑、发送和接收邮件消息。发送的邮件消息和接收的邮件消息都存储在邮件服务器上。
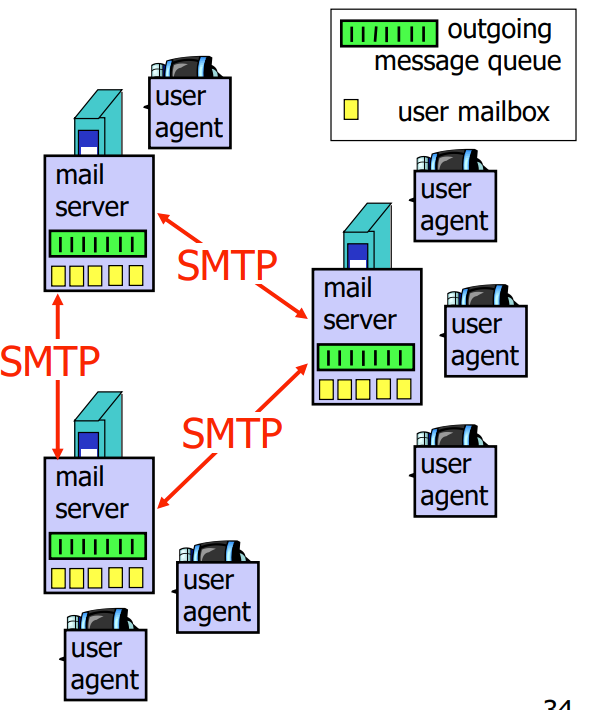
- 邮件服务器(Mail Servers):邮件服务器是指用于处理电子邮件的服务器。它包括两个主要组件:邮箱(Mailbox)和消息队列(Message Queue)。
- 邮箱(Mailbox)包含了用户接收的邮件消息。当其他用户向该用户发送邮件时,邮件服务器会将这些邮件消息存储在相应的邮箱中,以便用户可以检索和阅读。
- 消息队列(Message Queue)包含了等待发送的邮件消息。当用户发送邮件时,邮件服务器会将这些邮件消息存储在消息队列中,以便逐一发送到目标地址。邮件服务器之间使用SMTP协议进行邮件消息的传输。
- 邮件的构成
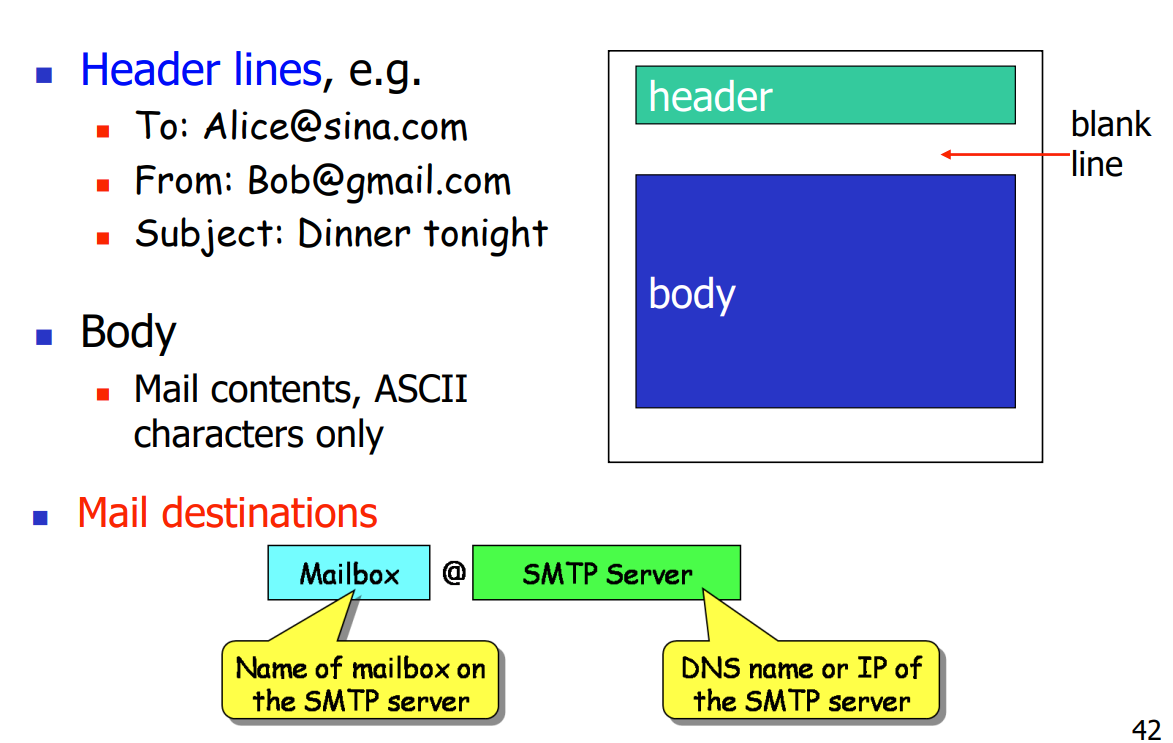
传输过程
- email从本地用户端发送到SMTP服务器
- 本地用户作为SMTP客户端,本地服务器作为SMTP服务器
- 本地服务器发送到远程SMTP服务器
- 本地服务器作为SMTP客户端
- 远程服务器使用access protocol to access the mailbox on remote server POP3 or IMAP4
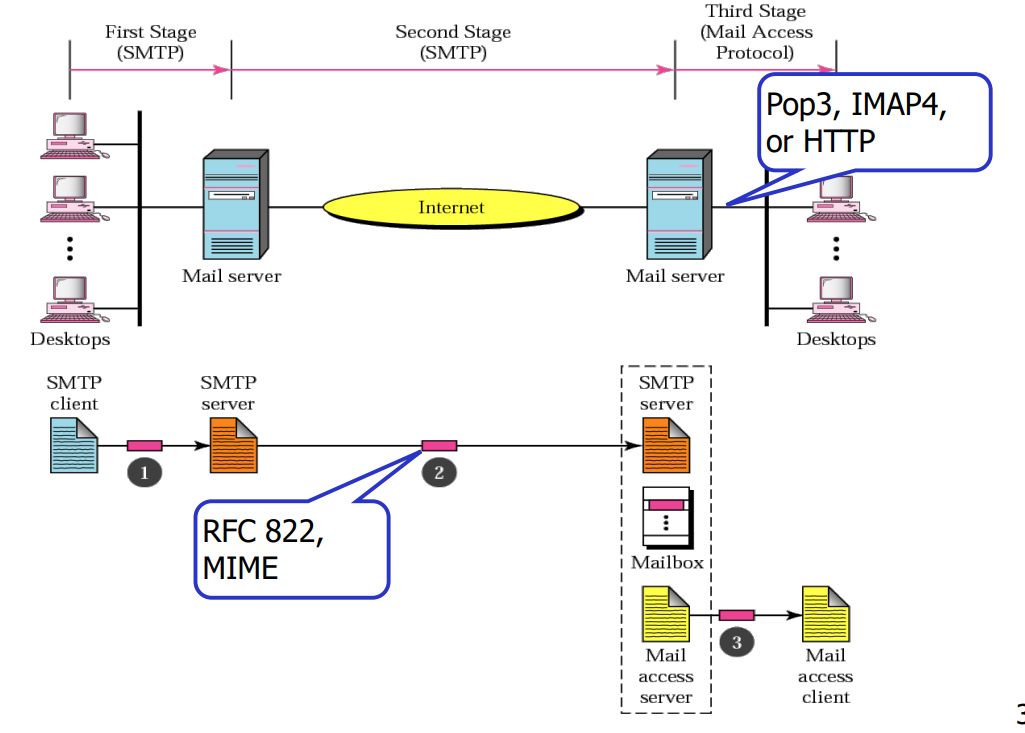
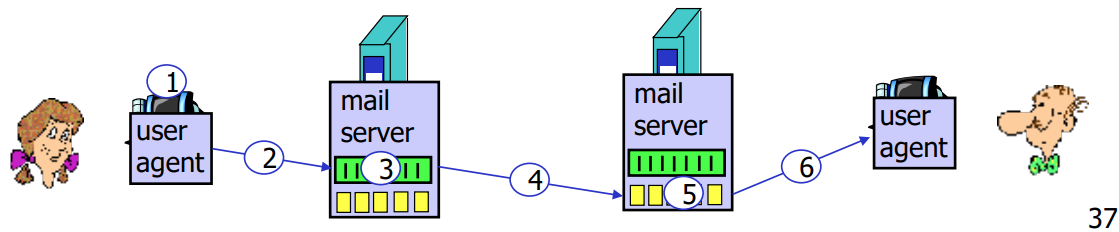
- Alice使用用户代理(UA)撰写一封邮件消息,并发送给bob@someschool.edu。
- Alice的用户代理通过SMTP协议将邮件发送到她的邮件服务器,并将邮件放置在消息队列中。
- SMTP客户端在客户端与Bob的邮件服务器之间建立TCP连接。
- SMTP客户端通过TCP连接发送Alice的邮件。
- Bob的邮件服务器将邮件放置在Bob的邮箱中。
- Bob使用他的用户代理(UA),例如通过POP3协议,来读取邮件。
SMTP传输协议
使用ASCII码文字作为交互命令
RFC 821:
- 使用TCP协议的25号端口进行通信。
- 直接传输:将电子邮件消息从客户端直接传输到服务器。
- 需要在邮件信封(即消息头)上写入相关信息,以确定邮件的传递路径。
- 可以在消息头中添加日志信息,以显示邮件的传递路径。
- RFC 821并不涵盖邮件消息或数据的格式。邮件消息的格式定义在RFC 822或MIME中。
- 邮件消息必须采用7位ASCII编码。
- 过程
- 握手
- 传输数据
- 关闭连接

- 可靠性
- 使用TCP进行传输,依赖于TCL的可靠性
- 不保证可以找回丢失的邮件
- 没有端到端的确认(回执,确认收到已读)
- 可能只是传输到了服务器,而没有到用户手中(可能未读)
- 通常是比较可靠的
邮件获取协议
- 从服务器获取收到的邮件
- POP(邮局协议):POP是一种用于电子邮件系统的协议,定义在RFC 1939中。它用于用户代理(邮件客户端)与邮件服务器之间的授权验证和邮件下载过程。使用POP协议,用户可以授权访问邮件服务器上的邮件,并将邮件下载到本地计算机进行阅读和处理。
- IMAP(互联网邮件访问协议):IMAP是一种用于电子邮件系统的协议,定义在RFC 1730中。IMAP相比于POP具有更多的功能。除了授权验证和邮件下载外,IMAP还提供了操作邮件服务器上存储的邮件的能力。用户可以在邮件服务器上直接管理和操作邮件,例如创建文件夹、移动邮件、标记已读或未读等。IMAP协议适用于需要在多个设备上同步邮件状态的场景。
- HTTP(超文本传输协议):HTTP是一种用于在互联网上传输超文本文档的协议,广泛用于网页浏览器和服务器之间的通信。某些电子邮件服务提供商(如Gmail、Hotmail、Yahoo!等)使用HTTP协议作为访问其电子邮件服务的接口。通过HTTP,用户可以使用网页浏览器访问电子邮件服务提供商的网页界面,进行邮件的发送、接收和管理操作。
pop3
- 过程
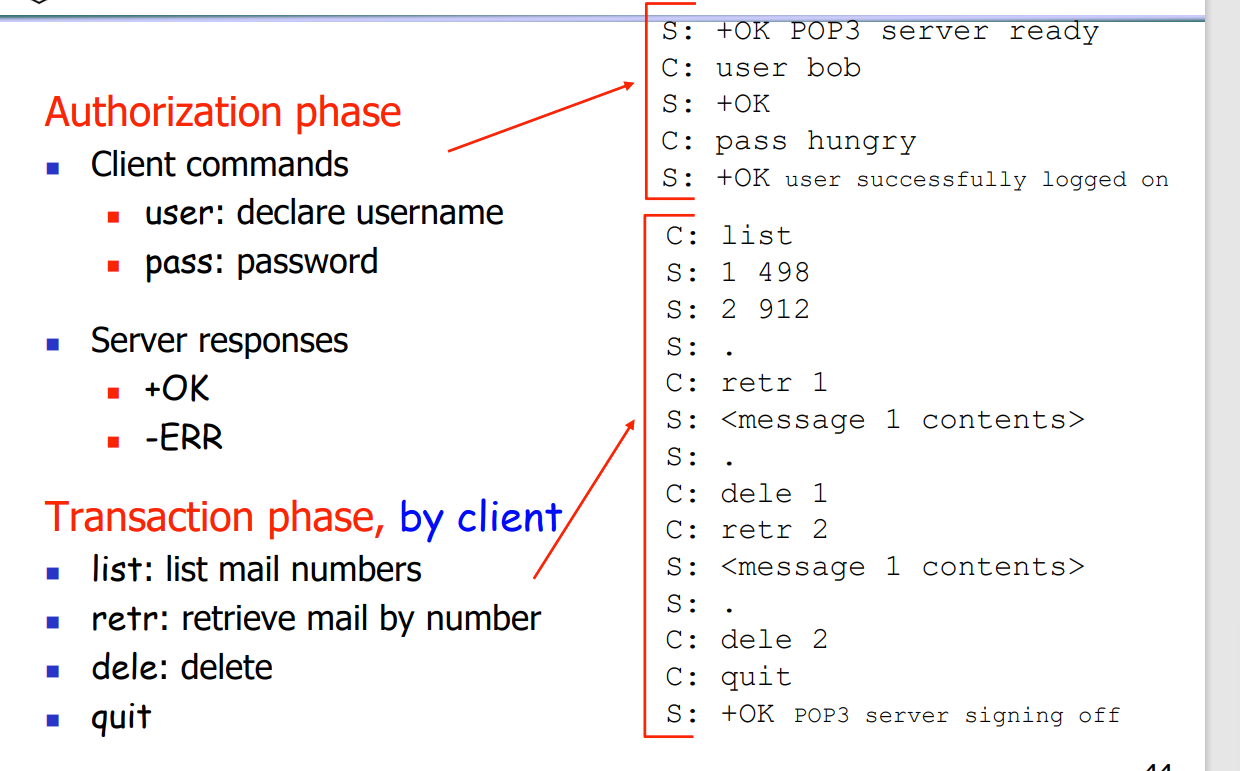
- 用户身份认证
- 获取数据/操作
- 可以选择下载并从服务器删除/继续保留
- IMAP可以在线观看/编辑,邮件都保存再服务器上,服务器可以记录邮件阅读状态(在线修改)
- 编码

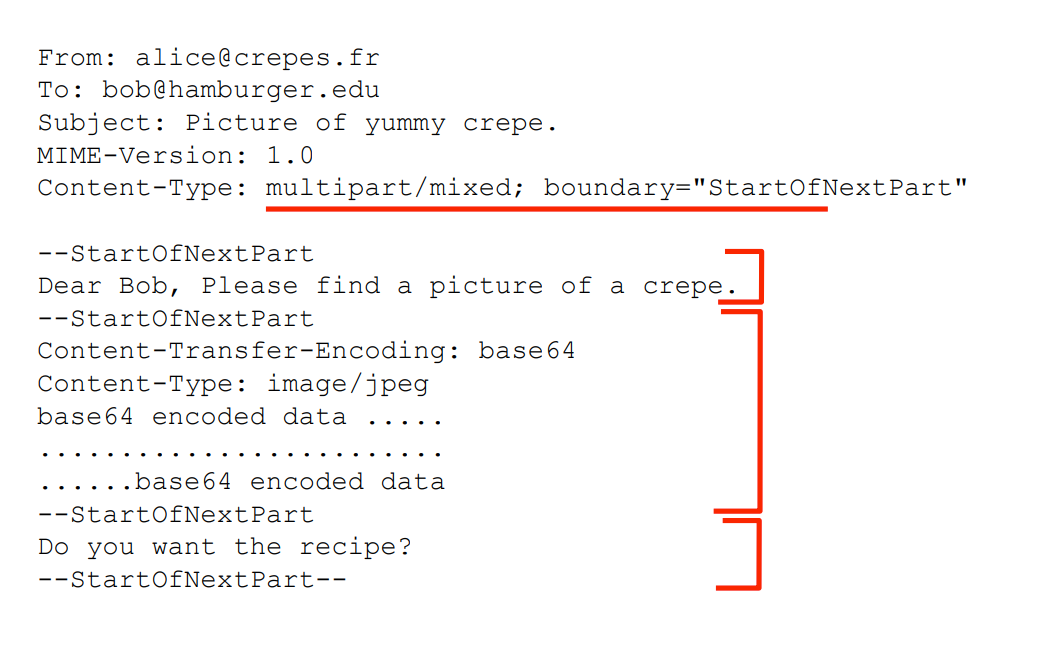
MIME多媒体拓展
- 所有数据内容使用文本(base64)进行编码,为了兼容其他的早期协议
- 以7位ASCII编码:MIME将邮件内容和附件中的所有数据都编码为7位ASCII字符集,以确保兼容性和可靠的传输。这意味着MIME邮件可以在任何支持ASCII字符集的系统上正确显示。
- 忽略非MIME邮件系统的头部和分隔符:非MIME邮件系统无法解析MIME邮件的头部和分隔符,因此会将其忽略。这样做可以确保MIME邮件在非MIME系统中的传递和显示。
- MIME是可扩展的:MIME提供了一种可扩展的机制,允许定义和支持各种不同类型的数据和附件。通过使用适当的MIME类型和子类型,发送方和接收方可以约定一致的编码方案,以确保正确解析和显示邮件中的数据。
- 增加头部

- 多文件

FTP
- RFC 959, use TCP, port 21/20
- 同样使用ascii作为控制命令
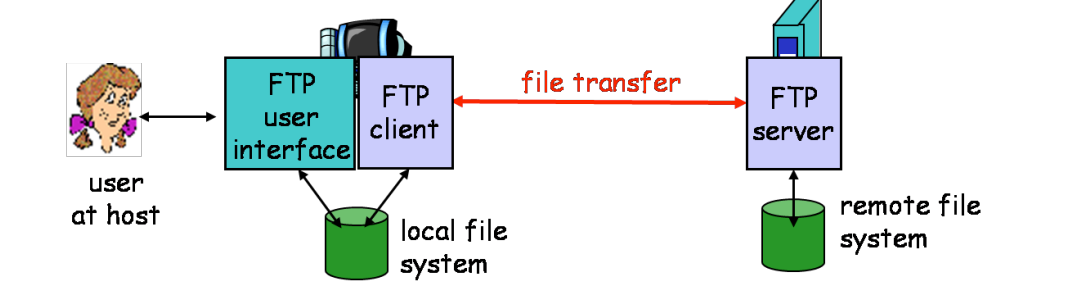
- 客户端/服务器模型,相互传递文件
- 由客户端发起文件下载/上传请求
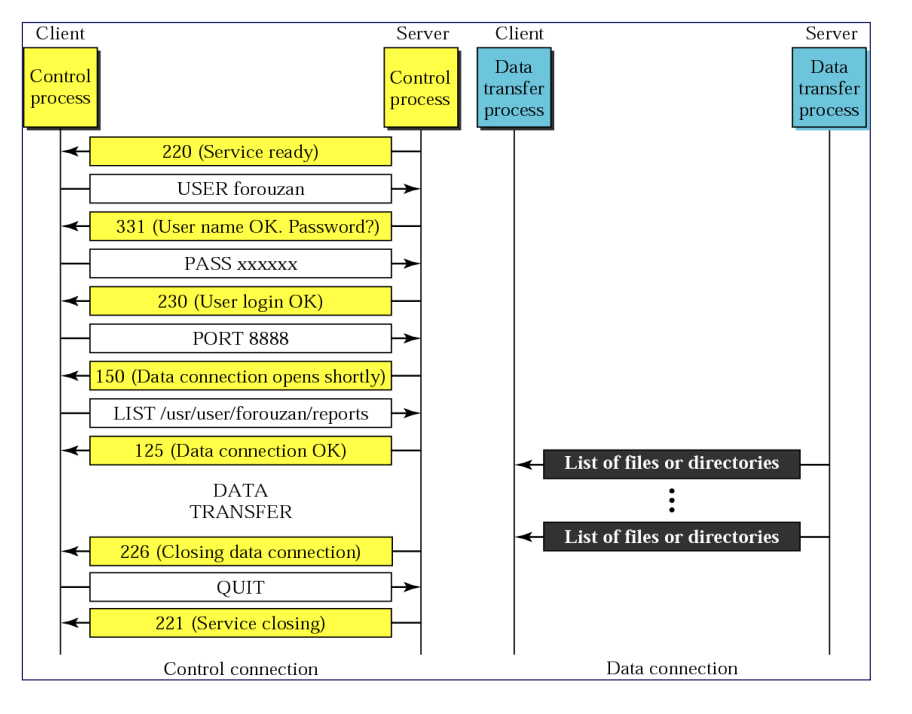
- 过程
- 建立两条信道:数据(tcp20)/控制(tcp21)
- 进行客户端身份认证
- 客户端收到文件列表,查看
- 客户端选择文件进行处理,服务端收到指令后开始执行(传输)
Web
"World Wide Web (WWW)" 万维网,它是由许多互连的文档(称为“页面”)组成的分布式数据库。这些页面通过超文本传输协议(HTTP)进行链接。
- "分布式数据库" 指的是万维网上存储的大量页面,这些页面可以由全球范围内的多个服务器托管和提供。
- "页面" 是包含文本、图像、音频、视频和其他媒体的文档,可以在浏览器中显示和访问。通过超链接,页面可以相互连接,形成一个网状结构。用户可以通过点击链接在页面之间进行导航。
- HTTP(Hypertext Transport Protocol)是用于在万维网上进行通信的协议。它定义了客户端和服务器之间的请求和响应规范。当用户在浏览器中访问一个页面时,浏览器会向服务器发送一个HTTP请求,服务器会响应并返回所请求的页面。
架构:client-servers
- 内容:
- URL:为内容命名
- HTML:页面内容
- 协议http
URL
- 每个页面都有一个唯一的地址,称为统一资源定位符(URL),可以通过浏览器访问
- 格式
<protocol>://<host>:<port>/<path>?<query_string>- 协议(Protocol):用于传输或解释对象的方法,例如 HTTP、FTP、Gopher 等。协议指定了客户端和服务器之间通信的规则和约定。
- 主机(Host):指对象所在的主机的 DNS 名称或 IP 地址。主机表示托管或提供对象的服务器的位置。
- 端口(Port):可选项,指定服务器上用于与客户端通信的端口号。如果未指定端口,则会使用默认的协议特定端口(例如 HTTP 的默认端口为 80)。
- 路径(Path):指对象所在文件的路径名,用于定位服务器上包含该对象的文件。路径可以包含文件夹和子文件夹的名称。
- 查询字符串(Query String):可选项,用于将参数以名称/值对的形式发送到服务器上的应用程序。查询字符串通常用于向服务器提供额外的参数或数据。
HTTP
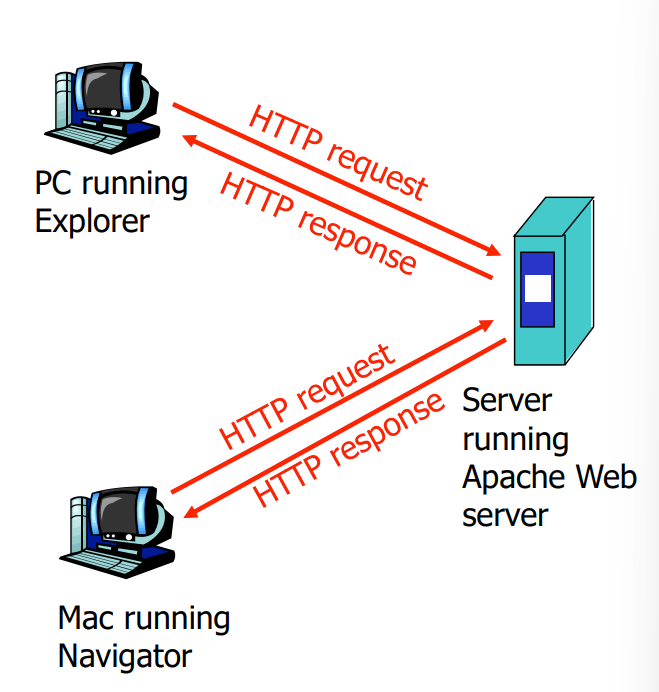
- 认为服务器总是开放,并且知名(公网ip)
- 客户端向服务器请求,初始化对话
- request/reply 使用TCP:80
- 无状态性
- 每个请求-响应独立处理:
- 每个客户端请求和服务器的响应都被独立地处理,服务器不需要保留先前请求的状态。
- 这意味着服务器在处理每个请求时不需要考虑之前的请求或响应,它可以按需处理每个请求而无需维护连接状态。
- 服务器不需要保留状态:
- 服务器不需要保留客户端请求的状态信息,因为每个请求都被视为独立的事件。
- 这提高了服务器的可伸缩性,因为它不需要为每个连接保留大量的状态信息。
- 优点:
- 独立处理请求-响应使得故障处理更加容易。
- 服务器能够处理更高速率的请求,因为每个请求都是独立处理的。
- 请求的顺序对服务器来说不重要,因为每个请求都是独立的。
- 缺点:
- 某些应用程序需要保持持久状态,例如购物车、用户配置文件、使用情况跟踪等。
- 对于这些需要持久状态的应用程序,需要一种方式来唯一标识用户或存储临时信息。
- 每个请求-响应独立处理:
- 使用ascii文本指令
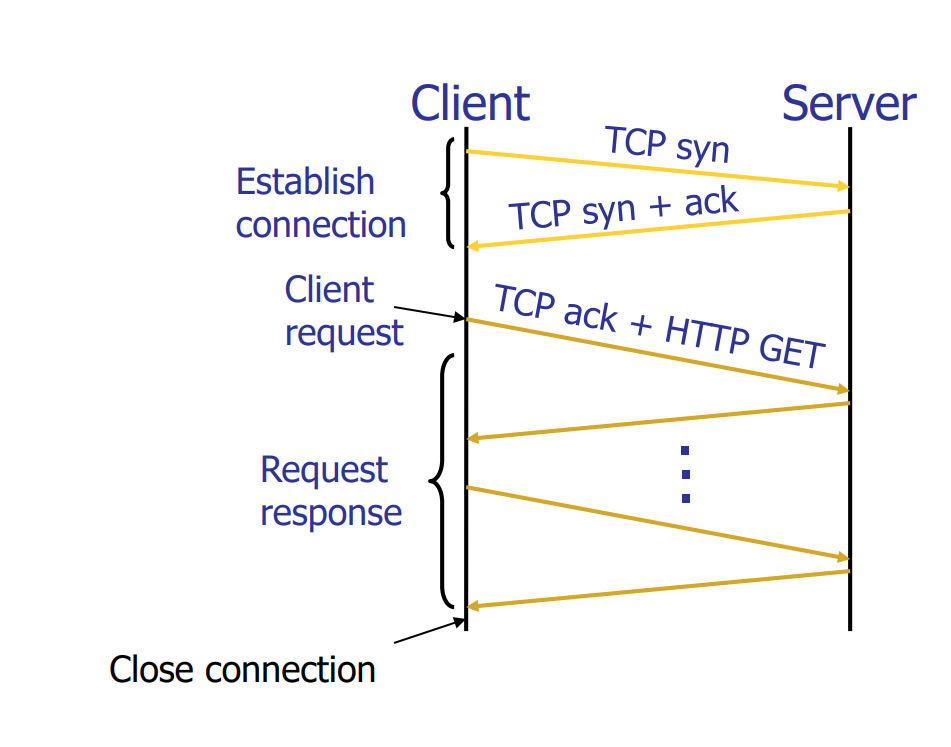
HTTP1.1
- 分类
- GET获取资源(页面)
- HEAD获取响应头
- POST提交内容(表单)
- PUT上传文件
- DELETE删除

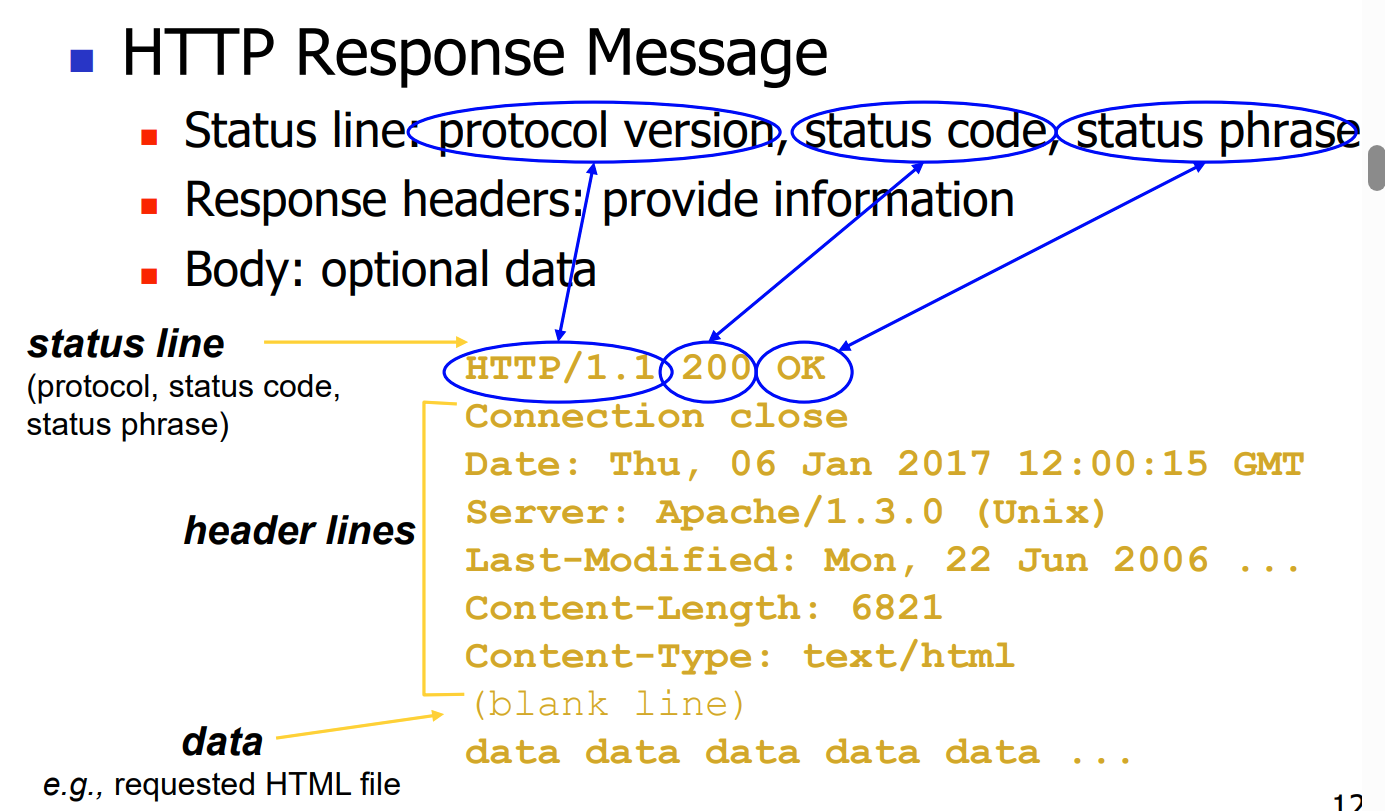
cookie
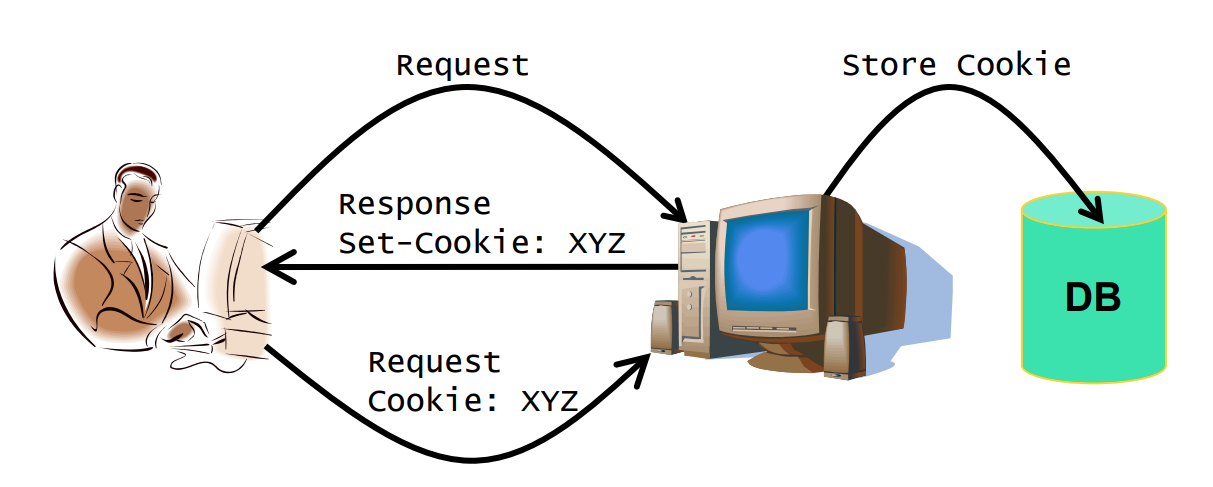
状态存储在客户端
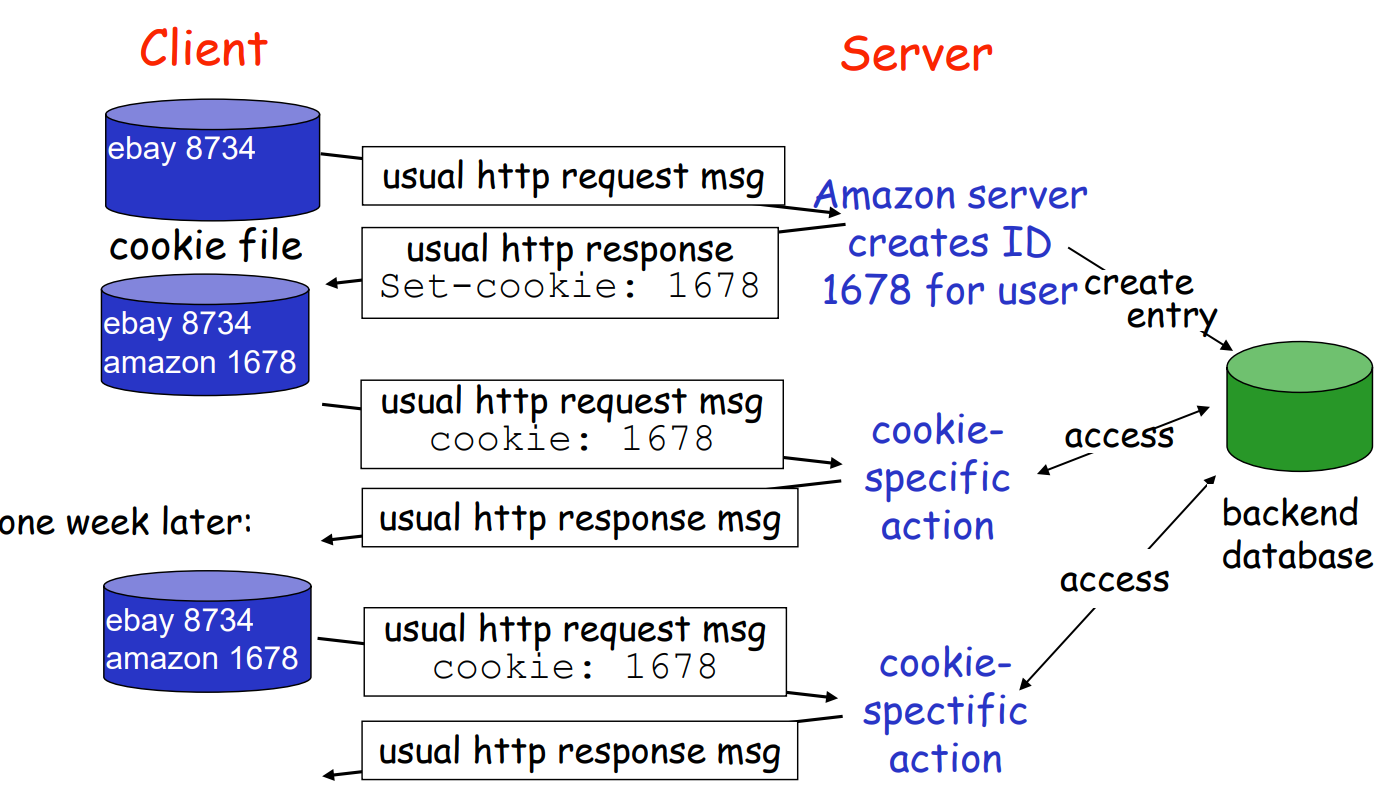
功能:
- 身份认证
- 信息存储(如购物车)
- 个性化推荐
问题:cookie可能会泄露信息,发送给网页服务器
- 如页面上的广告会根据信息推荐(如内嵌携程广告)
- 跨网站传输cookie
网页传输
- 目标
- 用户:速度快,高可用性
- 内容提供者:满意的用户,高效性(减少开销)
- 网络提供商:让网络性能满足需求、稳定
- 改进:
- 改进协议:http、tcp...
- 缓存,在多处存储内容,减少远距离传输
- CDN等专用服务
http性能提升
- 网页上有很多object,图片等各种信息,早期http一次一个,效率很低(tcp传输大量小文件!)


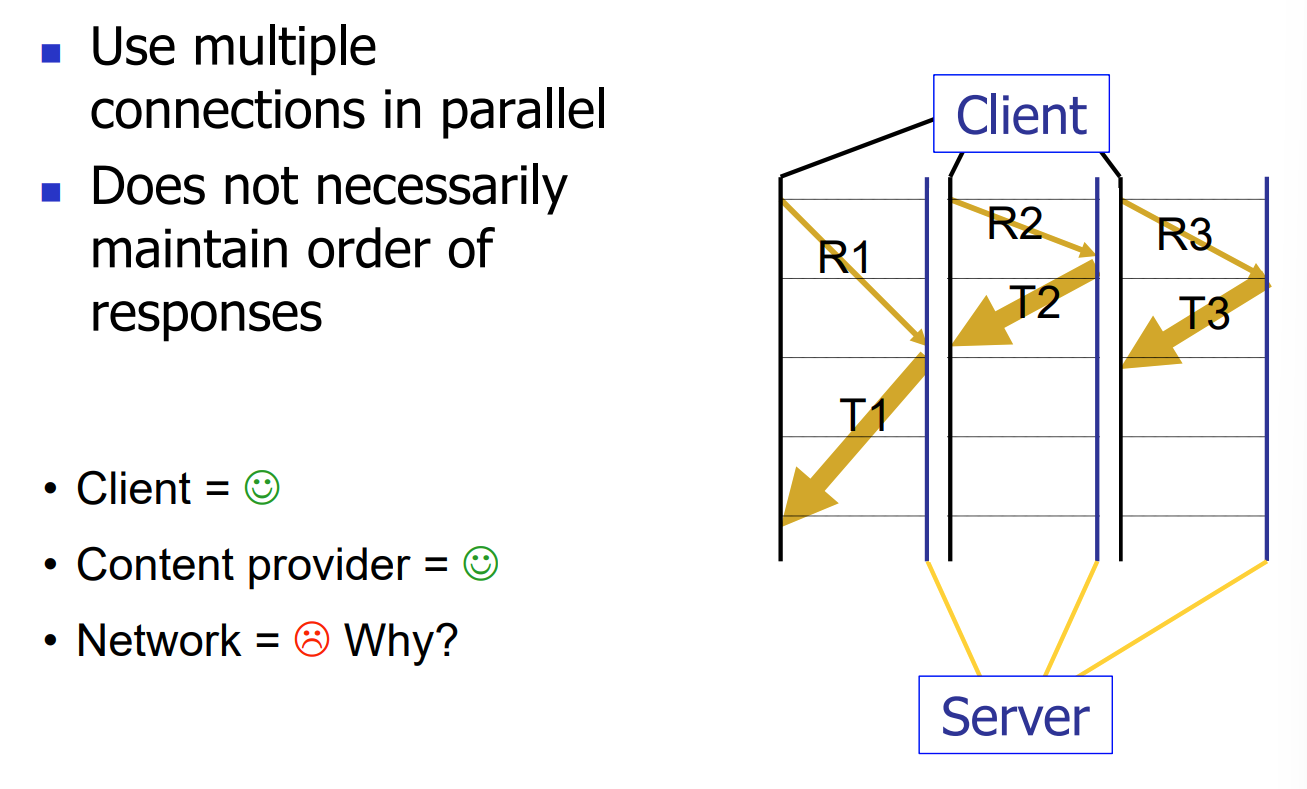
- 早期暴力解决:同时发送多个请求
- 最终改进:一个TCP传输更多信息,不再需要建立那么多的连接,并且传输时间长,TCP更稳定到达更大速率
- 多个请求组合在一起发送,减少数据包数量
- 最终改进:一个TCP传输更多信息,不再需要建立那么多的连接,并且传输时间长,TCP更稳定到达更大速率
- &&小文件延时(传输时间忽略)
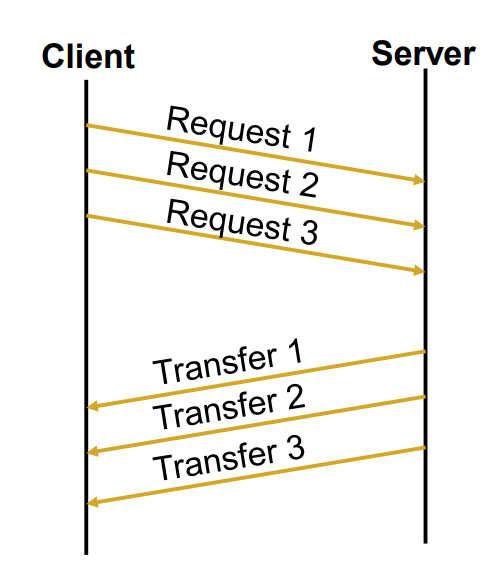
- 逐个获取(One-at-a-time):
- 当每个小对象都是逐个获取时,时间主要由网络延迟所主导。
- 在这种情况下,获取 n 个小对象所需的时间大约是 2nRTT
- 并发获取(Concurrent):
- 如果能够并发获取多个小对象,可以减少获取时间。
- 当使用 m 个并发连接时,获取 n 个小对象所需的时间大约是 2[n/m]RTT。
- 持久连接(Persistent):
- 当使用持久连接时,可以减少连接建立的开销。
- 在持久连接下,获取 n 个小对象所需的时间大约是 (n+1) RTT。第一个对象的获取需要一个额外的 RTT 用于建立连接,后续的对象可以在同一个连接上进行获取。(在同一个TCP上发送,但是一次发送一个)
- 流水线传输(Pipelined):
- 在使用流水线传输时,可以一个TCP同时发送多个请求并减少等待时间。
- 使用流水线传输,获取 n 个小对象所需的时间大约是 2 个 RTT。
- 流水线传输与持久连接(Pipelined/Persistent):
- 当结合流水线传输和持久连接时,首次获取可能需要 2 个 RTT 的时间,之后的获取只需要一个 RTT 的时间。
- 逐个获取(One-at-a-time):
- &&大文件延时(忽略RTT)
- 逐个获取(One-at-a-time):
- 当每个大对象都是逐个获取时,时间主要由带宽所主导。
- 在这种情况下,获取 n 个大对象所需的时间大约是 nF/B,其中 B 是每个连接的带宽。
- 并发获取(Concurrent):
- 如果能够并发获取多个大对象,可以减少获取时间。
- 当使用 m 个并发连接时,获取 n 个大对象所需的时间大约是 [n/m]F/B。
- 假设带宽是与大量用户共享的,并且每个 TCP 连接都获得相同的带宽。(个人总带宽会变化)
- 流水线传输和/或持久连接:
- 在流水线传输和/或持久连接下,获取 n 个大对象所需的时间大约是 nF/B。
- 逐个获取(One-at-a-time):
缓存
引入原因
- 生成不必要的服务器和网络负载:
- 当多个客户端同时请求相同的信息时,服务器需要为每个请求生成相同的响应。这会导致不必要的服务器负载和网络负载,因为相同的信息被多次传输。
- 客户端经历不必要的延迟:
- 当多个客户端同时请求相同的信息时,每个客户端都需要等待自己的响应。这可能导致不必要的延迟,因为客户端在获取相同的信息时需要等待其他客户端的响应。
- 生成不必要的服务器和网络负载:
引用局部性指的是在一段时间内,访问的数据往往具有较高的相关性,即相邻的数据项更有可能被多次访问。
- 缓存利用了这种引用局部性,将频繁访问的数据存储在快速访问的缓存中,从而加快数据的访问速度。
- 缓存的效果非常好,但是存在一定的限制。
- 缓存的效果取决于内容的重叠程度。虽然有大量内容重叠,但请求的内容也有很多是唯一的。缓存的有效性随着缓存的大小呈对数增长。

- 请求时提供上一次的请求时间,询问是否发生了变化
- 如果资源的最后修改时间早于或等于指定的时间,则服务器返回 "Not Modified" 的响应。
- 如果资源的最后修改时间晚于指定的时间,表示资源已经发生了修改,服务器将返回 "OK" 的响应,并提供最新版本的资源。
- Expires: 指示了资源在缓存中的有效期限,即缓存的过期时间。
- 当客户端再次发起请求时,如果当前时间已超过 Expires 字段指定的时间,则缓存的副本将被视为过期,客户端需要向服务器请求最新的资源。
- No-cache:
- No-cache 字段用于禁止缓存服务器对资源进行缓存。
- 当服务器返回带有 No-cache 字段的响应时,客户端和中间缓存服务器都会忽略缓存,每次都直接从服务器获取最新的资源。
- 这样可以确保客户端获取的是最新的资源,而不是缓存副本。
- 分类
- 客户端缓存
- 转发代理(Forward proxies):
- Forward proxies位于客户端和目标服务器之间,客户端发送请求时,请求首先发送到转发代理,然后由代理服务器转发请求到目标服务器。
- 转发代理还可以缓存响应以提高性能,减少对目标服务器的请求。
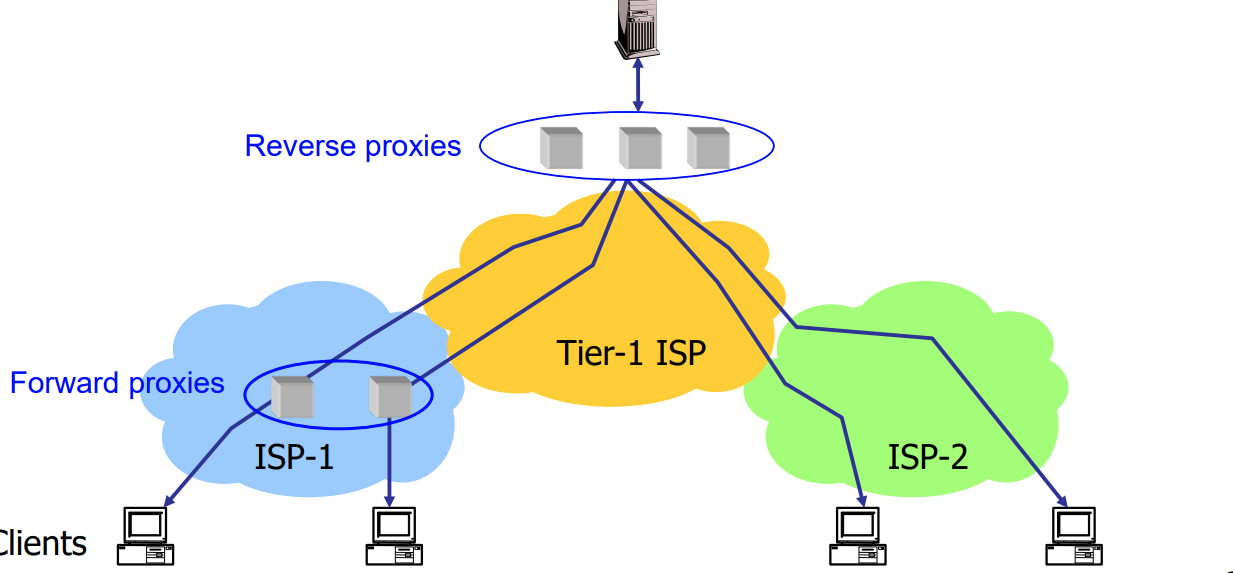
- 反向代理(Reverse proxies):
- 使用反向代理进行缓存可以将文档缓存在靠近服务器的位置。
- Reverse proxies的作用是代表目标服务器处理请求,并将响应返回给客户端。
- 这样做可以减少服务器的负载,因为对于经常请求的文档,反向代理可以直接提供缓存的副本,而无需每次都从服务器获取。
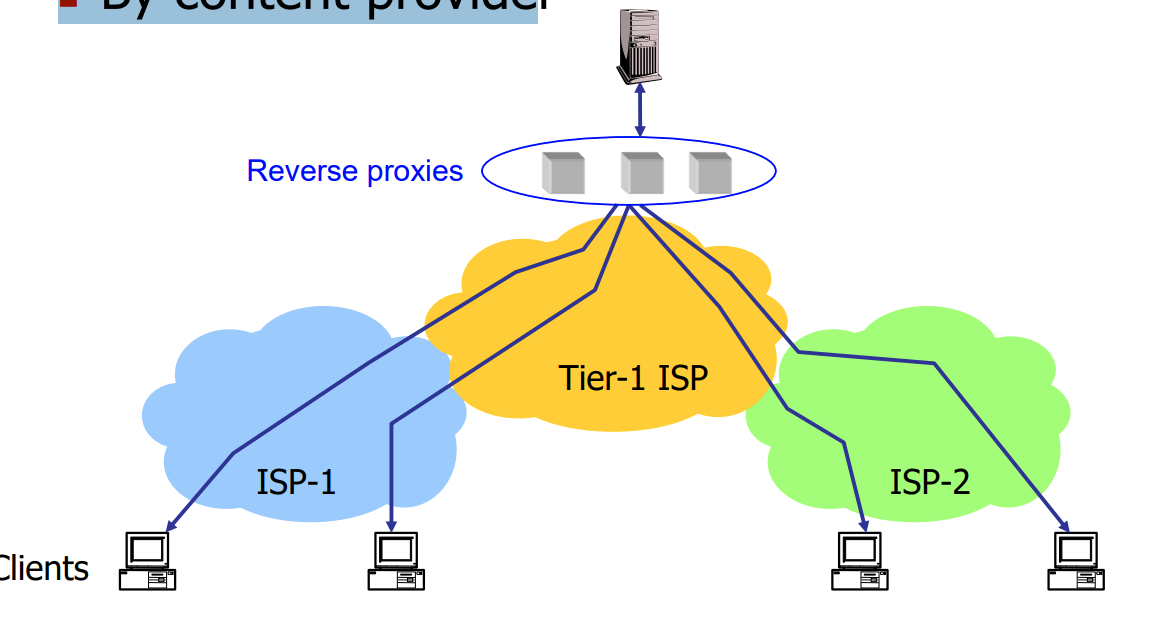
- Forward proxies位于客户端和目标服务器之间,代表客户端发送请求。
- Reverse proxies位于目标服务器和客户端之间,代表目标服务器处理请求。
- Forward proxies用于代表客户端发送请求、隐藏IP地址、提供访问控制和内容过滤等功能。
- Reverse proxies用于代表目标服务器处理请求、负载均衡、缓存内容等功能。
- 内容分发网络(Content Distribution Network,CDN)
CDN
- 起因
- 大量向单一服务器请求,不堪重负
- 防御DDOS
- 解决方案:
- 使用内容分发服务器,与内容生产(源)服务器区分
- 复制源服务器的内容
- 内容提供商(如视频网站)是CDN服务的客户
- CDN服务器会复制服务器的内容,并保持更新
实现
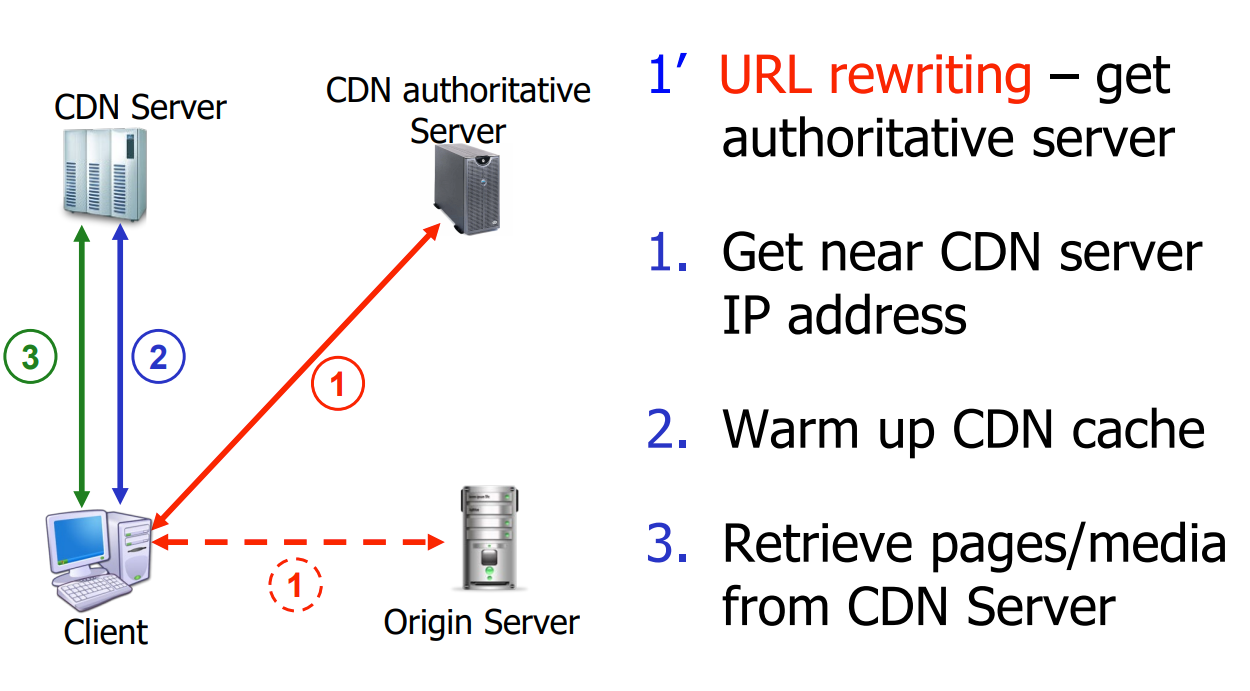
- DNS转接到CDN的地址(重定向)
- 一个域名会映射到多个ip
- (路由)转接到最近的、负载最小的服务器
- CDN通过创建一个“地图”,标示出与末端ISP和CDN服务器之间的距离。当查询到达权威DNS服务器时,服务器确定查询起源的ISP,并使用“地图”来确定最佳的CDN服务器。CDN服务器创建一个应用层覆盖网络。
- URL重定向
- DNS转接到CDN的地址(重定向)